目录
1.VMware 的配置
2.JDK的部署
3.防火墙,SElinux,时间同步设置
4.云平台
5.阿里云
6.UCloud
7.Hadoop理论
7.1 Hadoop理论
7.2 VMware Hadoop实践
7.3集群部署常见问题解决
7.4 云服务器上 Hadoop实践
7.5 HDFS 的 shell
7.6HDFSShell解决权限不足
7.7 JetBrains使用插件
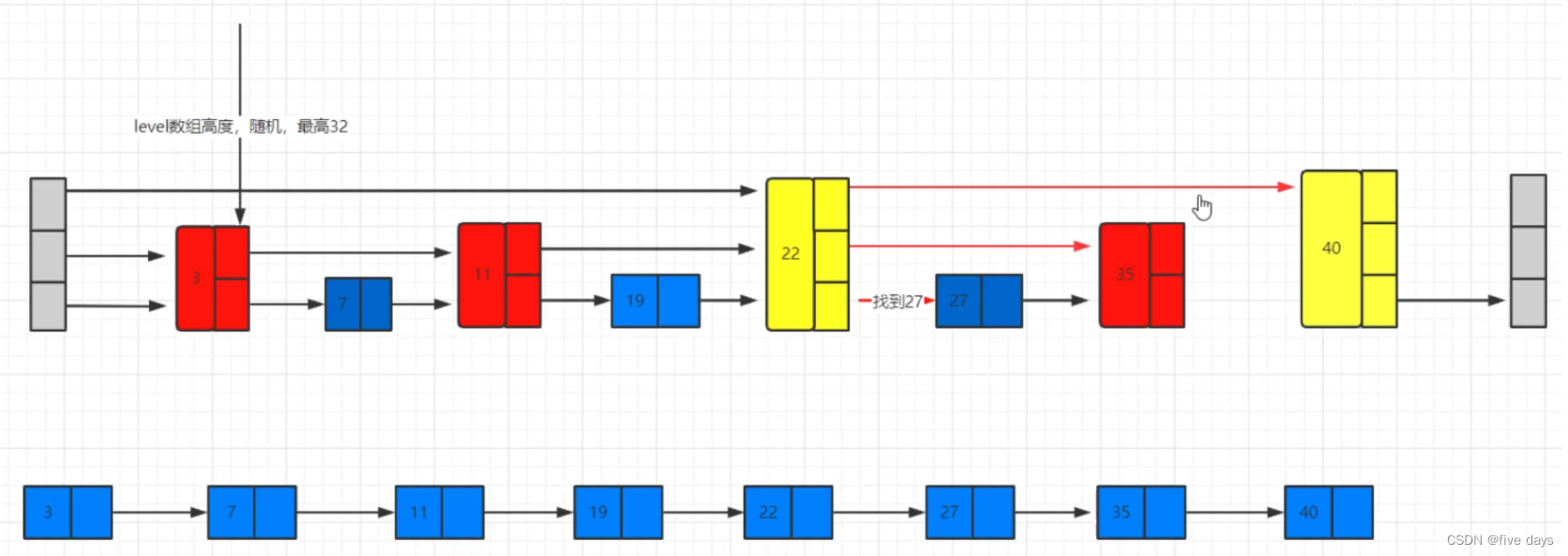
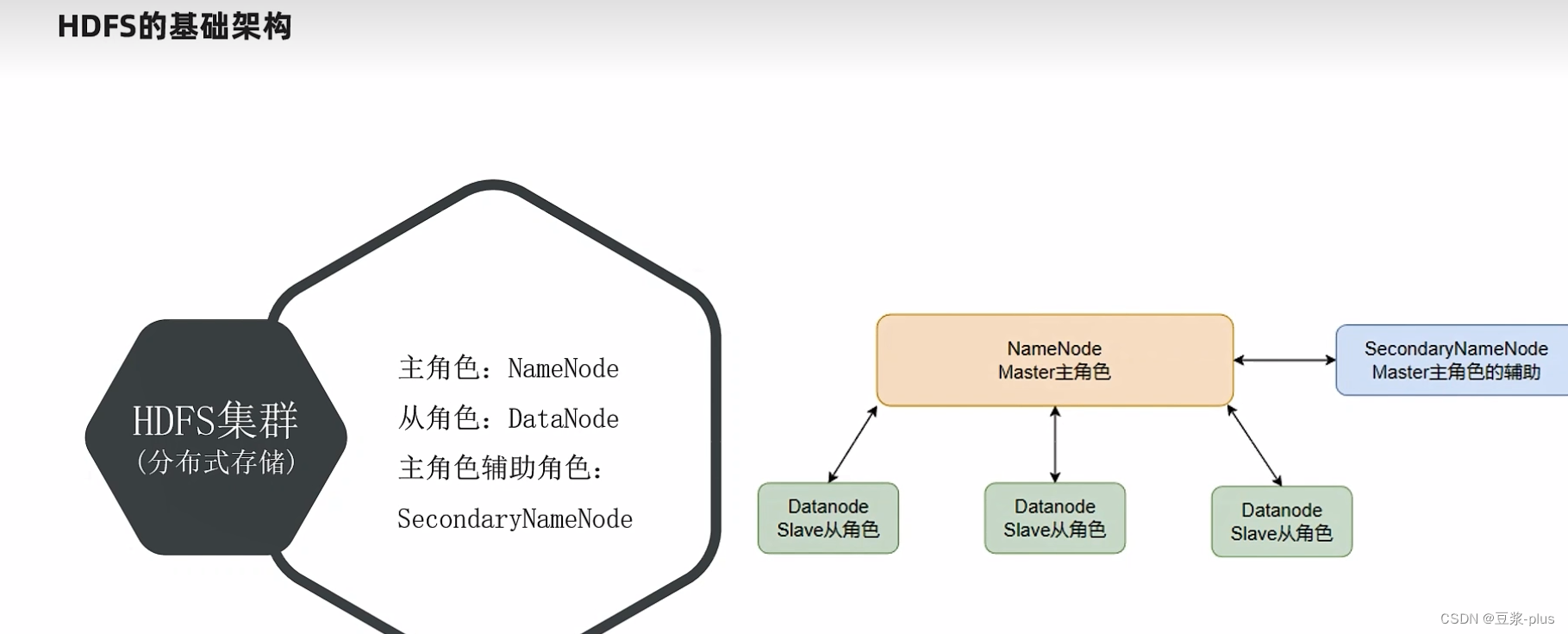
8 HDFS的存储原理
9.MapReduce
10. YARN
10.1 YARN 理论
10.2 YARN 实践
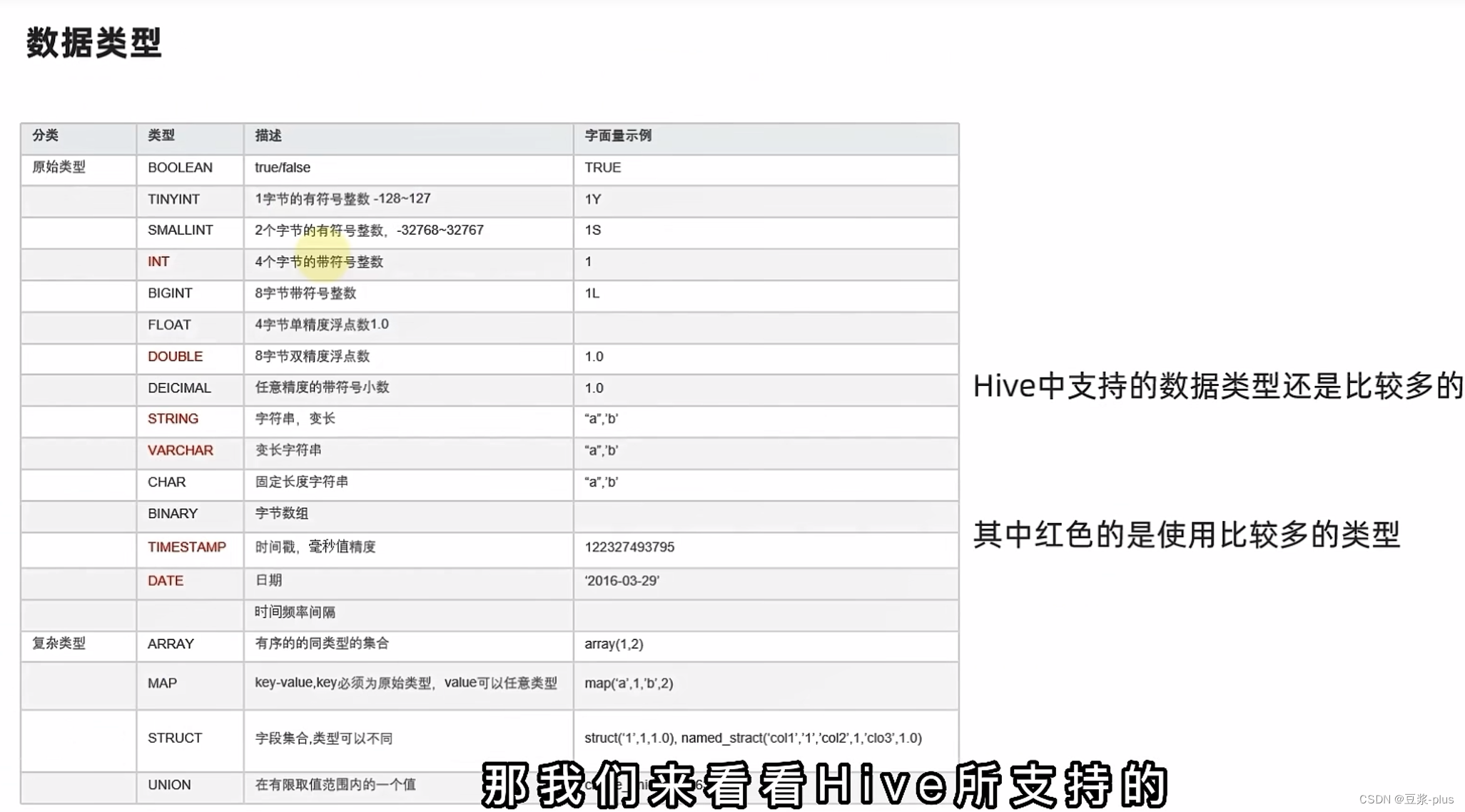
Hive理论
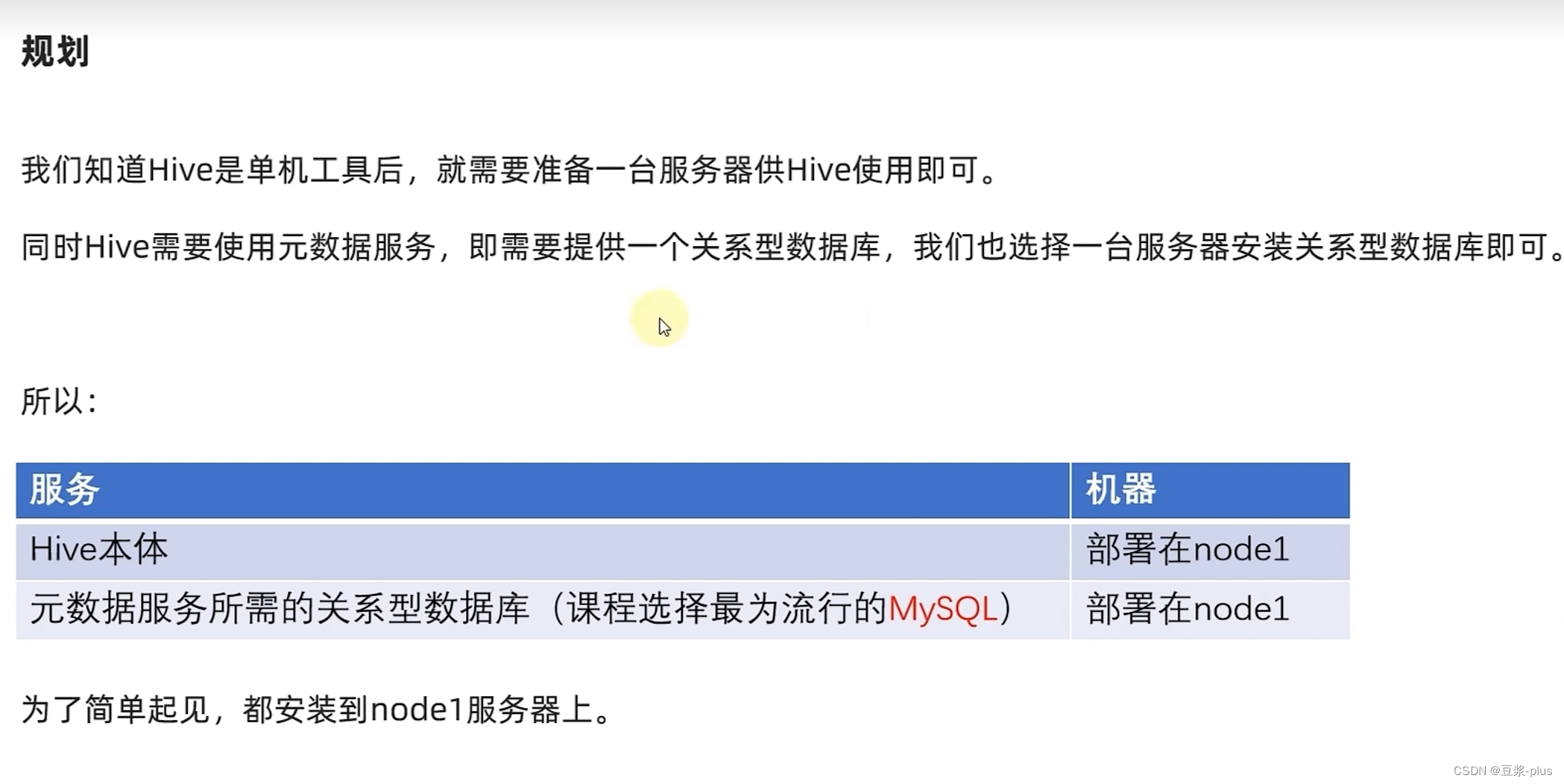
1.Hive理论编辑
2.Hive部署
3.Hive初体验
4.Hive 客户端
5.Hive 原理
BV1WY4y197g7
1.VMware 的配置
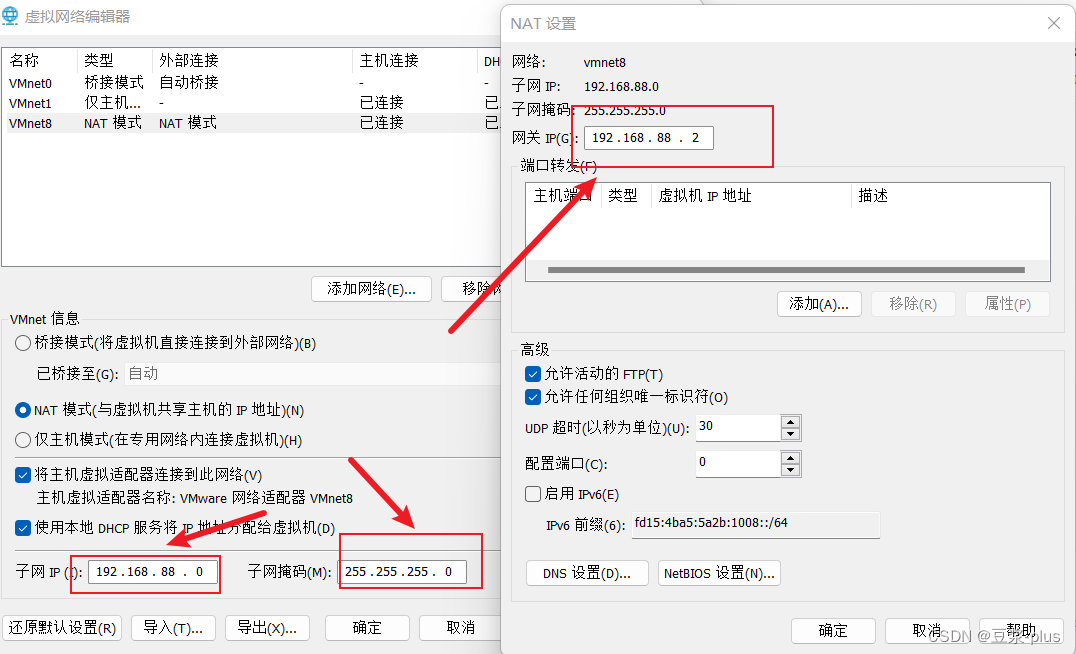
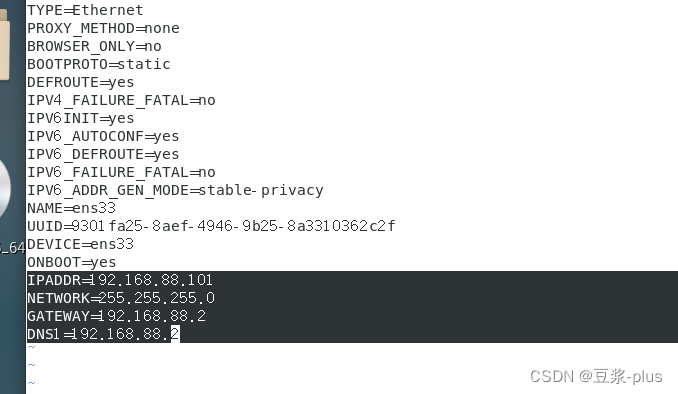
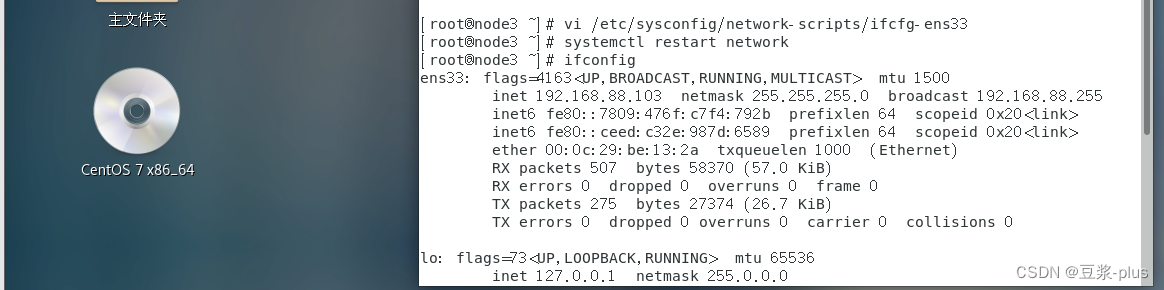
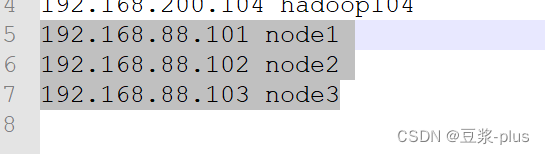
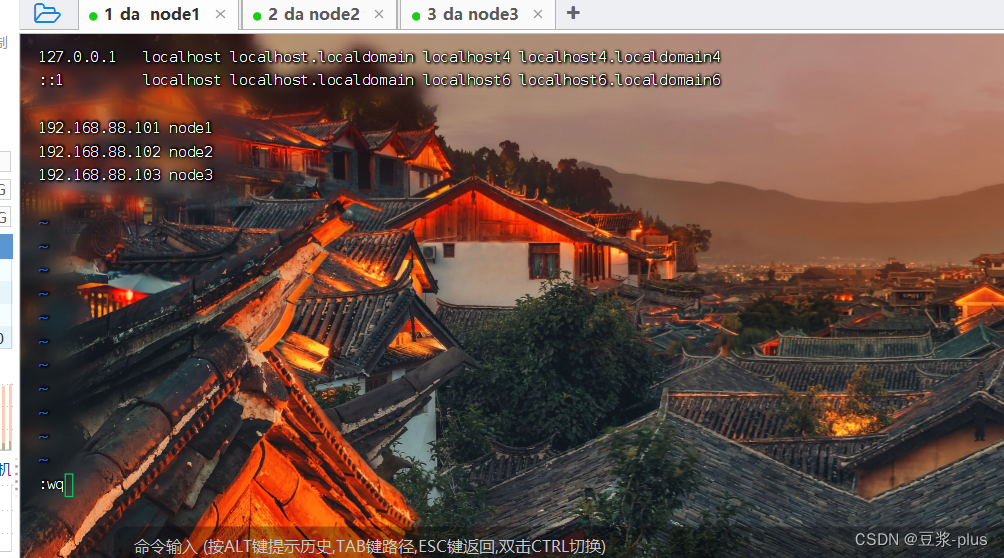
免密登录:

ssh-keygen -t rsa -b 4096ssh-copy-id node1ssh node2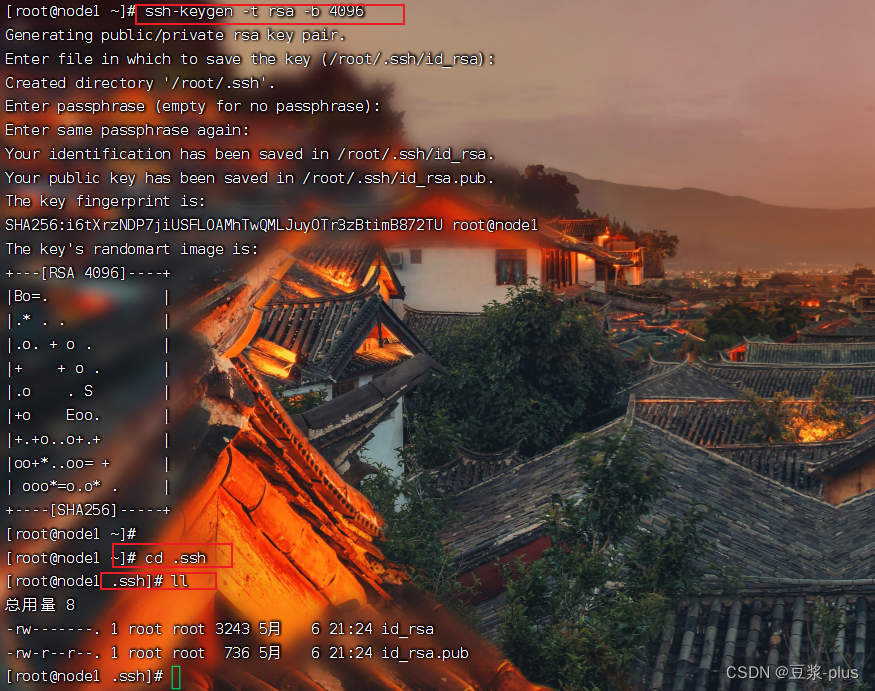


2.JDK的部署


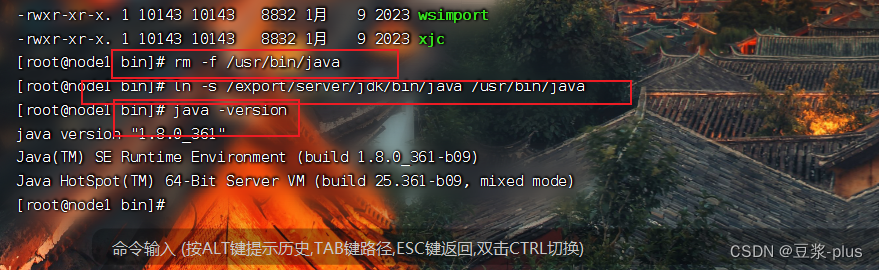
ln -s /export/server/jdk1.8.0_361 jdk3.防火墙,SElinux,时间同步设置
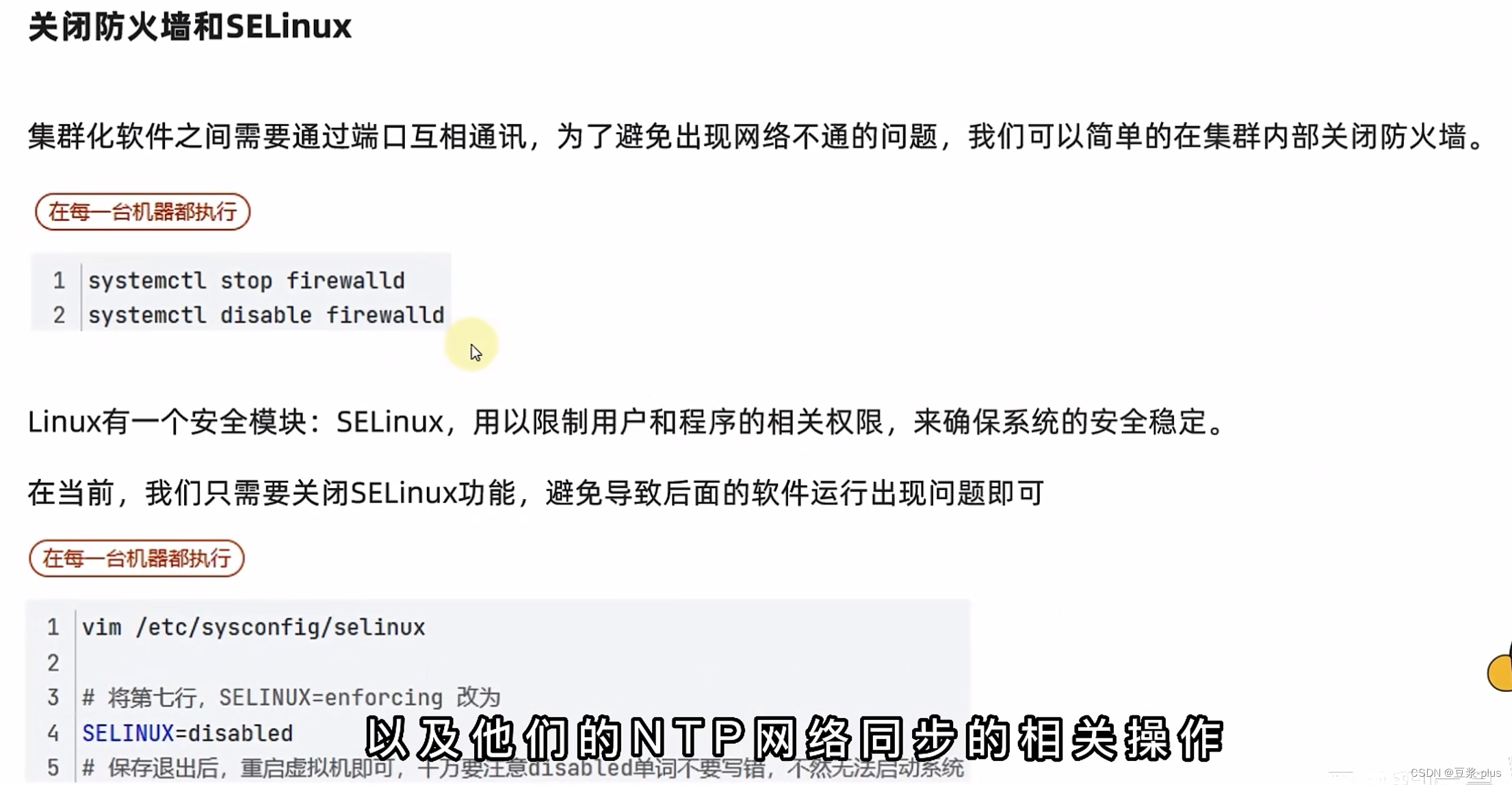
(为访到)关闭防火墙:
systemctl stop firewalld.service禁止防火墙开机启动
systemctl disable firewalld.service 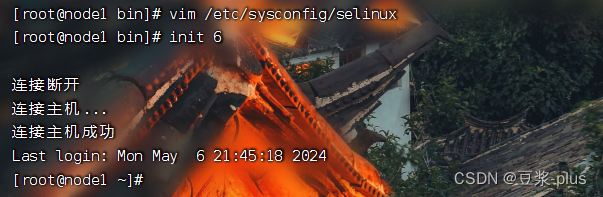

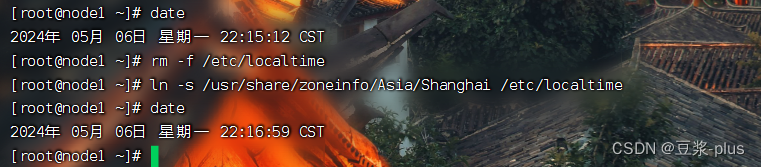
4.云平台
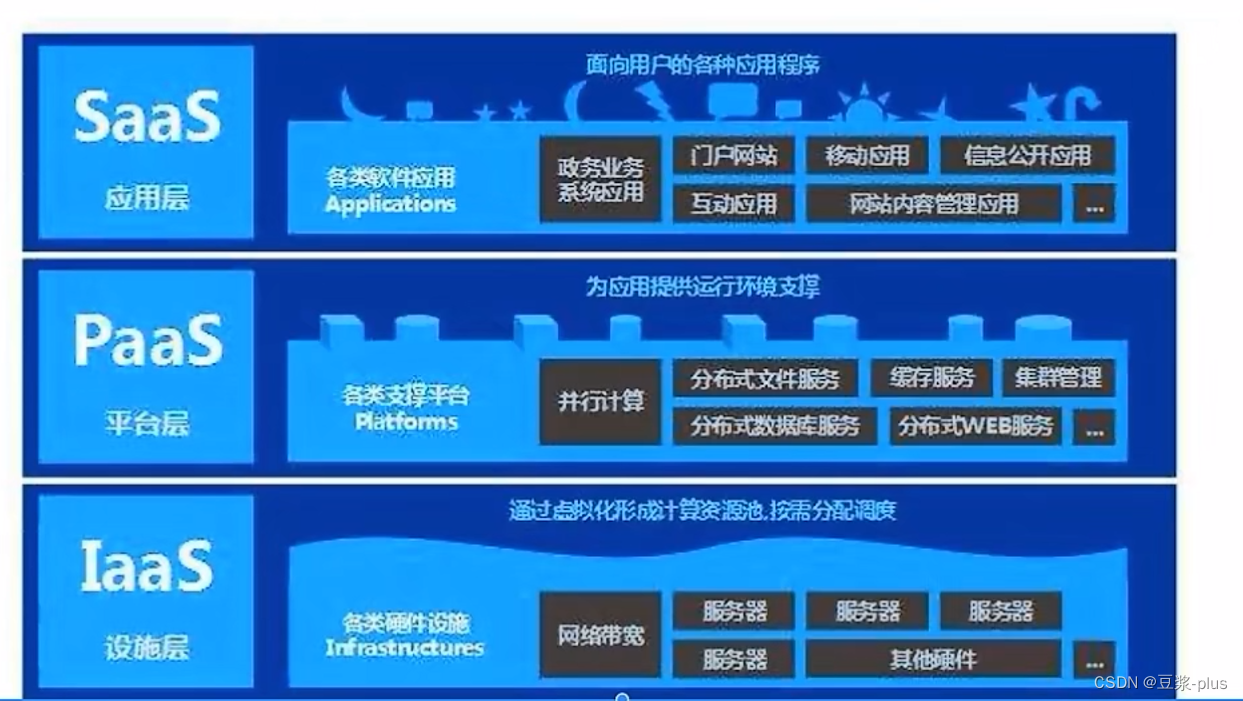
什么是云平台
云平台也称云计算平台。云计算,顾名思义,就是将计算在云上运行。
那么在这里面的3个概念
- 云:通俗的理解就是远程计算机,并且是一组 一堆,这些远程计算机协同工作构建出一个平台,对用户提供服务
- 计算:这是一个概念很大的名词,小了说可以认为是对业务数据进行计算分析的算力,不过通俗意义上,计算是指构建业务系统的各种需求
- 平台:将云(远程硬件资源)和计算(远程软件资源)组合在一起,就形成了一个平台,对用户提供各种各样的服务。
我们可以这样理解,云平台是:一个云上的平台,聚合了一些软硬件资源,为用户提供各种各样的远程服务





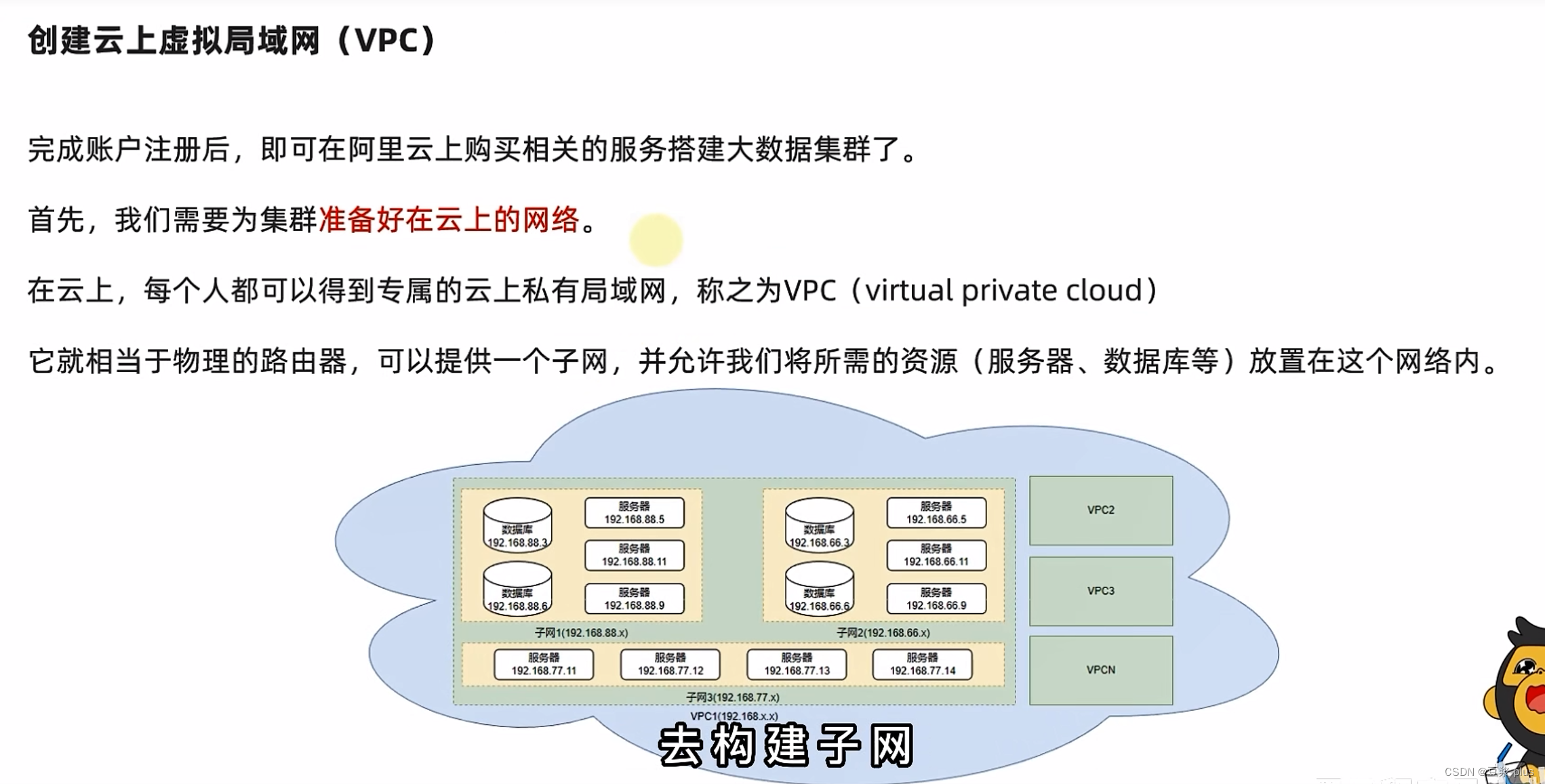
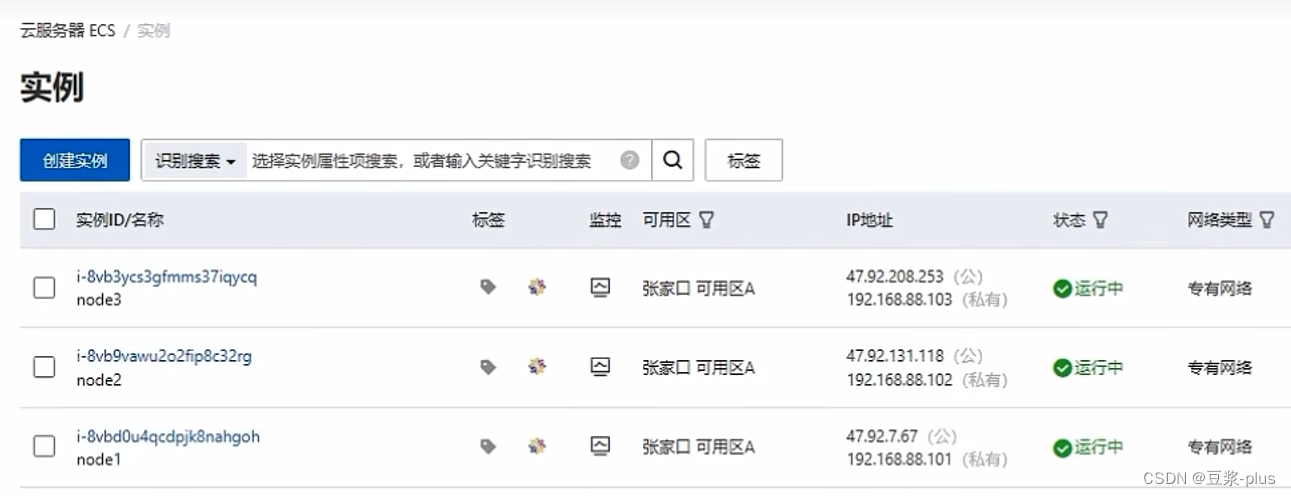
5.阿里云
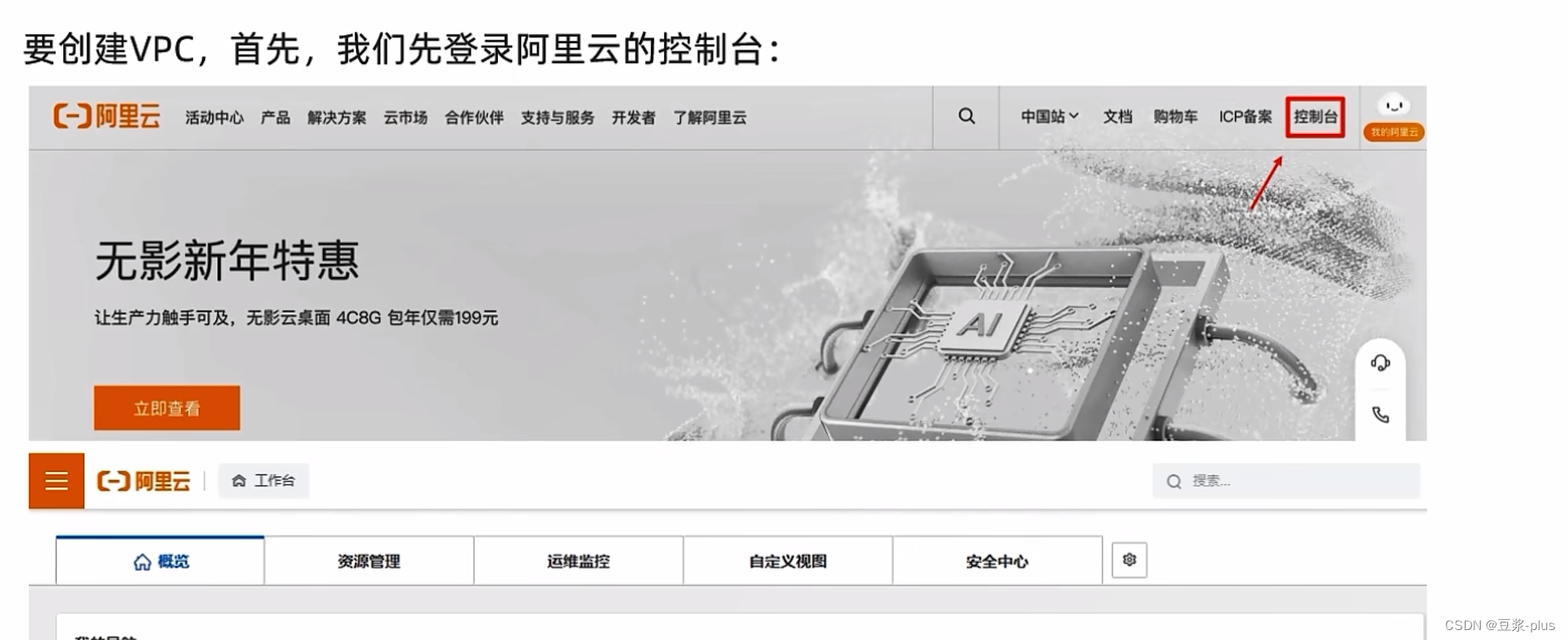
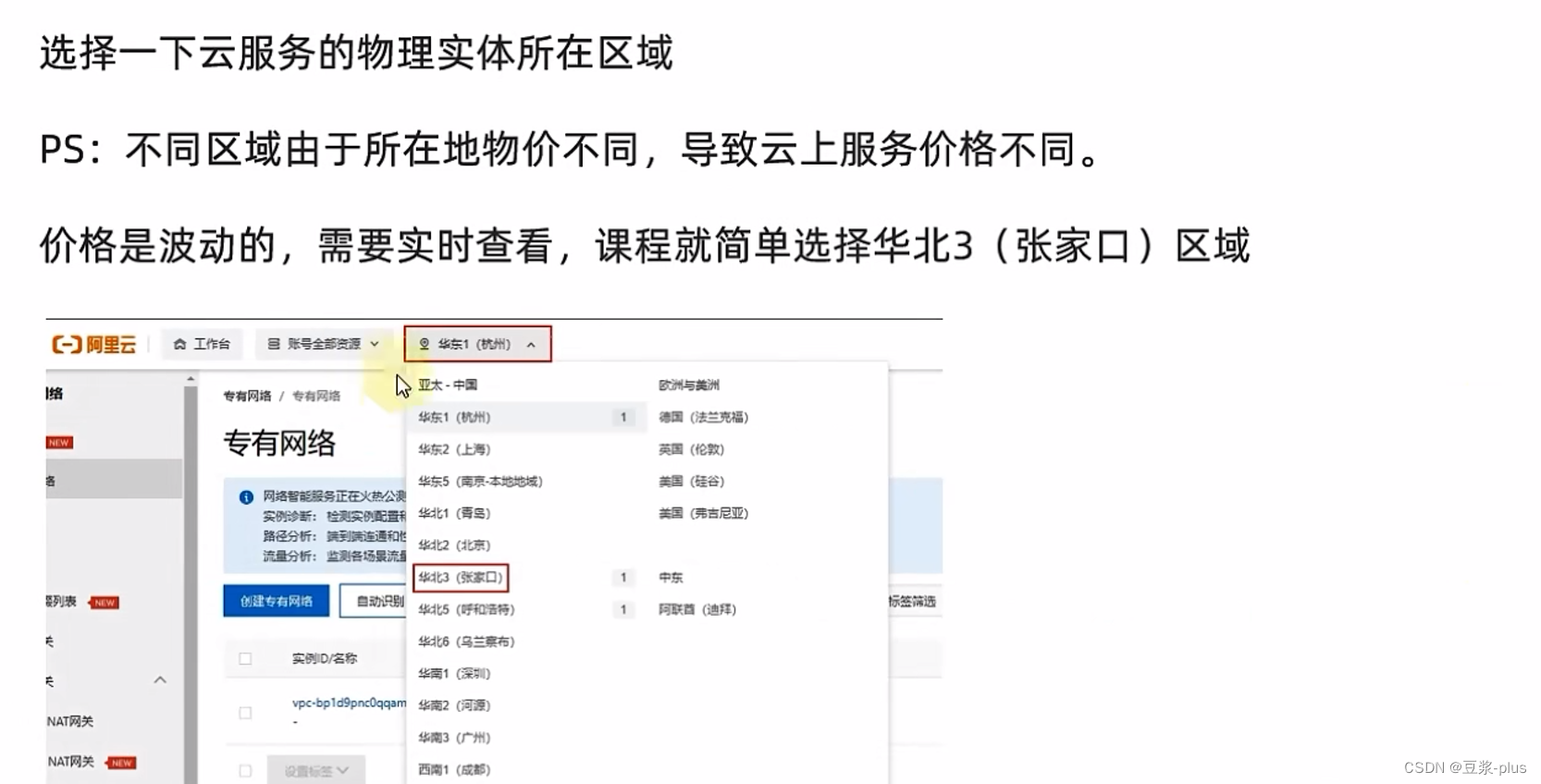
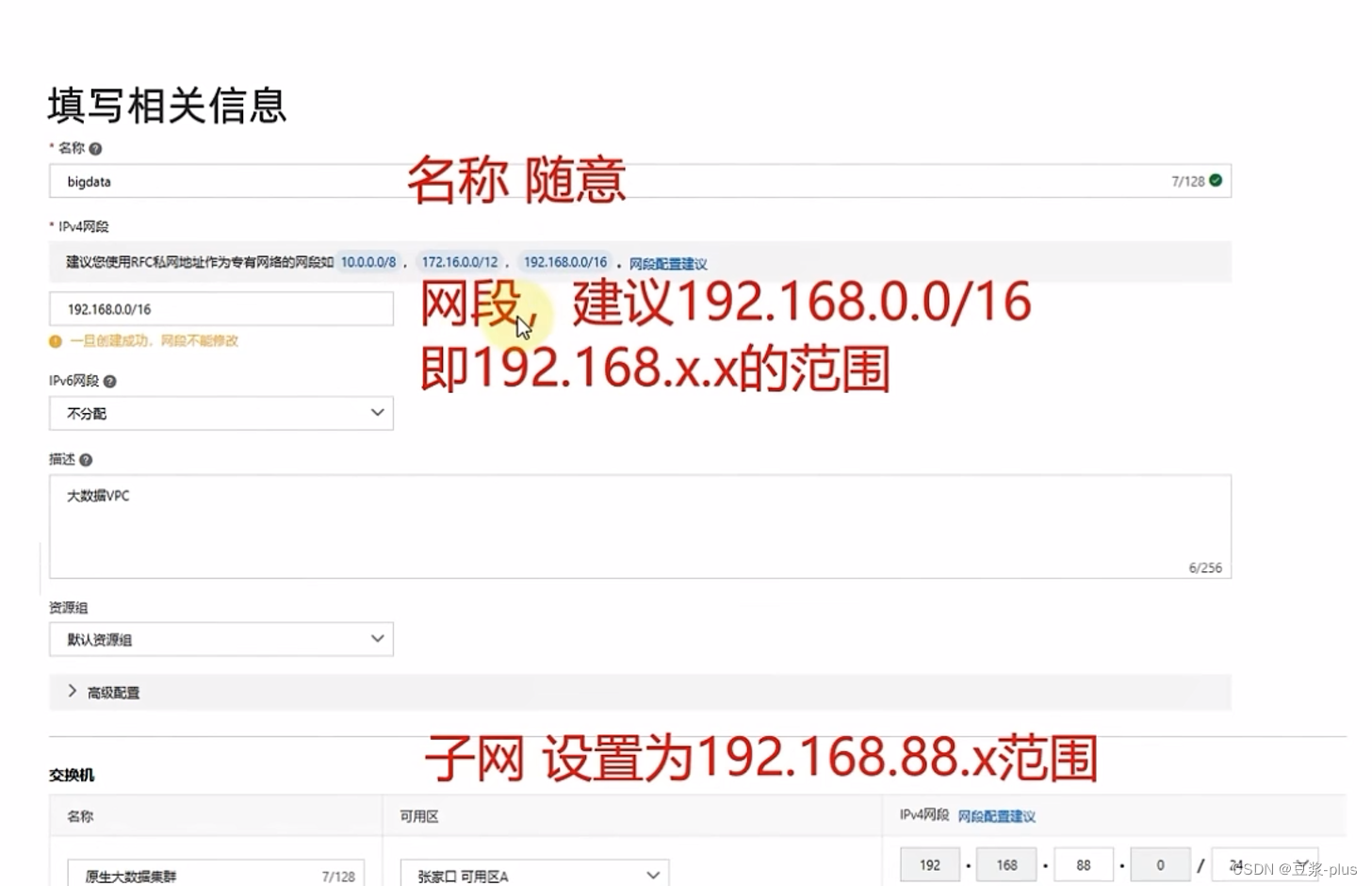
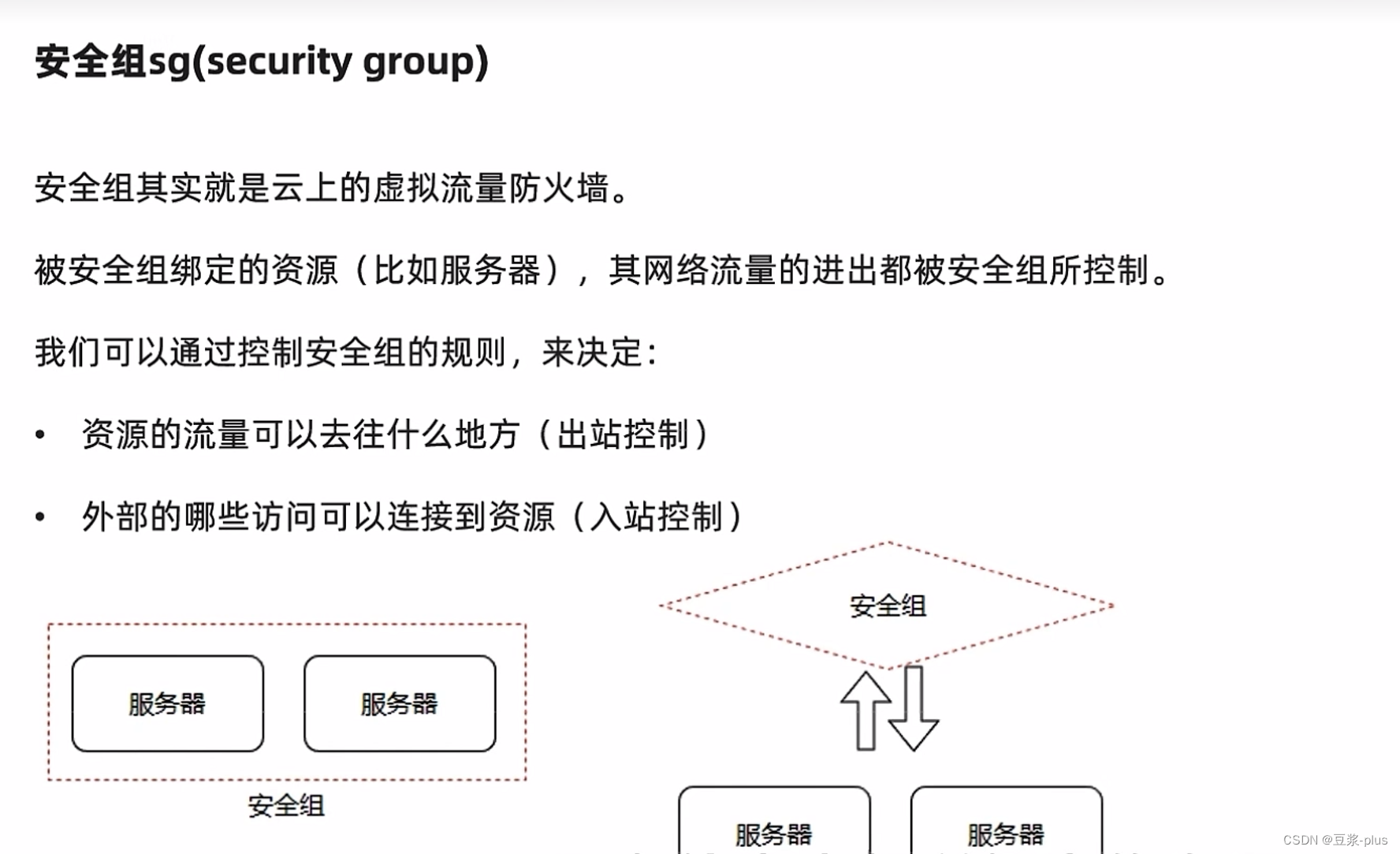


