自注意力机制
存在一些问题,将vector set/sequence作为input,例如:
- 文字处理:将文字用one-hot表示,或者向量空间的向量表示,然后进行翻译任务等
- 语音处理:25ms音频作为一个向量,10ms间隔采集下一个window音频,整个音频文件作为输入,对应多个音频向量
- 社交图/分子图处理:每个节点看成一个向量,图就是vector set
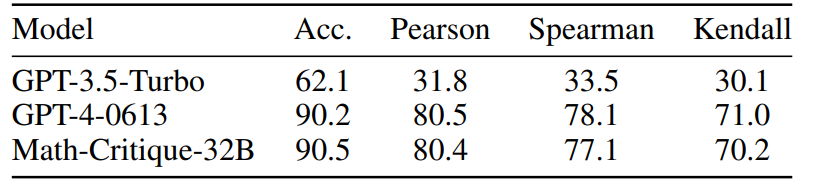
对应的,输出结果有以下可能:
每个向量有一个输出结果,被称为sequence labeling任务,例如:
- POS tagging(词性标注):每个词对应一个词性输出
- 图的节点处理:每个节点对应一个分类标签
整个向量序列只有一个输出结果,例如:
- sentiment analysis(情感分析):一句话对应一个情感分析结果
- 语者辨认:听一段声音,判断是谁讲的
- 分子的性质:给一个分子图,判断其毒性等特性
不知道有多少输出结果,被称为seq2seq任务,例如:
- 文本翻译
- 语音辨识
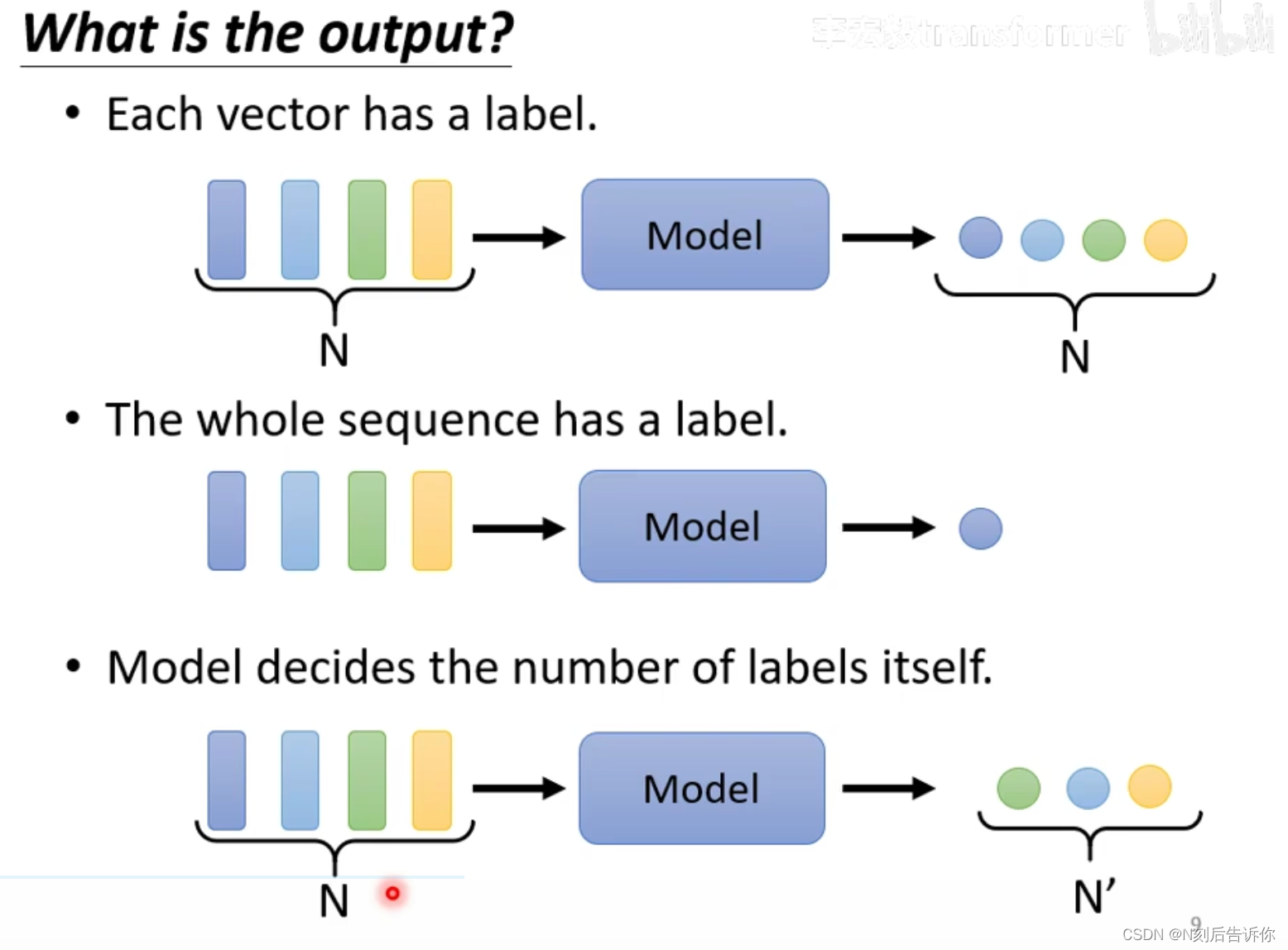
对于sequence labeling任务,可以借助FC和附近窗口,来获取周围的信息。但是这仍然不能保证窗口能观察到整个sequence的信息。
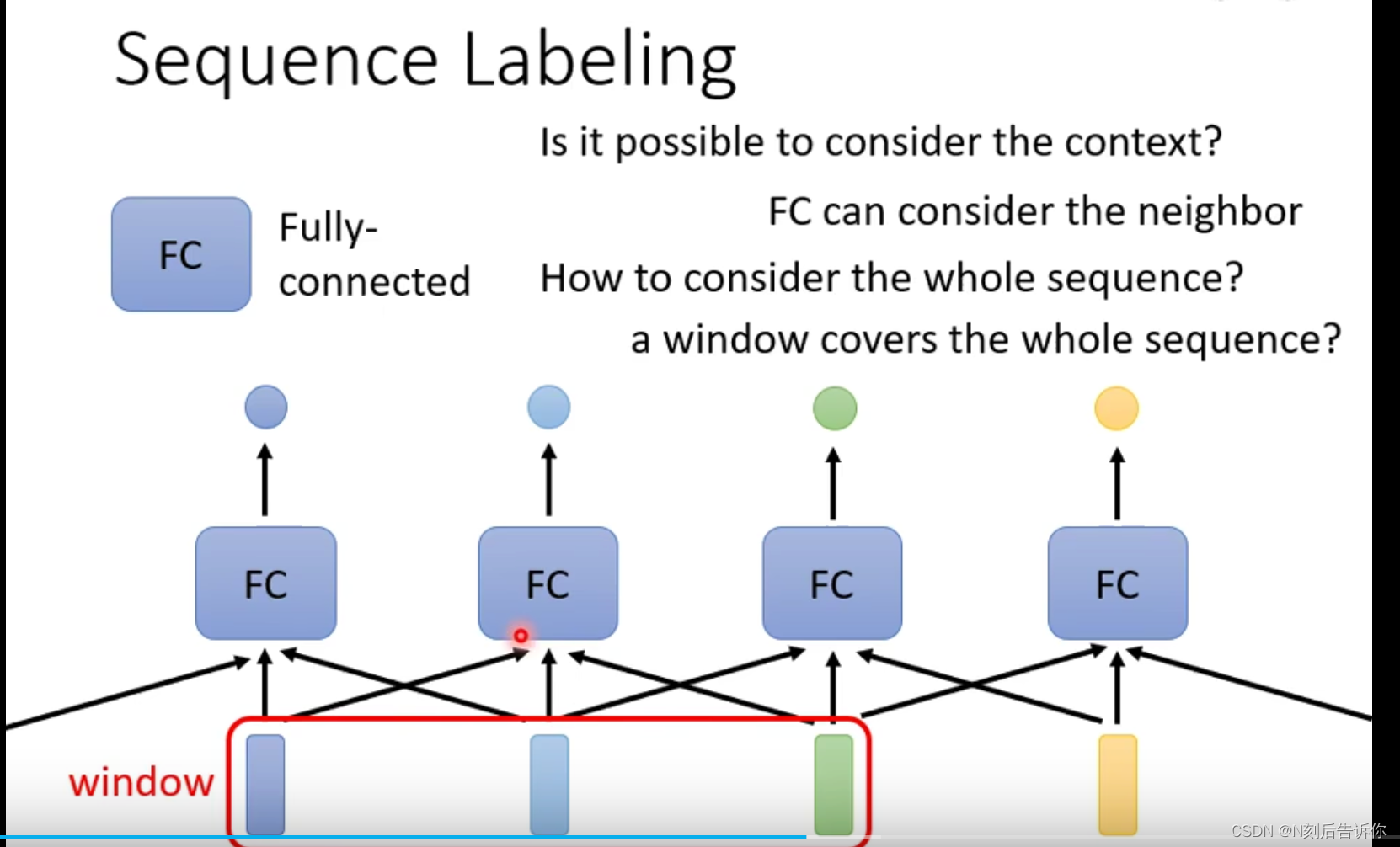
因此引出了self-attention,它能让输入向量/隐层向量(如果有多层self-attention,第二层self-attention的输入就可能是隐层向量),在考虑整个sequence的向量后,输出一个向量。
Self-attention的计算原理
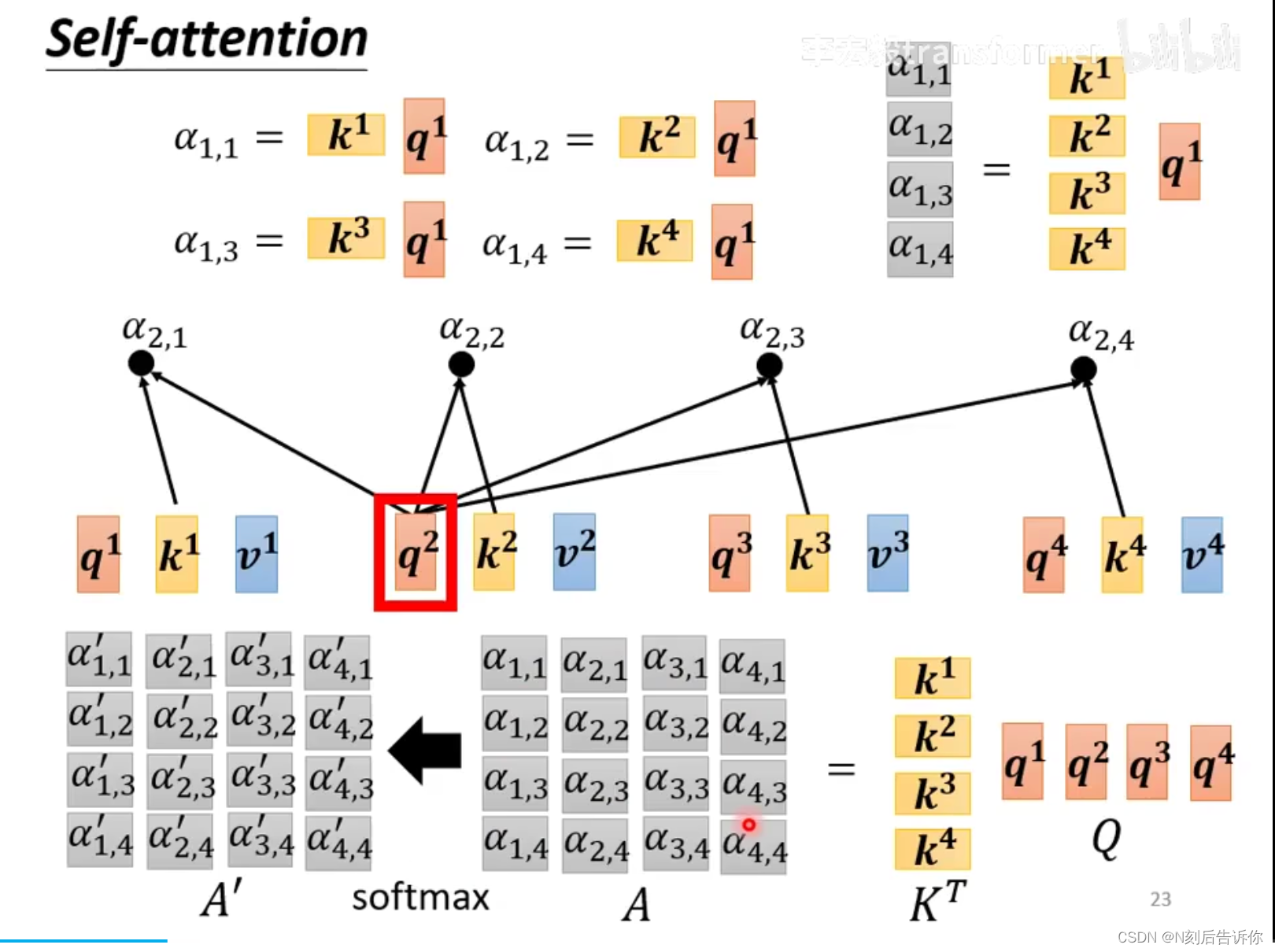
1.以输入向量 a 1 a^1 a1为例,计算sequence中的所有向量与 a 1 a^1 a1的相关性,称为attention score.
