Mixtral 8x7B 的推出, 使我们开始更多地关注 基于MoE 的大模型架构, 那么,什么是MoE呢?
1. MoE溯源
MoE的概念起源于 1991 年的论文 Adaptive Mixture of Local Experts(https://www.cs.toronto.edu/~hinton/absps/jjnh91.pdf)。这个概念与集成学习方法相似,旨在为由多个单独网络组成的系统并建立一个监管机制。在这种系统中,每个网络处理训练样本的不同子集,专注于输入空间的特定区域。
后来,论文(https://arxiv.org/abs/1312.4314)探索了将 MoE 作为更深层网络的一个组件。这种方法允许将 MoE 嵌入到多层网络中的某一层,使得模型既大又高效。而且, 由研究开始探索基于输入令牌动态激活或停用网络组件的方法。2017年,论文(https://arxiv.org/abs/1701.06538)将这一概念应用于 137B 的 LSTM ,通过引入稀疏性,这项工作在保持高规模的同时实现了快速的推理速度。
总之,MoE 的引入使得训练具有数千亿甚至万亿参数的模型成为可能。
2.什么是MoE?
从溯源中可以看到,MoE 的基本思想在于“人多力量大”,这意味着利用多个专家网络,每个专家网络专门处理数据的不同方面,以获得更好的性能。其目的是创建一个动态系统,在这个系统中,可以根据输入数据利用各种专家的优势,从而比单一模型能够实现的预测更加灵活和准确。
在技术上,MoE是一种集成学习方法,把一个大任务分解成更小的部分,让不同的专家处理每个部分。然后,有一个聪明的决策者,会根据情况决定采纳哪位专家的建议,所有这些建议都被混合在一起。
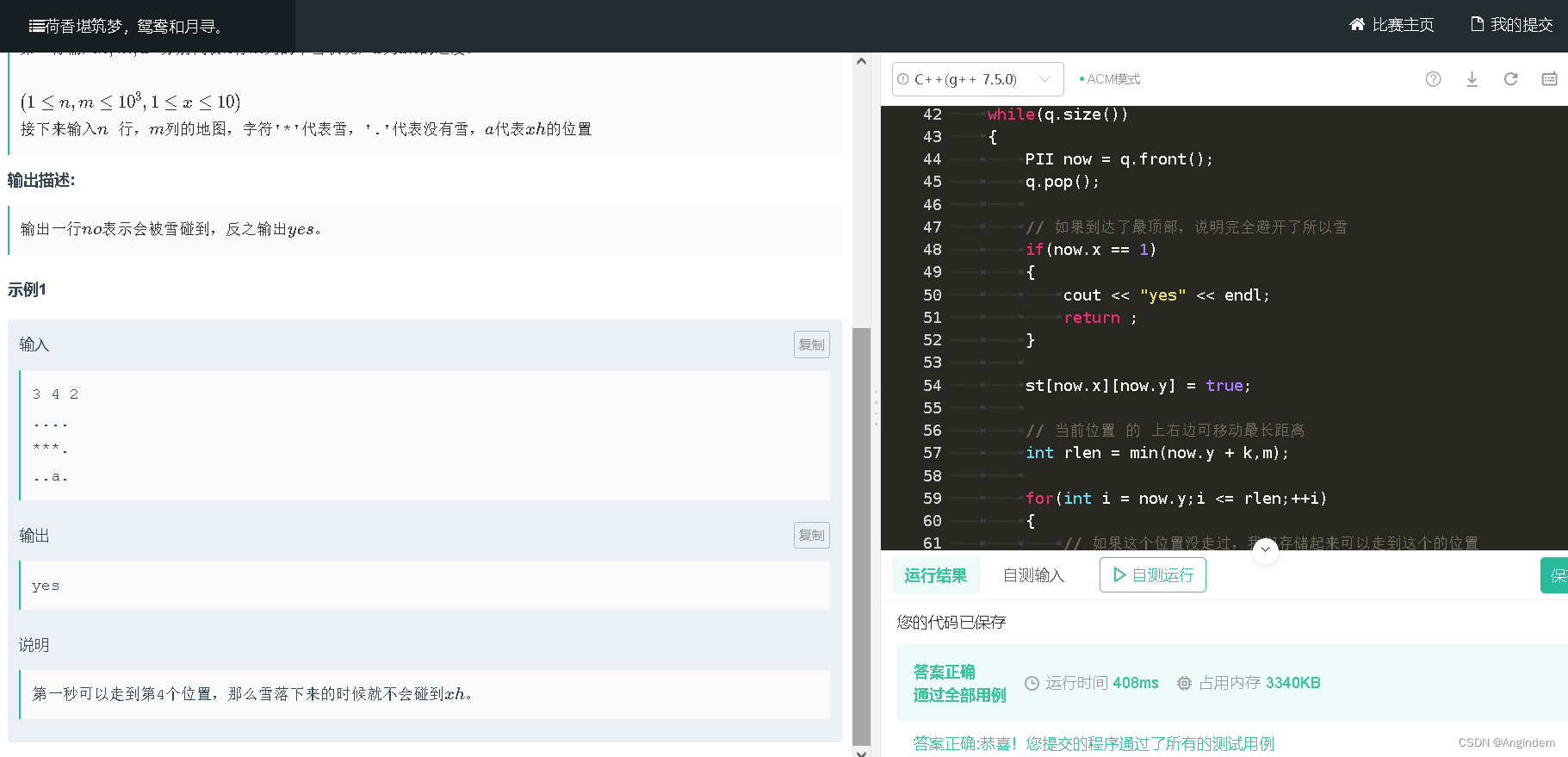
这种方法有四个主要步骤:
1. 把大问题分成小块;
2. 为每一块训练一个超级聪明的专家。
3. 引入一个决策者,也就是众所周知的门控模型,来选择应该由哪位专家带头。
4. 收集专家的意见和决策者的选择,提出最终的预测。
典型地,MoE 是一类transformer模型, 使用“稀疏”方法,其中每个输入只使用模型组件的一个子集。这种设置允许更有效的预训练和更快的推理,同时管理一个更大的模型大小。每个专家模型一般都是一个神经网络,通常是一个前馈网络(FFN) ,专门处理输入数据的不同方面,使模型能够更有效地处理范围更广的任务。
MoE的优势在于更少的计算工作使得模型的预训练更快,与为更多步骤训练更小的模型相比,为更少步骤训练更大的模型可以产生更好的结果。在推理过程中,与其他大模型相比,参数数目相同的 MoE 模型表现出更快的推理速度。尽管有许多参数,但只使用了一个子集,从而导致更快的预测。
3. MoE的组成
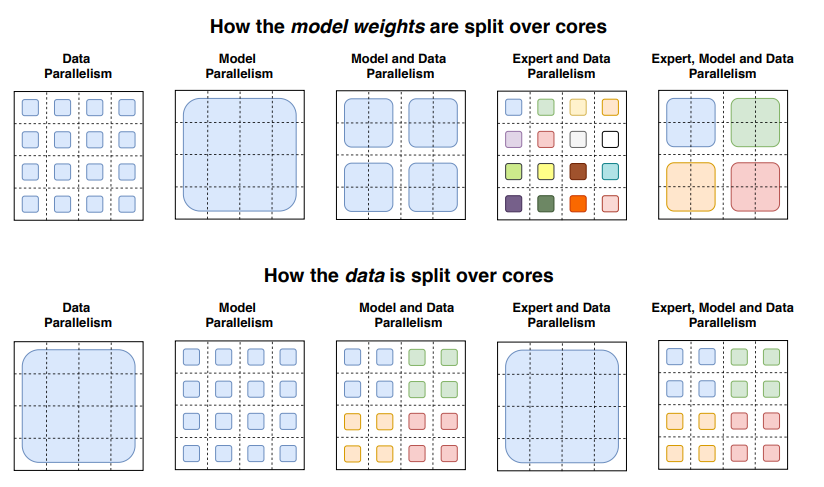
在MoE系统中,传统 Transformer 模型中的每个前馈网络 (FFN) 层替换为 MoE 层,其中 MoE 层由两个核心部分组成: 一个门控网络和若干数量的专家。
