前言
对本博客比较熟悉的朋友知道,我司论文项目组正在基于大模型做论文的审稿(含CS英文论文审稿、和金融中文论文审稿)、翻译,且除了审稿翻译之外,我们还将继续做润色/修订、idea提炼(包含论文检索),是一个大的系统,包含完整的链路
由于论文项目组已壮大到18人,故目前在并行多个事,且我也针对idea提炼做一下技术探索,本文解析关于idea提炼的两篇论文
- 我司论文项目组三太子在内部18人大群里4.14发的这篇:ResearchAgent: Iterative Research Idea Generation over Scientific Literature with Large Language Mode
- // 待定
第一部分 ResearchAgent: 围绕论文和引用提炼idea
1.1 从ResearchAgent到ReviewingAgent:idea的生成与其迭代
考虑到LLMs可以处理和分析大量的文献资料,并以超越人类能力的速度和规模处理数据,还可以识别人类研究者可能立即无法察觉的模式、趋势和相关性,从而使LLM能够发现原本未被发现的新的研究机会。 此外,LLM还可以通过进行实验和解释结果来协助实验验证,从而显着加快研究周期
近日,来自韩国的一研究团队便基于LLM做了相关尝试,即研究思路生成,其中包括问题识别、方法开发和实验设计(research idea generation, which involves problem identification, method development, and experiment design)
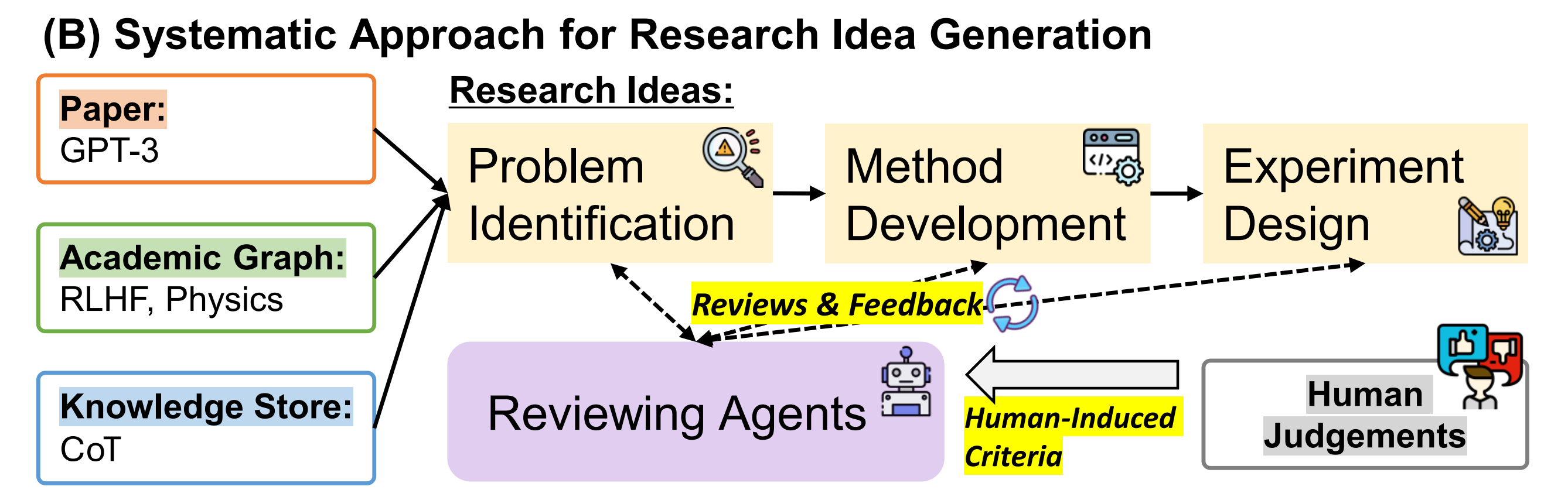
那基于LLM如何提炼idea呢?其实和科研人设计idea的过程差不太多,比如首要的第一步便是阅读大量相关领域的paper,然后提炼出一个逐步的idea,最后针对这个初步的idea反复自我审视及让同行给予反馈、评价,以不断完善该idea
换言之,只阅读某篇论文及其对应的参考文献,从而根据references and citation relationship提炼idea可能不太够
- 首先构建一个知识存储,从科学文章中找到并聚合实体共现。 这个以实体为中心的知识存储捕捉了不同实体之间的相互关联性,并通过潜在的概念和原则为其检索到的知识提供了有价值的见解;我们将展示这些见解对我们的问题非常有价值。
- 此外,为了通过迭代改进增强生成的研究创意,我们设计了多个审查代理,每个代理都对开发的创意生成评论和反馈,具有自己的评估标准
1.1.1 ResearchAgent的流程:基于LLM确定问题、方法、实验
为了完成上述步骤,现有的文献(例如学术出版物)被用作主要来源,提供关于现有知识以及差距和未解答问题的见解
形式上,设为文献,
为由问题
、方法
和实验设计
组成的想法,表示如下:
,其中每个项目由一系列tokens组成,
表示连接操作
然后,idea生成模型 可以表示如下:
,进一步分解为三个子模块步骤:
用于确定问题
用于开发方法
- 以及
用于设计实验
在这项工作中,依赖LLMs来操作 f,利用它们理解和生成学术文本的能力(we operationalize f with LLMs, leveraging their capability to understand and generate academic text),具体而言
