背景
一般来说,自动驾驶车辆的视觉传感器(比如摄像头)安装在车身上方或者车内后视镜上。无论哪个位置,摄像头所得到的都是真实世界在透视视图(Perspective View)下的投影(世界坐标系到图像坐标系)。这种视图与人类的视觉系统很类似,因此很容易被人类驾驶员理解。但是透视视图有一个致命的问题,就是物体的尺度随着距离而变化。因此,当感知系统从图像上检测到了前方有一个障碍物时,它并不知道这个障碍物距离车辆的距离,也不知道障碍物的实际三维形状和大小
BEV 优点:
首先,它没有在二维任务中普遍存在的遮挡或尺度问题。识别闭塞或交叉的车辆可以更好;其次,比检测分割+跟踪的方法更直观,更方便后面融合,规划,控制模块的开发部署。
BEV核心问题:
a: 如何从不同的传感器通过view transform模块重新构建丢失的3d信息
b: 如何从BEV网格获取GT标注
c: 如何制定一条从不同sources和views获得features的pipeline
d: 如何根据不同场景下传感器适配和泛化算法
Introduction:
自动驾驶的感知识别,本质上是一个从感知传感器往物理世界重建的过程。
根据输入数据,我们将BEV感知研究分为三个部分,主要是
1:BEV相机、BEV激光雷达和BEV融合,BEV相机表示以视觉或视觉为中心的算法,用于三维目标检测或分割;
2:BEV激光雷达描述从点云输入的检测或分割任务;
3:BEV融合描述了多个传感器输入的融合机制,如相机、激光雷达、GNSS、测程、HD-Map、CAN-总线等。
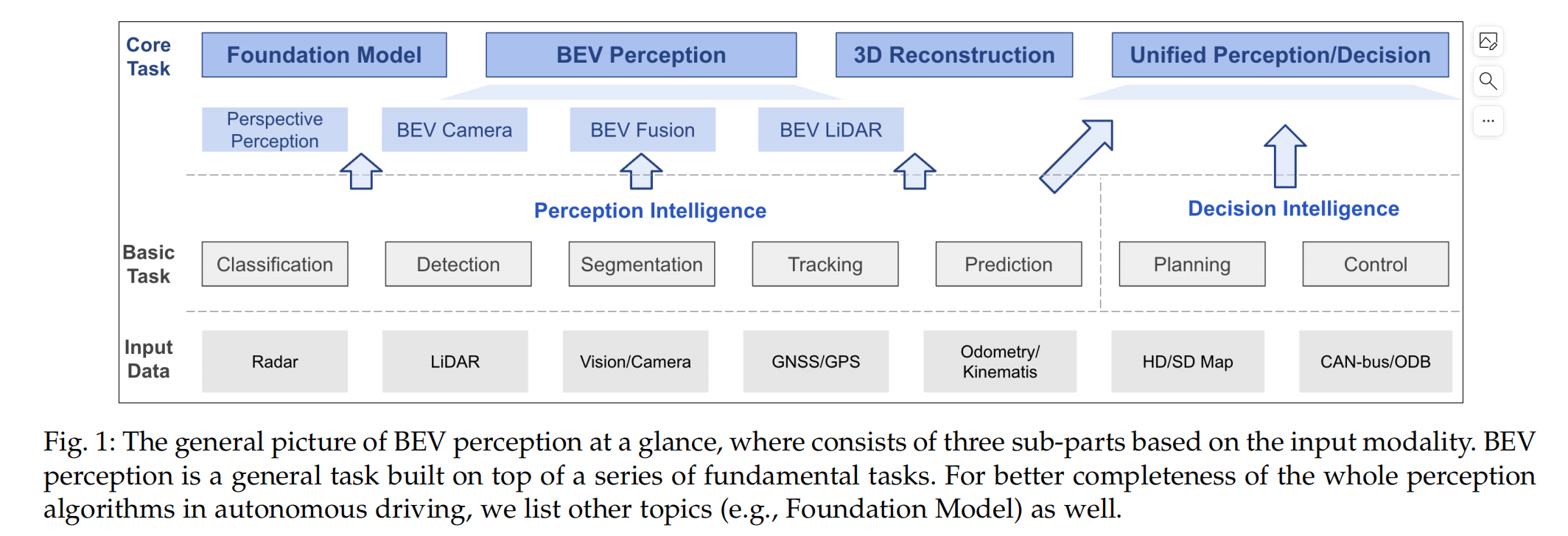 在本报告中,我们的目的是总结最近先进的BEV感知研究的一般pipeline和关键见解,除了各种输入组合和任务
在本报告中,我们的目的是总结最近先进的BEV感知研究的一般pipeline和关键见解,除了各种输入组合和任务
Motivation:
主要是三方面,
1 意义:
目前基于视觉和基于Lidar的方案差距过大,这自然促使我们去研究视觉解决方案是否能够击败或与激光雷达方法。
从学术的角度来看,设计一个基于相机的pipeline,使其性能优于激光雷达的本质,是更好地理解从二维视角输入到三维几何输出的视图转换过程。如何像点云一样将相机特征转换为几何表示,给学术界留下了有意义的影响。
在工业考虑上,一套激光雷达设备进入SDV的成本很昂贵;OEM(原始设备制造商,如福特、宝马等)更喜欢一个廉价而准确的软件算法部署。改进激光雷达的纯相机算法自然就符合这一目标,因为一个相机的成本通常比激光雷达低10倍。
此外,基于摄像头的pipeline可以识别远距离的物体和基于颜色的道路元素(例如,交通灯),这两种情况是激光雷达的方法是无法做到的。
尽管基于相机和激光雷达的感知有几种不同的解决方案,但在优越的性能和工业友好的部署方面,BEV是基于激光雷达的方法的最佳候选方案之一。
此外,最近的趋势表明,BEV表示在多摄像机输入方面也取得了巨大的进展。因为相机和激光雷达数据可以投射到BEV空间,BEV的另一个潜力是,我们可以很容易地在统一的表示下融合来自不同模态的特征。
2 (研究)空间:
BEV感知背后的要点是从相机和激光雷达输入中学习一个鲁棒和可一般化的特征表示。
这在激光雷达分支中很容易实现,因为输入(点云)具有这样的3D属性,在相机分支中,这是非常不容易的,因为从单目或多视图设置中学习三维空间信息是困难的。
另一个关键问题是如何在管道的早期或中期阶段融合特性。大多数传感器融合算法将该问题视为一个简单的对象级融合或沿着blob通道的简单特征连接。这可能解释了为什么由于相机和激光雷达之间的不对准或深度预测不准确,一些融合算法的表现低于仅使用激光雷达的解决方案。如何对齐和整合来自多模态输入的特征是至关重要的作用,从而留下了广泛的创新空间。