同时,token在封装输入数据中的特征和信息方面发挥着重要作用。token表示为高维向量,作为一种综合的结构化格式,用于编码输入的相关特征。每个token由多个维度组成,每个维度表示数据的特定特征或方面。通过以高维向量格式组织信息,系统可以有效地捕捉输入数据中的复杂性和细微差别,为进一步分析提供丰富的数据来源。
token的高维表示使系统内的专家能够从数据中提取详细的见解和模式。通过将token作为高维向量处理,专家模型可以利用先进的算法和技术来发现隐藏的相关性和关系,提高MoE系统的整体分析能力。
3.1 专家模型
专家模型是针对较小问题创建的模型,不仅仅局限于神经网络,也可以是任何类型的模型。对每个专家模型进行训练,使其能够在输入空间的指定区域内专门预测数据点。当然,可以神经网络来同时扮演决策者和专家的角色,这时一般会称为“混合密度网络”。所有这些专家都得到了相同的数据集 ,都会尝试在此基础上做出预测。
“专家”通常指的是模型的一个组成部分,专注于数据中特定类型的任务或模式(如代码生成、推理、汇总) 。其专业化程度取决于他们接受的训练数据和模型本身的结构,更多的是关于计算任务的本质(例如,识别特定的模式,处理特定类型的输入) ,而不是特定领域的知识。
MoE 模型中,每个专家模型一般是一个经过训练的神经网络,能够很好地处理整个数据或任务的子集。这些专家之前的共同骨干网络充当特征提取器,将原始输入转化为专家可以更有效地工作的高级表示。这种设置允许每个专家关注它最适合处理的模式或数据特征,从而实现更加细致和准确的预测。
3.2 门控模型
在给定的情况下,我们需要一个决策者来决定遵循哪位专家的建议,这个决策者被称为门控模型。门控模型决定了对于给定的输入应该使用哪个专家模型的预测。门控模型学习将输入路由到最合适的专家当门控模型是一个神经网络的时候, 有时也称为门控网络。门控网络基本上起到决策者的作用,根据不同专家的熟练程度和与输入数据的相关性为他们分配权重。也就是说,门控网络根据给出的信息动态调整专家模型的权重。
门控网络是 MoE 区别于一个简单的模型集合的关键。它是一个可训练的组件,学会根据输入数据为每个专家的输出分配适当的注意力(或权重)。这种分配不是任意的; 它是由门控网络对哪位专家最有可能为给定输入产生正确输出的评估决定的。门控机制有效地引导集合,将输入导向最相关的专家,并将他们的输出合成为一个内聚预测。这种动态路由功能允许 MoE 模型具有高度的适应性和高效性,并为每个任务利用最适当的资源。
当使用神经网络模型时,门控网络和专家模型一起训练,这种训练就像是教他们如何像一个团队一样工作。过去,用一种叫做“期望最大化”的方法来解决这个问题。门控网络可能会给每个专家一个看起来像概率的分数,表明它对每个专家的预测有多么信任。
随着Softmax和噪声top-k 门机制的引入,MoE模型有了长足的进展。Softmax是一种流行的选择,以确定每个专家模型的贡献模型的预测。它根据每个专家与输入数据的相关性为其分配权重,较高的权重给予更相关的专家。噪声 Top-k 门控机制通过选择一个Top-k 专家子集进行预测来引入随机性。这种随机元素有助于在专家选择过程中引入多样性,提高模型的鲁棒性和泛化能力。
4. MoE 的实现
实现MoE系统的关键在于体系结构的设计,其中一个比较前沿的方法涉及到利用Switch Transformer结构来集成混合的专家模型层。该体系结构使系统能够利用多个专家模型在作出决定和预测方面的综合专门知识。
