要确保Kafka在使用过程中的稳定性,需要从kafka在业务中的使用周期进行依次保障。主要可以分为:事先预防(通过规范的使用、开发,预防问题产生)、运行时监控(保障集群稳定,出问题能及时发现)、故障时解决(有完整的应急预案)这三阶段。
另外的篇幅请参考
如何更好地使用Kafka? - 事先预防篇-CSDN博客
如何更好地使用Kafka? - 运行监控篇-CSDN博客
防微杜渐,遇到问题/故障时有完整的应急预案,以快速定位并解决问题。
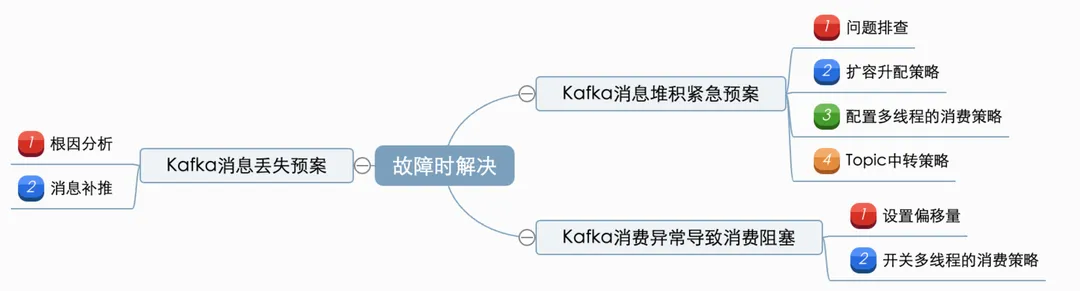
1. Kafka消息堆积紧急预案
问题描述:消费端产生消息积压,导致依赖该消息的服务不能及时感知业务变化,导致一些业务逻辑、数据处理出现延迟,容易产生业务阻塞和数据一致性问题。
方案:问题排查、扩容升配策略、消息Topic转换策略、可配置多线程的消费策略。
1.1 问题排查
遇到消息积压时,具体可以从以下几个角度去定位问题原因:
-
消息生产端数据量是否存在陡升的情况
-
消息消费端消费能力是否有下降
-
消息积压是发生在所有的partition还是所有的partition都有积压情况
对于第1、2点导致的消息积压:为暂时性的消息积压,通过扩分区、扩容升配、多线程消费、批量消费等方式提高消费速度能在一定程度上解决这类问题。
对于第3点导致的消息积压:可以采用消息Topic中转策略。
1.2 扩容升配策略
-
检查生产端消费发送情况(主要检查是否继续有消息产生、是否存在逻辑缺陷、是否有重复消息发送)
-
观察消费端的消费情况(预估下堆积消息的处理清理以及是否有降低趋势)
-
若为生产端问题,则评估是否可以通过增加分区数、调整偏移量、删除topic(需要评估影响面)等解决
-
消费端新增机器及依赖资源,提高消费能力;
-
如果涉及数据一致性问题,需要通过数据比对、对账等功能进行校验。
1.3 配置多线程的消费策略
简而言之,即线程池消费+动态线程池配置策略:将接收到的kafka数据进行hash取模(如果kafka分区接受消息已经是取模的了,这里一定要对id做一次hash再取模)发送到不同的队列,然后开启多个线程去消费对应队列里面的数据。
设计思路:
-
在应用启动时初始化对应业务的顺序消费线程池(demo中为订单消费线程池)
-
订单监听类拉取消息提交任务至线程池中对应的队列
-
线程池的线程处理绑定队列中的任务数据
-
每个线程处理完任务后增加待提交的offsets标识数
-
监听类中校验待提交的offsets数与拉取到的记录数是否相等,如果相等则
-
手动提交offset(关闭kafka的自动提交,待本次拉取到的任务处理完成之后再提交位移)

另外,可以根据业务流量调整的线程配置与pod的配置,如高峰期设置一个相对较高的并发级别数用来快速处理消息,平峰期设置一个较小的并发级别数来让出系统资源。这里,可以参考美团提供的一种配置中心修改配置动态设置线程池参数的思路,实现动态的扩容或者缩容。
实现了动态扩容与缩容:
-
通过配置中心刷新OrderKafkaListener监听类中的配置concurrent的值,
-
通过set方法修改concurrent的值时,先修改stopped的值去停止当前正在执行的线程池。
-
执行完毕后通过新的并发级别数新建一个新的线程池,实现了动态扩容与缩容。

此外,还可以新增开关,它设置为true是可以中断启动中的线程池,故障时进行功能开关。
注意: 如果涉及数据一致性问题,需要通过数据比对、对账等功能进行校验。
1.4 Topic中转策略