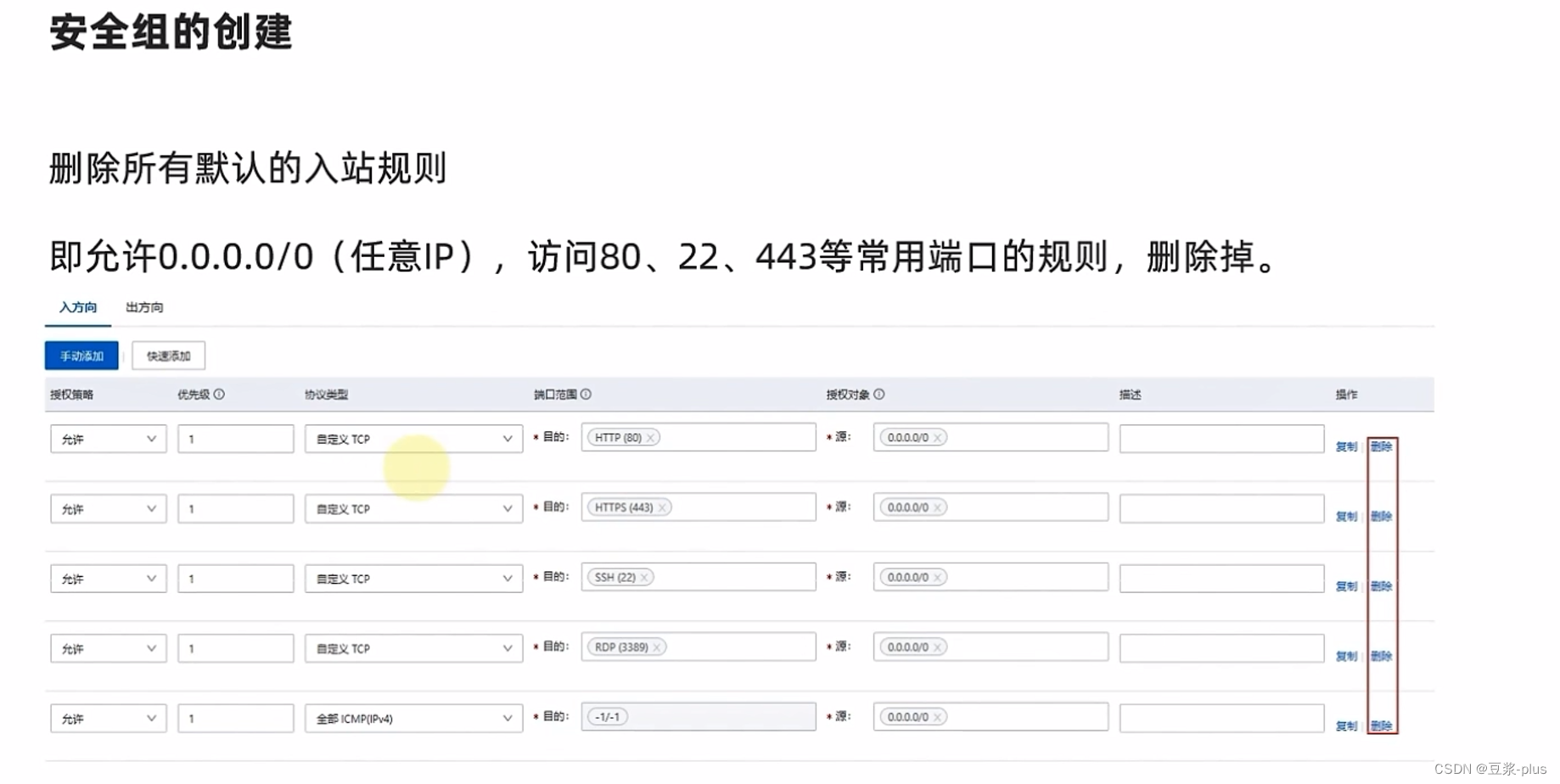
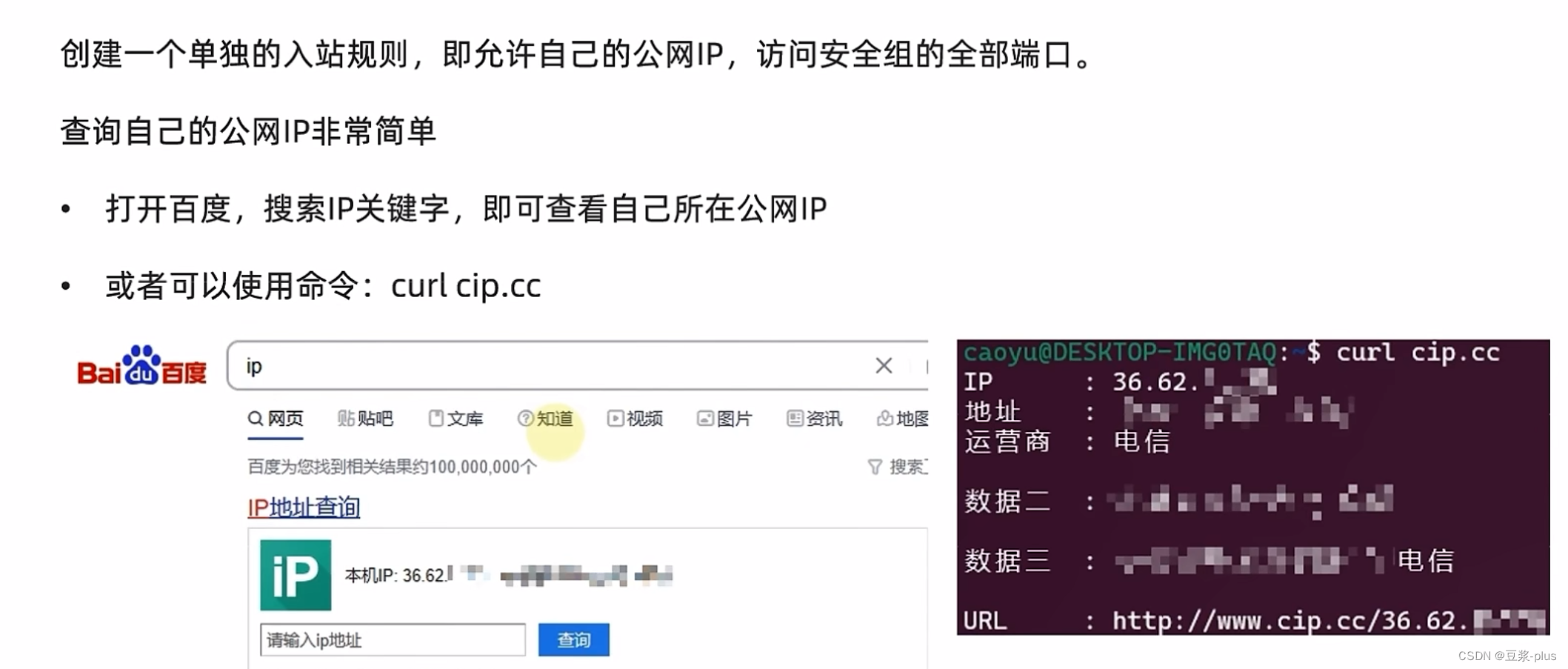
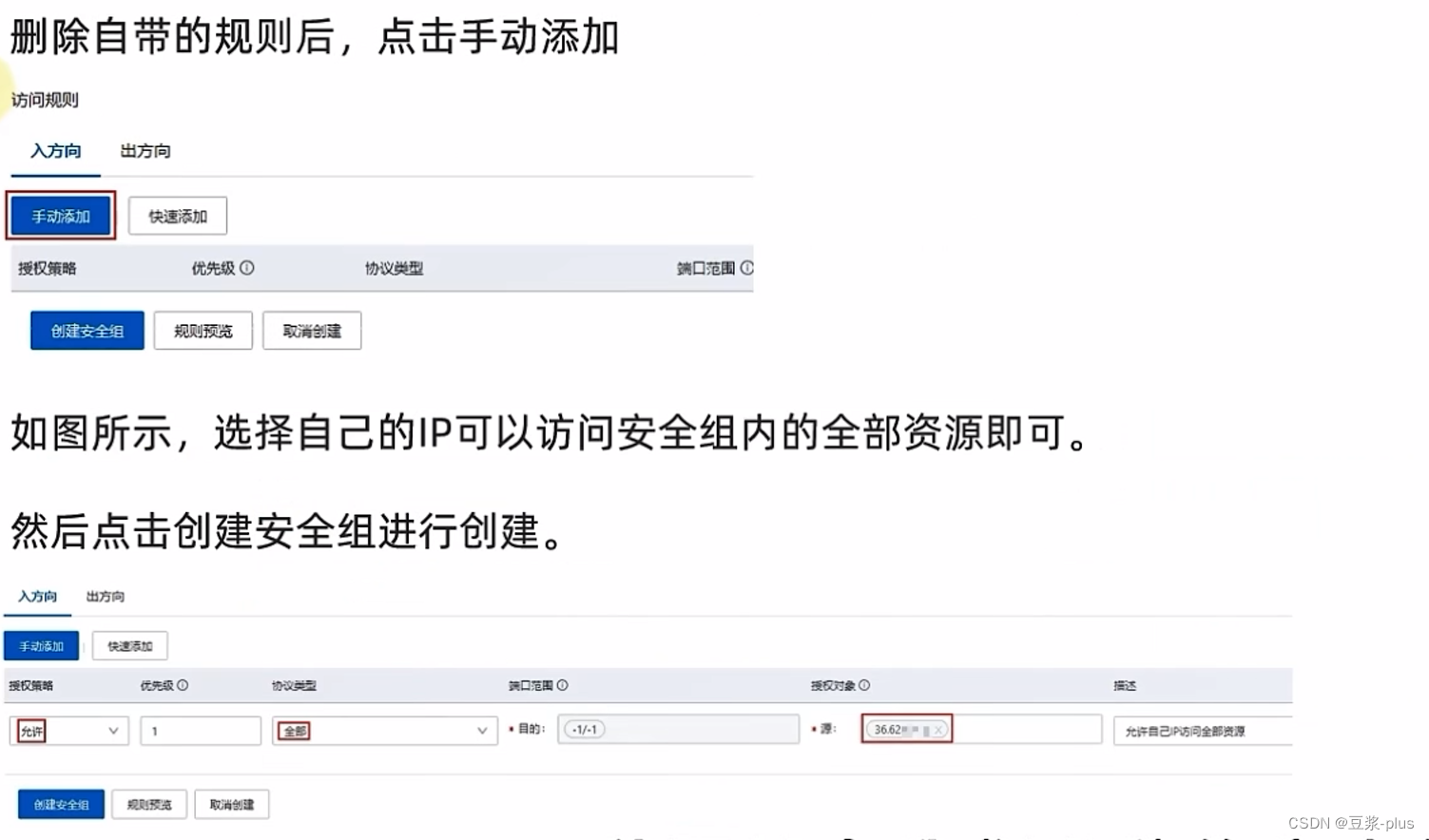


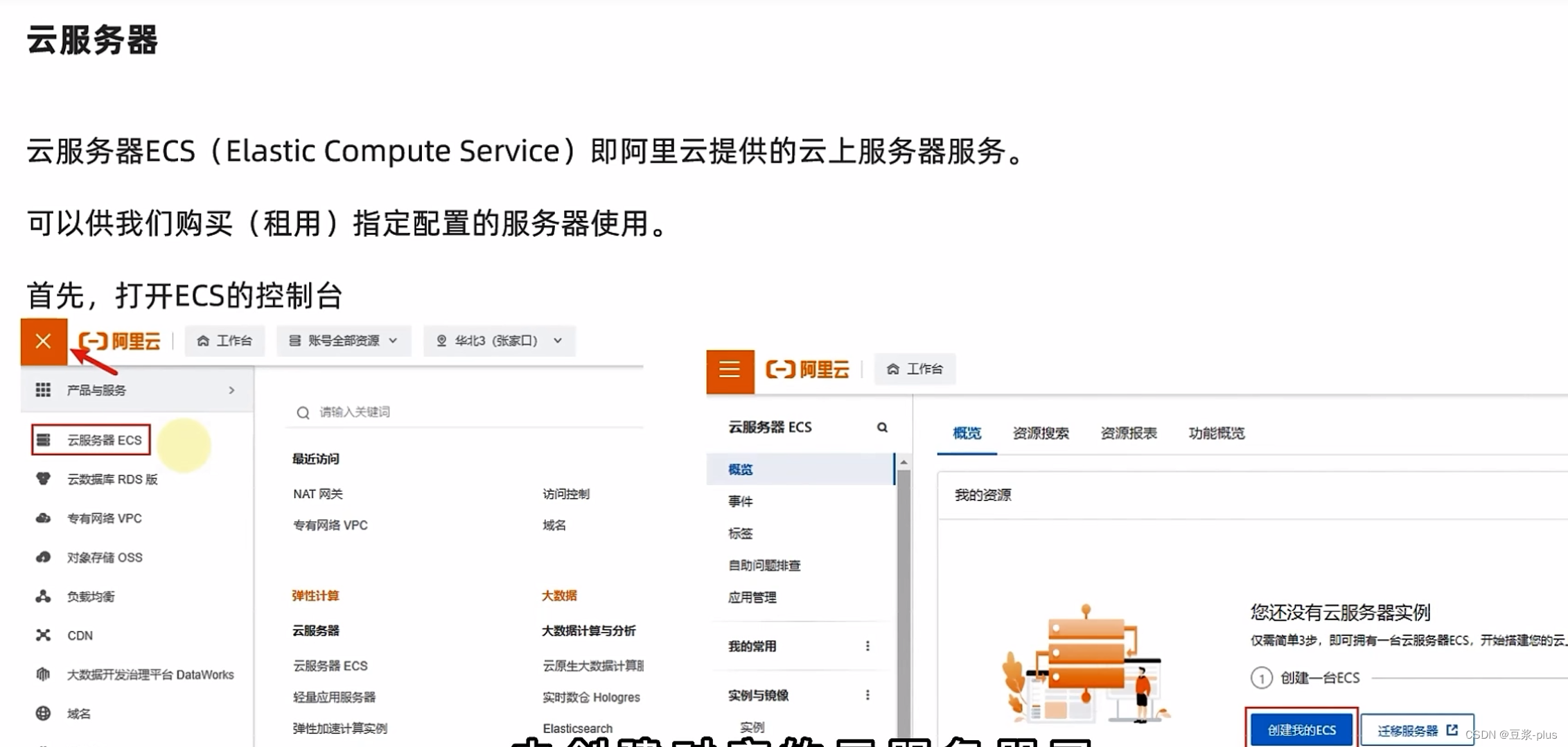

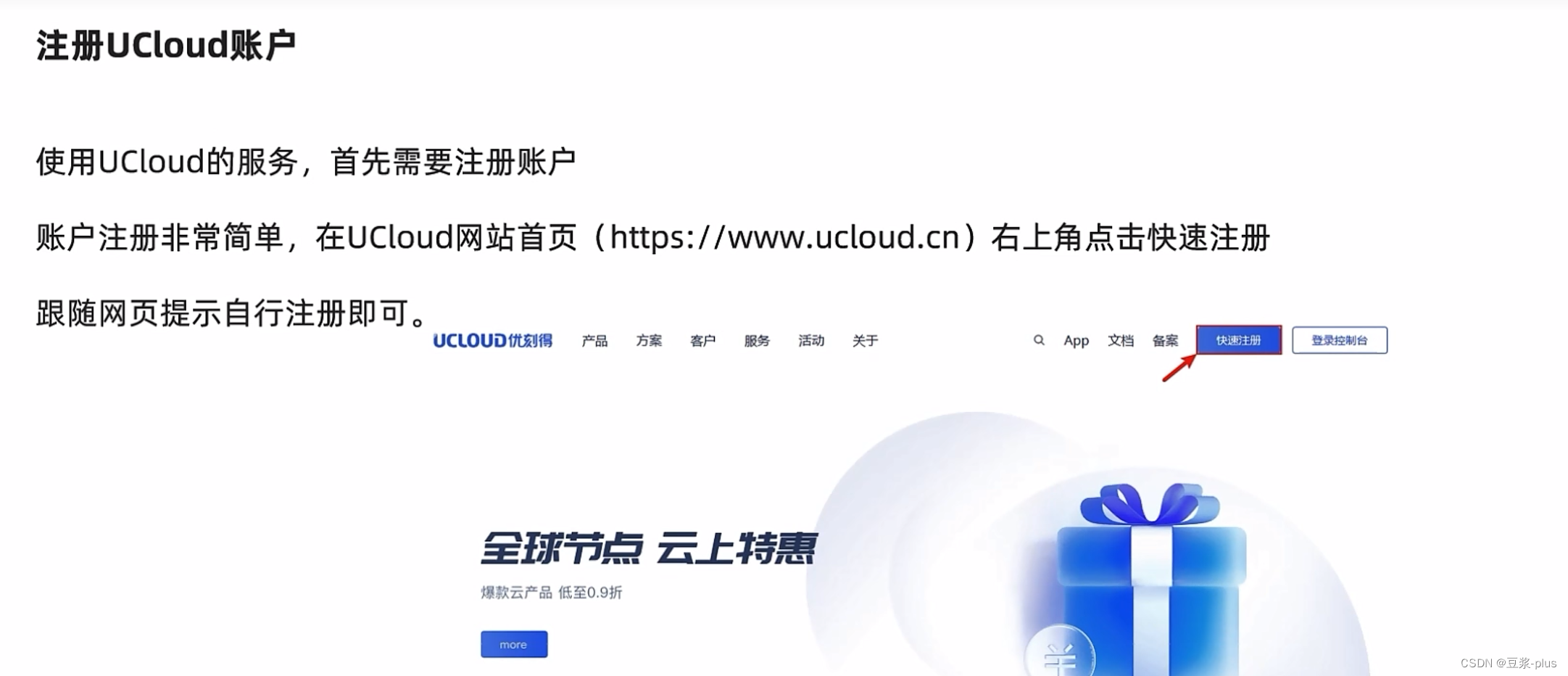
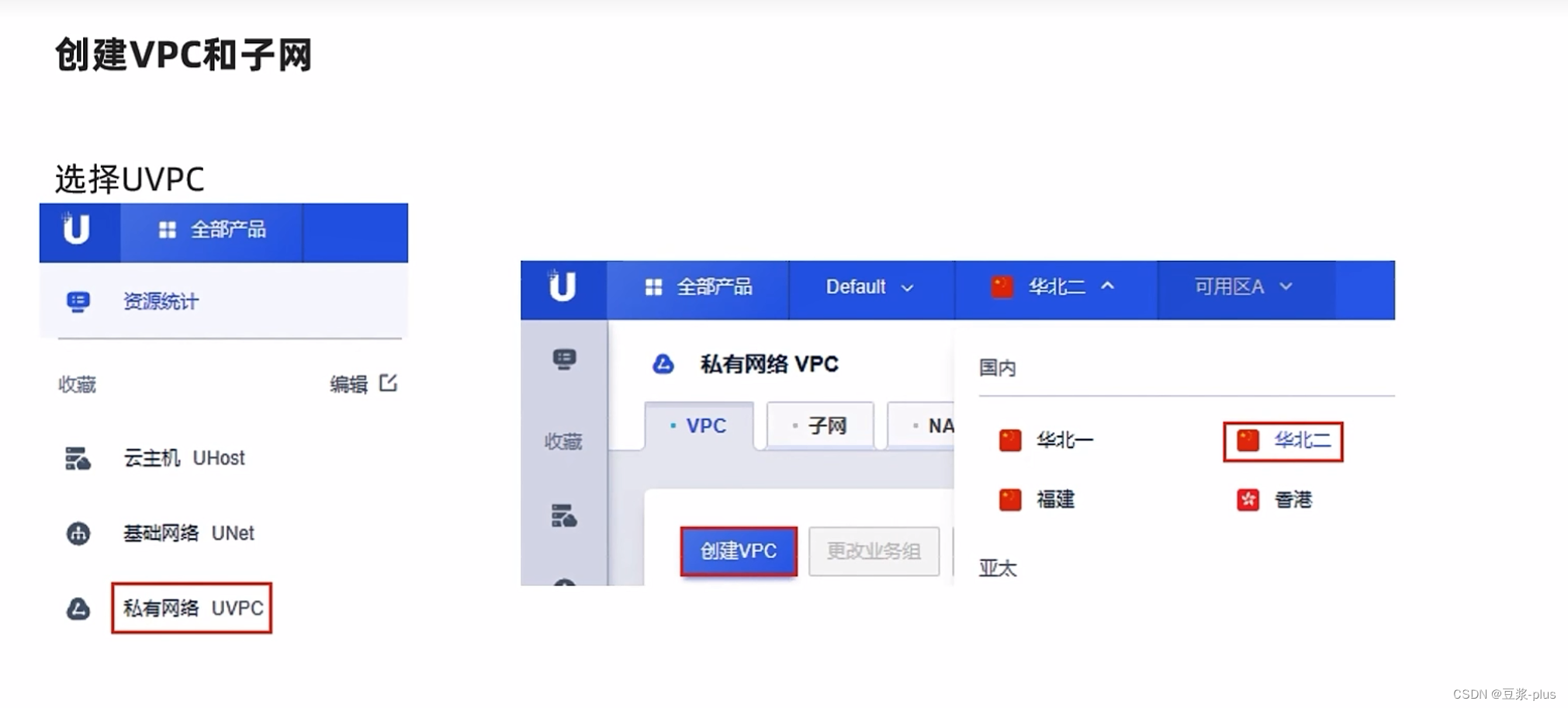
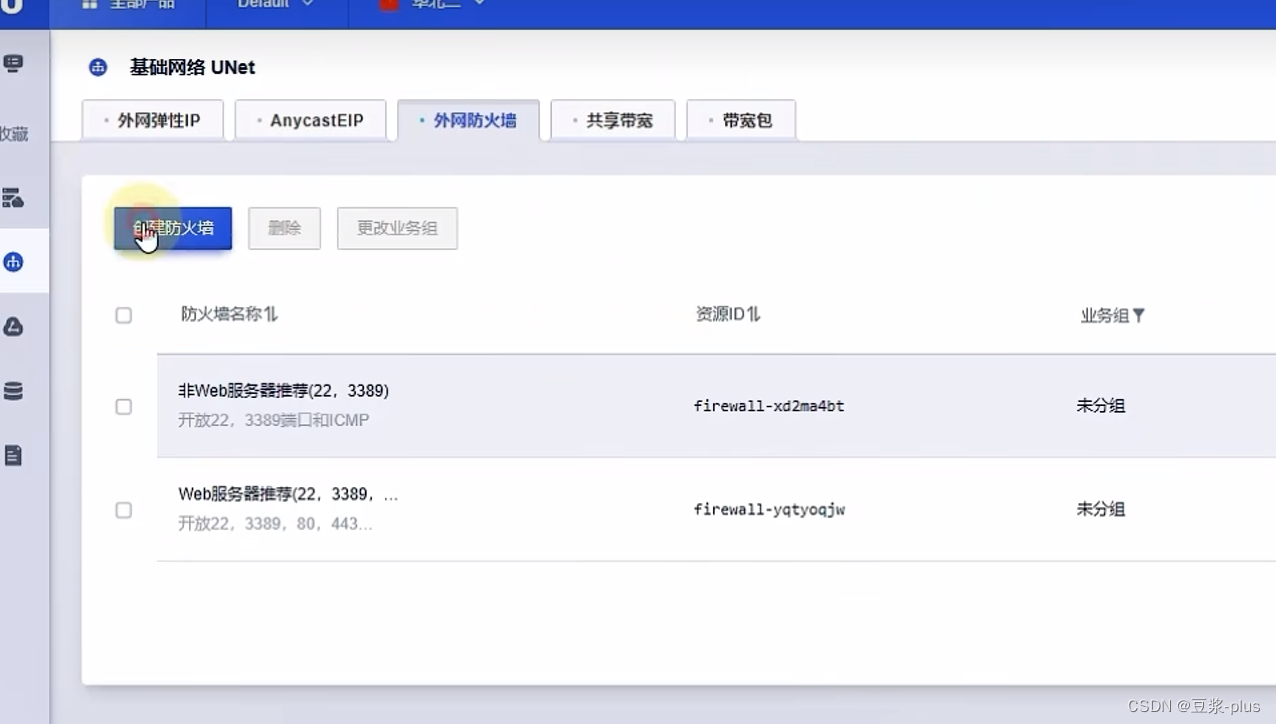
6.UCloud

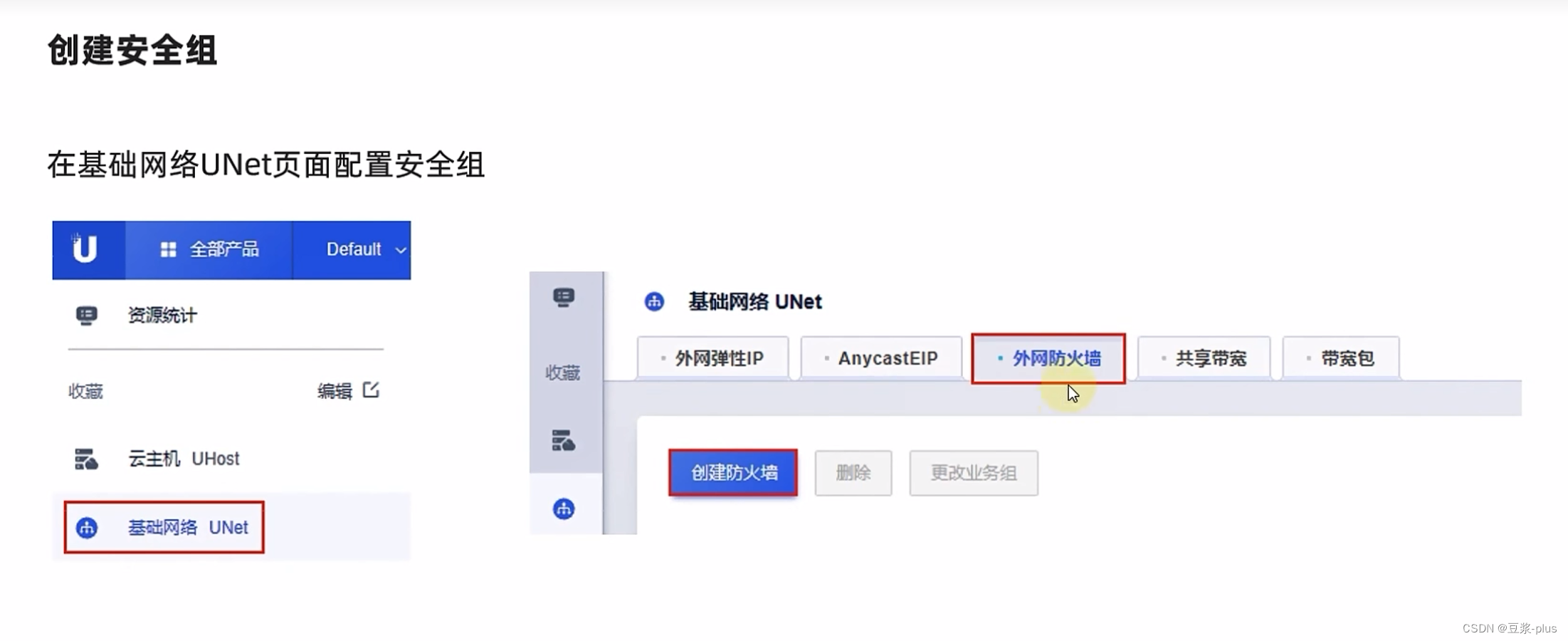

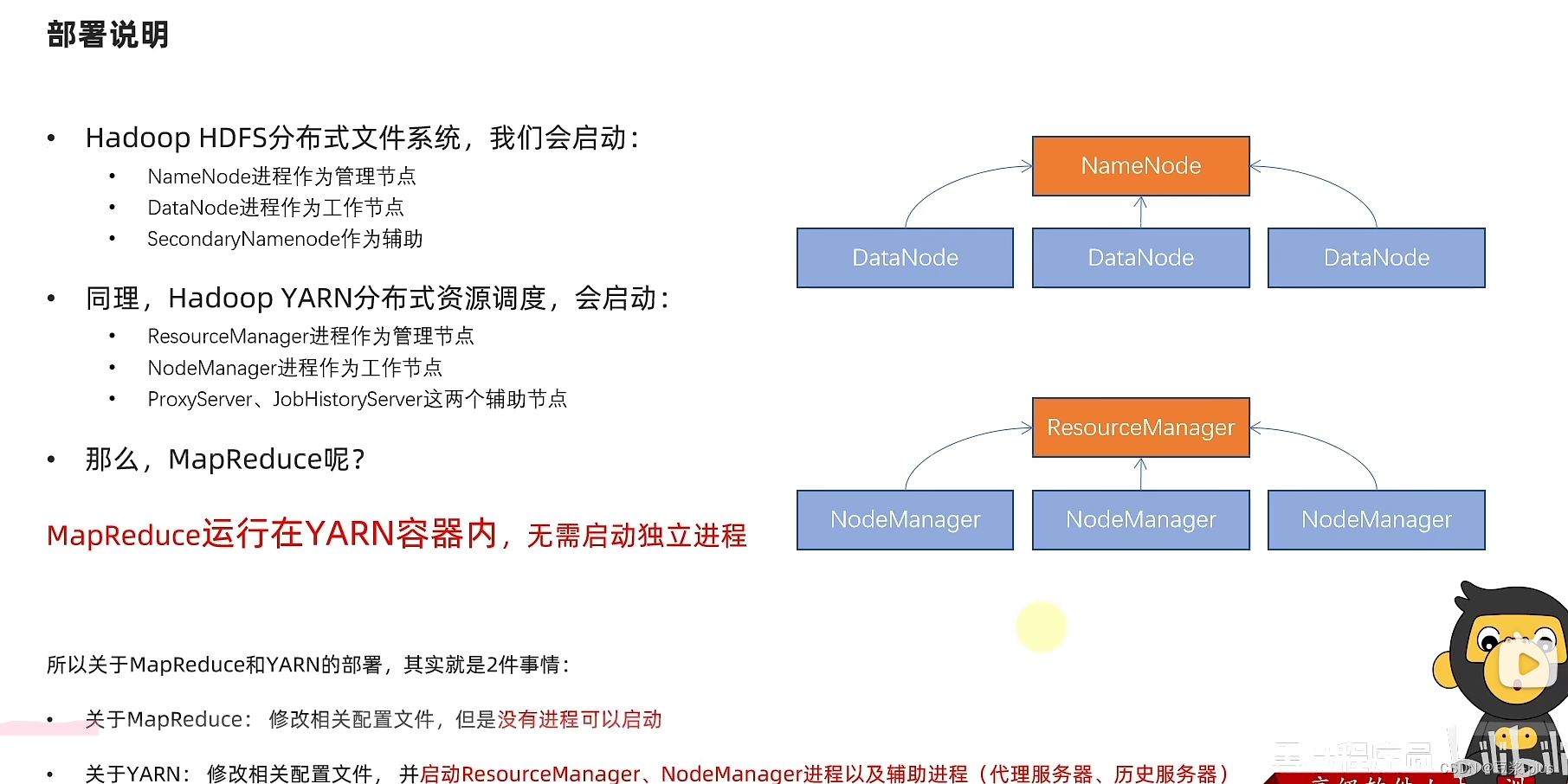
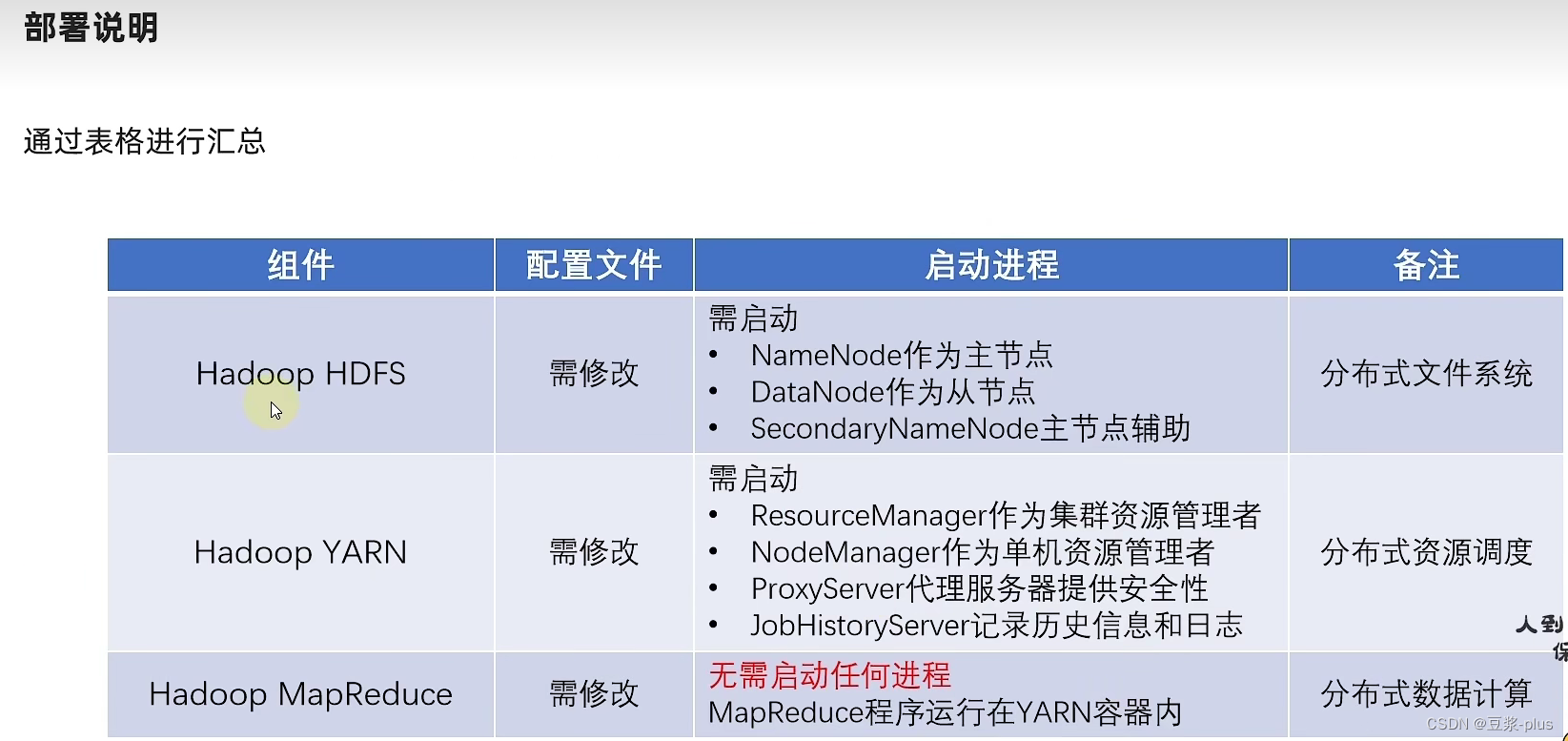
7.Hadoop理论
7.1 Hadoop理论


