YOLOv5的实现细节解析:基础组件与实现细节
YOLO(You Only Look Once)系列作为目标检测领域的重要算法,以其速度快、性能好而著称。YOLOv5是该系列的最新版本,它在保持YOLO一贯的简洁高效特点的同时,进一步优化了算法性能。本文将深入探讨YOLOv5的实现细节,包括其基础组件和关键实现步骤。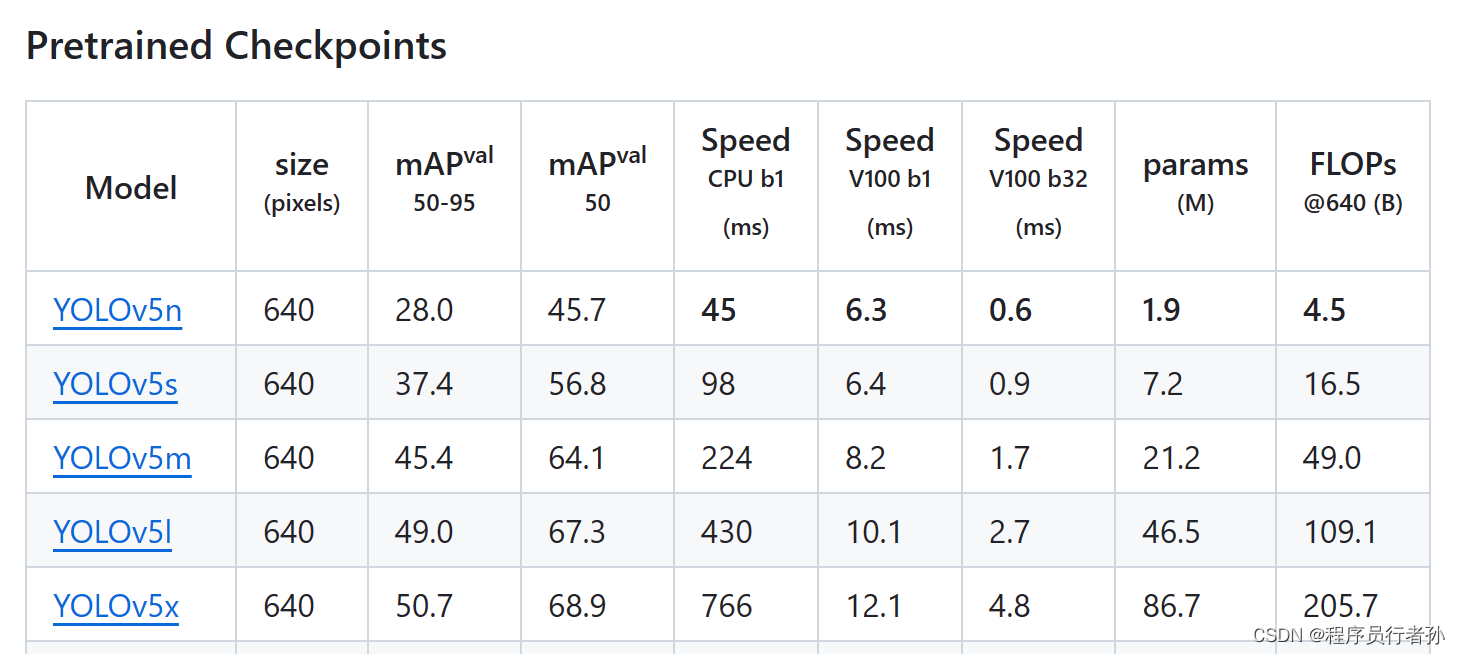
引言
目标检测是计算机视觉中的一项基础任务,目的是识别出图像中所有感兴趣的目标,并给出它们的类别和位置。YOLOv5通过一系列创新,如自注意力机制、Mish激活函数等,实现了对目标检测任务的高效处理。
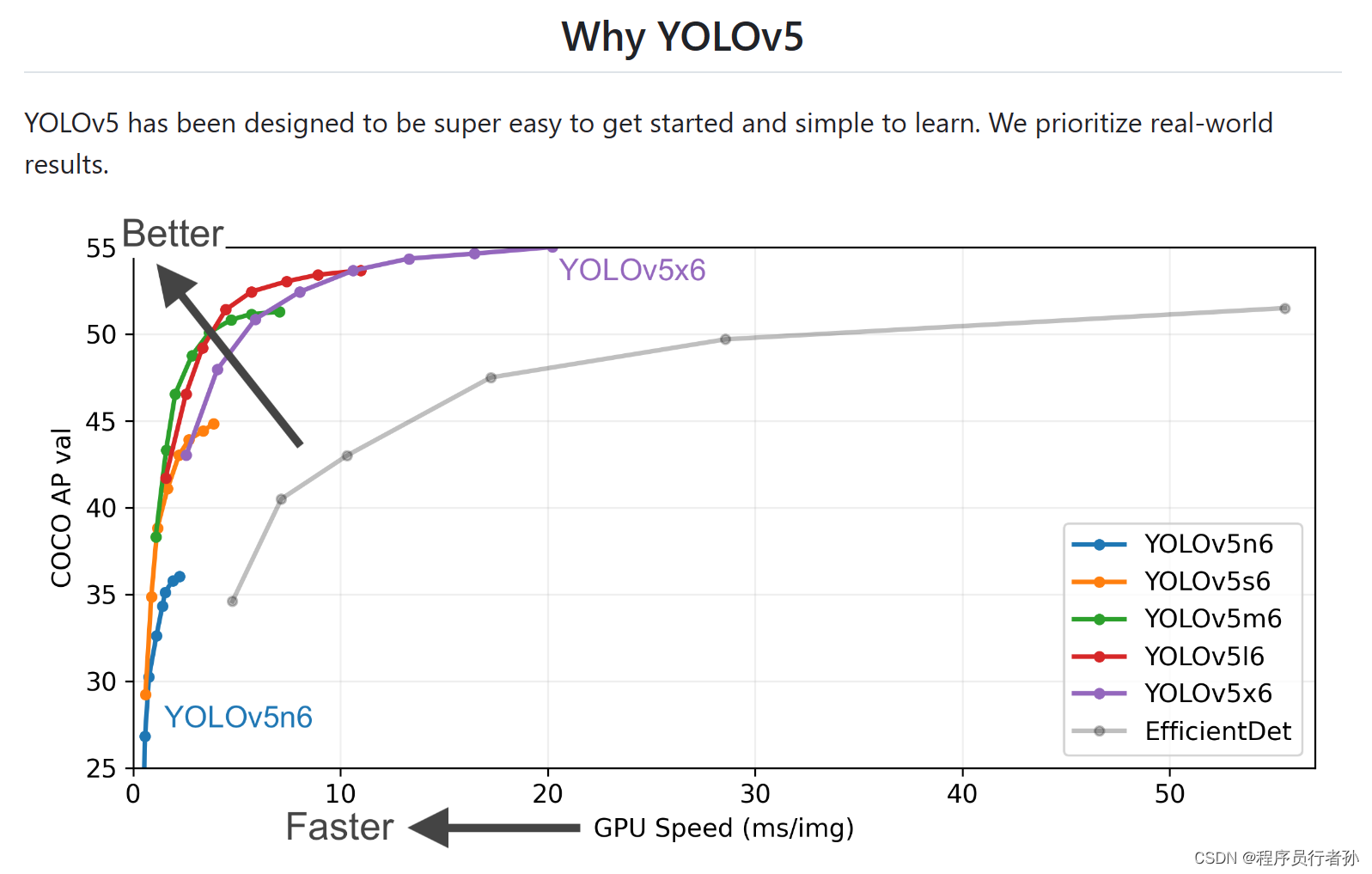
YOLOv5的基础组件
1. 网络架构
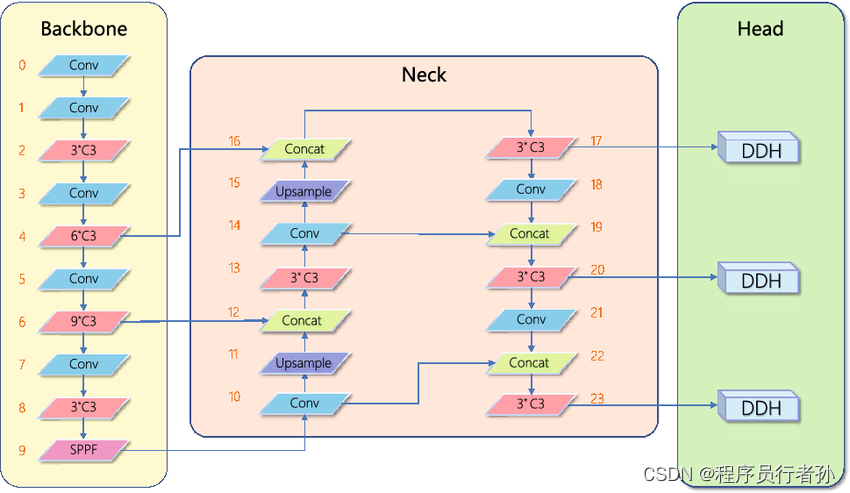
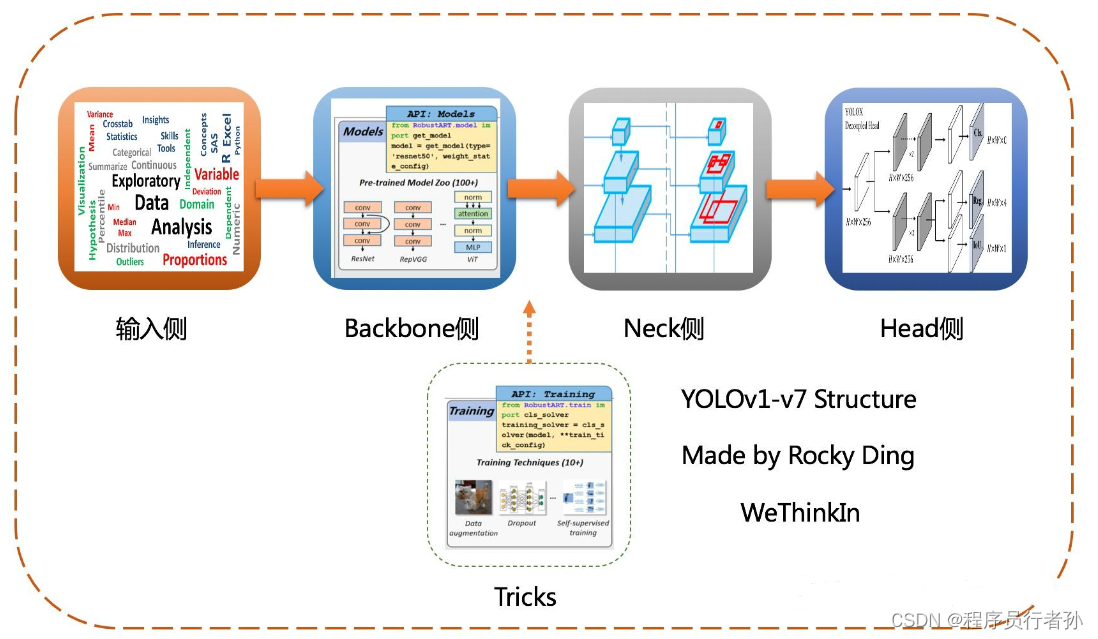
YOLOv5采用了一种模块化的网络架构,主要由三个部分组成:
Backbone(主干网络)
Neck(颈部网络)
Head(头部网络)
在深度学习驱动的目标检测算法中,关键的三个组件包括:
- Backbone:作为特征提取的核心,通常是在大规模数据集(如ImageNet或COCO)上预训练的卷积神经网络,如ResNet-50或Darknet53。
- Head:位于模型的末端,负责预测目标的类别和边界框位置。
- Neck:介于Backbone和Head之间,用于整合不同层级的特征图,以提升检测性能。
目标检测模型的工作流程可概括为:输入数据通过主干网络提取特征,然后颈部网络进一步提炼特征,最终由头部网络完成目标的类别和位置预测,输出检测结果。
YOLOv5与Yolov3及Yolov4进行比较。主要的不同点:
(1)输入端 : Mosaic数据增强(v4中使用到了)、自适应锚框计算、自适应图片缩放
(2)骨干网络(Backbone) : Focus结构,CSP结构
(3)颈部网络(Neck) : FPN+PAN结构
(4)头部网络(Head) : GIOU_Loss
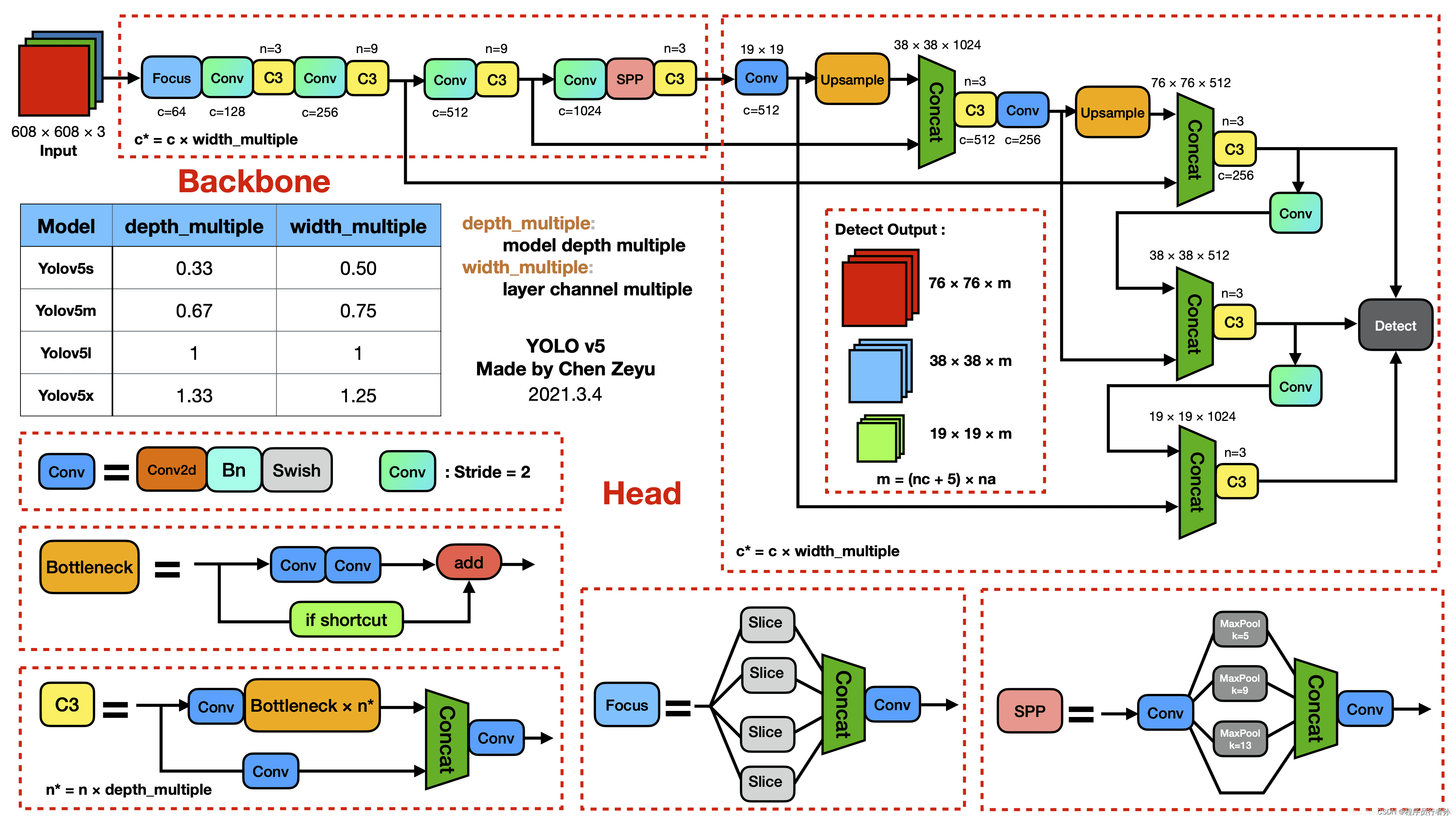
a. Backbone
YOLOv5的骨干网络(Backbone)是整个目标检测模型的基础,负责从输入图像中提取有用的特征。YOLOv5的Backbone采用了New CSP-Darknet53架构,这是一种专门为目标检测任务优化的深度学习模型。
New CSP-Darknet53
-
CSP结构:YOLOv5的Backbone使用了Cross Stage Partial Network(CSPNet)结构,这是一种减少计算量的技术。CSP通过在卷积层之间共享权重,减少了模型的参数数量和计算量,同时保持了特征提取的效率。
-
Darknet架构:Darknet是一个为YOLO系列优化的深度学习框架,它以速度快和资源消耗低而著称。Darknet53是Darknet系列中的一个变种,拥有53层深度,它通过堆叠多个卷积层和池化层来逐步提取图像的深层特征。
-
Focus结构:YOLOv5在Backbone的开始部分使用了Focus结构,这是一种有效的特征融合技术。Focus结构通过将输入图像分割成小块,然后分别提取特征,最后再将这些特征合并,从而提高了模型对小目标的检测能力。
-
预训练权重:YOLOv5的Backbone通常使用在大型数据集(如ImageNet)上预训练的权重进行初始化。这使得模型能够利用在大规模数据集上学习到的通用特征,加速收敛并提高检测性能。
