关于网络入侵检测领域使用Spark/Flink等计算框架做分布式
- 0、引言
- 1 基于LightGBM的网络入侵检测研究
- 2 基于互信息法的智能化运维系统入侵检测Spark实现
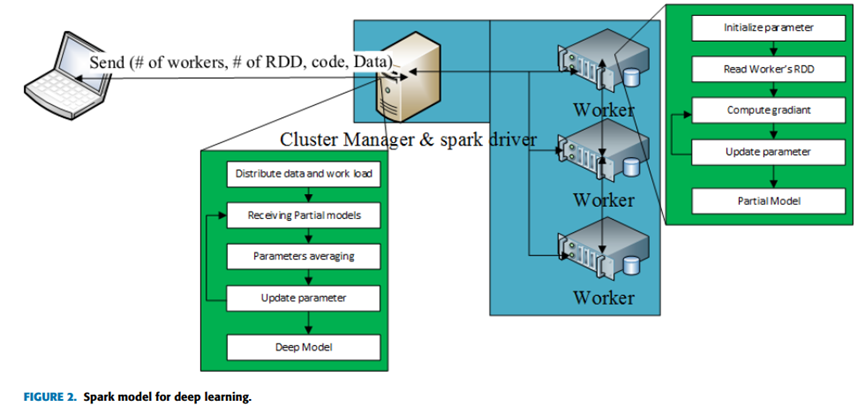
- 3 基于Spark的车联网分布式组合深度学习入侵检测方法
- 4 基于Flink的分布式在线集成学习框架研究
- 5 基于Flink的分布式并行逻辑回归算法的研究
- 6 Flink平台下的分布式平衡级联支持向量机
- 7 Flink水位线动态调整策略
- 8 面向Flink的负载均衡任务调度算法的研究与实现
- 9 面向云环境的Flink负载均衡策略
- 10 Network intrusion detection in big dataset using spark
- 11 Apache Spark and Deep Learning Models for High-Performance Network Intrusion Detection Using CSE-CIC-IDS2018
- 12 Research of intrusion detection algorithm based on parallel SVM on spark
- 13 Development of a network intrusion detection system using Apache Hadoop and Spark
- 14 Implementing a deep learning model for intrusion detection on apache spark platform
- 15 Performance evaluation of classification algorithms in the design of Apache Spark based intrusion detection system
⚠申明: 未经许可,禁止以任何形式转载,若要引用,请标注链接地址。 全文共计5277字,阅读大概需要5分钟
🌈更多学习内容, 欢迎👏关注👀【文末】我的个人微信公众号:不懂开发的程序猿
个人网站:https://jerry-jy.co/
0、引言
本篇博客是我在做基于Spark/Flink大数据环境下网络入侵检测的小论文过程中,阅读的一些参考文献,并把我认为对我有用的地方记录下来,希望也能打开你的研究思路
1 基于LightGBM的网络入侵检测研究
[1]唐朝飞,努尔布力,艾壮.基于LightGBM的网络入侵检测研究[J].计算机应用与软件,2022,39(08):298-303+311.