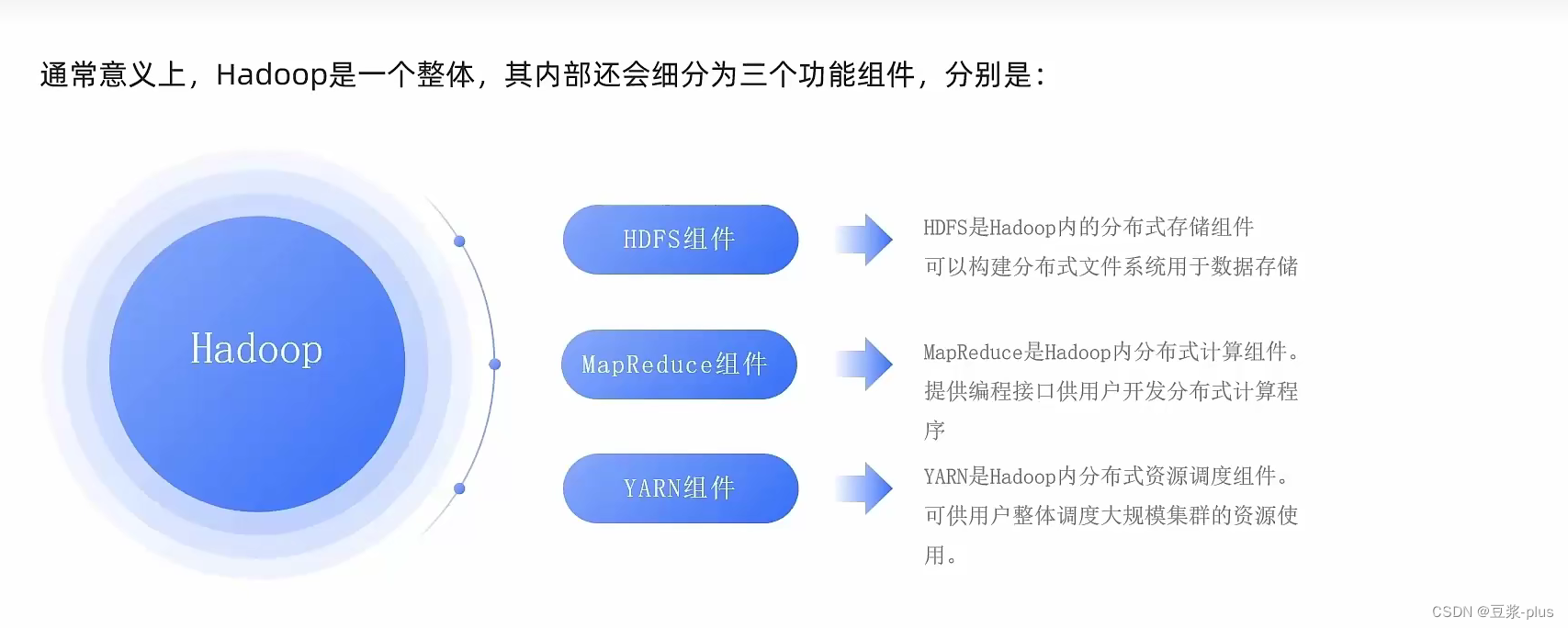


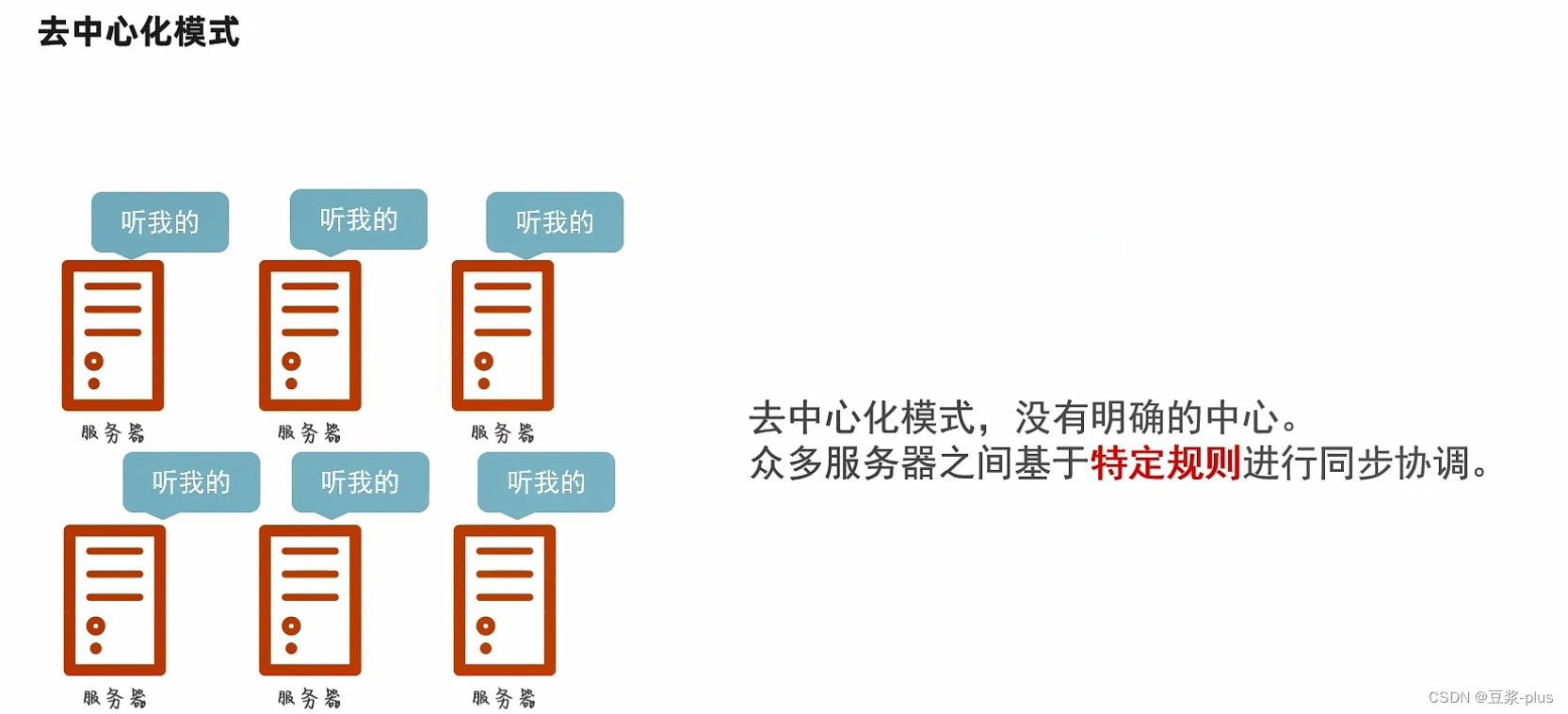
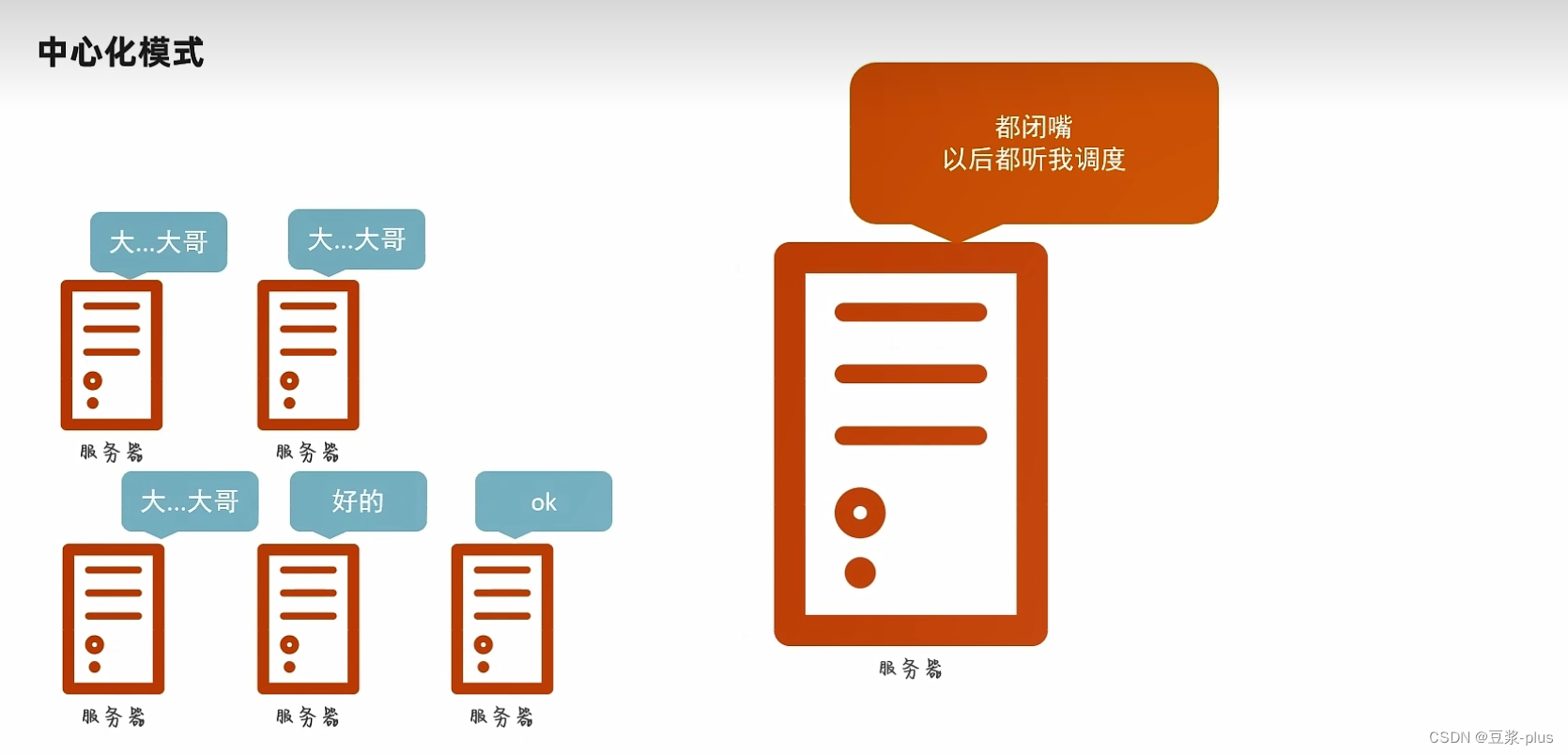
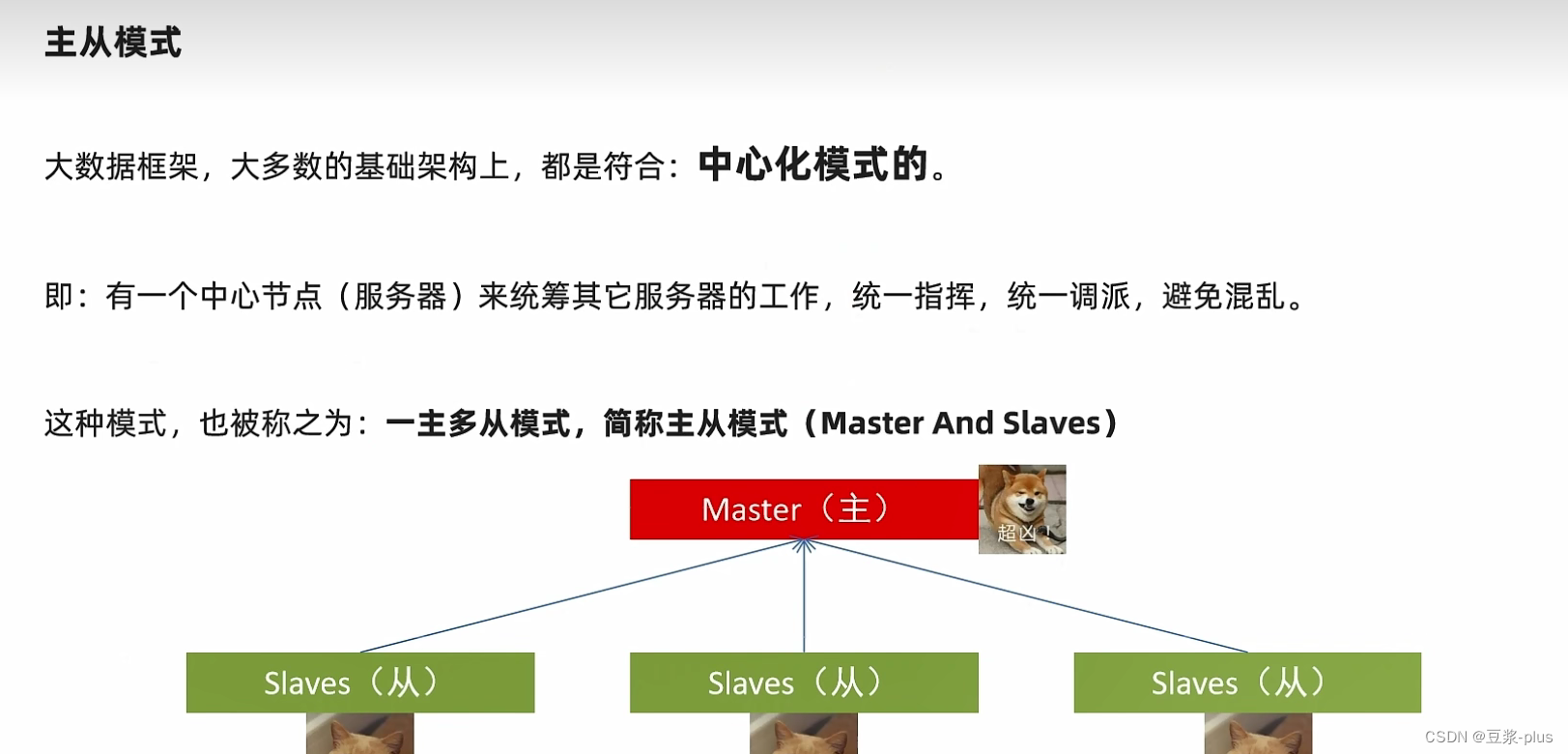

7.2 VMware Hadoop实践
https://hadoop.apache.org/
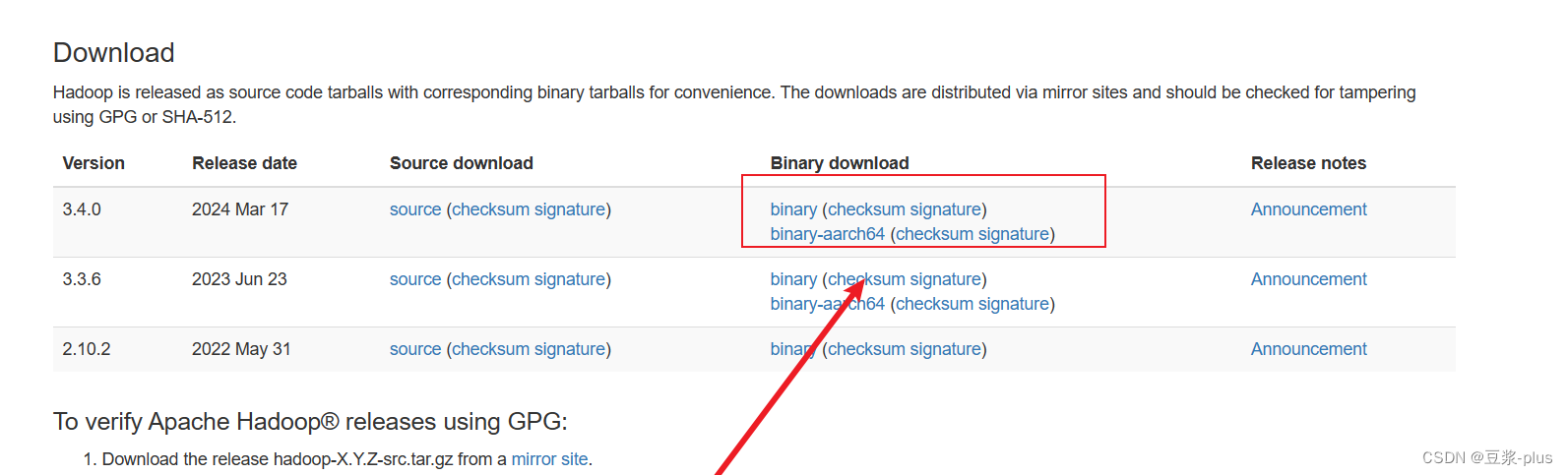
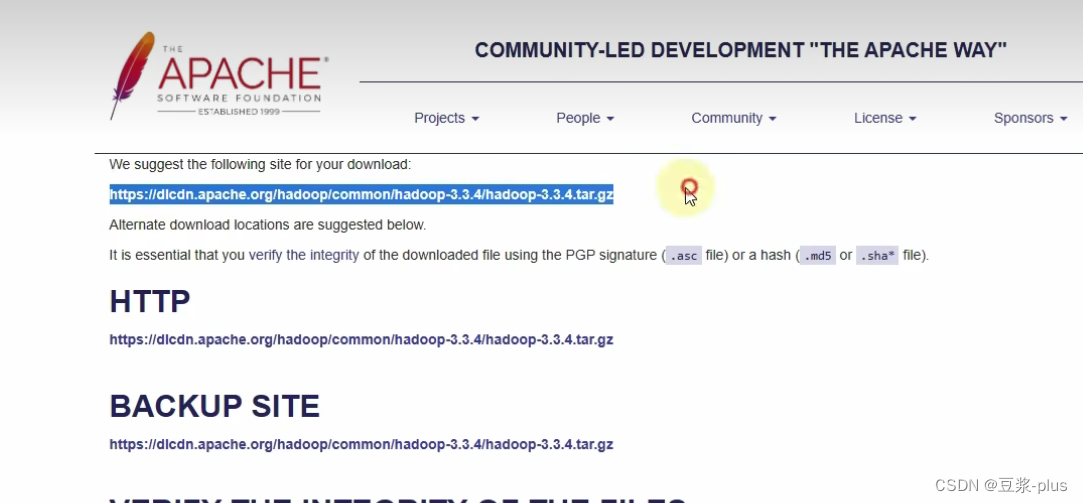


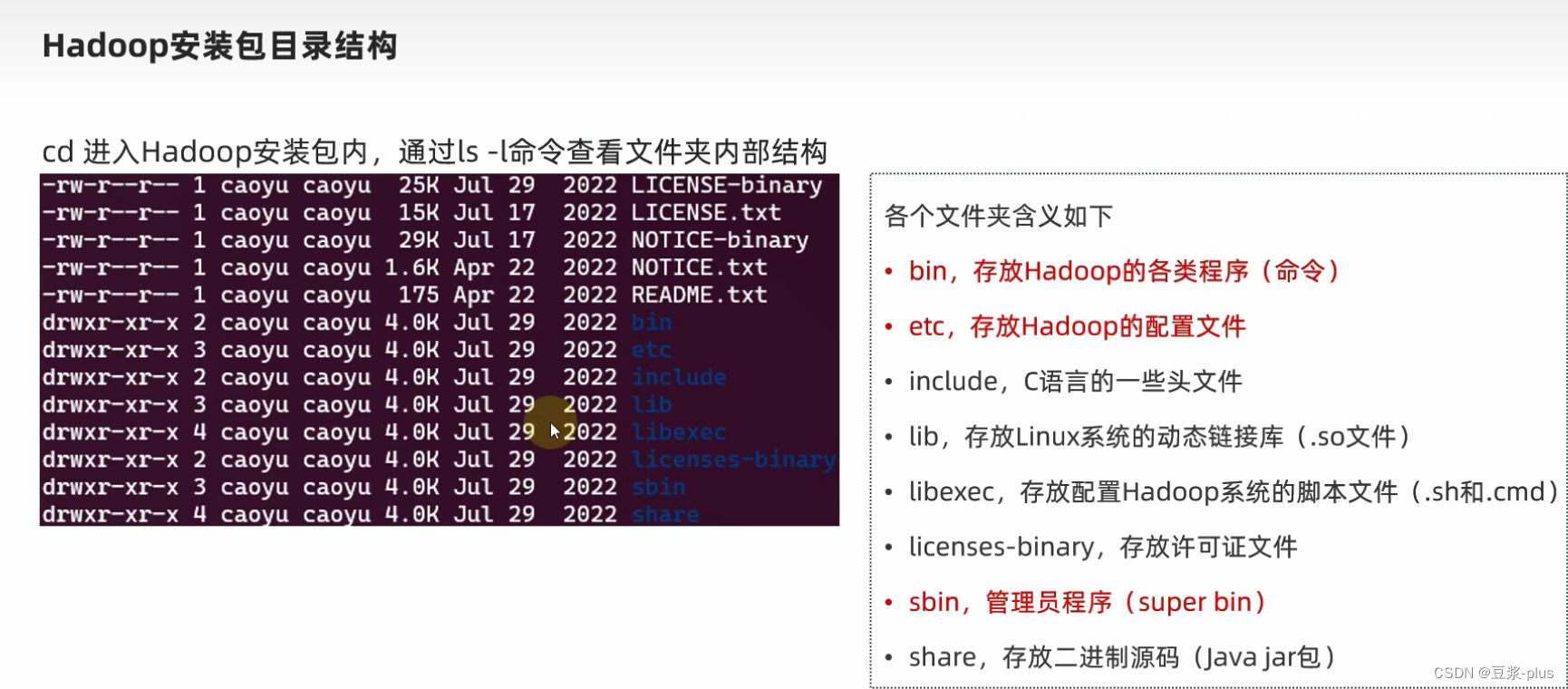


export JAVA_HOME=/export/server/jdk
export HADOOP_HOME=/export/server/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
<configuration><property><name>fs.defaultFS</name><value>hdfs://node1:8020</value></property><property><name>io.file.buffer.size</name><value>131072</value></property>
</configuration>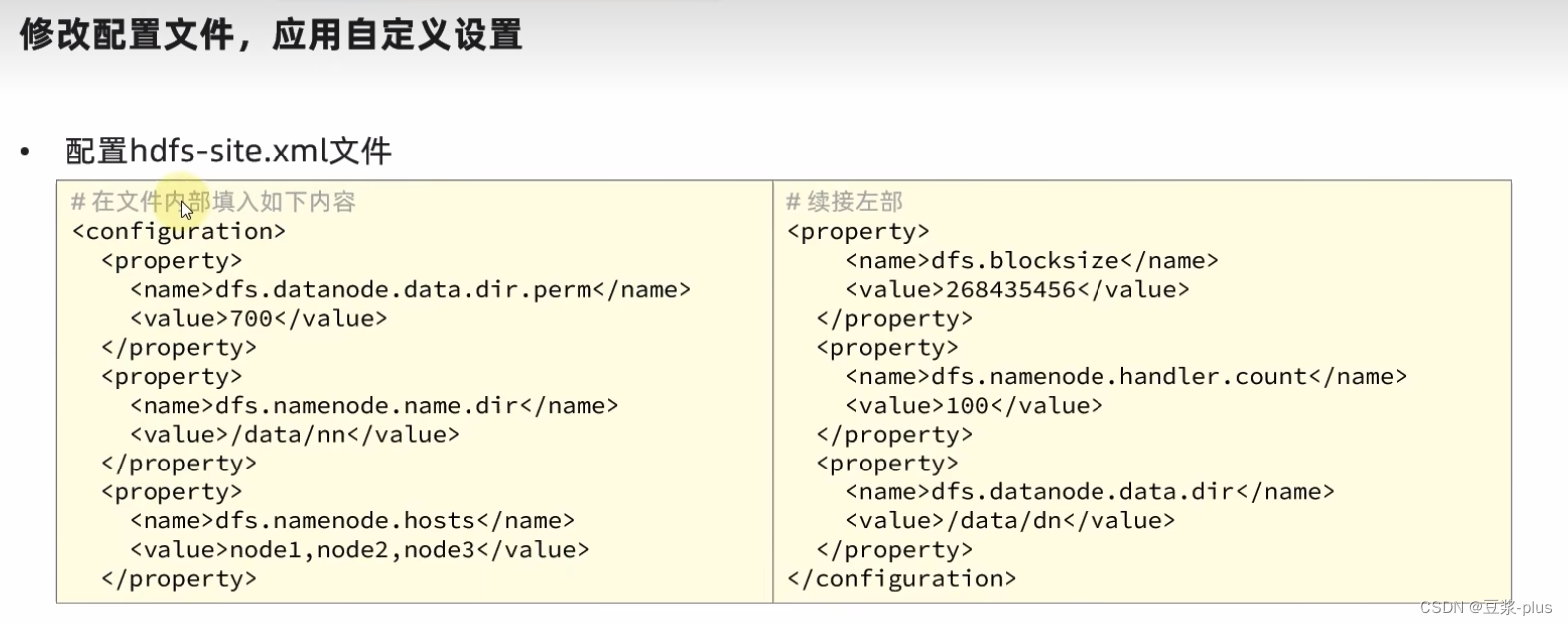
<configuration><property><name>dfs.datanode.data.dir.perm</name><value>700</value></property><property><name>dfs.namenode.name.dir</name><value>/data/nn</value></property><property><name>dfs.namenode.hosts</name><value>node1,node2,node3</value></property><property><name>dfs.blocksize</name><value>268435456</value></property><property><name>dfs.namenode.handler.count</name><value>100</value></property><property><name>dfs.datanode.data.dir</name><value>/data/dn</value></property></configuration>


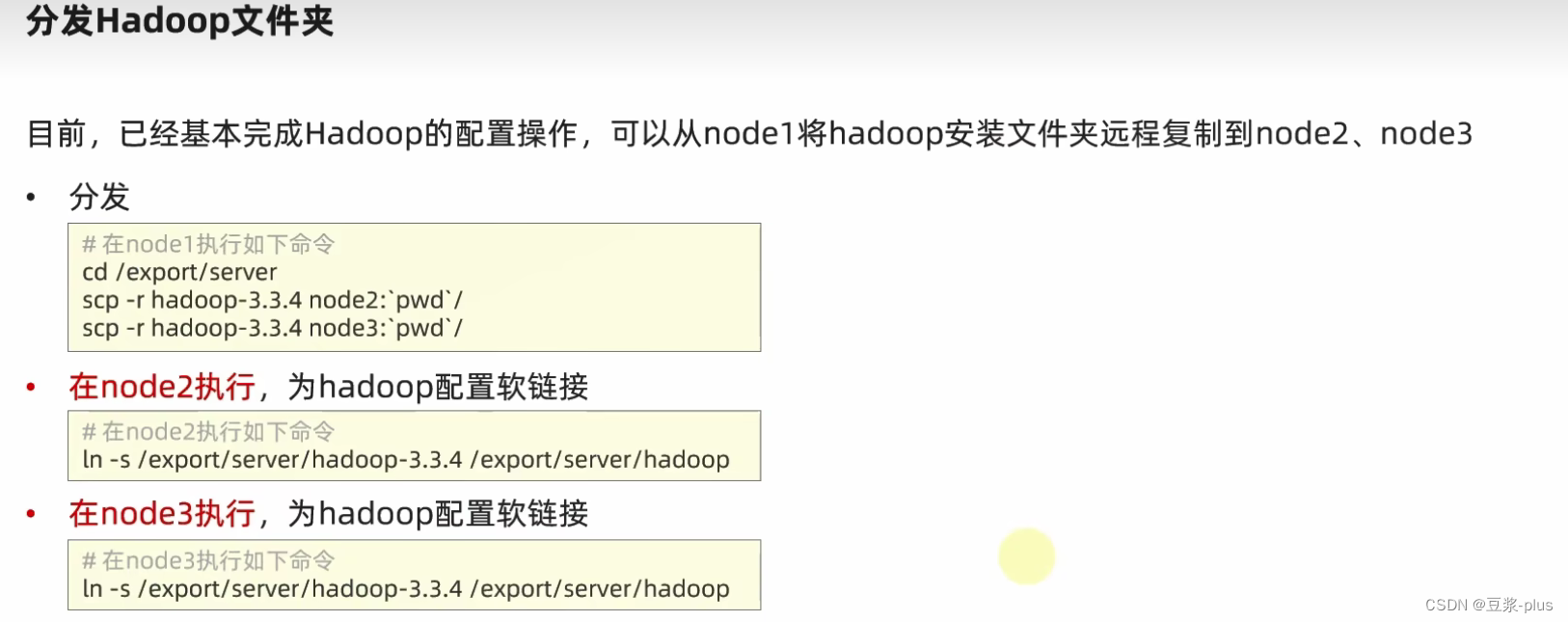
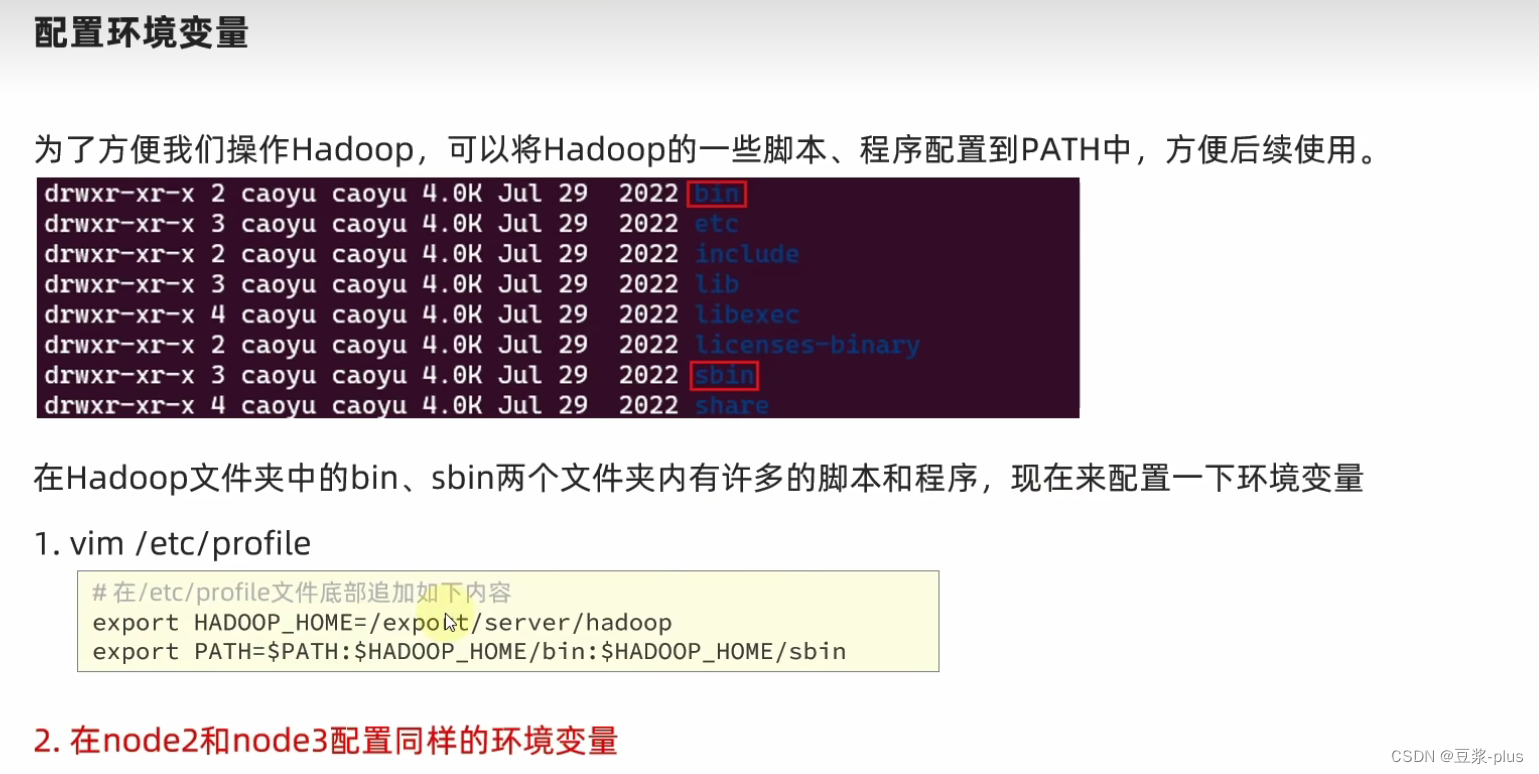
export HADOOP_HOME=/export/server/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
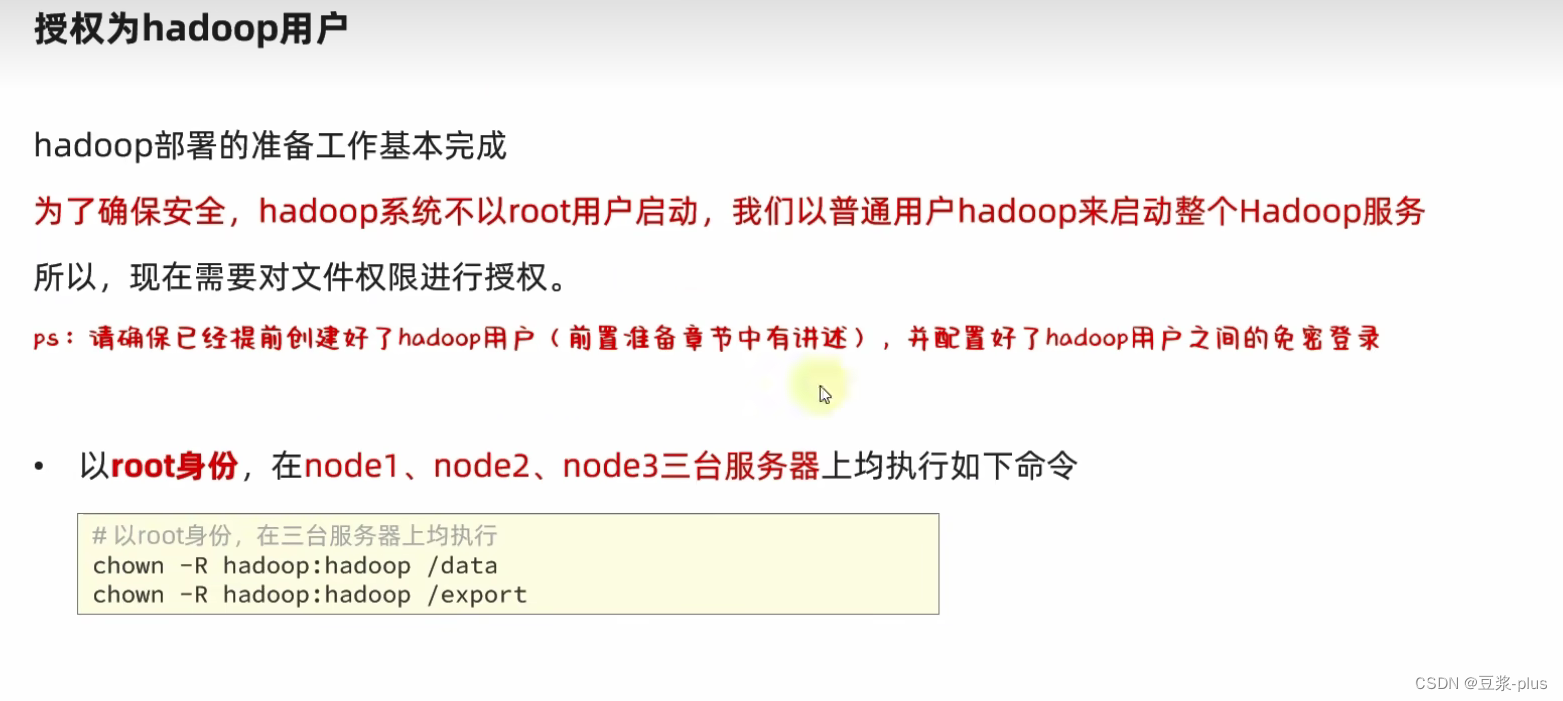
chown -R hadoop:hadoop /datachown -R hadoop:hadoop /export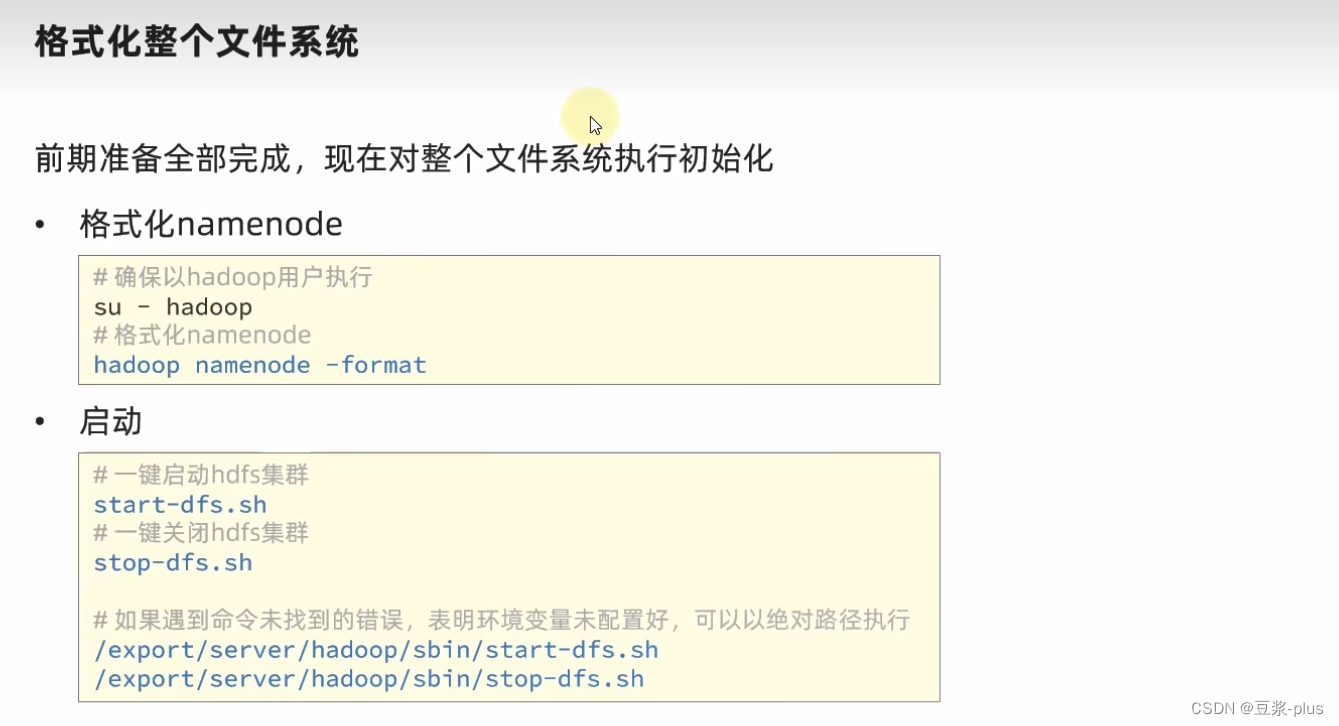
看见了 就成功了: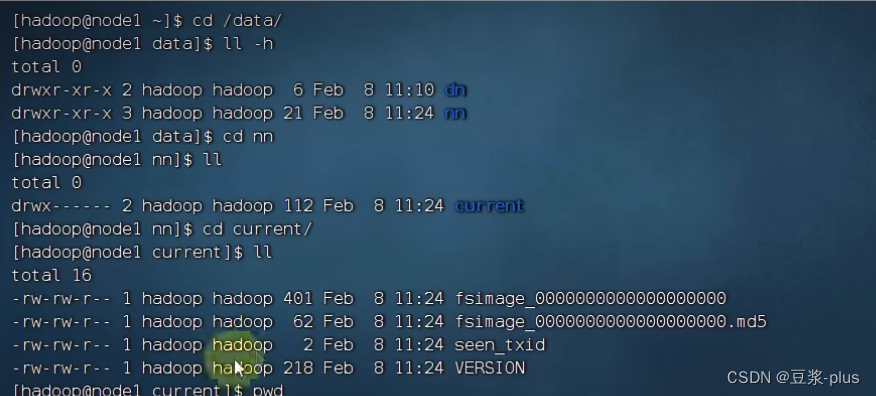
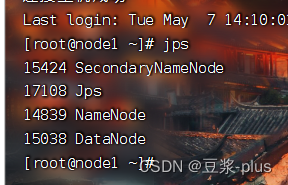
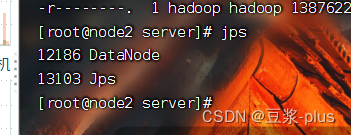
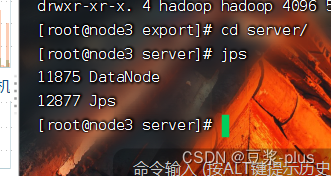

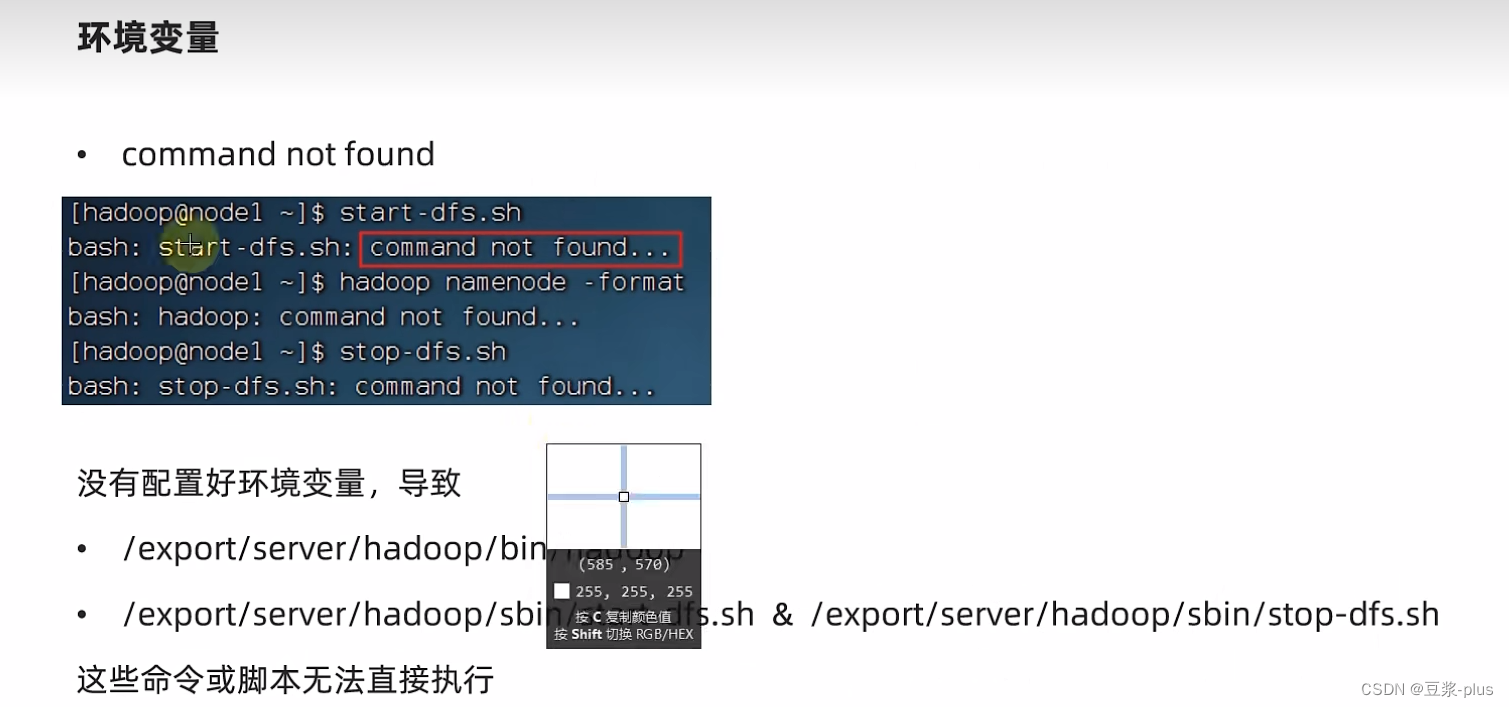
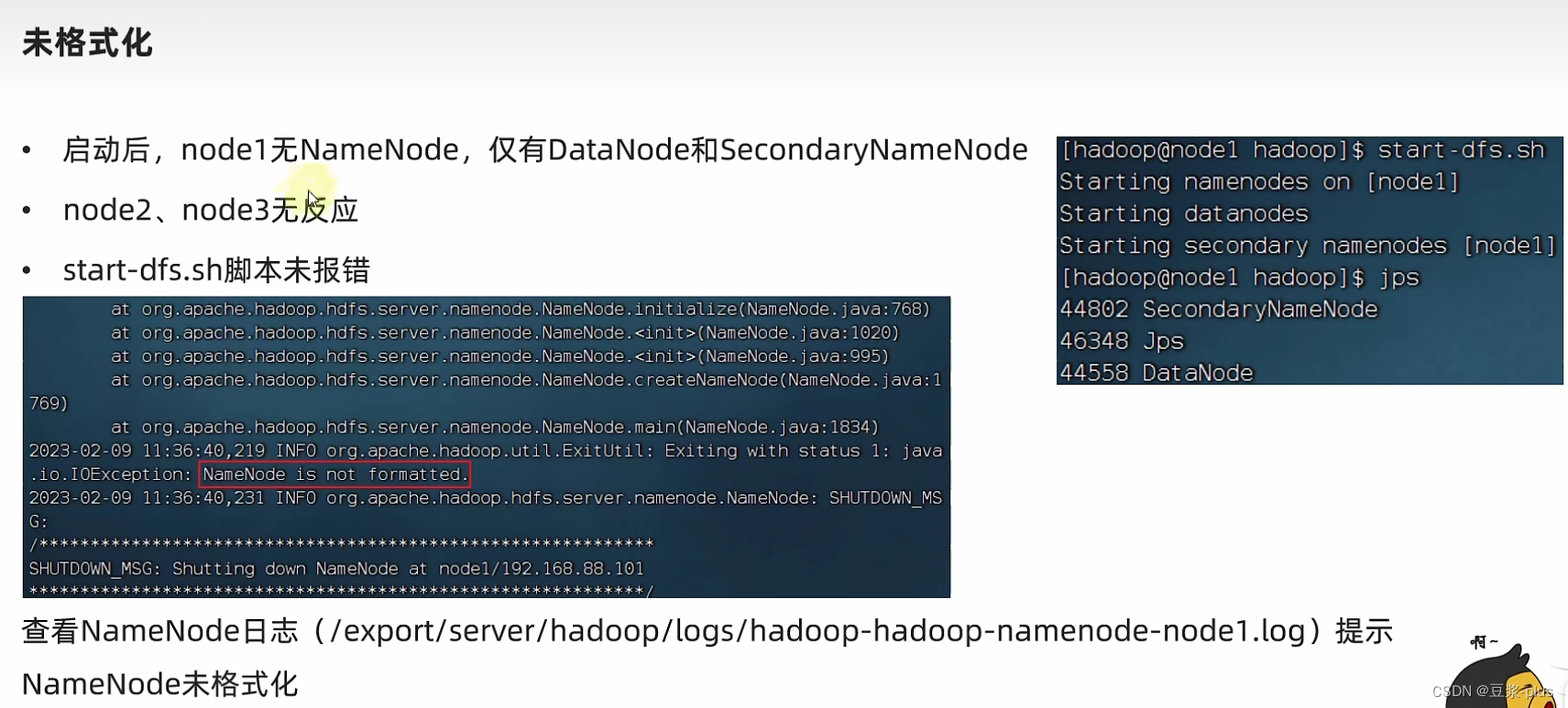
7.3集群部署常见问题解决







