摘要
嘴唇同步的任务(唇同步)寻求将人脸的嘴唇与不同的音频相匹配。它在电影行业以及创建虚拟化身和视频会议中有各种应用。这是一个具有挑战性的问题,因为人们需要同时引入详细、逼真的嘴唇动作,同时保持身份、姿势、情绪和图像质量。许多试图解决这个问题的先前方法由于缺乏完整的上下文信息而遭受图像质量下降。在本文中,我们提出了Diff2Lip,这是一种基于音频条件扩散的模型,它能够在保持这些质量的同时在野外进行嘴唇同步。我们在Voxceleb2上训练我们的模型,这是一个视频数据集,包含狂野的会说话的人脸视频。广泛的研究表明,我们的方法在用户的Frechet起始距离(FID)度量和平均意见得分(MOS)方面优于Wav2Lip和PC-AVS等流行方法。我们在Voxceleb2和LRW数据集上显示了重建(相同的音频-视频输入)以及交叉(不同的音频-图像输入)设置的结果。视频结果和代码可以从我们的项目页面访问
1 引言
奥斯卡获奖导演奉俊昊(Bong Joon Ho)著名地指出,字幕是不擅长语言的外国观众与他们充分欣赏精彩电影的能力之间的障碍[1],因为观众需要专注于观看和阅读。一种很少被探索的替代品,多语言版本电影(MLV),其中同一部电影以多种语言并行拍摄,自然要贵得多[49]。虽然配音是一种流行的折衷解决方案,但由于语音和演员视频之间缺乏同步,它可能会让人感觉不自然。作为一种更便宜的替代方案,嘴唇同步(lip-sync)旨在生成人脸的口腔区域,使得嘴唇对应于不同的语音音频。它在电影之外的应用包括教育、虚拟化身和视频会议。理想情况下,唇同步应该支持来自看不见的来源的任何身份和音频(在野外环境中)。这种设置带来了在保持逼真嘴唇同步的同时保持演员身份、姿势、情绪和视觉质量的挑战。
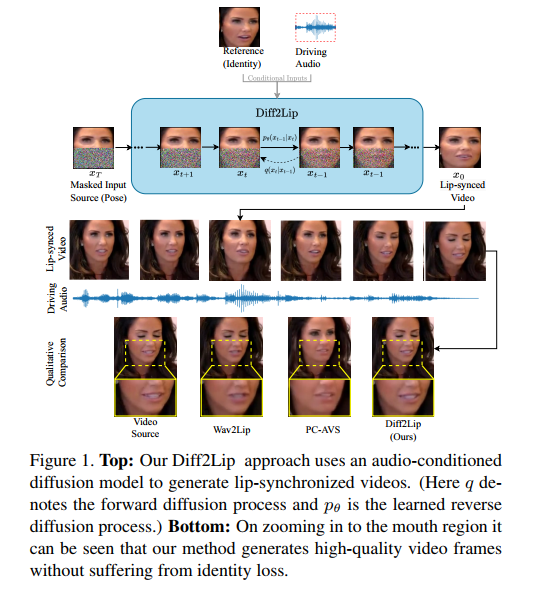
图1。顶部:我们的Diff2Lip方法使用音频条件扩散模型来生成嘴唇同步视频。(这里q表示正向扩散过程,pθ是学习的反向扩散过程
最早的唇同步方法之一,视频重写[2],有一个专门构建的解决方案,将音素映射到口型,然后将它们混合到目标视频中。现代技术有更通用的解决方案,但存在一定的局限性。例如,PC-AVS[58]和GCAVT[28]分别解开姿势和表情,但无法保持身份(图1底部),视觉质量较差,并且存在边界不一致(同时将生成的头部放回场景)。另一方面,针对特定身份的作品,需要视频/身份特定训练。其他依赖于提取中间表征的方法,例如MakeItTalk中的关键点,必须处理这些表征中的估计误差。最终,能在野外环境中普及的唇部同步方法将其视为一种修复任务,在该任务中,嘴部区域被遮盖,然后基于音频进行重建。例如,Wav2Lip实现了良好的唇部同步效果,但牺牲了视觉质量(见图1底部);AV-CAT虽有多级处理流程,但无法捕捉更细微的细节。在本文中,我们介绍了Diff2Lip,这是一种采用扩散模型的修复风格方法,用于解决唇同步任务,它克服了大多数缺点,并实现了视觉上优越的唇部同步效果。