3 准备就绪:
open数据集都给你准备好了,可以尽情测试算法。同时 Transformer , ViT , Masked Auto-encoders (MAE) and CLIP, 我们相信这些工作将有利于和激励BEV感知研究。
3D感知研究背景
1 基于单目相机的目标检测:
主要就是预测RGB图像的深度信息。由于从单个图像中估计深度是一个不适定的问题,通常的基于单眼摄像机的方法的性能不如基于激光雷达的方法
2 激光雷达的检测和分割:
激光雷达用三维空间中的一组点来描述周围的环境,这些点可以捕获物体的几何信息。尽管缺乏颜色和纹理信息,而且感知范围有限,基于激光雷达的方法由于深度先验的优势大大优于相机改进的方法。
3 传感器融合:
相机,激光雷达和毫米波雷达。每个传感器都有其优缺点。
相机数据包含密集的颜色和纹理信息,但不能捕获深度信息。
激光雷达提供了准确的深度和结构信息,但其范围很有限,并且具有稀疏性。
毫米波波雷达比激光雷达更稀疏,但有更长的传感范围,可以从移动的物体中捕获信息。
如何融合来自不同模式的数据仍然是一个具有挑战性的问题。
数据集和度量标注
对于BEV感知任务,三维边界框标注和三维分割标注是关键,高清地图配置已成为主流趋势。
KITTI:
它有7481张训练图像和7518张测试图像用于三维目标检测任务。它也有相应的点云捕获从速差激光扫描仪。测试集分为3个部分:简单、中等和硬,主要由检测框的大小和遮挡级别决定。目标检测的评价分为两种类型:三维目标检测评价和鸟瞰图评价。KITTI是第一个用于多个自动驾驶任务的综合数据集,它吸引了社区的广泛关注。
Waymo:
Waymo开放数据集有很多版本,以v1.3为例子 ,在训练、验证和测试集中分别包含798、202和80个视频序列。每个序列有5个激光雷达和5个侧左SideLeft、前左FrontLeft、前Front、右、右侧视图的图像分辨率为1920×1280像素或1920×886像素。Waymo是大规模和多样化的。随着数据集版本的不断更新,它正在不断发展。每年的Waymo开放挑战都会定义新的任务,并鼓励社区去解决这些问题。
NuScenes:
NuScenes是一个大型的自动驾驶数据集,它包含了在两个城市的1000个驾驶场景。850个场景用于训练/验证,150个场景用于测试。每个场景都有20秒长。它有4万个关键帧,整个传感器套件,包括6个摄像头,1个激光雷达和5个毫米波雷达。相机图像分辨率为1600×900。同时,发布相应的HD-Map和CANbus数据,探索多种输入的辅助。由于nuScenes提供了多样化的多传感器设置,在学术文献中越来越流行;数据规模没有Waymo那么大,这使得在这个基准上快速验证想法非常有效。
这里介绍一下NuScenes的评估指标NDS:
NuScenes检测分数(NDS)是几个指标的组合: mAP, mATE (Average Translation Error),
mASE (Average Scale Error), mAOE (Average Orientation
Error), mAVE (Average Velocity Error) and mAAE (Average
Attribute Error).。
NDS是通过使用上述指标的加权和和来计算的。. The weight of mAP is 5 and 1 for
the rest. In the first step the TPerror is converted to TPscore
as shown below .