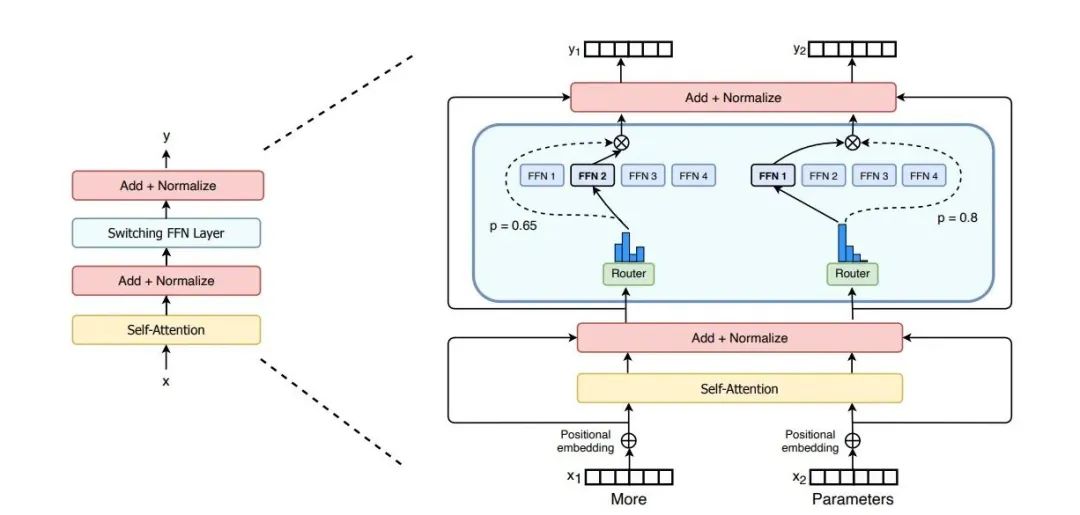
在构建Switch Transformer体系结构时,必须保证专家混合层的无缝集成。这些层负责从不同的角度处理和分析数据,使系统能够根据各种不同的见解作出明智的决定。典型的实现步骤如下:
结合Switch Transformer框架,设计MoE系统的总体架构;
将专家模型混合层集成到系统中,以支持并行的数据处理;
实现根据上下文和信息类型将数据路由到适当专家的机制;
优化训练过程,微调专家权重和切换机制。
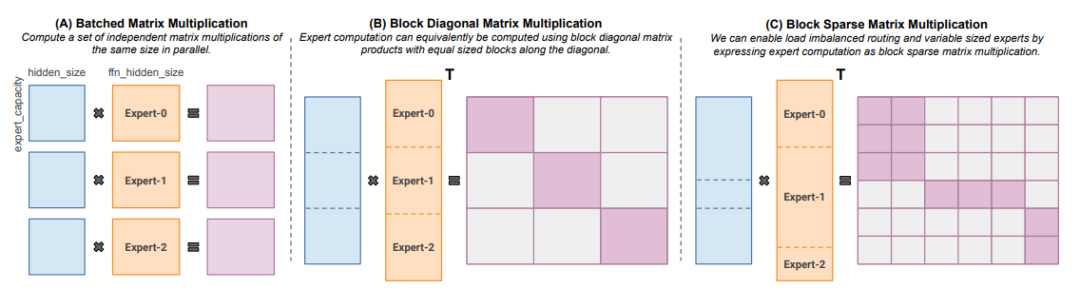
实现MoE系统的另一个关键点是动态路由和负载均。此策略确保token在整个系统中有效分布,优化性能和资源利用率。动态路由涉及到根据工作量和信息的复杂性实时分配任务和数据给不同的专家模型。通过动态路由token,系统能够适应不断变化的需求,在运行过程中保持最佳效率。负载均衡对于在专家之间均匀分配计算任务和数据处理起着至关重要的作用。这可以防止瓶颈和资源浪费,最终提高系统的整体性能。一般的策略实现方式如下:
监控每个专家模型的工作负载,并动态地重新分发token以保持平衡。
实现基于紧迫性和复杂性对任务进行优先排序的算法,以优化处理效率。
利用反馈机制不断调整负载均衡参数。
下面这些开源项目可以用于训练MoE:
Megablocks: https://github.com/stanford-futuredata/megablocks
Fairseq: https://github.com/facebookresearch/fairseq/tree/main/examples/moe_lm
OpenMoE: https://github.com/XueFuzhao/OpenMoE
5. MoE 的训练
MoE模型的训练是一个微妙的过程,其中每个专家在特定类型的推理中变得更好。它不像直接在特定任务或领域中训练一个专家那样简单。
5.1 MoE 系统训练的特点
由于模型的体系结构和它所暴露的数据组合,MoE 模型中专家的专业化通常在训练过程中自然出现,特点如下:
多样化数据: 该模型是在包含广泛任务或领域的多样化数据集上进行训练的。这种多样性至关重要,因为它使每个专家面临不同类型的数据和问题。
门控机制: MoE 模型有一个门控机制,它决定哪个专家处理输入数据的哪个部分。在训练期间,这个门控网络学会根据不同专家模型的专长向他们发送不同类型的数据。
专家模型: 随着训练的进行,每个专家模型逐渐变得更加擅长处理特定类型的数据或任务。发生这种专门化是因为专家接收并学习他们在处理数据时最有效的数据类型。
反馈回路: 有一个反馈回路在起作用的时候,如果一个专家模型在某种类型的数据方面做得更好,门控机制将更有可能向该专家发送类似的数据。这加强了每个专家的专业化。
正规化和损失函数: 训练过程通常包括正规化技术和专门的损失函数,以鼓励有效的学习,避免出现一个专家成为“万事通”的情况,从而确保专业化的分布。
能力限制: 通过对模型施加能力限制,该模型确保没有任何一位专家任务负担过重,促进所有专家之间学习的平衡分配。
