一、说明
文本摘要是为较长的文本文档生成简短、流畅且最重要的是准确摘要的过程。自动文本摘要背后的主要思想是能够从整个集合中找到最重要信息的一小部分,并以人类可读的格式呈现。随着在线文本数据的增长,自动文本摘要方法可能会非常有用,因为可以在短时间内有用的信息。
二、为什么要自动文本摘要?
- 摘要减少了阅读时间。
- 研究文档时,摘要使选择过程变得更加容易。
- 自动摘要提高了索引的有效性。
- 自动摘要算法比人工摘要的偏差更小。
- 个性化摘要在问答系统中非常有用,因为它们提供个性化信息。
- 使用自动或半自动摘要系统使商业摘要服务能够增加其能够处理的文本文档的数量。
三、文本总结的依据
在下图,至少出现了三个环节,1)文档归类 2)文档目的归类 3)主题信息抽取。
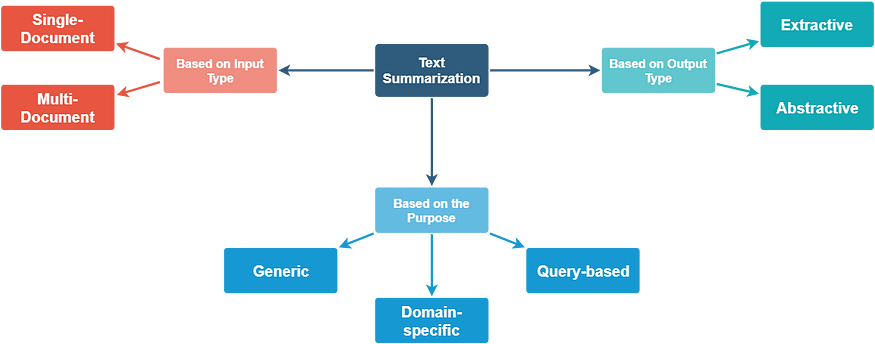
3.1 基于输入类型:
- Single Document ,输入长度较短。许多早期的摘要系统处理单文档摘要。
- 多文档,输入可以任意长。
3.2 根据目的的归类
- 通用,模型不对要总结的文本的领域或内容做出任何假设,并将所有输入视为同类。已完成的大部分工作都是围绕通用摘要展开的。
- 特定领域,模型使用特定领域的知识来形成更准确的摘要。例如,总结特定领域的研究论文、生物医学文献等。
- 基于查询,其中摘要仅包含回答有关输入文本的自然语言问题的信息。
3.3 根据输出类型:
- 提取,从输入文本中选择重要的句子以形成摘要。当今大多数总结方法本质上都是提取性的。
- 抽象,模型形成自己的短语和句子,以提供更连贯的摘要,就像人类会生成的一样。这种方法肯定更有吸引力,但比提取摘要困难得多。
四、如何进行文本摘要
- 文字清理
- 句子标记化
- 单词标记化
- 词频表
- 总结
4.1 文字清理:
# !pip instlla -U spacy
# !python -m spacy download en_core_web_sm
import spacy
from spacy.lang.en.stop_words import STOP_WORDS
from string import punctuation
stopwords = list(STOP_WORDS)
nlp = spacy.load(‘en_core_web_sm’)
doc = nlp(text)4.2 单词标记化:
tokens = [token.text for token in doc]
print(tokens)
punctuation = punctuation + ‘\n’
punctuation
word_frequencies = {}
for word in doc:
if word.text.lower() not in stopwords:
if word.text.lower() not in punctuation:
if word.text not in word_frequencies.keys():
word_frequencies[word.text] = 1
else:
word_frequencies[word.text] += 1
print(word_frequencies)4.3 句子标记化:
max_frequency = max(word_frequencies.values())
max_frequency
for word in word_frequencies.keys():
word_frequencies[word] = word_frequencies[word]/max_frequency
print(word_frequencies)
sentence_tokens = [sent for sent in doc.sents]
print(sentence_tokens)4.4 建立词频表:
sentence_scores = {}
for sent in sentence_tokens:
for word in sent:
if word.text.lower() in word_frequencies.keys():
if sent not in sentence_scores.keys():
sentence_scores[sent] = word_frequencies[word.text.lower()]
else:
sentence_scores[sent] += word_frequencies[word.text.lower()]
sentence_scores4.5 主题信息总结:
from heapq import nlargest
select_length = int(len(sentence_tokens)*0.3)
select_length
summary = nlargest(select_length, sentence_scores, key = sentence_scores.get)
summary
final_summary = [word.text for word in summary]
summary = ‘ ‘.join(final_summary)输入原始文档:
text = “””
Maria Sharapova has basically no friends as tennis players on the WTA Tour. The Russian player has no problems in openly speaking about it and in a recent interview she said: ‘I don’t really hide any feelings too much.
I think everyone knows this is my job here. When I’m on the courts or when I’m on the court playing, I’m a competitor and I want to beat every single person whether they’re in the locker room or across the net.
So I’m not the one to strike up a conversation about the weather and know that in the next few minutes I have to go and try to win a tennis match.
I’m a pretty competitive girl. I say my hellos, but I’m not sending any players flowers as well. Uhm, I’m not really friendly or close to many players.
I have not a lot of friends away from the courts.’ When she said she is not really close to a lot of players, is that something strategic that she is doing? Is it different on the men’s tour than the women’s tour? ‘No, not at all.
I think just because you’re in the same sport doesn’t mean that you have to be friends with everyone just because you’re categorized, you’re a tennis player, so you’re going to get along with tennis players.
I think every person has different interests. I have friends that have completely different jobs and interests, and I’ve met them in very different parts of my life.
I think everyone just thinks because we’re tennis players we should be the greatest of friends. But ultimately tennis is just a very small part of what we do.
There are so many other things that we’re interested in, that we do.’
“””4.6 输出(最终摘要):摘要
I think just because you’re in the same sport doesn’t mean that you have to be friends with everyone just because you’re categorized, you’re a tennis player, so you’re going to get along with tennis players. Maria Sharapova has basically no friends as tennis players on the WTA Tour. I have friends that have completely different jobs and interests, and I’ve met them in very different parts of my life. I think everyone just thinks because we’re tennis players So I’m not the one to strike up a conversation about the weather and know that in the next few minutes I have to go and try to win a tennis match. When she said she is not really close to a lot of players, is that something strategic that she is doing?有关完整代码,请查看我的存储库:
五、结语
本文至少精简地告诉大家,文章自动摘要需要哪些关键环节。
创建数据集可能是一项繁重的工作,并且经常是学习数据科学中被忽视的部分,实际工作要给以重视。不过,这是另一篇博客文章。阿努普·辛格


![NLP文本匹配任务Text Matching [有监督训练]:PointWise(单塔)、DSSM(双塔)、Sentence BERT(双塔)项目实践](https://img-blog.csdnimg.cn/img_convert/155097bc963b24648129c24d307f4547.png)