从零开始 Spring Cloud 10:Elasticsearch

图源:laiketui.com
基础
什么是 Elasticsearch
Elasticsearch 是一个开源搜索引擎,可以用它实现从海量数据中对数据的高效查询。
关于 Elasticsearch 的历史渊源以及广泛用途,可以观看这个视频。
倒排索引
和通常搜索数据使用顺序索引的方式不同,Elasticsearch 和其它搜索引擎一样,是基于倒排索引实现的关键词查询,关于倒排索引的原理,可以观看这个视频。
基本概念
与数据库不同,Elasticsearch 有以下基本概念:
- 文档(Document),一条数据,在 es 中以 json 形式存储。
- 字段(Field),文档中的字段。
- 索引(Index),同类型文档的集合。
- 映射(Mapping),索引中文档的约束。
这些概念与 MySQL 概念的对比:
| MySQL | Elasticsearch | 说明 |
|---|---|---|
| Table | Index | 索引(index),就是文档的集合,类似数据库的表(table) |
| Row | Document | 文档(Document),就是一条条的数据,类似数据库中的行(Row),文档都是JSON格式 |
| Column | Field | 字段(Field),就是JSON文档中的字段,类似数据库中的列(Column) |
| Schema | Mapping | Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema) |
| SQL | DSL | DSL是elasticsearch提供的JSON风格的请求语句,用来操作elasticsearch,实现CRUD |
对这些概念的说明和与 MySQL 中概念的对比可以观看这个视频。
部署
可以通过 Docker 部署 es。除了 es 本体之外,为了方便使用,还需要部署一个与 es 协同工作的 kibana,它可以提供一个图形化的 es 管理界面,此外还提供一些方便的开发工具,比如用于编写 DSL 的 devTool。除了 kibana,一般还需要安装一个 es 插件 ik 分词器,它可以提供对中文语句的分词支持。
es 的默认分词器对中文语句的分词很差。
部署以上应用的具体方法可以参考这篇文章。
索引库
映射
映射(Mapping)是对索引库中文档的约束,常见的映射属性包括:
- type:字段数据类型,常见的简单类型有:
- 字符串:text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址)
- 数值:long、integer、short、byte、double、float、
- 布尔:boolean
- 日期:date
- 对象:object
- index:是否创建索引,默认为true
- analyzer:使用哪种分词器
- properties:该字段的子字段
创建索引和映射
创建索引库映射的基本语法是:
- 请求方式:PUT
- 请求路径:/索引库名,可以自定义
- 请求参数:mapping映射
语法:
PUT /索引库名称
{"mappings": {"properties": { # 映射约束 "字段名1":{ # 文档字段约束"type": "text", # 字段类型"analyzer": "ik_smart" # 文本类型字段需要定义分词器},"字段名2":{"type": "keyword", # keyword 类型字段不会被分词"index": "false" # 是否索引},"字段名3":{"properties": { # 子字段约束"子字段": {"type": "keyword"}}},# ...}}
}
举例说明:
假设我们要创建的索引库名称为my-index-users,其中某个文档的内容为:
{"age": 21,"weight": 52.1,"isMarried": false,"info": "黑马程序员Java讲师","email": "zy@itcast.cn","score": [99.1, 99.5, 98.9],"name": {"firstName": "云","lastName": "赵"}
}
相应的映射创建语句就可以写成:
PUT /my-index-users
{"mappings": {"properties": {"age":{"type": "integer","index": false},"weight":{"type": "float","index": false},"isMarried":{"type": "boolean","index": false},"info":{"type":"text","analyzer": "ik_smart"},"email":{"type": "keyword","index": false},"score":{"type": "float","index": false},"name":{"type": "object", "properties": {"firstName":{"type":"keyword","index":false},"lastName":{"type":"keyword","index":false}}}}}
}
这里文档中的
score字段虽然是数组,但在映射中的字段类型只会是数组中的元素类型,因为在映射定义中,可以约束文档中的同一个字段有多少个值,用这种方式来表示数组。
获取索引库
语法为:
GET /索引库名称
示例:
GET /my-index-users
删除索引库
语法为:
DELETE /索引库名称
示例:
DELETE /my-index-users
给索引添加字段
不能对索引的已有字段进行修改,只能给索引添加新的字段,语法是:
PUT /索引库名称/_mapping
{"properties":{"新字段名称":{"type":"新字段类型",// ...}}
}
示例:
PUT /my-index-users/_mapping
{"properties":{"age":{"type":"integer","index":false}}
}
文档操作
新增文档
语法:
POST /索引库名/_doc/文档id
{"字段1": "值1","字段2": "值2","字段3": {"子属性1": "值3","子属性2": "值4"},// ...
}
示例:
POST /my-index-users/_doc/1
{"age":21,"weight":52.1,"isMarried":false,"info":"黑马程序员Java讲师","email":"zy@itcast.cn","score":[99.1, 99.5, 98.9],"name":{"firstName":"云","lastName":"赵"}
}
执行后会返回:
{"_index" : "my-index-users","_type" : "_doc","_id" : "1","_version" : 1,"result" : "created","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 0,"_primary_term" : 1
}
其中的"result" : "created"说明文档成功添加。
查询文档
语法:
GET /索引库名称/_doc/文档ID
示例:
GET /my-index-users/_doc/1
返回内容:
{"_index" : "my-index-users", # 索引库名称"_type" : "_doc", #数据类型(文档)"_id" : "1", # 文档ID"_version" : 1, # 版本,每修改(或删除)一次文档版本号+1"_seq_no" : 0,"_primary_term" : 1,"found" : true,"_source" : { # 添加文档时的原始信息"age" : 21,"weight" : 52.1,"isMarried" : false,"info" : "黑马程序员Java讲师","email" : "zy@itcast.cn","score" : [99.1,99.5,98.9],"name" : {"firstName" : "云","lastName" : "赵"}}
}
返回内容说明见上面的注释。
删除文档
语法:
DELETE /索引库名称/_doc/文档ID
示例:
DELETE /my-index-users/_doc/1
修改文档
修改文档分为两种方式:
- 全量修改:用新内容替换目标文档的旧内容
- 增量修改:只修改指定的部分文档字段的内容
需要注意的是,全量修改的语义符合 REST API 中关于 PUT 方法的规定,如果目标文档存在,就替换其内容,如果目标文档不存在,就创建。
全量修改的语法为:
PUT /索引库名称/_doc/文档ID
{"字段1名称":字段1值,"字段2名称":字段2值,# ...
