Distilling Diffusion Models into Conditional GANs
公和众和号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)

目录
0. 摘要
3. 方法
3.1 用于一步生成的配对的噪声到图像翻译
3.2 用于潜在空间蒸馏的组合的 LatentLPIPS
3.3 条件扩散鉴别器
4. 实验
5. 讨论与局限性
0. 摘要
我们提出了一种将复杂的多步扩散模型蒸馏为单步条件 GAN 学生模型的方法,极大地加速了推理速度,同时保持了图像质量。我们的方法将扩散蒸馏视为一种配对的图像到图像翻译任务,使用扩散模型的 ODE 轨迹的噪声到图像 pairs。为了进行有效的回归损失计算,我们提出了 E-LatentLPIPS,这是一种在扩散模型的潜在空间中直接操作的感知损失,利用组合(ensembling)增强。此外,我们改进了扩散模型,构建了一个多尺度鉴别器,并使用文本对齐损失构建了一个有效的基于条件 GAN 的公式。E-LatentLPIPS 的收敛速度比许多现有的蒸馏方法更高效,即使考虑到数据集构建成本。我们证明了我们的单步生成器在 zero-shot COCO 基准测试中优于最先进的一步扩散蒸馏模型 - DMD、SDXL-Turbo 和 SDXL-Lightning。
项目页面:https://mingukkang.github.io/Diffusion2GAN/
3. 方法
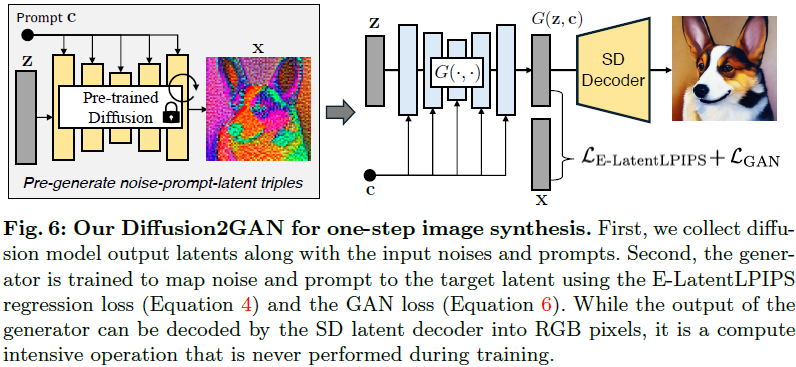
我们的目标是将预训练的文本到图像扩散模型蒸馏为一个单步生成器。也就是说,我们希望学习一个映射 x = G(z, c),其中单步生成器网络 G 将输入噪声 z 和文本 c 映射到扩散模型的输出 x。我们假设学生和老师共享相同的架构,因此我们可以使用老师模型的权重初始化学生模型 G。对于我们的方法部分,我们假设潜在扩散模型 [77] 中 x、z ∈ R^(4×64×64)。后来,我们还将我们的方法应用到 SDXL 模型 [71] 上。
3.1 用于一步生成的配对的噪声到图像翻译
随着扩散概率模型 [24,95] 的出现,Luhman 等人 [56] 提出,通过最小化以下蒸馏目标,预训练扩散模型的多步去噪过程可以减少到一步:
![]()
其中 z 是来自高斯噪声的样本,c 是文本提示,G 表示具有可训练权重的 UNet 生成器,x 是扩散模型的输出,模拟具有 DDIM 采样器的常微分方程(ODE)轨迹,d(·, ·) 是距离度量。由于获取每次迭代的 x 的计算成本,该方法在训练开始之前使用预先计算的(噪声,相应的 ODE 解)pairs。在训练期间,它随机抽样噪声-图像对,并最小化 ODE 蒸馏损失(公式 1)。虽然提出的方法看起来简单直接,但与更近期的蒸馏方法 [53, 60, 83, 93] 相比,直接蒸馏方法产生了较差的图像合成结果。
在我们的工作中,我们假设直接蒸馏的全部潜力尚未被实现。在 CIFAR10 上的实验中,我们观察到通过(1)扩大 ODE pair 数据集的规模和(2)使用感知损失 [106](而不是 Luhman 等人的像素空间 L2 损失),我们可以显著提高蒸馏的质量。在表 6 中,我们展示了在 CIFAR10 数据集上的训练进展,并将其性能与 Consistency Model [93] 进行了比较。令人惊讶的是,具有 LPIPS 损失的直接蒸馏可以在较小的总计算量下实现比 Consistency Model 更低的 FID,即使考虑到收集 ODE pairs 的额外计算量。

3.2 用于潜在空间蒸馏的组合的 LatentLPIPS
原始的 LPIPS [106] 观察到,来自预训练分类器的特征可以被校准得足够好,以匹配人类的感知响应。此外,LPIPS 在许多图像翻译应用中作为有效的回归损失 [67,98]。然而,LPIPS,设计用于像素空间,使用潜在扩散模型 [77] 时不够灵活。如图 4 所示,必须将潜在代码(latent code)解码到像素空间(例如,64 → 512 分辨率)才能使用带有特征提取器 F 和距离度量 ℓ 的 LPIPS 进行计算。
![]()
这违背了 LDM 的主要动机,即在更高效的潜在空间中运行。因此,我们能否绕过解码到像素的需求,直接在潜在空间中计算感知距离?