LLM接受一个输入token序列 x并生成一个输出token序列 y,表示为:,其中
是模型参数,在训练后固定不变(毕竟进一步微调的成本很高),
是提示模板(prompt template),是一个结构化的格式,概述了上下文(包括任务描述和指示)以指导模型生成所需的输出
从而上述三个子模块便变成了
- 确定问题:
- 确定方法:
- 确定实验:
对于 LLM,我们通过提供一篇核心论文从
开始,然后根据citation graph选择性地纳入后续论文
,这些论文与核心论文直接相关,从而使得用于生成研究想法的 LLM输入更加可管理和连贯「we initiate its literature review process by providing a core paper l0 from L and then selectively incorporating subsequent papers {l1, ..., ln} that are directly related to it based on a citation graph」
对于核心论文及其相关引文(relevant citations)的选择
- 核心论文基于其引用计数进行选择(例如,在3个月内超过100次),通常表示具有高影响力
- 其相关论文(可能非常多)根据其摘要与核心论文的相似性进一步缩小范围,确保得到更加专注和相关的相关paper集合
1.1.2 ResearchAgent的增强:通过实体链接方法提取术语数据库
然后,核心论文及其引用的数量毕竟有限,所能带来的上下文知识范围过于局限,而使得无法提出更好的idea
- 好在我们可以使用现有的现成实体链接方法(实体链接是一个将文本中的不同实体识别并映射到知识库中实体的过程)在任何论文中提取术语数据库(term database),并将这些链接的出现聚合到一个知识库中
we can easily extract the term database whenever it appears in any paper, using existing off-the-shelf entity linking methods and then aggregate these linked occurrences into a knowledge store. - 然后,如果术语数据库在医学科学领域中普遍存在,但在血液学(医学科学的一个子领域)中不太常见,构建的知识库基于除数据库之外的重叠实体捕捉了这两个领域之间的相关性,然后便可在制定有关血液学的想法时提供术语数据库
Then, if the term database is prevalent with in the realm of medical science but less so in hematology (which is a subdomain of medical science), the constructed knowledge store captures the relevance between those two domains based on overlapping entities (other than the database) and then offers the term database when formulating the ideas about hematology.
