数据库管理185期 2024-05-08
- 数据库管理-第185期 23ai:一套关系型数据干掉多套JSON存储(20240508)
- 1 上期示例说明
- 2 两个参数
- 2.1 NEST/UNNEST
- 2.2 CHECK/NOCHECK
- 3 一数多用
- 3.1 以用户维度输出订单信息
- 3.2 以产品维度
- 3.3 以产品种类维度
- 4 美化输出
- 总结
数据库管理-第185期 23ai:一套关系型数据干掉多套JSON存储(20240508)
作者:胖头鱼的鱼缸(尹海文)
Oracle ACE Associate: Database(Oracle与MySQL)
PostgreSQL ACE Partner
10年数据库行业经验,现主要从事数据库服务工作
拥有OCM 11g/12c/19c、MySQL 8.0 OCP、Exadata、CDP等认证
墨天轮MVP、认证技术专家、年度墨力之星,ITPUB认证专家、专家百人团成员,OCM讲师,PolarDB开源社区技术顾问,OceanBase观察团成员
圈内拥有“总监”、“保安”、“国产数据库最大敌人”等称号,非著名社恐(社交恐怖分子)
公众号:胖头鱼的鱼缸;CSDN:胖头鱼的鱼缸(尹海文);墨天轮:胖头鱼的鱼缸;ITPUB:yhw1809。
除授权转载并标明出处外,均为“非法”抄袭
上一期通过一个简单的示例展示了JSON关系二元性视图,视图创建了,但是里面很多内容,比如映射关系、数据关系维护等等都没有深入讲,还有就是如何用一套关系表数据实现多个JSON关系二元性视图。