微调和调整: 模型可能经历微调阶段,其中强调某些类型的任务,进一步完善每个组件的专门知识。指令调优已经成为超越传统稠密模型性能的关键策略。通过优化模型中每个专家执行的指令,以在不增加模型复杂性的情况下获得更高的精度和效率。
专家模型通常不会只专注于一个狭窄的任务类型,“专业知识”应该被理解为某些类型的数据或任务的效率或有效性的相对提高,而不是严格的领域限制。
5.2 联合训练
优化MoE模型的一个重要策略是对门控网络与其他组件进行联合训练。在联合训练过程中,门控网络的参数通过整个模型的反向传播进行更新。这个过程允许门控网络根据从专家模型收到的反馈来调整其路由决策。该模型通过对所有组件进行集成优化,可以更好地平衡不同专家的贡献,优化路由机制,达到最优结果。
5.3 指令调优
指令调优方法同样可用于训练MoE系统。这些方法着重于调整路由机制和专家模型,以提高模型在不同任务和输入数据分布中的性能。常见的微调策略包括:
软路由: 软路由技术使用连续概率来分配每个专家模型对最终输出的贡献。通过将路由决策建模为概率,特别是在多个专家模型可能提供互补信息的情况下,该模型可以执行更平滑和更灵活的路由。
硬路由: 与软路由不同,硬路由涉及为给定输入选择单个专家模型的离散路由决策。硬路由策略更易于实现和解释,因此适用于需要显式专家选择的任务。
正则化技术: 正则化方法,如 L1或 L2正则化可以应用到路由参数,以防止过拟合并提高泛化能力。通过惩罚过于复杂的路由决策,正则化可以鼓励模型关注更健壮和可解释的路由策略。
自适应路由: 自适应路由机制根据输入数据和模型的当前状态动态调整路由概率或决策。自适应路由策略使模型能够根据数据中不断变化的模式调整自己的路由行为,从而实现更加自适应和高效的专家选择。
6. MoE 的典型应用
MoE 架构已经被用来为语言模型建立大型的、计算效率高的神经网络。它们可以处理计算模式或任务,如代码生成、推理和汇总。MoE已经应用于强化学习问题,每个专家都可以专门处理环境的不同方面。在迁移学习中,MoE可以用来将在一个领域学到的知识应用到另一个相关领域。
另外,MoE正在个性化推荐系统方面取得长足进展,它们可以通过让不同的专家参与不同类型的内容或用户简介来迎合用户的不同偏好。这种基于输入数据进行适应和专门化的能力使得 MoE 对于未来的应用程序特别有吸引力。
举例而言,谷歌的 Gemini 1.5采用了MoE架构,这种架构使Gemini 1.5更有效的训练和服务。它将您的请求路由到一组较小的“专家”神经网络,这样响应速度更快,质量更高。Gemini 1.5 Pro,这是一个中等大小的多模态模型,针对不同任务的缩放进行了优化。它的性能与1.0 Ultra 相当,后者可能是迄今为止谷歌最重要的模型。Gemini 1.5 Pro 还在长语境理解方面引入了一个突破性的实验特性。它提供了一个标准的128,000 token 上下文窗口,但是有限的开发人员和企业客户可以使用最多100万token的上下文窗口来进行尝试。