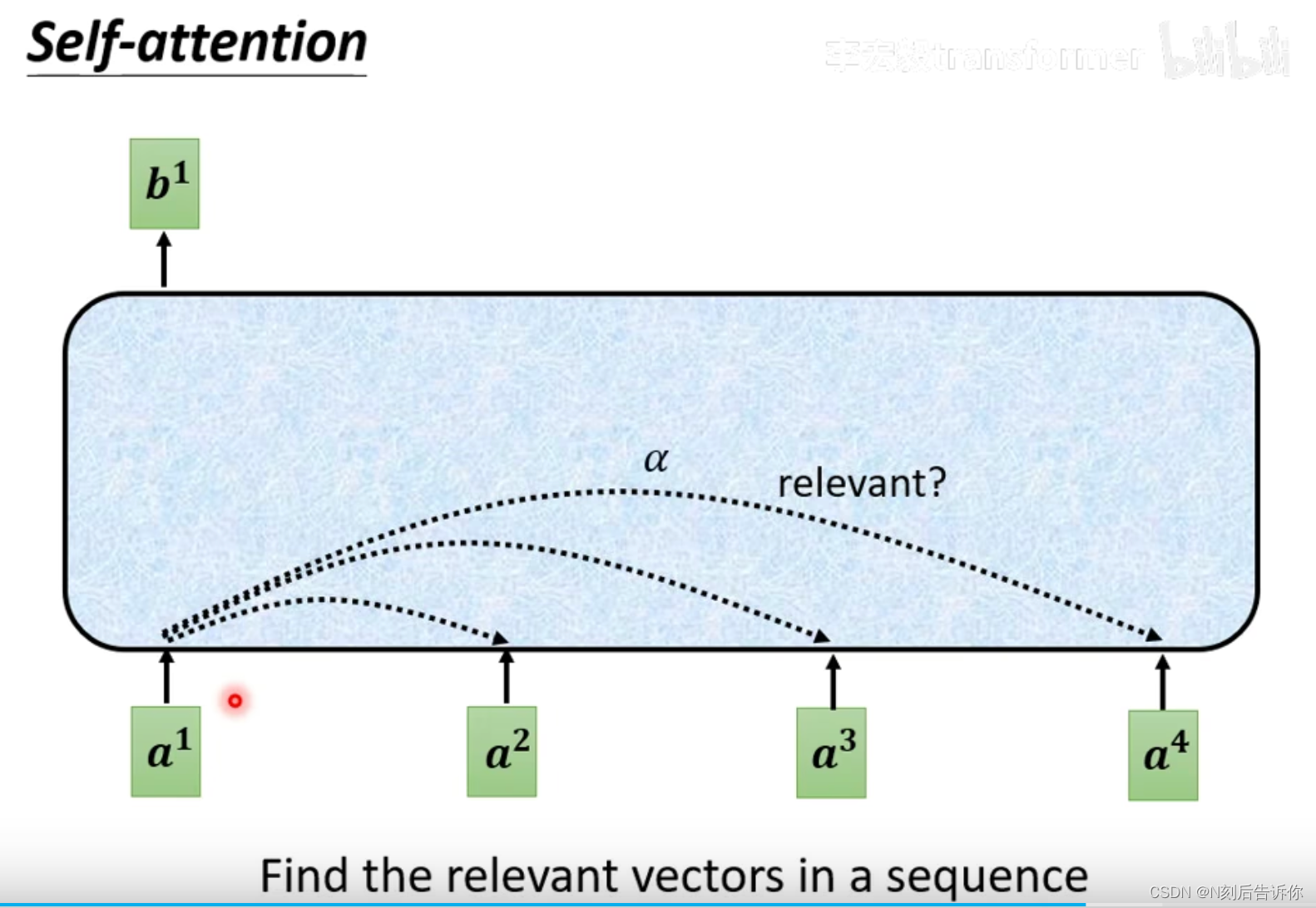
计算的方式有两种(一般采用Dot-product方法):
- Dot-product:考虑两个向量的attention score,先将这两个向量乘以权重矩阵得到向量 q q q和 k k k,再计算.
- Additive:考虑两个向量的attention score,先将这两个向量乘以权重矩阵得到向量 q q q和 k k k,再拼接起来,经过tanh和一个线性层,得到结果.
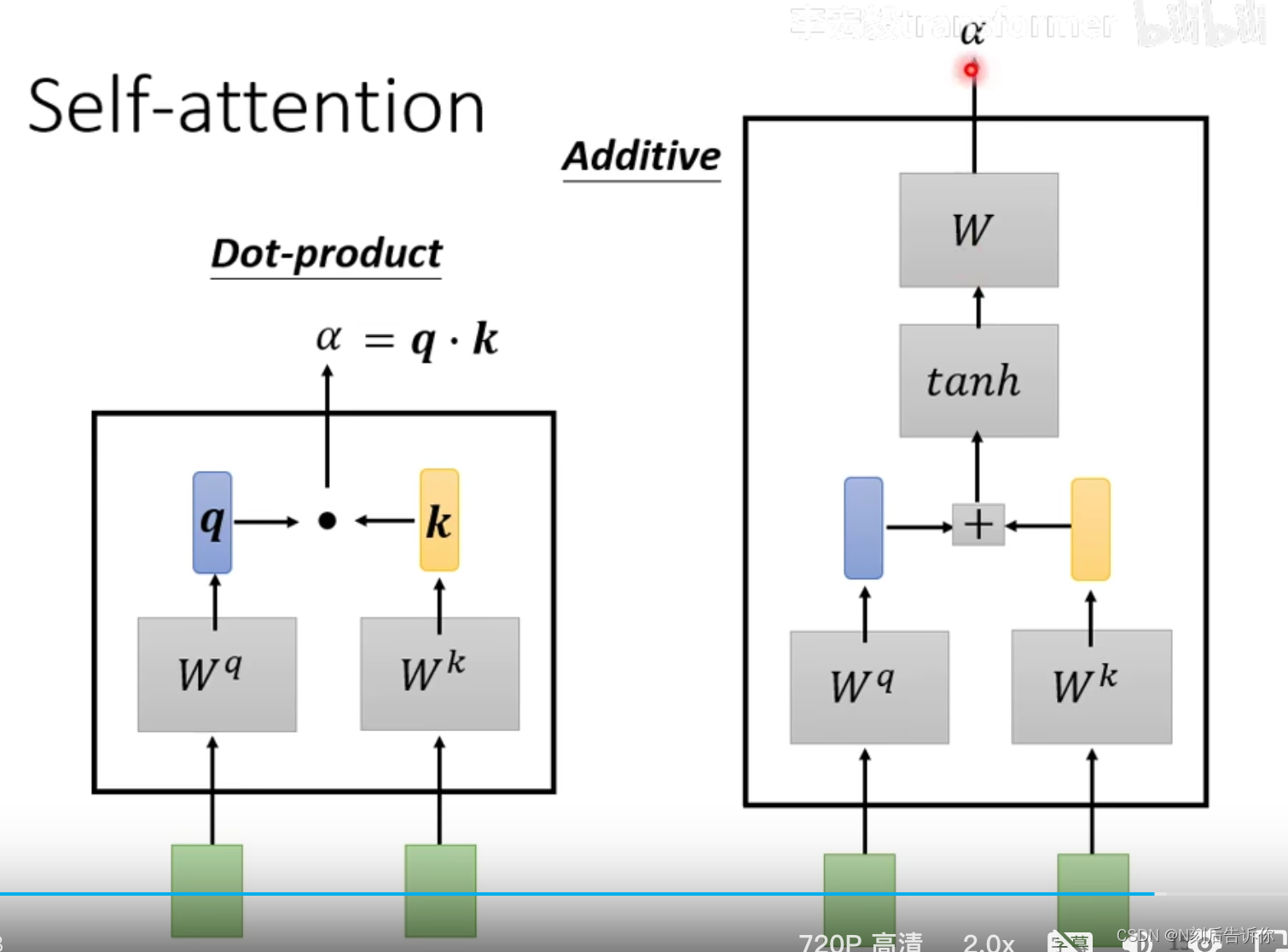
注意:计算的结果要经过softxmax进行归一化处理,才得到真正的attention score。

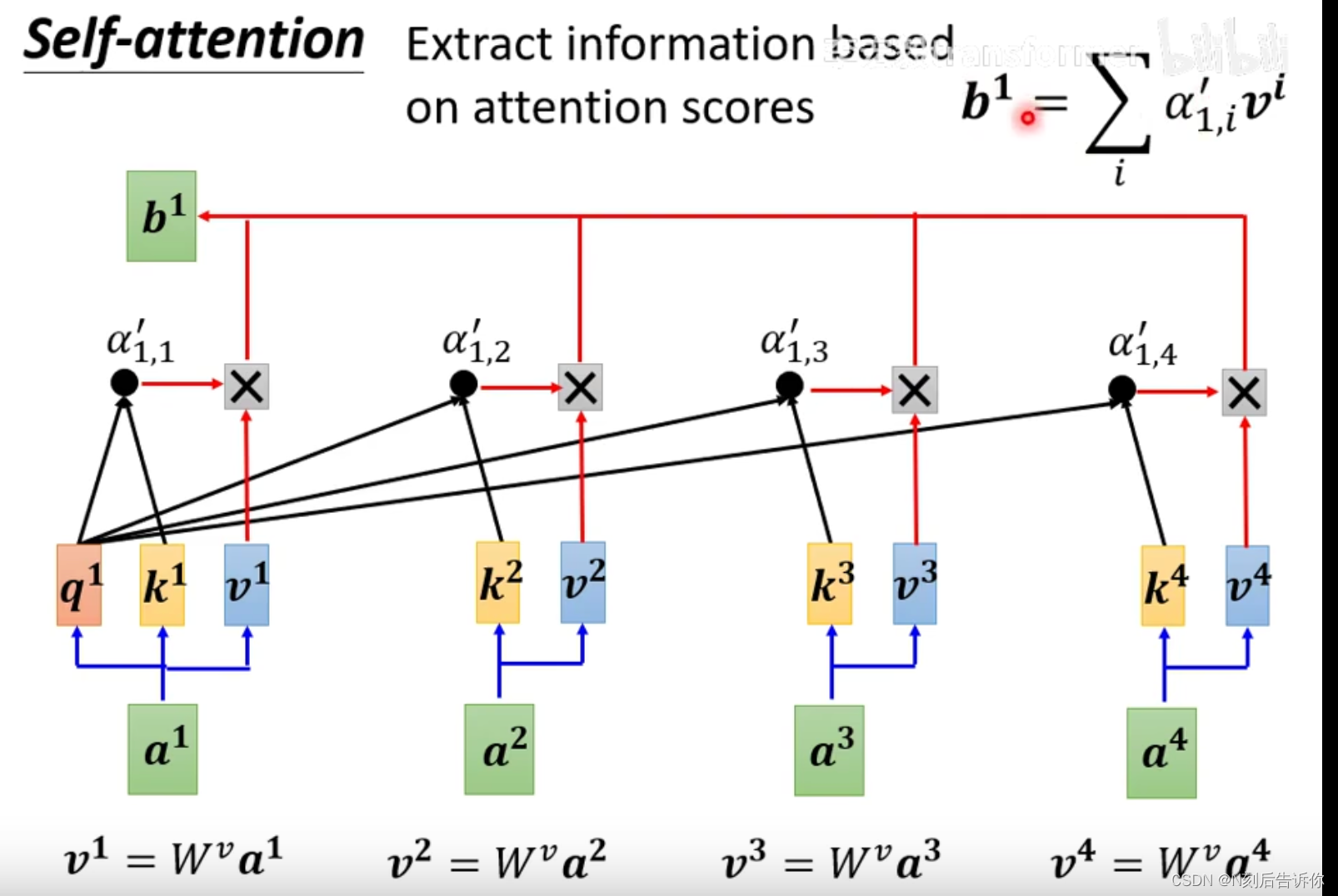
2.根据attention score,抽取对应向量的重要资讯:具体地,每个向量乘以权重矩阵,得到向量 v v v,然后 v v v都去乘以attention score并相加。