1 上期示例说明
这里展示一下表和视图之间的一些映射关系:
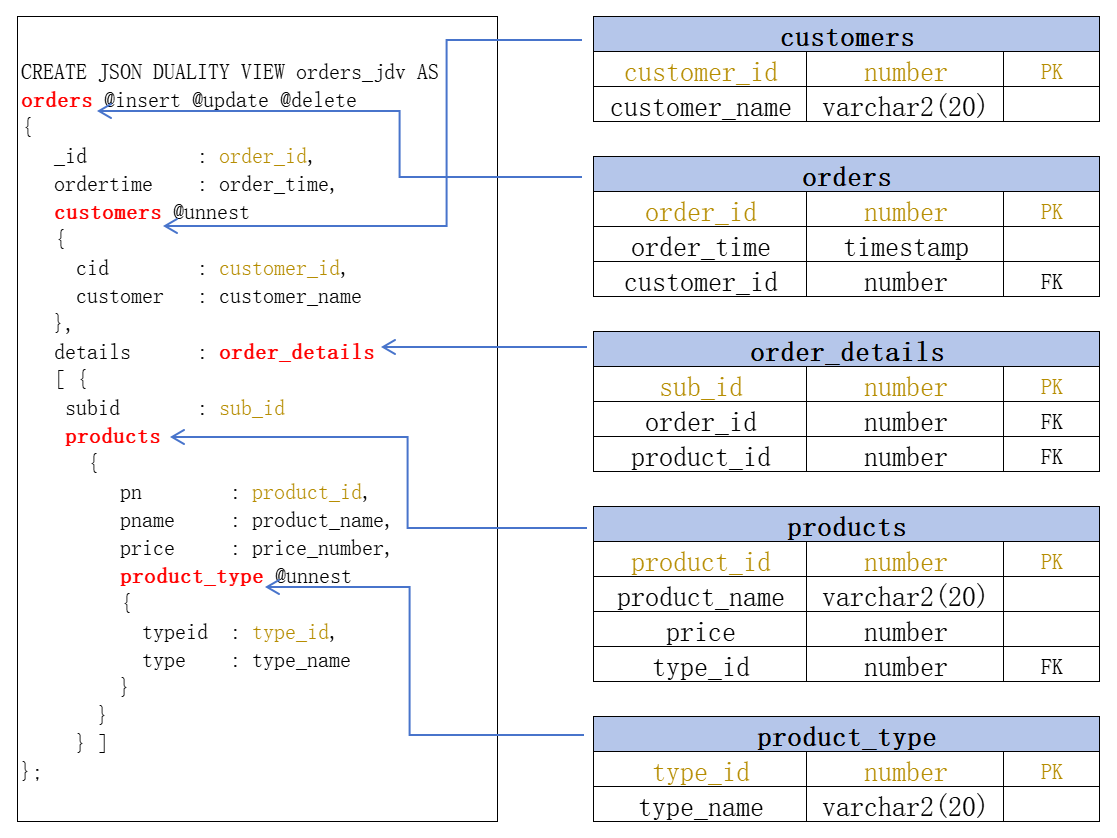
- 箭头指定了每个表在视图中的位置,其中最外层的是orders表,根据订单展示需求持续向内嵌套
- 各个主键(应当包含唯一约束列)都出现在了每一层表映射内容中
- 这里列之间的关联关系以及如何输出数据是由主外键关系实现的
- 这里创建视图使用的是GraphQL,这种方式可以用直接匹配输出结果的方式编写语句,也有以SQL定义,下面是官方文档提供的一个范例:

- NEST/UNNEST:这个放在下一节讲解
- 增删改:默认都是允许的JSON关系二元性视图是只读的,不能增删改,在使用GraphQL的模式下使用@[no]insert, @[no]update, @[no]elete,@[no]check;SQL下则是WITH [NO]INSERT [NO]UPDATE [NO]DELETE ;可以控制到每张表的级别。下面是官方文档提供的两个范例:


对于上一期的范例就是只能增删改orders表涉及的字段。
对于数据修改,特别是原来JSON存储的冗余数据,由于底层数据存储不存在冗余,现在可以仅在JSON关系二元性视图中更新一条数据即可修改所有相关JSON数据展示;也可以修改底层关系表实现 - CHECK:这个放在下一节讲解
2 两个参数
2.1 NEST/UNNEST
关于SQL中的unnest和nest,GraphQL中为@unnest, @nest,每个视图都定义了两个版本,其中一个包含嵌套对象,另一个使用关键字UNNEST定义,将嵌套对象展开为直接包含其字段,unset为指定嵌套对象中的属性何时应取消嵌套到父对象中。