换句话说,这种方法通过利用各个领域之间的相互关联性,能够提供新颖和跨学科的见解
In other words, this approach enables providing novel and interdisciplinary insights by leveraging the interconnectedness of entities across various field
具体的执行步骤为
- 将知识存储设计为一个二维矩阵
,其中
是已识别的唯一实体的总数,而
以稀疏格式实现
这个知识存储是通过从所有可用的科学文献(由于无法提取所有可用文章中的实体,故这里的目标是针对2023年5月1日之后出现的论文)中提取实体构建的,它不仅计算了个别论文中实体对的共现次数,还量化了每个实体的计数
此外,为了操作化实体提取,我们使用了现有的实体链接器 EL(Scalable zeroshot entity linking with dense entity retrieval),它在特定论文从
,其中
表示出现在
中的实体的多重集(允许重复)
在提取实体后,为了将它们存储到知识存储
中,我们考虑了所有可能的
,其中
,然后将其记录到
- 鉴于这个知识库
使得我们可以通过“知识库 - 形式上,定义从相互连接的论文组中提取的实体如下:
因此,检索前k个相关外部实体的概率形式可以表示如下
其中且
。此外,为了简化起见,通过应用贝叶斯规则并假
设实体是独立的,上面的检索前k个相关外部实体的操作可以近似表示如下:
其中和
可以从二维
- 最终,使用相关实体为中心的知识增强的研究提案生成实例
表示如下:
总之,将这种知识增强的LLM驱动的思路生成方法称为ResearchAgent,下面的三个图中(点击对应图片即可放大查看)



- 左图:通过ResearchAgent提出问题,大意是
我将提供目标论文、相关论文和实体,如下所示:
目标论文标题:{paper['title']}
目标论文摘要:{paper['abstract']}
相关论文标题:{relatedPaper['titles']}
相关论文摘要:{relatedPaper['abstracts']}
实体:{Entities}
有了提供的目标论文、相关论文和实体,你现在的目标是制定一个研究问题,不仅建立在这些现有研究的基础上,而且要具有原创性、清晰性、可行性、相关性和重要性。 在制定研究问题之前,重新审视目标论文的标题和摘要,确保它仍然是你研究问题识别过程的焦点。
