0、前言
最近在学习集成学习的时候了解到了k折交叉验证,其实在之前学习吴恩达老师的课程中也学过交叉验证,但是当时也不是很明白。这次借着自己的疑问以及网上搜找资料,终于把交叉验证给弄明白了。
在弄清楚前,我有这样几个疑问:
- ❓只划分测试集和训练集不行吗?貌似我之前训练的yolo并不需要valid验证集也可以训练呀,训练集用来得到最终的模型,测试集用来评估模型的性能,很对呀,为什么好端端多出来一个验证集❓
- ❓验证集就验证集,还得叫k折交叉验证?到底是如何进行的呢?验证集是否参与训练呢?如果不参与训练,那他岂不是和测试集作用差不多❓
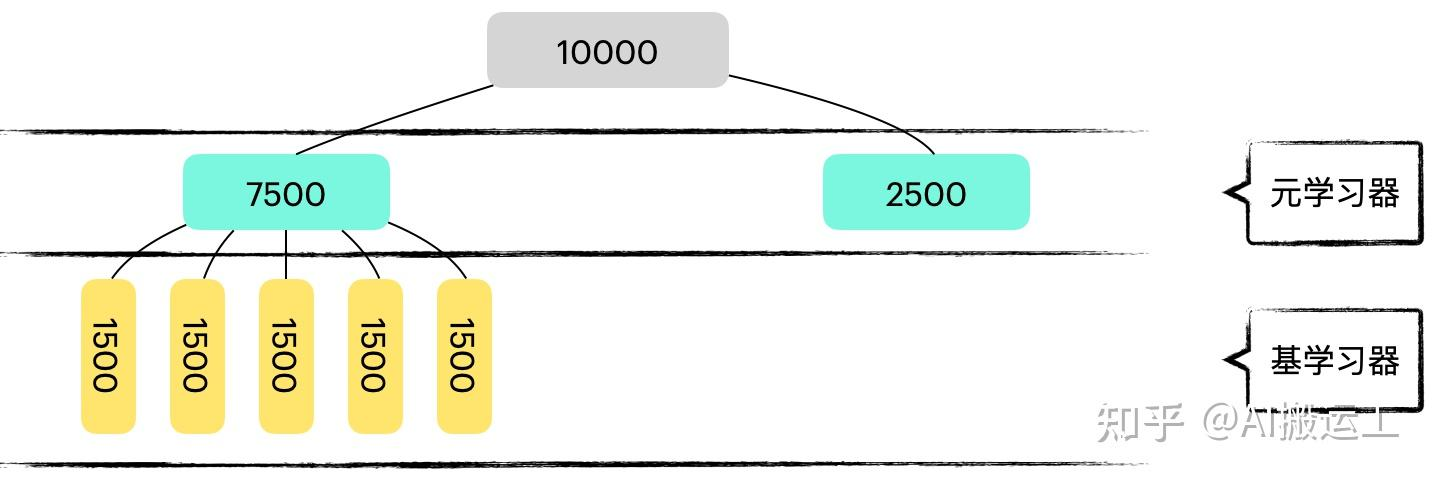
- ❓什么时候用k折交叉验证划分数据集呢?(因为在Stacking集成方法的学习中,基学习器和元学习器的的数据集划分方式不一样,基学习器采用直接划分训练集和测试集进而将数据集划分为两部分,而元学习器采用k折交叉验证进行划分:
带着这样几个疑问,我开始学习,在这之前,我先先过一遍理论,重学一遍吴恩达老师对这部分知识点的讲解。