这里直接通过下面的案例即可直观了解NEST/UNNEST的作用:
--新创建两个简单点的JSON关系二元性视图,分别使用@unnest和不指定
CREATE JSON DUALITY VIEW orders_jdv_unnest AS
orders
{_id : order_id,ordertime : order_time,customers @unnest{cid : customer_id,customer : customer_name}
};
select json_serialize(t.data PRETTY) from orders_jdv_unnest t;CREATE JSON DUALITY VIEW orders_jdv_nest AS
orders
{_id : order_id,ordertime : order_time,customers{cid : customer_id,customer : customer_name}
};
select json_serialize(t.data PRETTY) from orders_jdv_nest t;
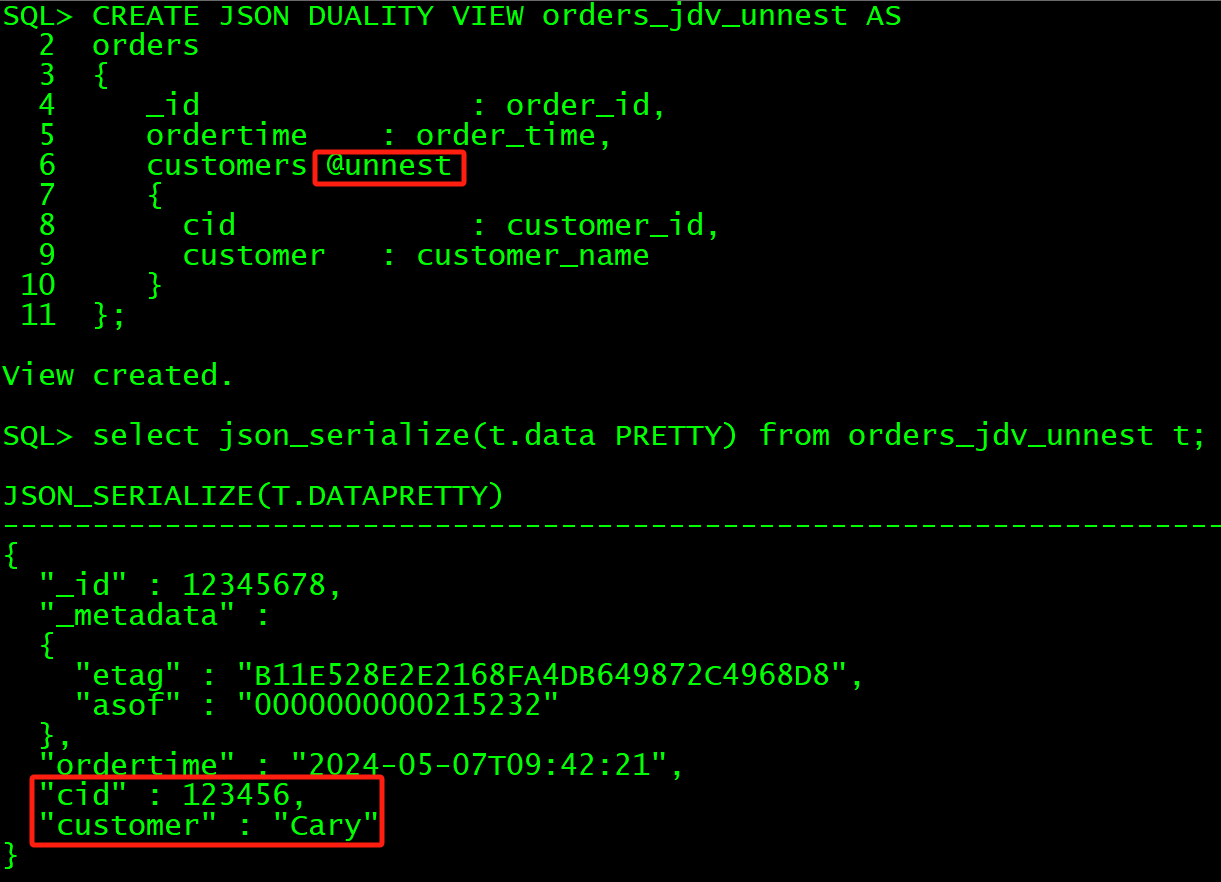
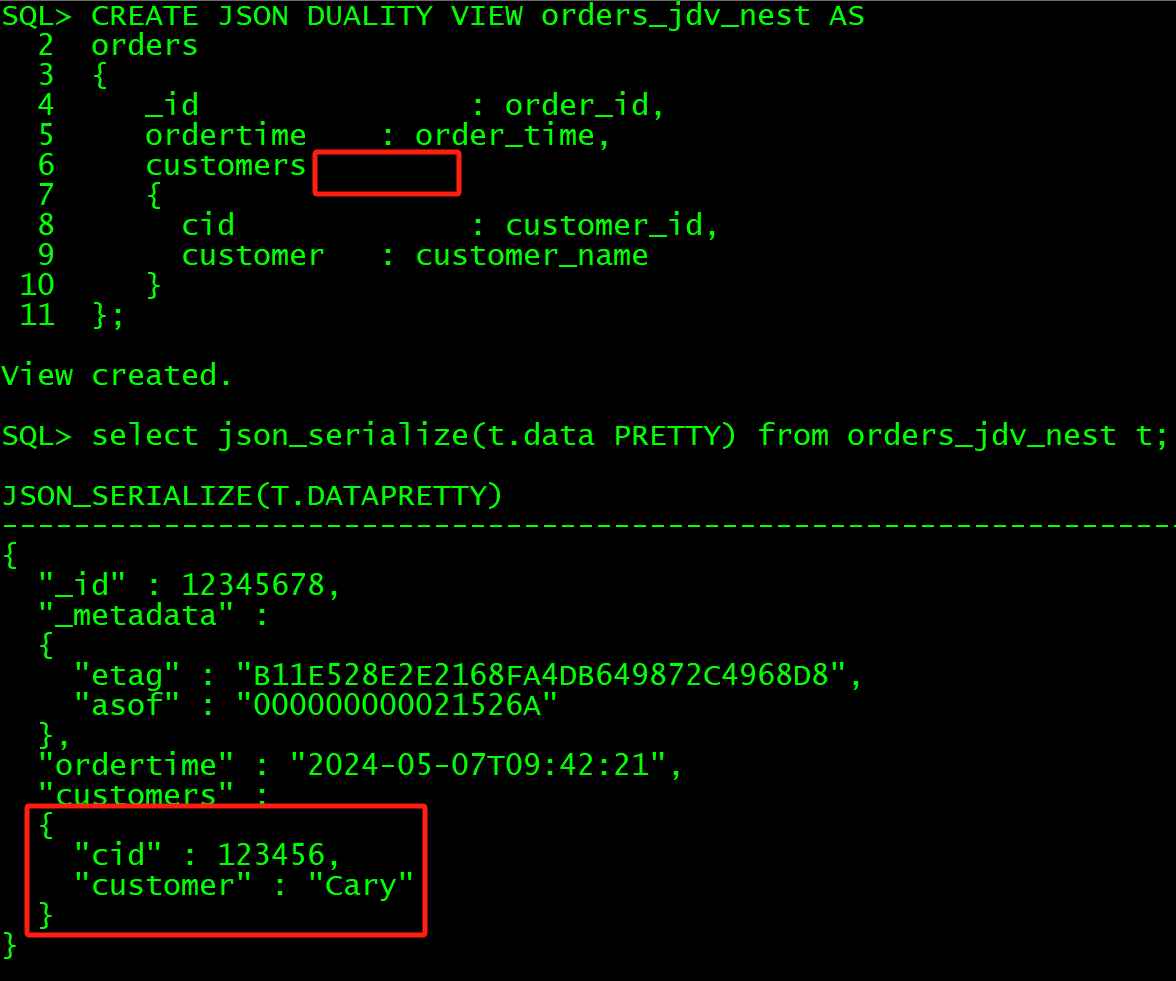
其实UNNEST就是将嵌套的JSON内容作为上级字段直接展开输出,而NEST则是仍以嵌套JSON格式输出。