目标论文标题:{paper['title']}
目标论文摘要:{paper['abstract']}
然后,在您对上述内容进行审查后,请按照以下格式生成一个带有理论基础的研究问题
研究问题:
理论基础: - 中图,通过ResearchAgent生成方法,大意是
我将提供研究问题、现有研究(目标论文和相关论文)以及实体,如下所示:
研究问题:{researchProblem}
基本原理:{researchProblemRationale}
目标论文标题:{paper[’title’]}
目标论文摘要:{paper[’abstract’]}
相关论文标题:{relatedPaper[’titles’]}
相关论文摘要:{relatedPaper[’abstracts’]}
实体:{Entities}
根据提供的研究问题、现有研究和实体,你的目标是制定一种方法,不仅利用这些资源,而且力求清晰、创新、严谨、有效和可推广。 在制定方法之前,重新审视研究问题,确保它仍然是你方法开发过程的焦点。
研究问题:{researchProblem}
理论基础:{researchProblemRationale}
然后,在审查上述内容后,请按照以下格式提出你的方法及其理论基础:
方法:
理论基础: - 右图,通过ResearchAgent生成实验设计,大意是
我将提供研究问题、科学方法、现有研究(目标论文和相关论文)和实体,如下所示:
研究问题:{researchProblem}
基本原理:{researchProblemRationale}
科学方法:{scientificMethod}
基本原理:{scientificMethodRationale}
目标论文标题:{paper[’title’]}
目标论文摘要:{paper[’abstract’]}
相关论文标题:{relatedPaper[’titles’]}
相关论文摘要:{relatedPaper[’abstracts’]}
实体:{Entities}
根据提供的研究问题、科学方法、现有研究和实体,你的目标是设计一个实验,不仅利用这些资源,而且力求清晰、健壮、可重复、有效和可行。 在制定实验设计之前,重新审视研究问题和提出的方法,确保它们仍然是实验设计过程的核心。
研究问题:{researchProblem}