针对传统的常用机器学习算法在网络入侵检测中存在准确率不够高、训练速度慢的缺点,提出基于特征选择、LightGBM 的网络入侵检测系统。 使用 PCA 进行特征选择,采用 QPSO 为 LightGBM 算法选择最优参数,在 Spark 集群上运行,缩短了训练时间。 此外,由于使用了基于 PCA 的特征选择方法,仅使用了 41 个特征中的 9个(21. 95% ),达到优于使用全部特征训练模型的性能。 在 NSL⁃KDD 数据集上测试了提出的系统的性能,其能准确、快速地对入侵行为样本进行识别。

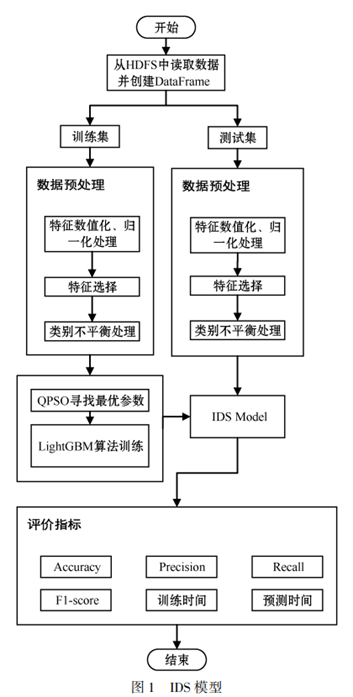
算法流程:
基于 PCA 的特征选择 —> 基于 LightGBM 的机器学习算法检测 —> 基于 QPSO 的智能优化算法进行超参数寻优算法
2 基于互信息法的智能化运维系统入侵检测Spark实现
[1]葛军凯,李震,张秀峰等.基于互信息法的智能化运维系统入侵检测Spark实现[J].自动化仪表,2022,43(03):26-28+33.DOI:10.16086/j.cnki.issn1000-0380.2020120064.
为了提高大数据平台处理海量数据的性能和准确性,在分析互信息(MI)算法的基础上,设计了基于 MI 算法的智能化运维系统入侵检测系统。 选取 UNSW-NB15 数据集,以 Spark 平台进行试验设计并完成测试过程。 通过 Spark 主执行器实现对从节点的控制功能。 在入侵检测阶段,分别采用 3 种机器学习方法进行检测,分别通过试验对比检测率,误报率和精确度。 相对于主成分分析(PCA)算法,MI 算法可以获得更高的特征提取精度,检测率明显提升,降低了误报率。 虽然 MI 算法具备较高精度,但也因此消耗较长时间。 当数据量快速增加后,分布式模型表现出了更短的入侵检测时间。 该研究对提高运维系统入侵检测稳定性具有一定的实践指导意义,但在小概率攻击类型中该算法存在导致检测率为零结果,有后续进一步的加强
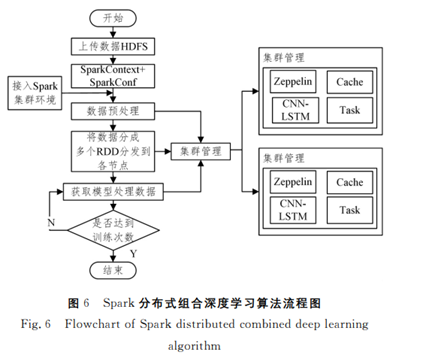
3 基于Spark的车联网分布式组合深度学习入侵检测方法
[1]俞建业,戚湧,王宝茁.基于Spark的车联网分布式组合深度学习入侵检测方法[J].计算机科学,2021,48(S1):518-523.

4 基于Flink的分布式在线集成学习框架研究
[1]曹张宇,钟原,周静.基于Flink的分布式在线集成学习框架研究[J].计算机应用研究,2023,40(06):1784-1788.DOI:10.19734/j.issn.1001-3695.2022.09.0535.
