引言
Abstract
文献阅读
1、题目
Deep High-Resolution Representation Learning for Human Pose Estimation
2、引言
在本文中,我们感兴趣的是人类姿态估计问题,重点是学习可靠的高分辨率表示。大多数现有的方法从由高到低分辨率网络产生的低分辨率表示中恢复高分辨率表示。相反,我们提出的网络在整个过程中保持高分辨率表示。我们从一个高分辨率的子网络开始作为第一阶段,逐步增加高分辨率到低分辨率的子网络,形成更多的阶段,并将多分辨率的子网络并行连接。我们进行重复的多尺度融合,使得每个从高到低的分辨率表示一遍又一遍地接收来自其他并行表示的信息,从而产生丰富的高分辨率表示。因此,所预测的关键点热图潜在地更准确且在空间上更精确。我们通过两个基准数据集:COCO关键点检测数据集和MPII人体姿势数据集的上级姿势估计结果实证证明了我们的网络的有效性。此外,我们展示了我们的网络在PoseTrack数据集上的姿态跟踪的优越性。
3、创新点
- 提出了High-Resolution Net (HRNet)用于人体姿势估计,通过保持高分辨率表示整个过程,而不需要恢复高分辨率。
- 引入了多次多尺度融合,使得每个高分辨率表示都能反复接收来自其他并行表示的信息,从而产生可靠的高分辨率表示。
4、姿态估计基于深度学习的方法
对于Human Pose Estimation任务,现在基于深度学习的方法主要有两种:
- 基于regressing的方式,即直接预测每个关键点的位置坐标。
- 基于heatmap的方式,即针对每个关键点预测一张热力图(预测出现在每个位置上的分数)。
当前检测效果最好的一些方法基本都是基于heatmap的,所以HRNet也是采用基于heatmap的方式。
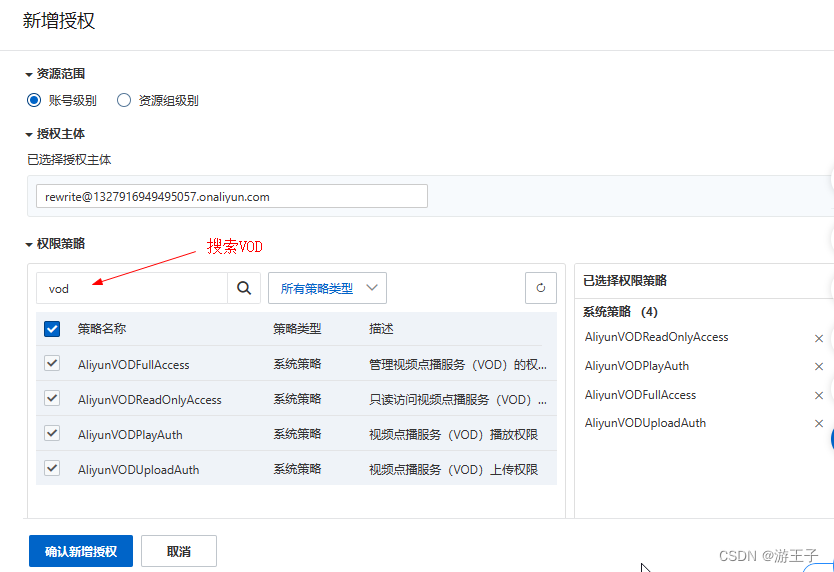
5、HRNet网络结构
5.1、总体架构
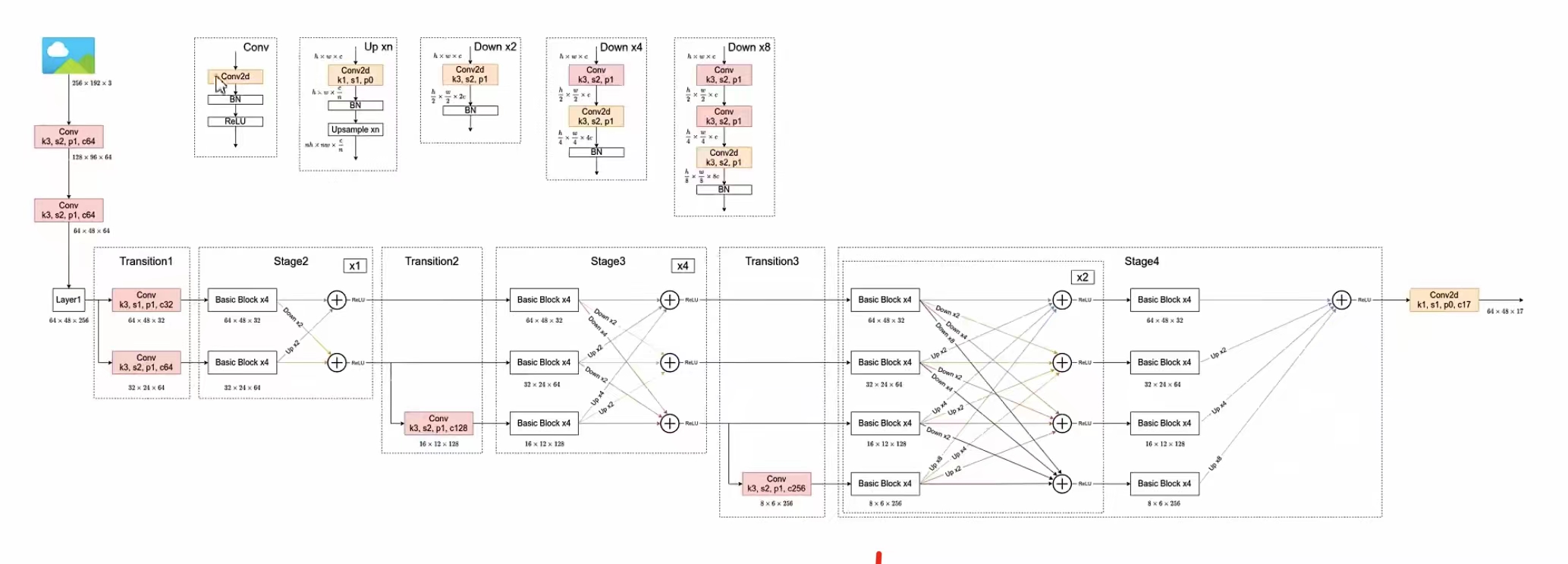