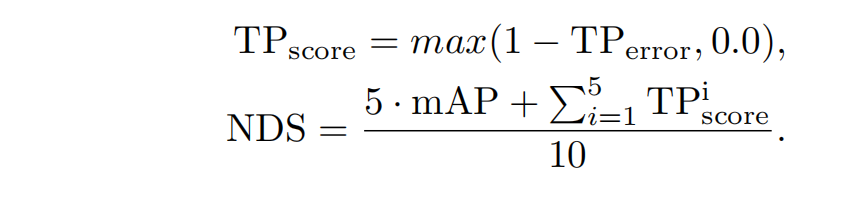
Methedology of BEV
在本节中,我们将详细描述来自学术界和工业界对BEV感知的各种方法。
我们根据输入模式在三种设置中区分了BEV pipeline ,
即1,BEV相机;(仅限相机的3D感知);2,BEV激光雷达;3,BEV融合。
下面对近年重要的BEV相关论文做了一个总结,我认为可以主要关注他们的INPUT格式和贡献。
在 Input Modality下,
“L”表示激光雷达,
“SC”表示单摄像机,
“MC”表示多摄像机,
“T”表示时间信息。
在Task下,“ODet”用于三维目标检测,“LDet”用于3D车道检测,“MapSeg”用于地图分割,“planning”用于运动规划,“MOT”用于多目标跟踪。
Depth Supervision means either camera-only model uses sparse/dense depth map to supervise the model, ✓ for yes, ✗ for no, - for LiDAR-input model. 【这一句我不太确定】,应该指的是:深度监督意味着任何一个camer-only的模型使用了稀疏或密集的深度地图来监督模型, ✓ 表示用了, ✗ 表示没有用,- 表示输入是Lidar数据,本身就有深度信息所以不考虑这方面。
在数据集下,
“nuS”表示 nuScenes dataset ,
“WOD”表示 Waymo Open Dataset [8],
“KITTI” 表示KITTI dataset [11],
“Lyft” 表示 Lyft Level 5 Dataset [28],
“OpenLane”表示 OpenLane dataset [26],
“AV”表示Argoverse Dataset [24],
“Carla” 表示carla simulator [40],
“SUN” SUN RGB-D dataset [41],
“ScanNet” ScanNet indoor scenes dataset。
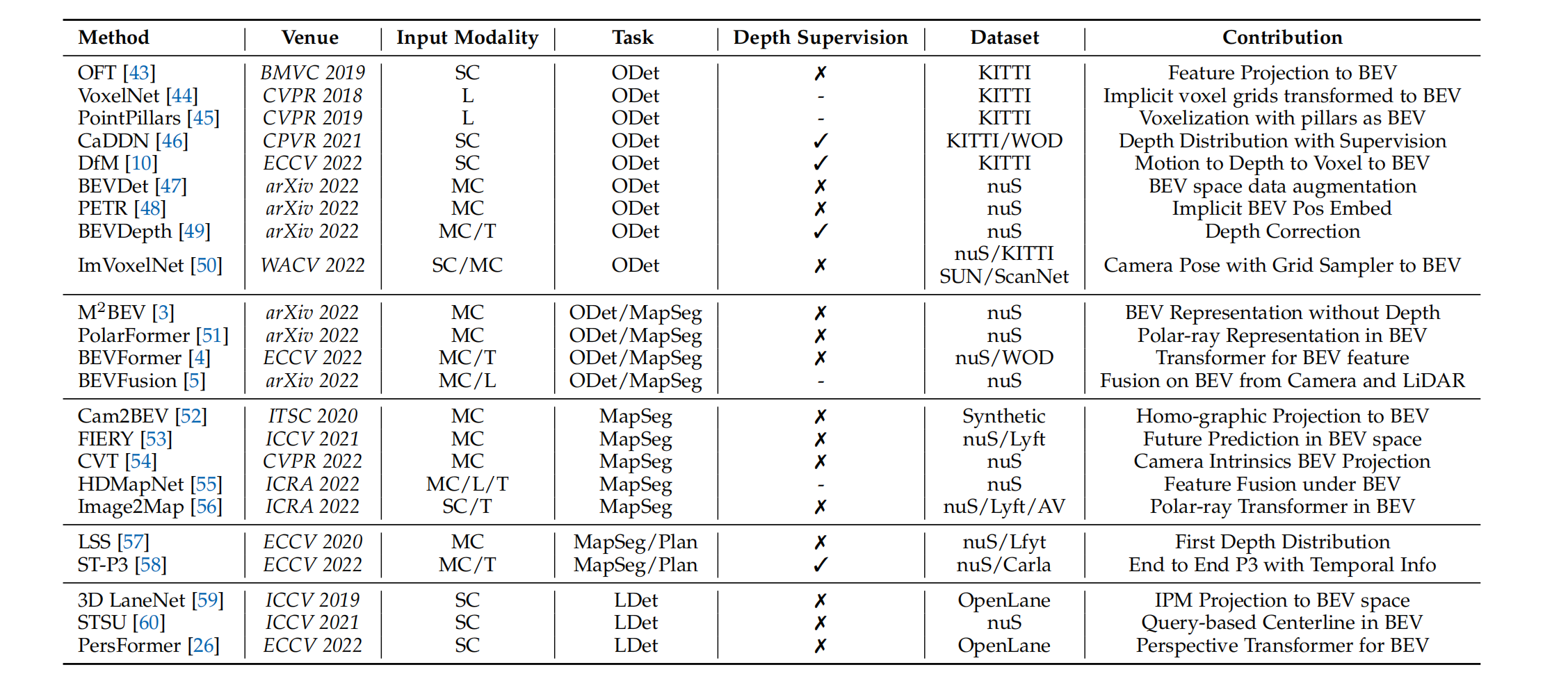
原文中还有一个表格列举了上面这些论文的一些性能,我这里不列举了。
1 BEV Camera-only
camera-only的3D感知可以分为三个领域:单相机设置,立体设置和多相机设置,他们有不同的方法来解决深度问题。
由于多台相机的方法通常从单台相机的baseline开始,所以我们也从单目相机的baseline设置开始。我们使用“二维空间”表示带有相机平面坐标的透视试图(perspective view),“三维空间”表示带有世界坐标的三维真实世界空间,“BEV空间”表示以下文的鸟瞰图。
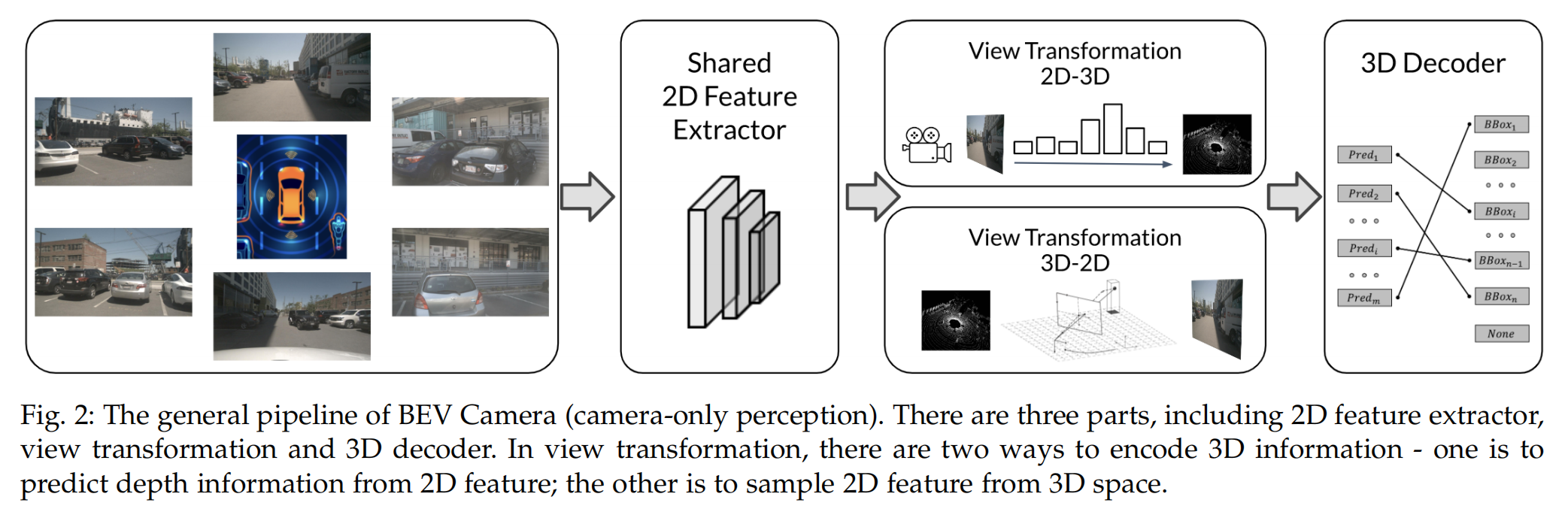
如上图描述,一个camera-only的3D感知系统可以划分为三部分,