另一个应用示例是Mixtral 8x7B ,它使用稀疏混合专家架构(SMoE)。它的架构与Mixtral 7B 相同,不同之处在于每一层包含八个前馈网络。对于每一个token,在每一层,门控网络选择两个专家来处理当前状态并合并他们的输出。因此,每个令牌都可以访问47B 参数,但是在推理期间只使用13B 活动参数。Mistral 8x7B 在所有评估的基准测试中都优于或匹配 Llama 270B 和 GPT-3.5。特别爹,Mixtral 在数学、代码生成和多语言基准测试方面远远超过了Llama 270B 。
7. MoE 的简单示例
MoE 模型通常用于处理复杂的数据分布,并根据不同的专家子模型进行预测。下面使用 TensorFlow/Kera 实现一个基本的 MoE 模型步骤。
(1)定义专家模型, 可以是任何典型的神经网络结构
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.layers import Dense, Input, Lambda, Layer, Softmax
from tensorflow.keras.models import Modeldef create_expert_model(input_dim, output_dim):inputs = Input(shape=(input_dim,))x = Dense(64, activation='relu')(inputs)x = Dense(32, activation='relu')(x)outputs = Dense(output_dim, activation='softmax')(x)model = Model(inputs=inputs, outputs=outputs)return model(2)定义门控网络,该网络接受输入并输出每个专家的门控系数(权重),这些系数决定了每个专家对最终预测的贡献。
def create_gating_network(input_dim, num_experts):inputs = Input(shape=(input_dim,))x = Dense(32, activation='relu')(inputs)x = Dense(num_experts, activation='softmax')(x)outputs = xmodel = Model(inputs=inputs, outputs=outputs)return model(3)创建 MoE 模型,使用门控机制来计算专家模型预测的加权和
def create_moe_model(input_dim, output_dim, num_experts):input_layer = Input(shape=(input_dim,))expert_models = [create_expert_model(input_dim, output_dim) for _ in range(num_experts)]gating_network = create_gating_network(input_dim, num_experts)expert_outputs = [expert(input_layer) for expert in expert_models]gating_coefficients = gating_network(input_layer)def