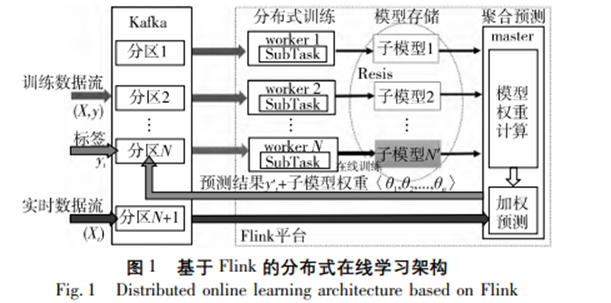
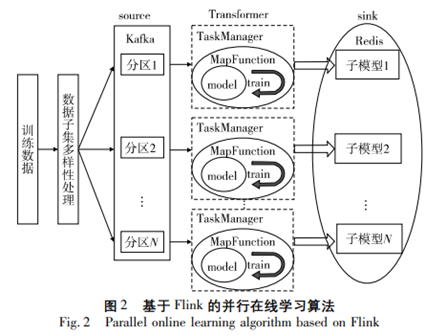
(1)本文设计的算法是在自己搭建的仿真环境下完成测试,对于是否能够更有效地处理真实环境中规模更大、计算更复杂的数据,后续仍需要继续研究。
(2)该算法只针对 Flink 集群,未来希望本文提出的 DSAWP 算法可以应用于其它的大数据计算引擎中,并取得性能提升。
(3)该算法要考虑实时监测和收集节点的资源性能指标数据,在提高集群性能时对集群的计算时延有一定的影响,所以下一步的研究就是对集群资源使用率设置约束阈值,找出平衡集群吞吐量和计算时延之间的参数,从而使得集群性能达到更优
5 基于Flink的分布式并行逻辑回归算法的研究
[1]安超广.基于Flink的分布式并行逻辑回归算法的研究[J].长江信息通信,2023,36(04):65-67.
逻辑回归
目前,机器学习中主要有两种并行化方案,分别是模型并行化与数据并行化。模型并行化是由于模型太过于庞大,在一个计算机中难以放下,所以需要将模型拆分为多块,分别放到不同的计算机中进行相应的计算任务。数据并行化则是在每个节点中都放置了完整的模型,让每个节点使用不同的数据训练模型[6]。数据并行的并行化方案适合于数据量大的情况。
主要是使用其 Sigmoid 函数,将计算结果映射到(0,1),其中结果大于 0.5 的可划为第一类,结果小于 0.5 的部分可被划为第二类。


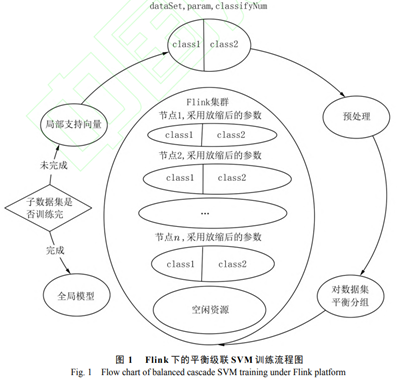
6 Flink平台下的分布式平衡级联支持向量机
[1]刘屹成,刘晓燕,严馨.Flink平台下的分布式平衡级联支持向量机[J/OL].云南大学学报(自然科学版):1-8[2023-08-02].http://kns.cnki.net/kcms/detail/53.1045.N.20230410.1007.004.html.
在训练之前,需要对数据集进行平衡分组及统计样本数量的预处理. 分块后的子数据集中,各类样本所占比例始终与原数据集相同. 由于 Flink 集群中的 TaskManager(类似于一台机器,也被称为 Worker)属性需要在启动前配置好,在启动后基本无法更改,真正用于执行任务的 Task Slot(相当于 TaskManager 上的一个执行任务的容器)在默认情况下是根据配置平分 TaskManager 中的所有资源. 故此处需要采用动
态资源分配策略,对 TaskManager 中的资源进行细粒度管理,与默认的粗粒度资源管理的对比如图 2所示. 在动态资源分配策略下,各节点所需最小资源集的计算方法为存储样本所需内存加上核函数矩阵所需内存,如在 LibSVM[16] 中,其计算方法如下:
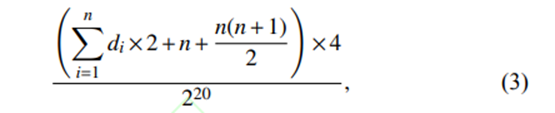
其中:n 为分配到各节点的样本数量, di为各样本的实际有效维度 (即取值不为 的维度). 4表示 float 类型的占用空间 , 2^20表示所需内存空间的单位为MB. 该方法可以根据样本数量决定节点所需的实际内存大小,也可以根据节点的资源属性,为不同规模的数据集采取相应的任务调度策略[17].算法工作需要提供 3 个参数:dataSet 代表需要训练的数据集;classifyNum 指每层训练时的子数据集个数;param 表示训练所需的参数,如惩罚参数
7 Flink水位线动态调整策略
[1]吕鹤轩,黄山,艾力卡木·再比布拉等.Flink水位线动态调整策略[J].计算机工程与科学,2023,45(02):237-245.
