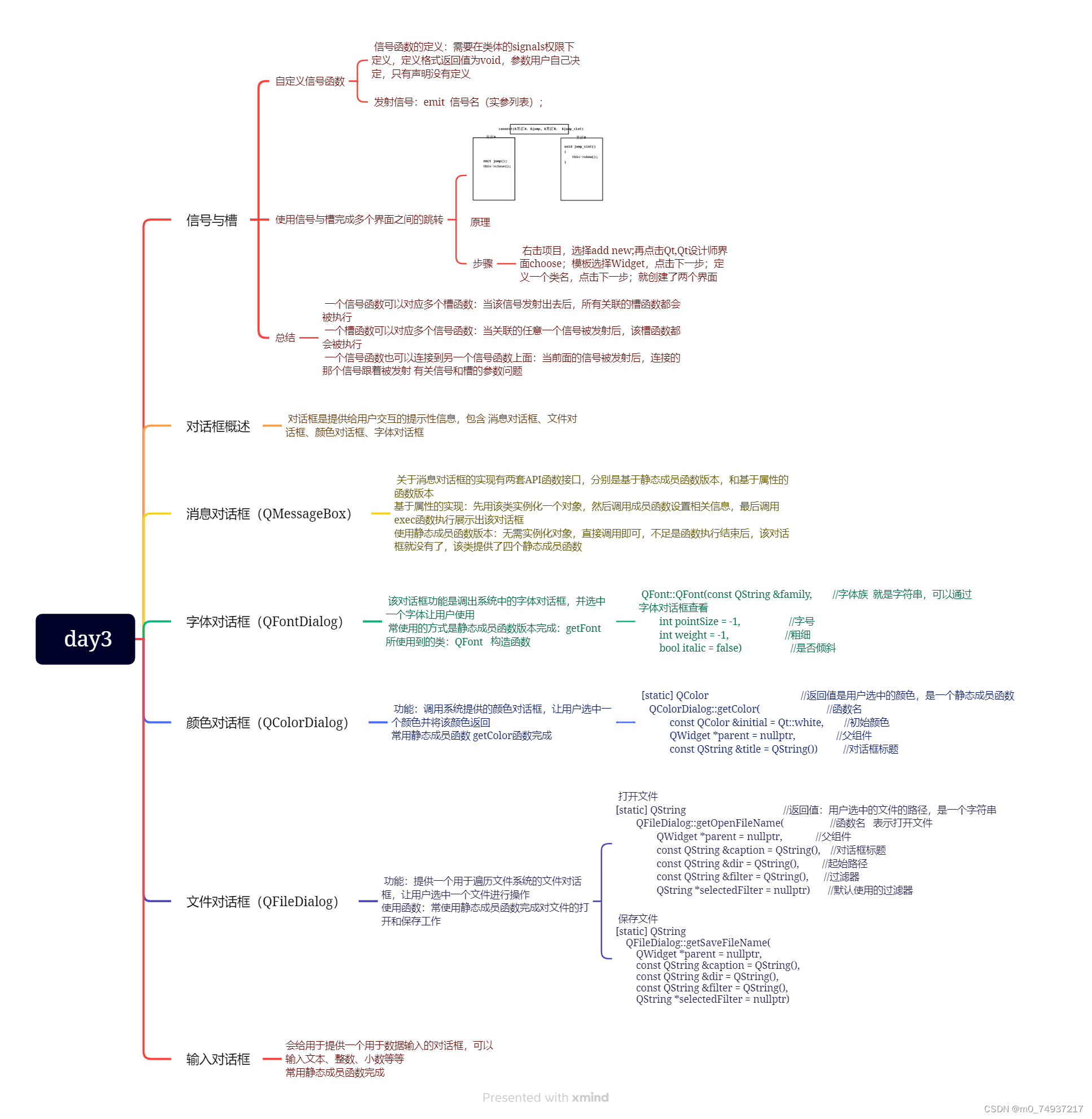
介绍
Flink的Data Source(数据源、源算子)是Flink作业的起点,它定义了数据输入的来源。Flink可以从各种数据来源获取数据,例如文件系统、消息队列、数据库等。以下是对Flink Data Source的详细介绍:
概述:
- Flink中的Data Source用于定义数据输入的来源。
- 将数据源添加到Flink执行环境中,可以创建一个数据流。
- Flink支持多种类型的数据源,包括内置数据源和自定义数据源。
内置数据源:
- 基于集合构建:使用Flink的API(如fromCollection、fromElements等)将Java或Scala中的集合数据转化为数据流进行处理。
- 基于文件构建:从文件系统中读取数据,支持多种文件格式,如CSV、JSON等。
- 基于Socket构建:从Socket连接中读取数据,适用于实时流数据场景。
自定义数据源:
- Flink允许用户通过实现SourceFunction接口或扩展RichParallelSourceFunction来自定义数据源。
- 常见的自定义数据源包括从第三方系统连接器(如Kafka、RabbitMQ、MongoDB等)中读取数据。
添加数据源到Flink执行环境:
- 使用StreamExecutionEnvironment.addSource(sourceFunction)方法将数据源添加到Flink执行环境中。
- sourceFunction需要实现SourceFunction接口或扩展RichParallelSourceFunction。
数据流处理:
- 一旦数据源被添加到Flink执行环境中,就可以创建一个数据流(DataStream)。
- 接下来,可以使用Flink的各种算子(如map、filter、reduce等)对数据流进行转换处理。
输出结果:
- 处理后的数据可以写入其他系统,如文件系统、数据库、消息队列等。