2.2 CHECK/NOCHECK
@[no]check/WITH [NO]CHECK,包括/排除ETAG的校验字段的步骤:
指定文档的部分内容在文档更新时是否检查state/version(状态/版本)。当更新文档时,通常需要上次数据库操作文档后,正在更新的文档的state/version不发生变化。
实现方法是使用无锁的乐观并发控制。默认情况下,JSON关系二元性视图支持每个文档在ETAG字段,即_metadata内的etag中记录一个文档状态签名。字段值被由文档内容和一些其他信息的哈希值,每次操作文档时都会被自动更新。
文档的更新操作会根据时间更新etag的值,并将该值与要更新的文档中之前存储的etag值(由应用程序发送)进行核对。如果两个值不一致则更新操作会失败。这种情况下,应用程序会重新从数据库数据库获取最新的etag值,然后再次尝试修改数据。
默认情况下,文档的所有字段的操作都需要校验etag的值。将指定字段排除校验之外,可以使用@nocheck/WITH NOCHECK来实现。在表级指定NOCHECK可以让这张表涉及所有列排除在校验之外,这种情况下在某些列上加上CHECK则可以将这些列的操作进行校验。也可以将NOCHECK指定到指定列以排除该列更新时校验etag值。
如果更新操作成功,则会进行它定义的所有更改,包括对未参与ETAG校验的字段的任何更改,从而覆盖在此期间可能对该字段进行的任何更改。也就是说,对于更新操作,不属于ETAG校验的字段不会被忽略。