衡量大数据的数据挖掘性能有2个最重要的任务指标:一是实时性,二是准确性。流数据从数据产生到消息队列再通过数据源流入 Flink进行计算,这个过程中因为网络传输速度不同,不同节点的计算性能不同等原因,流数据进入计算框架的先后顺序和数据产生的事件时间顺序会有局部乱序的现象。面对窗口作业的传统水位线机制在不确定乱序程度的流数据情况下无法同时兼顾作业结果的实时性和准确性。针对这个问题,建立了流数据微簇模型。通过局部乱序度算法,根据流数据微簇的流数据事件时间局部乱序程度计算出可以代表当前时刻流数据的乱序度。设计了水位线动态调整策略,使水位线根据流数据的乱序程度动态调整大小。最后,在 ApacheFlink框架中对基于事件时间窗口的水位线动态调整策略进行了实现。实验结果表明,弹性或不确定乱序流数据条件下,基于事件时间窗口的水位线动态调整策略可以有效地同时兼顾窗口作业的准确性和实时性
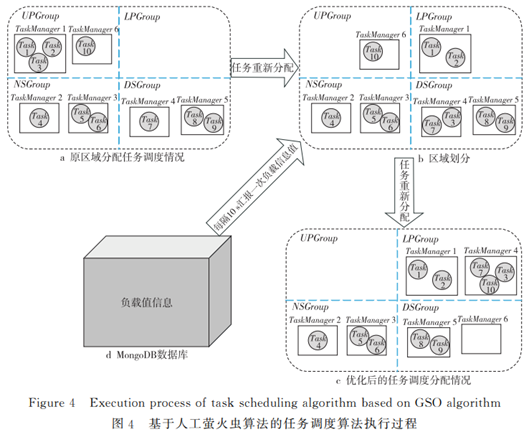
8 面向Flink的负载均衡任务调度算法的研究与实现
[1]李文佳,史岚,季航旭等.面向Flink的负载均衡任务调度算法的研究与实现[J].计算机工程与科学,2022,44(07):1141-1151.
大数据计算引擎的发展历程主要分为4个阶段。第一代大数据计算引擎是谷歌于 2004 年提出的基于 MapReduce[1]的 Hadoop[2]计算引擎。Hadoop主要依靠把任务拆分成 map和reduce2个阶段去处理,这种模式由于难以支持迭代计算,因此产生了第二代基于有向无 环 图 DAG(Directed AcyclicGraph)[3]的 以Tez[4]和 Oozie为代表的计算引擎。虽然第二代计算引擎解决了 MapReduce中不支持迭代计算的问题,但是由于这种计算引擎只能处理离线任务,在线任务处理需求增加的驱动下,产生了第三代基于弹 性 分 布 式 数 据 集 RDD(Resilient Distributed Dataset)[5]的Spark[6]计算引擎。Spark既可以处理离线计算也可以处理实时计算,它是在 Tez的基础上对Job作了更细粒度的拆分,但是其延迟较大,难以处理实时需求更高的连续流数据请求。因此,产生了现在主流的可以处理高实时性任务的第四代大数据计算引擎 Flink [7]。Flink对事件时间的支持、精确一次(Exactly-Once)的状态一致性以及内部检查点机制等特性,决定了其在大数据计算引擎上占据主流地位。
本文提出了基于资源反馈的负载均衡任务调度算法 RFTS(load balancing Task Scheduling algorithm based on Resource Feedback)。与传统的负载均衡算法不同的是,RFTS算法综合考虑了集群计算资源的实时负载情况以及处理任务的优先级和顺序,更高效地完成任务与计算资源之间的分配,通过实时资源监控、区域划分和基于人工萤火虫优化 GSO(Glowworm Swarm Optimization)的任务调度算法3个模块,把负载过重的机器中处于待队列中的任务分配给负载较轻的机器,提高系统处理任务的执行效率和集群利用率。
9 面向云环境的Flink负载均衡策略
[1]徐浩桐,黄山,孙国璋等.面向云环境的Flink负载均衡策略[J].计算机工程与科学,2022,44(05):779-787.