- Flink支持多种输出方式,如使用DataStream的writeAsText、writeAsCsv等方法将数据写入文件,或使用Flink的连接器将数据写入Kafka、HBase等系统。
总之,Flink的Data Source是构建Flink数据流处理应用的重要组成部分。通过选择合适的数据源和输出方式,可以方便地构建高效、可靠的数据流处理应用。
样例
程序中添加数据源
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.addSource(new SourceMySQL()).print();env.execute("Flink add mysql sourc");
Flink 已经提供了若干实现好了的SourceFunctions也可以通过实现 SourceFunction 来自定义非并行的 source 或者实现 ParallelSourceFunction 接口或者扩展 RichParallelSourceFunction 来自定义并行的 source,
stream sources
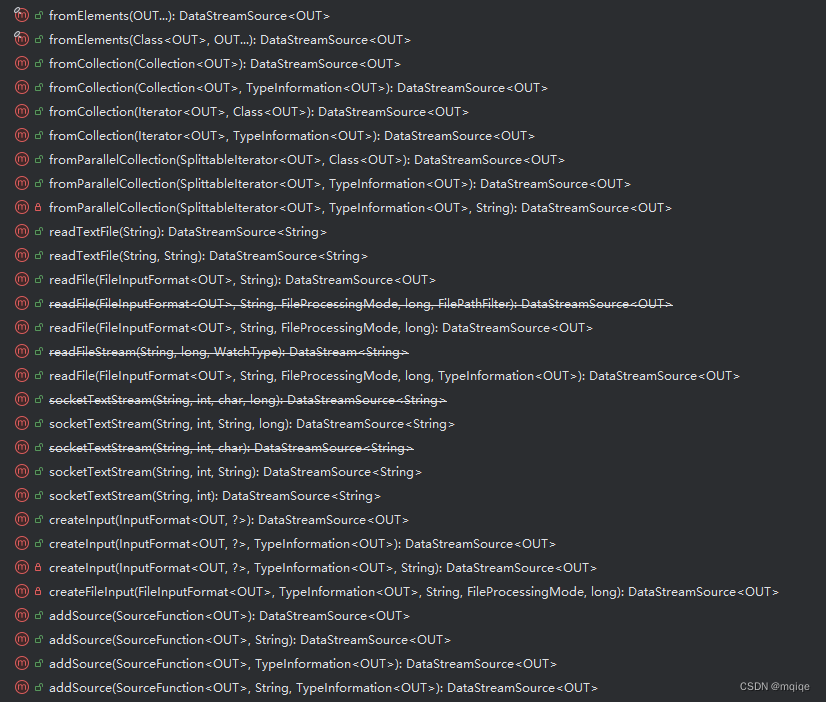
基于集合:
- fromCollection(Collection)
- fromCollection(Iterator, Class)
- fromElements(T …)
- fromParallelCollection(SplittableIterator, Class)
- generateSequence(from, to)
例如:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Event> input = env.fromElements(new Event(1, "ba", 4.0),new Event(2, "st", 5.0),new Event(3, "fo", 6.0),...