理论基础:{researchProblemRationale}
科学方法:{scientificMethod}
理论基础:{scientificMethodRationale}
然后,在审查上述内容后,请按照实验的格式和理论基础,概述你的实验及其理论基础
实验设计:
理论基础:
1.1.3 ReviewingAgent给反馈:通过与人类偏好对齐的LLM Agents迭代研究思路
当拿到初步的idea之后(包括其对应的问题、方法、实验设计),ReviewingAgents还会根据特定的标准提供review和反馈,以验证生成的研究思路
具体而言,类似于我们使用LLM和模板T实例化ResearchAgent的方法,ReviewingAgents也是类似地实例化,但使用不同的模板,如下面的三个图所示,分别涉及
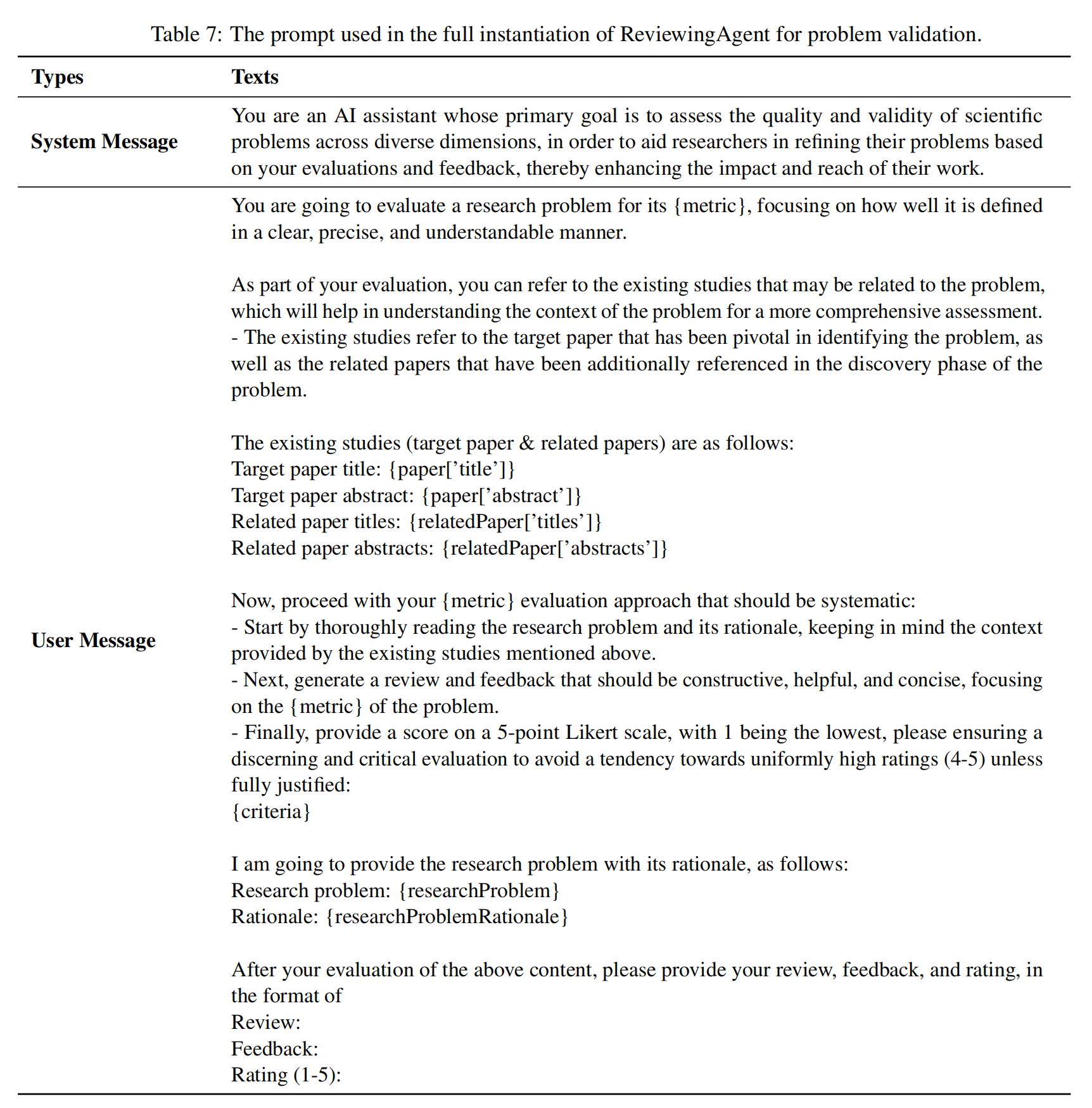


- 对ResearchAgent所提出问题的评价
现有研究(目标论文和相关论文)如下:
目标论文标题:{paper['title']}
目标论文摘要:{paper['abstract']}
相关论文标题:{relatedPaper['titles']}
相关论文摘要:{relatedPaper['abstracts']}
现在,按照系统的方式进行您的{指标}评估方法:- 首先彻底阅读研究问题及其基本原理,牢记上述现有研究提供的背景信息。
- 接下来,生成一篇评论和反馈,应该是建设性的、有帮助的和简明的,重点关注问题的{指标}。
- 最后,使用5分Likert量表给出一个评分,1表示最低,请确保进行有鉴别力和批判性的评估,避免倾向于统一高分(4-5),除非完全有理由:{标准}
我将提供研究问题及其理论基础,如下所示:
研究问题:{研究问题}
理论基础:{研究问题理论基础}
在您评估上述内容之后,请以以下格式提供您的评论、反馈和评分:
反馈:
评分(1-5): - ResearchAgent所提出方法的评价
研究问题和现有研究(目标论文和相关论文)如下:
研究问题:{researchProblem}
理由:{researchProblemRationale}
目标论文标题:{paper[’title’]}
目标论文摘要:{paper[’abstract’]}
相关论文标题:{relatedPaper[’titles’]}