结果表明,在相当高的吞吐量下,Storm 和 Flink 的延迟远低于 Spark Streaming(其延迟与吞吐量成正比)。另一方面,Spark Streaming 能够处理更高的最大吞吐量,但其性能对批处理持续时间设置非常敏感。
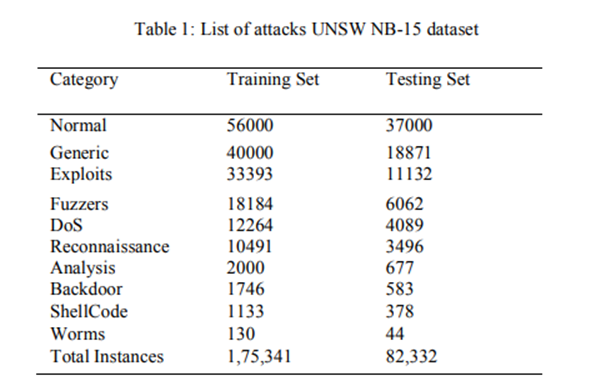
10 Network intrusion detection in big dataset using spark
Dahiya, Priyanka, and Devesh Kumar Srivastava. “Network intrusion detection in big dataset using spark.” Procedia computer science 132 (2018): 253-262.
11 Apache Spark and Deep Learning Models for High-Performance Network Intrusion Detection Using CSE-CIC-IDS2018
Hagar, Abdulnaser A., and Bharti W. Gawali. “Apache Spark and Deep Learning Models for High-Performance Network Intrusion Detection Using CSE-CIC-IDS2018.” Computational Intelligence and Neuroscience 2022 (2022).
12 Research of intrusion detection algorithm based on parallel SVM on spark
Wang, Hongbing, Youan Xiao, and Yihong Long. “Research of intrusion detection algorithm based on parallel SVM on spark.” 2017 7th IEEE International Conference on Electronics Information and Emergency Communication (ICEIEC). IEEE, 2017.
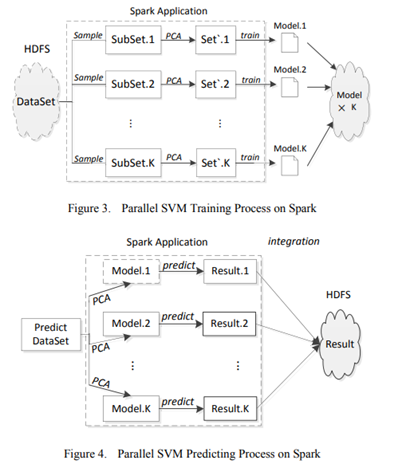
SVM 是强大的分类和回归工具。到目前为止,已经出现了一些SVM模型,例如顺序最小优化(SMO)、libSVM、lightSVM等。然而,直接使用它们不适合处理大规模数据集。当训练样本规模变大时,SVM算法训练所占用的内存和时间急剧增加[4]。此外,单一SVM算法无法有效处理大规模数据集。为了解决SVM处理大量数据不足的问题,目前的解析策略大致分为并行SVM算法[5]、[6]或采用分而治之的策略来缩小数据范围[7]。
入侵检测分析器的设计本质上是确定一个判别函数,以划分输入数据集D
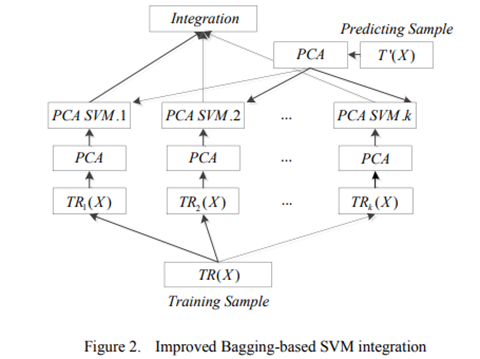
Bagging 整合策略 ???