通过上图可以看出,HRNet首先通过两个卷积核大小为3x3步距为2的卷积层(后面都跟有BN以及ReLU)共下采样了4倍。然后通过Layer1模块,这里的Layer1其实和ResNet中的Layer1类似,就是重复堆叠Bottleneck,注意这里的Layer1只会调整通道个数,并不会改变特征层大小。
下面是实现Layer1时所使用的代码
# Stage1
downsample = nn.Sequential(nn.Conv2d(64, 256, kernel_size=1, stride=1, bias=False),nn.BatchNorm2d(256, momentum=BN_MOMENTUM)
)
self.layer1 = nn.Sequential(Bottleneck(64, 64, downsample=downsample),Bottleneck(256, 64),Bottleneck(256, 64),Bottleneck(256, 64)
)
接着通过一系列Transition结构以及Stage结构,每通过一个Transition结构都会新增一个尺度分支。比如说Transition1,它在layer1的输出基础上通过并行两个卷积核大小为3x3的卷积层得到两个不同的尺度分支,即下采样4倍的尺度以及下采样8倍的尺度。在Transition2中在原来的两个尺度分支基础上再新加一个下采样16倍的尺度,注意这里是直接在下采样8倍的尺度基础上通过一个卷积核大小为3x3步距为2的卷积层得到下采样16倍的尺度。Transition2应该是通过融合不同尺度的特征层得到的(下图用红色矩形框框出的部分)。但根据源码的实现过程确实就和我上面图中画的一样,就一个3x3的卷积层没做不同尺度的融合。
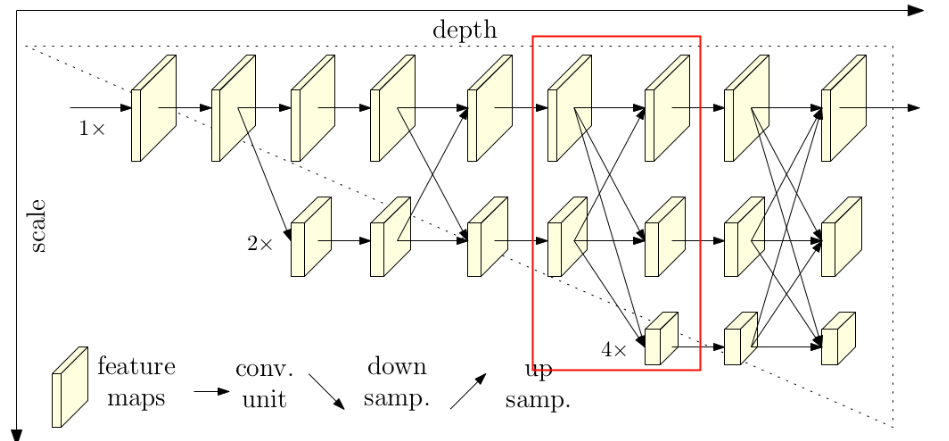
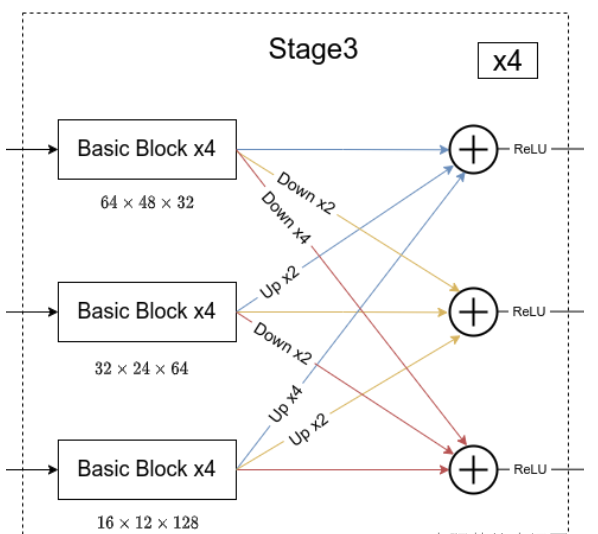