);
文件
- readTextFile(String filePath)
- readTextFile(String filePath, String charsetName)
- readFile(FileInputFormat inputFormat, String filePath)
样例:
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> text = env.readTextFile("file:///path/file");
Socket
- socketTextStream(String hostname, int port)
- socketTextStream(String hostname, int port, String delimiter)
- socketTextStream(String hostname, int port, String delimiter, long maxRetry)
样例:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStream<Tuple2<String, Integer>> dataStream = env.socketTextStream("localhost", 8888) // 监听 localhost 的 8888端口过来的数据.flatMap(new Splitter()).keyBy(0).timeWindow(Time.seconds(5)).sum(1);
自定义资源
通过实现 SourceFunction 来自定义非并行的 source 或者实现 ParallelSourceFunction 接口或者扩展 RichParallelSourceFunction 来自定义并行的 source。
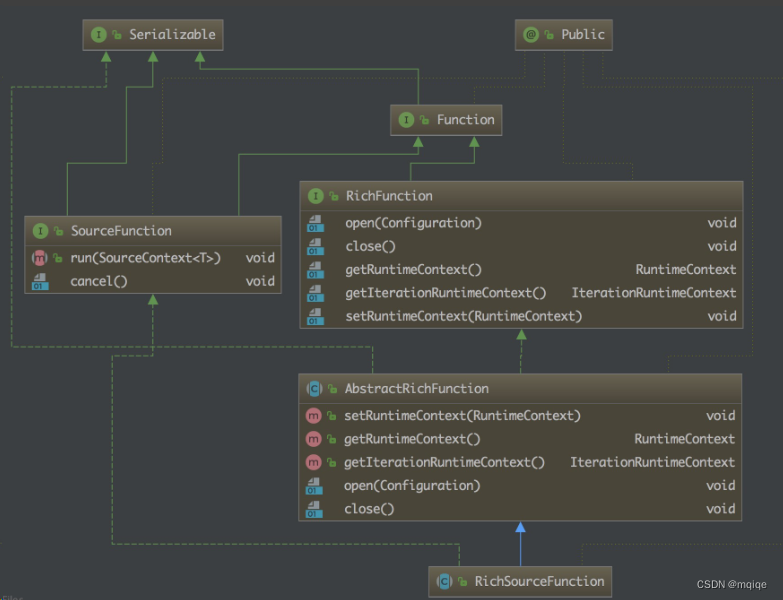
SourceFunction 非并行
SourceFunction 是一个用于定义数据源的函数接口。这个接口的实现通常负责从外部系统(如 Kafka、文件系统、数据库等)读取数据,并将这些数据作为 Flink 流处理或批处理作业的输入。
SourceFunction 通常与 Flink 的 DataStream API 一起使用,以定义和构建数据流处理任务。尽管 Flink 的内部实现和 API 可能会随着版本的更新而有所变化,但通常,一个 SourceFunction 会被实现为:
- 创建一个可以持续生成数据或等待外部数据到达的组件。
- 当有新数据到达时,将数据作为 Flink 的 DataStream 的一部分进行发射(emit)。
在 Flink 的内部,SourceFunction 可能会有多种不同的实现,具体取决于其要处理的数据源类型。例如,对于 Kafka 这样的消息队列,Flink 提供了专门的 Kafka 连接器和相应的 SourceFunction 实现,用于从 Kafka 主题中读取数据。
在实现自定义的 SourceFunction 时,你需要考虑以下几个方面:
- 数据源的连接和断开连接逻辑。
- 数据的读取和解析逻辑。
- 如何在 Flink 运行时环境中优雅地处理可能的错误和失败。
- 如何将读取的数据转换为 Flink 可以理解的格式(如 Tuple、POJO 或其他自定义类型)。
ParallelSourceFunction 并行
ParallelSourceFunction 是一个接口,用于定义并行数据源的行为。这个接口允许你创建自定义的数据源,这些数据源能够并行地读取数据并传递给 Flink 的数据处理管道。
ParallelSourceFunction 继承自 SourceFunction,但增加了并行处理的能力。当 Flink 任务需要并行处理多个数据流时,你可以通过实现 ParallelSourceFunction 来创建并行数据源。
Flink 还提供了一个 RichParallelSourceFunction 抽象类,它是 ParallelSourceFunction 的子类,并提供了更多的生命周期方法和上下文信息。使用 RichParallelSourceFunction 可以让你更容易地管理你的并行数据源,因为它提供了诸如 open()、close() 和 cancel() 等方法,这些方法可以在数据源的生命周期中的不同阶段被调用。