这部分是围绕机器学习系统的构建,我们知道了如何构建分类、回归、神经网络模型的一些它们的基本结构、基本工作原理,但是在这个机器学习系统(模型)的真正构建中(这个构建不只是说你得到了模型,同时你必须保证这个模型的性能是符合要求的),一次训练可以得到一个模型,但是这个模型的性能不一定是符合要求的,如何保证一次训练能得到一个较好、较为接近理想的模型,以及在得到不理想模型后,如何进行对模型的诊断和优化,这才是机器学习系统的构建!它是包含了数据的选择、数据集划分、训练模型、以及模型的诊断优化
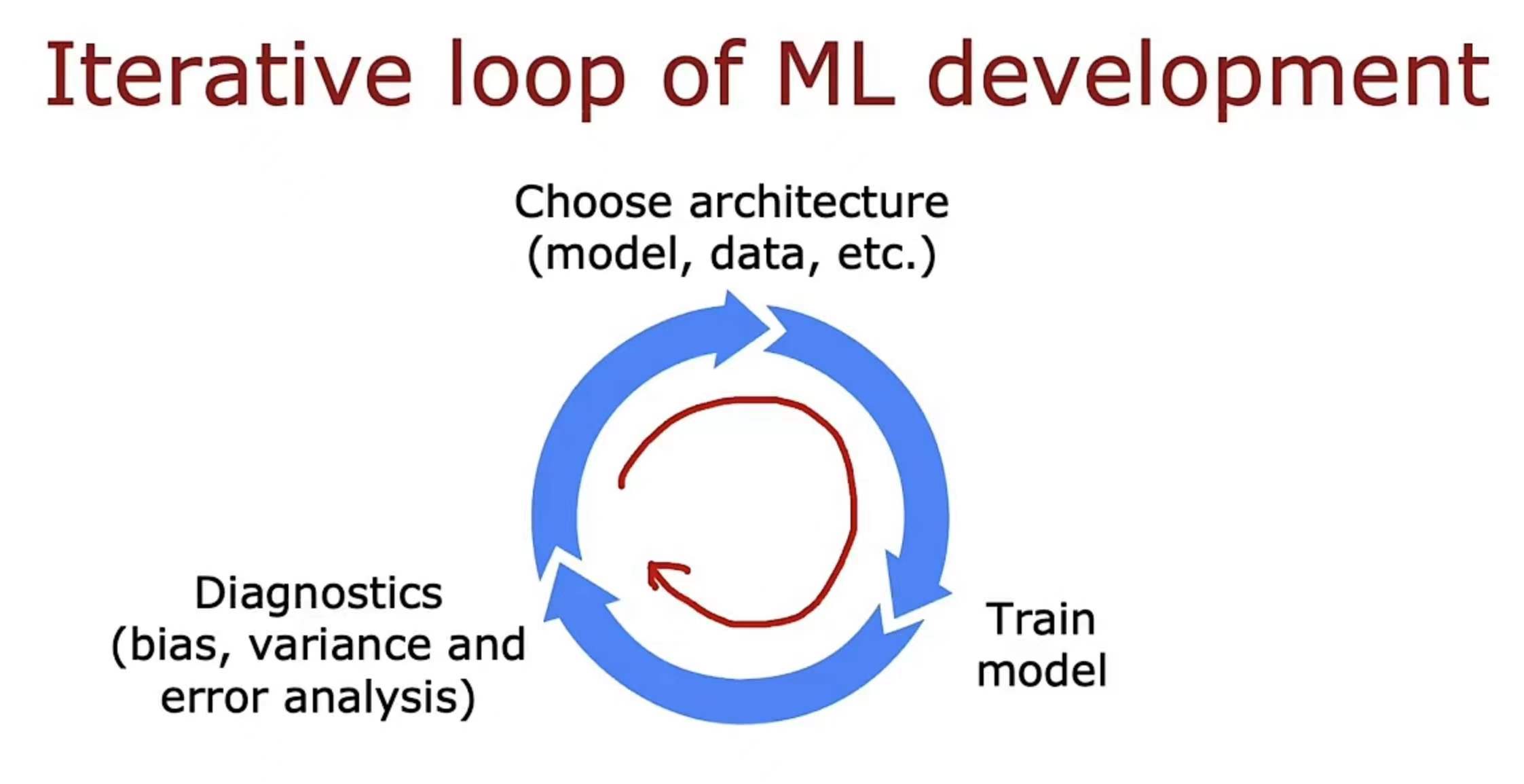
关于上图几个过程需要强调的是:
- 从选择(数据+模型)到训练模型,是训练的过程,训练完成后,我们就已经获得了基于当前训练集集的最优模型,注意是基于当前训练集,而不是模型实际的性能。——key:如何进行正确的划分数据集,从而经过训练后,能使这个模型的实际性能尽可能好呢?
- 但是这个训练得到的模型是否真正符合需求呢(泛化能力),那么我们还需要评估模型(模型的诊断diagnostics),模型的评估我们采用测试集进行,获得方差和偏差,从而判断是否需要重新选择结构(模型、数据等)来进行优化。——key:如何根据方差和偏差来调整呢?