简单介绍完Transition结构后,在来说说网络中最重要的Stage结构。这里以Stage3为例,对于每个尺度分支,首先通过4个Basic Block,没错就是ResNet里的Basic Block,然后融合不同尺度上的信息。对于每个尺度分支上的输出都是由所有分支上的输出进行融合得到的。比如说对于下采样4倍分支的输出,它是分别将下采样4倍分支的输出(不做任何处理) 、 下采样8倍分支的输出通过Up x2上采样2倍 以及下采样16倍分支的输出通过Up x4上采样4倍进行相加最后通过ReLU得到下采样4倍分支的融合输出。其他分支也是类似的,图中右上角的x4表示该模块(Basic Block和Exchange Block)要重复堆叠4次。
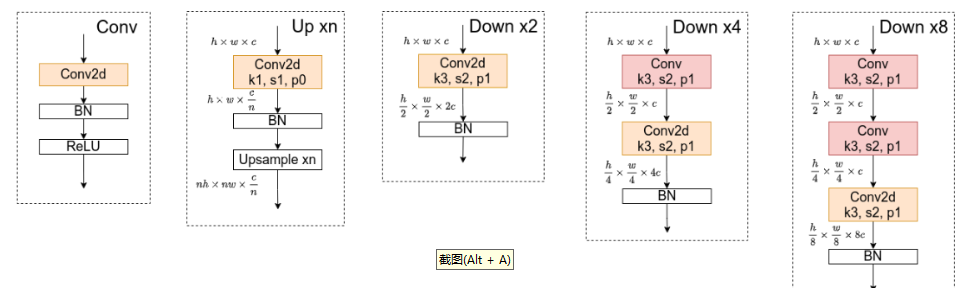
对于所有的Up模块就是通过一个卷积核大小为1x1的卷积层然后BN层最后通过Upsample直接放大n倍得到上采样后的结果(这里的上采样默认采用的是nearest最邻近插值)。Down模块相比于Up稍微麻烦点,每下采样2倍都要增加一个卷积核大小为3x3步距为2的卷积层(注意下图中Conv和Conv2d的区别,Conv2d就是普通的卷积层,而Conv包含了卷积、BN以及ReLU激活函数)。
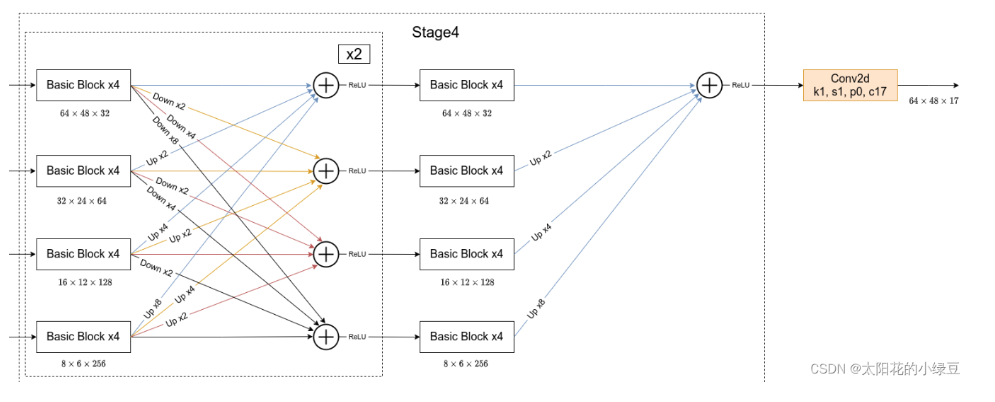
在Stage4中的最后一个Exchange Block只输出下采样4倍分支的输出(即只保留分辨率最高的特征层),然后接上一个卷积核大小为1x1卷积核个数为17(因为COCO数据集中对每个人标注了17个关键点)的卷积层。最终得到的特征层(64x48x17)就是针对每个关键点的heatmap(热力图)。
5.2、预测结果(heatmap)的可视化
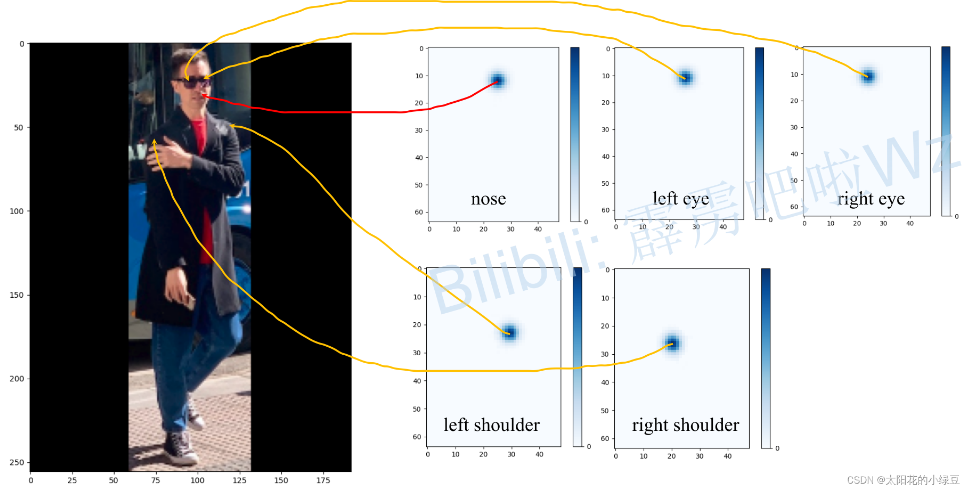
关于预测得到的heatmap(热力图)听起来挺抽象的,根据下面这幅图。首先,左边是输入网络的预测图片,大小为256x192,为了保证原图像比例,在两侧进行padding。右侧是我从预测结果,也就是heatmap(64x48x17)中提取出的部分关键点对应的预测信息(48x17x1)。网络最终输出的heatmap分辨率是原图的1/4,所以高宽分别对应的是64和48,接着对每个关键点对应的预测信息求最大值的位置,即预测score最大的位置,作为预测关键点的位置,映射回原图就能得到原图上关键点的坐标。
