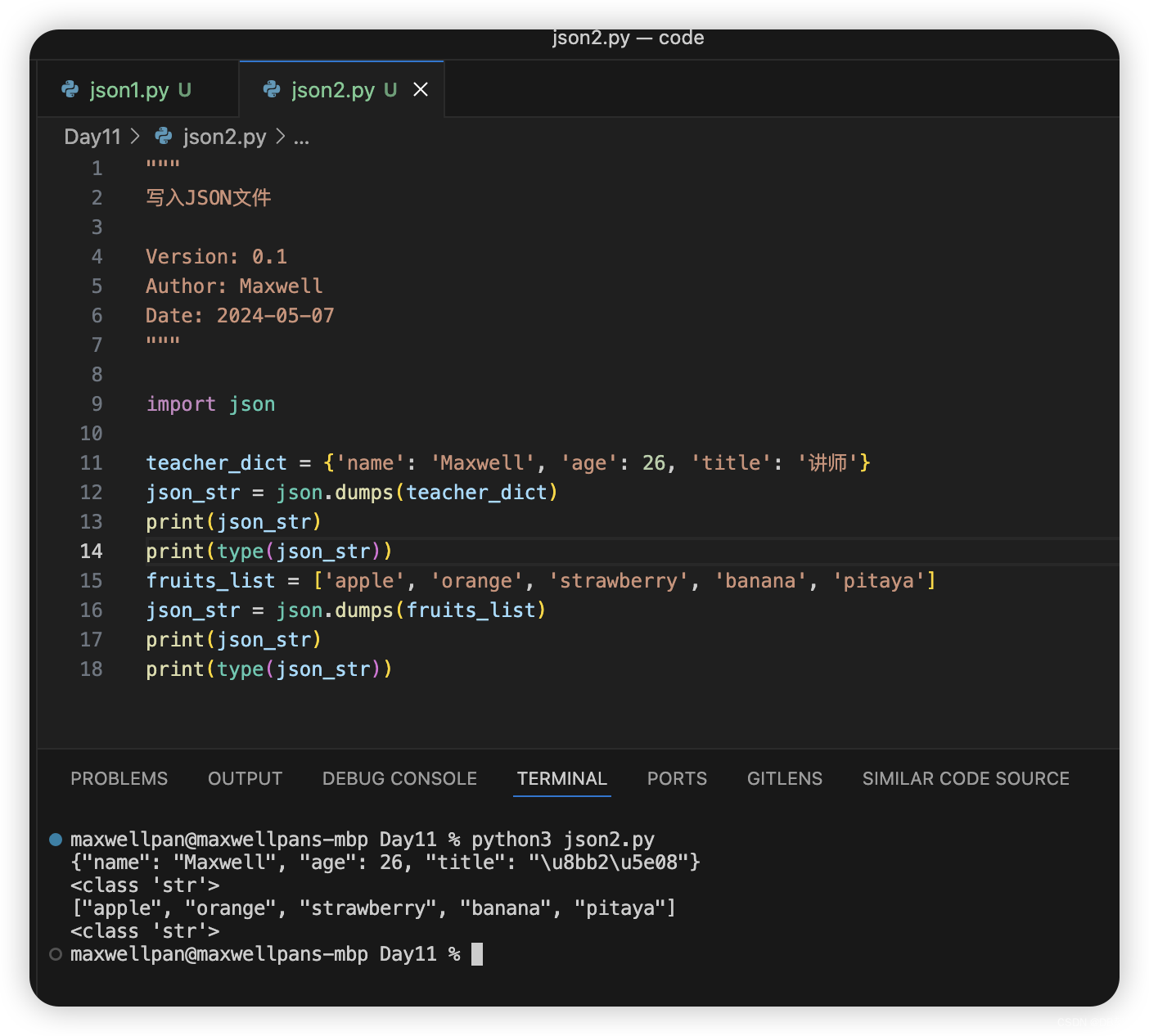
文章目录
- 一、安装 puppeteer 并更改默认缓存路径
- 1、更改 Puppeteer 用于安装浏览器的默认缓存目录
- 2、安装 puppeteer
- 3、项目结构目录
- 二、基本使用
- 1、启动浏览器并访问目标网站
- 2、生成截图
- 3、生成 PDF 文件
- 4、获取目标网站 html 结构并解析
- 5、拦截请求
- 6、执行 JavaScript
- 7、同时访问多个目标
- 8、补充说明图片获取后传递至前端展示
- 三、效果展示
- 四、参考资料
一、安装 puppeteer 并更改默认缓存路径
1、更改 Puppeteer 用于安装浏览器的默认缓存目录
在项目文件夹根目录中创建 .puppeteerrc.cjs 文件,文件内容如下:
const {join} = require('path');/*** @type {import("puppeteer").Configuration}*/module.exports = {// Changes the cache location for Puppeteer.cacheDirectory: join(__dirname, '.cache', 'puppeteer'),
};
注:安装 Puppeteer 时,它会自动下载最新版本的用于测试的 Chrome,该方法适用于不希望将安装的浏览器(Chrome)安装在默认路径下。浏览器默认下载到
$HOME/.cache/puppeteer文件夹(从 Puppeteer v19.0.0 开始)。根据自身实际可跳过该步骤。
2、安装 puppeteer
yarn add puppeteer
3、项目结构目录

更多安装详情及环境配置参见官网:https://pptr.nodejs.cn/
二、基本使用
1、启动浏览器并访问目标网站
const puppeteer = require('puppeteer');// 启动浏览器
const brower = await puppeteer.launch({// 无头模式(默认值 true,设置为false后启动程序将弹出浏览器)headless: false,args: ['--no-sandbox', '--disable-setuid-sandbox', '--enable-accelerated-2d-canvas', '--enable-aggressive-domstorage-flushing'],// 忽略 https 报错ignoreHTTPSErrors: true,timeout: 120000,
});
// 创建标签页
const page = await brower.newPage();
// 设置可视区域的大小
await page.setViewport({ width: 1920, height: 800 })
// 访问目标(此处以访问百度为例)
await page.goto('https://www.baidu.com/', {// waitUntil: 'networkidle0',timeout: 120000
});// 1、生成截图
// 2、生成PDF文件
// 3、其他...// 关闭浏览器
await brower.close();
参数说明:
waitUntil:给定事件字符串,直到事件被触发,表示等待成功。load:默认值,等待load事件触发。domcontentloaded:等待domcontentloaded事件触发。networkidle0:直到目标页面的请求不超过0个,且这一状态持续500ms。networkidle2:直到目标页面的请求不超过2个,且这一状态持续500ms。
参考链接:https://pptr.nodejs.cn/api/puppeteer.puppeteerlifecycleevent
2、生成截图
...