💡对于上面两大段文字,你只要清楚:如果能在过程1中经过训练,得到模型,且这个模型的性能(泛化能力)非常好,那是不是就能减轻过程2 的工作量(无需做更多次优化),所以如何基于现有数据就得到一个性能好的模型,就十分重要,我们不能单单只靠过程2去不断优化模型从而得到最终的好模型,这样工作量极大且十分低效!(其实k折交叉验证就是在帮助过程1能尽量训练一次就得到一个很棒的模型,直观上来说就是在客观的模型评估时方差和偏差都低)
其实弄清楚了上面的过程和关键点其实也就大概明白了k折交叉验证存在的意义,如果不懂也没关系,下面会一步一步讲解清楚的。
一、模型评估
模型的评估(evaluate the performance of the model),是指已经得到经过训练的模型(意味着,在训练上它的数据上已经表现得非常好了,但这不意味着它有很好的泛化能力),如何去评估这个模型实际的性能(泛化能力,即在其他没有见过的数据上的表现)。
比如说在下面这个例子上,在训练集上,这个模型训练的肯定是极佳了(损失函数几乎就是0了),但是这个模型性能不一定就是最好的,来个新数据,很有可能就预测不准确。所以,我们要一个好的模型,这个好,是它在其他任意数据到来时都能表现的好。

那么如何判断这个模型好不好呢?就需要用到我们模型评估的方法,直接给它上没见过的数据,看看预测的咋样呗——测试集(test set)
❗❗❗需要强调的是,必须是没见过的,即没有参与模型训练的数据,如何你从训练集里面拿数据(也就是已经参与训练这个模型的数据)来评估,这将不是客观的,不可取的,无法体现模型的实际性能!

如下图,通过计算模型分别在测试集上和训练集上的损失函数,我们可以进行模型性能的诊断和评估:

关于如何利用这两个值进行模型评估,在方差和偏差那一节会详细讲
这里需要强调的是,模型评估只能用来评估模型的性能,从而对这个模型进行优化。它不能用来作为选择模型的指标!!这句话其实很难懂。
换句话来说,模型评估,是基于你已经确定了一个模型的基础上进行的,这个步骤(模型评估)是在模型选择这个步骤之后的,且用测试集进行评估了之后,你不能再拿测试集去改模型,这就相当于把测试集数据当成了训练数据,会导致最终再拿这个测试集去评估时无法客观准确的去判断(那我再拿一些数据来?咳咳,数据集的划分也是在这些步骤之前的,你需要遵守,如果你预先留了一些数据,那么是不是按照刚刚的说法,你是不是得留无穷无尽的数据呢?)。
那么什么是模型的选择呢?
二、模型的选择(模型开发)&验证集
下面我们来讲模型的选择(model selection),这会解释:❓为什么不能拿测试集的损失函数结果来进行选择模型❓以及带大家了解,❓什么是验证集,它到底有什么作用?
- 🌸什么是模型的选择?
- 🪧答:其实是指选择模型的结构,也成为模型的开发过程,一些超参数层面上的,比如一些决策树的深度、神经网络的层数,如何选择可以得到一个更好的性能?
下图这个例子,比如我们想从已经训练好的十个多项式模型里面进行选择一个性能好的模型,OK,我直接拿测试集进行代价函数计算,选在测试集上代价函数最小的那个模型不就OK啦?在测试集上的代价函数小,就说明其泛化能力强不是吗?

这样想法是错误的,为什么呢?因为当你用测试集进行选择了一个代价函数最小的时候,你其实这个过程还是在训练模型的过程(广义上的,指由数据得到一个模型),也就是说你的测试集是参与了你的模型的训练,你选择了当前这些模型中在测试集上损失函数最小的那个,其实这个模型是基于训练集数据+测试集数据得到的,这时测试集也不再是测试集,它不再具有模型泛化能力的客观评估作用,它其实还是相当于训练集。因为模型的结构的那些神经网络的层数、决策树的深度,其实也相当于模型训练过程的参数,只不过是超参数,如果你根据测试集的代价函数的结果大小去选择模型(其实本质就是调整超参数),那么你还是相当于用测试集去参与了模型的训练过程(更精确来讲是模型的开发过程,包括模型的训练和模型的选择即超参数调整),这时,再用测试集去评论模型的泛化能力就不再客观了。
上面说了这么多,你只用得出的结论就是:测试集(test set)的作用是客观公正的评估一个模型的性能(泛化能力),它必须独立于模型的开发过程(模型的训练、选择、超参数调整),这样才能保证模型评估的客观公正.(🍀到这里也解释了开篇提到的第一个问题,为什么需要验证集!)
那么,模型的选择(超参数的选择)改如何办呢?——验证集(valid set)
也可以称为开发集( dev set),因为它是直接参与模型的开发中的模型选择这个过程中的。
有了验证集,我们可以进行模型的选择,根据验证集,选择了模型之后,我们才可以用测试集进行模型的评估!