下面是源码中对应的实现,其中coords是每个关键点对应预测score最大的位置:
for n in range(coords.shape[0]):for p in range(coords.shape[1]):hm = batch_heatmaps[n][p]px = int(math.floor(coords[n][p][0] + 0.5))py = int(math.floor(coords[n][p][1] + 0.5))if 1 < px < heatmap_width-1 and 1 < py < heatmap_height-1:diff = np.array([hm[py][px+1] - hm[py][px-1],hm[py+1][px]-hm[py-1][px]])coords[n][p] += np.sign(diff) * .25
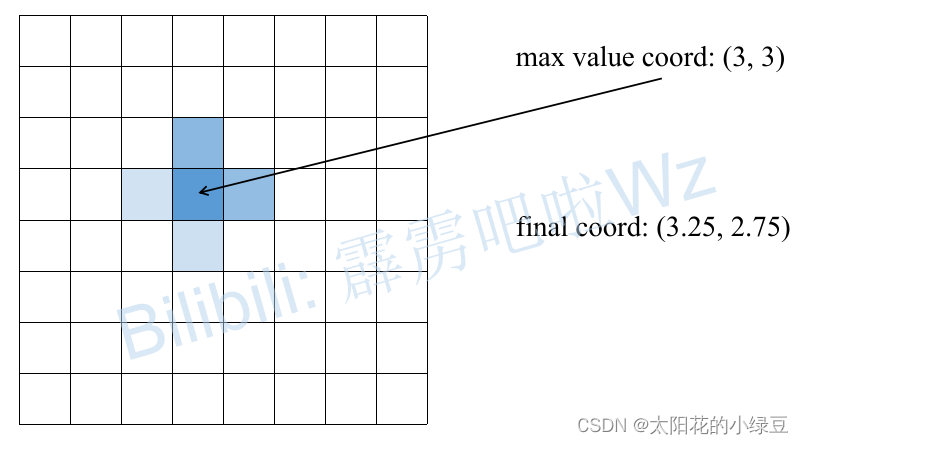
假设对于某一关键点的预测heatmap如下所示,根据寻找最大score可以找到坐标(3, 3)点,接着分别对比该点左右两侧(x方向),上下两侧(y方向)的score。比如说先看左右两侧,明显右侧的score比左侧的大(蓝色越深代表score越大),所以最终预测的x坐标向右侧偏移0.25故最终x=3.25,同理上侧的score比下侧大,所以y坐标向上偏移0.25故最终y=2.75。
关于COCO数据集中标注的17个关键点的顺序如下:
"kps": ["nose","left_eye","right_eye","left_ear","right_ear","left_shoulder","right_shoulder","left_elbow","right_elbow","left_wrist","right_wrist","left_hip","right_hip","left_knee","right_knee","left_ankle","right_ankle"]