改进的基于Bagging的SVM集成策略
对于分类问题,分类器的性能非常依赖于所研究的样本,而样本中的无用信息,如冗余、噪声或不可靠信息,会削弱分类器的能力。在入侵检测中,入侵行为信息往往只集中在某些特征上,如Dos和Probe类型的入侵主要与流量属性相关,U2R和R2L主要与内容属性相关。学习算法的冗余特征也会产生影响。随着不相关特征的增加,学习问题不容易描述,分类精度会大大降低,学习算法的速度会受到影响。为了减少大量冗余信息的干扰,
在模型训练开始之前,将待训练的入侵数据上传到HDFS分布式文件存储系统。Spark集群的任务调度将数据集分为K块。每个部分在执行器中创建一个新任务,并分配计算资源。然后在Spark集群上进行PCA数据处理和SVM并行训练,直到训练完成得到K个模型。每个模型用于预测待测试数据集,最后通过投票将预测结果合并。
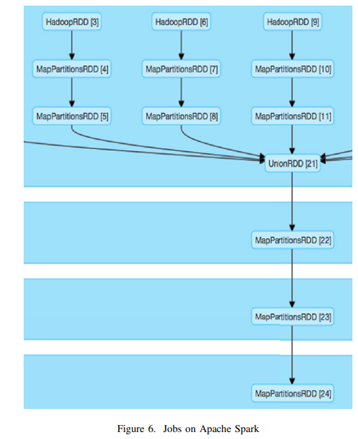
13 Development of a network intrusion detection system using Apache Hadoop and Spark
Kato, Keisuke, and Vitaly Klyuev. “Development of a network intrusion detection system using Apache Hadoop and Spark.” 2017 IEEE Conference on Dependable and Secure Computing. IEEE, 2017.
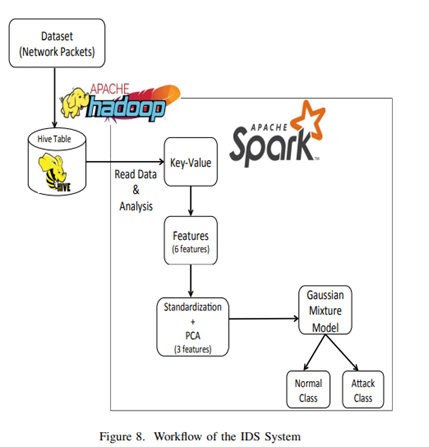
14 Implementing a deep learning model for intrusion detection on apache spark platform
Haggag, Mohamed, Mohsen M. Tantawy, and Magdy MS El-Soudani. “Implementing a deep learning model for intrusion detection on apache spark platform.” IEEE Access 8 (2020): 163660-163672.