Self-attention的计算特点(可并行计算)
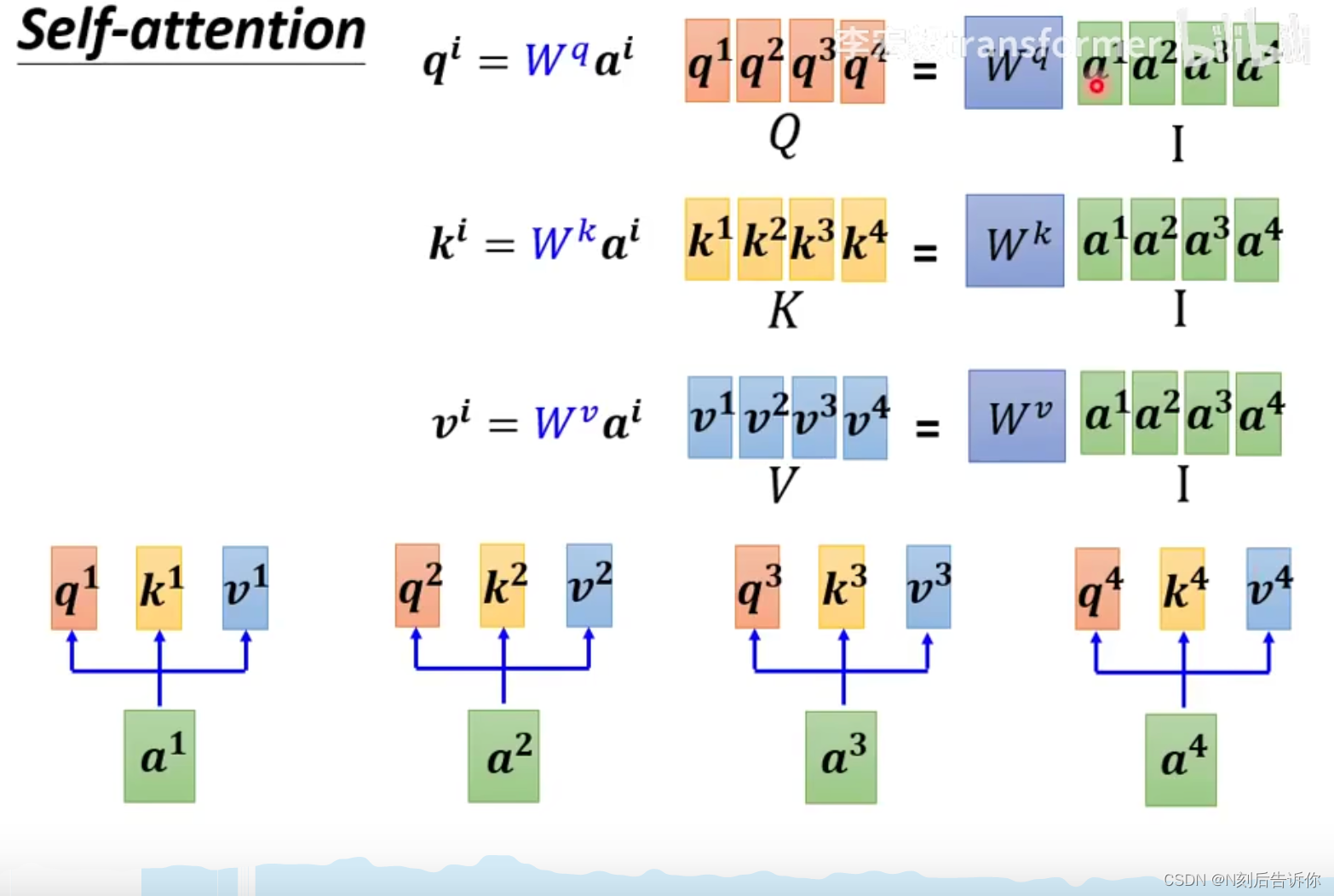
- 计算q,k,v可并行
- query向量 q q q可以同时被计算出来
- key向量 k k k可以同时被计算出来
- value向量 v v v可以同时被计算出来
2.计算attention score可并行
3.计算输出向量可并行
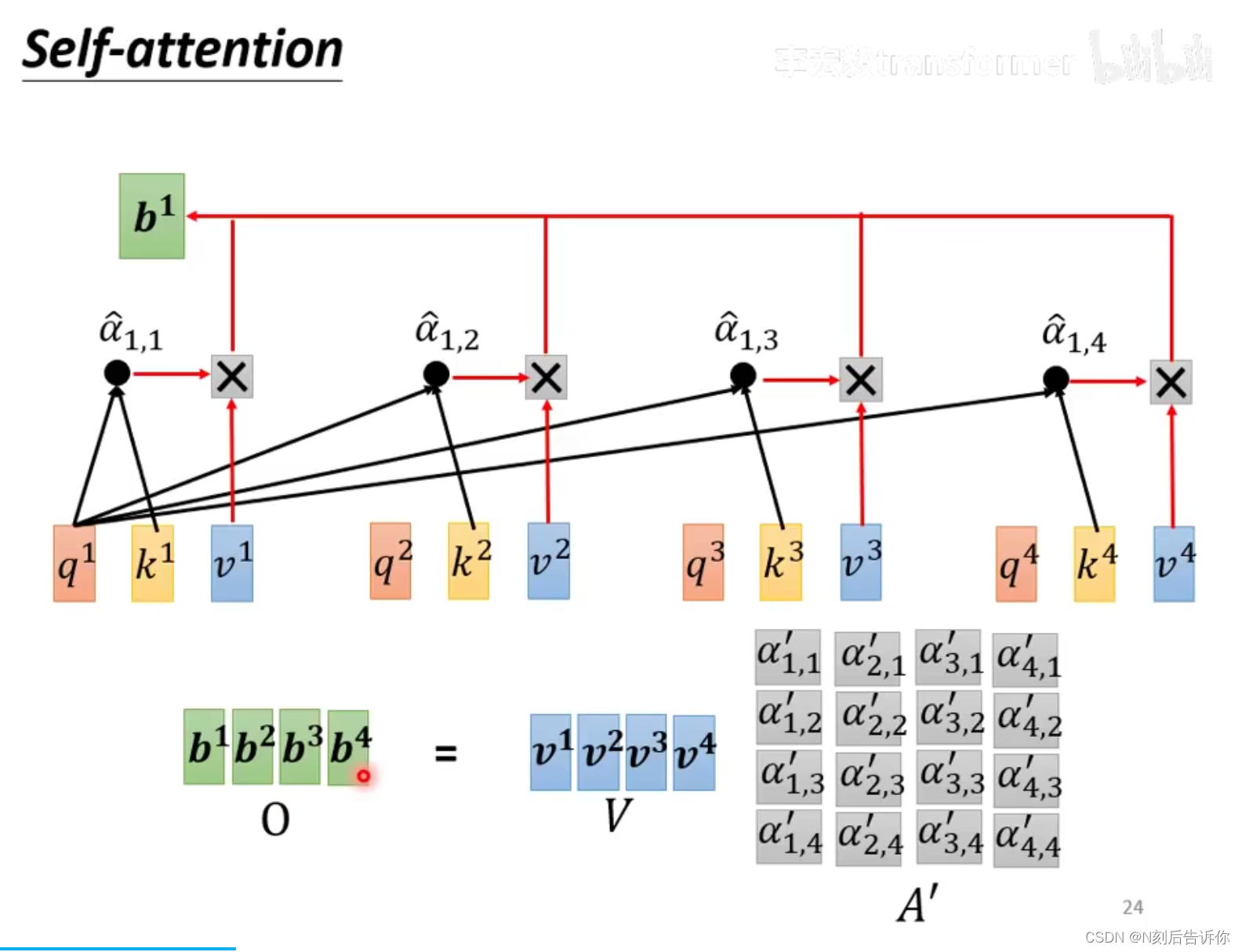
综合上面的结果: 从输入向量矩阵 I I I到输出向量矩阵 O O O,都可以并行计算。

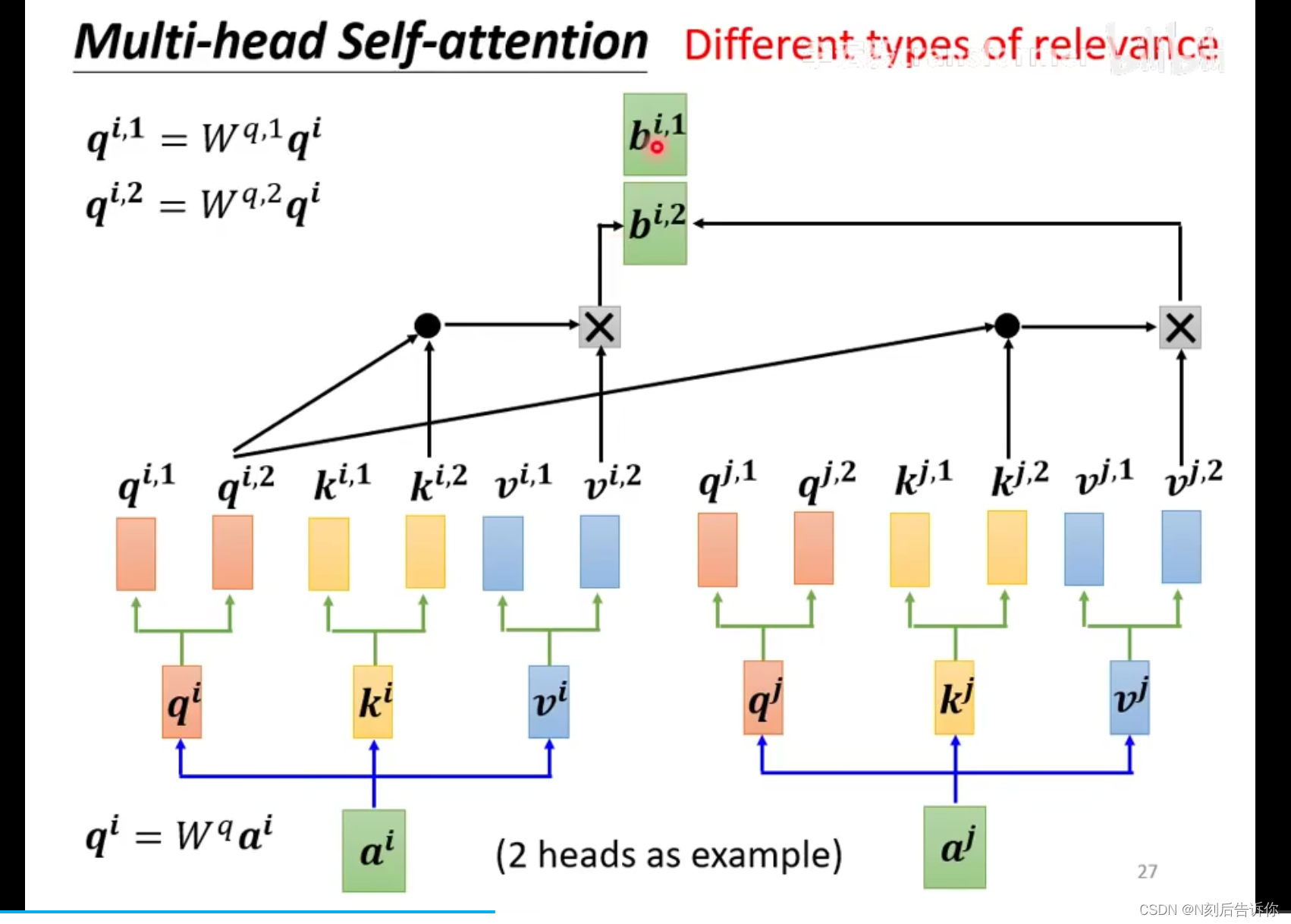
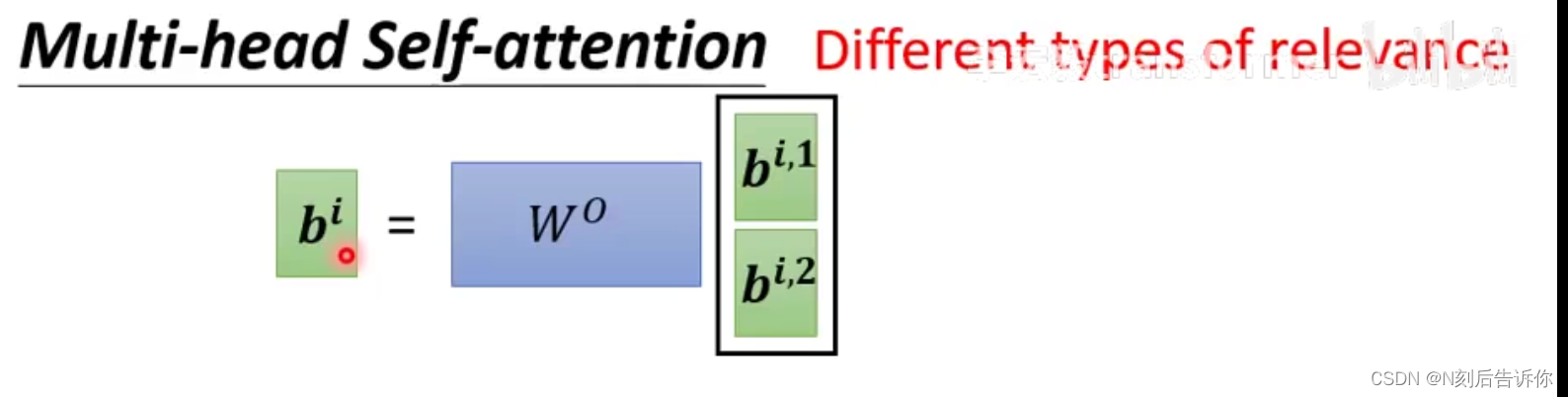
Multi-head Self-attention
可能需要不同的self-attention模块学习到不同种类的相关性,因此引入Multi-head Self-attention.