最后把每个关键点绘制在原图上,就得到如下图所示的结果。

5.3、损失计算
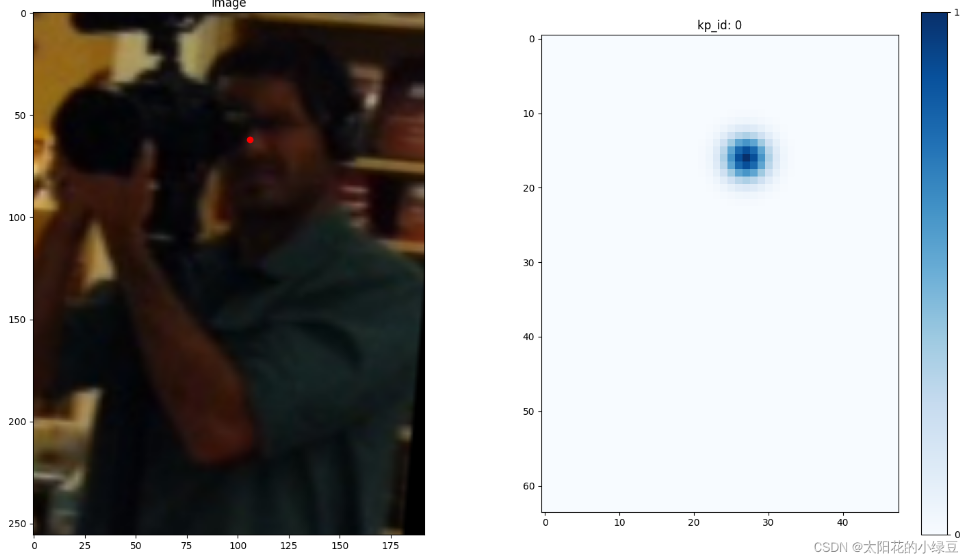
网络预测的最终结果是针对每个关键点的heatmap,根据标注信息我们是可以得知每个关键点的坐标的(原图尺度),接着将坐标都除以4(缩放到heatmap尺度)在进行四舍五入。针对每个关键点,我们先生成一张值全为0的heatmap,然后将对应关键点坐标处填充1就得到下面左侧的图片。如果直接拿左侧的heatmap作为GT去训练网络的话,会发现网络很难收敛(可以理解为针对每个关键点只有一个点为正样本,其他64x48-1个点都是负样本,正负样本极度不均),为了解决这个问题一般会以关键点坐标为中心应用一个2D的高斯分布(没有做标准化处理)得到如右图所示的GT(随手画的不必深究)。利用这个GT heatmap配合网络预测的heatmap就能计算MSE损失了。

下面这幅图是某张真实训练样本(左侧)对应nose关键点的GT heatmap(右侧)
代码中在计算总损失时,并不是直接把每个关键点的损失进行相加,而是在相加前对于每个点的损失分别乘上不同的权重。下面给出了每个关键点的名称以及所对应的权重。
"kps": ["nose","left_eye","right_eye","left_ear","right_ear","left_shoulder","right_shoulder","left_elbow","right_elbow","left_wrist","right_wrist","left_hip","right_hip","left_knee","right_knee","left_ankle","right_ankle"]