}
示例:
PUT /my-index-users/_doc/1
{"age":25,"weight":52.1,"isMarried":true,"info":"黑马程序员Java讲师","email":"zy@itcast.cn", "score":[99.1, 99.5, 98.9],"name":{"firstName":"云","lastName":"赵"}
}
如果上述 DSL 中的文档 ID 不存在,比如/my-index-users/_doc/2,将创建一个新的文档。
增量修改的语法为:
POST /索引库名称/_update/文档ID
{"doc": {"字段1名称":字段1值,"字段2名称":字段2值,# ...}
}
需要注意,增量修改使用的是 POST 而非 PUT。
示例:
POST /my-index-users/_update/1
{"doc": {"weight":45}
}
案例:通过 Java 操作 ES
准备工作
RestAPI
ES官方提供了各种不同语言的客户端,用来操作ES。这些客户端的本质就是组装DSL语句,通过http请求发送给ES。官方文档地址:https://www.elastic.co/guide/en/elasticsearch/client/index.html
其中的Java Rest Client又包括两种:
- Java Low Level Rest Client
- Java High Level Rest Client
我们学习的是Java HighLevel Rest Client客户端API,下面用实际案例说明如何使用。
数据库
在 MySQL 数据库中创建一个数据库 heima, 然后导入SQL文件。
项目代码
解压并在 Idea 中打开项目代码。
按需要修改数据库的相关配置,比如:
spring:datasource:url: jdbc:mysql://localhost:3306/heima?useSSL=falseusername: rootpassword: mysqldriver-class-name: com.mysql.jdbc.Driver
如果 Maven 依赖下载出错,可以尝试将项目中的 Spring Boot 版本修改为
2.3.9.RELEASE后重新下载依赖。
定义映射
我们的目的是将数据库中的表信息添加到 es 中作为文档保存,然后用 es 进行搜索。因此,我们需要根据表结构定义一个 es 中的索引库的映射。
作为示例数据的表结构如下:
CREATE TABLE `tb_hotel` (`id` bigint(20) NOT NULL COMMENT '酒店id',`name` varchar(255) NOT NULL COMMENT '酒店名称;例:7天酒店',`address` varchar(255) NOT NULL COMMENT '酒店地址;例:航头路',`price` int(10) NOT NULL COMMENT '酒店价格;例:329',`score` int(2) NOT NULL COMMENT '酒店评分;例:45,就是4.5分',`brand` varchar(32) NOT NULL COMMENT '酒店品牌;例:如家',`city` varchar(32) NOT NULL COMMENT '所在城市;例:上海',`star_name` varchar(16) DEFAULT NULL COMMENT '酒店星级,从低到高分别是:1星到5星,1钻到5钻',`business` varchar(255) DEFAULT NULL COMMENT '商圈;例:虹桥',`latitude` varchar(32) NOT NULL COMMENT '纬度;例:31.2497',`longitude` varchar(32) NOT NULL COMMENT '经度;例:120.3925',`pic` varchar(255) DEFAULT NULL COMMENT '酒店图片;例:/img/1.jpg',PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
根据表结构定义映射:
GET /_analyze
{"analyzer": "ik_smart","text": "传智教育Java就业超过90%,奥力给!"
}PUT /hotel
{"mappings": {"properties": {"id":{ # 酒店ID"type": "keyword" # 作为文档ID的字段比较特殊,必须定义为 keyword 类型,且需要索引},"name":{ # 酒店名称"type":"text", # 需要分词"analyzer": "ik_max_word", # 使用 ik 最大分词"copy_to": "all" # 将多个字段内容拷贝到 all 字段,创建的索引可以进行“综合查询”},"address":{ # 酒店地址"type": "keyword", # 酒店地址不需要分词"index": false # 不对酒店地址进行查询},"price":{ # 酒店价格"type": "integer" # 需要进行排序和搜索,所以进行索引},"score":{ # 酒店评分"type": "integer" # 同上},"brand":{ # 酒店品牌"type": "keyword", # 不需要分词"copy_to": "all" # 需要进行“综合查询”},"city":{ # 城市"type": "keyword", #不需要分词"copy_to": "all" # 需要进行“综合查询”},"starName":{ # 酒店星级"type": "keyword" # 不需要分词},"business":{ # 所在商圈"type": "keyword" # 不需要分词},"location":{ # 经纬度"type": "geo_point" # 在 es 中,表示一个经纬度坐标用 geo_point 这个类型},"pic":{ # 酒店图片"type": "keyword", # 不需要分词"index": false #不需要索引},"all":{ # 为了实现“综合查询”所添加的字段,其索引可以用于对多个字段数据的查询"type": "text", # 需要分词,将包含所有用 copy_to 拷贝过来的内容"analyzer": "ik_max_word" # 使用 ik 分词器}}}
}
RestClient
我们需要使用 es 的 Java 客户端与 es 进行通讯,这里使用 RestHighLevelClient。
添加相关依赖:
<dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>
因为 Spring Boot 默认指定的 es 版本与我们需要的 es 版本不符,所以需要指定版本:
<properties><!-- ... --><elasticsearch.version>7.12.1</elasticsearch.version>
</properties>
可以用一个测试用例测试 es 客户端的创建:
public class HotelTests {private RestHighLevelClient restHighLevelClient;@BeforeEachvoid initClient(){restHighLevelClient = new RestHighLevelClient(RestClient.builder(HttpHost.create("http://192.168.0.88:9200")));}@AfterEach@SneakyThrowsvoid closeClient(){restHighLevelClient.close();}@Testpublic void testClientBuild(){System.out.println(restHighLevelClient);}
}
索引库操作
创建索引库
创建索引库的测试用例:
public class HotelTests {// ...@Test@SneakyThrowspublic void testIndexCreate() {// 从 Spring 资源文件读取 es 映射定义Resource resource = new ClassPathResource("/es/mapping/hotel.json");File jsonFile = resource.getFile();String source = FileUtil.getFileContent(jsonFile);// 新建索引创建请求CreateIndexRequest createIndexRequest = new CreateIndexRequest("hotel");// 添加映射定义createIndexRequest.source(source, XContentType.JSON);// 发送请求到 es 服务器restHighLevelClient.indices().create(createIndexRequest, RequestOptions.DEFAULT);}
}
注意,这里的
CreateIndexRequest所在的包是org.elasticsearch.client.indices,create方法有另一个重载版本,使用的是另一个包下的CreateIndexRequest类。
RestHighLevelClient.indices方法返回的是一个IndicesClient类型的对象,可以用它实现对索引库的增删改查操作。
IndicesClient.create方法用于创建索引库,有两个参数,第一个参数用于提供索引库名称、映射DSL等,第二个参数用于定义发送的 HTTP 请求头,一般使用默认的请求头(RequestOptions.DEFAULT)。
方便起见,将映射定义语句添加到 Spring 资源文件resources/es/mapping/hotel.json:
{"mappings": {"properties": {"id":{"type": "keyword"},# ..."all":{"type": "text","analyzer": "ik_max_word"}}}
}
实际上就是 DSL 语句中的 json 部分。
执行测试用例后 es 上就会添加一个索引库。
判断索引库是否存在
代码与创建索引库的类似:
public class HotelTests {// ...@Test@SneakyThrowspublic void testIndexExists() {String indexName = "hotel";GetIndexRequest request = new GetIndexRequest(indexName);boolean exists = restHighLevelClient.indices().exists(request, RequestOptions.DEFAULT);System.out.println(String.format("index %s %s", indexName, exists ? "exists" : "not exists"));}
}
删除索引库
代码同样与创建索引库的类似:
public class HotelTests {// ...@Test@SneakyThrowspublic void testDeleteIndex(){DeleteIndexRequest request = new DeleteIndexRequest("hotel");restHighLevelClient.indices().delete(request, RequestOptions.DEFAULT);}
}
文档操作
添加文档
添加文档的 API 调用方式与创建索引库类似:
@SpringBootTest
public class HotelDocTests {@Autowiredprivate IHotelService hotelService;// ...@Test@SneakyThrowsvoid testAddHotelDoc(){// 从数据库查询要添加的数据Hotel hotel = hotelService.getById(38665L);// 创建文档添加请求IndexRequest request = new IndexRequest("hotel").id(hotel.getId().toString());// 将数据转化为文档需要的格式HotelDoc hotelDoc = new HotelDoc(hotel);// 转化为 json 格式并附加到请求对象request.source(JSON.toJSONString(hotelDoc), XContentType.JSON);// 发送文档添加请求restHighLevelClient.index(request, RequestOptions.DEFAULT);}
}
不同的是,我们需要先从数据库中查询需要添加的数据,再将其转化成文档需要的格式后进行发送。
添加文档使用的 API 是
RestHighlevelClient.index方法,方法名index的含义是:添加文档同样意味着创建倒排索引。
查询文档
@SpringBootTest
public class HotelDocTests {// ...@Test@SneakyThrowsvoid testGetHotelDoc(){// 构建文档查询请求对象GetRequest request = new GetRequest("hotel", "38665");// 进行查询并获取返回值GetResponse response = restHighLevelClient.get(request, RequestOptions.DEFAULT);// 从返回对象中获取文档内容(source)String sourceAsString = response.getSourceAsString();// 解析字符串,获取对象HotelDoc hotelDoc = JSON.parseObject(sourceAsString, HotelDoc.class);System.out.println(hotelDoc);}
}
更新文档
@Test
@SneakyThrows