Positional Encoding
self-attention其实并没有位置的资讯。因此,考虑为每个位置单独设定一个位置向量 e i e^i ei。但是这个位置向量其实是“人为设置”的。

应用
In NLP
self-attention在NLP的应用,包括:Transformer,Bert
In Speech
由于语音往往有很长的向量序列,这会导致attention matrix很大,难以处理。
一个处理的技巧是Truncated Self-attention,即不看整个序列,而看一个范围。

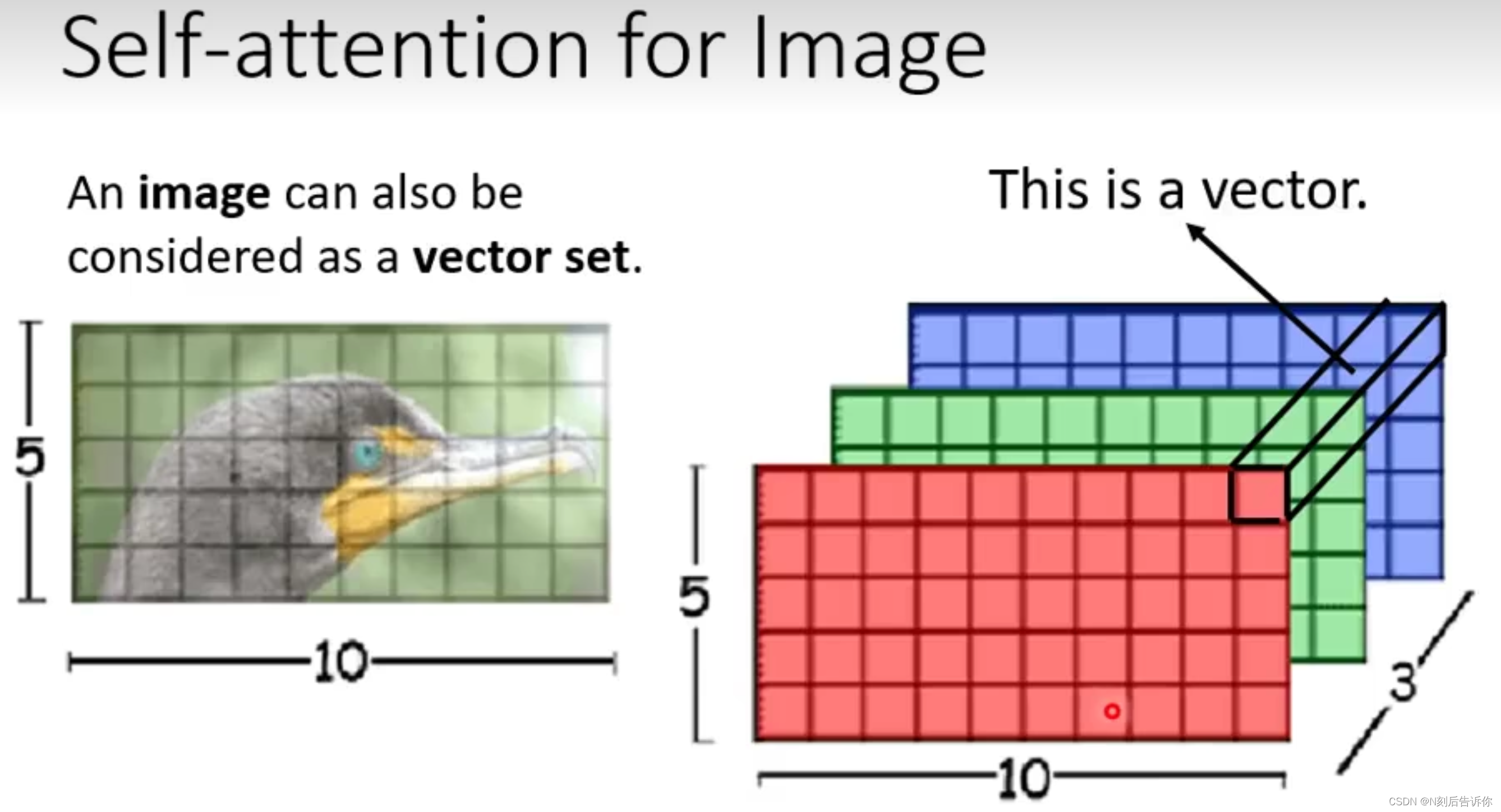
In Image
图片也可以被看成是vector set,其中的一个vector是三维向量。
self-attention vs CNN
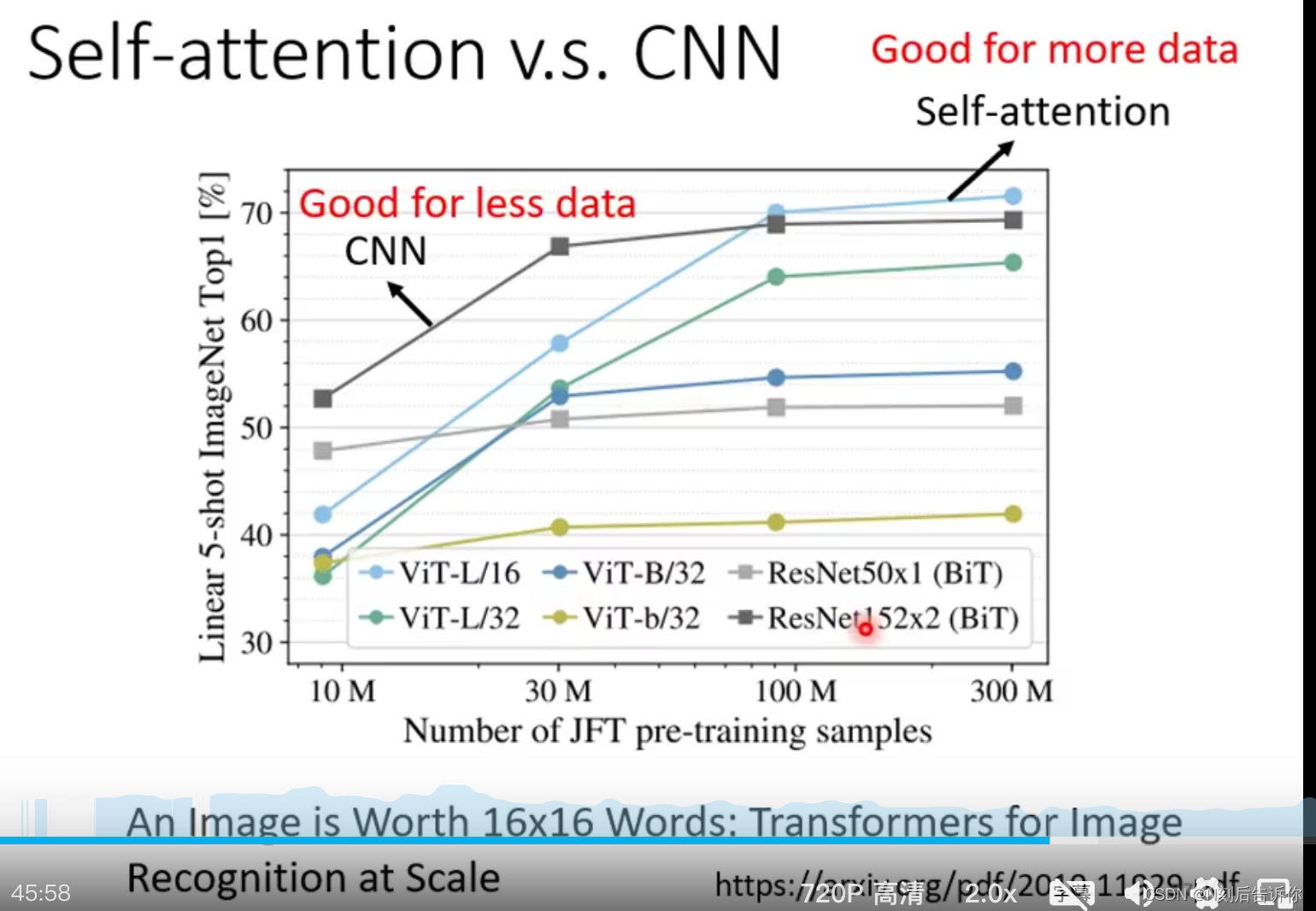
事实上,self-attention可以看成是复杂化的CNN,而CNN可以看成是简化的self-attention。self-attention的感受野是学到的,而CNN的感受野是人为定义的。

这种角度看,self-attention更加flexible,但是也意味着需要更多数据才不会overfitting。如下图,当数据量较少的时候,更不flexible的CNN的效果比较好,但随着数据量增大,更flexible的Self-attention则更好。
self-attention vs CNN
相似点:
1.输入都是vector sequence
2.都是sequence labeling,一个input向量对应有一个output向量
不同点:
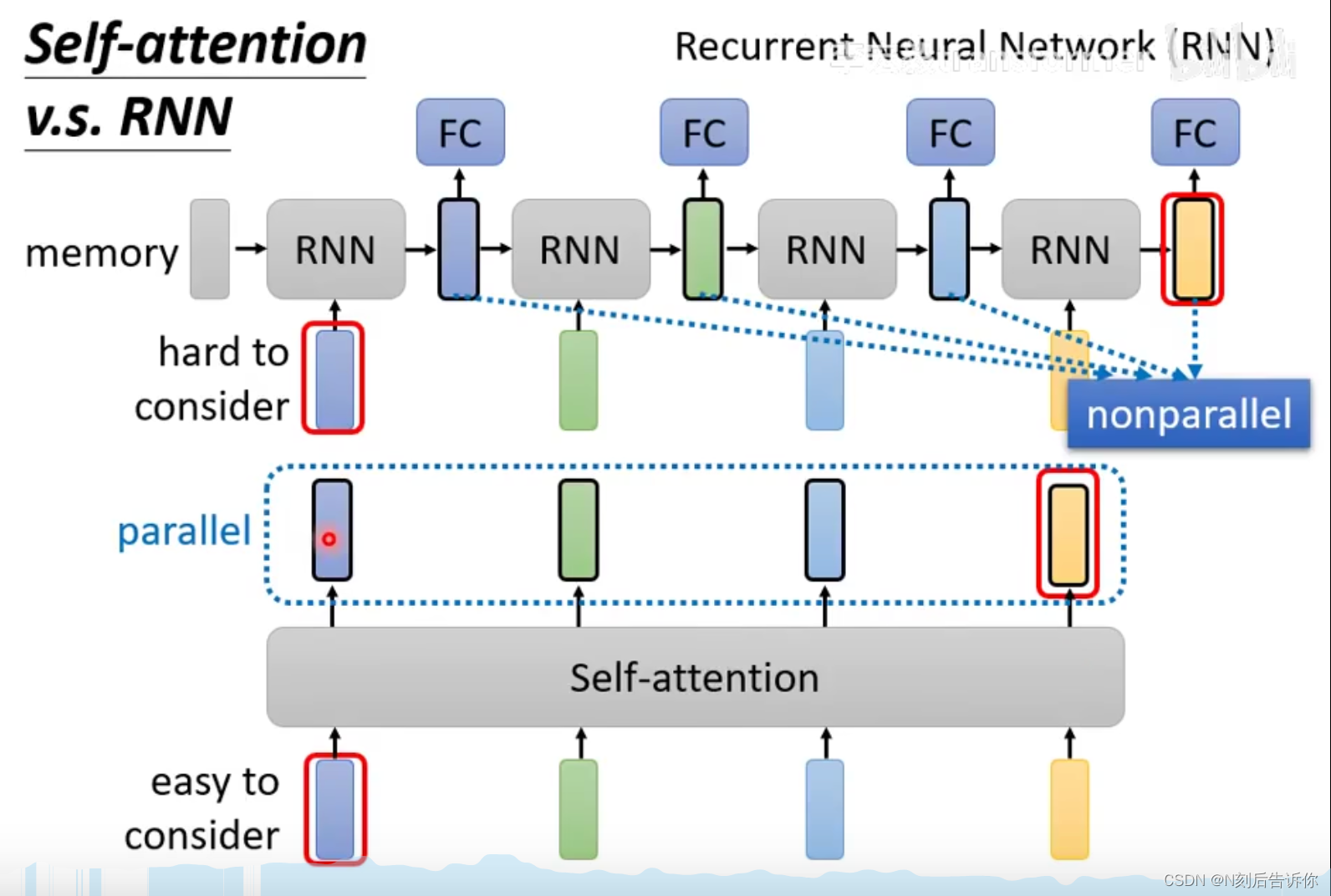