"kps_weights": [1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.2, 1.2, 1.5, 1.5, 1.0, 1.0, 1.2, 1.2, 1.5, 1.5]
5.4、评价准则
在目标检测(Object Detection)任务中可以通过IoU(Intersection over Union)作为预测bbox和真实bbox之间的重合程度或相似程度。在关键点检测(Keypoint Detection)任务中一般用OKS(Object Keypoint Similarity)来表示预测keypoints与真实keypoints的相似程度,其值域在0到1之间,越靠近1表示相似度越高。
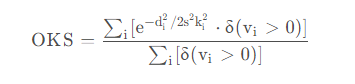
6、实验
6.1、COCO关键点检测
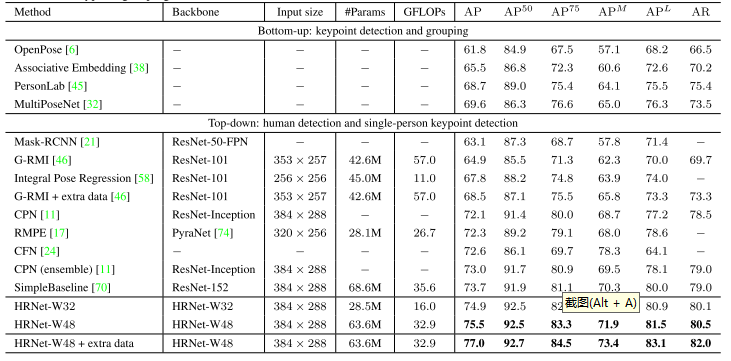
COCO验证集的比较,通过对原始图像和翻转图像的头部图进行平均来计算热图。通过在从最高响应到第二高响应的方向上以四分之一偏移调整最高热值位置来预测每个关键点位置。在表1中报告了本文的方法和其他最先进方法的结果。本文的小型网络HRNet-W32,从头开始训练,输入大小为256 × 192,获得了73.4的AP分数,优于其他具有相同输入大小的方法。与Hourglass相比,本文的小型网络将AP提高了6.5个点,并且本文网络的GFLOP要低得多,不到一半,而参数数量相似,本文的略大。
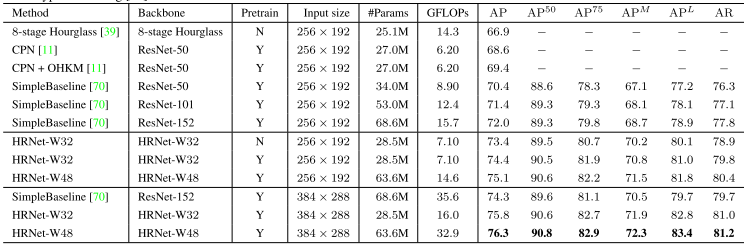
COCO测试开发集中,小型网络HRNet-W32实现了74.9的AP。它优于所有其他自顶向下的方法,并且在模型大小(#Params)和计算复杂度(GFLOPs)方面更有效。本文的大型号HRNet-W 48达到了最高的75.5 AP。与具有相同输入大小的SimpleBaseline [70]相比,我们的小型和大型网络分别获得了1.2和1.8的改进。通过AI Challenger [68]的额外数据进行训练,本文的单个大型网络可以获得77.0的AP。