学习 LatentLPIPS。我们假设 LPIPS 的同样感知属性可以适用于直接在潜在空间计算的函数。按照 Zhang 等人的方法 [106],
- 我们首先在 ImageNet 上在 Stable Diffusion 的潜在空间中训练了一个 VGG 网络 [89],
- 但稍微修改了架构,删除了 3 个最大池化层,因为潜在空间已经 8× 下采样,并将输入更改为 4 个通道。
- 然后,我们使用 BAPPS 数据集 [106] 线性校准中间特征。
- 这成功地产生了在潜在空间中运行的函数:d_LatentLPIPS(x0, x1) = ℓ(F(x0), F(x1))。
有趣的是,我们观察到虽然在潜在空间中的 ImageNet 分类准确率比在像素上稍低,但感知一致性得到了保留。这表明,虽然将图像压缩到潜在空间会破坏一些有助于分类的低级信息 [28],但它保留了图像的感知相关细节,我们可以轻松地利用这些细节。附录 B 中有更多细节。

组合(Ensembling)。我们观察到,将 LatentLPIPS 直接应用为蒸馏的新损失函数会导致产生波浪状、斑块状的伪影。我们在一个简单的优化设置中进一步调查了这一现象,如图 5 所示,通过将随机抽样的潜在代码优化到单个目标图像。在这里,我们旨在使用不同的损失函数恢复目标潜在:
![]()
其中 x 是目标潜在,ˆx 是重建的潜在,d 是原始的 LPIPS 或 LatentLPIPS。我们观察到,在 LatentLPIPS 下,单个图像的重建不会收敛(图 5 (c))。我们假设这种限制是由于潜在版本的 VGG 网络形成了次优的损失景观。 受 E-LPIPS [38] 的启发,我们对生成的和目标潜在都应用了随机可微分的增强 [35,108]、通用几何变换 [35] 和切割 [11]。在每次迭代中,随机的增强都会应用到生成的和目标潜在上。当应用于单个图像优化时,组合策略几乎完美地重建了目标图像,如图 4 (d) 所示。新的损失函数称为组合-潜在 LPIPS,简称 E-LatentLPIPS。
![]()
其中 T 是一个随机抽样的增强。将该损失函数应用于 ODE 蒸馏:
![]()
其中,z 表示高斯噪声,x 表示其目标潜在。如图 4(右)所示,与其 LPIPS 对应物相比,由于(1)不需要解码到像素(在 A100 上为一个图像节省了 79 毫秒)和(2)(Latent)LPIPS 本身在比像素空间分辨率低的潜在代码上运行(38→8 毫秒),计算时间显著降低。虽然增强需要一些时间(4 毫秒),但总体上,我们的 E-LatentLPIPS 的感知损失计算几乎快了 10 倍(117→ 12 毫秒)。此外,内存消耗大大降低(15→0.6 GB)。