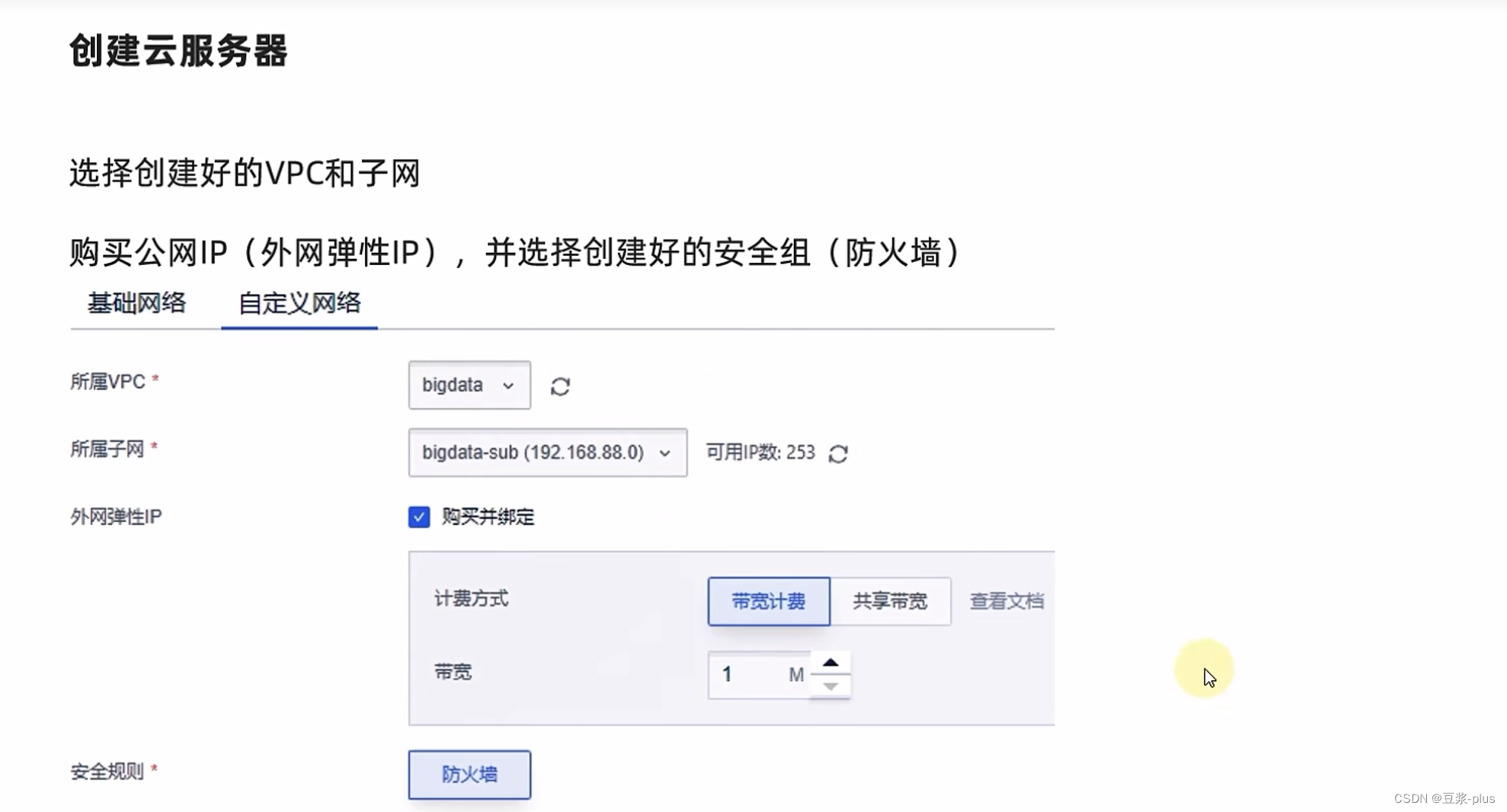
7.4 云服务器上 Hadoop实践
一个唯一的不同点:就是访问它的Web Ul 我们要走公网IP

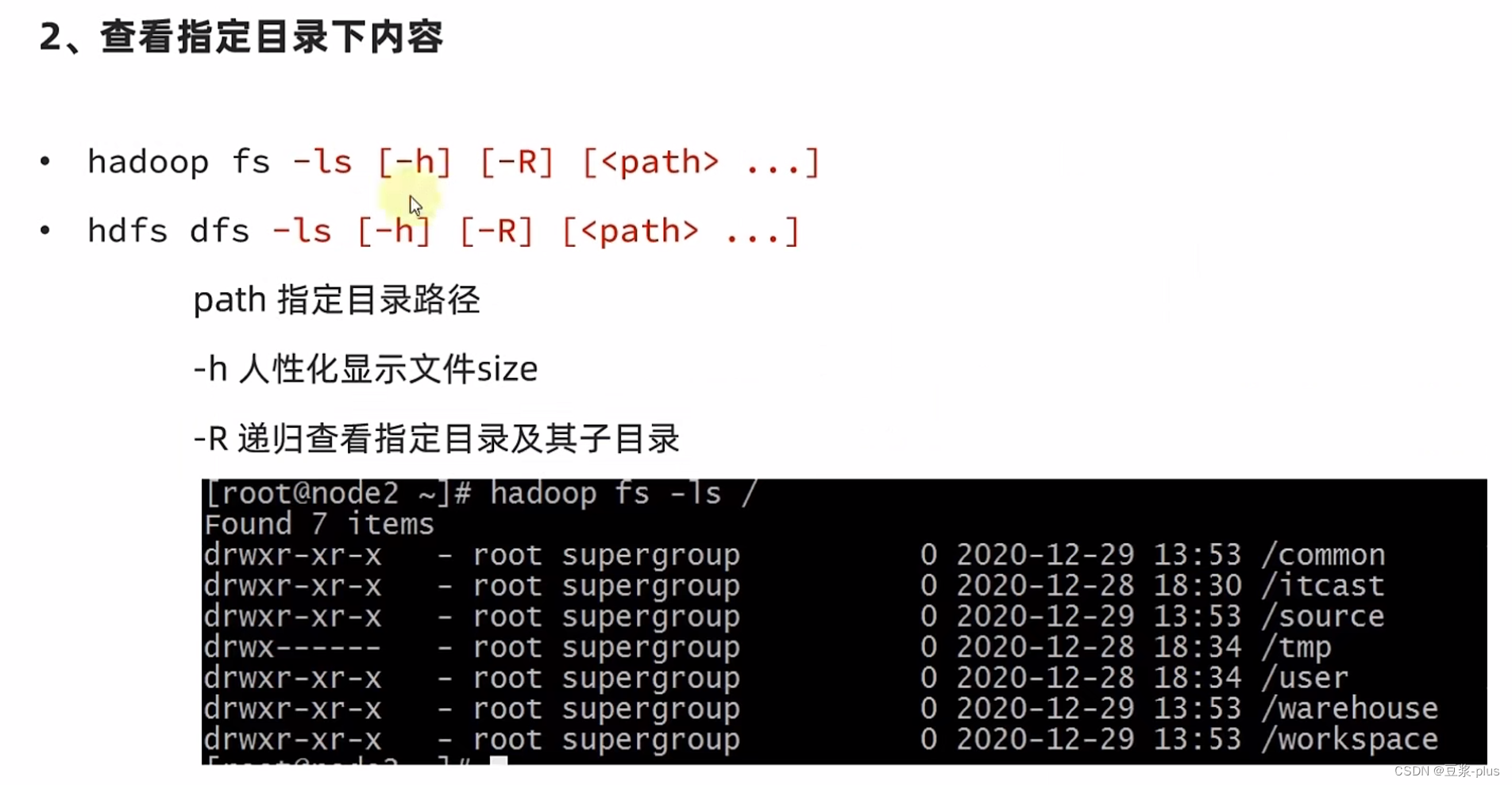
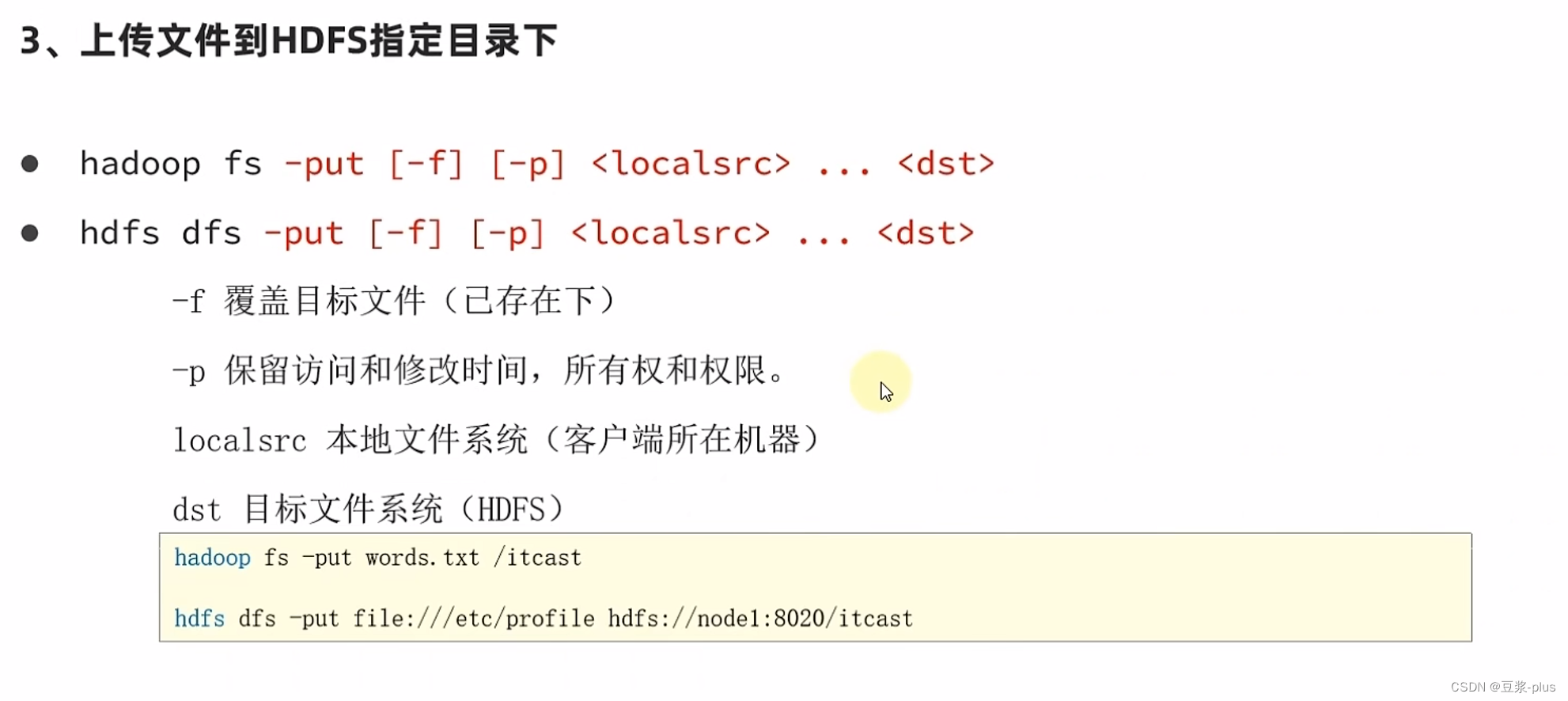
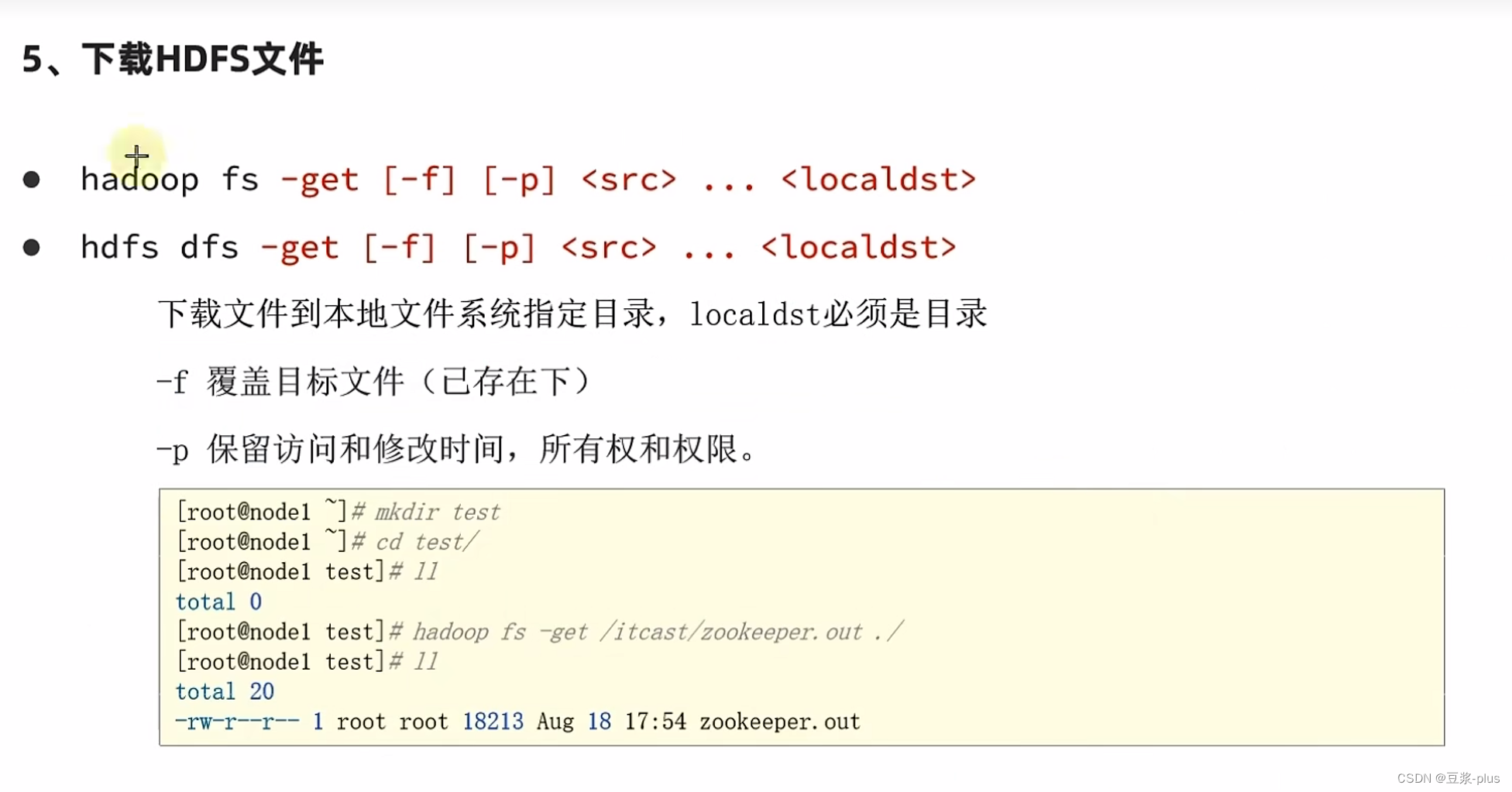
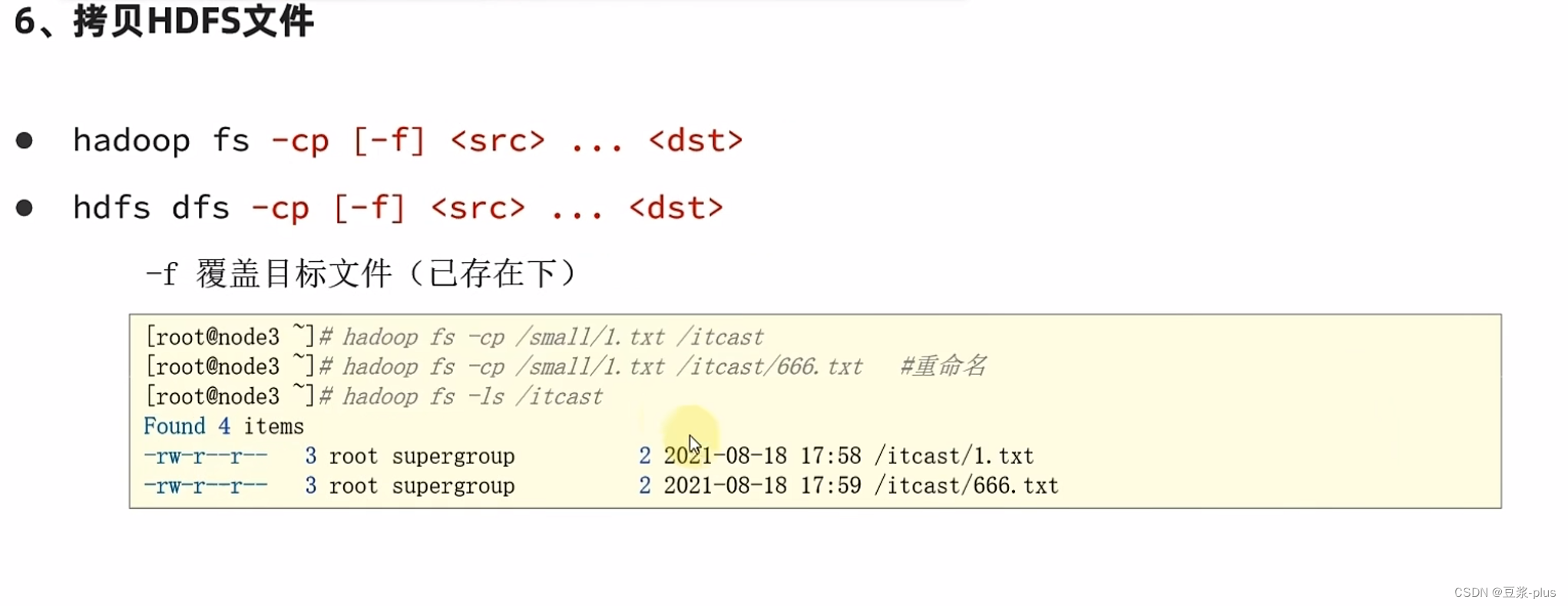
7.5 HDFS 的 shell


hadoop-daemon.sh start datanode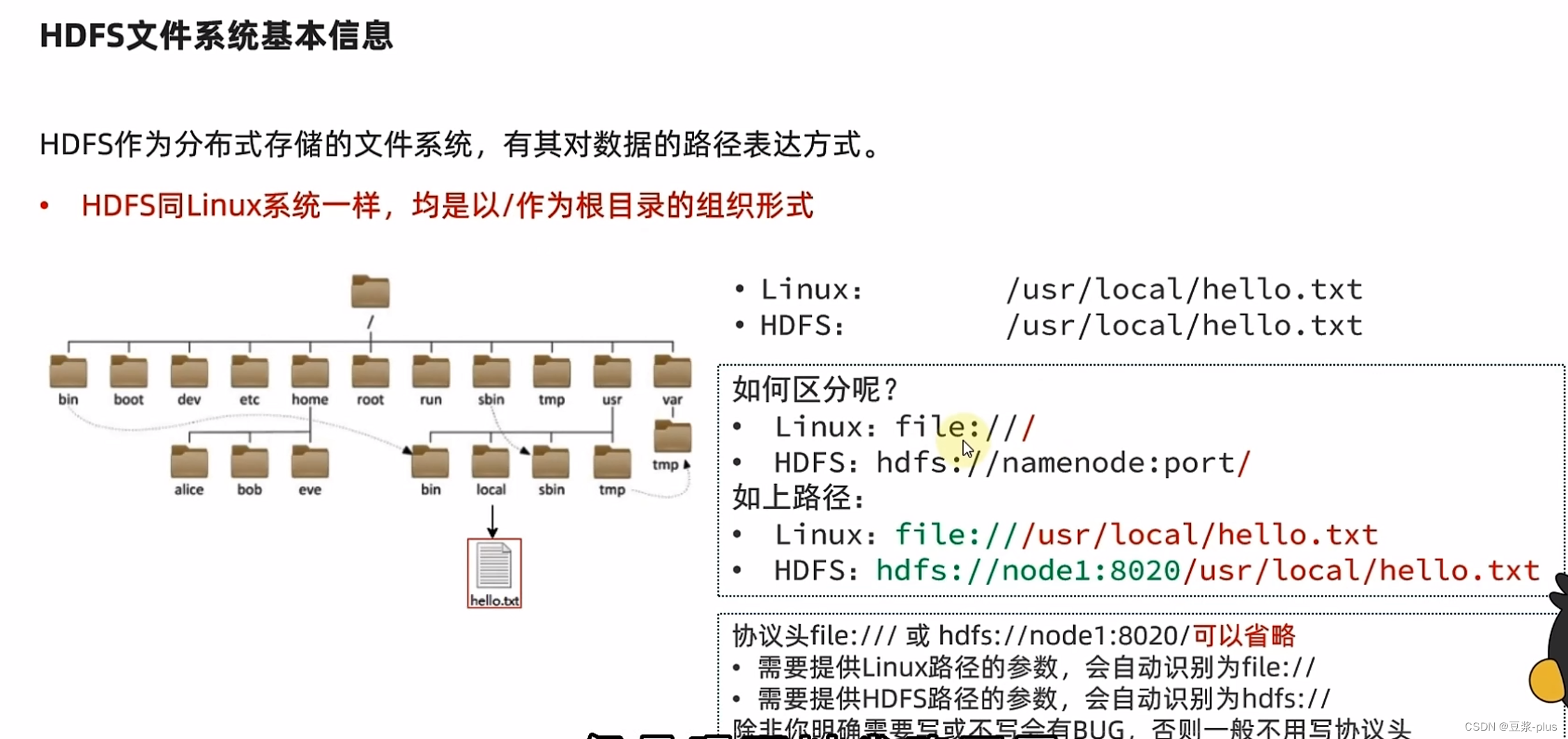



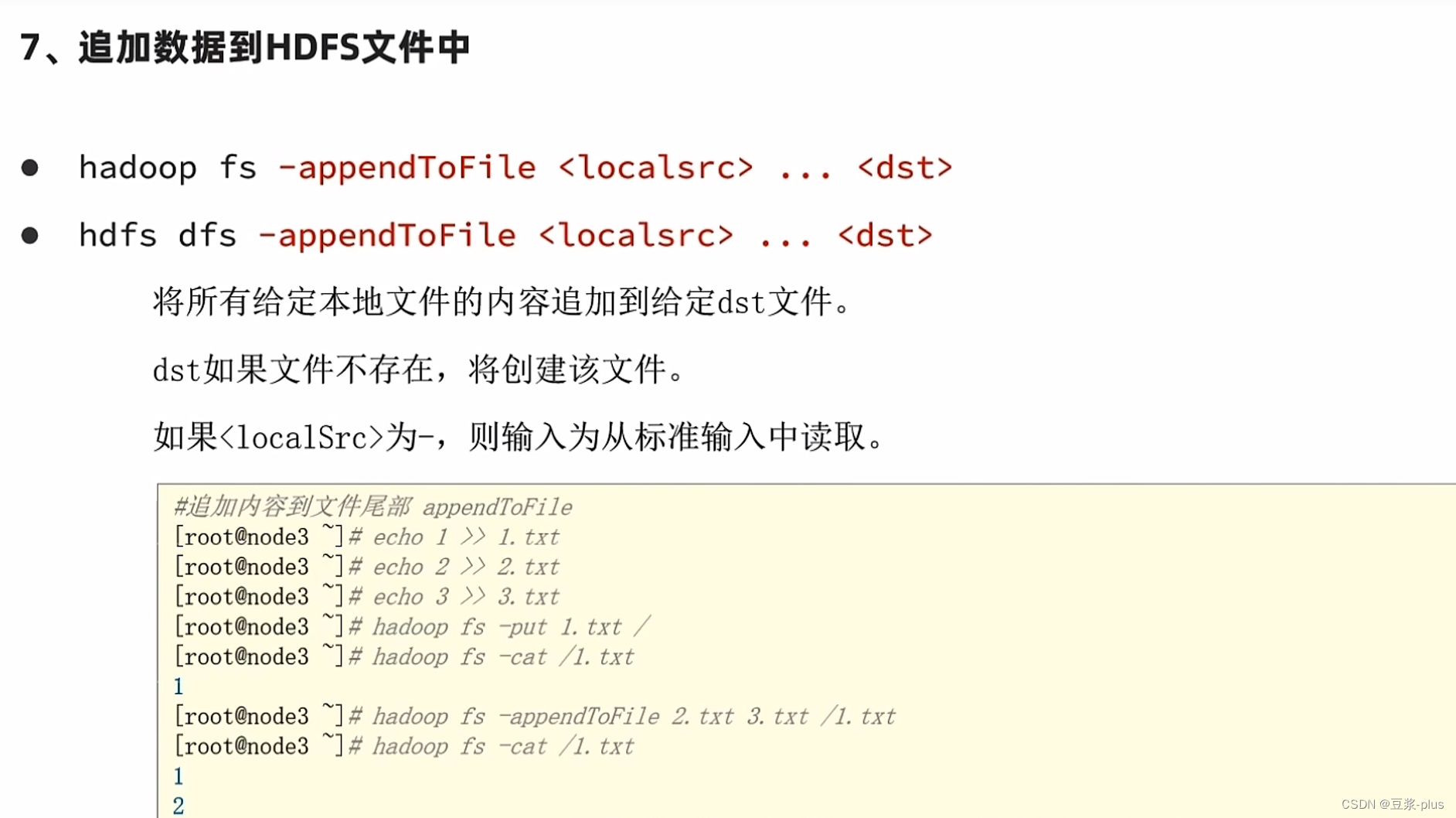


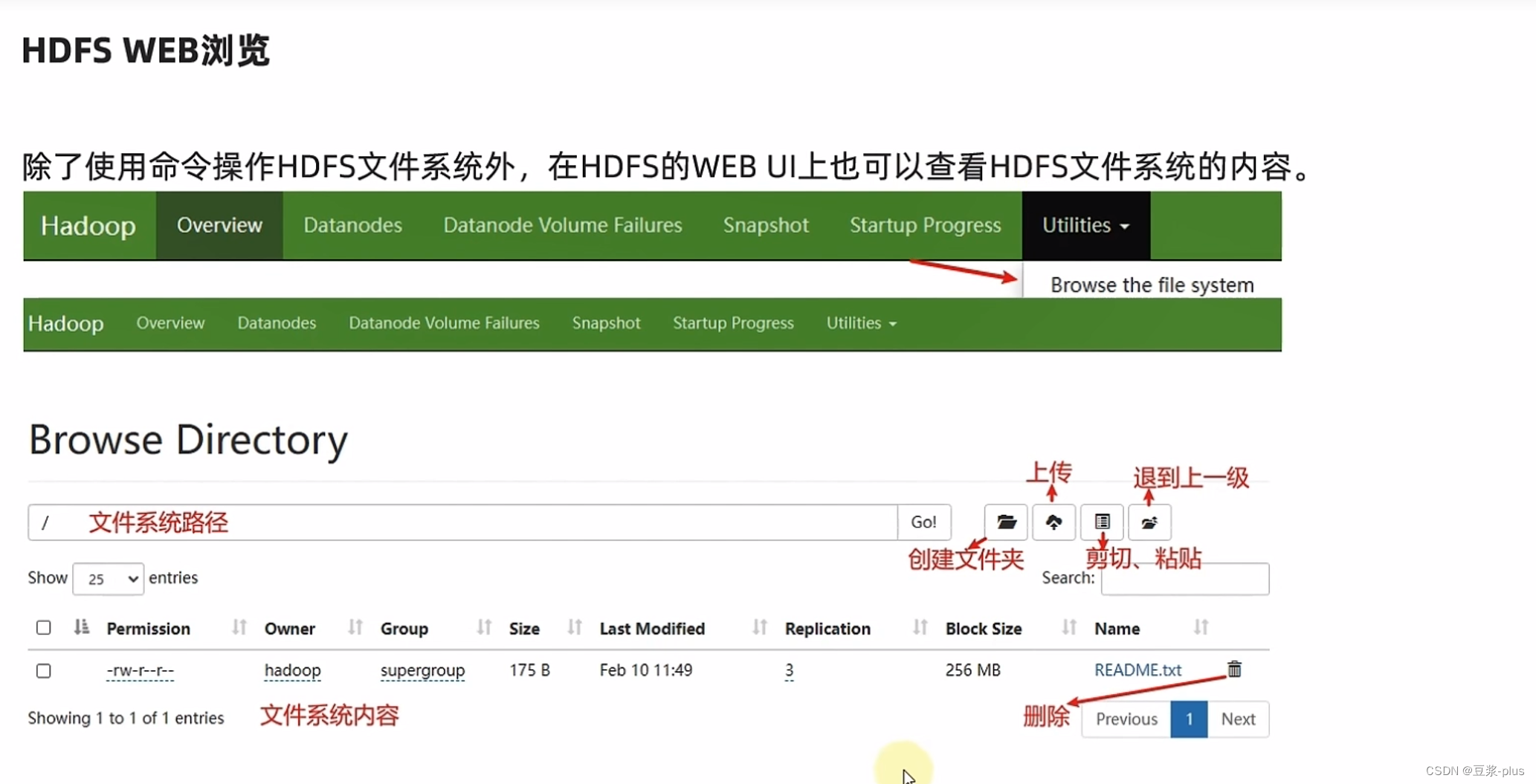

7.6HDFSShell解决权限不足



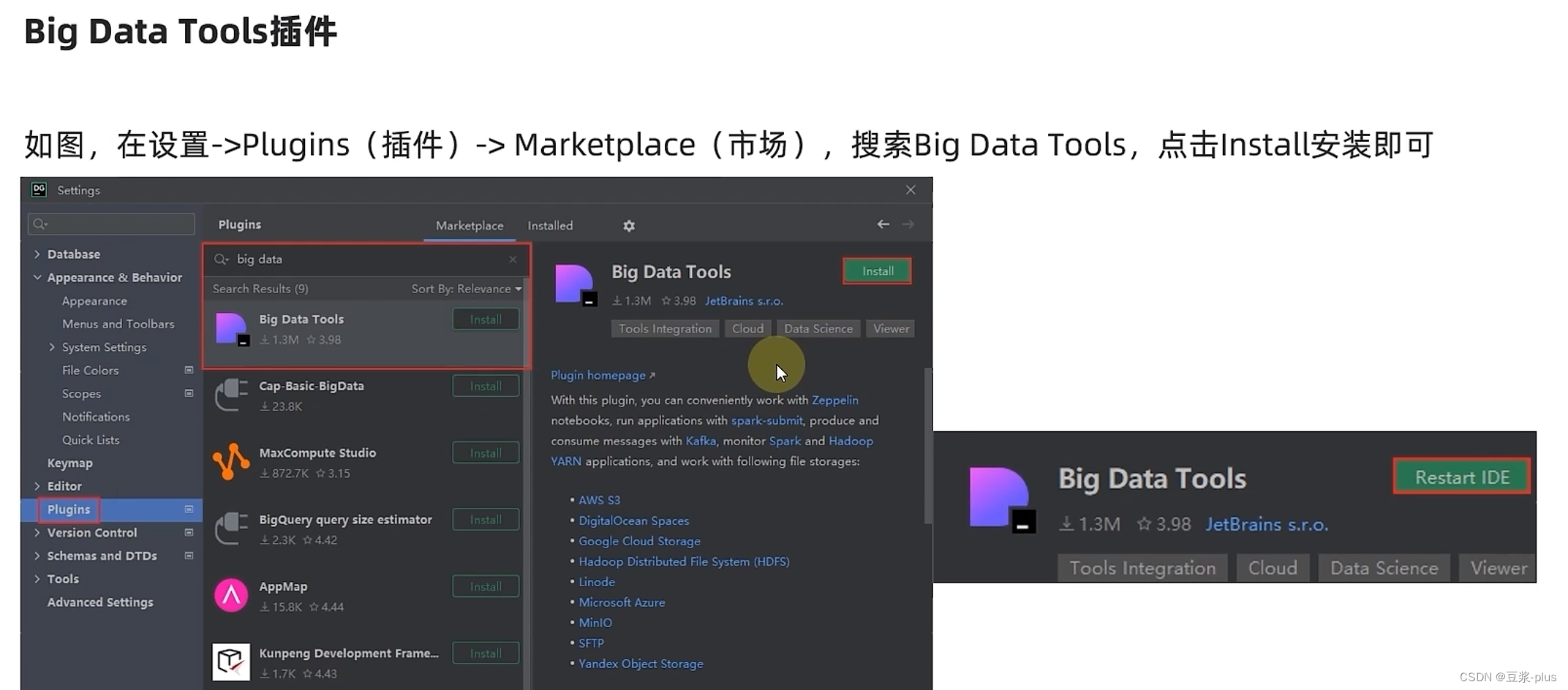
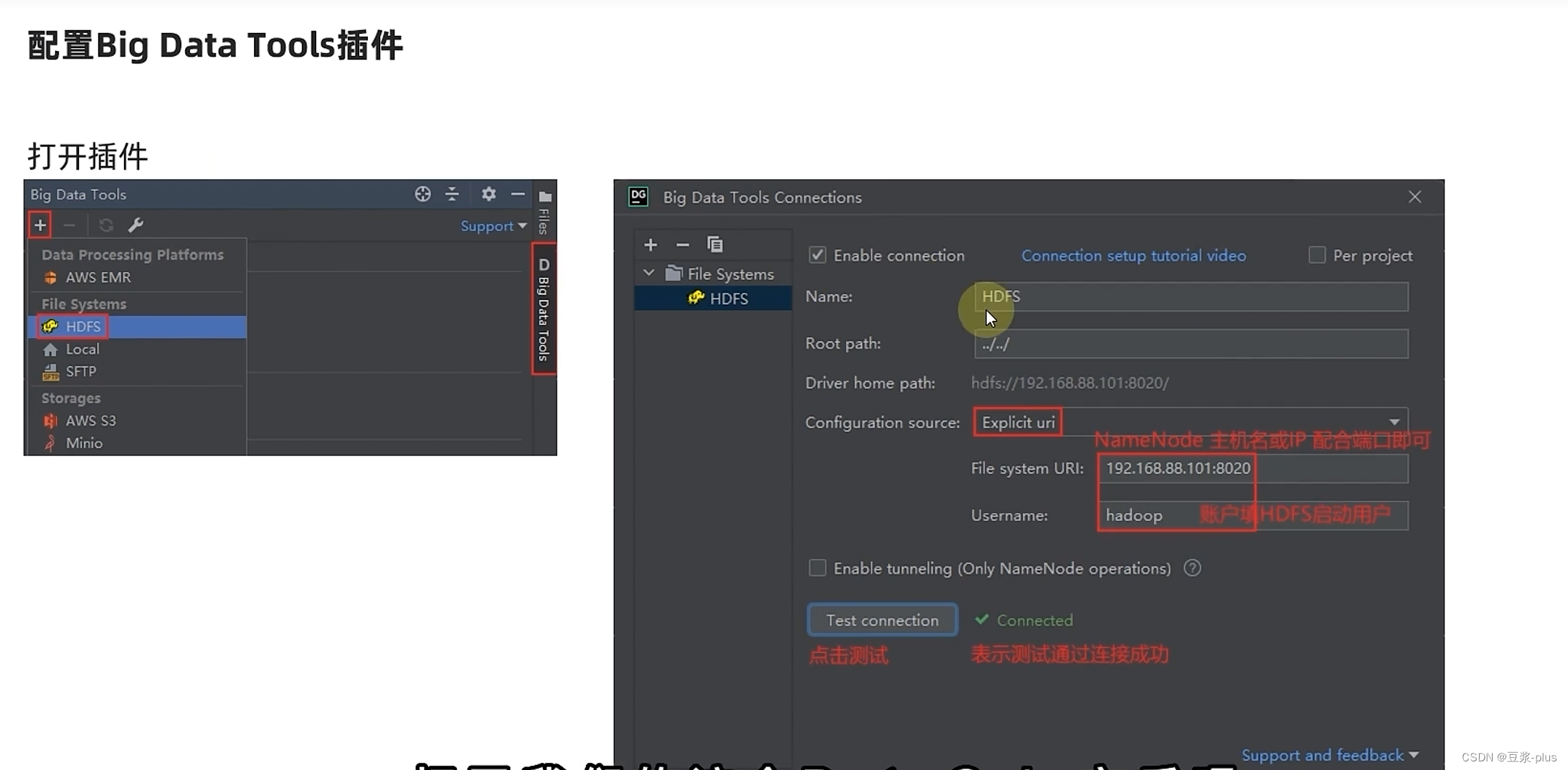
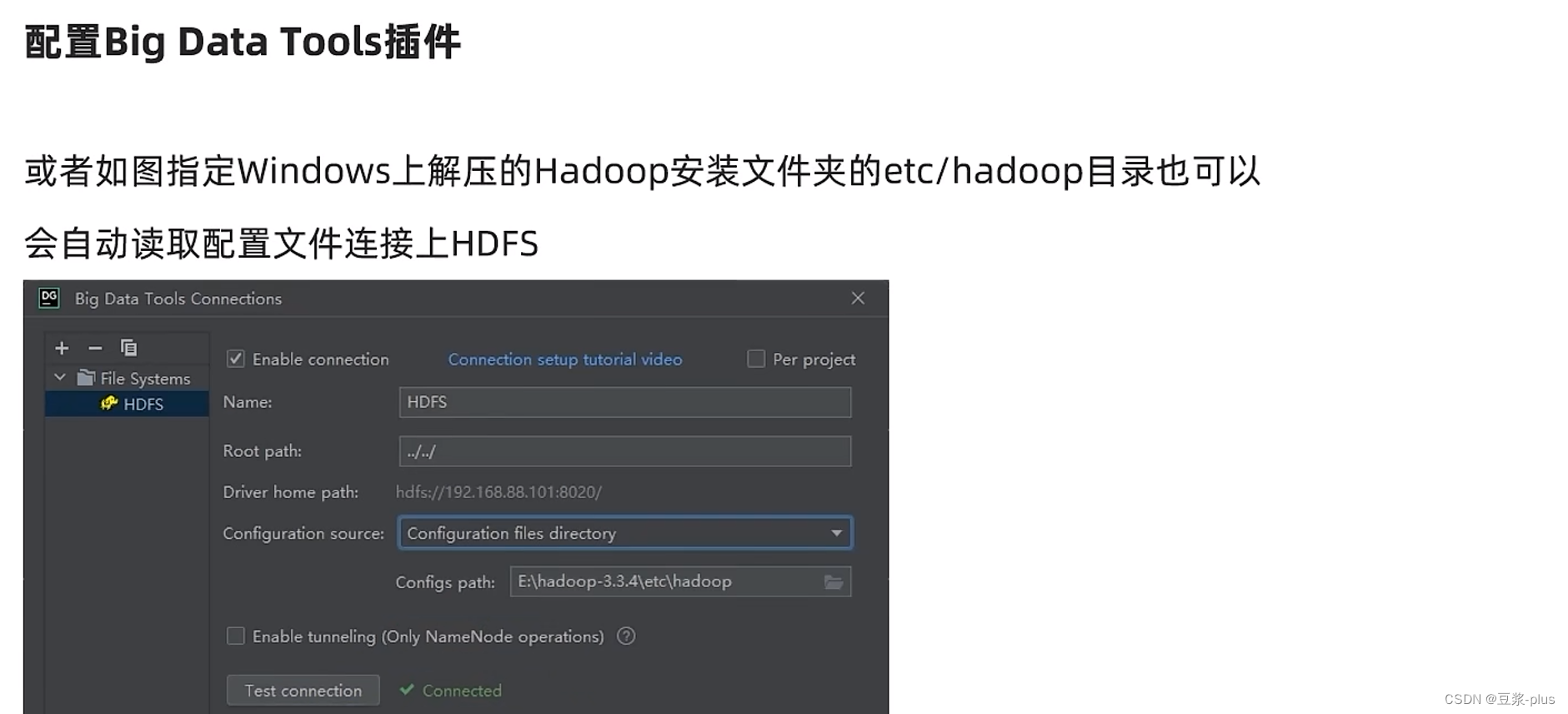
7.7 JetBrains使用插件
了解在JetBrains产品中安装使用BigDataTools插件