1.self-attention的输出向量考虑了整个sequence的向量,而一般RNN的输出向量只考虑了sequence左边的向量(但实际上也有双向的RNN可以考虑双边的向量)。
2.RNN最右边的hidden vector很难回忆起最左边的输入向量的信息(因为这要求该信息一层层保存而不丢失),而self-attention则容易的多。
3.RNN是不可并行的,而self-attention是可并行的。
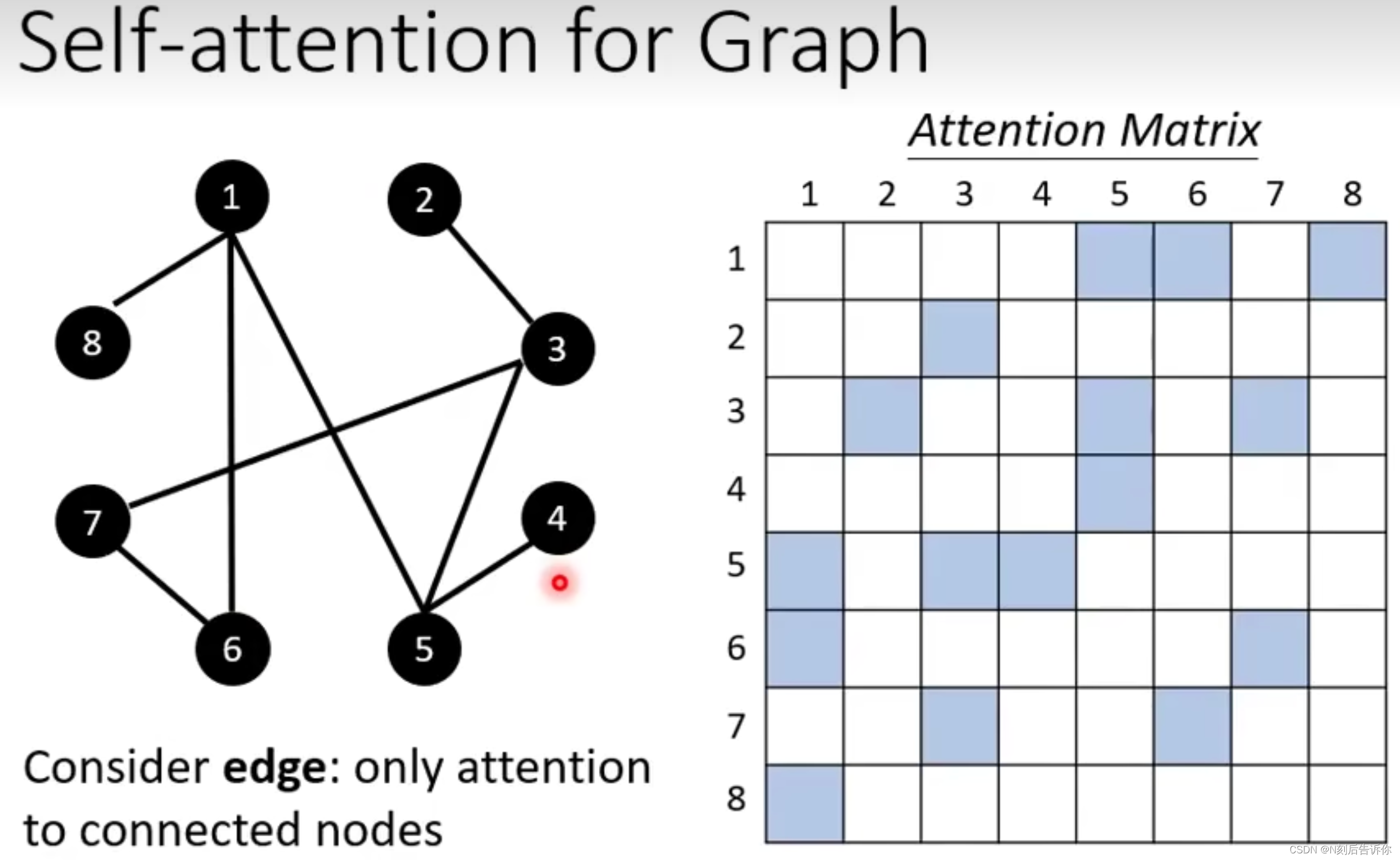
In Graph
因为图已经有了边,所以不需要计算没有边的attention score。
Transformer
Transformer是为了解决seq2seq的问题。
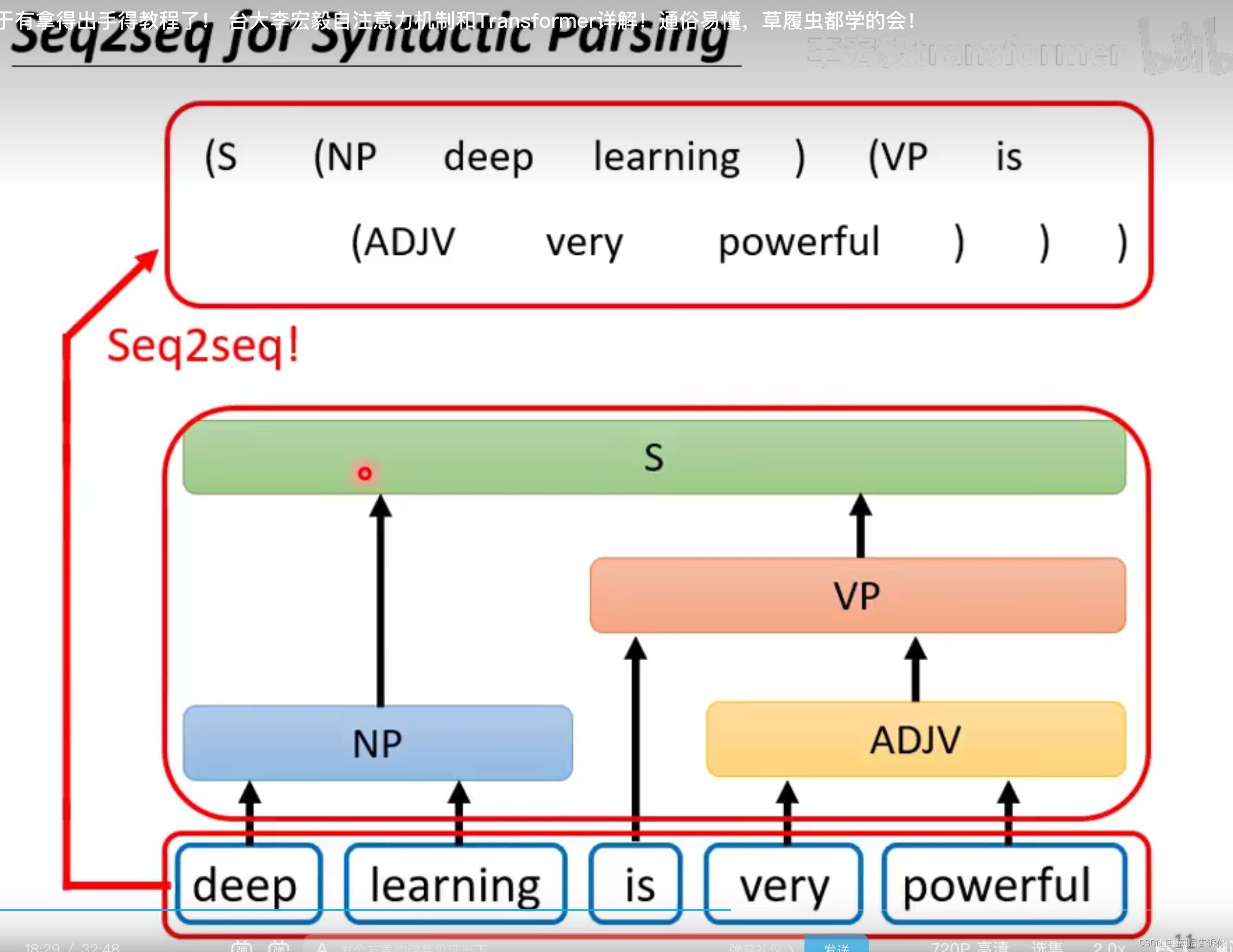
具体的例子有:语音辨识;语音合成;聊天机器人;QA问题(很多NLP任务都可以看成是QA);文法剖析(如下下图,目标是根据一个句子,写出他的文法树);Multi-label classficitaion(一个样本对应多个label);目标检测等。

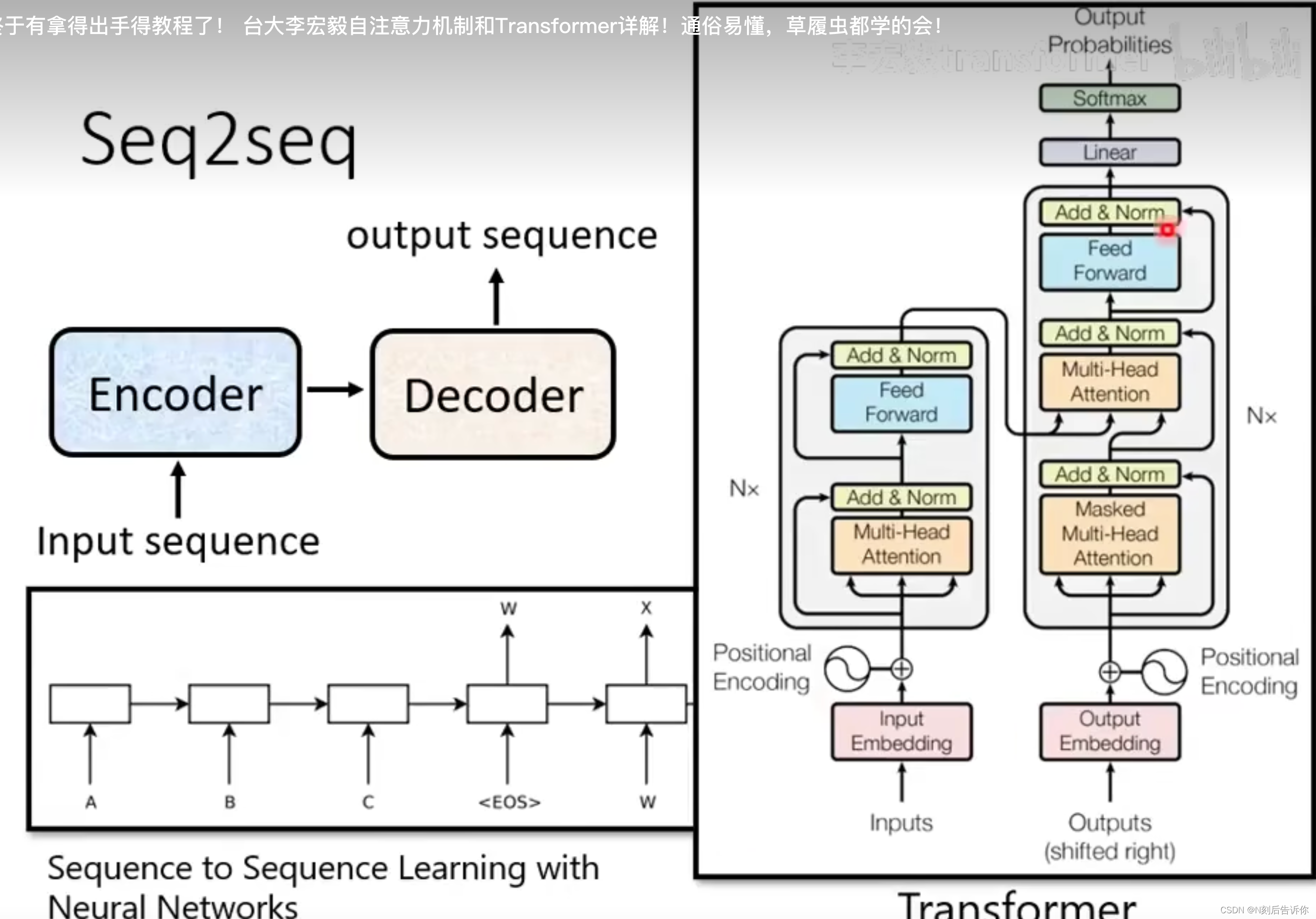
接下来介绍seq2seq模型,它一般包含两个部分,encoder和decoder。
encoder负责处理sequence,decoder负责决定要输出什么样的sequence。
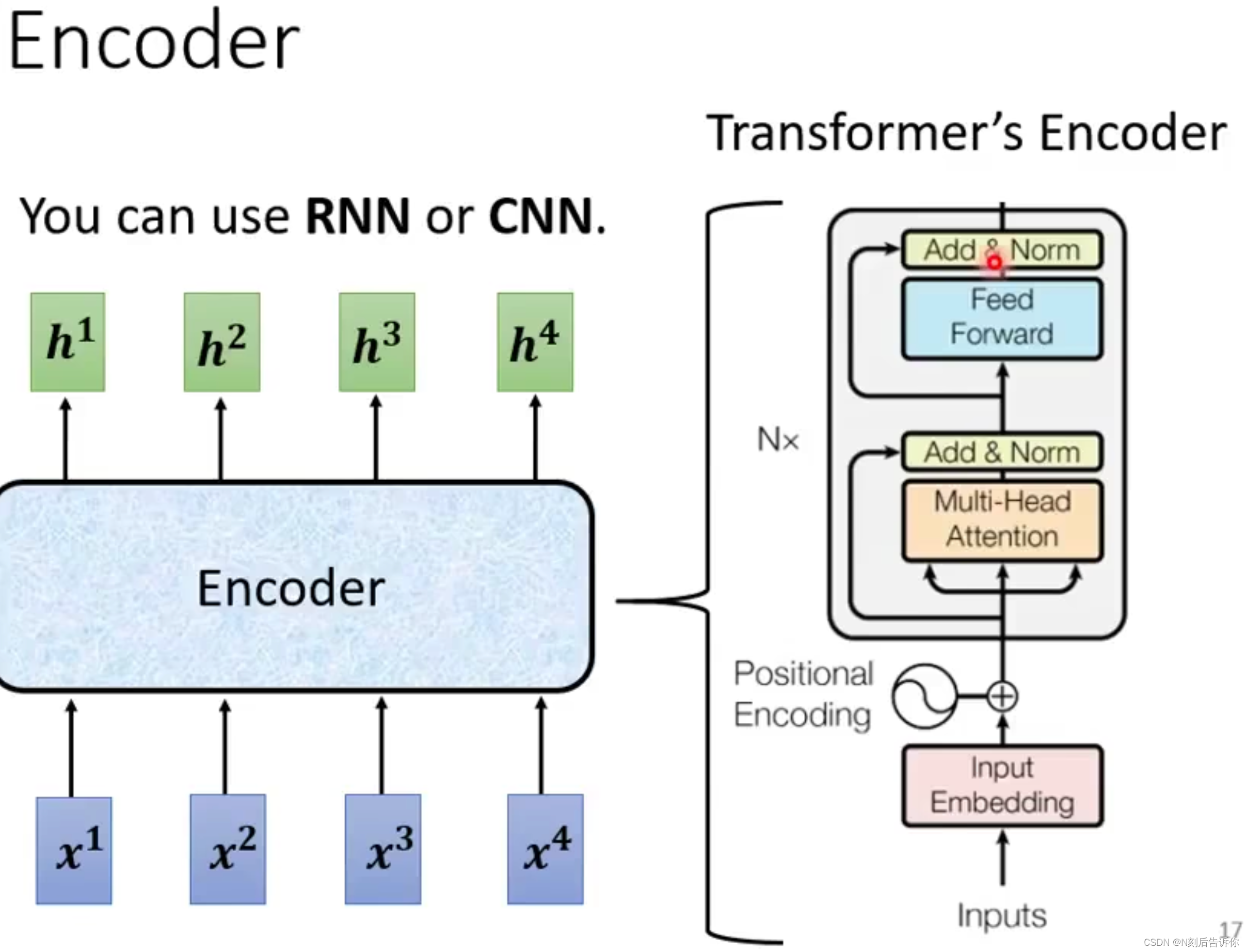
Encoder
Encoder的目标是输入一排向量,输出一排向量。其实RNN和CNN也可以做。但是Transformer里是采用Self-attention实现的。
解析每个Encoder-block