如果没有列被标记NOCHECK,那么作为一个整体的JSON关系二元性视图的文档被操作时都会校验etag;如果所有列都被标记NOCHECK,则整个文档的操作都不会校验etag。这可以提高性能,对于较大的文档,这种提升更为显著。在以下情况下可能希望JSON关系二元性视图排除所有ETAG校验:
- 应用程序有自己的并发控制方式,因此不需要数据库ETAG校验
- 应用程序是单线程的,不可能同时对数据进行修改
3 一数多用
先增加一部分数据:
--orders
insert into orders values(12345682,to_timestamp('2024-05-07 09:42:21','yyyy-mm-dd hh24:mi:ss'),123456);
insert into orders values(12345683,to_timestamp('2024-05-07 09:45:25','yyyy-mm-dd hh24:mi:ss'),234567);
insert into orders values(12345684,to_timestamp('2024-05-07 09:48:01','yyyy-mm-dd hh24:mi:ss'),456789);
insert into orders values(12345685,to_timestamp('2024-05-07 09:51:44','yyyy-mm-dd hh24:mi:ss'),345678);--order_details
insert into order_details values(11,12345685,98765);
insert into order_details values(12,12345685,87654);
insert into order_details values(13,12345683,87654);
insert into order_details values(14,12345684,65432);
insert into order_details values(15,12345684,76543);
insert into order_details values(16,12345682,98765);
insert into order_details values(17,12345682,98765);
insert into order_details values(18,12345682,87654);
insert into order_details values(19,12345683,76543);
insert into order_details values(20,12345684,65432);commit;
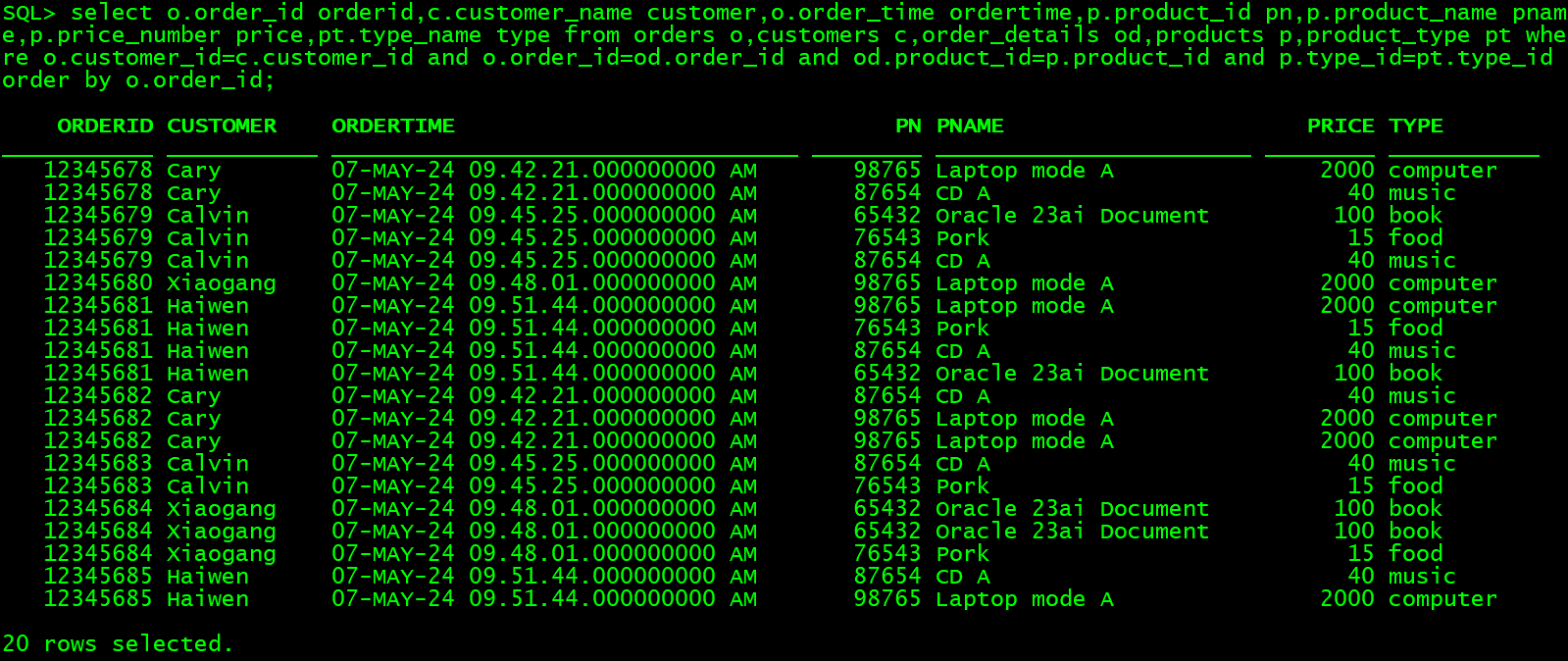
现在尝试用一套关系表数据解决多套需求:
3.1 以用户维度输出订单信息
CREATE JSON DUALITY VIEW customers_jdv AS
customers