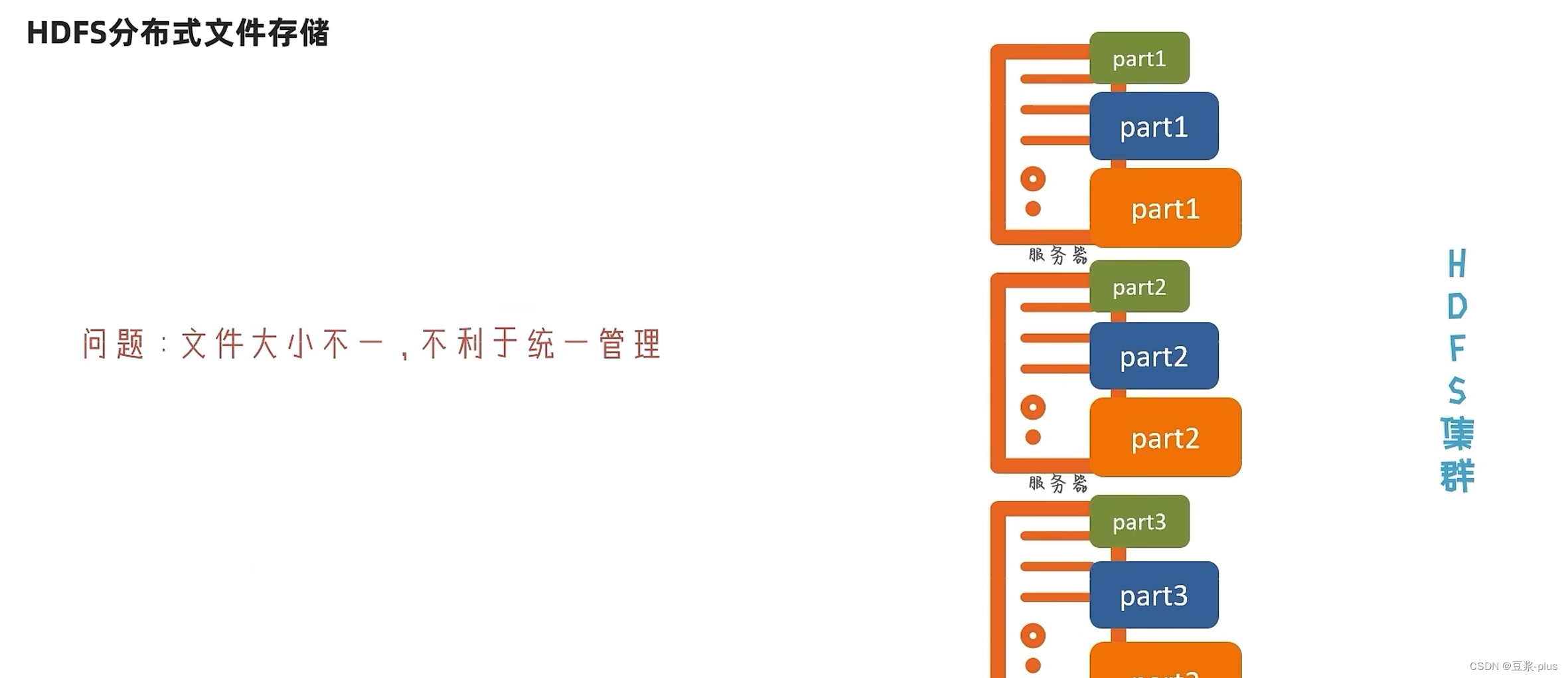
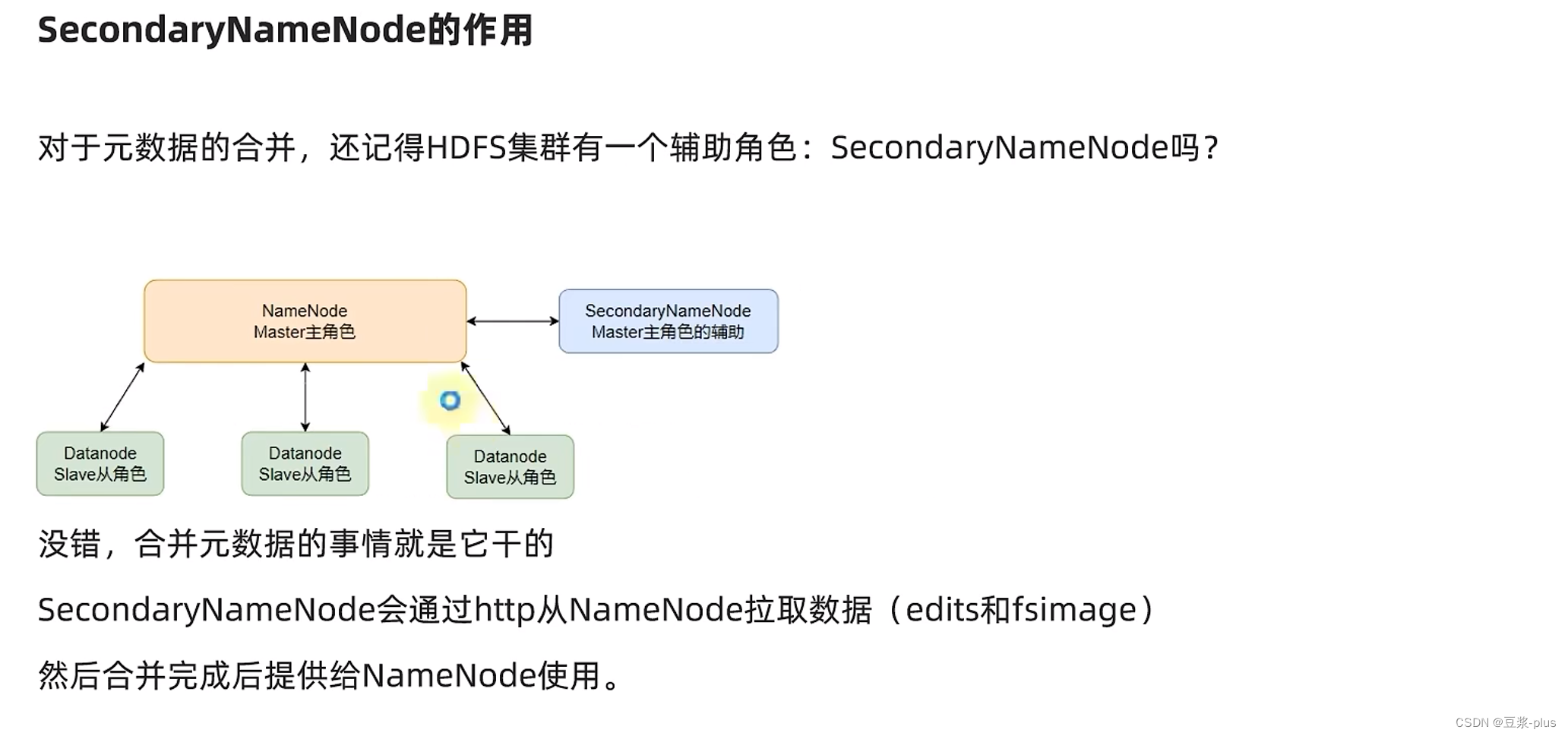
8 HDFS的存储原理

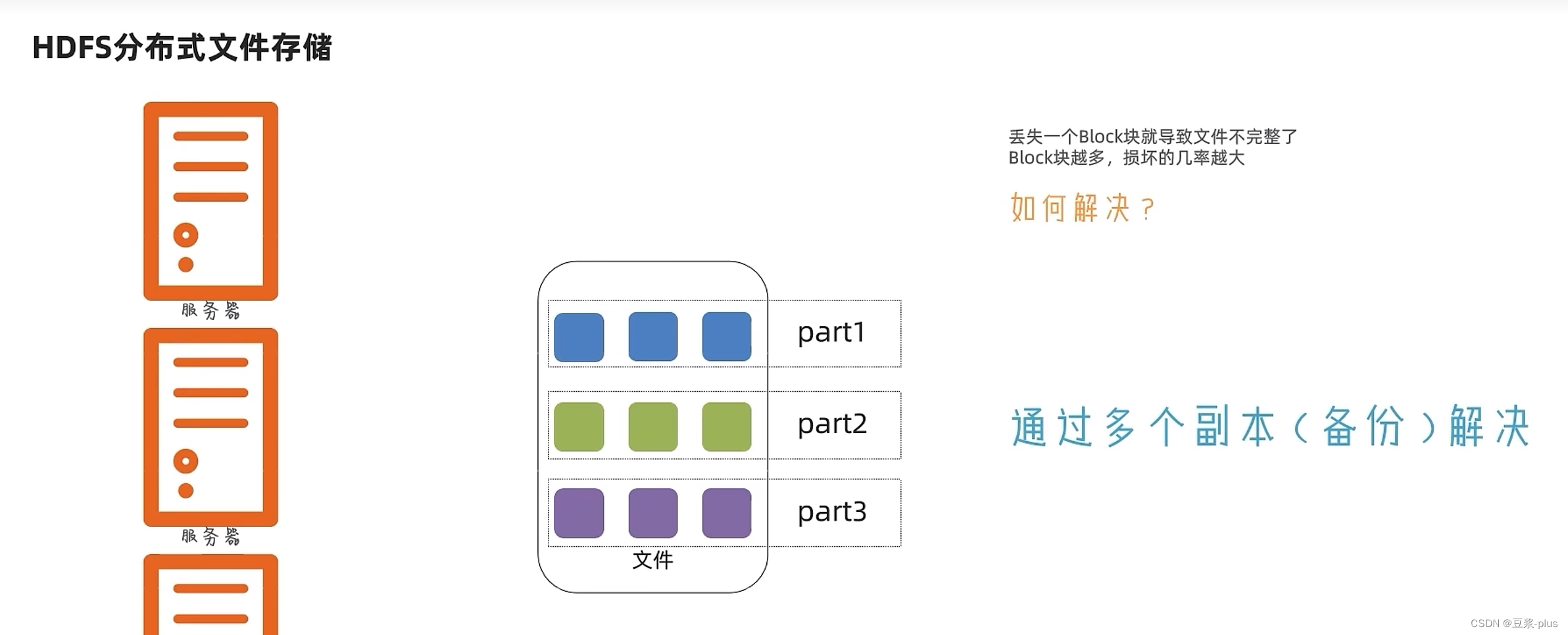


<property><name>dfs.replication</name><value>3</value></property> 








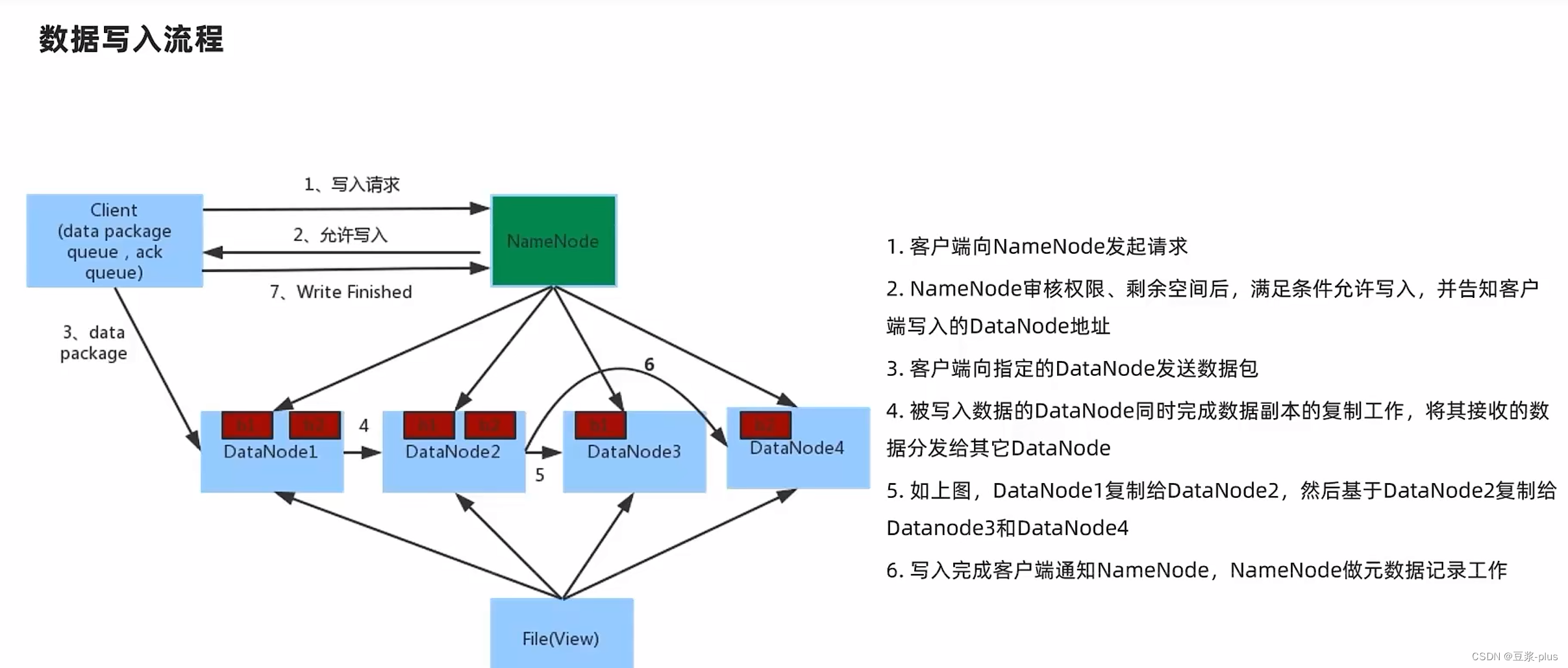
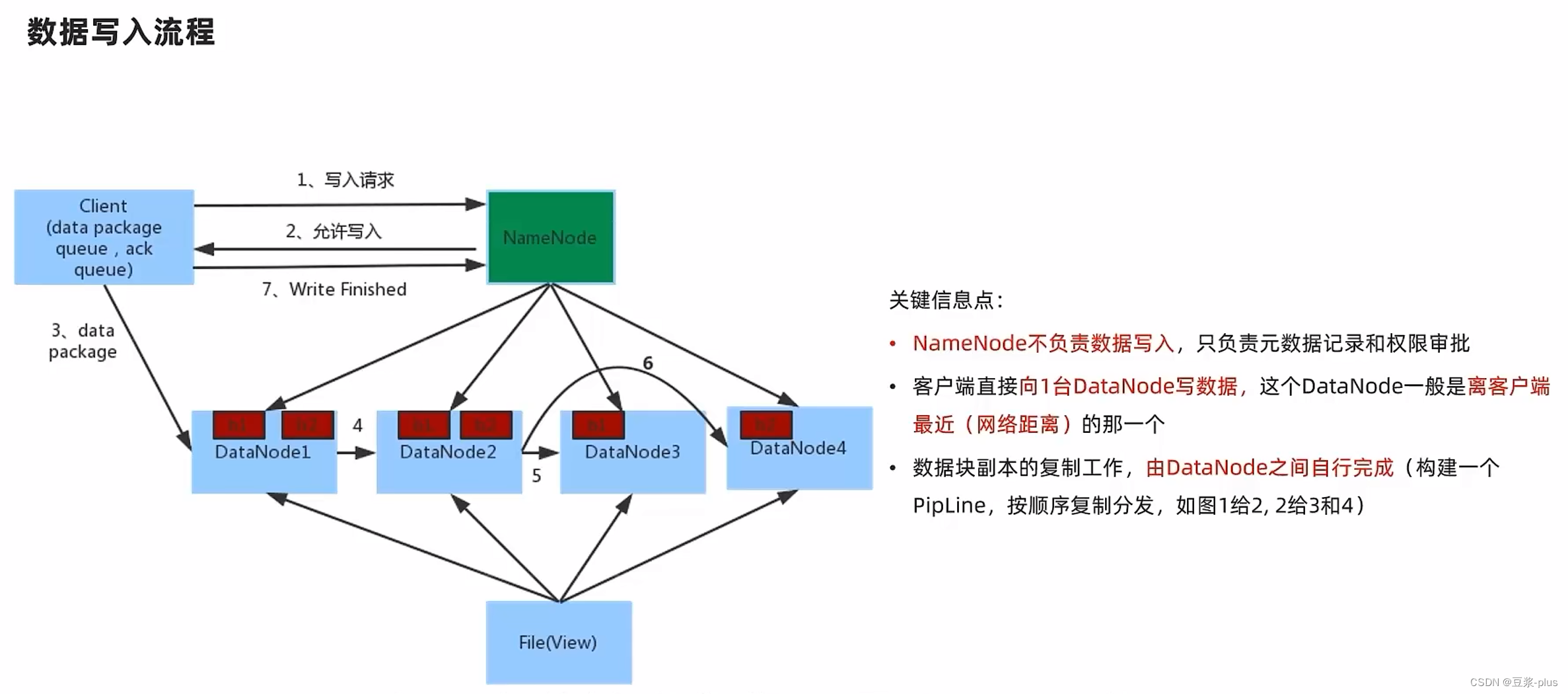
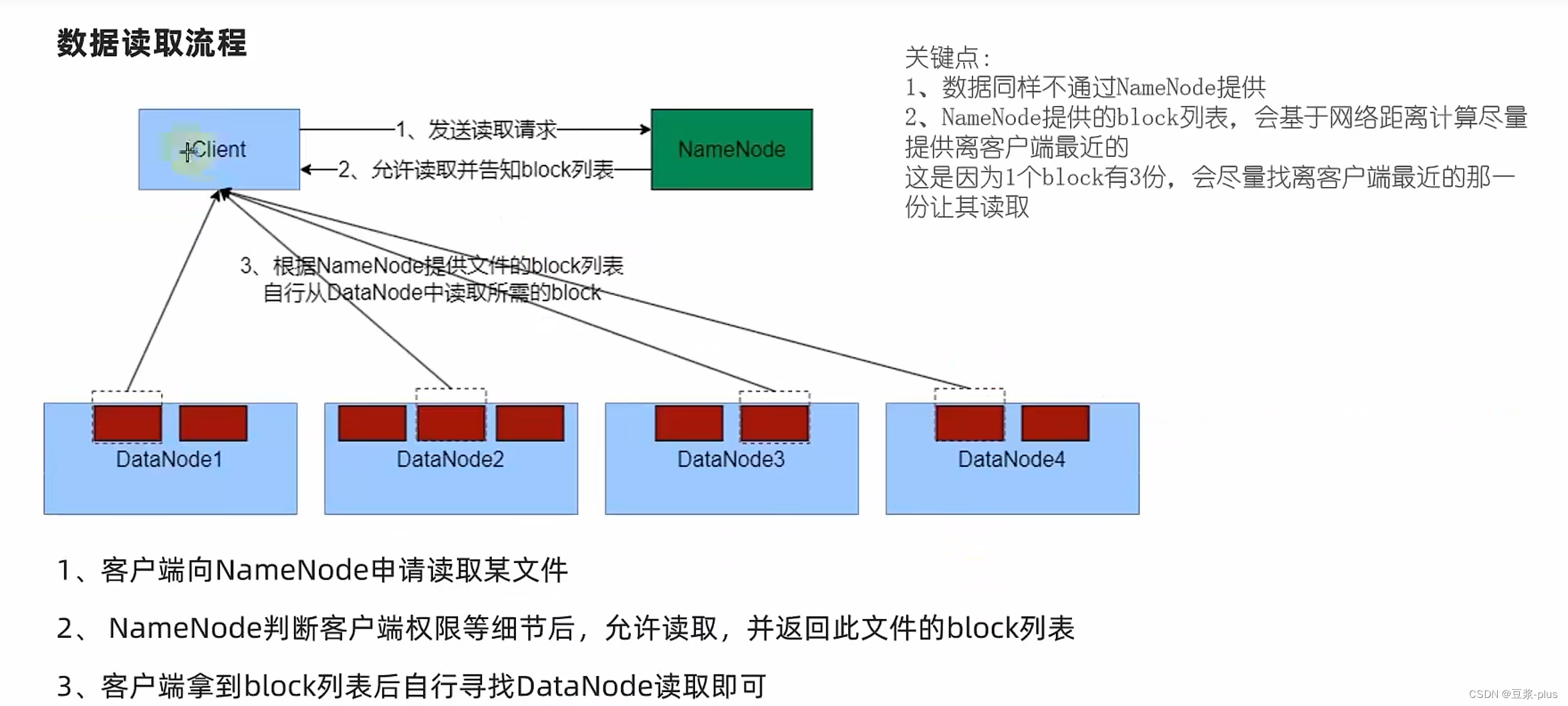

9.MapReduce


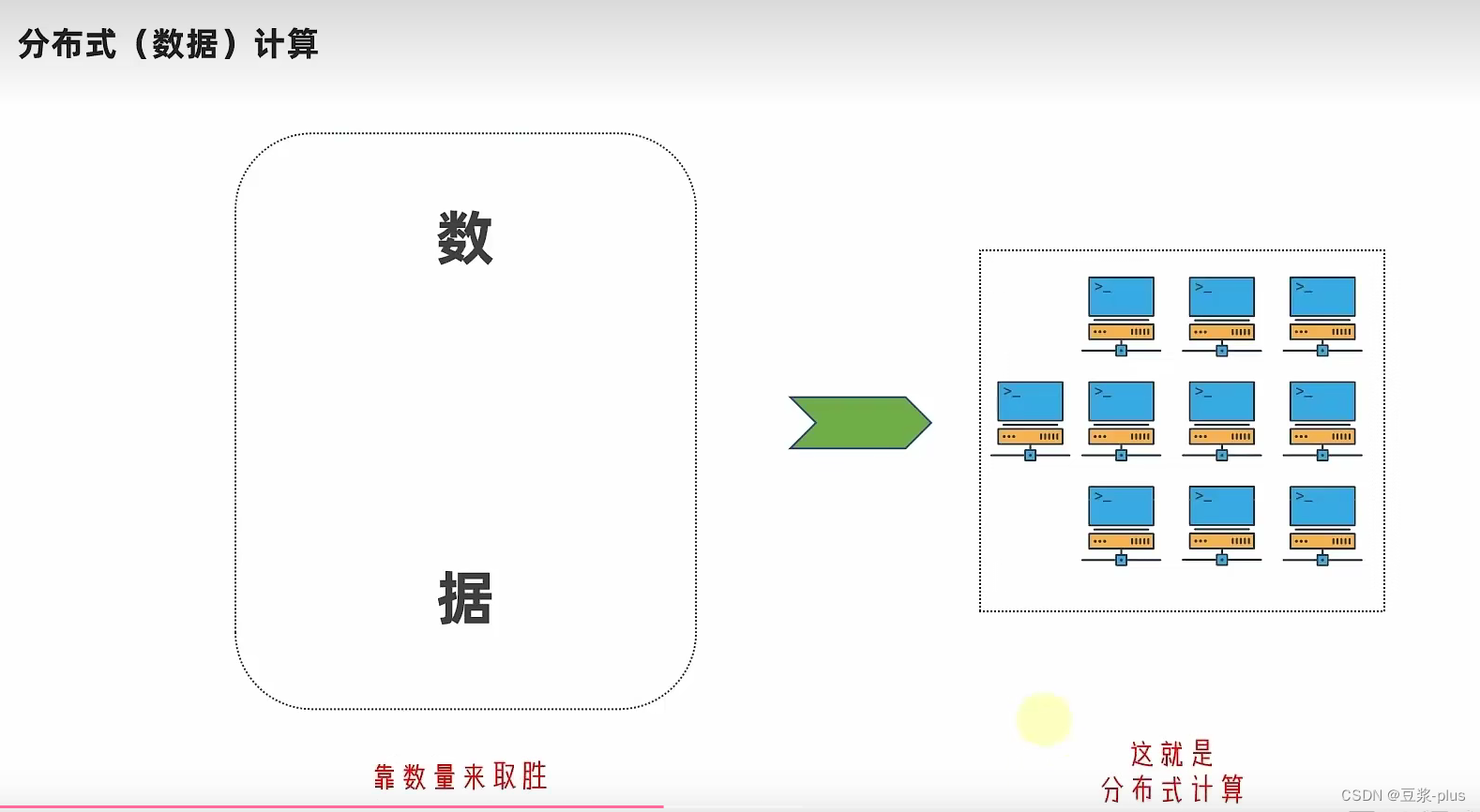

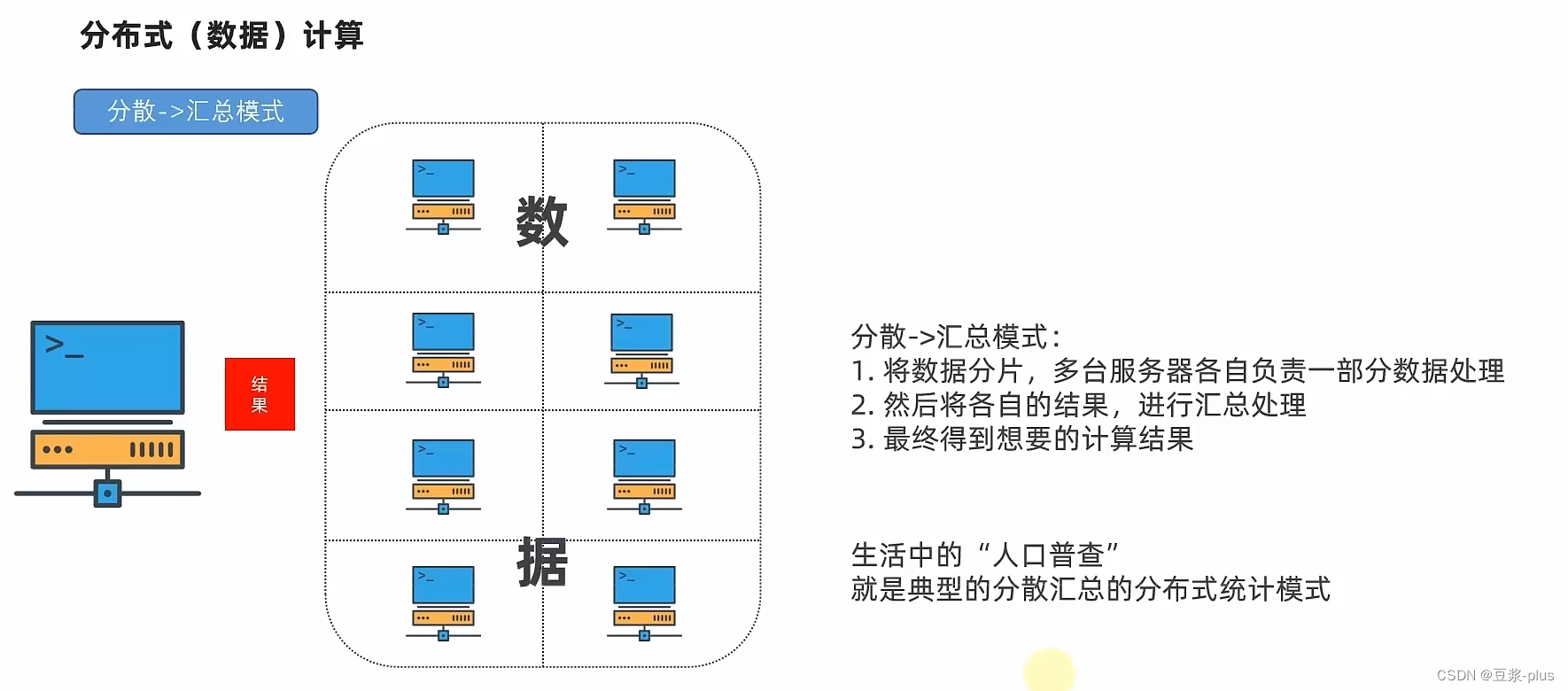
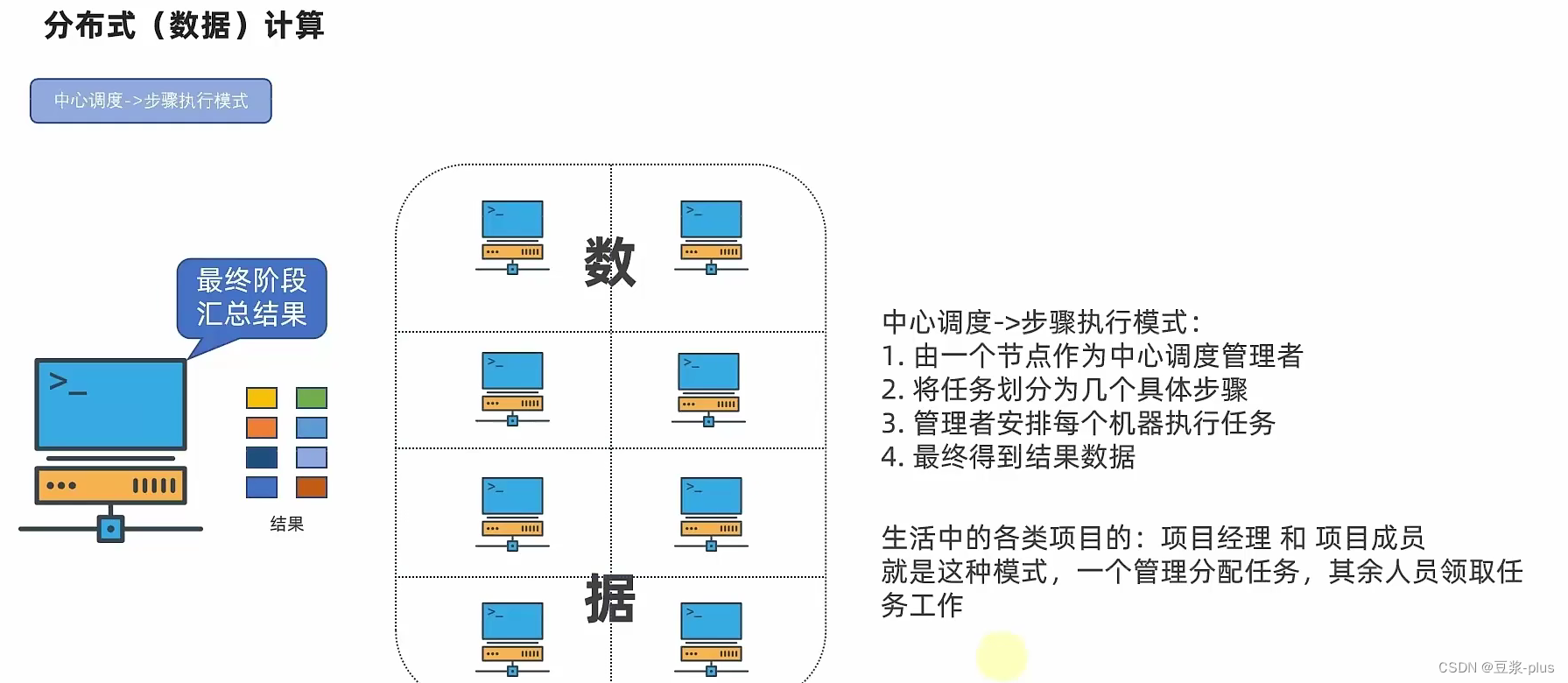



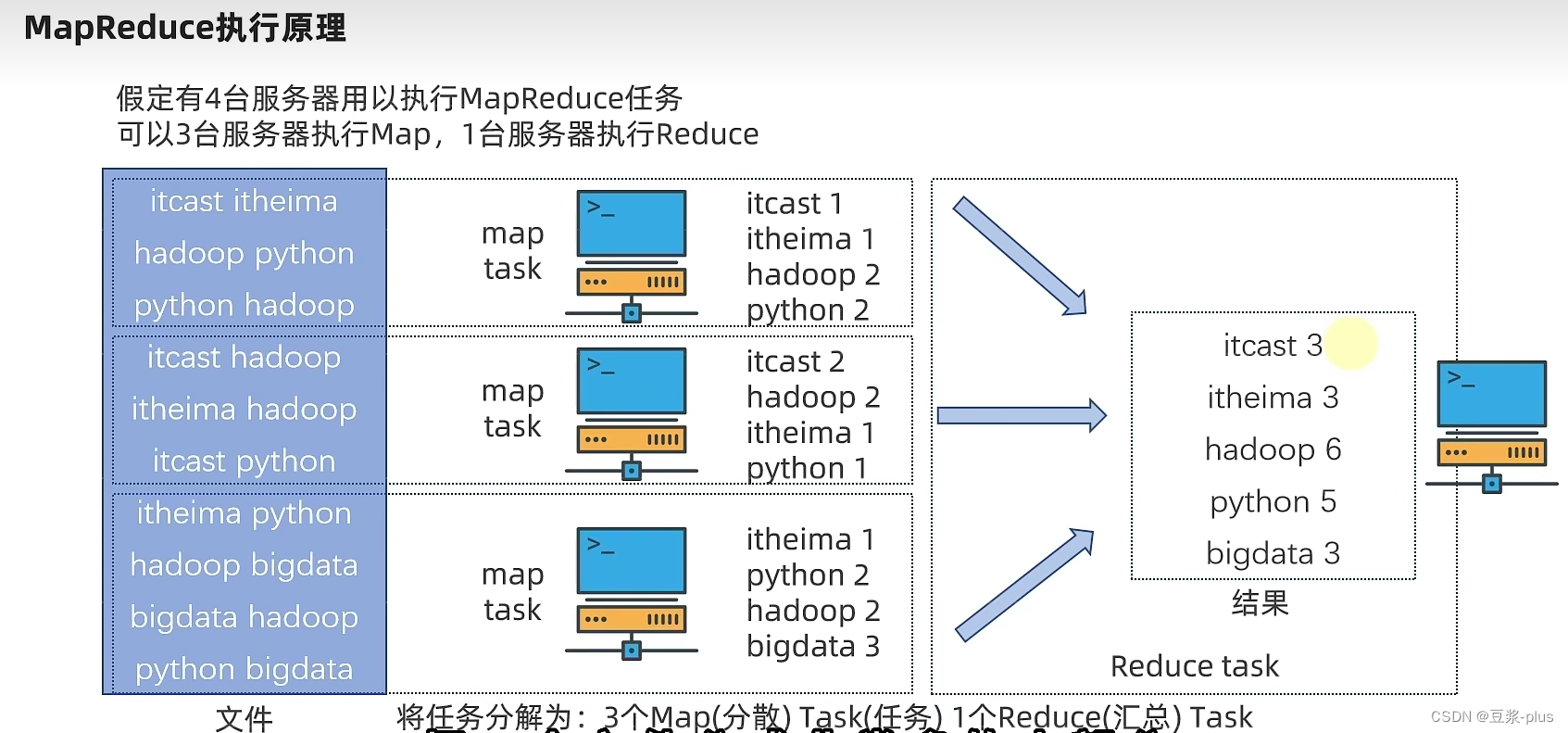

10. YARN
10.1 YARN 理论

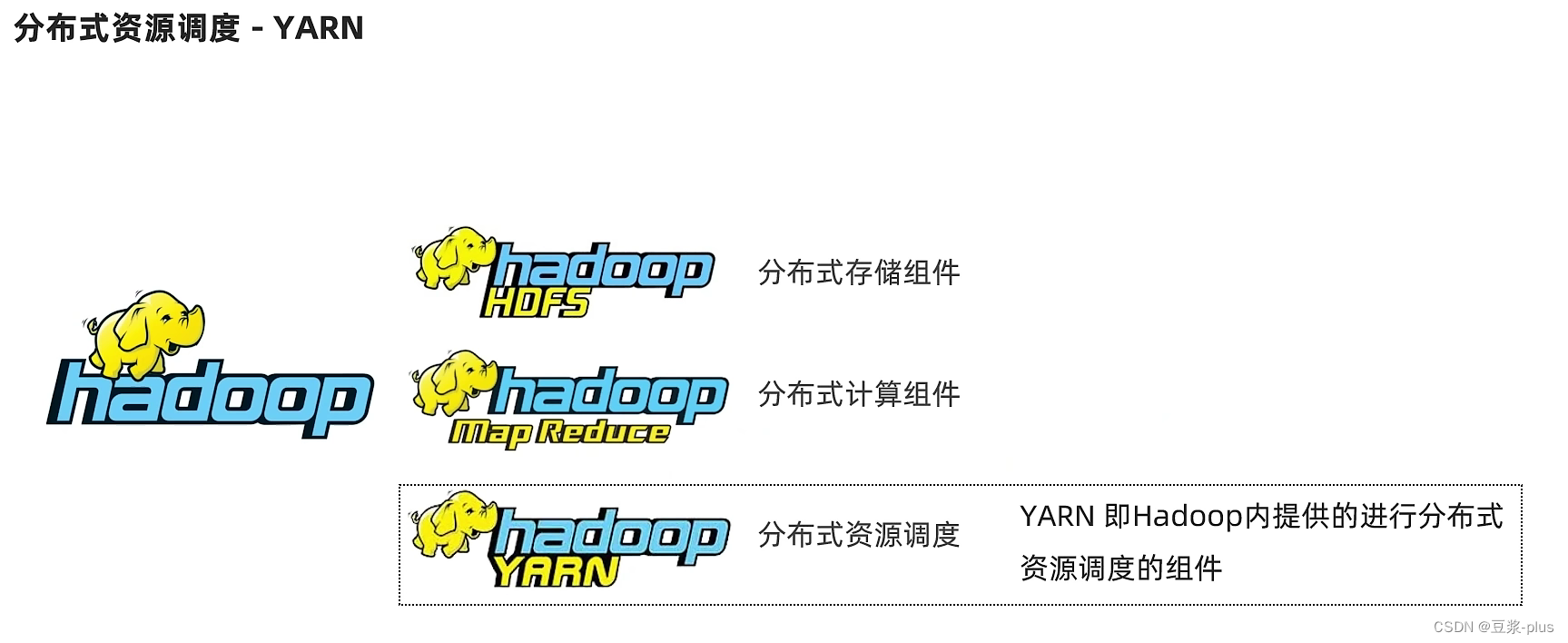


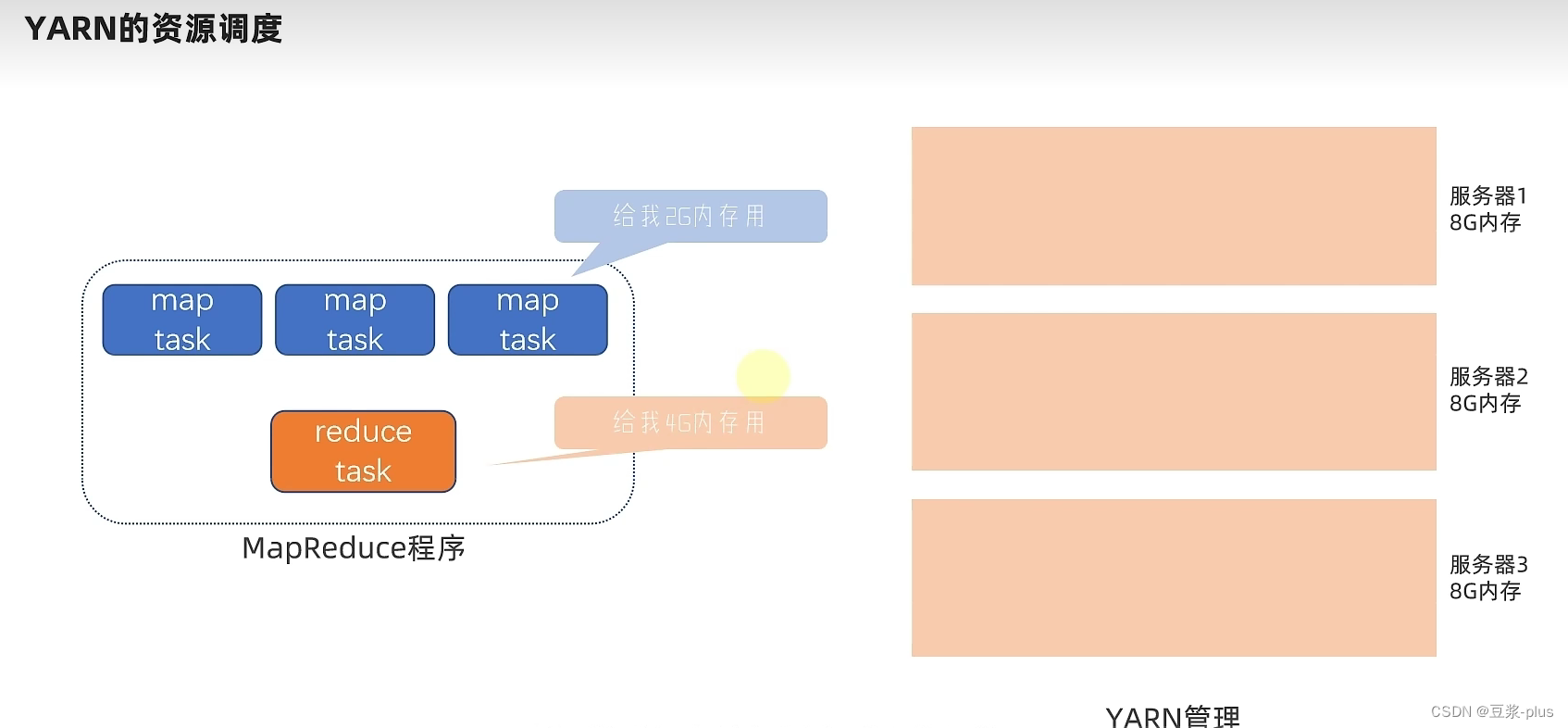
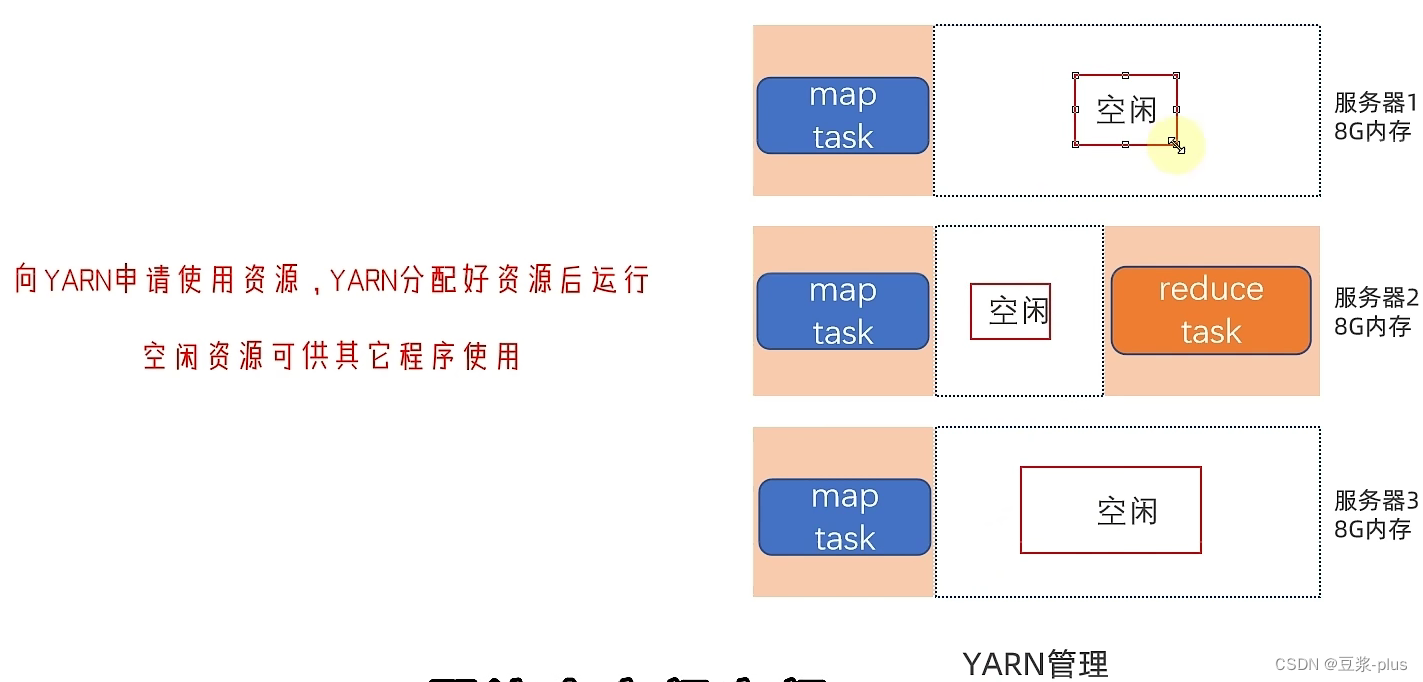
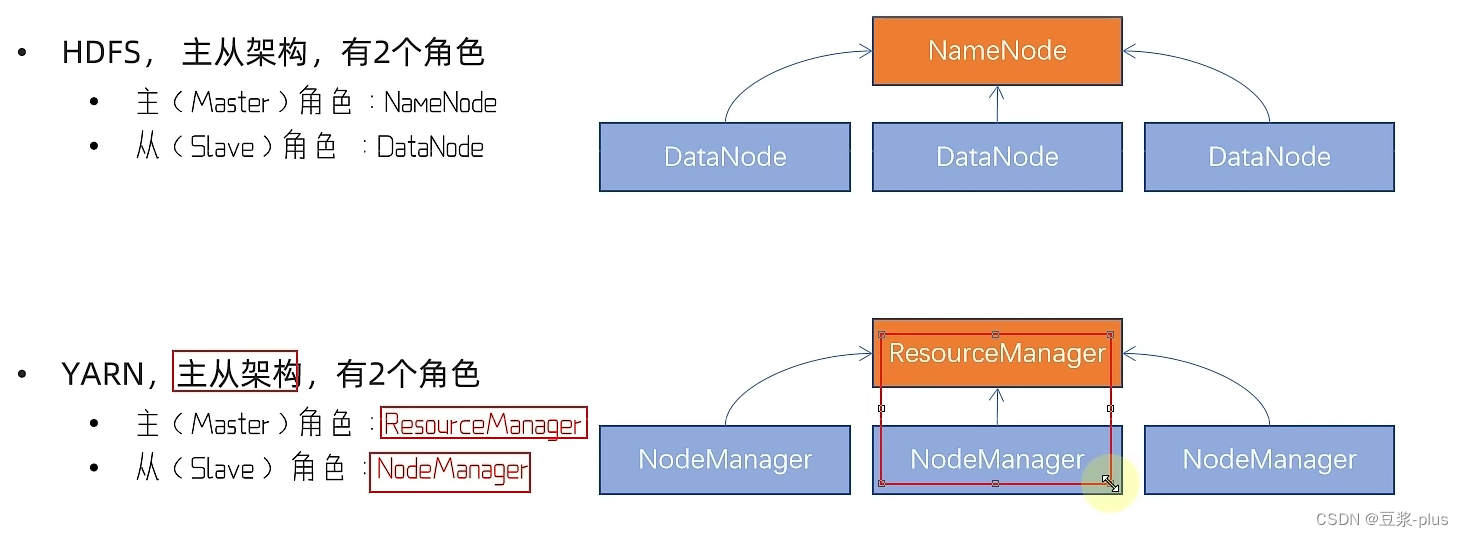
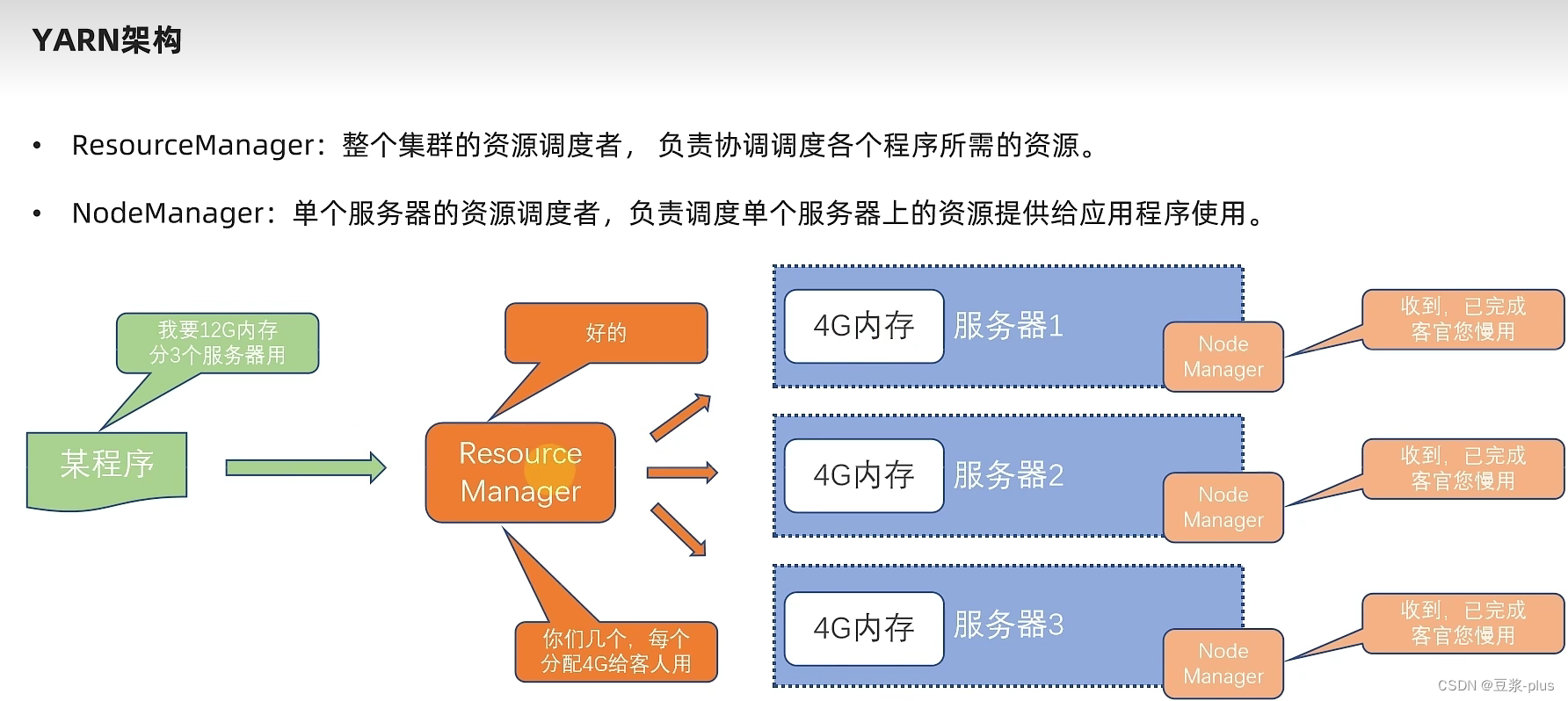
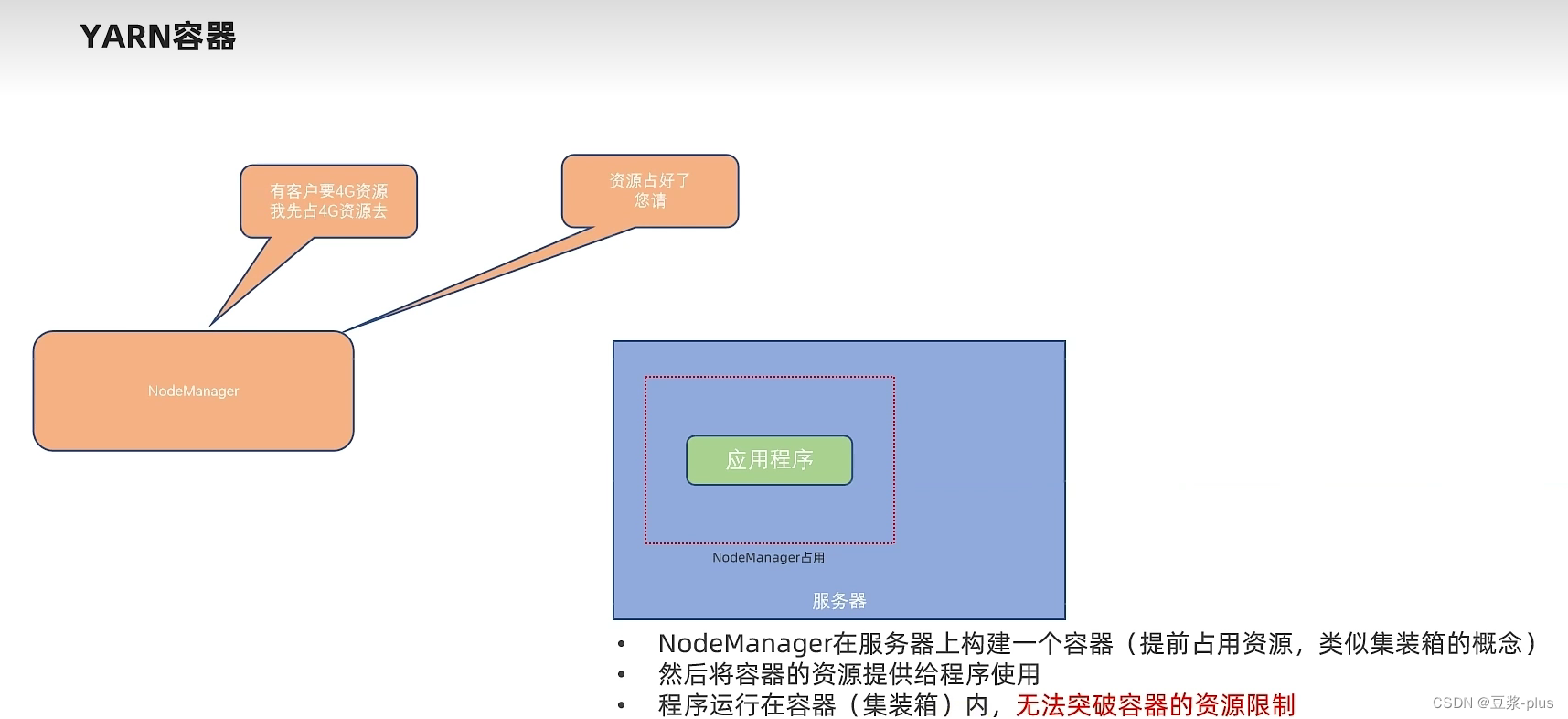
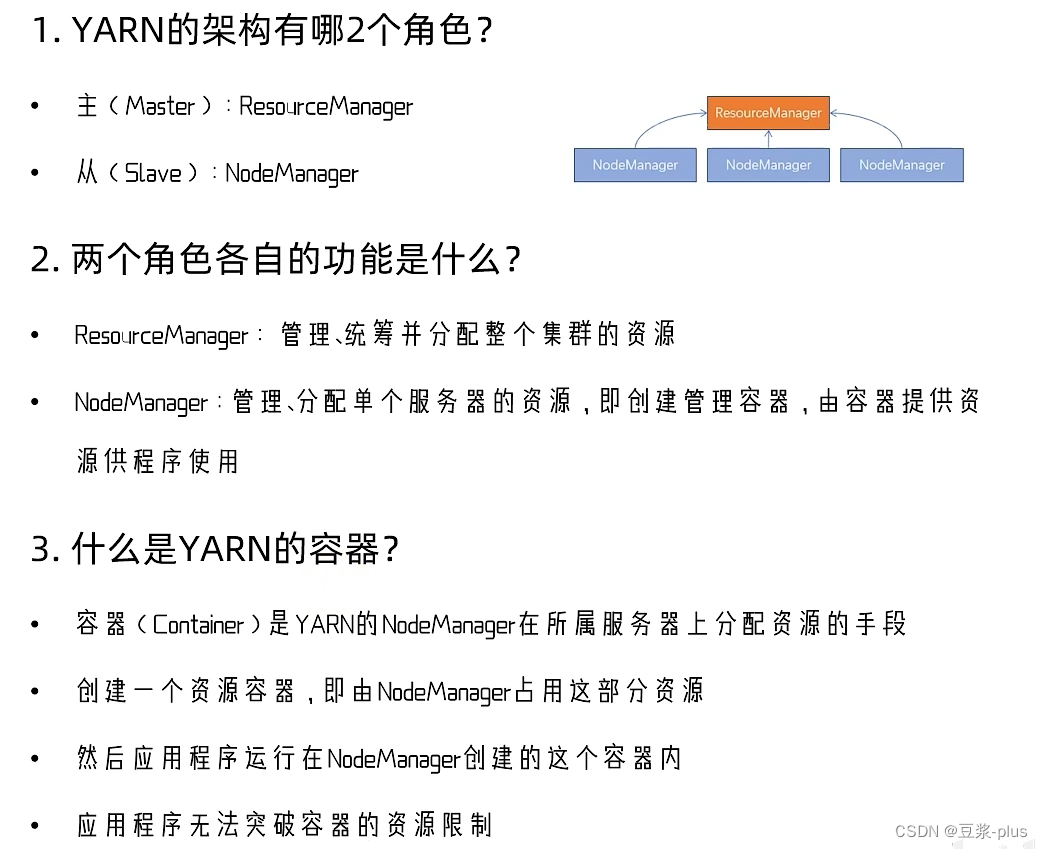