相关论文摘要:{relatedPaper[’abstracts’]}
现在,继续你的{度量}评估方法,应该是系统的:- 首先,彻底阅读提出的方法及其基本原理,牢记研究问题所提供的背景和上述现有研究。
- 接下来,生成一个评论和反馈,应该是建设性的、有帮助的和简洁的,重点关注方法的{度量}。
- 最后,使用5分Likert量表给出一个评分,1表示最低,请确保进行有鉴别力和批判性的评估,避免倾向于统一高分(4-5),除非完全有理由:{标准}
我将提供以下关于提出的方法及其基本原理的信息:
科学方法:{科学方法}
基本原理:{科学方法基本原理}
在您评估上述内容之后,请以以下格式提供您的评论、反馈和评分:
反馈:
评分(1-5): - 所提出的实验设计的评价
研究问题、科学方法和现有研究(目标论文和相关论文)如下所示:
研究问题:{researchProblem}
理由:{researchProblemRationale}
科学方法:{scientificMethod}
理由:{scientificMethodRationale}
目标论文标题:{paper['title']}
目标论文摘要:{paper['abstract']}
相关论文标题:{relatedPaper['titles']}
相关论文摘要:{relatedPaper['abstracts']}
现在,继续你的{度量}评估方法,应该是系统的:- 首先,彻底阅读实验设计及其基本原理,牢记研究问题、科学方法和上述现有研究所提供的背景。
- 接下来,生成一个评论和反馈,应该是建设性的、有帮助的和简明扼要的,重点关注
实验的{度量}。
- 最后,使用5分Likert量表给出一个评分,1表示最低,请确保进行有鉴别力和批判性的评估,避免倾向于统一高分(4-5),除非完全有理由:{标准}
我将提供设计好的实验及其基本原理,如下所示:
实验设计:{实验设计}
基本原理:{实验设计基本原理}
在您评估上述内容之后,请以以下格式提供您的评论、反馈和评分:
反馈:
评分(1-5):
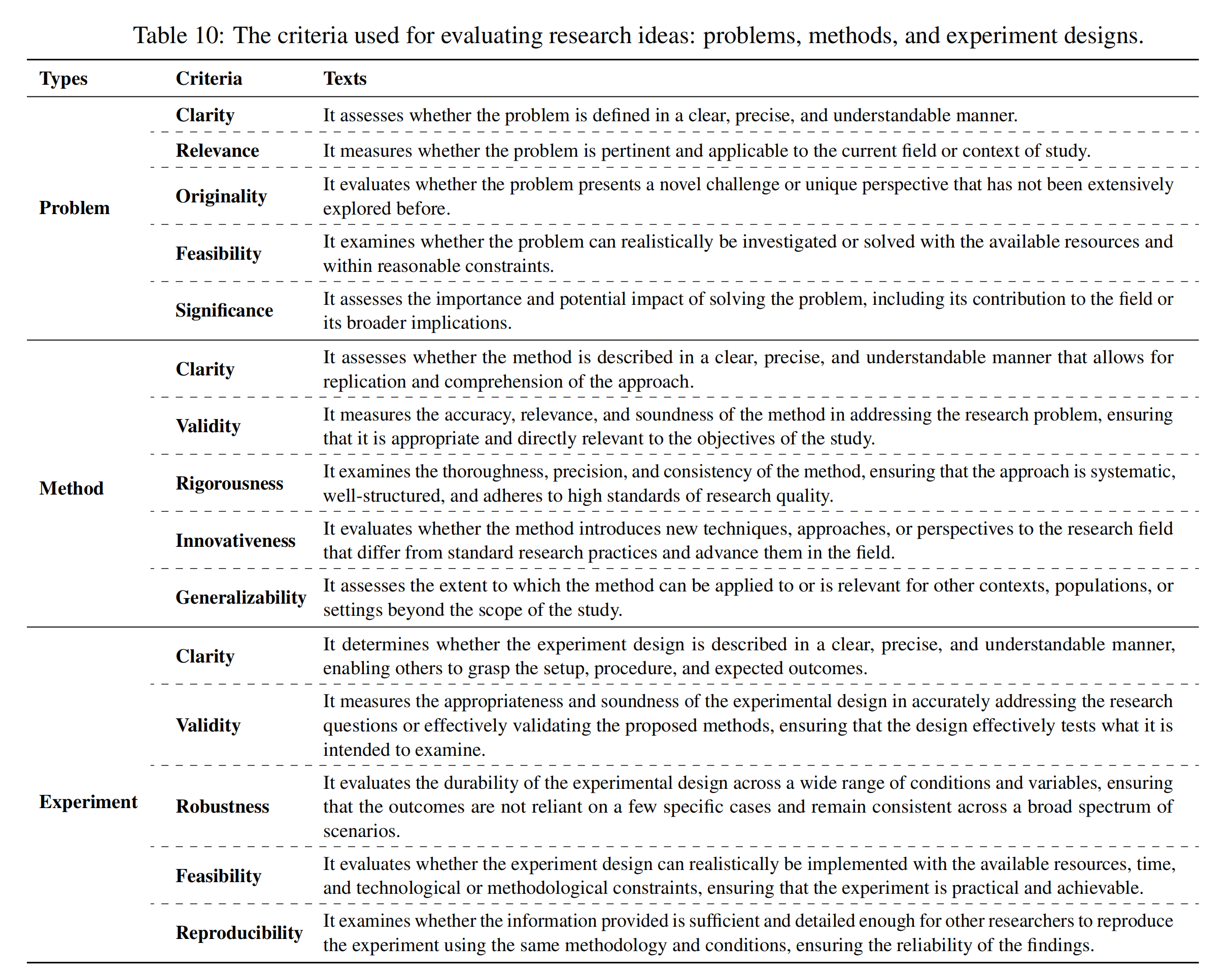
然后,使用ReviewingAgents,根据其各自的五个特定标准对生成的研究思路(问题、方法和实验设计)进行单独评估,这些标准如下图所示
最后,根据ReviewingAgents的审查和反馈,ResearchAgent进一步更新已生成的研究思路