-
高效的激活函数:YOLOv5采用了Mish激活函数,这是一种比传统的ReLU激活函数更加平滑的激活函数,有助于在训练过程中提供更稳定的梯度流动。
-
多尺度特征融合:YOLOv5的Backbone通过SPPF(Spatial Pyramid Pooling with Feature map Fusion)模块,实现了多尺度的特征融合,这使得模型能够同时检测不同大小的目标。
通过这些设计,YOLOv5的Backbone能够高效地从输入图像中提取丰富的特征,为后续的检测任务提供了坚实的基础。这些特征随后会被传递到Neck和Head部分,进行更精细的目标检测和定位。
Focus结构
Focus结构
这里详细讲一下Focus结构,Focus结构是YOLOv5中的一个创新点,它用于在模型的早期阶段有效地进行特征图的下采样,同时增加网络的通道数,以保留更多的图像信息。Focus结构的设计理念是在不增加计算量的前提下,通过特定的操作来提升特征的表达能力。
Focus结构的作用
- 减少计算量:通过特定的切片操作,Focus结构能够在不丢失关键信息的情况下,实现对输入图像的下采样。
- 增加通道数:在下采样的同时,Focus结构将输入图像的通道数增加,这样做可以在后续的网络结构中提供更丰富的特征表示。
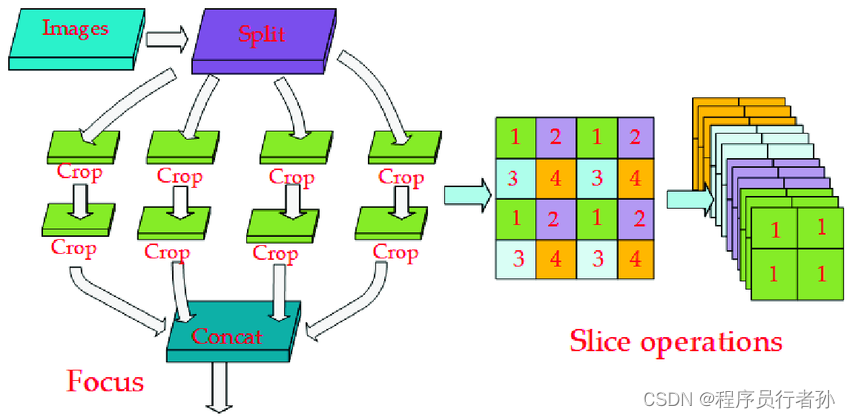
Focus结构的工作原理
Focus结构的工作原理可以分解为以下几个步骤:
-
切片操作:将输入图像按通道进行切片,每隔一个通道取一个通道的值。例如,对于一个具有3个通道的输入图像,如果按照顺序排列通道值为
[C1, C2, C3],则切片后得到的通道值为[C1, 0, C3],其中0代表未使用的通道位置。 -
拼接操作:将切片后得到的图像按通道方向拼接起来。例如,如果原始图像是
320x320x3,经过切片操作后,图像变为160x320x6,因为每个通道的像素点数减半,而通道数翻倍。 -
卷积操作:对拼接后的图像进行卷积操作,通常是一个1x1的卷积,用于混洗和整合特征,最终得到下采样的特征图,尺寸通常是输入图像的一半,但通道数保持不变或有所增加。
Focus结构的优势
- 计算效率:相比于直接进行卷积操作,Focus结构通过切片和拼接的方式减少了计算量。
- 信息保留:尽管进行了下采样,但由于切片操作的特性,图像的关键视觉信息得以保留。
- 特征增强:增加的通道数为后续网络结构提供了更丰富的特征表示,有助于提升检测性能。
Focus结构的实现
在YOLOv5的早期版本中,Focus结构是作为一个独立的模块实现的。但在后续的版本中,为了提高计算效率,特别是考虑到某些硬件对大卷积核的支持更好,Focus结构被一个6x6的卷积层所替代。这个6x6的卷积层在计算上等同于Focus结构的切片和拼接操作,但可能更适合某些GPU硬件的优化。
Focus结构是YOLOv5中的一个创新点,它体现了设计者在保持模型性能的同时对计算效率的重视。通过这种方式,YOLOv5能够在资源受限的设备上实现高效的目标检测。
代码示例
在YOLOv5的早期版本中,Focus结构作为一个独立的模块被实现。以下是一个简化版的Focus结构的代码示例,它展示了如何通过切片和拼接操作来实现通道数的增加和特征图的下采样:
import torch