三、训练集、验证集、测试集:作用总结
综上,我们基本就弄清楚了各个各个数据集的作用,在这里我们总结一下:
- 训练集(train set):在一个确定的模型结构上,基于训练集的数据,用相应模型的训练方法(比如反向传播和梯度下降)进行模型的训练——模型的训练
- 验证集(valid set/ dev set):对训练好的、不同结构的模型进行性能的评估,进行选择,选择一个性能最好的(这里的最好,是只这个模型是基于训练集、验证集表现的最好的,并不代表它的泛化能力就一定强)——模型的选择和超参数调整
- 测试集(test set):独立于模型开发过程,在最终由前两个步骤推出来一个模型后,对这个模型的泛化能力进行客观公众的评估。——在最终选择好模型后,进行模型性能评估(当然不仅仅是看代价函数,还有准确率(Accuracy)、精确度(Precision)、和召回率(Recall)F1 分数(F1 Score)、均方误差(Mean Squared Error, MSE)、混淆矩阵(Confusion Matrix),当然这都是后话
四、k折交叉验证法
k折交叉验证,是一种特殊数据集划分,从而选择模型的方法,用这种数据集划分的方法来进行模型的开发(训练和选择)。
对全部数据集划分成训练集和测试集,然后对训练集进行K折。
所谓k折就是把训练集等分为k分,取其中的1份作为验证集,其余的k-1份作为训练集,这样取k次,可以训练得到k个模型(结构相同但是参数已经被训练的不同了)。

具体流程:
-
将全部训练集S分成k个不相交的子集,假设S中的训练样例个数为
m,那么每一个子集有m/k个训练样例,相应的子集称作 { S 1 , S 2 , . . . , S k } \left \{ S_1,S_2,...,S_k \right \} {S1,S2,...,Sk} -
每次从模型集合M中拿出来一个 M i M_i Mi,然后在训练子集中选择出
k-1个 { S 1 , S 2 , S j − 1 , S j + 1 . . . , S k } \left \{ S_1,S_2,S_{j-1},S_{j+1}...,S_k \right \} {S1,S2,Sj−1,Sj+1...,Sk},(也就是每次只留下一个 { S j } \left \{ S_j \right \} {Sj},,使用这k-1个子集训练 M i M_i Mi后,得到假设函数 h i j h_{ij} hij。最后使用剩下的一份 { S j } \left \{ S_j \right \} {Sj}作测试,得到经验错误: ε ^ S j ( h i j ) \hat{\varepsilon}_{S_j}(h_{ij}) ε^Sj(hij) -
由于我们每次留下一个 { S j } \left \{ S_j \right \} {Sj},(j从1到k),因此会得到k个经验错误,那么对于一个模型 M i M_i Mi,它的经验错误是这k个经验错误的平均。(而对于这一个模型结构 M i M_i Mi会得到k个由其训练出来的模型)
-
选出平均经验错误率最小的 M i M_i Mi(⭐最终模型选择得出!),然后使用全部的S再做一次训练,得到最后的 h i h_i hi
核心内容: 通过上述1,2,3步进行模型性能的测试,取平均值作为某个模型的性能指标,关于最终模型的获得有以下两者方式:
- 🍀方法一,将所有训练的KFold进行融合——不再进行第四步的全部重新训练,使用模型融合的方式(集成学习),即:多个模型的预测结果做了个简单的Ensemble,会更稳定一点
- 🍀方法二,根据性能指标来挑选出最终单个的最优模型,再进行上述第4步重新进行训练,获得最终模型——用上训练集和验证集的全部数据,再基于k个子集的完整训练集进行重新训练
对k折交叉验证作用的理解
-
模型选择&超参数调整: 对于上面步骤4步很好理解,对于模型选择上,相较于传统的固定划分验证集和训练集的方法,交叉验证能够尽可能使所有数据参与验证,减少了由于训练集和验证集的分布差异较大从而造成的误差,能够更客观公正的进行模型开发阶段模型之间的比较和选择
-
模型的集成,使总模型更加稳定:由一个模型架构可以训练出k个模型,k个模型的预测结果做了个简单的Ensemble,会更稳定一点。
-
充分利用数据: 传统的对数据划分的方法有可能会保留大约20%-30%的数据作为测试集,10%-20%的数据作为验证集。这意味着只有50%-70%的数据被用于训练模型。然而,在数据量较小的情况下,我们希望用尽可能多的数据来训练模型,以便模型能学习到足够的信息。k折交叉验证通过轮流将数据的每个子集作为验证集,使得每个数据点都有机会被用于验证,并且同样也被用于训练。这样,我们实际上使用了全部的数据进行训练和验证,从而充分利用了有限的数据。(所以在小数据量的情况下,可以使用k折验证方法划分数据集!)