分别是:2D特征提取器、视图转换模块view transform module(可选),3D解码器。
下面view transform module都称为VTM。
通常有两种方法来执行VTM,一个是执行转换从三维空间到二维空间,另一种是从二维空间到三维空间进行转换,这两者要么在三维空间用物理先验要么利用三维监督。这种转换可以表述为:
F 3 D ( x , y , z ) = M t r a n s ( F 2 D ∗ ( u ^ , v ^ ) , [ R , T ] , K ) F_{3D}(x,y,z)=M_{trans}(F^{*}_{2D}(\hat{u},\hat{v}),[R,T], K) F3D(x,y,z)=Mtrans(F2D∗(u^,v^),[R,T],K)
其中 F 3 D F_{3D} F3D,KaTeX parse error: Expected '}', got 'EOF' at end of input: F_{2D表示3D特性(或者voxel)和2D特征,x,y,z代表3D空间的坐标, M t r a n s M_{trans} Mtrans代表VTM, u ^ \hat{u} u^, v ^ \hat{v} v^代表对应的二维坐标的x,y,z(注意,这可能取决于特定的VTM的不同)。
[R, T] 和 代表相机外参和内参,详见附录B.1
3D解码器在2D/3D空间中接收特征,并输出3D感知结果,如三维bounding boxes,BEV地图分割、3D车道关键点等。
大多数3D解码器来自基于lidar的方法,它们在voxel空间/BEV空间进行检测,但仍有一些只有相机的3D解码器利用二维空间中的特征,直接回归3D目标的定位。
2 View Transform Module (VTM)
最近的研究主要集中在VTM[3,4,10,26,47,48,49,51,56,59]上,其中三维信息是由二维特征或三维先验假设构建的.
由于我最近在看VTM相关内容,我把上述文章都列出来
- 3:E. Xie, Z. Yu, D. Zhou, J. Philion, A. Anandkumar, S. Fidler, P. Luo, and J. M. Alvarez, “M2BEV: Multi-camera joint 3d detection and segmentation with unified birds eye view representation,” arXiv preprint arXiv:2204.05088, 2022
- 4: Z. Li, W. Wang, H. Li, E. Xie, C. Sima, T. Lu, Q. Yu,
and J. Dai, “BEVFormer: Learning bird’s-eye-view representation from multi-camera images via spatiotemporal