moe_function(args):expert_outputs, gating_coefficients = argsreturn tf.reduce_sum(expert_outputs * tf.expand_dims(gating_coefficients, axis=-1), axis=1)moe_output = Lambda(moe_function)([expert_outputs, gating_coefficients])model = Model(inputs=input_layer, outputs=moe_output)return model(4)选择适当的损失函数,编译模型并在数据集上对其进行训练
input_dim = X_train.shape[1]
output_dim = len(np.unique(y_train))
num_experts = 5
moe_model = create_moe_model(input_dim, output_dim, num_experts)
moe_model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
moe_model.fit(X_train, y_train, epochs=10, batch_size=32)一句话小结
在复杂的门控机制指导下,智能地结合多个专家网络,基于MoE 系统的大模型提供了强大的灵活性、效率和准确性。
【参考文献与关联阅读】
Mixtral of Experts,https://arxiv.org/abs/2401.04088
Improving Expert Specialization in Mixture of Experts,https://arxiv.org/abs/2302.14703
Merging Experts into One: Improving Computational Efficiency of Mixture of Experts,https://arxiv.org/abs/2310.09832
https://huggingface.co/blog/zh/moe
https://blog.google/technology/ai/google-gemini-next-generation-model-february-2024/
大模型应用的10种架构模式
提示工程中的10个设计模式
在大模型RAG系统中应用知识图谱
面向知识图谱的大模型应用
让知识图谱成为大模型的伴侣
如何构建基于大模型的App
Qcon2023: 大模型时代的技术人成长(简)
论文学习笔记:增强学习应用于OS调度
LLM的工程实践思考
大模型应用设计的10个思考
基于大模型(LLM)的Agent 应用开发
解读大模型的微调
解读ChatGPT中的RLHF
解读大模型(LLM)的token
解读提示词工程(Prompt Engineering)
解读Toolformer
解读TaskMatrix.AI
解读LoRA
解读RAG
大模型应用框架之Semantic Kernel
浅析多模态机器学习
深度学习架构的对比分析
老码农眼中的大模型(LLM)
系统学习大模型的20篇论文