import torch.nn as nnclass Focus(nn.Module):def __init__(self, c1, c2): # c1为输入的通道数,c2为输出的通道数super(Focus, self).__init__()self.conv = nn.Conv2d(c1 * 4, c2, 3, 2, 1) # 卷积操作,输出通道为c2,步长为2实现下采样def forward(self, x):# 假设输入特征图的尺寸为 [N, C, H, W],其中 C = c1# 切片操作:将C个通道分为4组,每组有C//4个通道# 通过reshape改变维度,使用view操作重新排列通道x = x.view(x.size(0), x.size(1) // 2, 2, x.size(2), x.size(3))x = x.permute(0, 1, 3, 2, 4).contiguous() # 调整维度顺序,然后进行拼接x = x.view(x.size(0), x.size(1) * 2, x.size(2), x.size(3)) # 拼接后的特征图# 通过卷积层实现特征融合,并进行下采样return self.conv(x)# 假设输入的特征图尺寸为 [N, 3, 320, 320]
focus = Focus(c1=3, c2=12)
input_tensor = torch.randn(1, 3, 320, 320) # 随机生成一个输入特征图
output_tensor = focus(input_tensor) # 通过Focus结构print("Output shape:", output_tensor.shape) # 输出特征图的尺寸
在这个代码示例中,Focus 类首先将输入特征图的通道数减半,并将其分为两部分,然后通过view和permute操作重新排列这些通道,实现切片和拼接的效果。最后,通过一个卷积层进一步融合特征并进行空间维度的下采样。
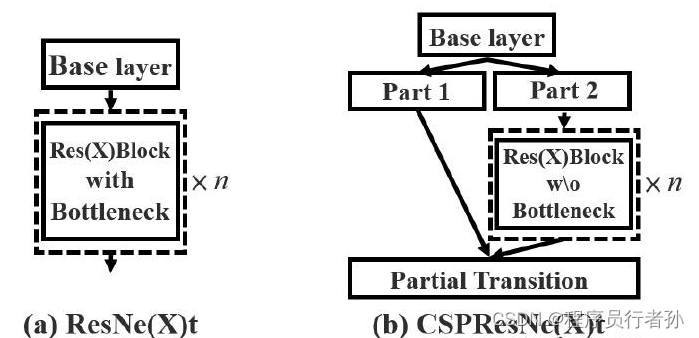
CSP结构
- CSP1_X:在Backbone中使用,通过共享权重减少计算量。
- CSP2_X:在Neck中使用,结合CSP结构和Focus结构的优点,进一步减少计算量并保持特征表达能力。
- CSPNet(Cross Stage Partial Network)是一种用于计算机视觉任务,尤其是在目标检测领域中的网络结构优化技术。CSPNet的核心思想是在网络的多个阶段中共享权重,以此来减少计算量和参数数量,同时保持或提升模型的性能。

CSPNet的主要特点:
-
权重共享:在网络的多个阶段(stage)中,CSPNet通过共享卷积层的权重来减少模型的参数量。
-
计算量减少:由于权重共享,模型在训练和推理时的计算量会显著减少,这使得模型可以更快地训练和执行。
-
性能保持:尽管参数和计算量减少了,CSPNet通过精心设计的网络结构,仍然能够保持较高的性能。
-
灵活性:CSPNet可以很容易地集成到现有的网络架构中,如YOLO系列,以提高效率。
CSPNet的工作流程:
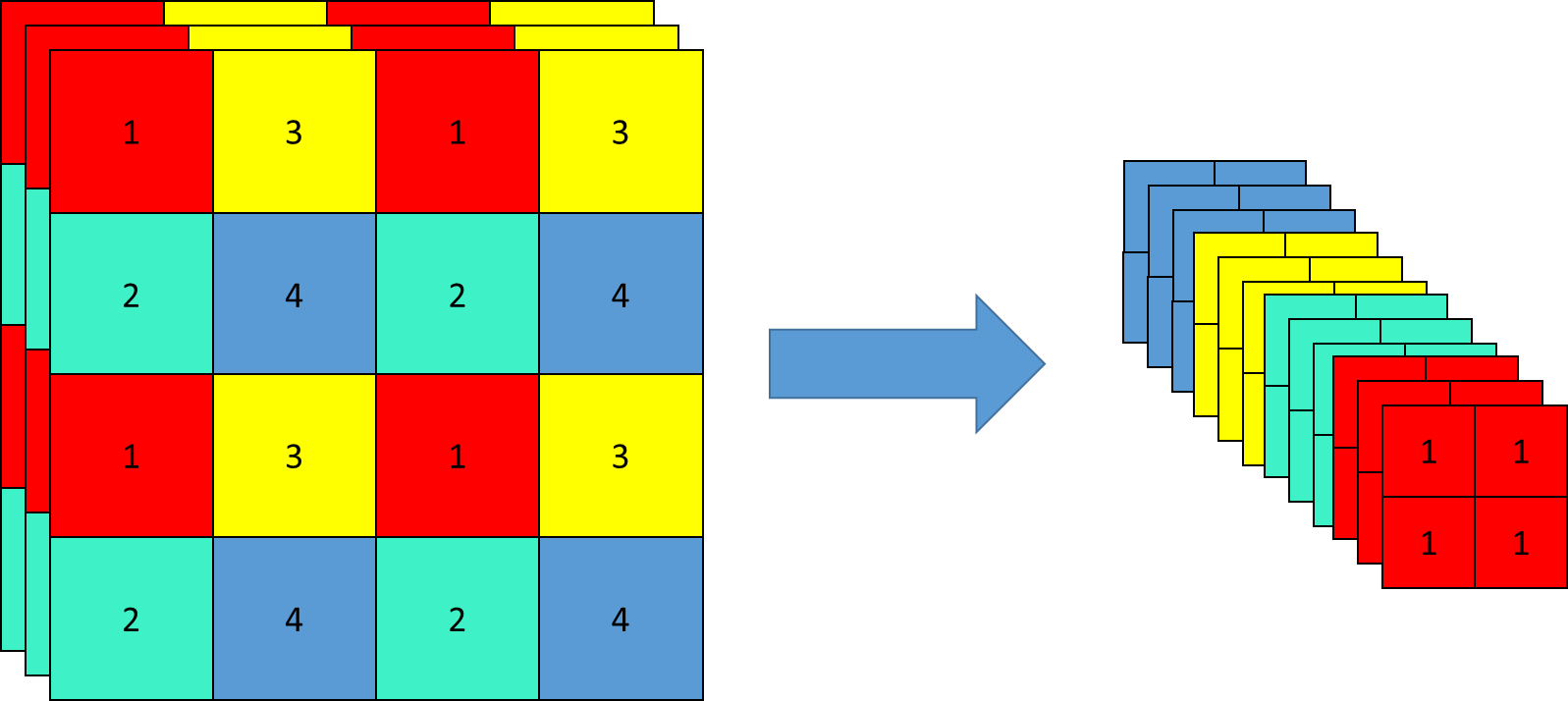
-
输入特征图:网络接收输入特征图,该特征图是从之前的网络层传递而来。
-
卷积操作:对输入特征图进行卷积操作,得到初步的输出特征图。
-
权重共享:将初步的输出特征图复制一份,并将复制的副本与原始输出特征图一起输入到下一个卷积层。在这个阶段,两个输入共享相同的卷积权重。
-
特征融合:通过共享权重的卷积层后,得到的特征图在通道维度上进行合并,形成最终的输出特征图。
-
输出:最终的输出特征图将传递到网络的下一个阶段,用于进一步的处理或作为检测任务的输入。
代码示例:
下面是一个简化版的CSP结构的代码示例,展示了如何在PyTorch中实现CSPNet的概念:
import torch
import torch.nn as nnclass CSPBlock(nn.Module):def __init__(self, c1, c2):super(CSPBlock, self).__init__()self.conv1 = nn.Conv2d(c1, c2, 1, 1, 0, bias=False)self.conv2 = nn.Conv2d(c1, c2, 1, 1, 0, bias=False)def forward(self, x):x1 = self.conv1(x)x2 = self.conv2(x)# 假设这里有一个额外的卷积层或网络分支# 例如: x2 = some_other_conv(x2)return torch.cat([x1, x2], dim=1) # 在通道维度上合并特征图# 假设输入的特征图尺寸为 [N, C, H, W]
csp_block = CSPBlock(c1=64, c2=32)
input_tensor = torch.randn(1, 64, 56, 56) # 随机生成一个输入特征图
output_tensor = csp_block(input_tensor)print("Output shape:", output_tensor.shape) # 输出特征图的尺寸
在这个示例中,CSPBlock 类通过两次卷积操作生成两个特征图,然后将它们在通道维度上合并。这种方式减少了参数数量和计算量,同时保留了特征信息。
CSPNet通过减少模型的计算负担,使得在资源受限的设备上部署高效的深度学习模型成为可能,特别是在需要实时处理的场合,如自动驾驶和视频监控系统中的目标检测。
backbone简要示例代码
import torch
import torch.nn as nndef DarknetConv2d(filter_in, filter_out, kernel_size, stride):pad = (kernel_size - 1) // 2 if kernel_size else 0return nn.Sequential(nn.Conv2d(filter_in, filter_out, kernel_size, stride, pad, bias=False),nn.BatchNorm2d(filter_out),nn.LeakyReLU(0.1))class DarknetResidualBlock(nn.Module):def __init__(self, filter_in, filter_out):super(DarknetResidualBlock, self).__init__()self.conv1 = DarknetConv2d(filter_in, filter_out, 3, 1)self.conv2 = DarknetConv2d(filter_out, filter_out, 3, 1)def forward(self, x):residual = xout = self.conv1(x)out = self.conv2(out)return out + residualclass CSPDarknet53(nn.Module):def __init__(self):super(CSPDarknet53, self).__init__()self.conv1 = DarknetConv2d(3, 32, 6, 2)# 这里省略了中间的层,实际YOLOv5的Backbone会有更多层级self.neck = nn.Sequential(DarknetConv2d(512, 1024, 1, 1),DarknetResidualBlock(1024, 1024))def forward(self, x):x = self.conv1(x)# 这里省略了中间的层级,实际YOLOv5的Backbone会有更多层级x = self.neck(x)return x# 实例化Backbone并进行前向传播测试