void testUpdateHotelDoc() {UpdateRequest request = new UpdateRequest("hotel", "38665");request.doc("price", 300,"starName", "四钻");restHighLevelClient.update(request, RequestOptions.DEFAULT);
}
UpdateRequest.doc可以接收一个可变参数列表,可以按照键值对依次传入的方式进行文档的增量更新。
上面的方式有些不直观,doc方法的另一个重载版本可以接收Map类型的参数,这样更直观一些:
@Test
@SneakyThrows
void testUpdateHotelDoc2() {UpdateRequest request = new UpdateRequest("hotel", "38665");Map<String, Object> hotelUpdated = new HashMap<>();hotelUpdated.put("price", 350);hotelUpdated.put("starName", "五钻");request.doc(hotelUpdated);restHighLevelClient.update(request, RequestOptions.DEFAULT);
}
删除文档
删除文档的调用方式很简单:
@Test
@SneakyThrows
void testDelHotelDoc(){DeleteRequest request = new DeleteRequest("hotel","38665");restHighLevelClient.delete(request, RequestOptions.DEFAULT);
}
批量添加文档
如果要批量添加文档,通过RestHighLevelClient.index的重复调用是可行的,但这样做效率太低,因为每次 HTTP 请求只能添加一个文档。
RestAPI 中封装了一个向 es 服务端发送批量文档操作的 API,我们可以用它来实现文档的批量添加:
@Test
@SneakyThrows
void testBatchAddHotelDoc(){BulkRequest request = new BulkRequest();List<Hotel> hotels = hotelService.list();for(Hotel hotel: hotels){HotelDoc hotelDoc = new HotelDoc(hotel);request.add(new IndexRequest("hotel").id(hotelDoc.getId().toString()).source(JSON.toJSONString(hotelDoc), XContentType.JSON));}restHighLevelClient.bulk(request, RequestOptions.DEFAULT);
}
RestHighLevelClient.bulk方法可以用于在单次 HTTP 请求中发送多条文档操作。具体的文档操作需要在BulkRequest对象中定义。
BulkRequest对象本身并不需要指定索引库名称或者文档 ID,也就是说它只是个纯粹的批处理操作容器,具体其中的批处理操作并不会限定为对某一个索引库的某种操作。我们一次性可以添加对不同索引库的不同操作。
BulkRequest.add方法用于添加单条文档操作语句,它有多个重载版本,可以添加文档新增、文档删除、文档更新等操作,具体执行的操作类型取决于参数类型。比如这里我们使用BulkRequest.add(IndexRequest)添加单条文档新增操作。
文档新增所需的信息(文档库名称、文档ID、文档内容)等,我们在IndexRequest对象中指定。
最后,批量添加执行成功后,可以通过 DSL 语句GET /hotel/_search查看执行结果。
DSL 查询
DSL 查询的基本语法是:
GET /indexName/_search
{"query": {"查询类型": {"查询条件": "条件值"}}
}
查询所有
DSL 示例:
GET /hotel/_search
{"query": {"match_all": {}}
}
查询所有的时候不需要查询条件值,所以用空对象{}表示。
查询结果:
{"took" : 40, # 查询耗时"timed_out" : false, # 查询是否超时"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits":{ # 查询命中数据信息"total" : {"value" : 201, # 查询到的总数据条数"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "hotel", # 索引名称"_type" : "_doc", # 类型(文档)"_id" : "36934", # 文档ID"_score" : 1.0,"_source" : { # 原始文档创建 json"address" : "静安交通路40号","brand" : "7天酒店",# ..."price" : 336,"score" : 37,"starName" : "二钻"}},# ...]}
}
实际上并不会返回所有数据,返回的只是第一页的数据。
全文检索
所谓的全文检索(full text),实际上就是利用 es 生成的倒排索引进行查找。
语法:
GET /索引库名称/_search
{"query": {"match": {"字段名": "检索关键字"}}
}
示例:
比如说要搜索所有包含外滩和如家关键字的酒店:
GET /hotel/_search
{"query": {"match": {"all": "外滩如家"}}
}
返回的结果是按照关联性排序的,all 字段中即包含了如家也包含了外滩的酒店会排在最前边,后边是只包含了外滩或只包含了如家的酒店。
商用搜索引擎(如 Google) 按照关键字关联程度、出现频次、引用权重等进行排序。
除了上面的方式,还可以指定多个字段进行检索,语法如下:
GET /索引库名称/_search
{"query": {"multi_match": {"query": "检索关键字","fields": ["字段名1", "字段名2", ...]}}
}
示例:
GET /hotel/_search
{"query": {"multi_match": {"query": "外滩如家","fields": ["brand","name","city"]}}
}
这里和上边示例的检索结果是相同的,因为实际上我们在映射定义中通过 copy_to 字段将 brand、name、city 这三个字段拷贝到了 all 字段中,所以两者检索结果完全相同。
但两者检索效率不同,前者只针对一个索引进行检索,后者要遍历三个索引检索,所以效率更低。因此更建议使用前者的方式进行检索。
精确查询
精确查询分为两种:
- term 查询,查询关键字要与所查询的字段完全匹配
- range 查询,查询字段满足某个区间的值
term 查询的语法:
GET /索引库名称/_search
{"query": {"term": {"字段名": {"value": "查询内容"}}}