1.输入向量经过self-attention(Multi-head self attention)的输出向量和residual向量(输入向量)相加得到向量。
注意:最初的输入向量有包含Positional Encoding向量。
2.进行Layer Normalizaiton。
注意:Layer Normalizaiton不同于Batch Normalization,前者会求一个向量不同维度的均值和标准差,进行归一化。后者是求同一个维度不同向量的均值和标准差,进行归一化。
3.2中的向量经过全连接层的输出向量和residual向量(2中的向量)相加得到向量。
4.进行Layer Normalization。

补充说明:事实上,有研究表明:
1.不在输出之后做Layer Normalization,而是在进行网络计算前进行Layer Normalization,效果会更好。
2.Batch Normalization不如Layer Normalization。

Decoder
AutoRegressive(AT)
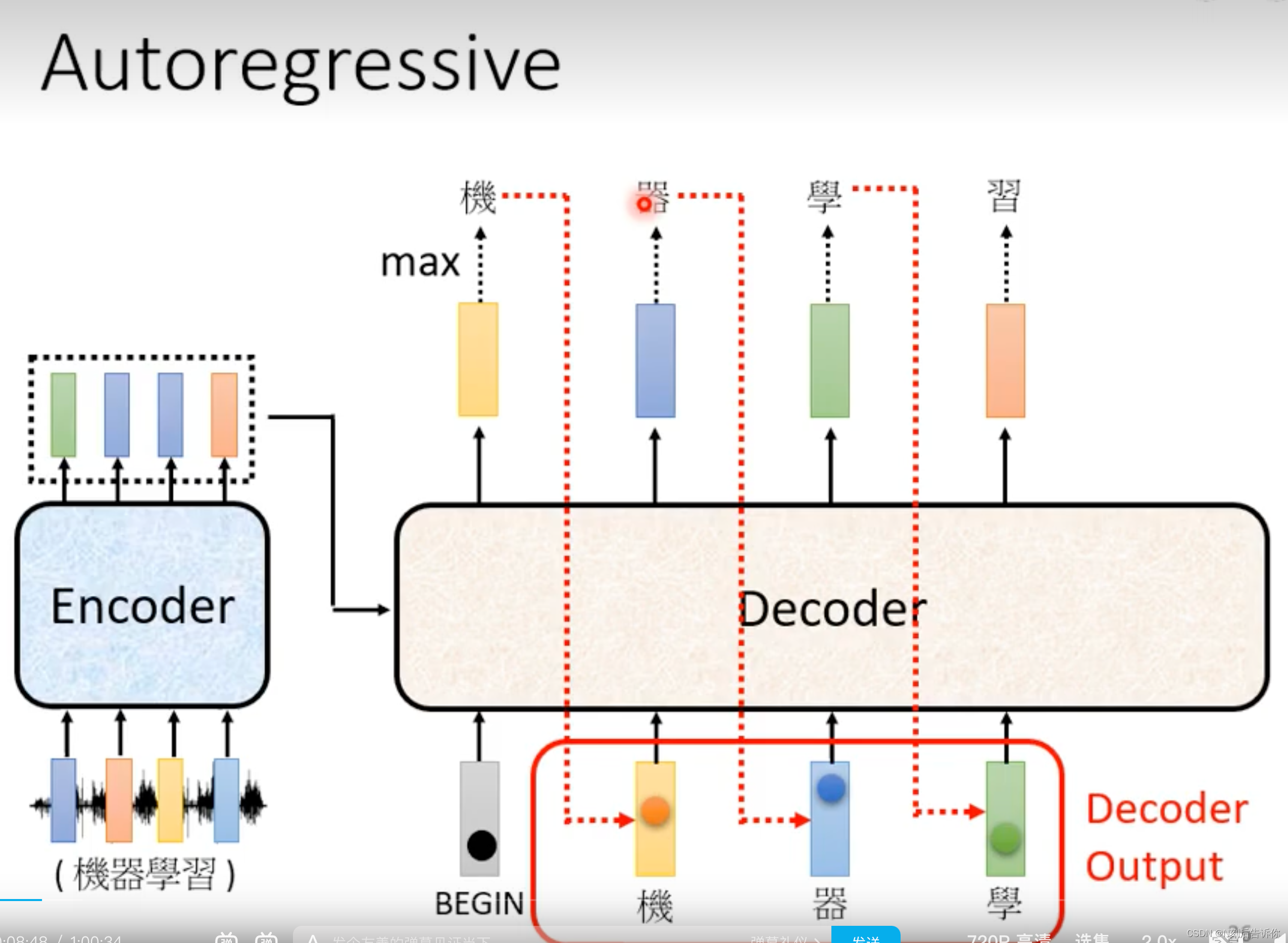
Masked Self-attention
所谓的masked self-attention,就是求当前向量关于其他向量的attention score,只能考虑在它前面的向量,不能考虑之后的向量。
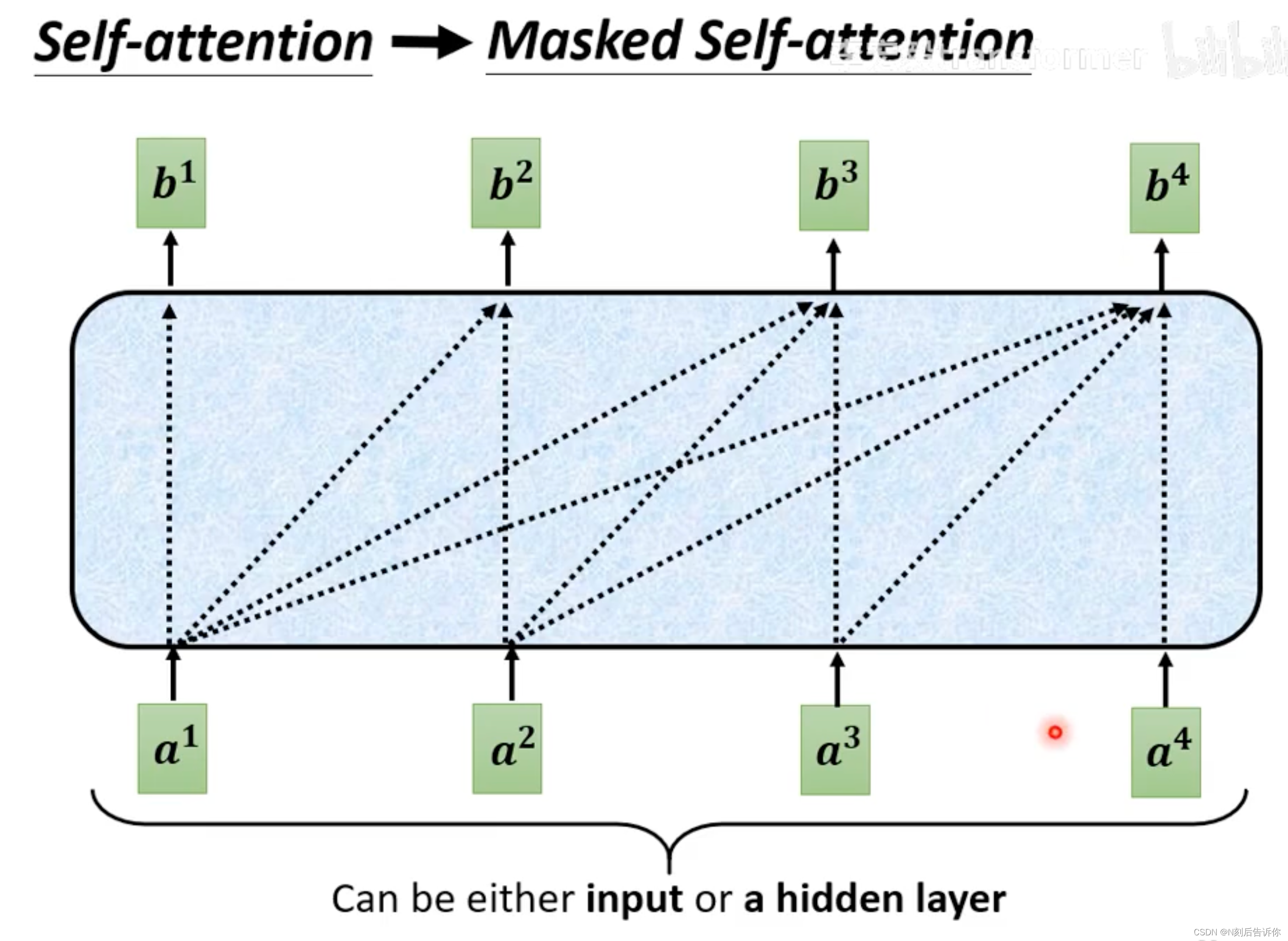
以计算b2为例。

Decoder输出END

Non-autoRegressive(NAT)
NAT的decoder是将一整排begin的token作为输入,同时生成输出。
如何知道输出的长度
1.另外学一个模型,预测输出的长度