transformers,” arXiv preprint arXiv:2203.17270, 2022. - 10:T. Wang, J. Pang, and D. Lin, “Monocular 3d object detection with depth from motion,” arXiv preprint arXiv:2207.12988, 2022
- 26:L. Chen, C. Sima, Y. Li, Z. Zheng, J. Xu, X. Geng, H. Li,
C. He, J. Shi, Y. Qiao, and J. Yan, “PersFormer: 3d lane detection via perspective transformer and the openlane benchmark,” arXiv preprint arXiv:2203.11089, 2022. - 47:J. Huang, G. Huang, Z. Zhu, and D. Du, “BEVDet: High performance multi-camera 3d object detection in bird eye-view,” arXiv preprint arXiv:2112.11790, 2021.
- 48:Y. Liu, T. Wang, X. Zhang, and J. Sun, “Petr: Position embedding transformation for multi-view 3d object detection,” arXiv preprint arXiv:2203.05625, 2022.
- 49:Y. Li, Z. Ge, G. Yu, J. Yang, Z. Wang, Y. Shi, J. Sun, and Z. Li, “BEVDepth: Acquisition of reliable depth for multiview 3d object detection,” arXiv preprint arXiv:2206.10092, 2022
- 51:Y. Jiang, L. Zhang, Z. Miao, X. Zhu, J. Gao, W. Hu, and Y.G. Jiang, “Polarformer: Multi-camera 3d object detection with polar transformers,” arXiv preprint arXiv:2206.15398,2022.
- 56:A. Saha, O. Mendez, C. Russell, and R. Bowden, “Translating images into maps,” in IEEE International Conference on Robotics and Automation, 2022.