NSL-KDD数据集中存在的攻击是以下四种类型之一:
拒绝服务攻击(DoS),这是一种通过消耗计算和内存资源来针对服务可用性的攻击。
用户对根攻击 (U2R),这种攻击首先以网络上的合法用户身份进行访问,然后尝试利用漏洞来获取根访问权限。
远程到本地攻击 (R2L),这是一种用户以远程用户身份登录,然后像本地用户一样尝试检测系统漏洞并利用权限的攻击。
探测攻击(Probe),这是一种尝试收集有关计算机网络的数据,以便在以后的攻击中使用这些数据。
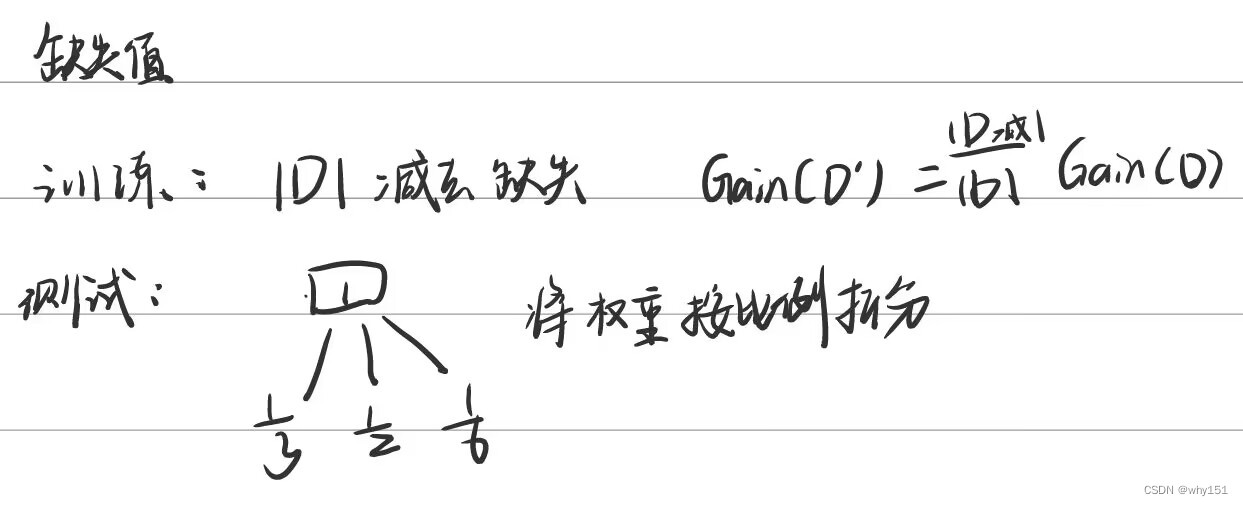
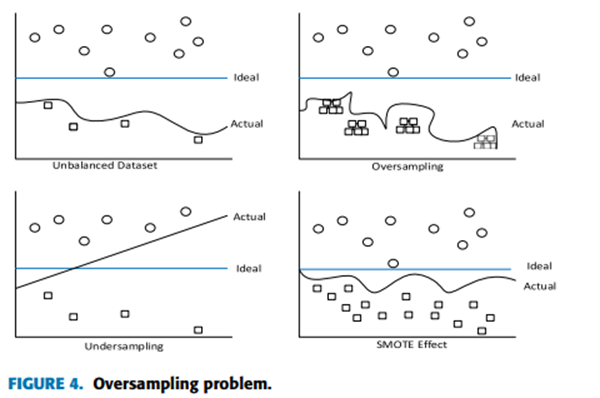
NSL-KDD 数据集存在类别不平衡分布的问题。一些研究人员使用过采样,即复制少数类点,但这种方法的缺点是对这些点过度拟合。
其他人则使用欠采样,这会从多数类中删除一些点。这种方法的问题在于,一些被删除的点对于代表类别可能至关重要。有一个混合解决方案,可以复制少数类点并删除一些多数类点。该方法将增强模型,但会继承两个过程的问题。
引入了一种新技术[28],称为合成少数过采样技术(SMOTE)。该技术是过采样和欠采样的组合。尽管如此,过采样是通过创建少数类的新点而不是重复来完成的,这减少了过拟合的影响,如图4所示。
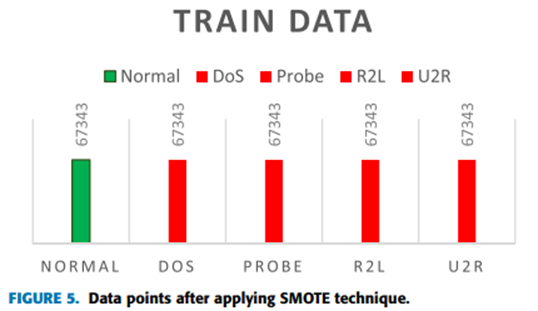
应用SMOTE后,所有类别(正常和攻击)的NSL-KDD数据点相等,如图5所示。
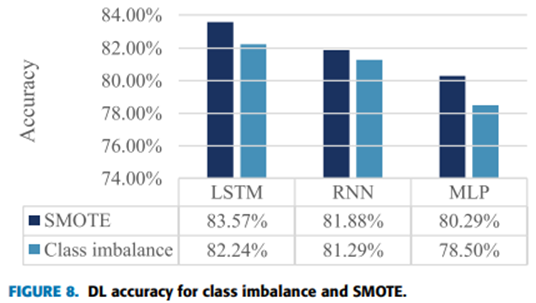
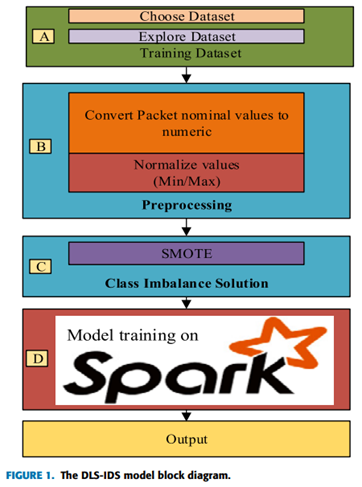
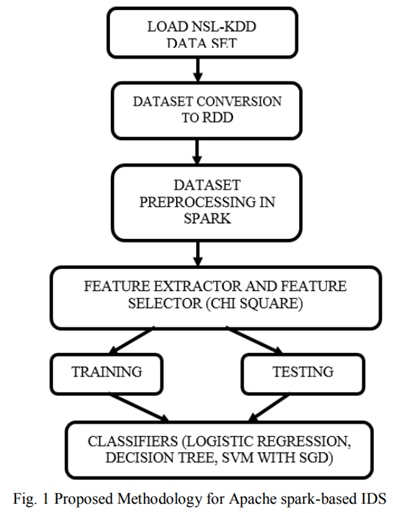