}
示例:
GET /hotel/_search
{"query": {"term": {"city": {"value": "上海"}}}
}
这可以检索出所有上海的酒店。
如果要匹配多个结果,比如查询上海和北京的酒店,可以:
GET /hotel/_search
{"query": {"terms": {"city": ["北京","上海"]}}
}
range 查询可以让我们查询字段值是否在某个区域之间,比如:
GET /hotel/_search
{"query": {"range": {"price": {"gte": 100,"lte": 150}}}
}
这里的 gte 意思是大于等于(greater than equals),lte 意思是小于等于(less than equals)。
对应的,可以用 gt 表示大于,lt 表示小于。
地理查询
地理查询是针对经纬度的查询,具体来说就是对类型是 geo_point 的字段进行的查询。
这里介绍两种:
geo_bounding_box,划定一个矩形区域查询属于该区域内的结果geo_distance,指定一个坐标点,查询离该坐标点一定范围内的结果
geo_bounding_box查询语法:
GET /索引库名/_search
{"query": {"geo_bounding_box": {"字段名": {"top_left": {"lat": 左上坐标点纬度,"lon": 左上坐标点经度},"bottom_right": {"lat": 右下坐标点纬度,"lon": 右下坐标点经度}}}}
}
示例:
GET /hotel/_search
{"query": {"geo_bounding_box": {"location": {"top_left": {"lat": 31.1,"lon": 121.5},"bottom_right": {"lat": 30.9,"lon": 121.7}}}}
}
这里查询酒店坐标(location 字段)属于指定区域内的酒店。
上面这种方式不太常见,更常见的是针对某个坐标(通常是手机所在坐标)查询一定范围内的结果。
语法是:
GET /索引库名/_search
{"query": {"geo_distance": {"distance": "离指定坐标的直线距离", "字段名": "指定坐标纬度,指定坐标经度" }}
}
示例:
GET /hotel/_search
{"query": {"geo_distance":{"distance":"5km","location":"31.21,121.5"}}
}
这里查询的就是距离坐标(31.21,121.5)5公里范围内的酒店。
相关性算法
es 会将查询结果按照相关性进行打分,然后按照评分高低进行排序。在早期版本(es 5.0 之前),使用 TF-IDF 算法进行评分,在 es 5.0 之后,改为默认使用 BM25 算法。
关于这两种算法的介绍,可以观看这个视频。
有时候我们需要修改查询结果的默认排序,比如将某些酒店排位靠前。可以通过人为修改相关性评分来实现这一点,具体来说,是通过使用复合查询语句function score来实现。
语法:
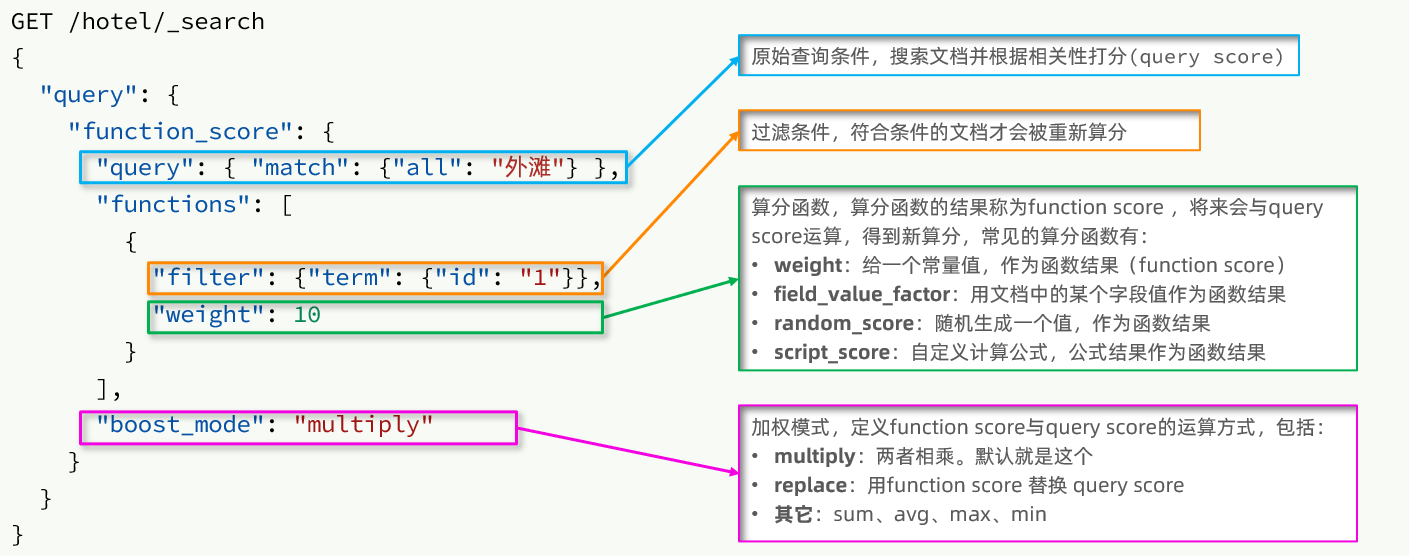
function score 查询语句分为四部分:
- 原始查询语句:基于查询语句中的查询条件进行查询,并按照默认的 BM25 算法给文档进行评分(query score)。
- 过滤条件:指定一个过滤条件,符合条件的文档才会被重新评分。
- 算分函数:指定一个算分函数,以计算出一个函数评分(function score),函数分为四种:
- weight:指定一个常量作为分值
- field_value_factor:用文档的某个字段值作为分值
- random_score:产生一个随机数作为分值
- script_score:定义一段代码产生分值
- 运算模式:重新计算的最终分值需要将原始的查询分值(query score)和函数分值(function score)结合产生,运算模式决定了以何种方式结合:
- multiply:相乘
- replace:用函数分值作为最终分值。
- 其它,比如:sum、avg、max、min
用一个示例来说明:
默认情况下查询:
GET /hotel/_search
{"query": {"match": {"all": "浦东"}}
}
结果是:
{# ..."hits" : {# ..."max_score" : 3.6517773,"hits" : [{# ..."_id" : "200208940","_score" : 3.6517773,"_source" : {"brand" : "喜来登",# ..."name" : "上海浦东喜来登由由公寓",# ...}},{# ..."_id" : "200214715","_score" : 3.5170424,"_source" : {"brand" : "喜来登",# ..."name" : "上海浦东喜来登由由大酒店",# ...}},# ...{# ..."_id" : "608374","_score" : 3.0647388,"_source" : {"brand" : "如家",# ..."name" : "如家酒店(上海浦东机场龙东大道合庆店)",# ...}},{# ..."_id" : "1584362548","_score" : 2.7155147,"_source" : {"brand" : "如家",# ..."name" : "如家酒店(上海浦东国际旅游度假区御桥地铁站店)",# ...}}]}
}
文档属性_score就是原始评分(query score),可以看到如家是排在后边的,评分要低于前边的喜来登。
如果我们要人为修改如家的评分,将其排序靠前,可以:
GET /hotel/_search
{"query": {"function_score": {"query": {"match": {"all": "浦东"}},"functions": [{"filter": {"term": {"brand": "如家"}},"weight": 10}],"boost_mode": "sum"}}
}
这里简单将查询结果中所有品牌(brand)是如家的酒店的评分+10,所以最终的查询结果:
{# ..."hits" : {# ..."max_score" : 13.064739,"hits" : [{# ..."_id" : "608374","_score" : 13.064739,"_source" : {# ..."brand" : "如家",# ..."name" : "如家酒店(上海浦东机场龙东大道合庆店)",# ...}},{# ..."_id" : "1584362548","_score" : 12.715515,"_source" : {# ..."brand" : "如家",# ..."name" : "如家酒店(上海浦东国际旅游度假区御桥地铁站店)",# ...}},{# ..."_id" : "200208940","_score" : 4.6517773,"_source" : {# ..."brand" : "喜来登",# ..."name" : "上海浦东喜来登由由公寓",# ...}},# ...]}