2.给一个输出长度的上限,当生成的输出有end,就将end后面的内容截断。
NAT的decoder的优点是并行,可控长度(在语音合成里面,输出长度减半,可以让语音速度变快)。
NAT的缺点是表现往往不如AT的decoder。
Encoder和Decoder之间如何传递资讯-Cross attention

Encoder会传过来K和V矩阵,而Decoder这边,经过masked multi-head attention,会传入Q矩阵。这个Q,K,V矩阵会进行multi-head-attention过程(也称为cross attetnion)。
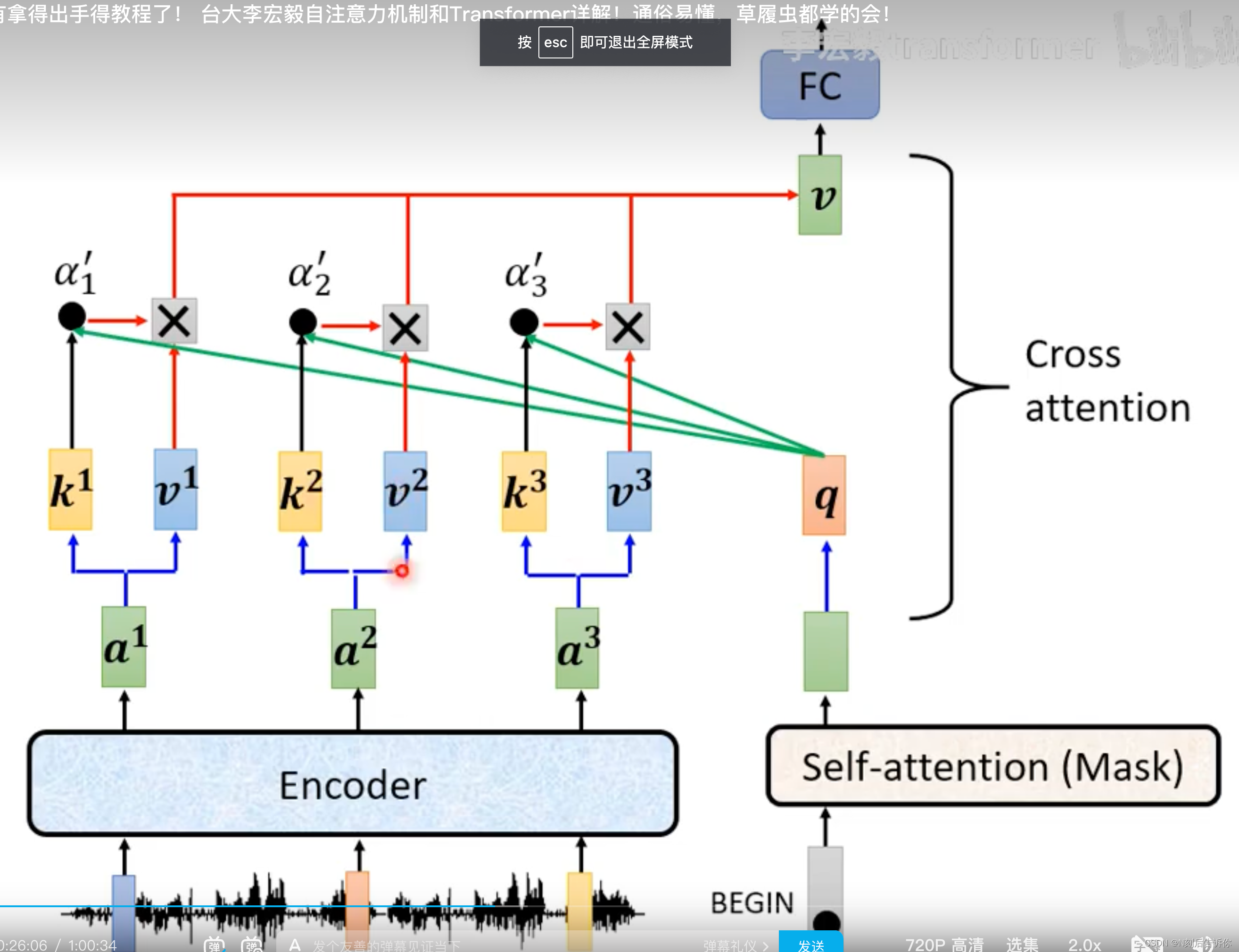
PS:在Transformer原始论文中,Decoder的每一层Cross-attention都是拿Encoder最后一层的输出作为K和V。但是不一定需要这样,也有研究者在研究其他连接方式。
Training
以上讲的是推理过程。下面讲如何训练。(仍以语音识别为例)
1.构建数据集。声音讯号-对应标签。
2.Cross-entropy作为loss function。
注意:训练时,decoder的输入是ground truth,也就是会给decoder看正确答案。这种使用ground truth作为输入的技术被称为Teacher Forcing。
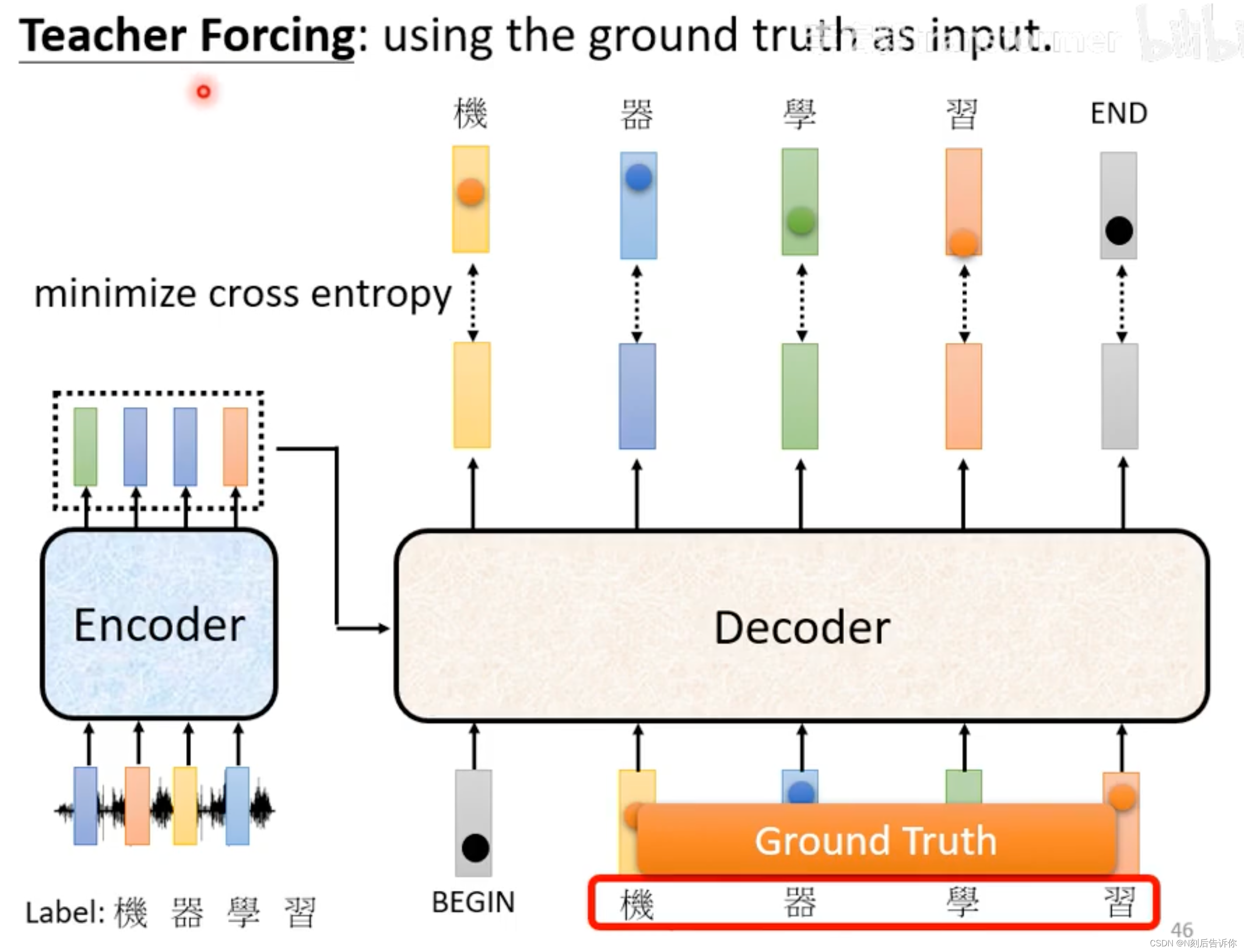
训练seq2seq模型(Transformer)的技巧
Copy mechanism
有些句子其实是需要复制出来。比如复制名称,简写摘要。解决方案详见:

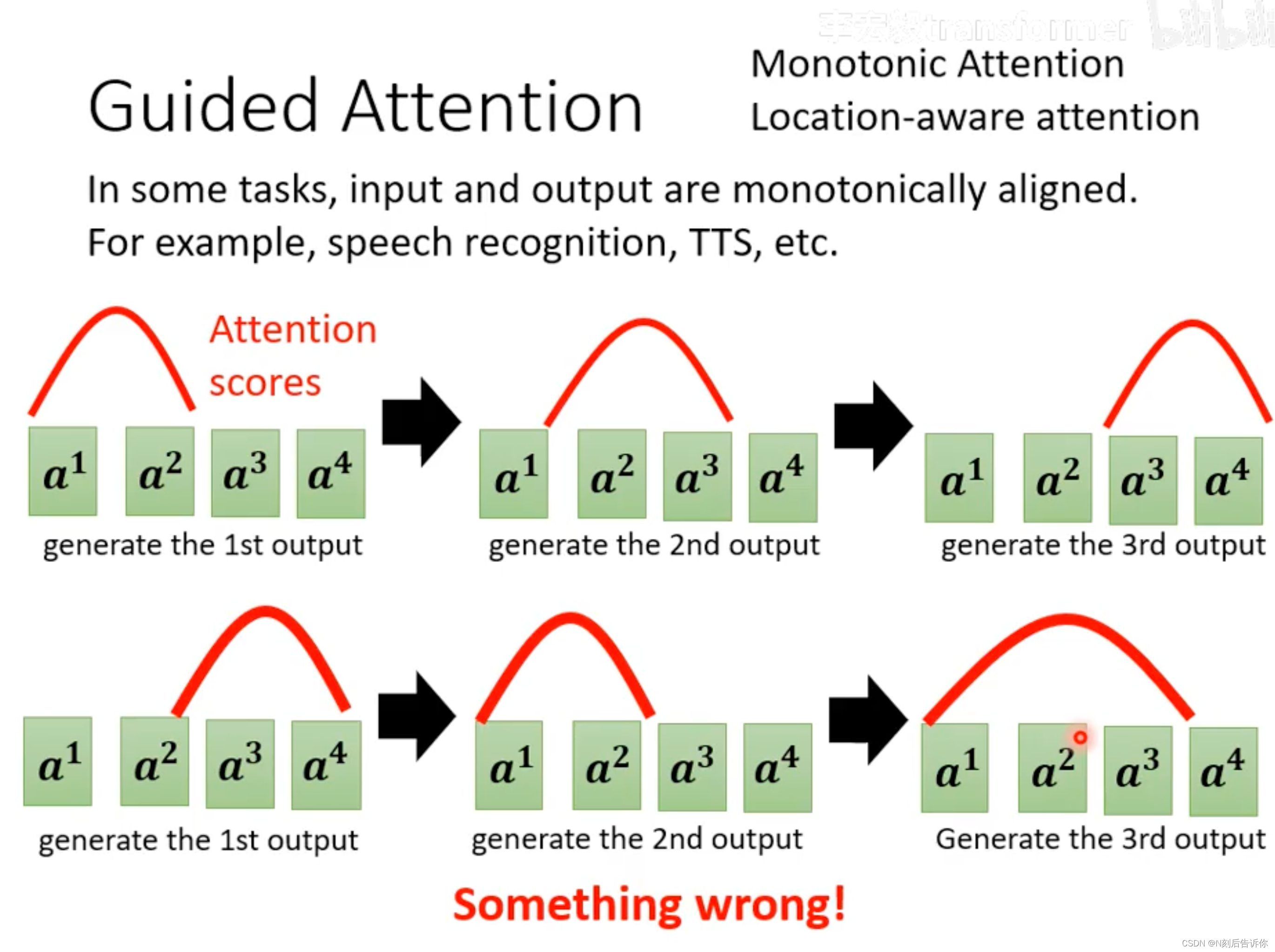
Guided Attention