下面是一个简单的示例,演示了如何使用 RichParallelSourceFunction 创建一个并行数据源,该数据源生成递增的数字:
import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction;
public class IncrementingNumberSource extends RichParallelSourceFunction<Long> { private volatile boolean running = true; private long count = 0L; @Override public void run(SourceContext<Long> ctx) throws Exception { while (running) { synchronized (ctx.getCheckpointLock()) { ctx.collect(count++); // 这里可以添加一些休眠或其他逻辑来控制数据的生成速度 Thread.sleep(100); } } } @Override public void cancel() { running = false; }
}
在这个示例中,IncrementingNumberSource 类继承了 RichParallelSourceFunction,并覆盖了 run() 和 cancel() 方法。在 run() 方法中,我们创建了一个无限循环来生成递增的数字,并使用 ctx.collect() 方法将每个数字发送到 Flink 的数据处理管道中。在 cancel() 方法中,我们设置了一个标志来停止 run() 方法中的循环,以便在需要时可以优雅地关闭数据源。
自定义资源DEMO
/*** Desc: 自定义 source mysql 数据*/
public class SourceMySQL extends RichSourceFunction<Map<String, Object>> {PreparedStatement ps;private Connection connection;/*** open 方法中建立连接,这样不用每次 invoke 的时候都要建立连接和释放连接。*/@Overridepublic void open(Configuration parameters) throws Exception {super.open(parameters);connection = MySQLUtil.getConnection("com.mysql.jdbc.Driver","jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=UTF-8","root","123456");String sql = "select * from ST;";ps = this.connection.prepareStatement(sql);}/*** 关闭连接和释放资源的动作*/@Overridepublic void close() throws Exception {super.close();if (connection != null) {connection.close();}if (ps != null) {ps.close();}}/*** DataStream 从run方法用来获取数据*/@Overridepublic void run(SourceContext<Map<String, Object>> ctx) throws Exception {ResultSet resultSet = ps.executeQuery();while (resultSet.next()) {Map<String, Object> rs = new HashMap<>();rs.put("id", resultSet.getInt("id"));rs.put("name", resultSet.getString("name").trim());ctx.collect(rs);}}@Overridepublic void cancel() {}
}
![[机器学习-01]一文了解|机器学习简介、工具选择和Python包基础应用](https://img-blog.csdnimg.cn/direct/fec785c6900142a3b2f542ff2db39ce9.png)