}
bool 查询
bool 查询也是一种复合查询,可以用它将多个查询条件组合起来进行查询,类似于 SQL 中的 Where 条件。
语法:
GET /索引库名/_search
{"query": {"bool": {"must": [必须匹配的查询条件],"should": [只要有一个匹配的查询条件],"must_not": [必须不能匹配的查询条件,不参与评分],"filter": [必须匹配的查询条件,不参与评分]}}
}
bool 有四种类型的子查询:
- must,必须匹配的查询条件
- should,只要有一个匹配的查询条件
- filter,必须匹配的查询条件,不参与评分
- must_not,必须不能匹配的查询条件,不参与评分
filter 与 must 作用类似,区别在于前者不会参与文档评分(query score)的计算,只用于对结果集的筛选。这样做的好处是,计算评分比较消耗系统资源,不参与计算评分就可以节省系统资源。因此,对于不需要参与评分的检索条件(通常是用户手动输入的关键字以外的部分),最好作为 filter 或 must_not 查询子句使用。
看一个具体示例:
假设我们需要查询如家酒店,且价格不能高于400,还要在指定坐标范围10公里内,可以:
GET /hotel/_search
{"query": {"bool": {"must": [{"match": {"name": "如家"}}],"must_not": [{"range": {"price": {"gt": 400}}}],"filter": [{"geo_distance": {"distance": "10km","location": {"lat": 31.21,"lon": 121.5}}}]}}
}
当然,也可以写成以下方式:
GET /hotel/_search
{"query": {"bool": {"must": [{"match": {"name": "如家"}}],"filter": [{"geo_distance": {"distance": "10km","location": {"lat": 31.21,"lon": 121.5}}},{"range": {"price": {"lte": 400}}}]}}
}
结果是相同的。
在上边两个示例中,影响查询评分(query score)的只有对酒店name的查询。
处理结果
排序
es 默认情况下对查询结果按文档评分进行排序,除此之外,我们可以指定排序规则。
对于普通字段(数字、字符串、日期等)的排序,其语法是:
GET /hotel/_search
{"query": {查询语句},"sort": [{"字段名": {"order": "[desc]|[desc]"},# ...}]
}
示例:
GET /hotel/_search
{"query": {"match_all": {}},"sort": [{"score": {"order": "desc"},"price": {"order": "asc"}}]
}
上面的示例是对所有酒店,按照用户评分(score)降序、价格(price)升序进行排列。
查询结果:
{"took" : 2,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" :{"total" : {"value" : 201,"relation" : "eq"},"max_score" : null,"hits" : [{// ..."_score" : null,"_source" : {// ..."name" : "汉庭酒店(深圳海岸城店)",// ..."price" : 562,"score" : 49,// ...},"sort" : [49,562]},{// ..."_score" : null,"_source" : {// ..."name" : "深圳同泰万怡酒店",// ..."price" : 617,"score" : 48,// ...},"sort" : [48,617]},{// ..."_score" : null,"_source" : {// ..."name" : "北京通州北投希尔顿酒店",// ..."price" : 1068,"score" : 48,// ...},"sort" : [48,1068]},// ...]}
}
需要注意的是,一旦我们指定了排序规则,es 就不会再计算文档评分,所以示例中的查询结果中_score属性是null。这样做是有意义的,可以避免无效的计算资源浪费。
此外,作为排序依据的字段值,展示在sort字段中。
对简单字段的排序语句可以进行一定程度的简写,比如:
GET /hotel/_search
{"query": {"match_all": {}},"sort": [{"score": "desc","price": "asc"}]
}
有时候需要对地理坐标(经纬度)进行排序,示例:
GET /hotel/_search
{"query": {"match_all": {}},"sort": [{"_geo_distance": {"location": { // 用于排序的文档地理位置字段"lat": 31.21, // 指定坐标的纬度"lon": 121.5 // 指定坐标的经度},"order": "asc","unit": "km" //显示结果中 sort 字段的单位}}]
}
这里对所有酒店到指定坐标(31.21, 121.5)的距离进行了升序排序,换言之,与指定坐标越近的酒店显示顺序越靠前。
查询结果:
{// ..."hits" : {// ..."hits" : [{// ..."_source" : {// ..."location" : "31.220706, 121.498769","name" : "如家酒店·neo(上海外滩城隍庙小南门地铁站店)",// ...},"sort" : [1.1961954983953926]},{// ..."_source" : {// ..."location" : "31.208739, 121.518305","name" : "上海浦东喜来登由由大酒店",// ...},"sort" : [1.7464917055703821]},{// ..."_source" : {// ..."location" : "31.208553, 121.518552","name" : "上海浦东喜来登由由公寓",// ...},"sort" : [1.7716688654108073]},// ...]}
}
最近的酒店距离 1.1 公里,其次是 1.7 公里。
分页
默认查询出的结果是 top10 的数据,我们可以在查询时指定分页信息。
语法:
GET /hotel/_search
{"query": {查询条件},"from": 分页开始位置,默认为0,"size": 每页数据条数
}
示例:
GET /hotel/_search
{"query": {"match_all": {}},"sort": [{"price": {"order": "asc"}}],"from": 0,"size": 10