机器可能会漏掉一些讯息。在一些任务中,漏掉讯息是不可接受的,比如语音辨识,语音合成。解决方案:
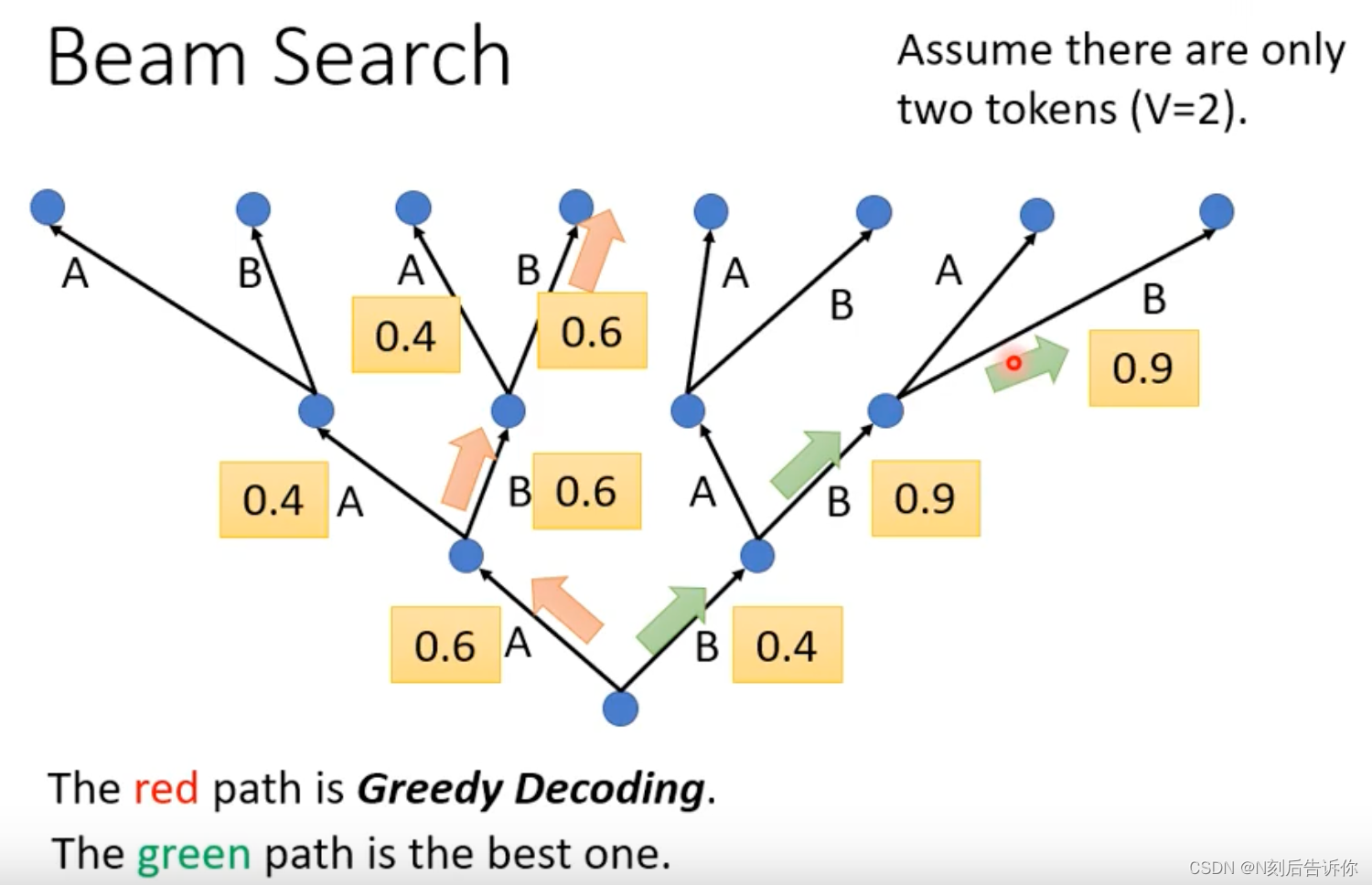
Beam search
每次decoder都是贪心选择,但这不一定能保证全局最优。beam search方法可以获得一定程度上的更全局的优解。
注意:在一些创造性的任务中,比如语音合成,写文章,那么不适合用beam search找分数最高的路,而需要引入一些随机性。在答案明确的任务,比如语音辨识中,beam search则比较适合。
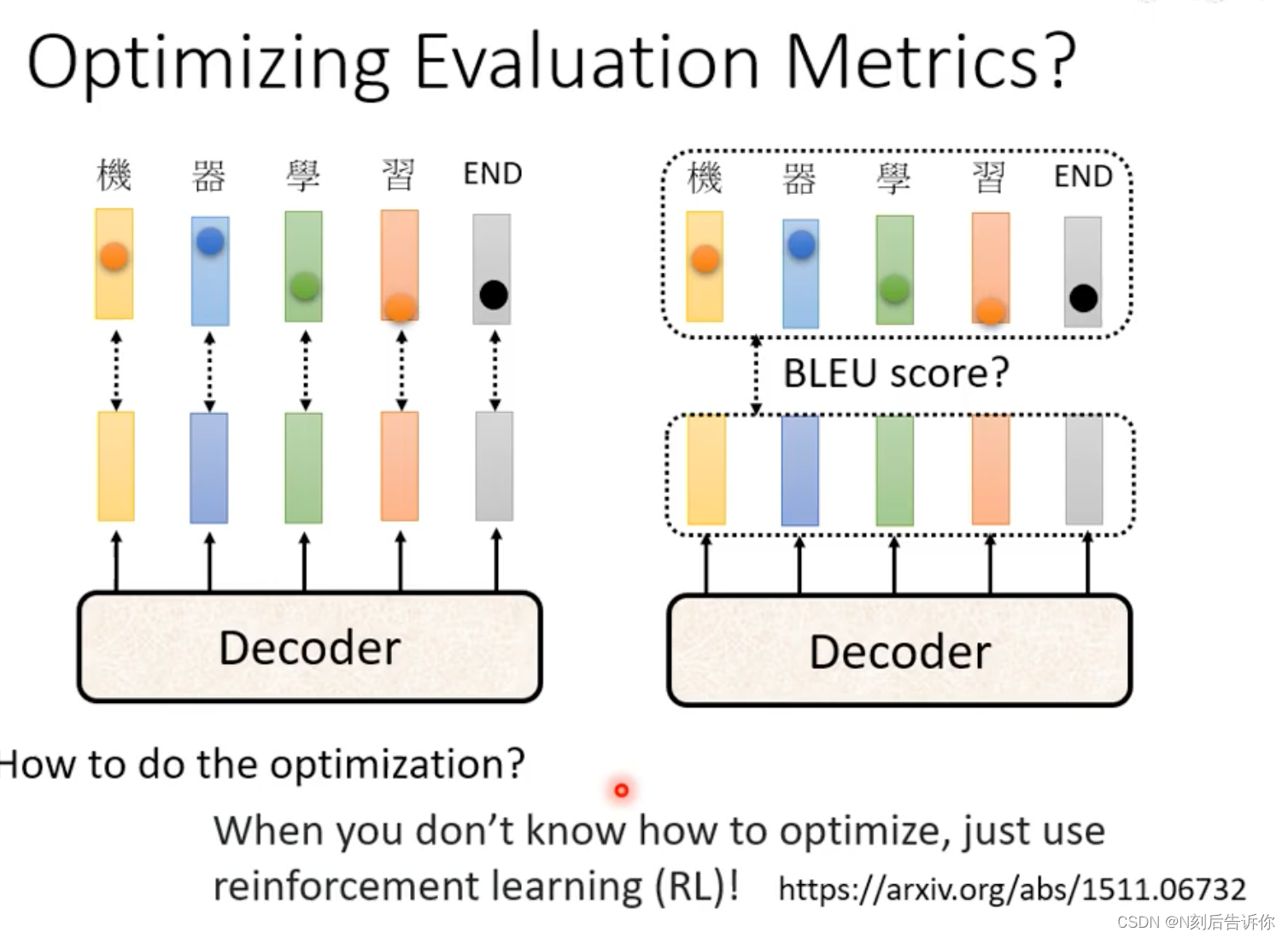
评价模型的指标-BLEU score
decoder产生完整句子后,再和正确答案去比较,得到BLUE score。
训练的时候,最小化cross entropy。
评价,模型选择的时候,是看BLUE score的。
训练的时候看BLUE score,很难训练,因为不容易算梯度。(当然也可以用RL的技术强行训练)。
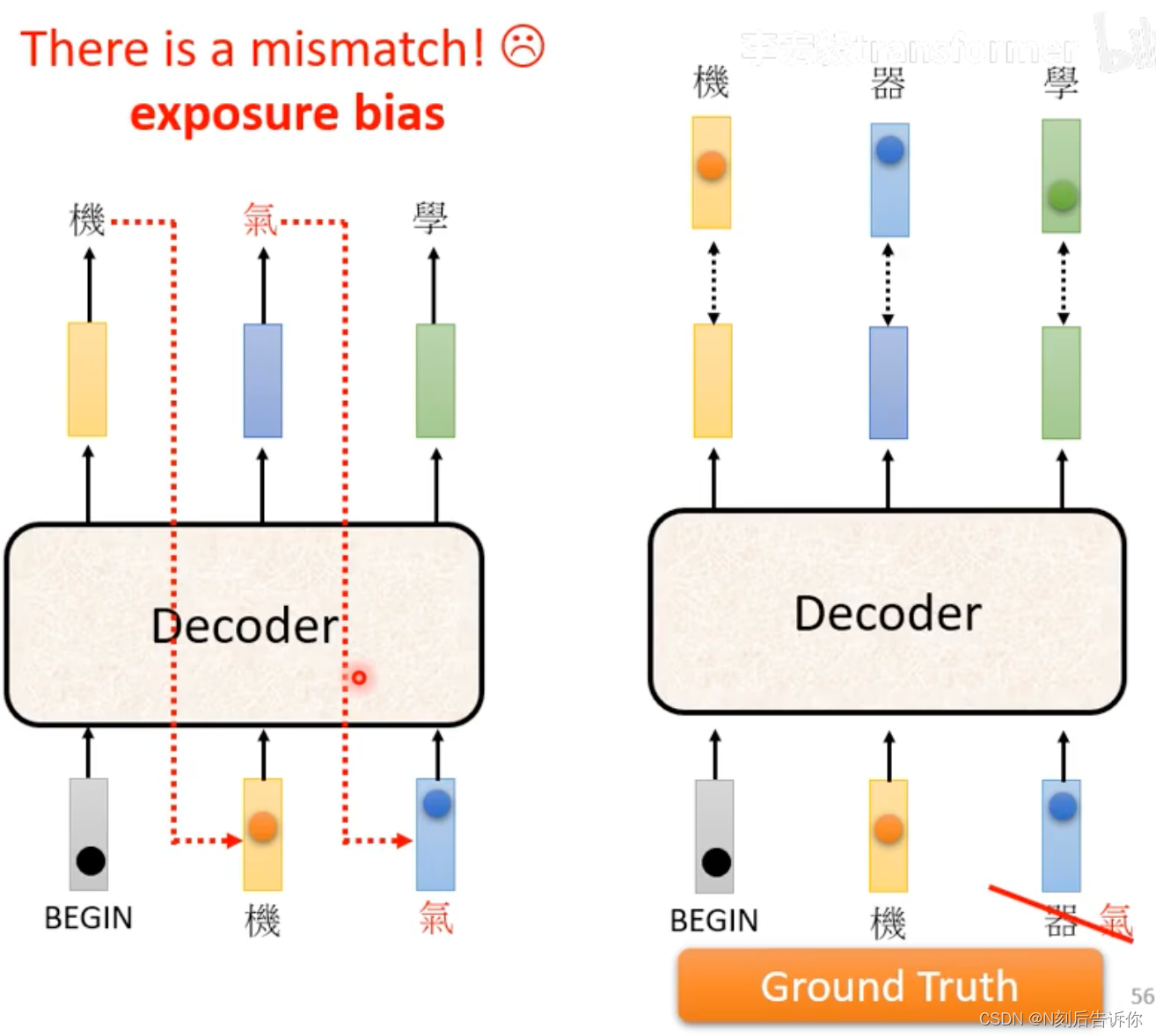
exposure bias
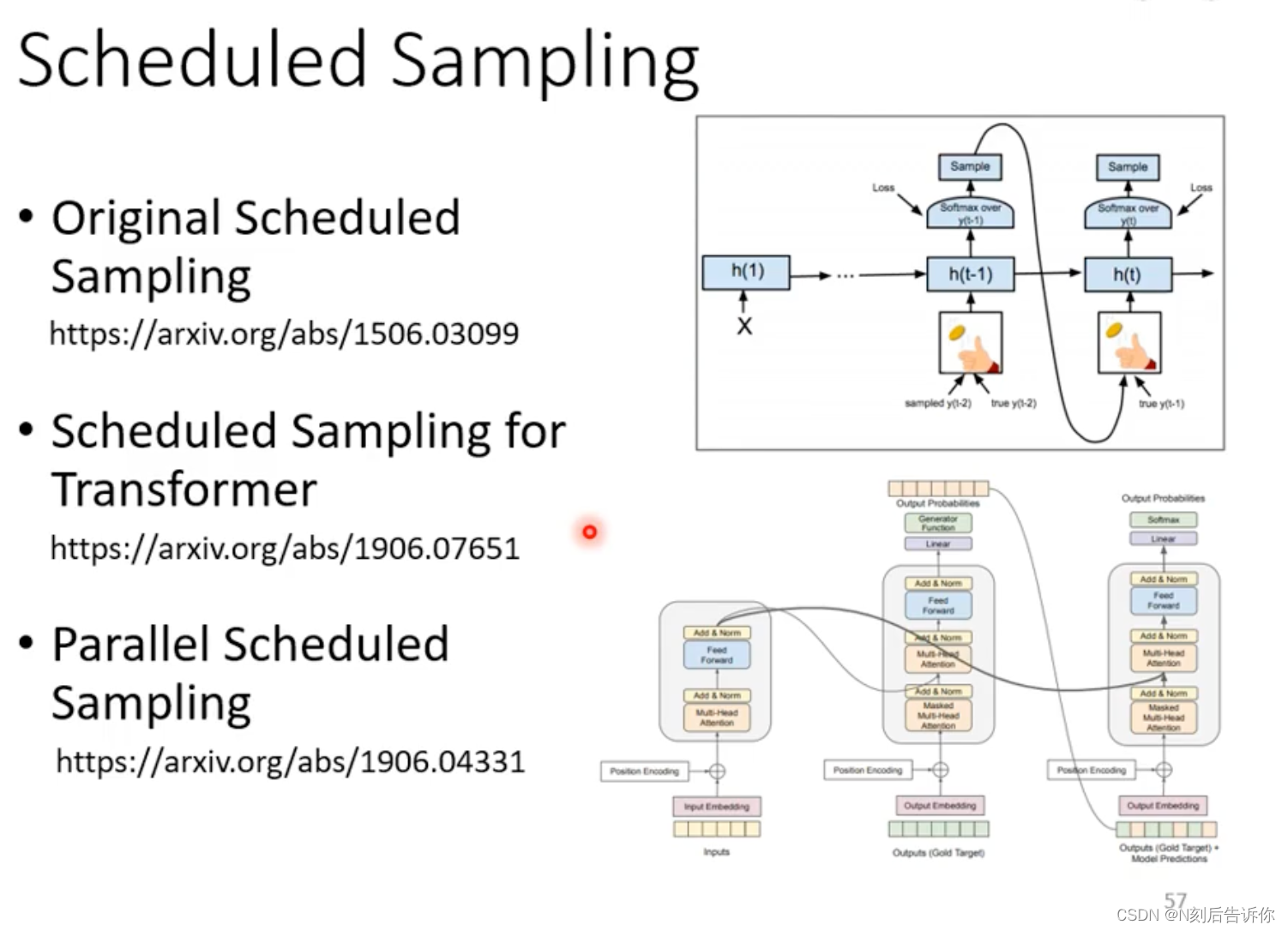
在训练时,decoder的输入是ground truth,在推理时,decoder的输入可能不是正确的。这中间存在mismatch,称为exposure bias。这可能导致模型推理效果不理想。一种解决办法实际上是在训练的时候,输入并不完全用ground truth,这一定程度上在训练时,引入了随机性,这一种方法被称为Scheduled Sampling。
关于Scheduled Sampling技术可以详细看下面的文章。