await page.goto(...);let imgBuffer = null;
imgBuffer = await page.screenshot({// 保存路径path: './screenshot/img.png',// 全屏截取fullPage: true,// 截取范围// clip: {x: 0, y: 0, width: 1920, height: 800}
});await brower.close();// 后续可封装成函数
// return imgBuffer;
imgBuffer:截图获取成功后,生成 buffer 数据,便于后续将该图片传递至前端展示。
关于screenshot方法的更多参数见:https://pptr.nodejs.cn/api/puppeteer.screenshotoptions/
3、生成 PDF 文件
...
await page.goto(...);await page.pdf({path: `./public/pdf/article.pdf`,// 隐藏页眉和页脚displayHeaderFooter: true,// 页面范围(全部)pageRanges: '',// 格式format: 'A3',// scale: 1.2,// 生成带标签的(可访问的)PDF。// tagged: false,// 背景printBackground: true,margin: { top: '15px' }// outline: true,
})await brower.close();
更多详情参见:https://pptr.nodejs.cn/api/puppeteer.pdfoptions
4、获取目标网站 html 结构并解析
此处解析使用 cheerio,安装 cheerio:
yarn add cheerio
获取 html 结构:
...
await page.goto(...);// 获取页面 html 结构
const html = await page.content();
// 有点类似于 JQuery
const $ = cheerio.load(html);
// 获取目标元素中的属性
const link = $('#xxx .xxx').find('a').attr('href');
// 获取文本内容
const title = $('#xxx .xxx').find('a span').text();await brower.close();
5、拦截请求
// 创建标签页
let page = await brower.newPage();
// 启用请求拦截
await page.setRequestInterception(true);// 设置请求处理函数
page.on('request', (request) => {// 只允许加载HTML、CSS、JS文件,其他资源(如图片)则阻止加载,提高加载速度if (request.resourceType() === 'image' || request.url().endsWith('.mp4')) {// 终止请求request.abort();} else {request.continue();}
});await page.goto(...);
6、执行 JavaScript
...
await page.goto(...);await page.evaluate(async () => {// 获取目标元素const element = document.querySelector('#xxx');// 隐藏目标元素element ? element.style.display = 'none' : '';
})
7、同时访问多个目标
// 目标网站信息,可以把过滤规则写在里面
const targetUrl = {"url1": { "url": "http://xxx.com","filter": async (html) => {const $ = cheerio.load(html);// 获取文本内容const title = $('#xxx .xxx').find('a span').text();return title;}},"url2": { "url": "xxx",... },
}// 启动浏览器 ...
const brower = await puppeteer.launch({...})// 针对不同网站获取信息
const promises = Object.keys(targetUrl).map(async (target) => {let page = target;// 创建标签页page = await brower.newPage();// 访问目标网址await page.goto(targetUrl[target]['url'], {waitUntil: 'domcontentloaded'});// 获取页面 html 结构const html = await page.content();// 针对不同的网站过滤提取不同的信息const titleList = await targetUrl[target]['filter'](html);// 关闭标签页await page.close();// 以对象的键命名return { [target]: titleList }
})// 处理返回的信息,插入数据库
const data = {};
await Promise.all(promises).then((result) => {// 获取集合,此处使用的mongodb数据库,集合名称为 eng_newsconst engNewsTable = mongoDB.collection('eng_news');result.forEach((el, index) => {// 获取键名const target = Object.keys(targetUrl)[index];// 获取键名对应的值data[target] = el[target]})// 插入数据库engNewsTable.insertOne(data);
}).catch((error) => {console.log(error);
});// 关闭浏览器
await brower.close();
8、补充说明图片获取后传递至前端展示
后端使用 express 框架:
router.post('/getTargetImg', async function (req, res, next) {const pdfResult = await getTargetPDF(req.body.url);if (pdfResult) {const imgBuffer = pdfResult.imgBuffer;if (imgBuffer) {// 设置 Content-Type 为 image/pngres.setHeader('Content-Type', 'image/png');res.send(imgBuffer);} else {res.send(null);}} else {res.send(null);}
})
前端使用 vue3 接收:
await getTargetImgAPI({ url: url }).then((response) => {if (response.data) {// 图片获取成功 ...const blob = new Blob([response.data], { type: "image/png" });const url = URL.createObjectURL(blob);} else {// 图片获取失败...}},(error) => {console.log(error);}
);
前端获取到 buffer 数据并处理完成后,生成的
url可直接放在img标签的:src中使用。例:<img :src="xx">
三、效果展示

四、参考资料
- https://pptr.nodejs.cn/
- https://blog.csdn.net/zhai_865327/article/details/104792646
- https://juejin.cn/post/7047794666191716383
- https://juejin.cn/post/6923868889306644488
- https://zhuanlan.zhihu.com/p/76237595