表 1 的实验结果表明,使用 E-LatentLPIPS 学习 ODE 映射导致更好的收敛性,显示出与其他指标(如 MSE、Pseudo Huber 损失 [27,92] 和原始 LPIPS 损失)相比更低的 FID。有关玩具重建实验和可微分增强的其他细节,请参阅附录 B。
3.3 条件扩散鉴别器
在第 3.1 和第 3.2 节中,我们阐明了扩散蒸馏可以通过将其构建为配对的噪声到潜在翻译任务来实现。受条件 GAN 用于配对的图像到图像翻译的有效性的启发,我们采用条件鉴别器。该鉴别器的条件不仅包括文本描述 c,还包括提供给生成器的高斯噪声 z。我们的新鉴别器结合了前述的条件,同时利用了预训练的扩散权重。形式上,我们优化了以下生成器 G 和鉴别器 D 的 minimax 目标:
![]()
对于生成器,我们最小化以下非饱和 GAN 损失 [15]。
![]()
生成器的最终损失为
![]()
我们提供了有关鉴别器和损失函数的更多细节。
初始化预训练的扩散模型。我们证明了使用预训练的扩散模型来初始化鉴别器权重对于扩散蒸馏是有效的。与使用 GigaGAN 鉴别器 [33] 的实现相比,使用预训练的 Stable Diffusion 1.5 U-Net [79] 并将该模型微调为潜在空间中的鉴别器,在表 2 中产生了更优异的 FID。对于 U-Net 鉴别器输出的每个位置,对抗损失都是独立计算的。请注意,原始的 U-Net 架构以文本为条件,但不以输入噪声图 z 为条件。我们进一步修改了鉴别器架构,以支持以 z 为条件,方法是在通道维度上添加零初始化的单个卷积层。请注意,扩散鉴别器的文本条件设置是通过 SD U-Net 中的内置交叉注意力层自然进行的。我们观察到在所有指标上都有适度的改善。
单样本 R1 正则化。虽然来自预训练扩散权重的条件 U-Net 鉴别器已经在 zero-shot COCO2014 [49] 基准测试中取得了竞争性结果,但我们注意到不同运行之间存在相当大的训练方差,这很可能是由于鉴别器的缺乏正则化和梯度无界性所致。为了缓解这一问题,我们在每个小批量上引入了 R1 正则化 [61] 来训练扩散鉴别器。然而,引入 R1 正则化会增加 GPU 内存消耗,这构成了一个实际挑战,尤其是当鉴别器是高容量 U-Net 时。为了最小化内存消耗并加速训练,我们不仅采用了间隔为 16 的懒惰正则化 [37],还仅对每个小批量的单个样本应用 R1 正则化。除了改善稳定性外,我们还观察到单样本 R1 正则化导致更好的收敛性,如表 2 所示。