- 59:N. Garnett, R. Cohen, T. Pe’er, R. Lahav, and D. Levi, “3d multiple lanenet: end-to-end 3d multiple lane detection,” in IEEE International Conference on Computer Vision, 2019
总的来说,VTM 可以分为两个方面,一是利用二维特征构造深度信息和将二维特征“lift 提升”到三维空间;另一种是通过3D-to-2D投影映射将二维特征编码到三维空间。我们将第一种方法命名为2D- 3D,将第二种方法命名为3D-2D。下图给出了通过这两种方法执行VTM的摘要路线图。
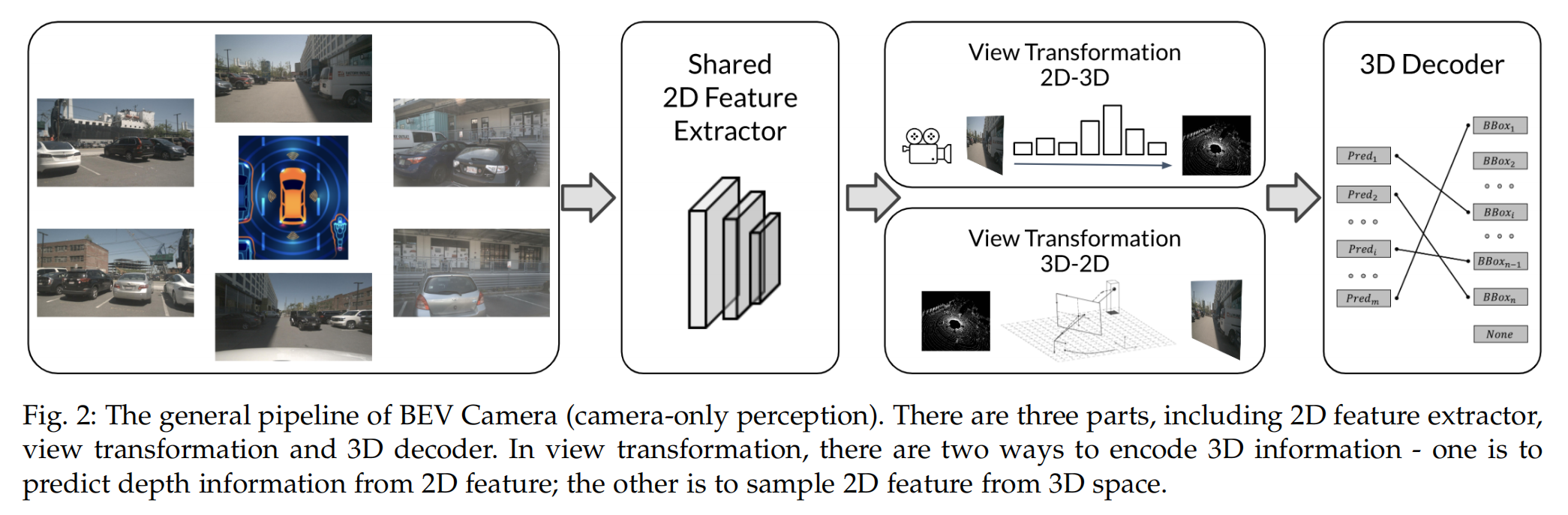
在VTM中,有两个方式编码3D信息,一种是从2D特征中预测深度信息;另一种是从3D空间中采样2D特征。
对我个人来说,第一种方式很好理解,就是对于camera采集的的RGB图像,我们用算法预测它的深度信息就行了。
LSS [“Lift, splat, shoot”]
首先引入了2D-3D方法,预测二维特征上每个网格的深度分布,然后通过相应的深度将每个网格的二维特征“提升”到体素空间,并采用基于lidar激光雷达的方法执行下游任务。这个过程可以表述为
xxxxxxxxxxxxxx 公式
在LSS 之后,还有另一项工作遵循formulating depth as bin-wise distribution 的概念,即CaDDN 。CaDDN采用类似的网络预测深度分布(分类深度分布),将体素空间特征压缩到BEV空间,最后进行三维检测。LSS 和CaDDN 的主要区别在于,CaDDN使用 depth ground truth 来监督其分类深度分布预测,从而有更优秀的深度预测网络从二维空间中提取三维信息。请注意,当我们声称这是“一个更好的深度网络”时,它实际上是在特征层面上学习路面和透视视图之间的隐式投影。这条路带来了随后的工作,如BEVDet 及其时间版本BEVDet4D ,BEVDepth ,BEVFusion 等。
请注意,在立体设置中,深度值/分布更容易通过强先验获得,因为相机之间的距离(即系统的baseline)应该是恒定的。这个过程可以被描述为:
D ( u , v ) = f × b d ( u , v ) D(u,v)=f\times{\frac{b}{d(u,v)}} D(u,v)=f×d(u,v)b
其中,d (u,v)是在位置(u,v)上的一对图像的水平视差,视差等于同名点对在左视图的列坐标减去在右视图上的列坐标,是像素单位,f为照相机的焦距,见附录B.1
D (u、v)是(u、v)处的深度值,b是上述提到的系统baseline的长度。
LIGA Stereo [92]和DSGN [65]利用了这种强大的先验,在KITTI排行榜上的表现与基于激光雷达的替代方案媲美。
而对于3D-2D方案,可以追溯到30年前。当Inverse Perspective Mapping(IPM)将从三维空间到二维空间的投影有条件地假设三维空间中的相应点位于水平平面上。
这种变换矩阵可以从摄像机的内在参数和外在参数[94]的数学上推导出,该过程的细节在附录B.1
一系列的工作应用IPM,以预处理或后处理的方式将元素从透视视角转换为鸟瞰视图。在视图转换的背景下,OFTNet 首先引入了3D-2D方法,即从3D到2D的特征投影,它将2D特征投影到体素空间(3D空间),它基于的假设是,在三维空间中,从相机原点沿光线到特定点的深度分布是均匀的。这个假设适用于自动驾驶的大多数场景,但在起伏的道路上,有时不管用。
同时,大量的BEV地图分割工作利用多层感知器或Transformer架构,在没有摄像机参数的情况下隐式建模3D-2D投影。
最近,受特斯拉发布了感知系统[6]的技术路线图的启发,3D-2D几何投影和神经网络的结合成为了流行的[4,26,48,56,86,96]。请注意,Transformer体系结构中的交叉注意机制在概念上满足了这种几何投影的需要,可以表达为:
xxxxxx公式8
q, k, v stand for query, key and value, P x , y , z P_{x,y,z} Px,y,z是体素空间中预定义的锚点,其他值和之前的公式一样意义,一些[4,48,86]方法利用相机参数将 P x , y , z P_{x,y,z} Px,y,z投影到图像平面上,使模型快速收敛。
为了获得具有鲁棒性的检测结果,BEVFormer[4]利用Transformer中的交叉注意机制来增强3D-2D视图转换的建模。其他的[50,97]缓解了网格采样器,以有效地加速这一过程,以实现大规模生产。然而,这些方法在很大程度上依赖于相机参数的准确性,这些参数在长时间驾驶下容易发生变化。