}
es 的分页存在一个“深度分页问题”:每次分页都需要将 from+size 条数据取出并排序才能确定某个分页的数据。随着 from+size 的增大,对内存的消耗也会增大,这种情况在 es 集群部署的情况会更加显著。所以 es 对分页有限制,from+size 的值不能大于 10000,否则会报错。
如果一定要“突破”这种限制,可以使用 after search 或 scroll,但它们都存在一些限制:前者不能进行随机分页,只能一页页“翻”,后者会使用缓存保存分页结果,数据不能及时更新。更多说明可以查看官方文档。
关于“深度分页问题”的更多说明,可以观看这个视频。
高亮
高亮的作用是在前端显示查询结果时,将其中的检索关键字能用显眼的颜色凸出显示。具体是通过 es 服务端给查询结果打上特殊的 html 标签,并由前端用 css 颜色渲染完成高亮显示。
进行高亮的 DSL 查询语句语法:
GET /索引库名/_search
{"query": {查询子语句},"highlight": {"fields": {"字段名1": {"pre_tags": "起始标签","post_tags": "结束标签"}}}
}
示例:
GET /hotel/_search
{"query": {"match": {"name": "如家"}},"highlight": {"fields": {"name": {"pre_tags": "<em>","post_tags": "</em>"}}}
}
返回结果:
{// ..."hits" : {// ..."hits" : [{// ..."_source" : {// ..."name" : "如家酒店(北京良乡西路店)",// ...},"highlight" : {"name" : ["<em>如家</em>酒店(北京良乡西路店)"]}},// ...]}
}
可以看到,_source中的name字段内容并没有打上高亮标签,因为_source字段表示原始数据,打上高亮标签的结果是用一个新的字段highlight表示的。我们只需要按需求进行字段替换即可。
es 的高亮功能默认使用<em></em>标签,所以一般我们不需要显示指定标签:
GET /hotel/_search
{"query": {"match": {"name": "如家"}},"highlight": {"fields": {"name": {}}}
}
需要注意的是,默认情况下查询子句中的字段必须与高亮字段一致才能触发高亮功能,比如:
GET /hotel/_search
{"query": {"match": {"all": "如家"}},"highlight": {"fields": {"name": {}}}
}
这里查询的字段是all,highlight中指定的高亮字段是name,所以结果中并不会有任何高亮结果。
但我们这里这样做是有意义的,因为all字段包含三个字段的内容,其执行“综合检索”的效率要比分别查询三个字段高,此时可以这样编写 DSL:
GET /hotel/_search
{"query": {"match": {"all": "如家"}},"highlight": {"fields": {"name": {"require_field_match": "false"},"brand": {"require_field_match": "false"},"city": {"require_field_match": "false"}}}
}
require_field_match可以规避字段必须匹配的限制,现在返回结果中包含高亮结果。
RestClient 查询文档
我们的最终目标是使用 es 的 Java 客户端 RestClient 执行 DSL 查询。
快速入门
这里从一个最简单的 DSL 查询 match_all 的实现开始:
// ...
public class HotelSearchTests {// ...@Test@SneakyThrowsvoid testMatchAll() {// 构建请求对象,并指定索引库名SearchRequest request = new SearchRequest("hotel");// 构建 DSL 查询语句request.source().query(QueryBuilders.matchAllQuery());// 执行查询并返回结果SearchResponse searchResponse = restHighLevelClient.search(request, RequestOptions.DEFAULT);// 获取外层的 hits 对象SearchHits searchHits = searchResponse.getHits();// 查询到的总数long total = searchHits.getTotalHits().value;System.out.println(String.format("找到了%d条数据", total));// 获取内层 hits 数组(查询到的实际数据)SearchHit[] hits = searchHits.getHits();// 遍历for (SearchHit h : hits) {// 对原始数据进行 json 解码,生成 java 对象String json = h.getSourceAsString();HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);System.out.println(hotelDoc);}}
}
SearchRequest.source方法返回的是SearchSourceBuilder对象,可以利用这个对象给SearchRequest对象附加各种查询子语句,比如:
SearchSourceBuilder.query(),query 查询子语句。SearchSourceBuilder.sort(),排序子语句。SearchSourceBuilder.size()和SearchSourceBuilder.from(),分页子语句。SearchSourceBuilder.highlight,高亮子语句。
这里的SearchSourceBuilder.query()方法接收一个QueryBuilder类型的参数,这是一个接口类型,可以使用工具类QueryBuilders返回合适的实现,这些实现对应我们之前介绍的不同类型的 DSL 查询。具体包括:
.matchAllQuery(),对应 match_all 查询。.boolQuery(),对应 bool 查询。.functionScoreQuery(),对应 function score 查询。.geoDistanceQuery(),对应 geo_distance 查询。.matchQuery(),对应精确匹配查询。
执行查询后返回的SearchResponse对象,其结构与 DSL 查询返回的原始 json 结构一致,所以我们可以参考 json 结构对其进行解析。
可以看出,执行不同类型的查询,只需要使用不同的QueryBuilders方法构建 DSL 即可,所以为了方便后续演示不同查询 API 的调用,我们可以对之前的示例进行重构:
// ...