我们提出了一种音频条件扩散模型来解决唇同步任务(见图1顶部)。扩散模型是基于概率的模型,能在数据变化较大的数据集(例如ImageNet)中生成惊人的结果,这是GANs无法比拟的。为了在野外环境中具有泛化能力,我们将问题定义为一个基于条件扩散模型的图像修复任务。Diff2Lip接受三个输入:一个遮蔽的输入帧、一个参考帧和一个音频帧,并输出同步的嘴部区域。Diff2Lip利用(1)遮蔽的输入帧来获取姿势上下文;(2)参考帧来获取身份和嘴部区域的纹理;(3)音频帧来驱动唇形。通过一个音频+图像条件的扩散模型,Diff2Lip在所有这些上下文输入信息之间保持了细微的平衡,避免了唇同步问题(例如身份丢失、参考复制、唇形不准确)。Diff2Lip优化三种损失:重建损失指导合成;同步专家损失强化同步;序列对抗损失强化帧间连续性。如图1底部所示,Diff2Lip生成的图像质量高,没有身份丢失或泛化问题。
我们在常用的Voxceleb2和LRW数据集上评估了我们的工作,这些数据集用于重建和交叉生成任务(见第4节)。我们与用于唇同步的流行方法如Wav2Lip和PC-AVS进行了比较。广泛的评估显示,Diff2Lip在图像保真度方面超越了现有方法,同时具有可比的同步性。以下是本工作的贡献:
- 我们提出了一种基于扩散模型的新颖方法,用于音频条件的图像生成。
- 通过使用逐帧和序列损失,我们能够成功生成高质量的唇同步。
- 我们展示了使用序列对抗性损失使得在帧间的扩散模型视频生成更为稳定。
- 广泛的评估验证了我们的生成在FID指标和用户的平均意见得分(MOS)上超越现有方法,显示了Diff2Lip的有效性。
2 相关工作
在本节中,我们首先讨论现有的唇部同步方法,然后探讨条件扩散模型。
2.1 唇部同步
唇部同步方法大致可以分为以下四类。请注意,这些分类之间可能会有重叠:
-
基于嵌入的头部重建方法。这类方法倾向于通过融合语音和身份特征来合成整个头部。这通常使用编码器-解码器风格的架构来完成。例如,Song等人[45]和Vougioukas等人[50]使用RNN,而Speech2Vid[7]使用CNN。LipGAN[25]使用音视频鉴别器来改善同步效果。PC-AVS[58]执行身份、语音和姿态的解耦,以实现完全的姿态控制。GC-AVT[28]额外解耦情感。最近的现代作品如DiffTalk[41]使用潜在扩散模型来实现高视觉质量,但以牺牲唇部同步为代价,跨生成的效果更差。这种方法还需要使用地标进行正确的面部定位,使用不能并行化的自回归推理策略,并且由于存在抖动,采用外部帧插值方法。通常,这些方法生成完整面部时,将生成的头部重新放回帧时会遇到边界一致性问题。
-
基于中间表示的方法。这些方法学习操纵稀疏的中间表示,如面部地标或网格。Chen等人[6]和Das等人[11]生成的面部是基于音频估计的地标条件的。MakeItTalk[59]提出根据音频预测说话者地标的位移。像Song等人[44]、Yu等人[55]和Xie等人[54]使用3DMM(面部网格)生成面部视频。Neural Voice Puppetry[48]使用音频预测3D模型的表情基础系数。Zhang等人[57]提出首先预测基于3DMM的动画参数,然后将其转换为用于面部动画的密集流。尽管这些方法利用中间结构进行唇部同步,手动获取这些表示昂贵,自动预测容易出错。此外,由于表示稀疏,它们也倾向于丢失更细微的细节。
-