BEV及透视方法的探讨
在仅使用相机的三维感知的初期,主要的焦点是如何从2D感知空间预测三维物体的位置。这是因为二维感知在那个[1,2,98,99]阶段发展得很好,所以如何使二维探测器具有感知三维场景的能力成为主流方法[62,82,83,100]。
后来,一些研究涉及了BEV,因为在这种视角下,很容易解决三维空间中相同大小的物体由于与相机的距离而在图像平面上大小非常不同的问题,包括遮挡问题。
这一系列的工作[43,46,65,89,92]要么预测深度信息,要么利用三维先验假设来补偿摄像机输入中三维信息的损失。
然而最近基于bev的方法[3,4,5,47,49,91,101]已经席卷了3D感知世界,但值得注意的是,这种成功主要来自于三个部分:
- 第一个原因是nuScenes数据集[7],它具有多摄像头设置,非常适合在BEV下应用多视图特征聚合。
- 第二个原因是,大多数只有相机的BEV感知方法在检测头和相应的损失设计上都从基于激光雷达的方法[44,45,67,84,85,102,103])中获得了很大的帮助。
- 第三个原因是,单目方法[82,83,100]的长期发展使基于bev的方法在处理透视视角的特征表达方面蓬勃发展,其核心问题是如何从二维图像中重建丢失的三维信息。
为此,基于bev的方法和透视方法是解决同一问题的两种不同的方法,它们并不相互排除
3.2 BEV Lidar
暂略
3.3 BEV Fusion
暂略
3.4 BEV感知的工业界应用
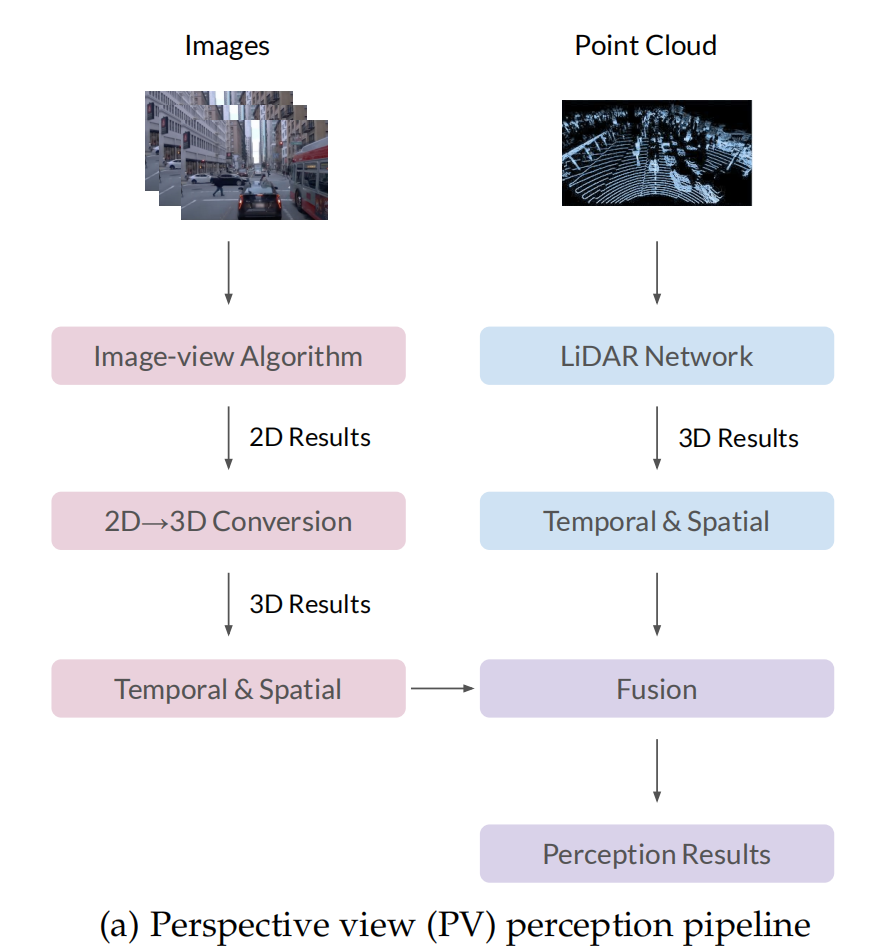
下面是透视视角方法的pipeline,激光雷达轨迹直接生成三维结果。基于几何先验,从二维结果转换为图像的三维结果。然后,我们融合了来自图像和激光雷达的预测,利用一些人工设计的方法在现实的场景中并不总是表现得很好。
相反,如下图,基于BEV的方法,利用神经网络进行二维到三维转换,整合特征,而不是来自不同模态的直接检测输出,导致手工设计更少,鲁棒性更强。
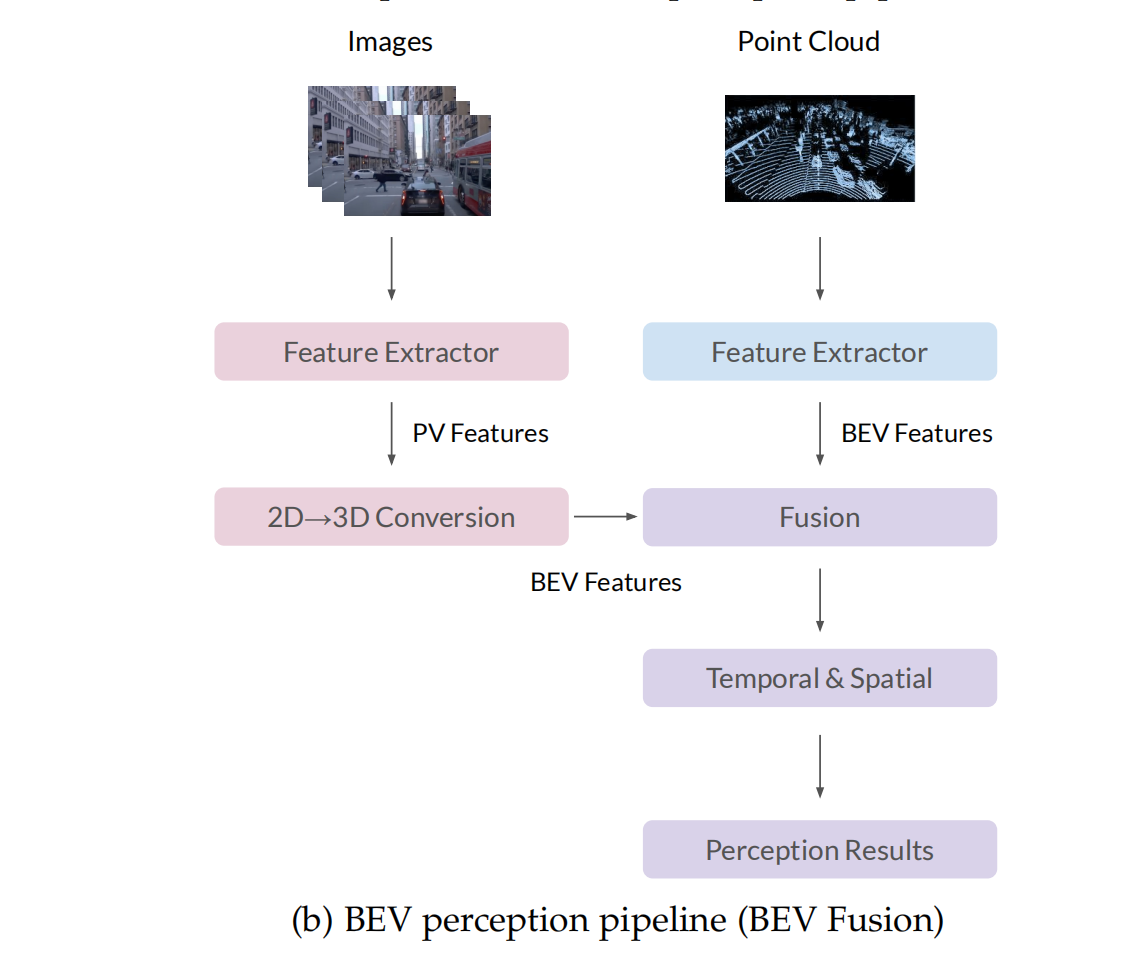
4 评估
4.2 BEV Encoder
(a) 2D Feature Extractor
(b) View transformation