{_id : customer_id,customer : customer_name,order : orders[ {oid : order_id,ordertime : order_time,details : order_details[ {subid : sub_id,products{pn : product_id,pname : product_name,price : price_number, product_type @unnest{typeid : type_id,type : type_name}}} ]} ]
};
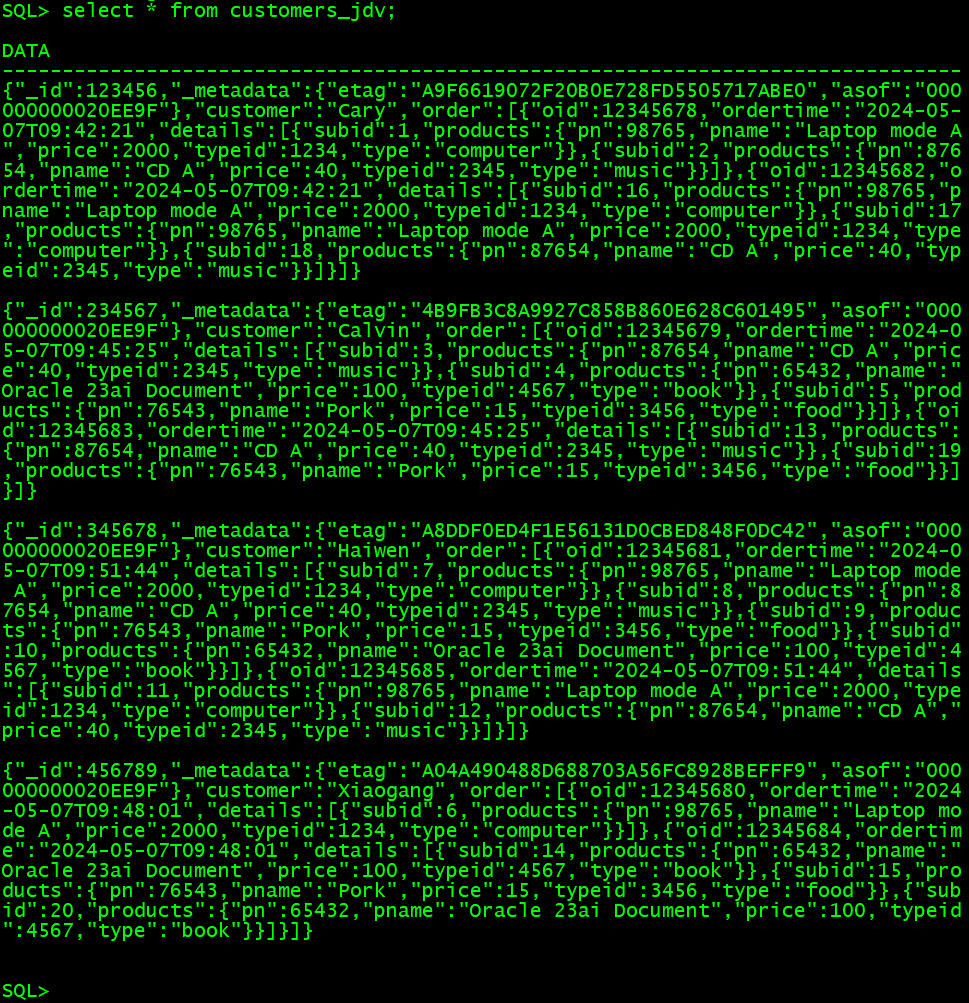
3.2 以产品维度
CREATE JSON DUALITY VIEW products_jdv AS
products
{_id : product_id,pname : product_name,price : price_number,product_type @unnest{typeid : type_id,type : type_name},order_details[ {subid : sub_id,orders @unnest{order : order_id,ordertime : order_time,customers @unnest{cid : customer_id,customer : customer_name}}} ]
};
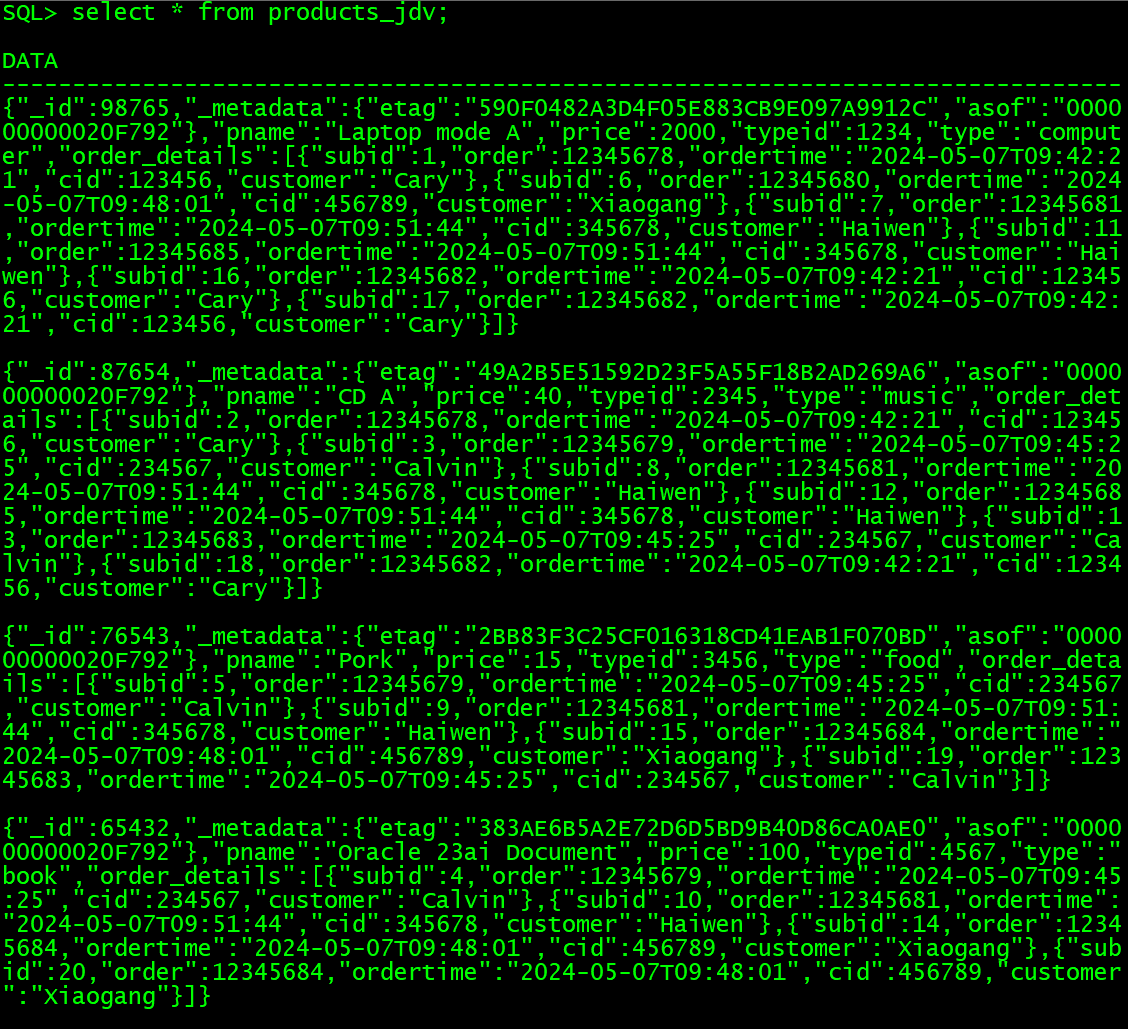
3.3 以产品种类维度
CREATE JSON DUALITY VIEW type_jdv AS