当消息积压是发生在所有的partition还是所有的partition都有积压情况时,只能操作临时扩容,以更快的速度去消费数据了。
设计思路:
-
临时建立好原先10倍或者20倍的queue数量(新建一个topic,partition是原来的10倍)。
-
然后写一个临时分发消息的consumer程序,这个程序部署上去消费积压的消息,消费之后不做耗时处理,直接均匀轮询写入临时建好分10数量的queue里面。
-
紧接着征用10倍的机器来部署consumer,每一批consumer消费一个临时queue的消息。
-
这种做法相当于临时将queue资源和consumer资源扩大10倍,以正常速度的10倍来消费消息。
-
等快速消费完了之后,恢复原来的部署架构,重新用原来的consumer机器来消费消息。
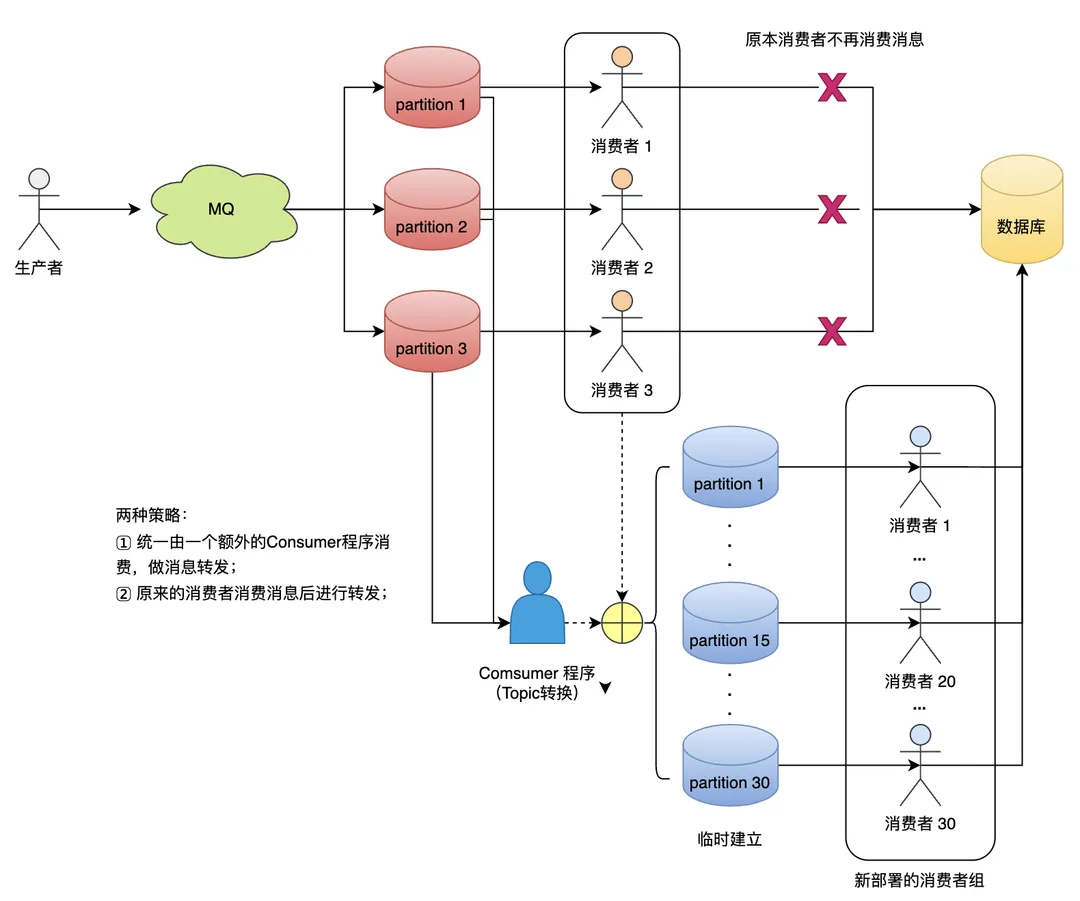
改进:
-
consumer程序可以写在服务里面;
-
指定一个“预案topic”,在服务中预先写好对“预案topic”
-
采用策略模式进行”业务topic“->“预案topic”的转换;
注意:
-
如果涉及数据一致性问题,需要通过数据比对、对账等功能进行校验。
-
需要有个单独的topic转换服务,或修改服务代码,或在事前将多线程逻辑写好或者
2. Kafka消费异常导致消费阻塞
问题描述:某个消息消费异常或者某个操作较为耗时,导致单个pod的消费能力下降,甚至产生阻塞。
方案:设置偏移量;开关多线程的消费策略;
2.1 设置偏移量
1. 调整偏移量:联系运维,将offset后移一位;
2. 消息补推:针对跳过的消息或某个时间段内的数据进行消息补推;
3. 如果涉及数据一致性问题,需要通过数据比对、对账等功能进行校验。
2.2 开关多线程的消费策略
参考上面的“可配置多线程的消费策略”,在发生阻塞时开启多线程消费开关。
注:需要修改代码或者在事前将多线程逻辑写好
3. Kafka消息丢失预案
问题描述:服务没有按照预期消费到kafka消息,导致业务产生问题
方案:根因分析;消息补推;
3.1 根因分析
(1) 生产端是否成功发送消费(源头丢失)
-
Broker丢失消息:Kafka为了得到更高的性能和吞吐量,将数据异步批量的存储在磁盘中,异步刷盘有肯能造成源头数据丢失;
-
Producer丢失消息:发送逻辑存在Bug,导致消息为发送成功。
解决:需要检查生产端与集群健康性;消息补发。
(2) 是否被成功消费
Consumer自动提交的机制是根据一定的时间间隔,将收到的消息进行commit。commit过程和消费消息的过程是异步的。也就是说,可能存在消费过程未成功(比如抛出异常),commit消息已经提交了。
此外,如果消费逻辑有bug,也导致消息丢失的假象。
解决:修复问题,视情况修改消费确认机制。
(3) 是否有其他服务共用了同一个消费组
多服务误用同一个消费组会导致消息一定比率或规律性丢失。
例如,创建用户的kafka消息,可能价格中心和促销服务误用了一个消费组,导致每个服务都是消费了部分消息,导致一些问题出现偶现的情况。
解决:修改配置,重启服务,各种建立的消费组;事前需要有检查是否有多个服务共用一个消费的情况(检测+比对);
3.2 消息补推
-
通过业务影响查询影响的数据信息;
-
构建kafka消息,进行消息补偿;
-
如果涉及数据一致性问题,需要通过数据比对、对账等功能进行校验。
针对每个对外发送的服务,生产端一般都需要有较为完善的消息补推接口,并且消费端也需要保障消息消费的幂等)