backbone = CSPDarknet53()
input_tensor = torch.randn(1, 3, 224, 224) # 假设输入是一个224x224的彩色图像
output_features = backbone(input_tensor)
print(output_features.shape) # 输出特征的维度
这段代码定义了一个非常基础的Backbone,包括一个初始化的卷积层,一个残差结构块,以及一个颈部网络的简化版本。在实际的YOLOv5中,Backbone会有更复杂的结构,包括多个残差结构块、Focus结构、SPPF模块等。此外,实际的YOLOv5 Backone还会使用更高级的技术,如Mish激活函数、自注意力机制等。
b. Neck
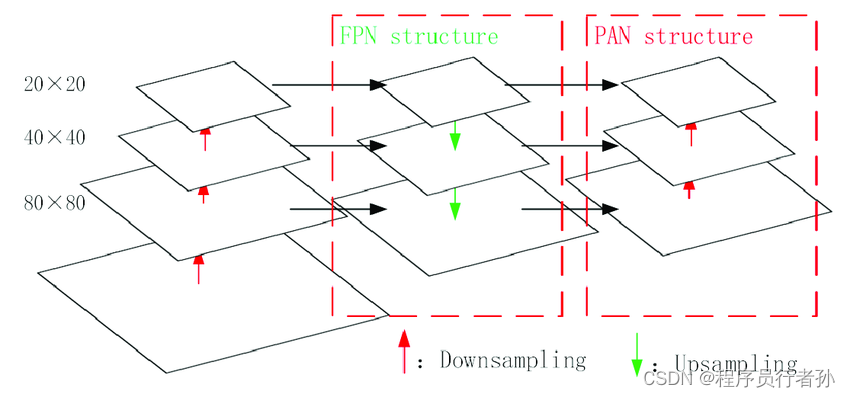
Neck是连接Backbone和Head的中间部分,负责特征的进一步融合和传递:
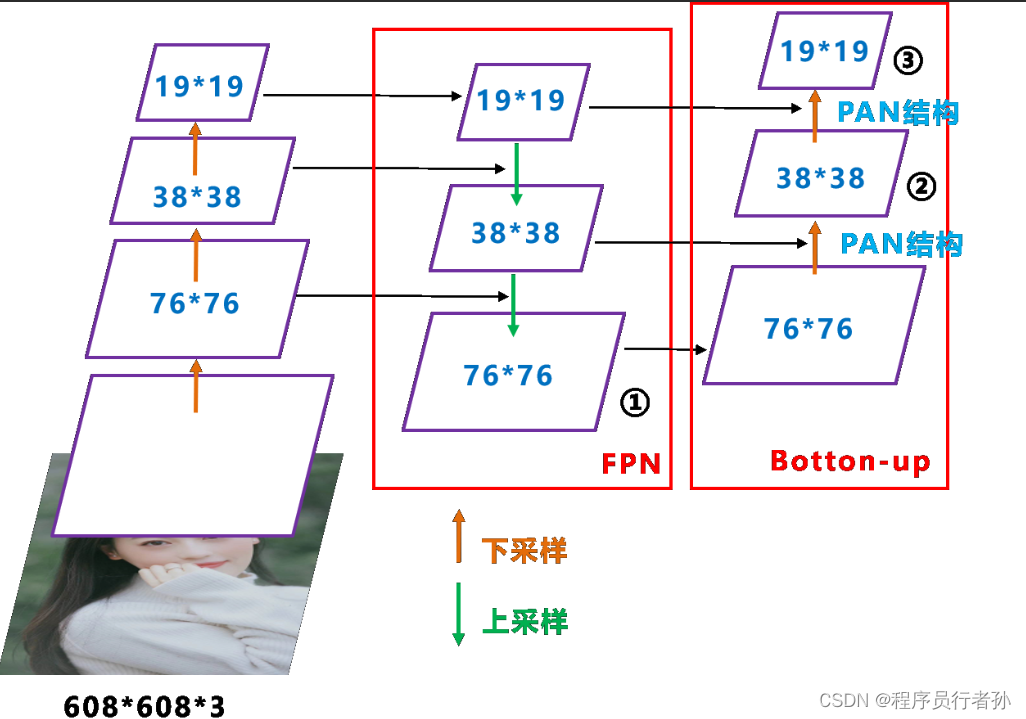
FPN+PAN结构
-
FPN (特征金字塔网络):通过自顶向下的路径传递高层的语义信息。
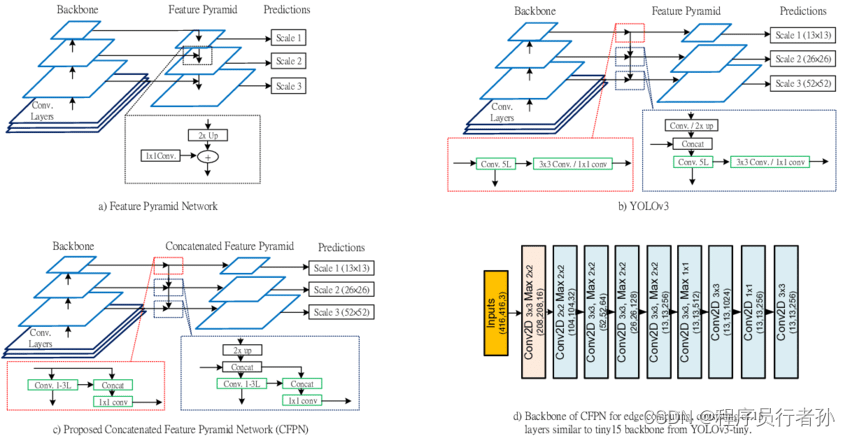
-
PAN (路径聚合网络):通过自底向上的路径传递低层的细节信息。
CSP2结构
- 应用:在Neck中采用CSP2结构,加强了特征融合的能力,同时保持了计算效率。
c. Head
Head部分负责最终的检测任务,包括分类和定位。YOLOv5的Head包括分类器和边界框回归器,它们共同工作以预测每个网格单元中的目标类别和位置。
2. 数据流
YOLOv5的数据流设计是其高效性能的关键因素之一,它通过精心设计的并行处理策略和多尺度预测机制,显著提升了目标检测的速度和准确性。以下是对YOLOv5数据流设计的详细扩写:
并行处理
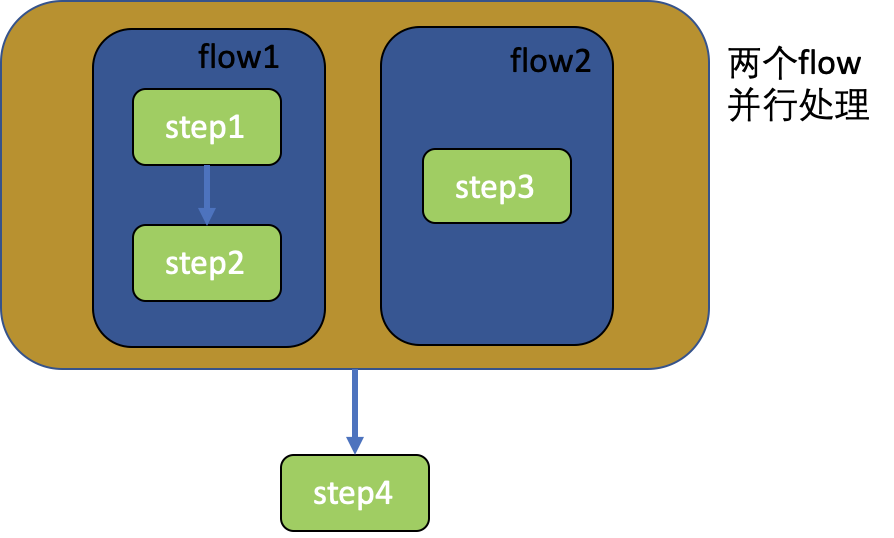
-
多线程数据加载:YOLOv5在数据加载过程中采用多线程技术,允许同时从磁盘读取多个数据样本,而不是传统的单线程串行加载。这种方式显著减少了CPU到GPU的数据传输时间,从而提高了数据的吞吐率。
-
异步I/O操作:YOLOv5的数据流还包括异步I/O操作,这意味着数据的读取和预处理可以不必等待前一个操作完成就能开始,从而进一步提高了数据处理的速度。
-
批处理优化:YOLOv5通过合理的批处理大小优化,确保了GPU的高效利用。批处理太小可能导致GPU资源浪费,而太大则可能导致内存不足。YOLOv5通过实验确定了最优的批处理大小,以达到速度和资源利用的平衡。
-
数据增强策略:YOLOv5的数据流中还包括了数据增强技术,如Mosaic数据增强,这不仅提升了模型的泛化能力,也使得数据加载过程更加高效。
多尺度预测
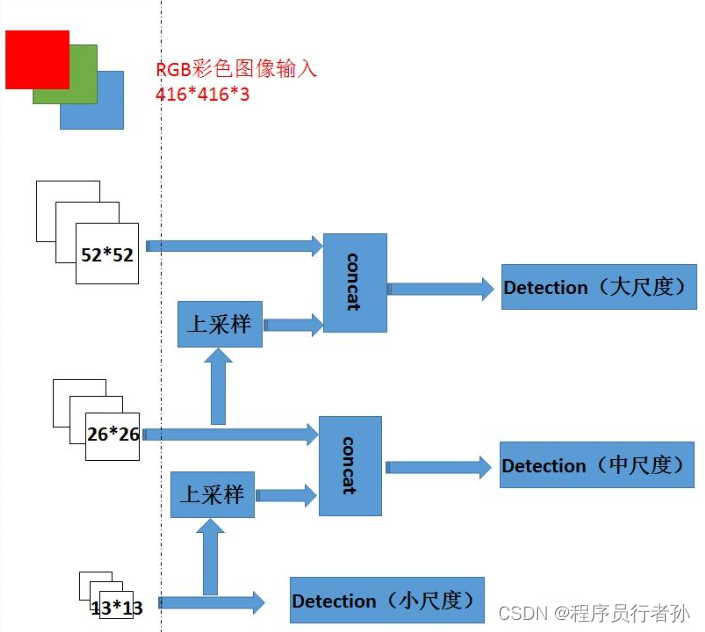
-
特征金字塔:YOLOv5通过FPN和PANet构建了特征金字塔,这允许模型在不同的尺度上进行预测。这种多尺度预测能力使得YOLOv5能够有效地检测不同大小的目标。