product_type
{_id : type_id,type : type_name,products[ {pn : product_id,pname : product_name,price : price_number,order_details[ {subid : sub_id,orders @unnest{order : order_id,ordertime : order_time,customers @unnest{cid : customer_id,customer : customer_name}}} ]} ]
};
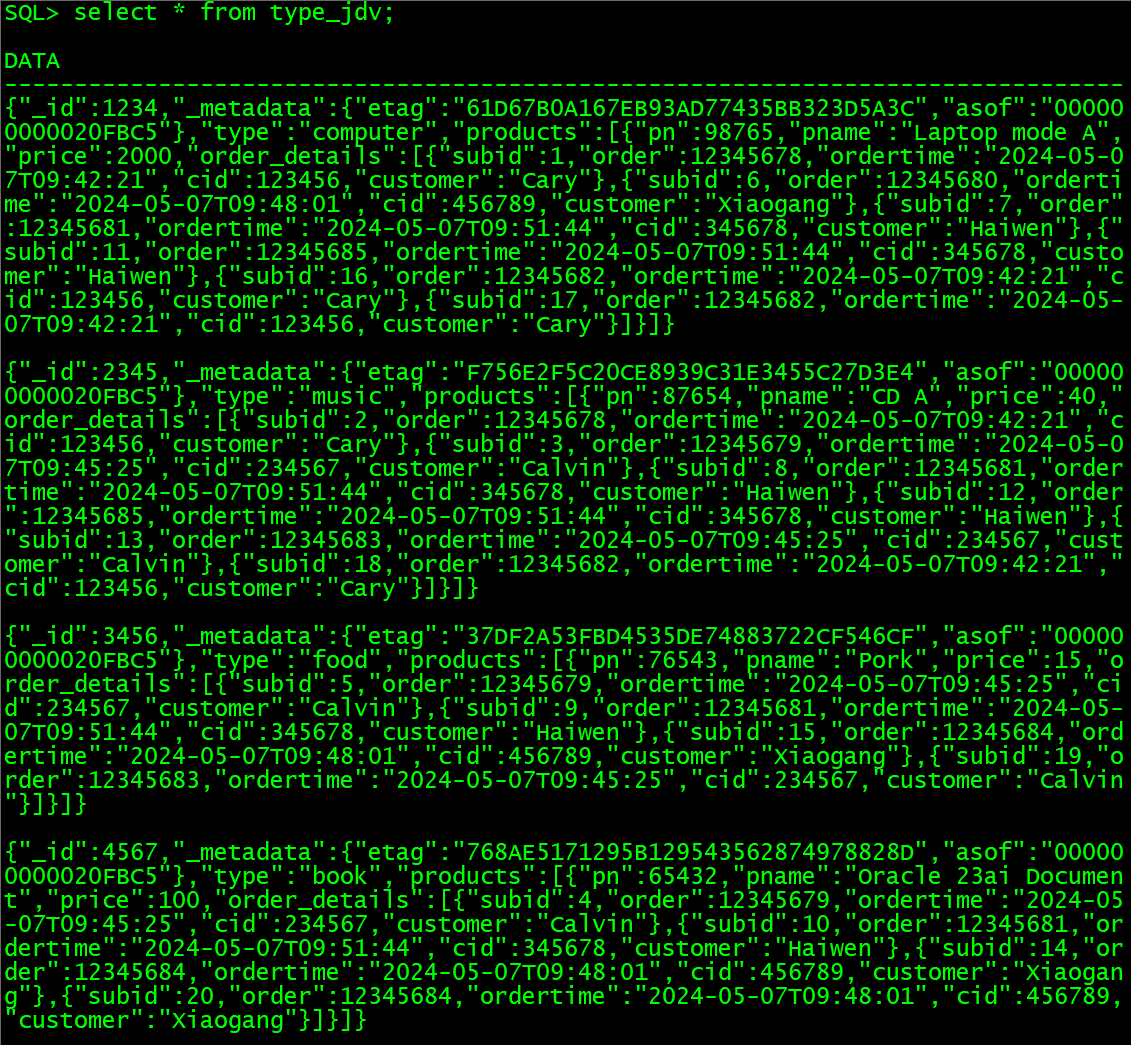
4 美化输出
这里可以在SQL中使用json_serialize函数美化输出:
select json_serialize(t.data PRETTY) from orders_jdv t;
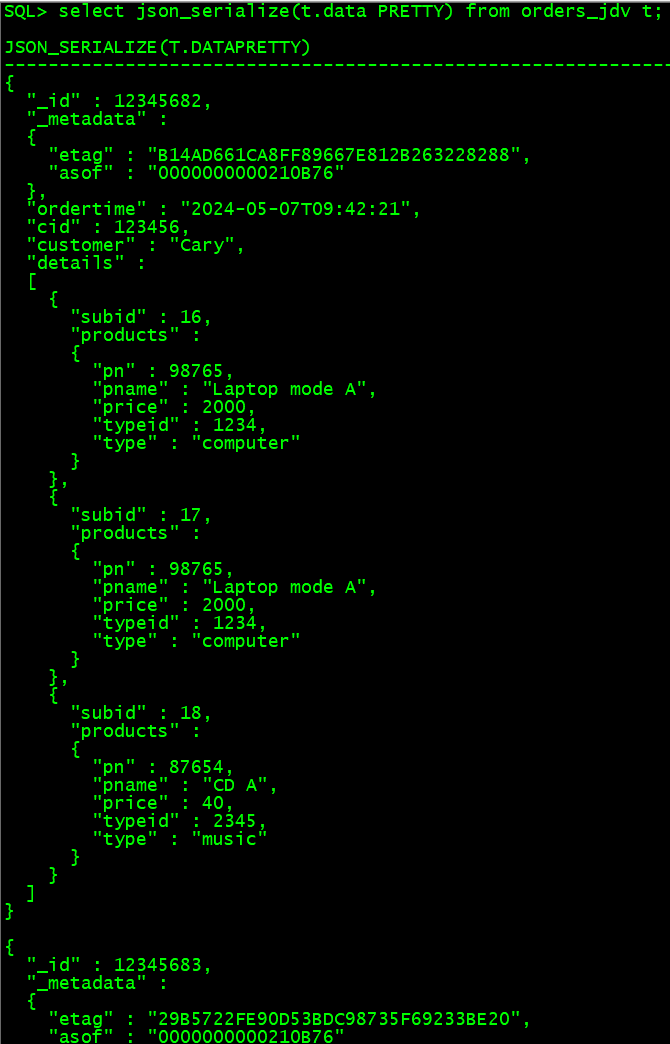
也可以使用最新的SQLDeveloper 23.1.1来试试:
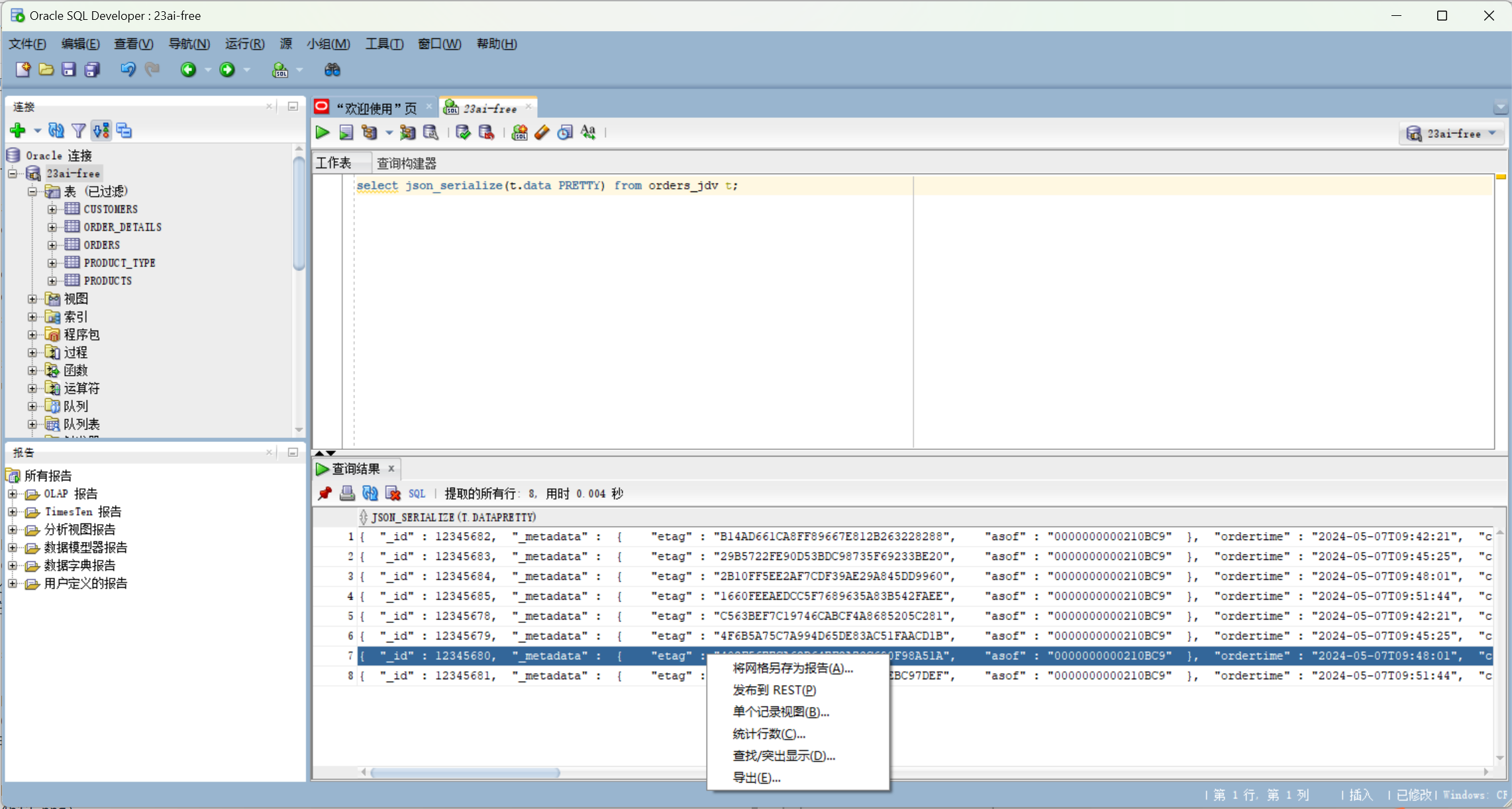
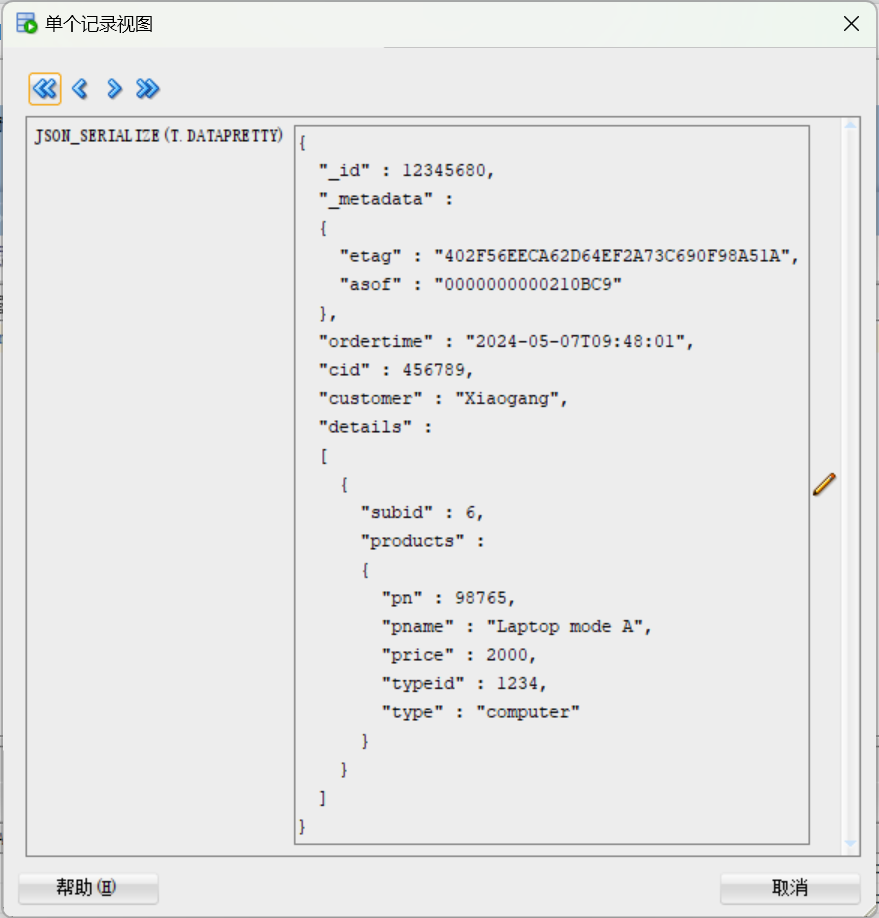
总结
本期展示了JSON关系二元性视图更详细的内容,如何用一套数据实现多个JSON模型需求,以及在SQL层面美化JSON输出。
更多的关于JSON关系二元性视图其他操作将放在下一期。
老规矩,知道写了些啥。