15 Performance evaluation of classification algorithms in the design of Apache Spark based intrusion detection system
Saravanan, S. “Performance evaluation of classification algorithms in the design of Apache Spark based intrusion detection system.” 2020 5th International Conference on Communication and Electronics Systems (ICCES). IEEE, 2020.
A. 数据集描述
B. 加载 NSL-KDD 数据集
实现阶段首先将数据集加载为 RDD 格式,因为 RDD 是[15]的 Spark 基本架构,因此第一步将数据集加载到弹性分布式数据集中。
C. Spark 中的数据预处理
在此步骤中,用于去除不需要的数据、去除噪声和去除均值的不同预处理步骤。
字符串索引器:通常,IDS 算法处理一种或多种原始输入数据类型(例如 SVM 算法),并且还处理数据并将分类数据转换为数据集中的数值数据。字符串索引器用于将分类数据转换为数值数据,以实现更高的准确性。
编码:编码是一种将分类变量转换为可用于通过机器学习算法进行更准确预测的形状的机制
标准化:标准化是在机器学习中实现一致结果的重要技术。重新调整一个或多个属性的方法需要数据标准化
D. 特征选择
ChiSqSelector 是一种特征选择方法,用于在数据集中的所有特征中选择排名靠前的特征。与其他特征选择算法相比,它工作高效且准确。它从数据集中存在的所有属性中选择最重要的特征。冗余和不相关的数据特征导致了网络流量分类的问题。减少分类过程,防止分类准确,尤其是在处理高维大数据时。
–
–end–