多尺度 in-and-out U-Net 鉴别器。GigaGAN [33] 发现 GAN 鉴别器倾向于集中在特定频段,经常忽视高级结构,并引入了多尺度鉴别器来解决这个问题。类似地,我们提出了一种新的 U-Net 鉴别器设计,如图 7 所示,它强制在 U-Net 的各个段独立进行真/假预测。具体而言,我们修改了 U-Net 编码器,使其在每个下采样层接收调整大小的输入,并在 U-Net 解码器的每个尺度上附加三个读出层,以对 U-Net 跳过连接特征、从 U-Net 瓶颈进行上采样的特征和组合特征,进行独立的真/假预测。总的来说,新设计强制所有 U-Net 层参与最终预测,从浅层跳过连接到深层中间块。该设计增强了低频结构一致性,并显著增加了 FID,如表 2 所示。
混合匹配增强(Mix-and-match augmentation)。为了进一步鼓励鉴别器专注于文本对齐和噪声条件设置,我们引入了混合匹配增强用于鉴别器训练,类似于 GigaGAN [33] 和早期的文本到图像 GAN 作品 [74, 104]。在鉴别器训练过程中,我们将一部分生成的潜在替换为来自目标数据集的随机、不相关的潜在,同时保持其他条件不变。由于潜在与其配对的噪声和文本之间的对齐不正确,因此将被替换的潜在归类为假,从而促进了改进的对齐。此外,我们对文本和噪声进行替换,有助于整体提升条件扩散鉴别器。
4. 实验


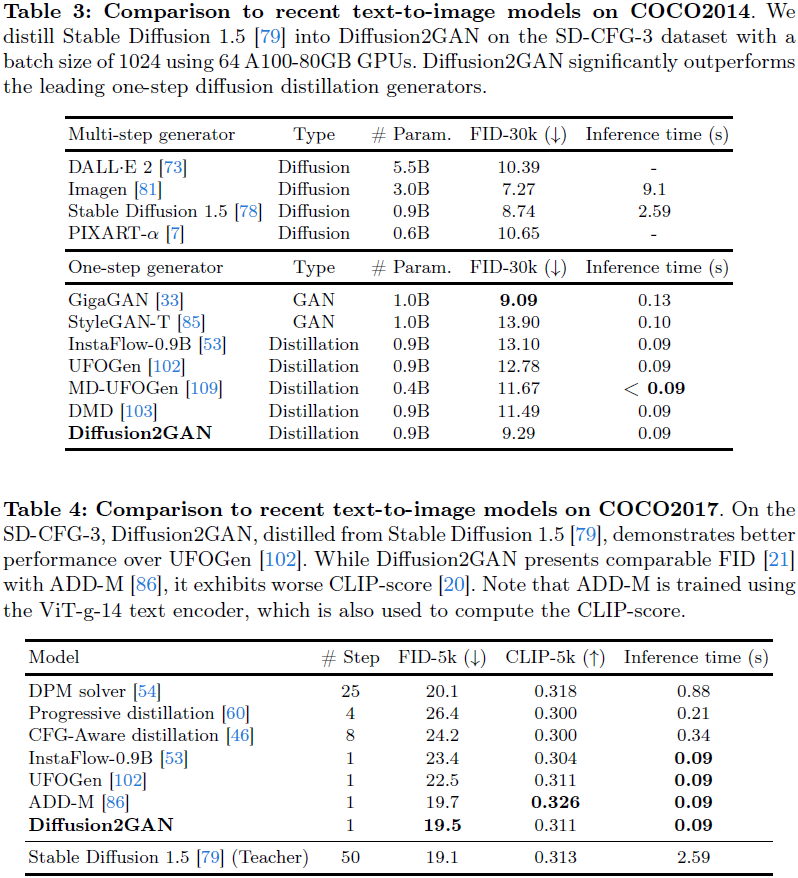
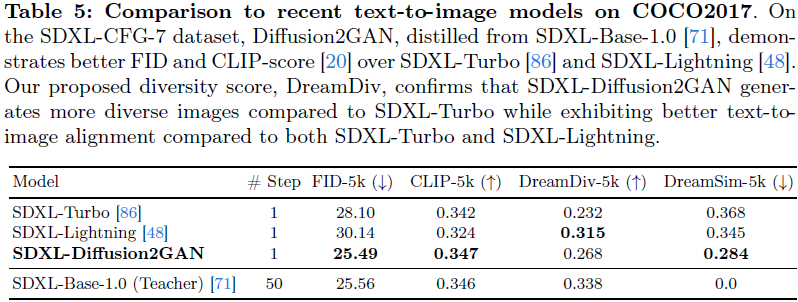
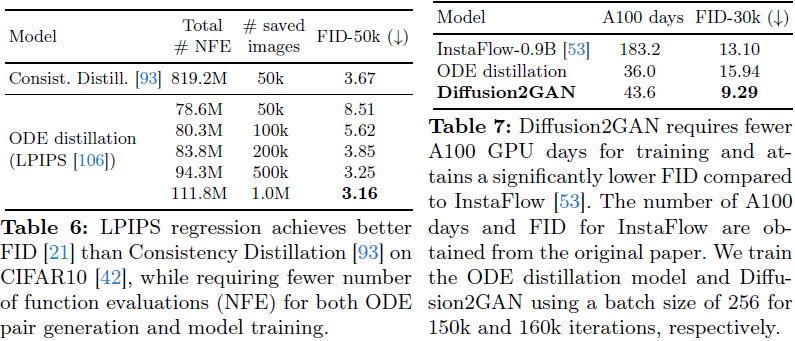



5. 讨论与局限性
我们提出了一个新的框架 Diffusion2GAN,用于将预训练的多步扩散模型蒸馏为一个使用条件 GAN 和感知损失训练的一步生成器。我们的研究表明,将生成建模分为两个任务——首先识别对应关系,然后学习映射——使我们能够使用不同的生成模型来改善性能和运行时的权衡。我们的一步模型不仅有利于交互式图像生成,还为高效的视频和三维应用提供了潜在的可能性。
局限性。虽然我们的方法在保持图像质量的同时实现了更快的推理,但它确实有一些局限性。
- 首先,我们当前的方法模拟了一个固定的无分类器指导尺度,这是一种用于调整文本依从性的常见技术,但在推理时不支持变化的 CFG 值。探索像引导蒸馏 [60] 这样的方法可能是一个有前途的方向。
- 其次,由于我们的方法蒸馏了一个教师模型,我们的模型的性能极限受到原始教师输出质量的限制。进一步利用真实的文本和图像对是学习一个超越原始教师模型的学生模型的潜在途径。
- 最后,虽然 Diffusion2GAN 通过引入 ODE 蒸馏损失和条件 GAN 框架缓解了多样性下降,但我们发现,当我们扩大学生和教师模型时,多样性下降仍然会发生。我们将进一步调查这个问题留给未来的工作。