public class HotelSearchTests {// ...@Testvoid testMatchAll() {doQuery(QueryBuilders.matchAllQuery());}@SneakyThrowsprivate void doQuery(QueryBuilder queryBuilder){// ...request.source().query(queryBuilder);// ...}
}
全文检索
DSL 语句:
GET /hotel/_search
{"query": {"match": {"all": "外滩如家"}}
}
对应的 RestAPI 调用示例为:
@Test
void testMatch(){doQuery(QueryBuilders.matchQuery("all","外滩如家"));
}
DSL 语句:
GET /hotel/_search
{"query": {"multi_match": {"query": "外滩如家","fields": ["brand","name","city"]}}
}
对应的 RestAPI 调用示例:
@Test
void testMultiMatch() {doQuery(QueryBuilders.multiMatchQuery("外滩如家", "name", "brand", "city"));
}
精确查询
DSL:
GET /hotel/_search
{"query": {"term": {"city": {"value": "上海"}}}
}
对应的 RestAPI 调用示例:
@Test
void testTerm() {doQuery(QueryBuilders.termQuery("city", "上海"));
}
DSL:
GET /hotel/_search
{"query": {"range": {"price": {"gte": 100,"lte": 150}}}
}
对应的 RestAPI 调用示例:
@Test
void testRange() {doQuery(QueryBuilders.rangeQuery("price").gte(100).lte(150));
}
地理查询
DSL 语句:
GET /hotel/_search
{"query": {"geo_distance": {"distance": "5km","location": "31.21,121.5"}}
}
对应的 RestAPI 调用示例:
@Test
void testGeoDistance(){doQuery(QueryBuilders.geoDistanceQuery("location").distance("5km").point(31.21,121.5));
}
function score 查询
DSL 语句:
GET /hotel/_search
{"query": {"function_score": {"query": {"match": {"all": "浦东"}},"functions": [{"filter": {"term": {"brand": "如家"}},"weight": 10}],"boost_mode": "sum"}}
}
对应的 RestAPI 调用示例:
@Test
void testFunctionScore() {FunctionScoreQueryBuilder.FilterFunctionBuilder[] filterFunctionBuilders = {new FunctionScoreQueryBuilder.FilterFunctionBuilder(QueryBuilders.termQuery("brand", "如家"),ScoreFunctionBuilders.weightFactorFunction(10))};FunctionScoreQueryBuilder fsqb = QueryBuilders.functionScoreQuery(QueryBuilders.matchQuery("all", "浦东"),filterFunctionBuilders);fsqb.filterFunctionBuilders();fsqb.boostMode(CombineFunction.SUM);doQuery(fsqb);
}
这个查询构建复杂一些,但依然遵循 DSL 查询语句的结构。
bool 查询
DSL 语句:
GET /hotel/_search
{"query": {"bool": {"must": [{"match": {"name": "如家"}}],"must_not": [{"range": {"price": {"gt": 400}}}],"filter": [{"geo_distance": {"distance": "10km","location": {"lat": 31.21,"lon": 121.5}}}]}}
}
对应的 RestAPI 查询示例:
@Test
void testBool() {BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();boolQueryBuilder.must(QueryBuilders.matchQuery("name", "如家"));boolQueryBuilder.mustNot(QueryBuilders.rangeQuery("price").gt(400));boolQueryBuilder.filter(QueryBuilders.geoDistanceQuery("location").distance("10km").point(31.21, 121.5));doQuery(boolQueryBuilder);
}
排序和分页
假设涉及排序和分页的 DSL 是:
GET /hotel/_search
{"query": {"match_all": {}},"sort": [{"price": {"order": "asc"}}],"from": 0,"size": 10
}
用 RestAPI 调用实现:
@Test
@SneakyThrows
void testSortAndPage() {SearchRequest request = new SearchRequest("hotel");SearchSourceBuilder source = request.source();source.query(QueryBuilders.matchAllQuery());source.sort("price", SortOrder.ASC);source.from(0).size(10);SearchResponse searchResponse = restHighLevelClient.search(request, RequestOptions.DEFAULT);printResponse(searchResponse);
}
当然也可以用级联调用的风格:
@Test
@SneakyThrows
void testSortAndPage() {SearchRequest request = new SearchRequest("hotel");request.source().query(QueryBuilders.matchAllQuery()).sort("price", SortOrder.ASC).from(0).size(10);SearchResponse searchResponse = restHighLevelClient.search(request, RequestOptions.DEFAULT);printResponse(searchResponse);
}
高亮
假设高亮的 DSL 语句内容如下:
GET /hotel/_search
{"query": {"match": {"all": "如家"}},"highlight": {"fields": {"name": {"require_field_match": "false"},"brand": {"require_field_match": "false"},"city": {"require_field_match": "false"}}}
}
用 RestAPI 调用实现就是:
@Test
@SneakyThrows
void testHighlight() {SearchRequest request = new SearchRequest("hotel");request.source().query(QueryBuilders.matchQuery("all", "如家")).highlighter(new HighlightBuilder().field("name").field("brand").field("city").requireFieldMatch(false));SearchResponse searchResponse = restHighLevelClient.search(request, RequestOptions.DEFAULT);// 获取外层的 hits 对象SearchHits searchHits = searchResponse.getHits();// 查询到的总数long total = searchHits.getTotalHits().value;System.out.println(String.format("找到了%d条数据", total));// 获取内层 hits 数组(查询到的实际数据)SearchHit[] hits = searchHits.getHits();// 遍历for (SearchHit h : hits) {// 对原始数据进行 json 解码,生成 java 对象String json = h.getSourceAsString();HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);// 获取高亮部分以替换原始内容Map<String, HighlightField> highlightFields = h.getHighlightFields();for (Map.Entry<String, HighlightField> entry : highlightFields.entrySet()) {String fieldName = entry.getKey();HighlightField highlightField = entry.getValue();if (highlightField == null) {//高亮内容为空,下一条continue;}Text[] fragments = highlightField.getFragments();if (fragments == null || fragments.length == 0){//缺少实际的高亮内容,不处理continue;}String highlightContent = fragments[0].toString();//利用反射,将高亮内容替换原始内容Field hotelDocField = null;try{hotelDocField = HotelDoc.class.getDeclaredField(fieldName);}catch (NoSuchFieldException e){//不能和类型中的字段名匹配,不处理continue;}hotelDocField.setAccessible(true);hotelDocField.set(hotelDoc, highlightContent);}System.out.println(hotelDoc);}
}
这里解析和重新组装对象的代码部分更复杂一些,遍历内层hits时,h.getHighlightFields()返回的部分就是 es 对每条命中数据的高亮结果,对应 json 返回值中的:
"highlight" : {"name" : ["<em>如家</em>酒店(北京良乡西路店)"],"brand" : ["<em>如家</em>"]
}
所以对h.getHighlightFields()的遍历就是对实际上高亮内容的遍历。这是一个Map对象,其中的 key 是字段名,对应上面例子中的name和brand,值是一个HighlightField对象,可以通过HighlightField.getFragments()[0].toString()获取其中的高亮内容。
案例:酒店检索页面
可以用上面学到的内容实现一个简单的酒店检索页面,具体可以参考这组视频。
The End,谢谢阅读。
本文所有的示例代码可以从这里获取。