-
自适应锚框:YOLOv5引入了自适应锚框技术,根据目标的实际大小动态调整锚框的尺寸,这进一步提升了多尺度预测的准确性。
-
不同尺度的特征融合:YOLOv5的Neck部分通过融合不同尺度的特征图,生成了丰富的特征表示,这为小目标和大目标的检测提供了更加精确的特征信息。
-
损失函数的设计:YOLOv5的损失函数设计也考虑了多尺度预测,如CIoU Loss,它综合考虑了预测框与真实框之间的重叠区域、中心点距离和宽高比,有助于提升不同尺度目标的检测性能。
-
实时性能:由于YOLOv5在不同尺度上进行预测,它能够实现实时目标检测,这对于需要快速响应的应用场景(如视频监控、自动驾驶)尤为重要。
结合并行处理和多尺度预测
YOLOv5将并行处理和多尺度预测结合起来,形成了一个强大的数据处理流水线。这种设计不仅提高了目标检测的速度,也确保了检测的准确性,特别是在处理包含不同尺寸目标的场景时。通过这种方式,YOLOv5在目标检测领域中实现了高效率和高性能的平衡,满足了实时性和准确性的双重要求。
实现细节
YOLOv5在目标检测算法中引入了多项创新技术,以提高检测性能和准确性。以下是对YOLOv5中关键技术点的详细扩写,这些技术点共同构成了YOLOv5高效、准确的目标检测能力。
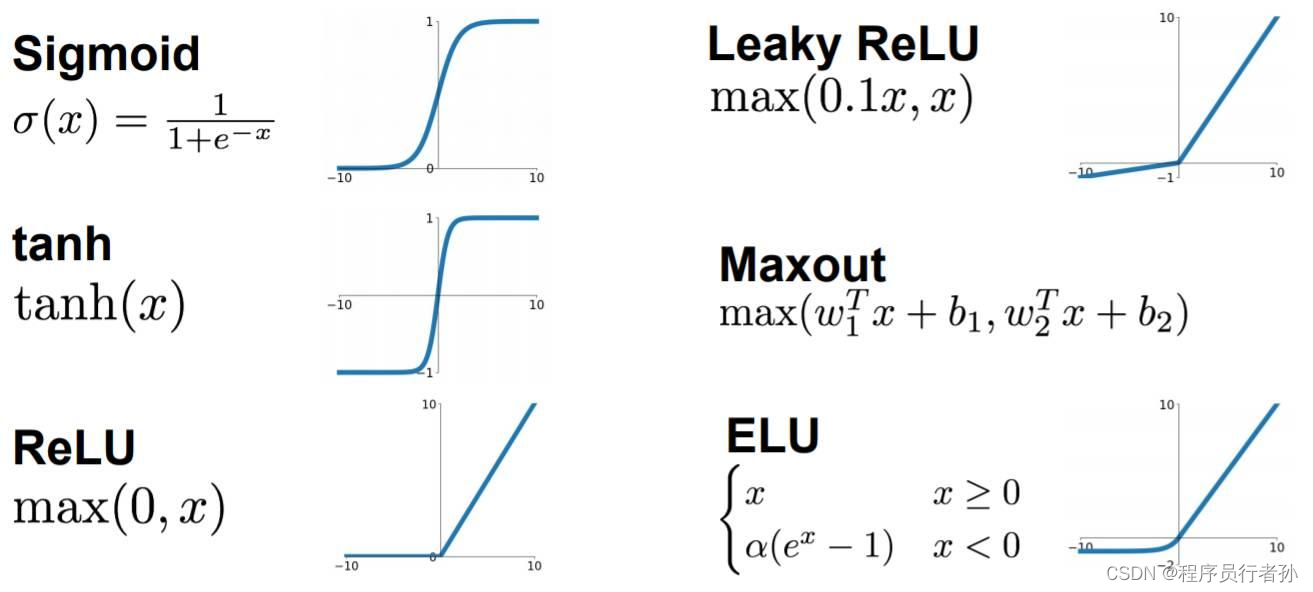
Mish激活函数
Mish激活函数是YOLOv5中的一个关键创新,它在正区间的表现比传统的ReLU激活函数更为平滑,这有助于梯度更有效地流动,从而加快网络训练的收敛速度。Mish的设计避免了ReLU在负区间的梯度消失问题,同时在正区间保持了类似ReLU的线性增长,这对于提取深层次特征和提高模型的非线性表达能力至关重要。
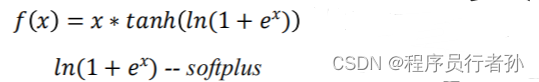
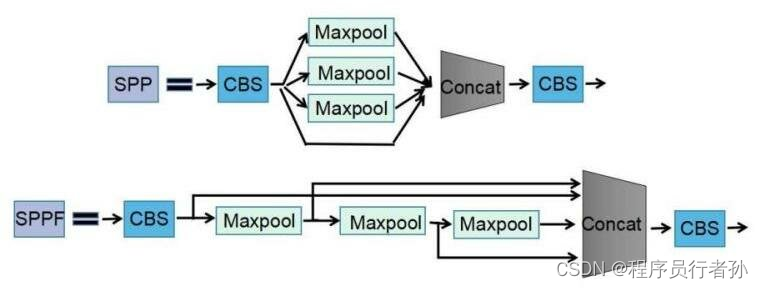
SPPF模块
YOLOv5的SPPF(Spatial Pyramid Pooling with Feature map Fusion)模块通过在不同尺度上聚合特征,增强了模型对不同尺寸目标的检测能力。SPPF模块通过在不同大小的池化窗口上操作,生成多尺度的特征图,然后将这些特征图融合起来,从而使得模型能够捕捉到不同尺度的特征信息,这对于检测不同大小的目标对象非常有效。
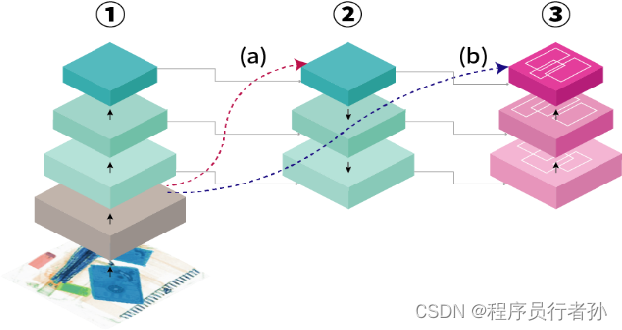
PANet(Path Aggregation Network)
PANet是YOLOv5中用于增强感受野的技术,它通过将低层次的细节特征与高层次的语义特征相结合,提高了小目标的检测性能。PANet的设计允许信息在网络中的多个尺度上流动,这不仅增强了模型对小目标的检测能力,同时也保留了对大目标检测的准确性。
自注意力机制
在某些版本的YOLOv5中,自注意力机制的引入进一步提升了模型的性能。自注意力机制使模型能够更加关注图像中与目标最相关的部分,无论这些目标位于图像的哪个位置。这种机制特别有利于检测那些在图像中不占主导地位或被遮挡的目标对象。
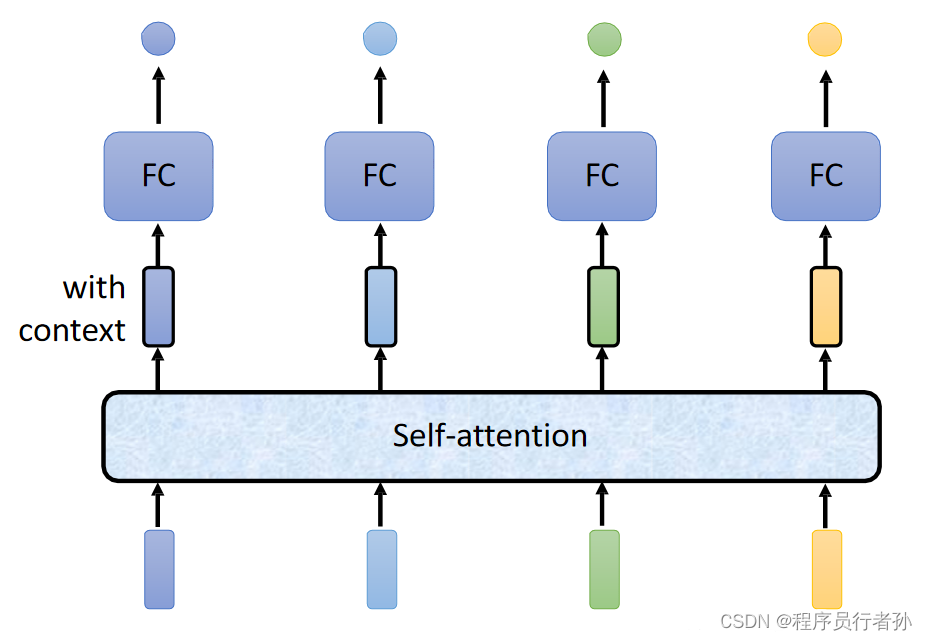
自注意力机制(Self-Attention Mechanism)是一种在深度学习模型中模拟序列内部不同位置间关联的机制,它允许模型在处理序列数据时,能够捕捉序列内部的长距离依赖关系。自注意力机制在自然语言处理(NLP)领域尤其流行,如Transformer模型中就广泛使用了自注意力机制。