个性化方法。在这类方法中,模型被训练为特定于身份甚至是特定于视频[27]。例如,SynthesizingObama[47]只关注使用音频到地标网络的奥巴马的唇部同步。MEAD[24]利用边缘,而Lu等人[30]使用面部地标创建类似边缘的条件特征图来生成说话的面孔。像Song等人[44]、Zhang等人[57]和Neural Voice Puppetry[48](之前讨论过的)等使用音频驱动的表情操作(3DMM)也属于此类。一些方法还处理显式的3D网格顶点变形,如LipSync3D[26]。基于NeRF的模型,如ADNeRF[16]和SSPNeRF[29],也是特定于个人的。这类方法有时展示高视频质量,但需要每次针对特定人物和环境重新训练模型。
-
基于修补的方法。在这些方法中,不是生成整个面部,而是只修改受语音影响的面部下部。这些模型在将嘴部部分粘贴回整个帧时,不会遇到图像
2.2 条件扩散模型
在这一领域的初步研究涉及到图像生成的类别条件。例如,Ho & Salimans [20] 使用类别标签来训练扩散模型,通过在有条件和无条件输出之间插值。而导向扩散(Guided-diffusion)[13] 使用分类网络进行类别条件化,以实现更好的图像生成。像GLIDE [32]、DALLE-2 [36]、Stable-Diffusion[37]和IMAGEN [40]等方法利用语言模型仅通过文本提示输入生成逼真以及其他多种风格的图像。还有一些研究涉及文本到视频的生成,如视频扩散模型(Video Diffusion Models)[21]以及更逼真的模型如Gen-1 [14]。近期,随着扩散模型的流行,人们还提出了像Noise2Music [22]这样的模型,可以仅通过文本提示生成音乐。也有一些关于图像条件扩散模型的工作。Palette [39] 是一个通用的图像到图像生成框架,能够解决如上色、修补、扩画、JPEG恢复等任务。我们也将问题定义为一种修补风格的扩散任务,但增加了音频和参考身份条件的输入。
3 方法
在本节中,我们讨论了我们提出的方法 - Diff2Lip。我们提出了一种新颖的音频和图像条件扩散模型,该模型能够合成高质量、与音频输入相对应的唇同步嘴部。我们在第3.1节讨论扩散模型。然后在第3.2节介绍我们的方法。最后,在第3.2.1节,我们讨论了训练我们模型所需的损失。
3.1 扩散模型
扩散模型[19]是基于似然的模型,试图通过逐步去噪随机高斯噪声,经过T步骤采样给定分布的点。在前向扩散过程中,逐步向样本点x0迭代添加越来越多的噪声,如x0 → x1 → · · · → xt−1 → xt → · · · → xT−1 → xT,以获得完全嘈杂的图像xT。正式地,前向扩散过程是一个马尔可夫加噪过程,由一系列噪声规模![]()
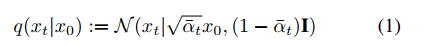
可被重写为
![]()
其中ϵ是噪声,N表示正态分布,x0是原始图像,xt是经过t步扩散过程后的噪声图像。逆向扩散过程旨在学习后验分布q(xt−1|x0, xt),使用该分布可以估计给定xt的xt−1。这通常通过一个神经网络完成,该网络可以以多种方式参数化。类似于[13, 19, 33],我们选择参数化神经网络以预测噪声,即ϵθ(xt, t),其中θ代表神经网络的参数。它接受一个噪声样本xt和时间步t来预测方程2中添加的噪声ϵ。模型的学习使用[19]中简化的目标,该目标重新权衡最大似然目标的变分下界:
![]()
后验分布q(xt−1|x0, xt)也可以使用贝叶斯规则追踪,并且最终是另一个正态分布。使用DDIM[43]进行抽样时,我们可以通过忽略方差确定性地抽样后验。由于我们可以使用方程2将x0表示为xt和ϵ的函数,因此我们可以确定性地恢复xt−1,给定xt和ϵ使用:
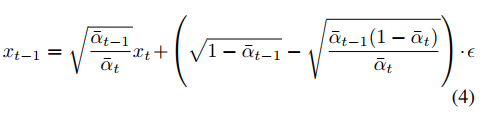
这个方程代表了在DDIM[43]公式中学习到的后验分布pθ(xt−1|xxt)的均值。在推断时进行采样时,xT从标准正态分布中采样。然后神经网络可以恢复需要去除的噪声ϵθ。这反过来可以输入到方程4中,以恢复xT−1。通过这种迭代,可以获得干净的图像,如xT → xT−1 → · · · → xt → xt−1 → · · · → x1 → x0,如图3顶部所示。 符号说明。在本文中,我们处理扩散过程和视频。我们使用t表示扩散过程的步骤编号,而使用s表示视频帧编号。对于扩散过程,我们保持这里的符号与[33]相同。

3.2. 所提方法
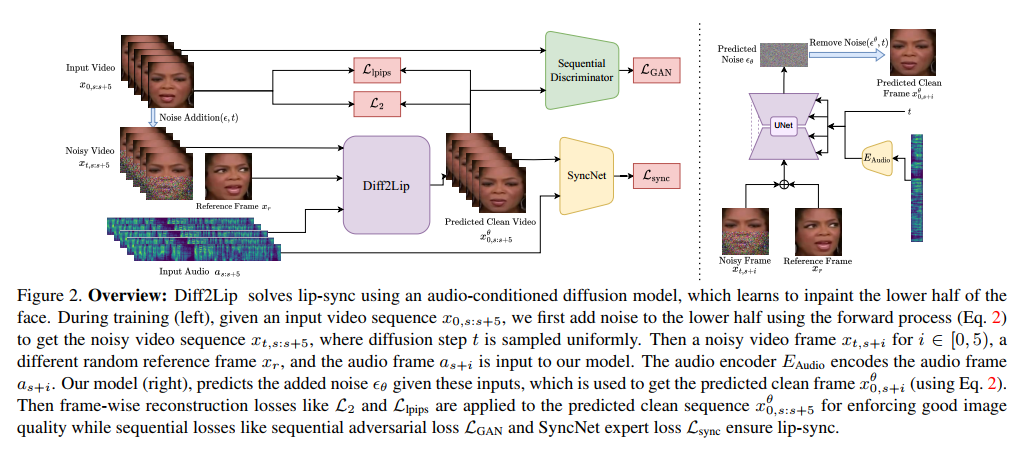
Figure 2. Overview: Diff2Lip通过使用一个受音频条件驱动的扩散模型来解决唇部同步问题,该模型学习对脸部下半部分进行修补。在训练阶段(左侧),给定一个输入视频序列x0,s:s+5,我们首先使用前向过程(方程2)向脸部下半部分添加噪声,得到噪声视频序列xt,s:s+5,其中扩散步骤t是均匀采样的。然后将一个噪声视频帧xt,s+i(对于i ∈ [0, 5)),一个不同的随机参考帧xr,以及音频帧as+i输入到我们的模型中。音频编码器EAudio对音频帧as+i进行编码。我们的模型(右侧)预测给定这些输入的添加噪声εθ,该噪声用于获取预测的干净帧xθ0,s+i(使用方程2)。然后对预测的干净序列xθ0,s:s+5应用逐帧重建损失,如L2和Llpips,以确保良好的图像质量,同时序列损失如序列对抗损失LGAN和SyncNet专家损失Lsync确保唇部同步。
| 关键组成部分 | 详细说明 |
|---|---|
| 问题定义 | 将唇部同步问题定义为下半部面部的修复任务,需要根据遮盖的面部、音频输入和参考帧输入来生成遮盖区域的图像。 |
| 输入数据 | 视频V由S帧组成,每一帧vs与对应的音频帧as结合,每次处理一个视频帧x0,s。 |
| 扩散模型设置 | 使用噪声遮罩的视频帧xs,T(完全噪声化的帧)作为输入,结合音频帧和随机参考帧进行逆向扩散过程以恢复原始帧vs。 |
| 参考帧选择 | 随机参考帧xr从同一视频中选择,提供关于源身份和姿态的线索,确保其不同于输入帧以避免训练时的信息泄露。 |
| 音频输入处理 | 音频输入通过组归一化处理,提供有关唇形结构的信息。 |
| 神经网络结构 | 使用具有残差块和注意力块的UNet网络作为主干,从未遮盖的输入帧和参考帧中提取上下文信息。 |
| 音频条件编码 | 使用可训练的音频编码器EAudio来编码音频,生成的嵌入作为条件输入。 |
| 训练方法 | 在训练过程中,首先取一个干净的样本帧xs,0(= vs),添加噪声得到xs,t,模型训练预测添加到其中的噪声。 |