以下是使用PyTorch框架实现的自注意力层的一个简单示例:
import torch
import torch.nn as nn
import torch.nn.functional as Fclass SelfAttention(nn.Module):def __init__(self, embed_size, heads):super(SelfAttention, self).__init__()self.embed_size = embed_sizeself.heads = headsself.head_dim = embed_size // headsassert (self.head_dim * heads == embed_size), "Embedding size needs to be divisible by heads"self.values = nn.Linear(self.head_dim, self.head_dim, bias=False)self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False)self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False)self.fc_out = nn.Linear(heads * self.head_dim, embed_size)def forward(self, values, keys, query, mask):N = query.shape[0]value_len, key_len, query_len = values.shape[1], keys.shape[1], query.shape[1]# Split the embedding into 'heads' number of headsvalues = values.reshape(N, value_len, self.heads, self.head_dim)keys = keys.reshape(N, key_len, self.heads, self.head_dim)queries = query.reshape(N, query_len, self.heads, self.head_dim)values = self.values(values)keys = self.keys(keys)queries = self.queries(queries)# Einsum does matrix multiplication for query*keys for each training example# with a specific headattention = torch.einsum("nqhd,nkhd->nhqk", [queries, keys])if mask is not None:attention = attention.masked_fill(mask == 0, float("-1e20"))# Apply softmax activation to the attention scoresattention = F.softmax(attention / (self.embed_size ** (1 / 2)), dim=3)out = torch.einsum("nhql,nlhd->nqhd", [attention, values]).reshape(N, query_len, self.heads * self.head_dim)# Combine the attention heads togetherout = self.fc_out(out)return out# Example usage
embed_size = 256
heads = 8
attention = SelfAttention(embed_size, heads)# Dummy data
N = 3 # number of samples
value_len, key_len, query_len = 5, 6, 7 # sequence lengths
values = torch.rand((N, value_len, embed_size))
keys = torch.rand((N, key_len, embed_size))
queries = torch.rand((N, query_len, embed_size))
mask = None # Add mask here if neededout = attention(values, keys, queries, mask)
print(out.shape) # Should be (N, query_len, embed_size)
在这个例子中,SelfAttention类定义了一个自注意力层,它将输入的嵌入(embedding)分割成多个“头”(heads),然后每个头独立地计算查询(query)、键(key)和值(value)之间的关系,最后将结果合并回去。einsum函数用于执行高效的矩阵乘法,以计算注意力分数。
请注意,这个例子是一个简化的自注意力机制实现,没有包括完整的Transformer模型中的所有细节,例如层规范化(LayerNorm)和前馈网络(Feed-Forward Networks)。此外,为了在实际应用中使用,可能还需要添加更多功能,如对齐掩码(padding masks)和序列长度掩码(sequence length masks)。
Anchor Boxes
YOLOv5使用预定义的Anchor Boxes来预测边界框,这些框基于数据集中目标的典型尺寸和形状。Anchor Boxes的引入使得网络能够学习预测目标的实际大小和位置,从而提高了边界框预测的准确性。
CIoU Loss
YOLOv5采用了CIoU(Complete Intersection over Union)Loss函数来优化边界框预测。CIoU Loss不仅考虑了预测框与真实框之间的重叠区域,还考虑了两者中心点的距离、宽高比和对角线长度,从而更全面地评估预测框与真实框之间的相似度。CIoU Loss的引入使得模型在训练过程中能够更精确地预测边界框,尤其是在目标尺寸和形状上。
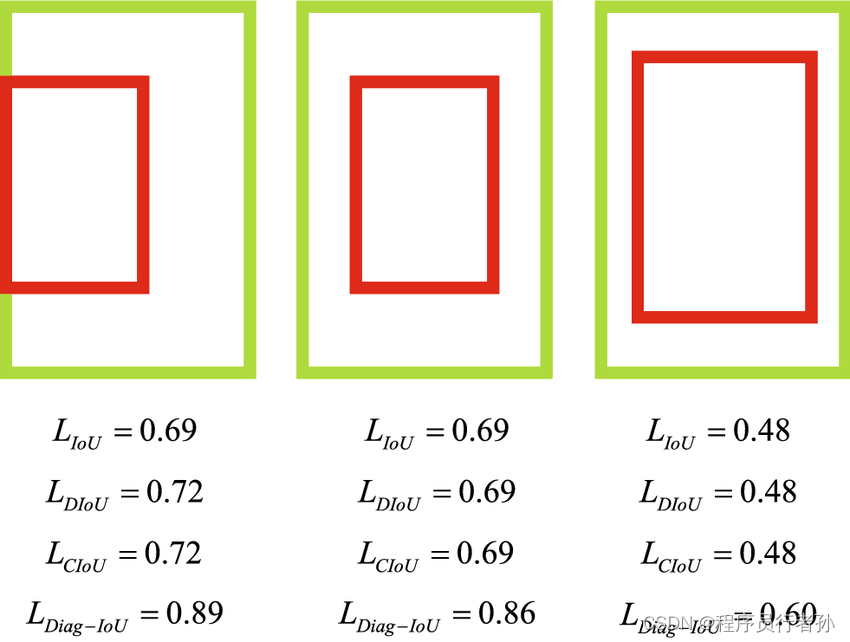
IOU计算对比
综合影响
YOLOv5通过这些技术的有机结合,实现了对目标检测任务的高效处理。Mish激活函数和自注意力机制增强了模型的特征提取能力,而SPPF模块、PANet和Anchor Boxes则提升了模型对多尺度目标的检测性能。CIoU Loss的采用进一步提高了边界框预测的准确性。这些技术的融合,使得YOLOv5在目标检测领域中表现出色,无论是在速度还是准确性上,都达到了业界领先水平。
结论
YOLOv5通过一系列创新和优化,实现了在目标检测任务中的高效和准确。从基础组件到实现细节,YOLOv5展示了如何通过精心设计来提升算法性能。随着计算机视觉技术的不断进步,YOLOv5及其后续版本将继续在该领域扮演重要角色。