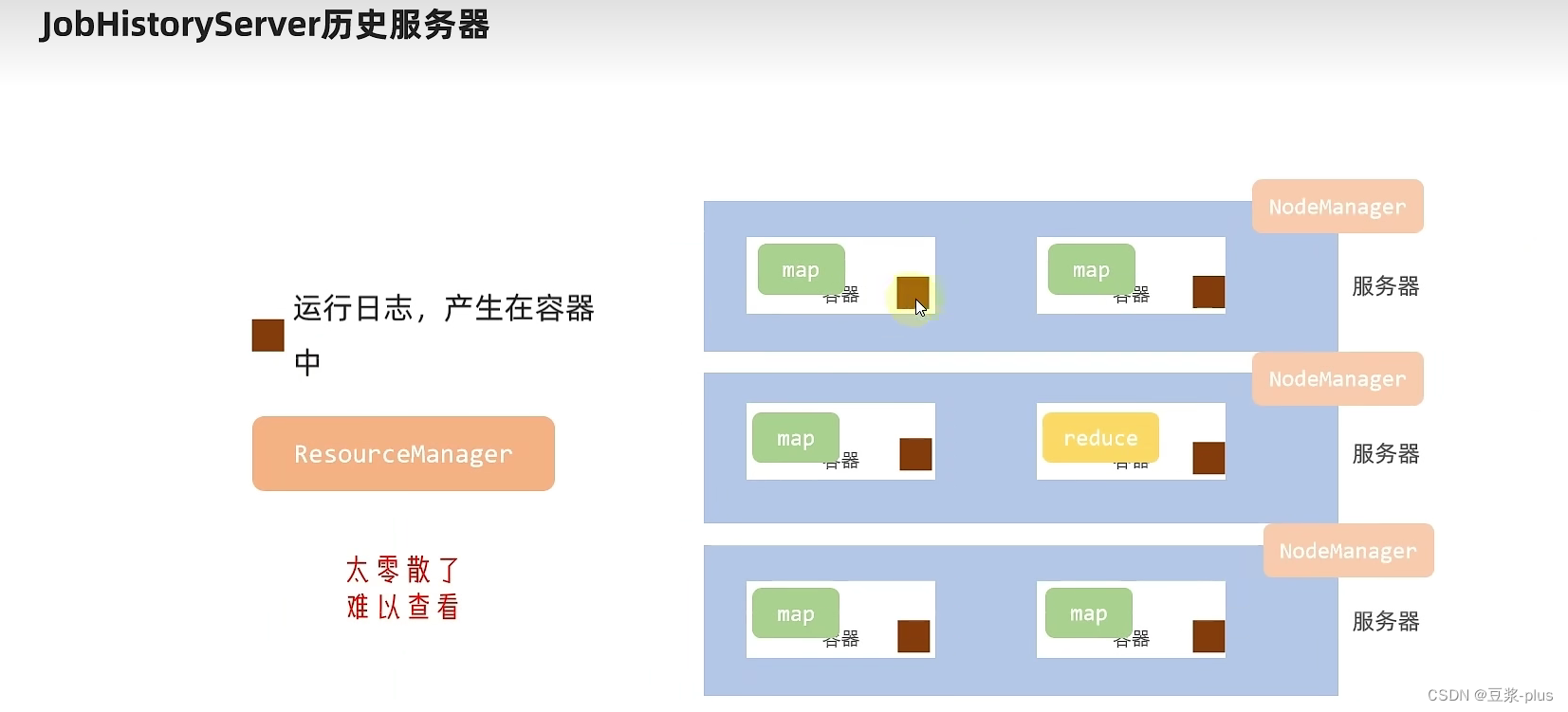
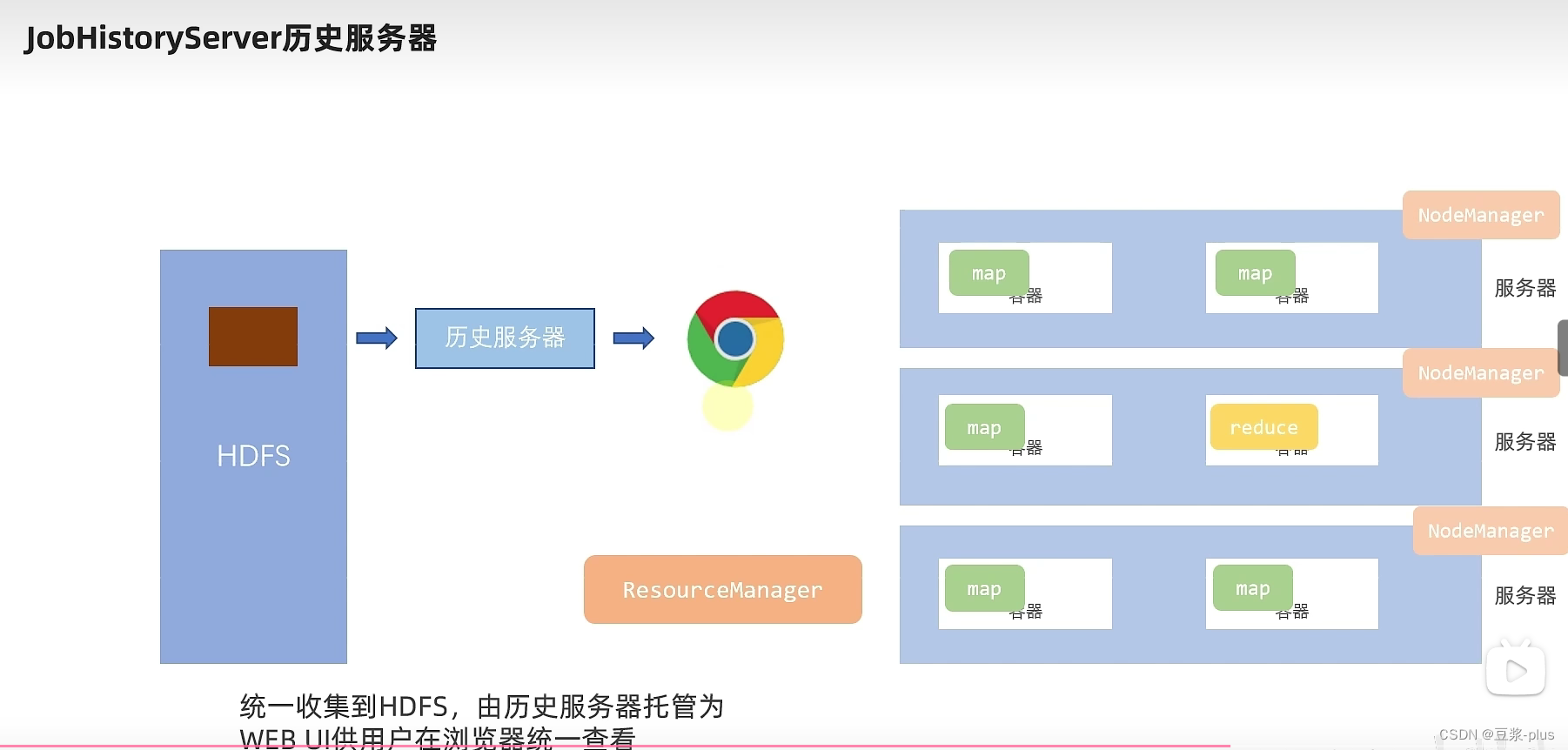
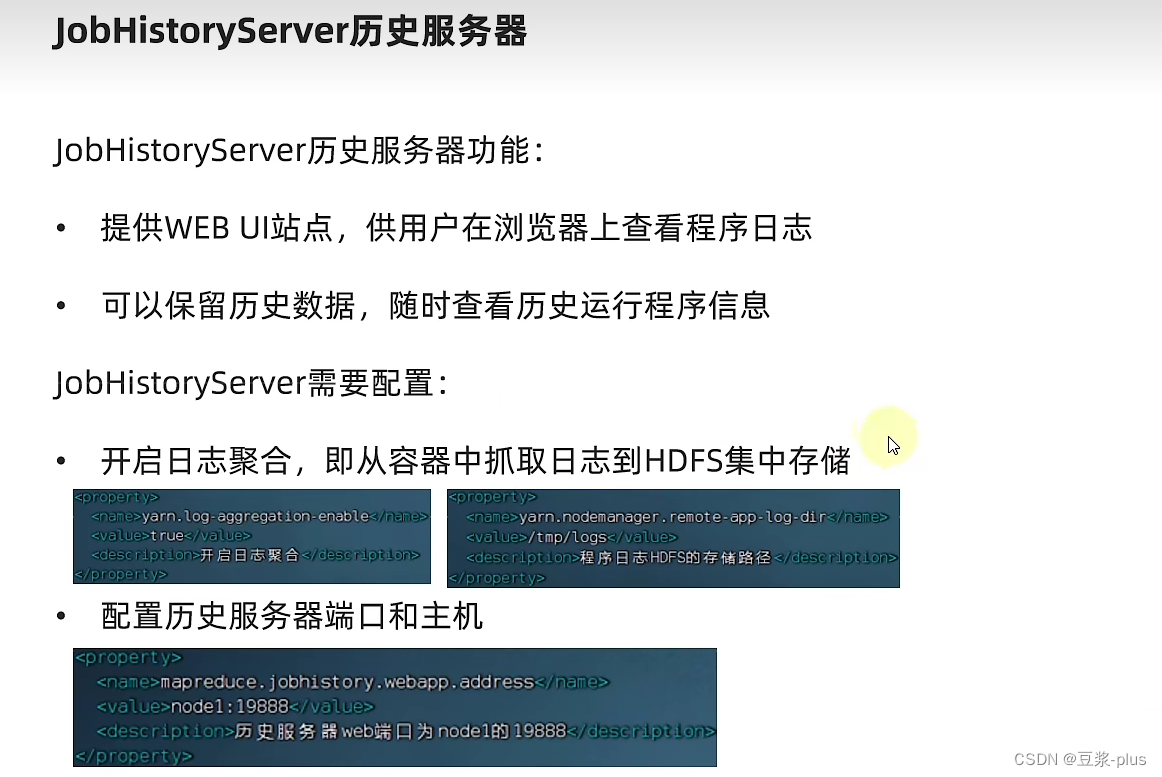

10.2 YARN 实践


1.
vm mapred-env.sh 
#设置JDK路径
export JAVA_HOME=/export/server/jdk
# 设置JobHistoryServer进程内存为1G
export HADOOP_JOB_HISTORYSERVER_HEAPSIZE=1000
#设置日志级别为INFO
export HADOOP_MAPRED_ROOT_LOGGER=INFO,RFA2.

<property><name>mapreduce.framework.name</name><value>yarn</value><description>MapReduce的运行框架设置为YARN</description></property><property><name>mapreduce.jobhistory.address</name><value>node1:10020</value><description>历史服务器通讯端口为node1:10020</description></property><property><name>mapreduce.jobhistory.webapp.address</name><value>node1:19888</value><description>历史服务器web端口为node1:19888</description></property><property><name>mapreduce.jobhistory.intermediate-done-dir</name><value>/data/mr-history/tmp</value><description>历史信息HDFS的记录临时路径</description></property><property><name>mapreduce.jobhistory.done-dir</name><value>/data/mr-history/done</value><description>历史信息HDFS的记录路径</description></property><property><name>yarn.app.mapreduce.am.env</name><value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value><description>MapReduce HOME 设置为 HADOOP_HOME</description></property><property><name>mapreduce.map.env</name><value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value><description>MapReduce HOME 设置为 HADOOP_HOME</description></property><property><name>mapreduce.reduce.env</name><value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value><description>MapReduce HOME 设置为 HADOOP_HOME</description></property>
1.

# 设置JDK路径的环境变显
export JAVA_HOME=/export/server/jdk
# 设置HADOOP HOME的环境变品
export HAD00P_HOME=/export/server/hadoop#设置配置文件路径的环境变品
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop#设置目志文件路备的环境变量
export HADOOP_LOG_DIR=$HADOOP_HOME/logs2.
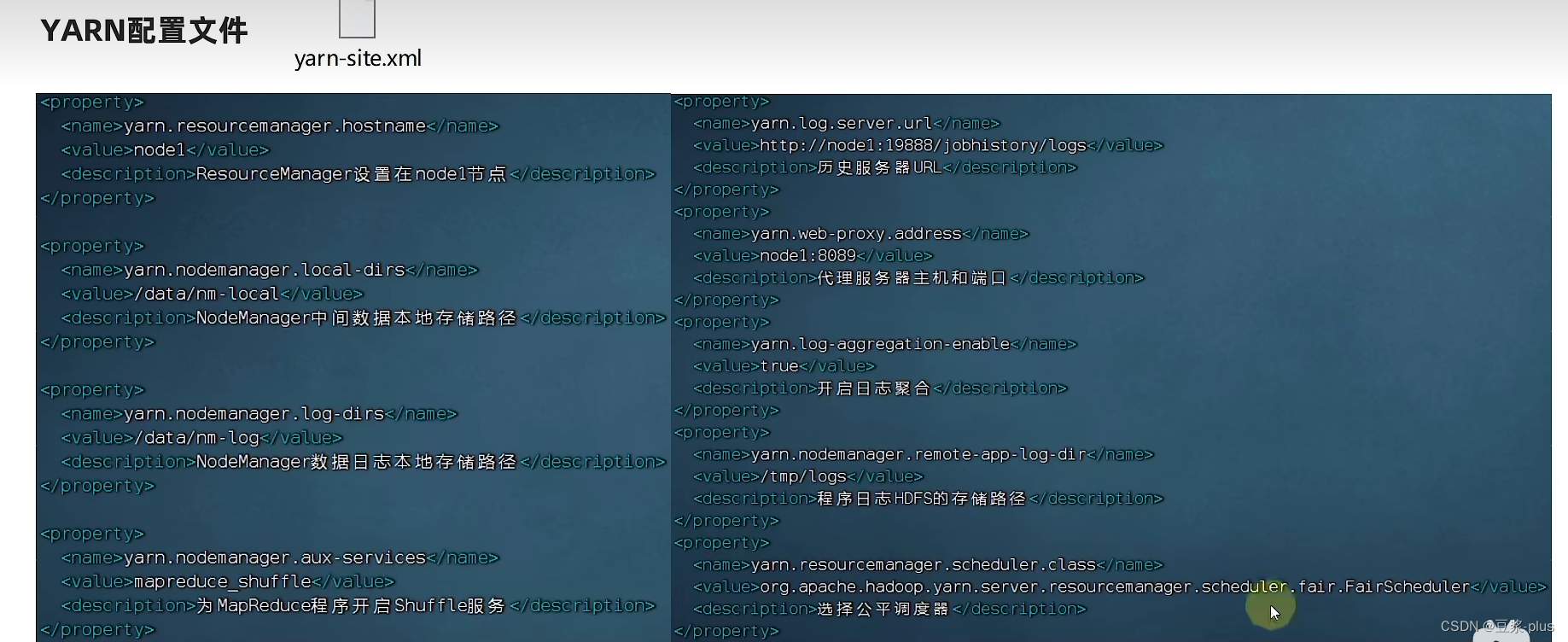
<property><name>yarn.resourcemanger.hostname</name><value>node1</value><description>ResourceManager设置在node1节点</description></property><property><name>yarn.nodemanager.local-dirs</name><value>/data/nm-local</value><description>Nodemanager证中间数据本地存储路径</description></property><property><name>yarn.nodemanager.log-dirs</name><value>/data/nm-log</value><description>Nodemanager数据日志本地存储路径</description></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value><description>为MapReduce程序开启Shuffle服务</description></property><property><name>yarn.log.server.url</name><value>http://node1:19888/jobhistory/logs</value><description>历史服务器URL</description></property><property><name>yarn.web-proxy.address</name><value>node1:8089</value><description>代理服务器主机和端口</description></property><property><name>yarn.log-aggregation-enable</name><value>true</value><description>开启日志聚合</description></property><property><name>yarn.nodemanager.remote-app-log-dir</name><value>/tmp/logs</value><description>程序日志HDFS的存储日志</description></property><property><name>yarn.resourcemanager.scheduler.class</name><value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value><description>选择公平调度器</description></property> 3.
scp mapred-env.sh mapred-site.xml yarn-env.sh yarn-site.xml node3:/export/server/hadoop/etc/hadoop

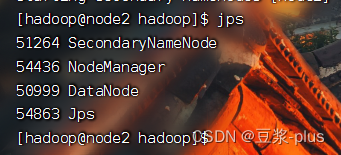
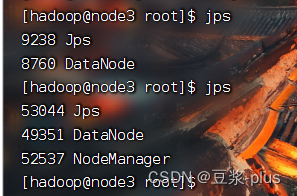
mapred --daemon start historyserver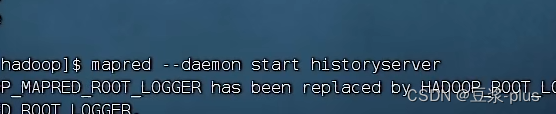
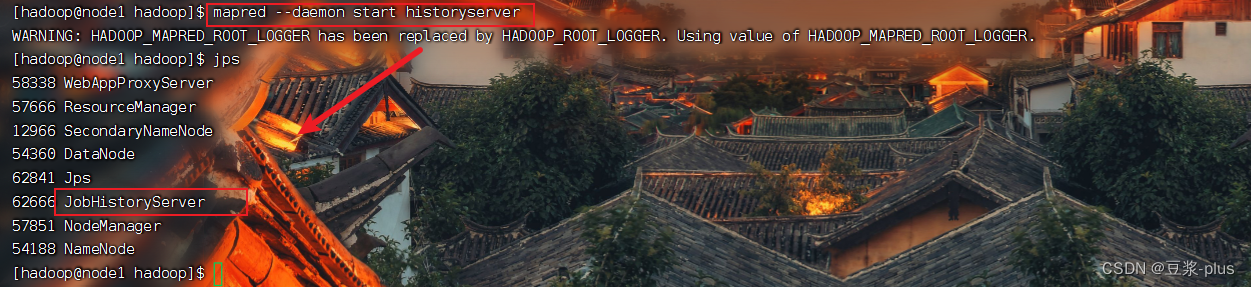
mapred --daemon start historyserver




提交MapReduce任务到YARN执行:





Hive理论
1.Hive理论
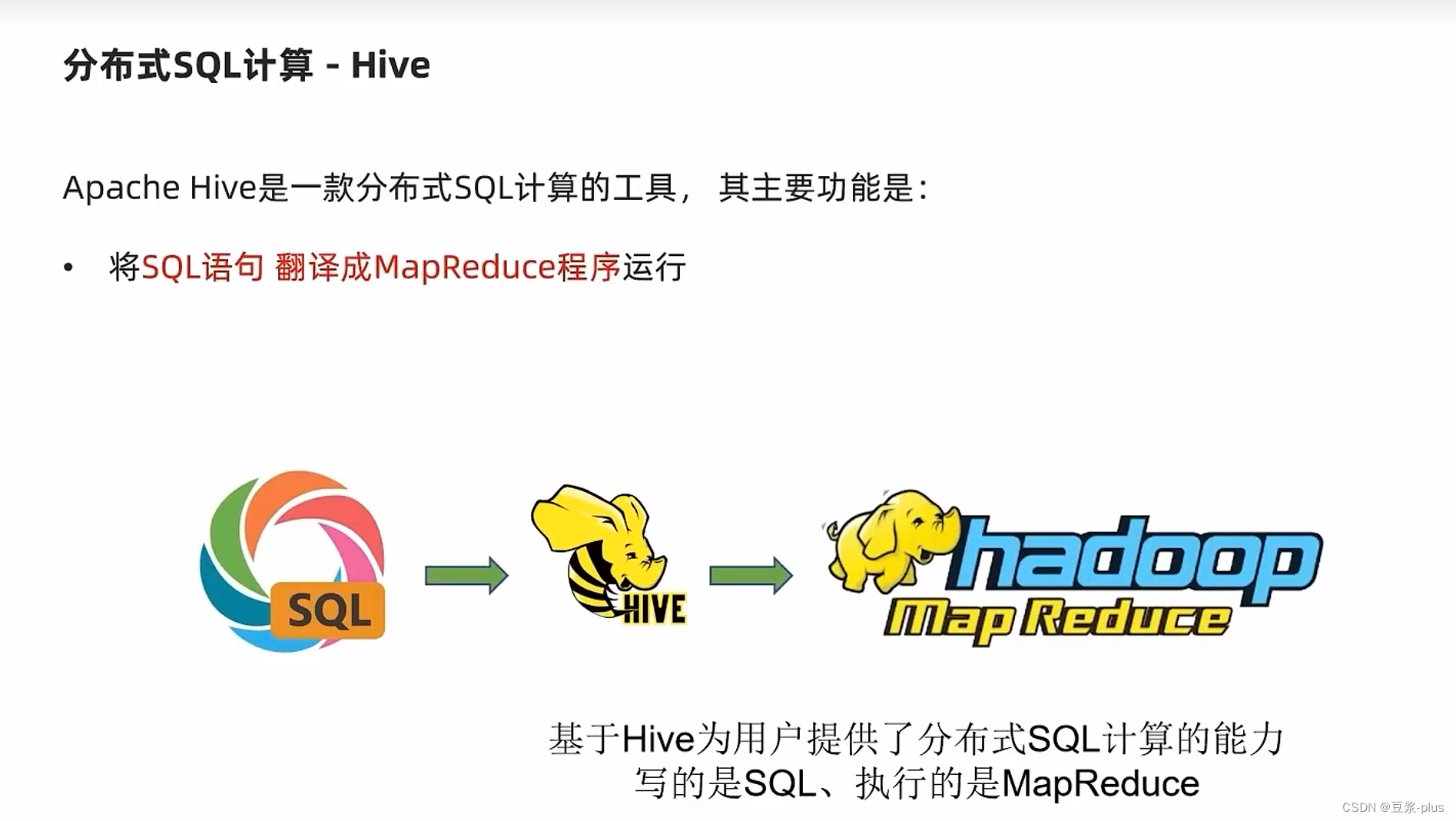






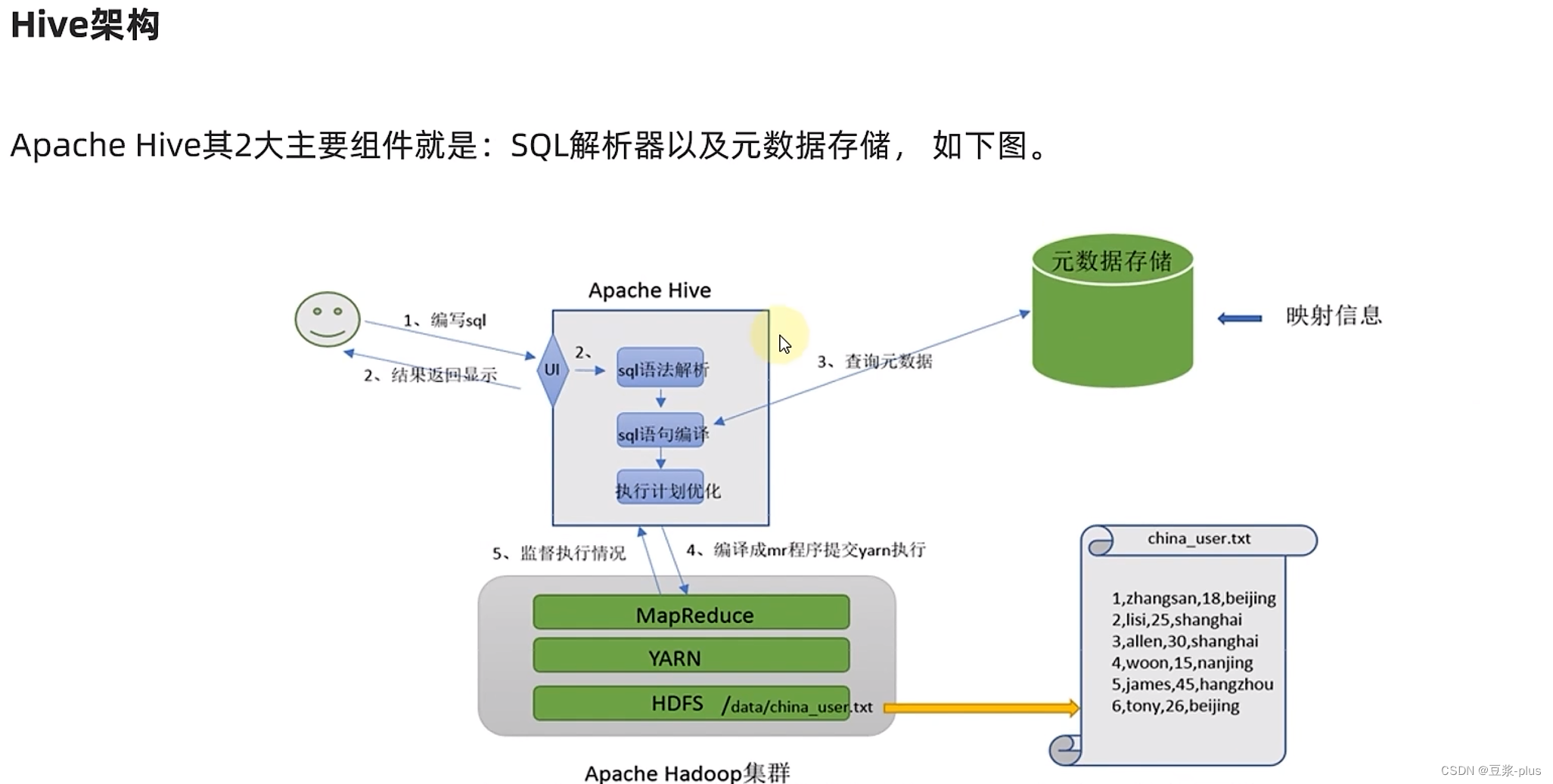

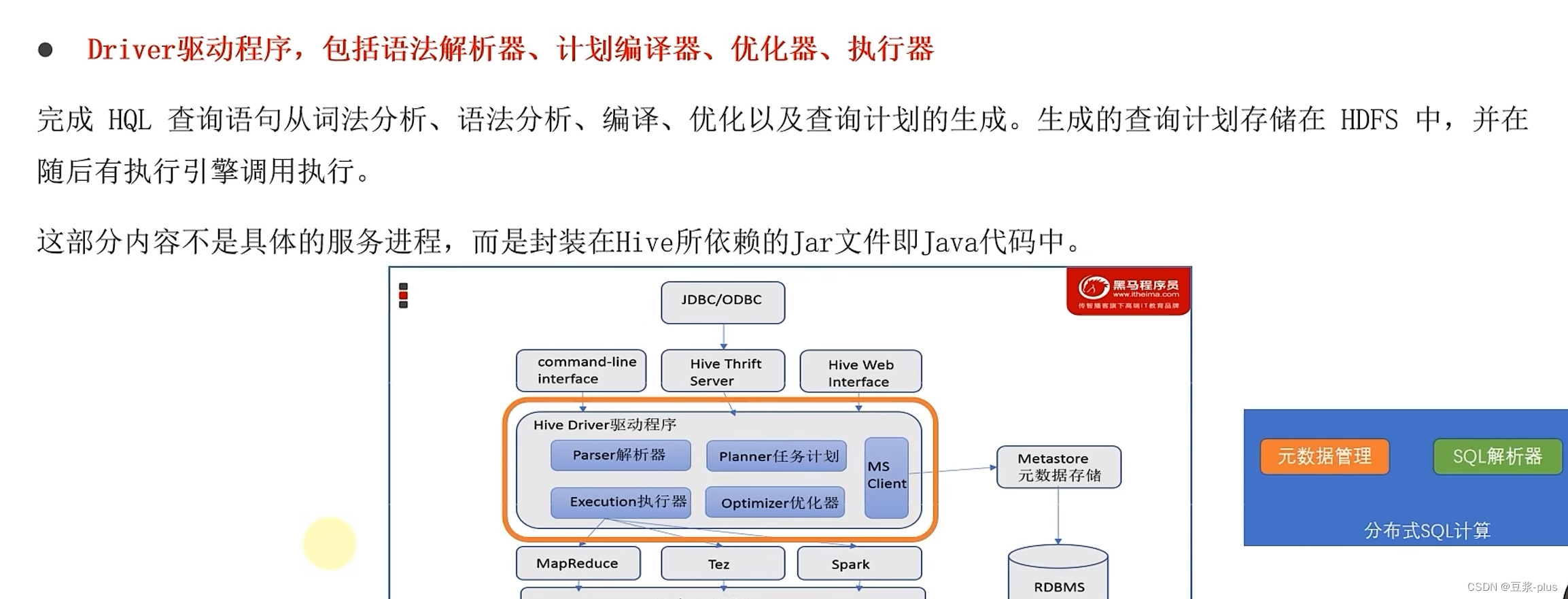
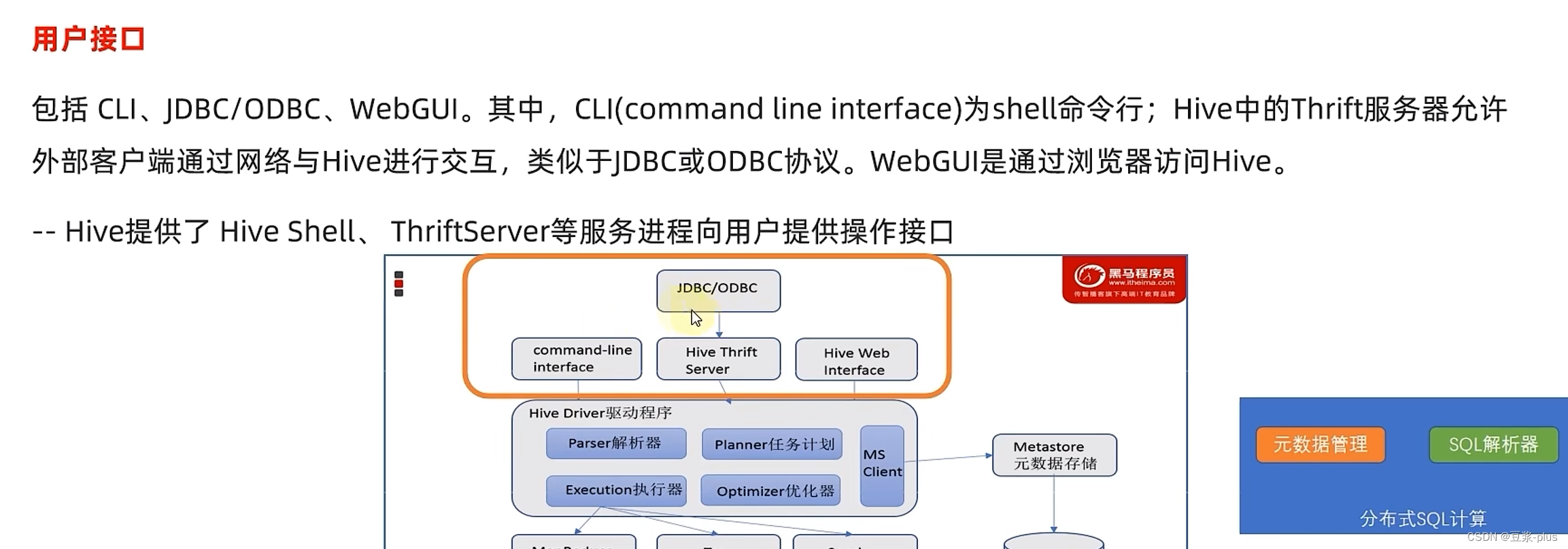
2.Hive部署
VMware:


# 更新密钥
rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2022
# 安装Mysql yum库
rpm -Uvh http://repo.mysql.com//mysql57-community-release-el7-7.noarch.rpm
# yum安装Mysql
yum -y install mysql-community-server
# 启动Mysql设置开机启动
systemctl start mysqld
systemctl enable mysqld
# 检查Mysql服务状态
systemctl status mysqld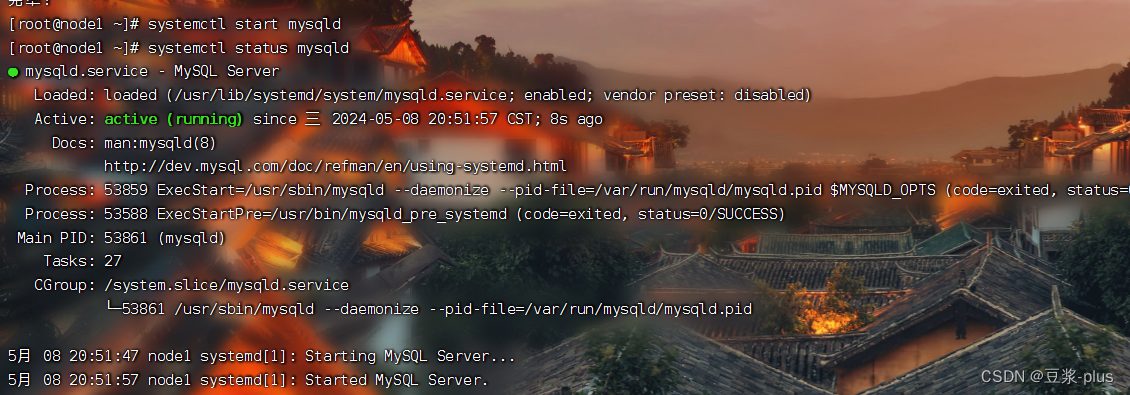
# 第一次启动mysql,会在日志文件中生成root用户的一个随机密码,使用下面命令查看该密码
grep 'temporary password' /var/log/mysqld.log
# 修改root用户密码
mysql -u root -p -h localhost
Enter password:
mysql> ALTER USER 'root'@'localhost' IDENTIFIED BY 'Root!@#$';
# 如果你想设置简单密码,需要降低Mysql的密码安全级别
set global validate_password_policy=LOW; # 密码安全级别低
set global validate_password_length=4; # 密码长度最低4位即可
# 然后就可以用简单密码了(课程中使用简单密码,为了方便,生产中不要这样)
ALTER USER 'root'@'localhost' IDENTIFIED BY 'root';
/usr/bin/mysqladmin -u root password 'root'
grant all privileges on *.* to root@"%" identified by 'root' with grant option;
flush privileges;
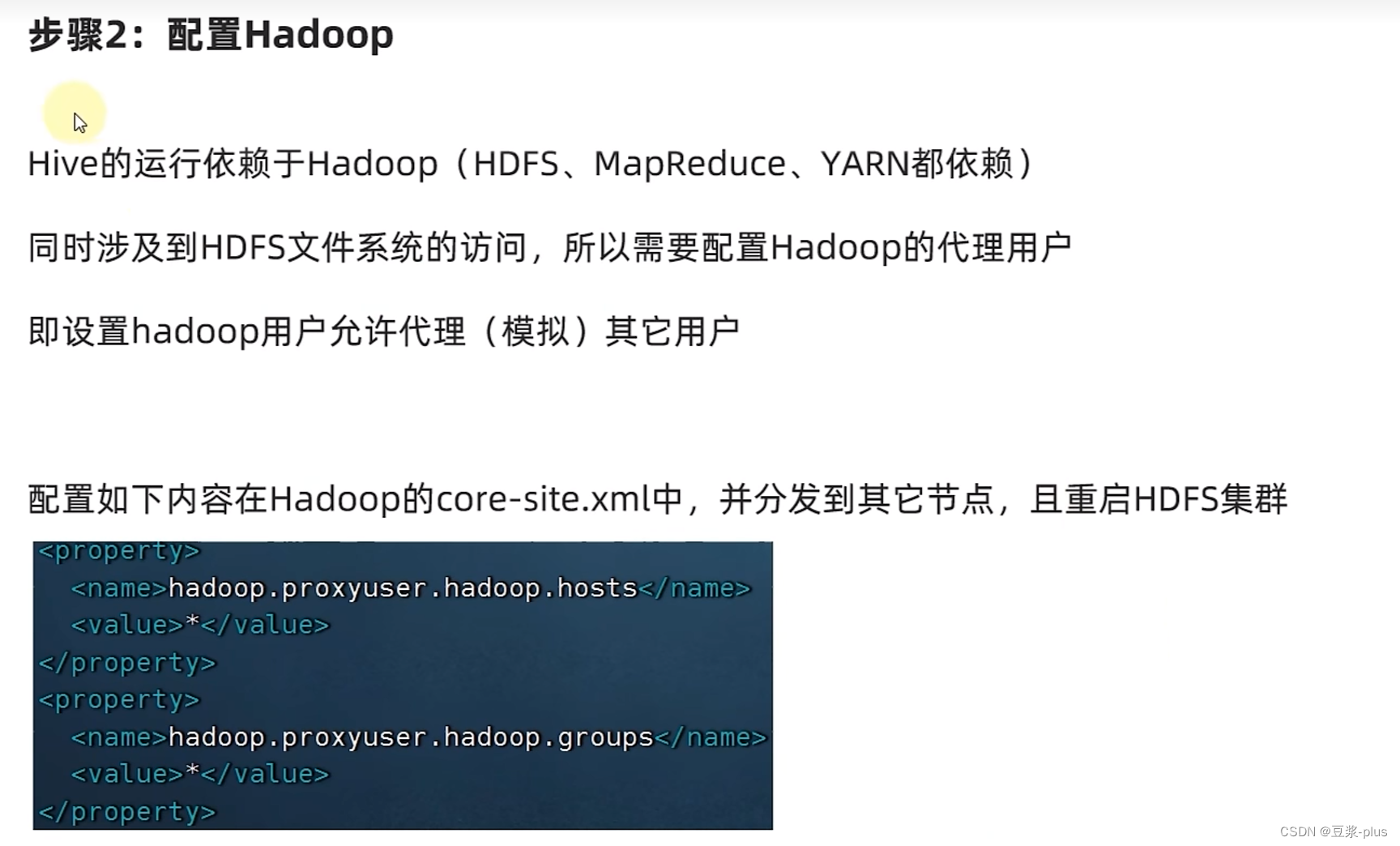
<property><name>hadoop.proxyuser.hadoop.hosts</name><value>*</value></property><property><name>hadoop.proxyuser.hadoop.groups</name><value>*</value></property>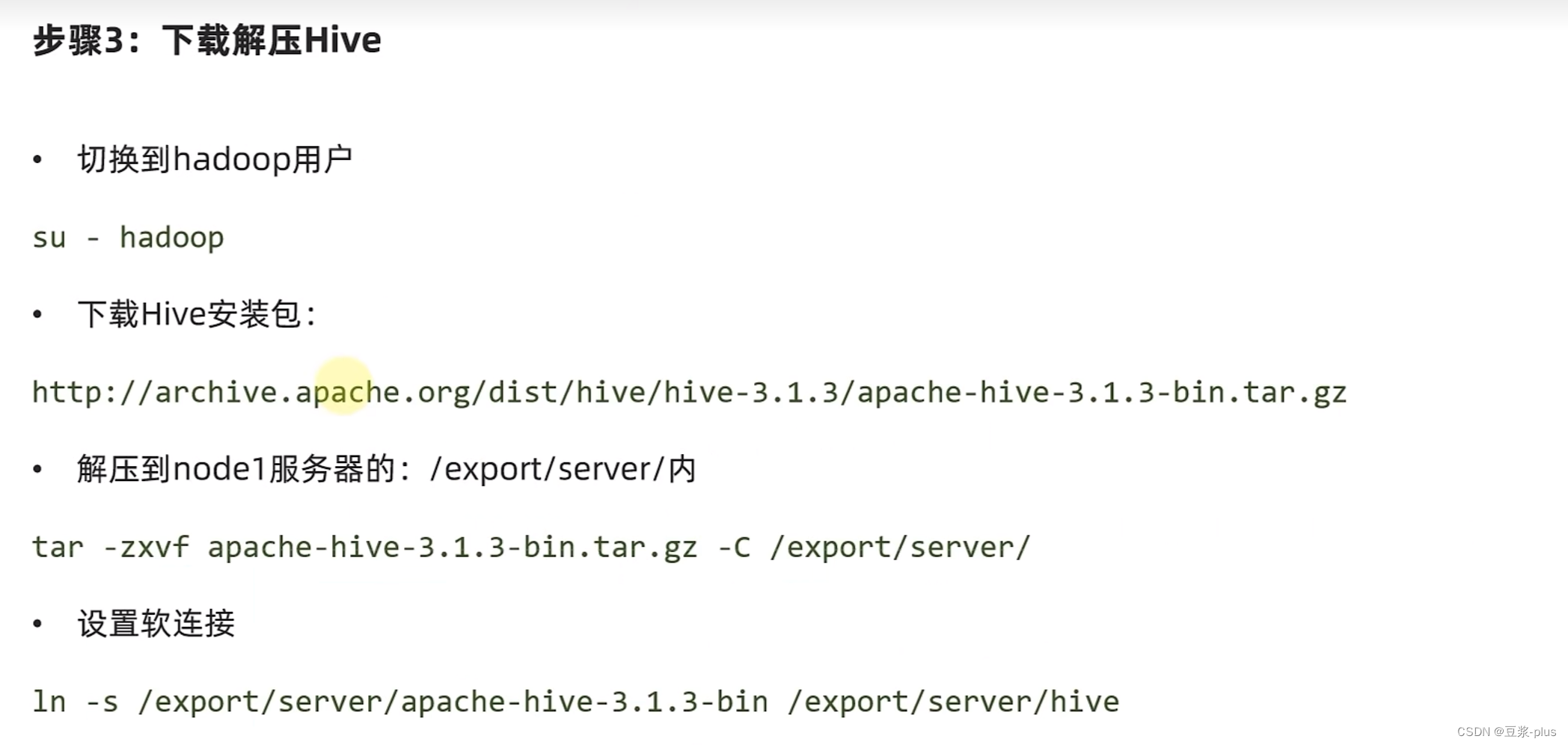
- 切换到hadoop用户
su - hadoop
- 下载Hive安装包:
http://archive.apache.org/dist/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz
- 解压到node1服务器的:/export/server/内
tar -zxvf apache-hive-3.1.3-bin.tar.gz -C /export/server/
- 设置软连接
ln -s /export/server/apache-hive-3.1.3-bin /export/server/hive

- 下载MySQL驱动包:
https://repo1.maven.org/maven2/mysql/mysql-connector-java/5.1.34/mysql-connector-java-5.1.34.jar
- 将下载好的驱动jar包,放入:Hive安装文件夹的lib目录内
mv mysql-connector-java-5.1.34.jar /export/server/hive/lib/


export HADOOP_HOME=/export/server/hadoop
export HIVE_CONF_DIR=/export/server/hive/conf
export HIVE_AUX_JARS_PATH=/export/server/hive/lib
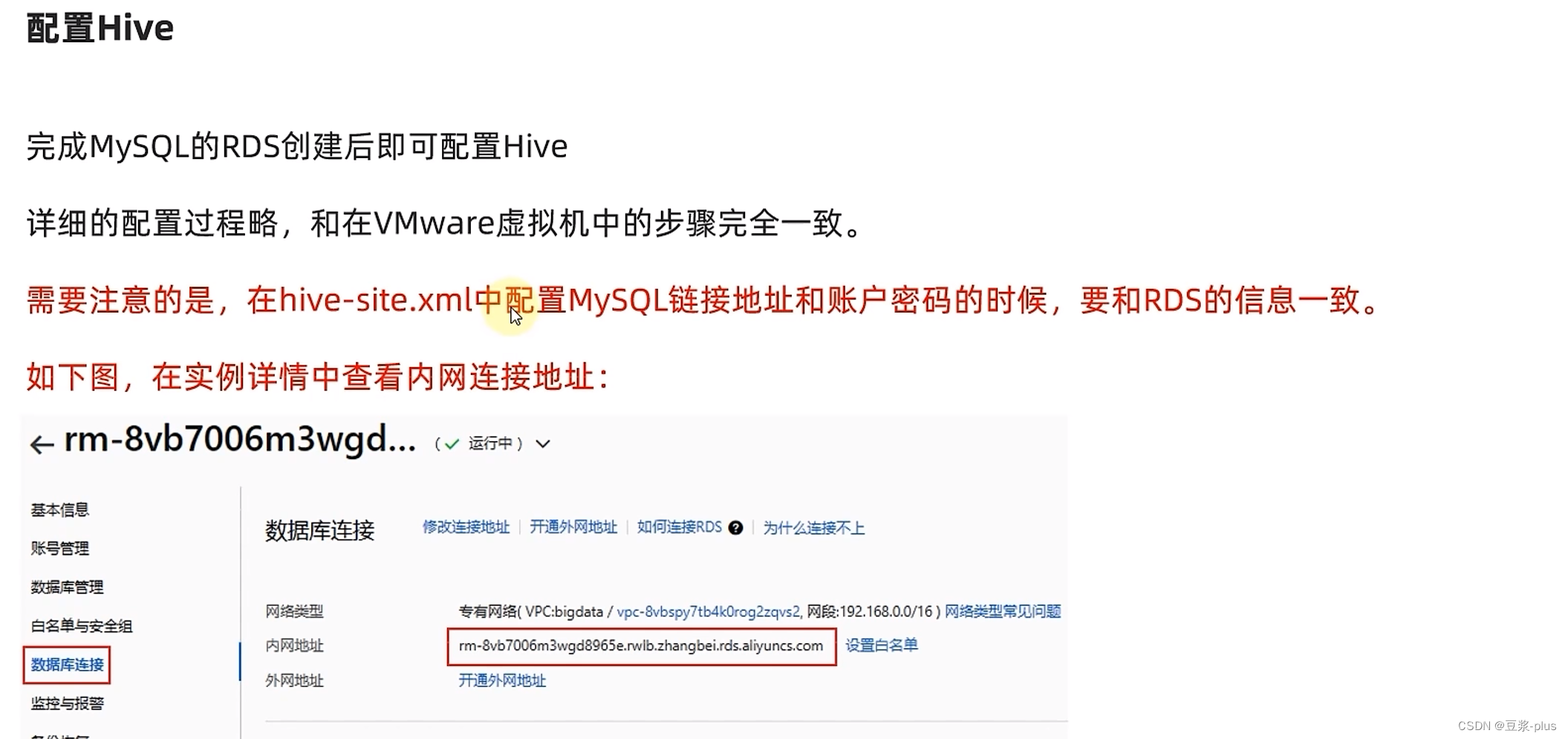
<configuration><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://node1:3306/hive?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8</value></property><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value></property><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value></property><property><name>javax.jdo.option.ConnectionPassword</name><value>root</value></property><property><name>hive.server2.thrift.bind.host</name><value>node1</value></property><property><name>hive.metastore.uris</name><value>thrift://node1:9083</value></property><property><name>hive.metastore.event.db.notification.api.auth</name><value>false</value></property>
</configuration>
支持,Hive的配置已经完成,现在在启动Hive前,需要先初始化Hive所需的元数据库。
- 在MySQL中新建数据库:hive
CREATE DATABASE hive CHARSET UTF8;
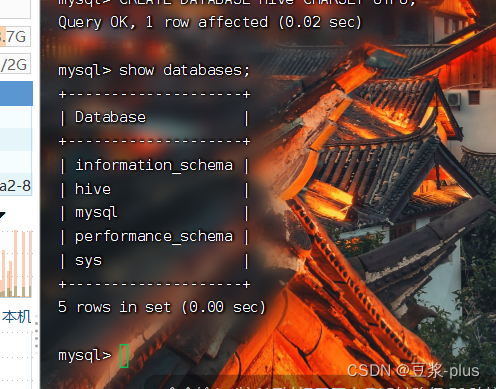
- 执行元数据库初始化命令:
cd /export/server/hive
bin/schematool -initSchema -dbType mysql -verbos
- # 初始化成功后,会在MySQL的hive库中新建74张元数据管理的表。
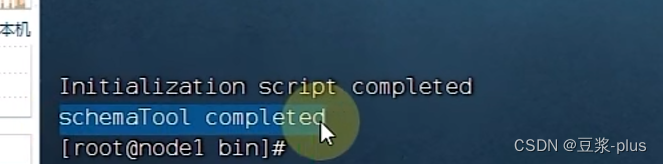

- 确保Hive文件夹所属为hadoop用户
chown -R hadoop:hadoop apache-hive-3.1.3-bin hive- 创建一个hive的日志文件夹:
mkdir /export/server/hive/logs
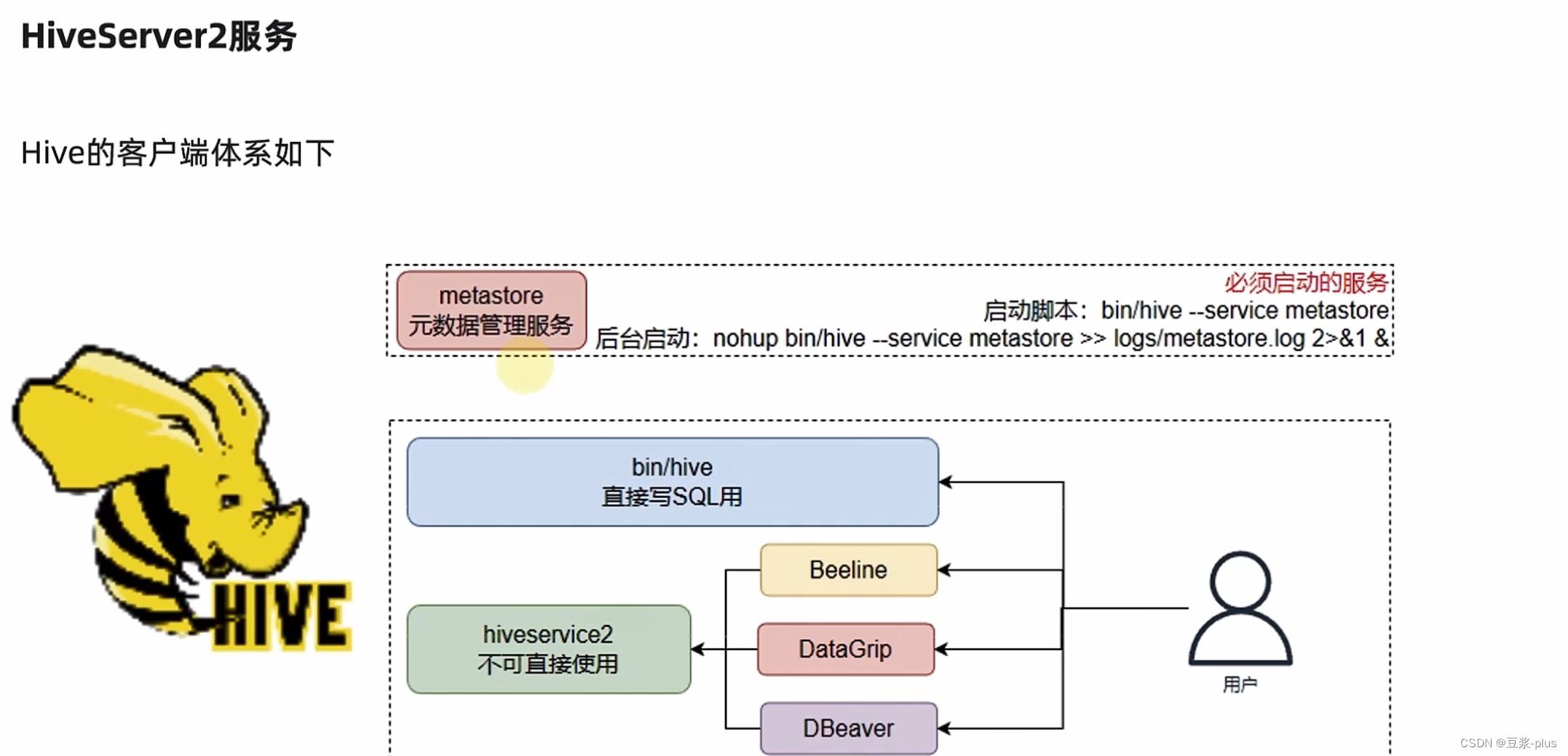
- 启动元数据管理服务(必须启动,否则无法工作)
前台启动:bin/hive --service metastore
后台启动:nohup bin/hive --service metastore >> logs/metastore.log 2>&1 &
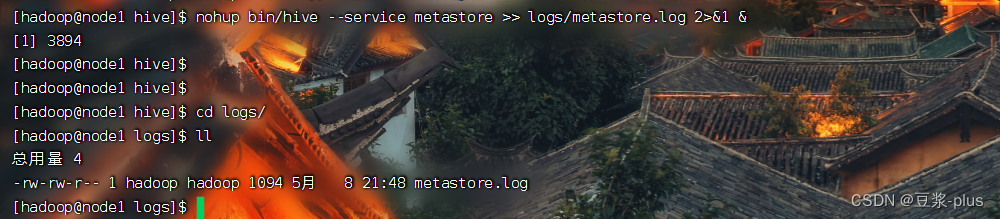
- 启动客户端,二选一(当前先选择Hive Shell方式)
Hive Shell方式(可以直接写SQL): bin/hive
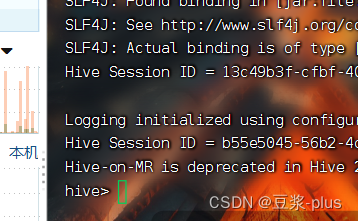
Hive ThriftServer方式(不可直接写SQL,需要外部客户端链接使用): bin/hive --service hiveserver2

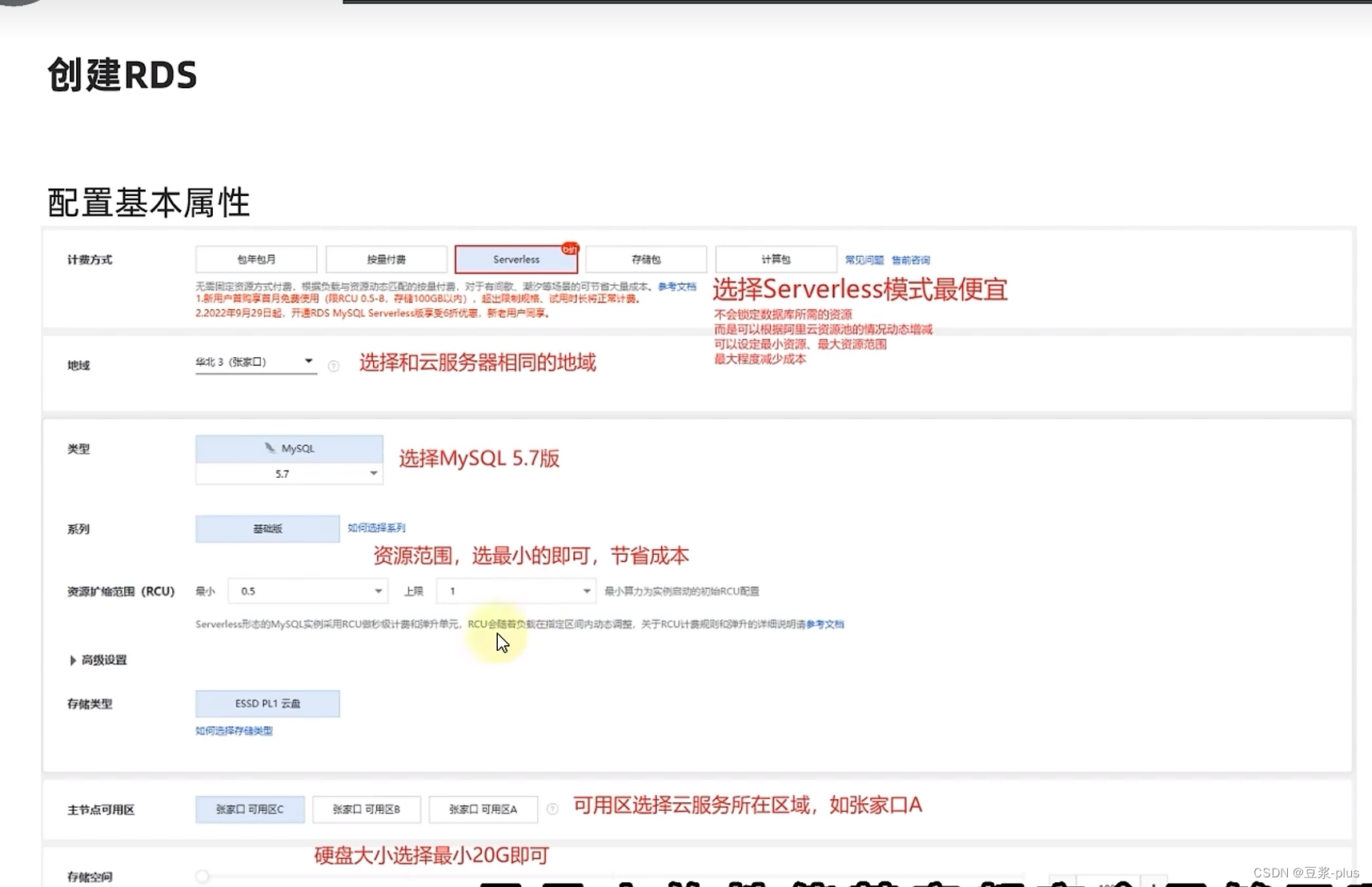
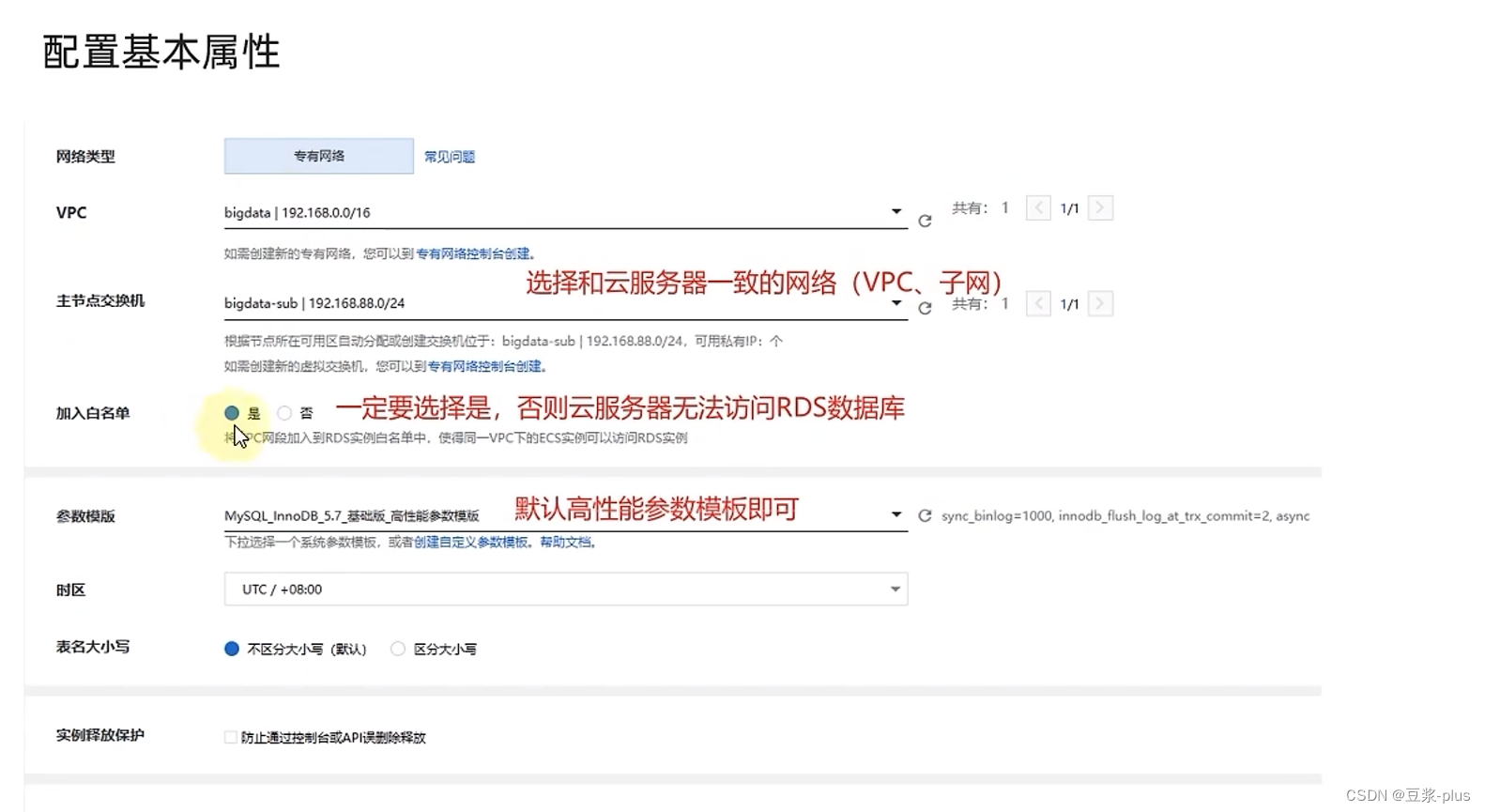
阿里云部署:


3.Hive初体验




4.Hive 客户端


#先启动metastore服务 然后启动hiveserver2服务
nohup bin/hive --service metastore >> logs/metastore.log 2>&1 &
nohup bin/hive --service hiveserver2 >> logs/hiveserver2.log 2>&1 &
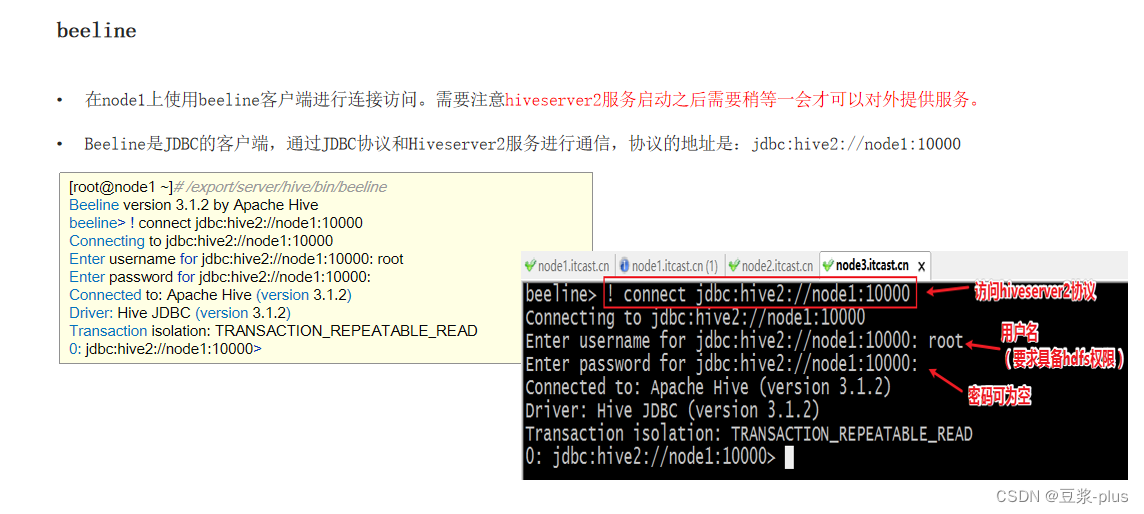
netstat -anp | grep 10000


5.Hive 原理

![]()





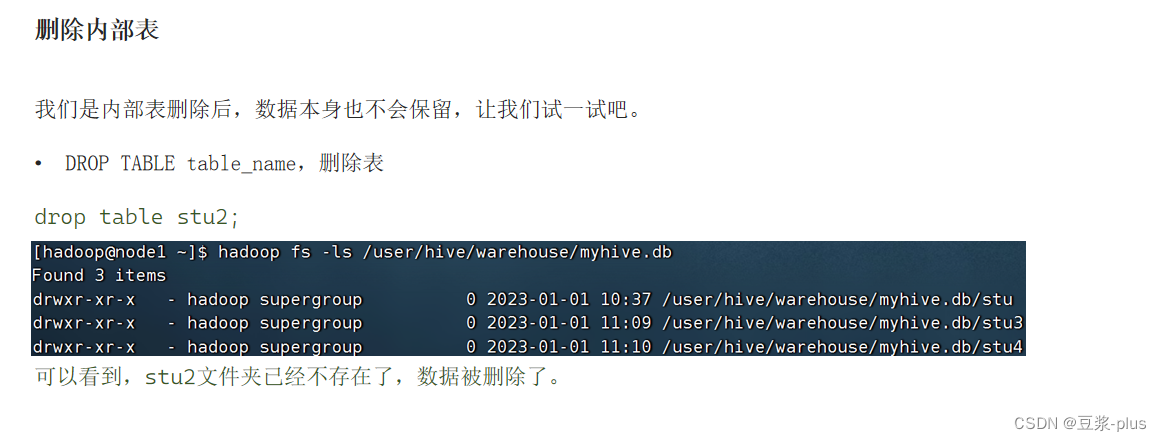
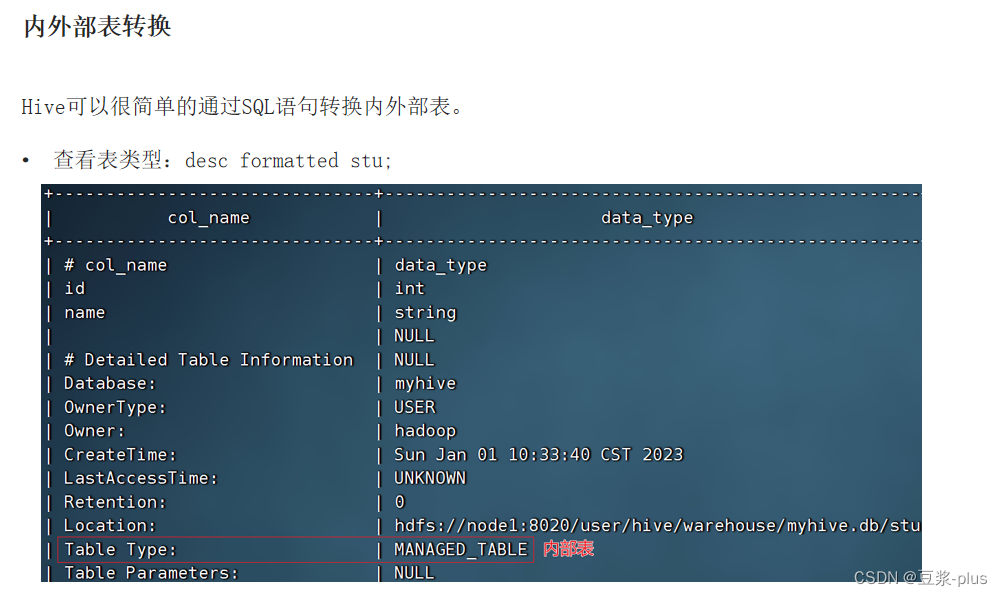
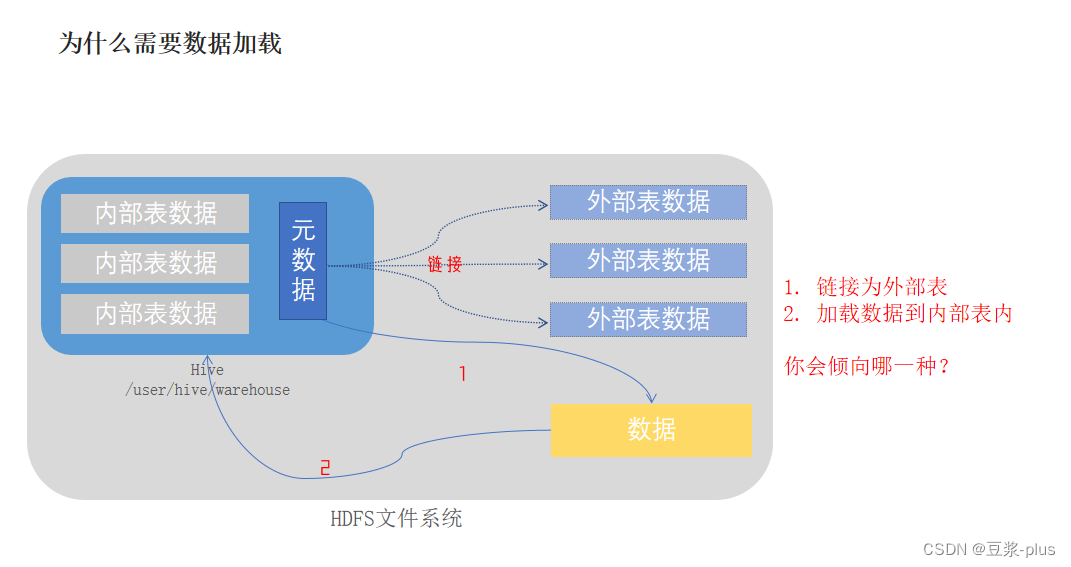
内部标,外部表:







row format delimited fields terminated by '\t':表示以\t分隔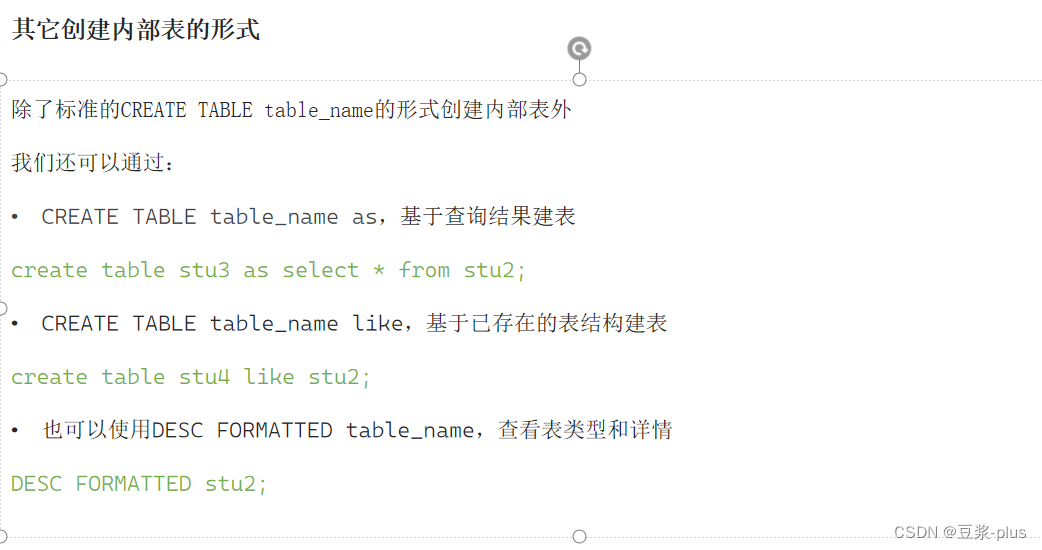






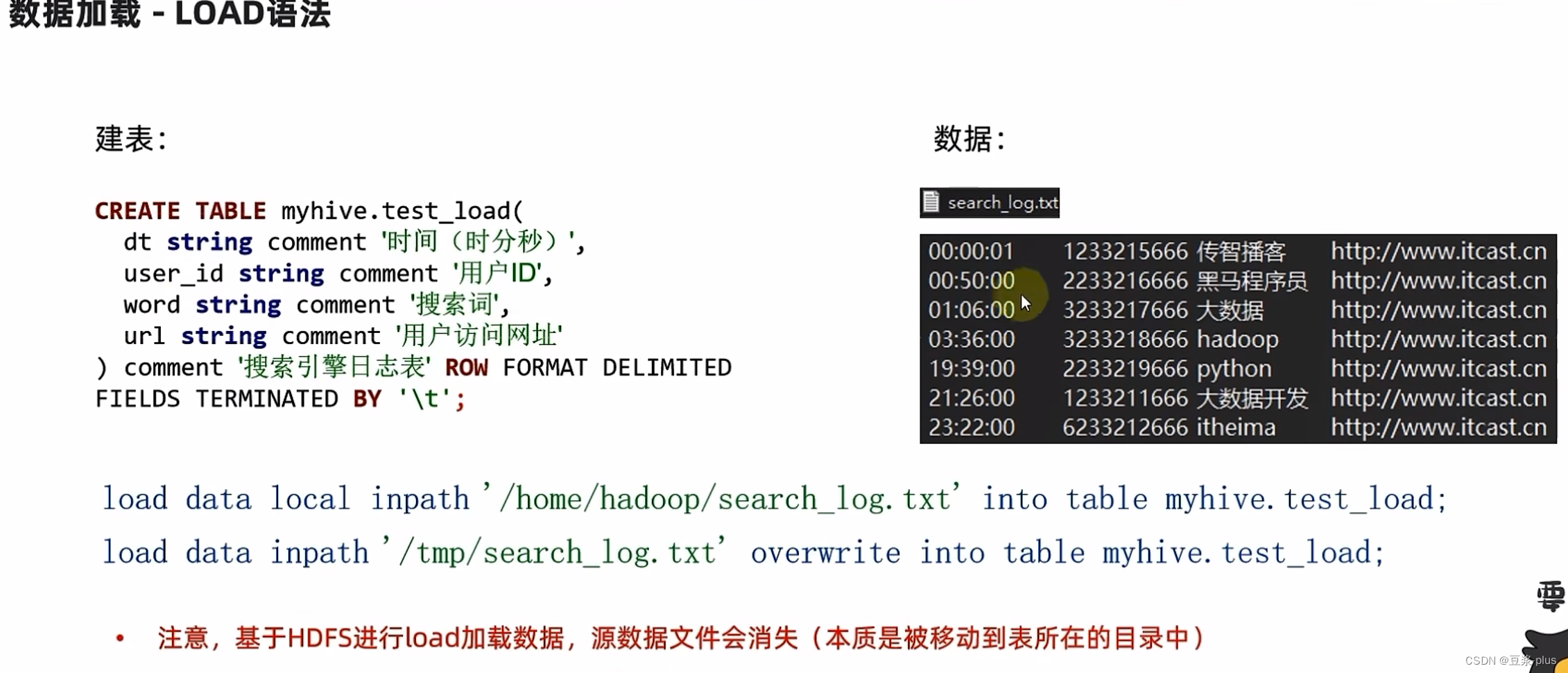
数据加载:

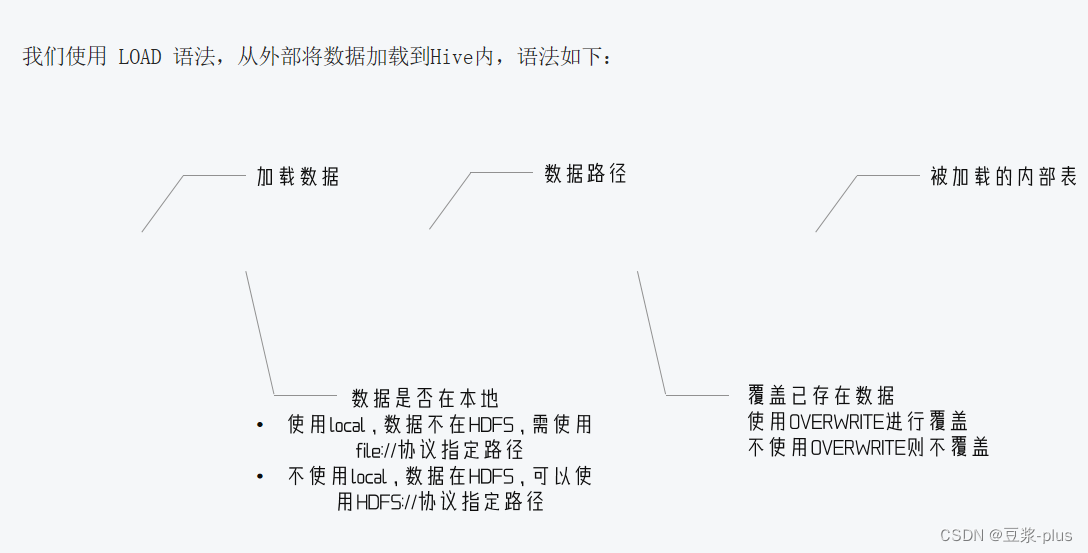






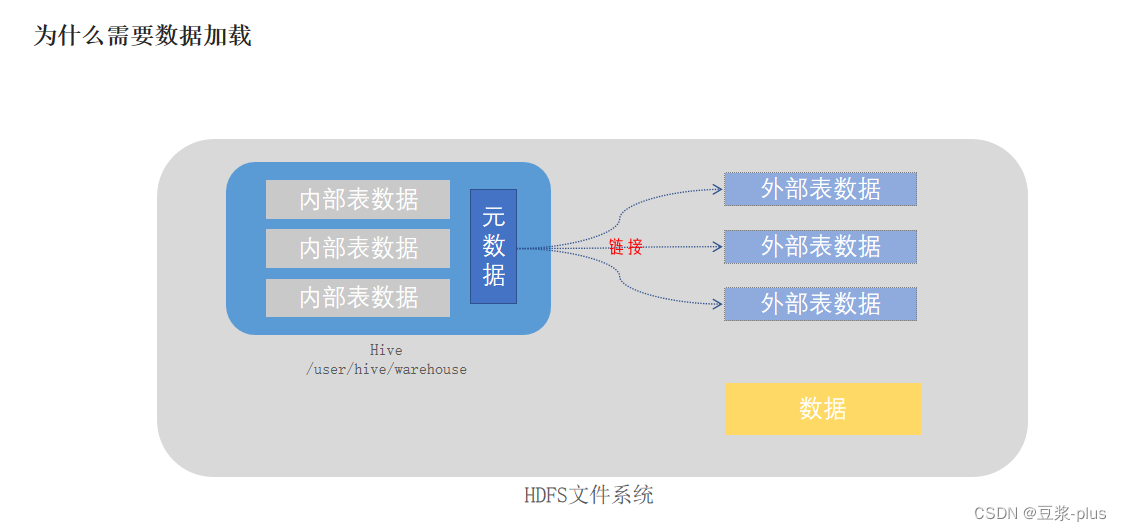
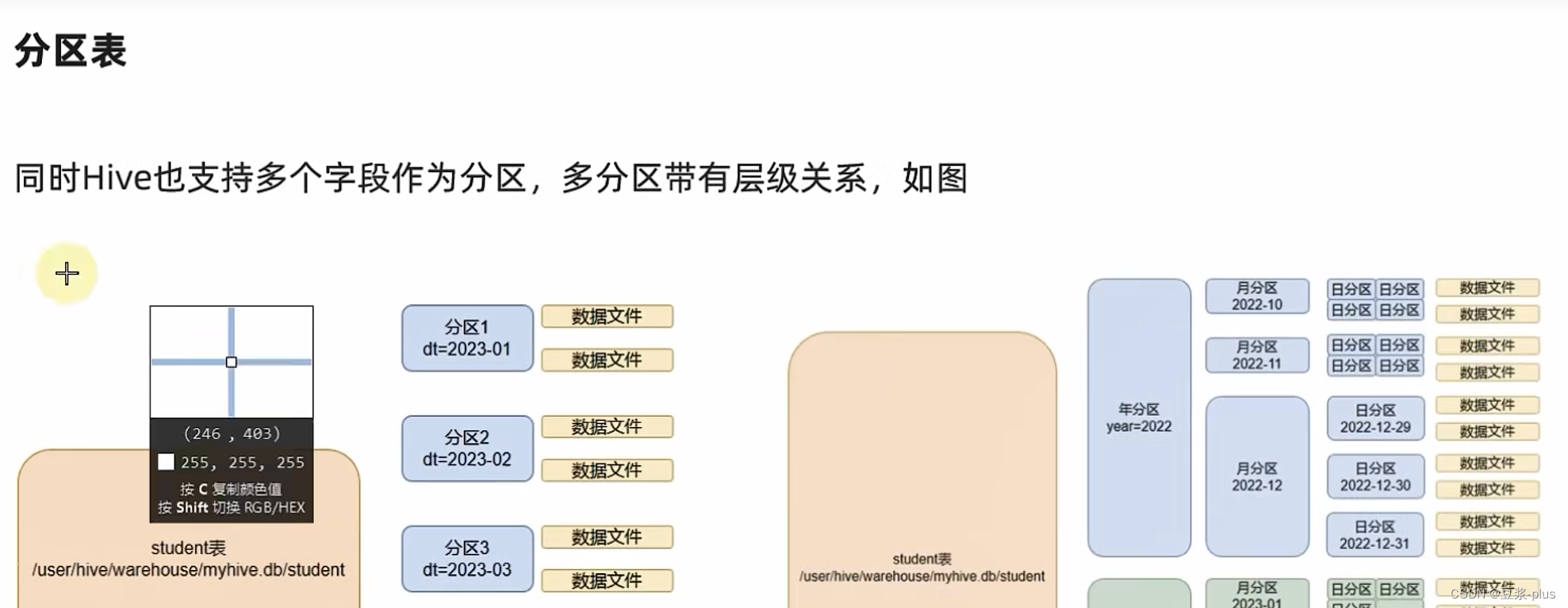
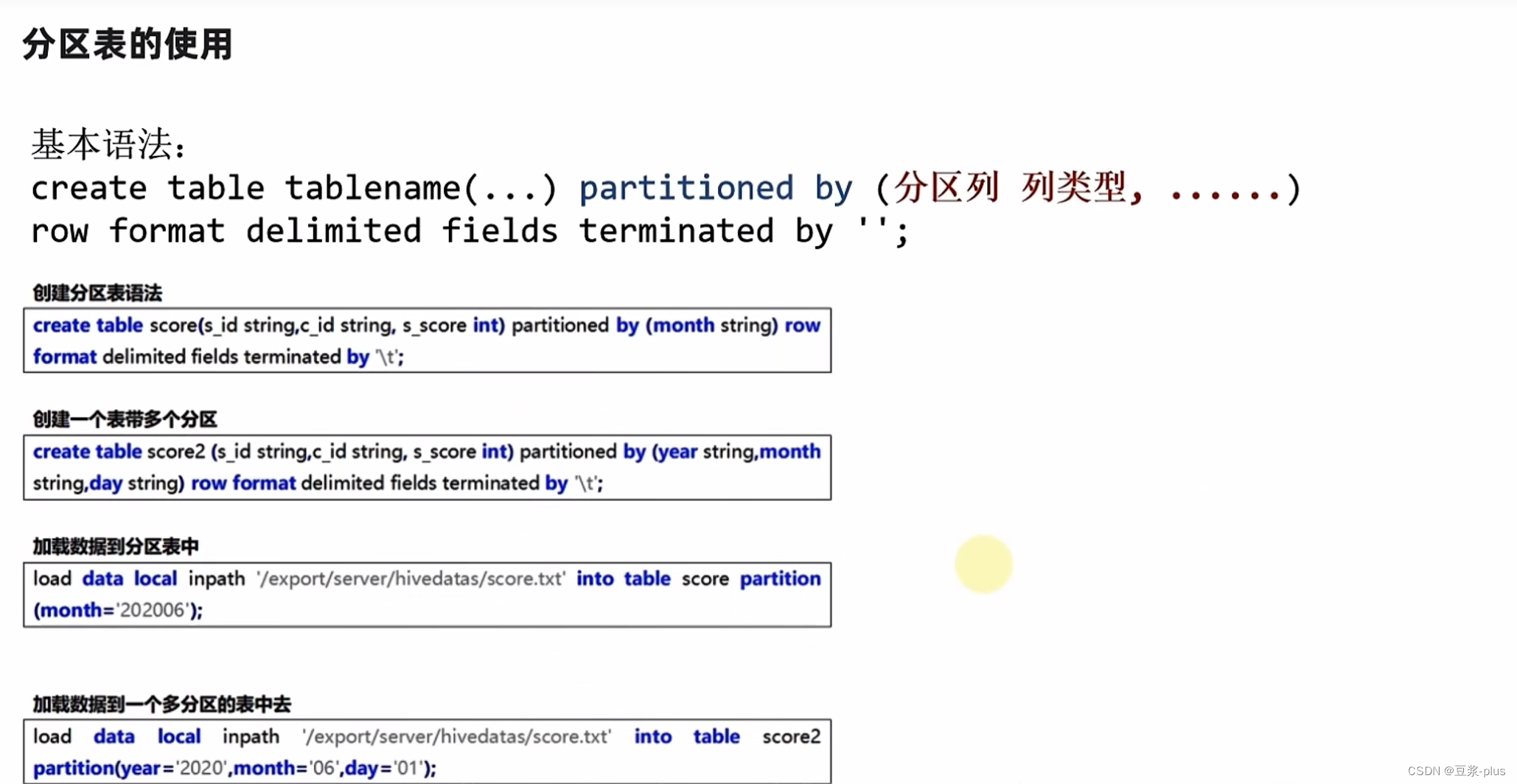
分区表:



分桶表:
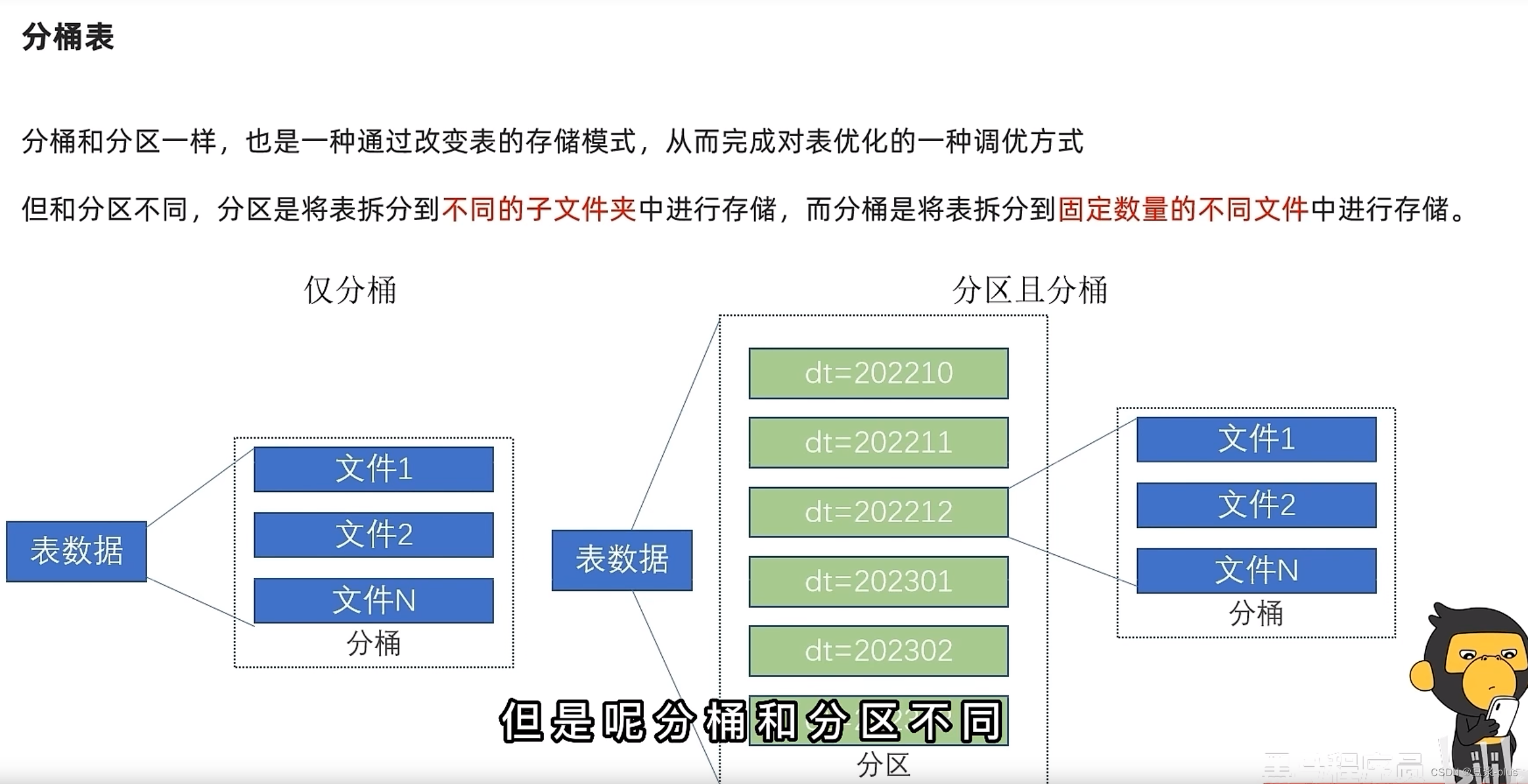
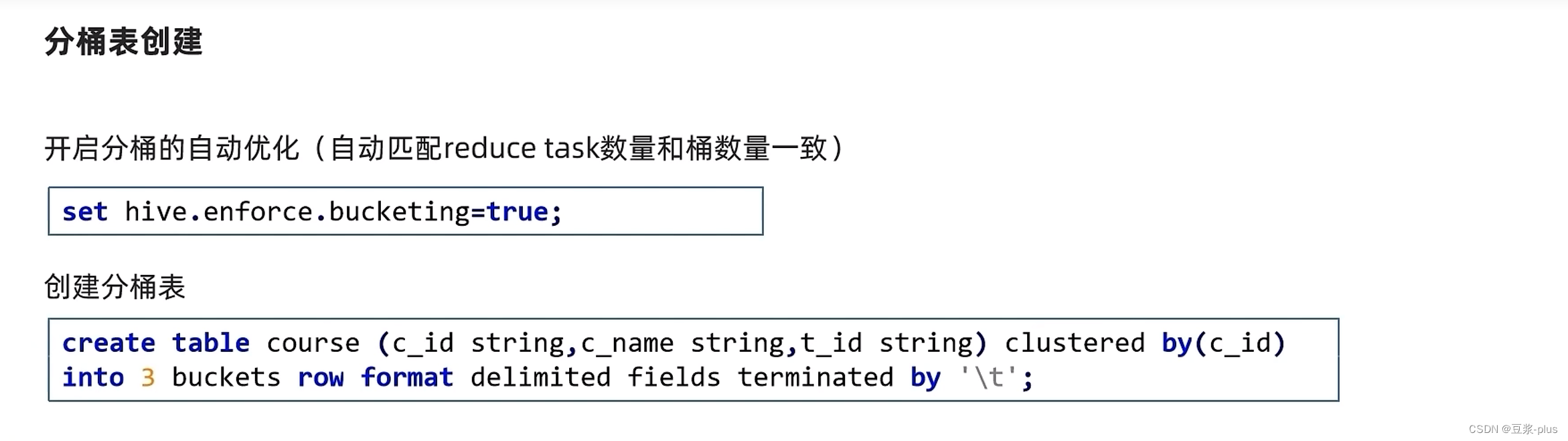
set hive.enforce.bucketing=true;create table course (c_id string,c_name string,t_id string) clustered by(c_id) into 3 buckets row format delimited fields terminated by '\t'; 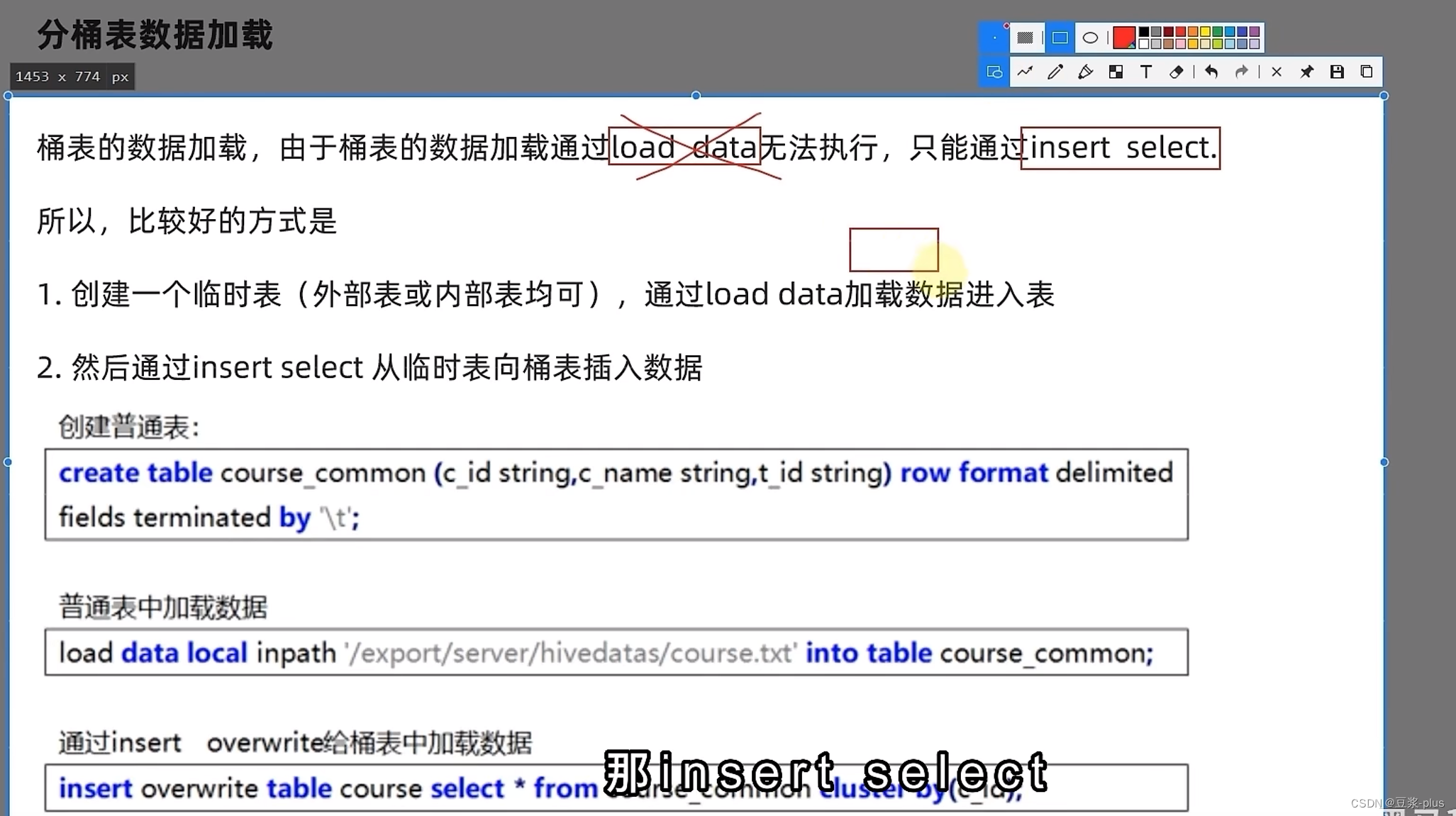
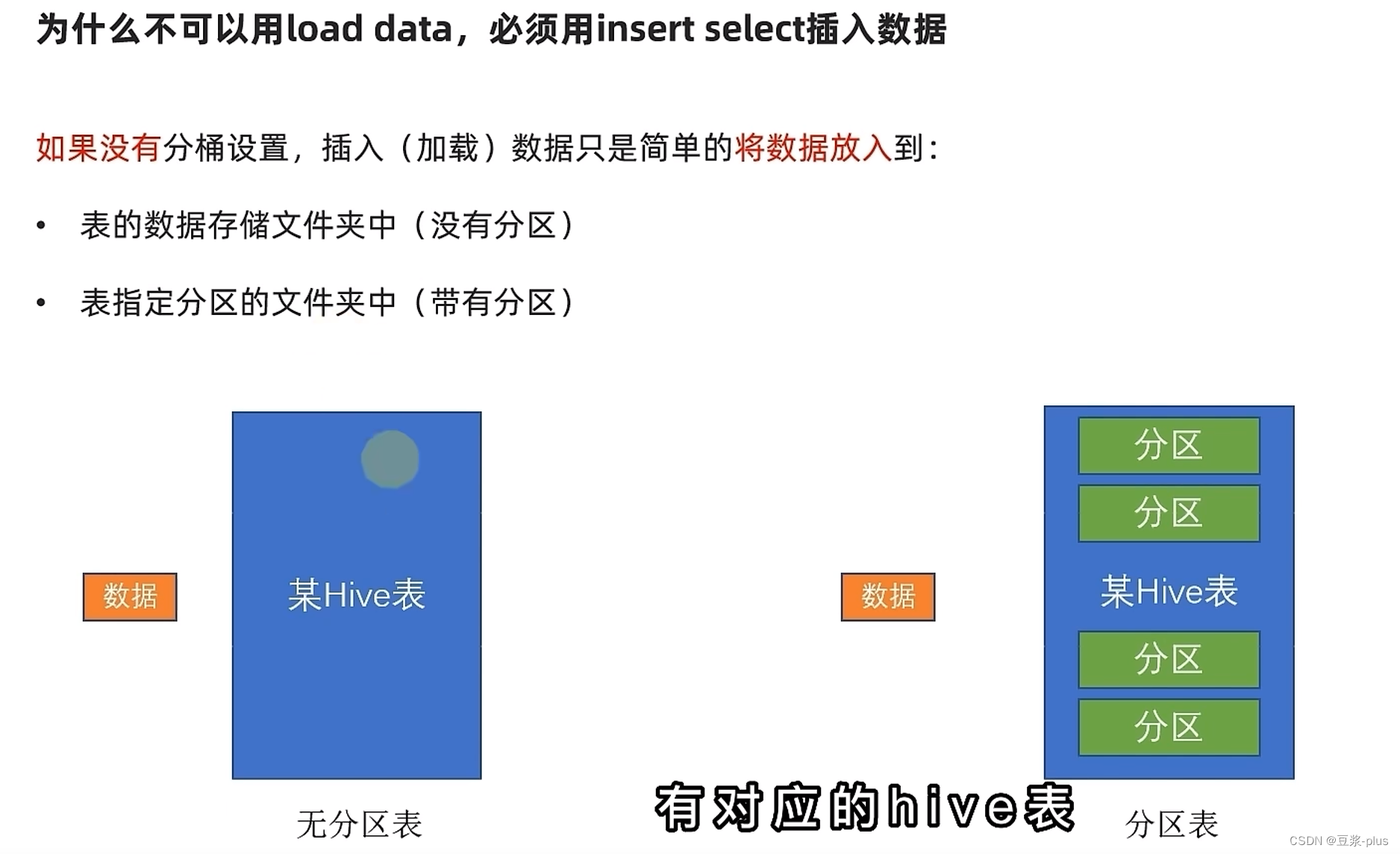
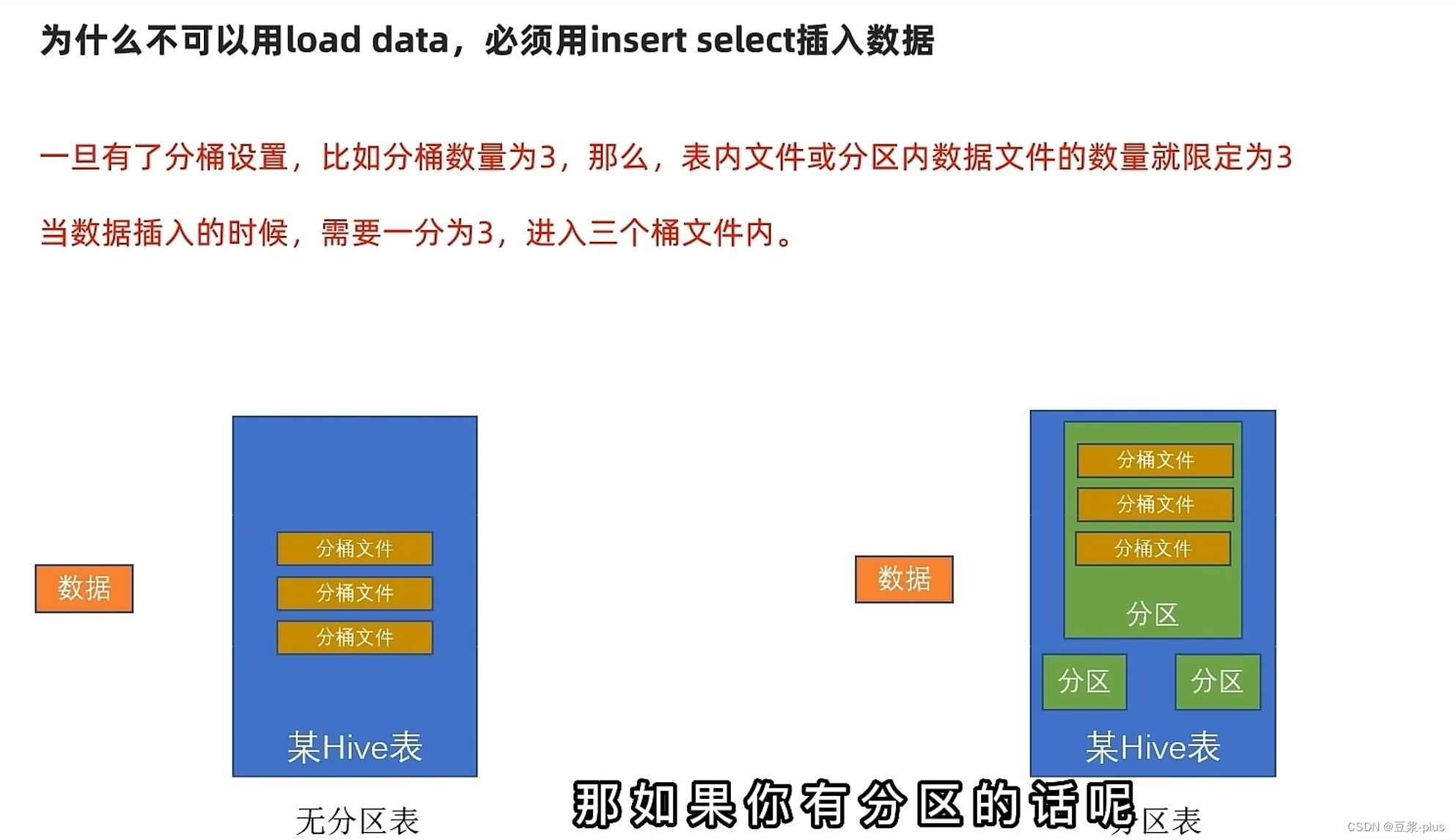


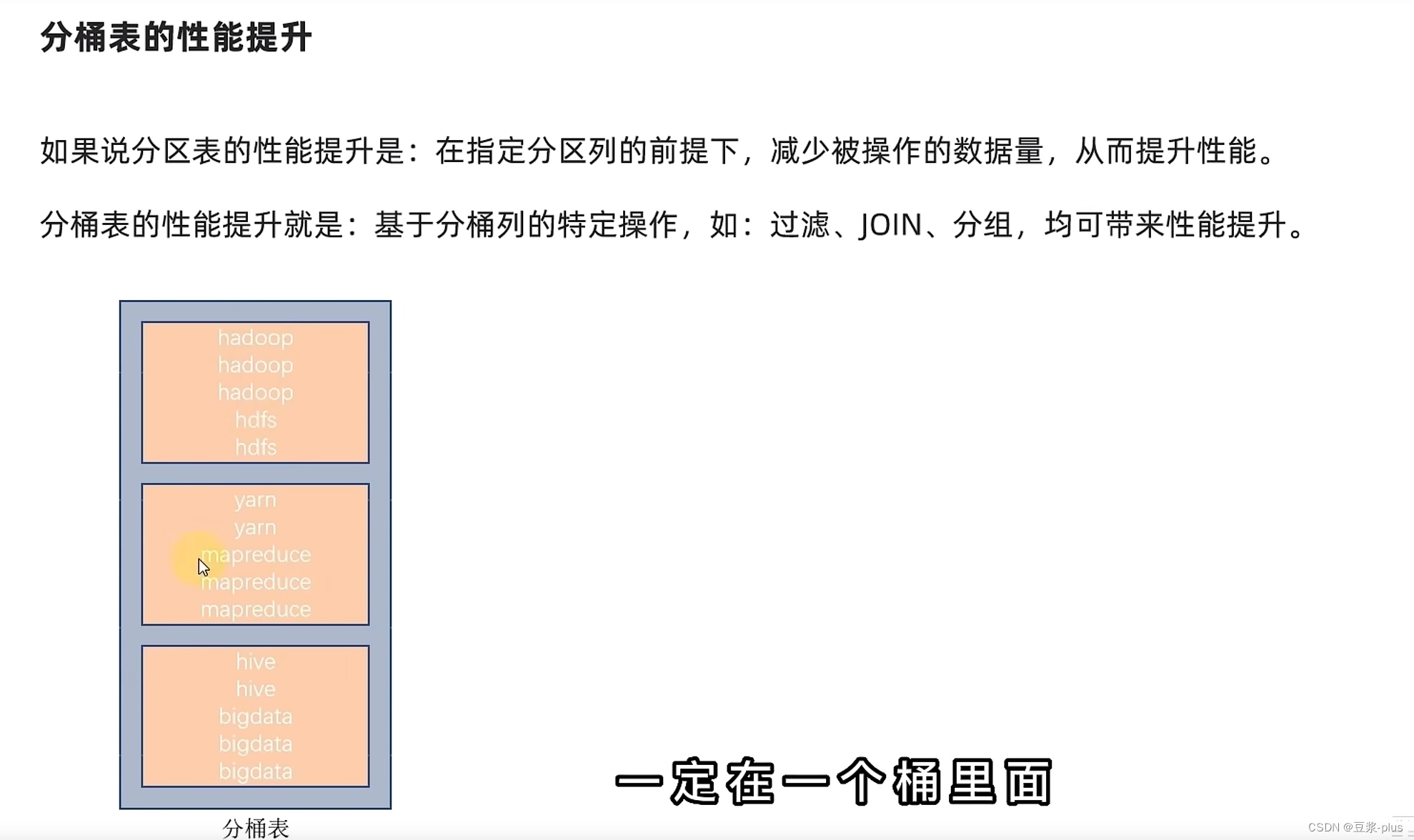
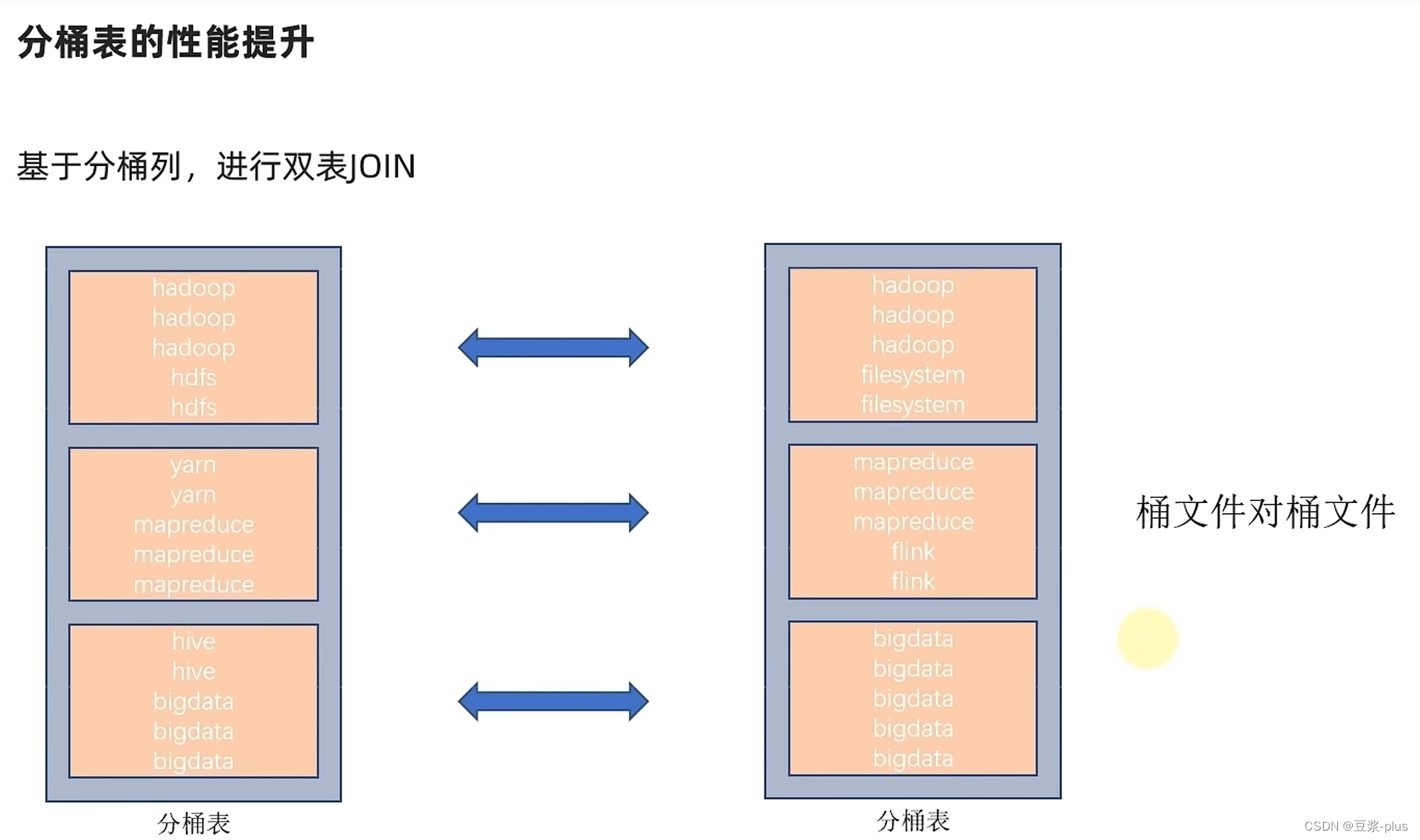


修改表:


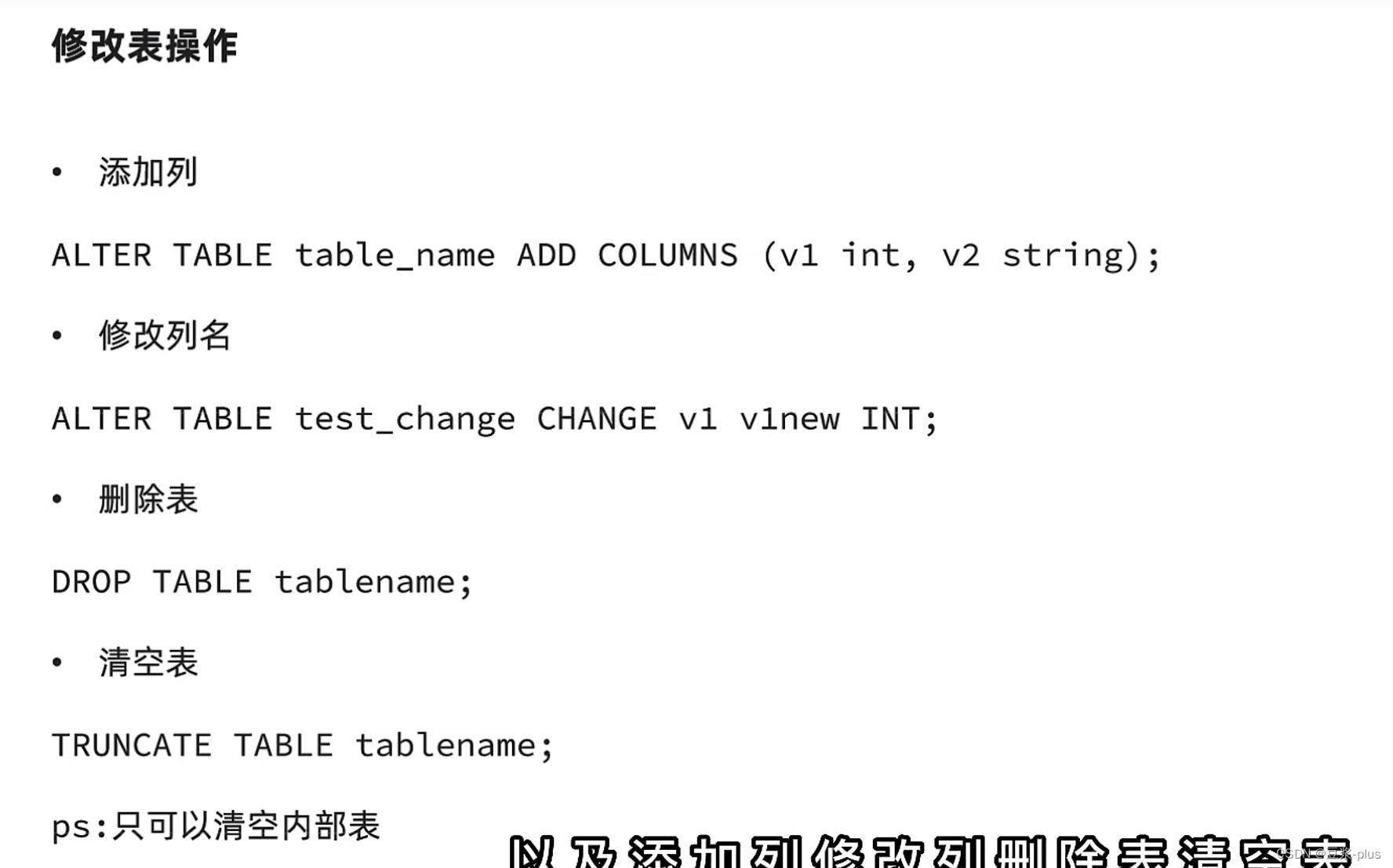
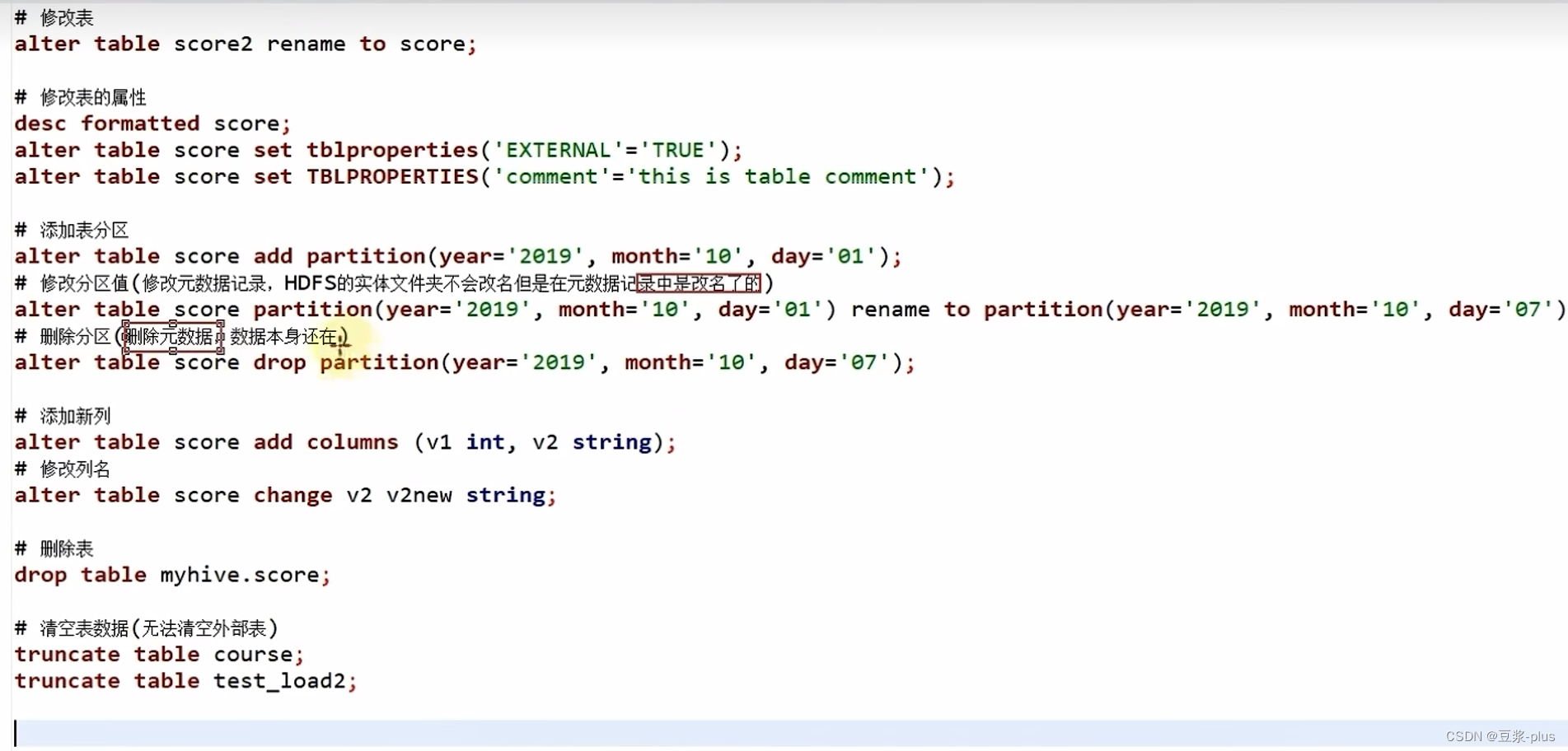
Array复杂类型:
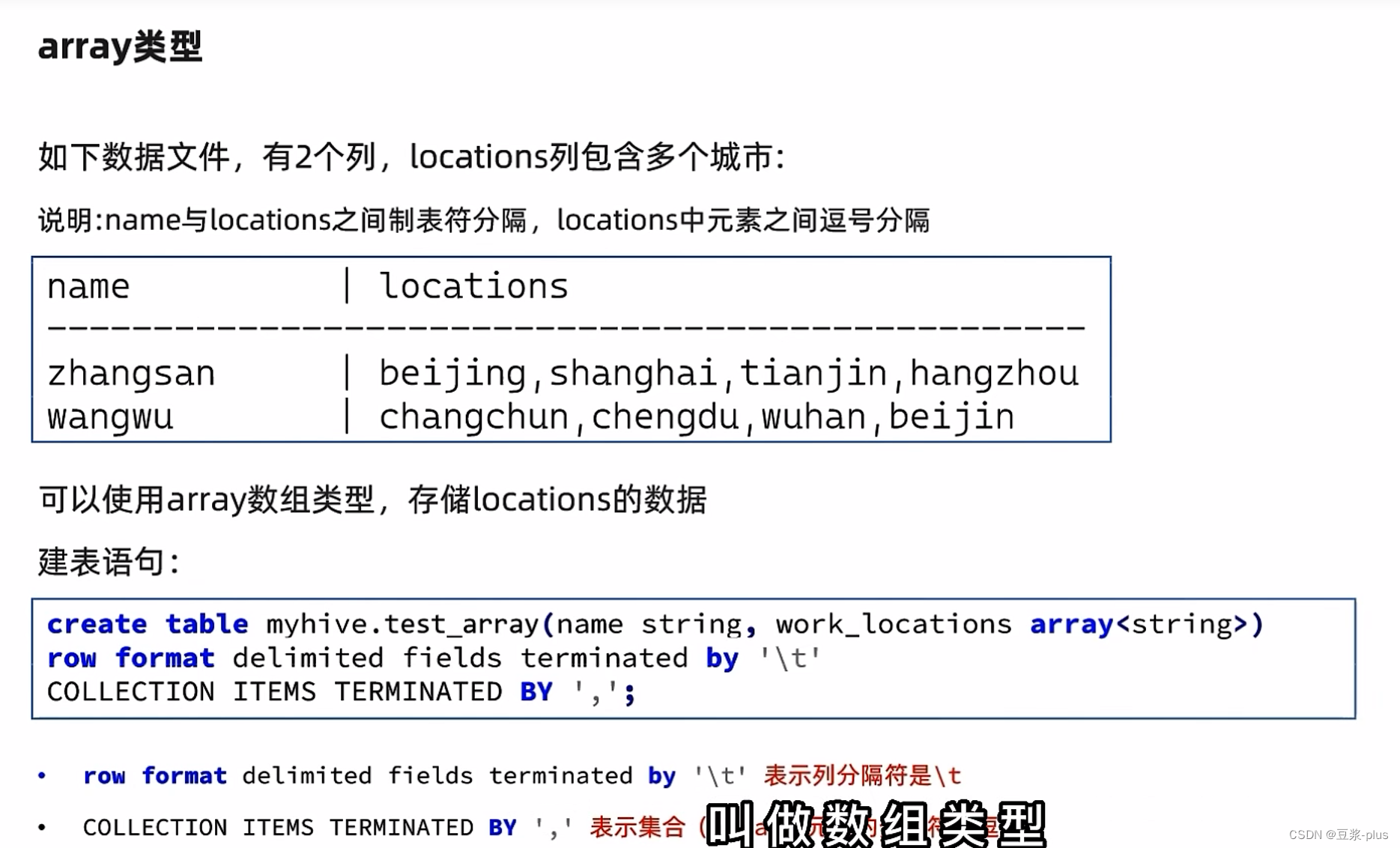

create table myhive.test_array(name string, work_locations array<string>)
row format delimited fields terminated by '\t'
COLLECTION ITEMS TERMINATED BY ',';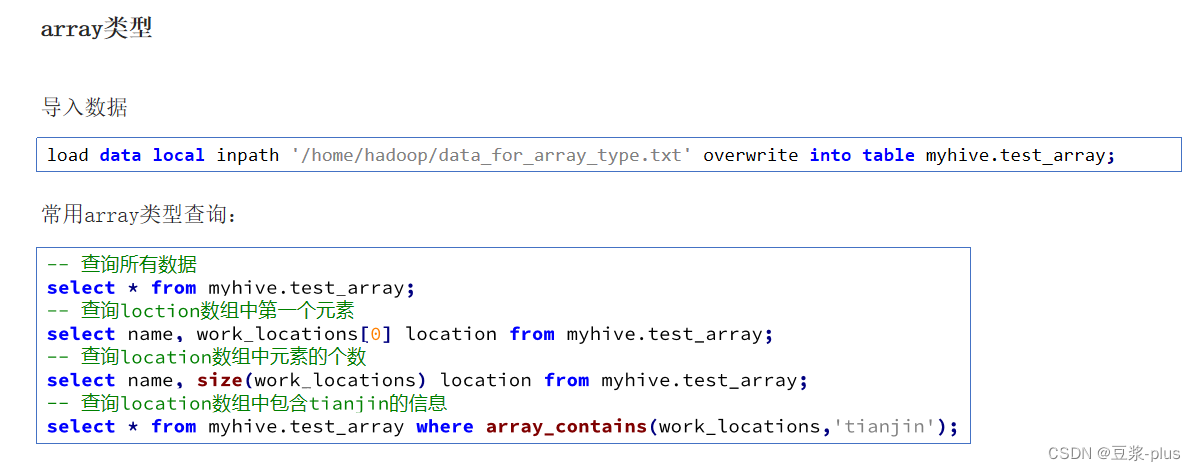
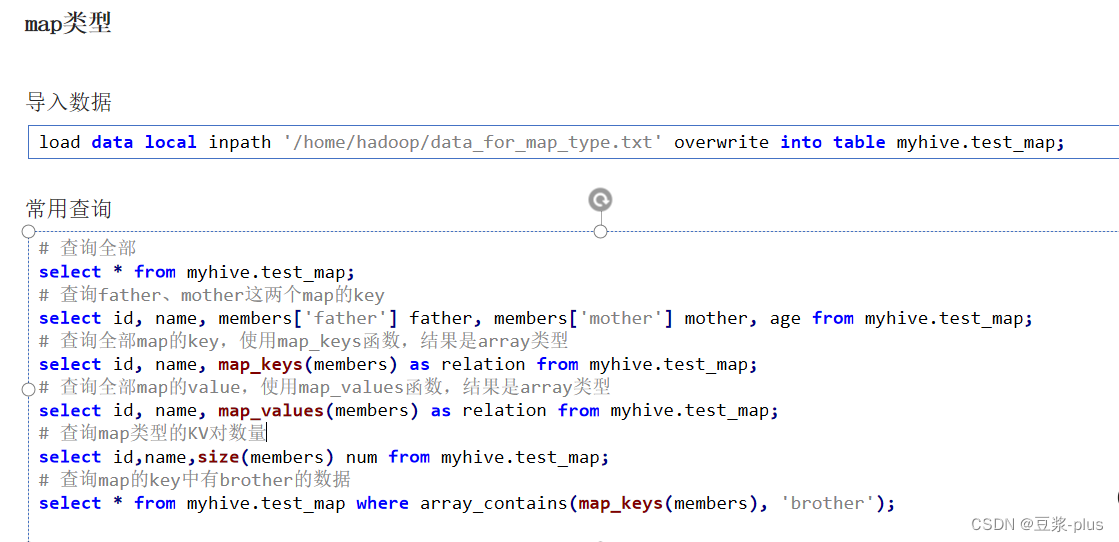
Map复杂类型:
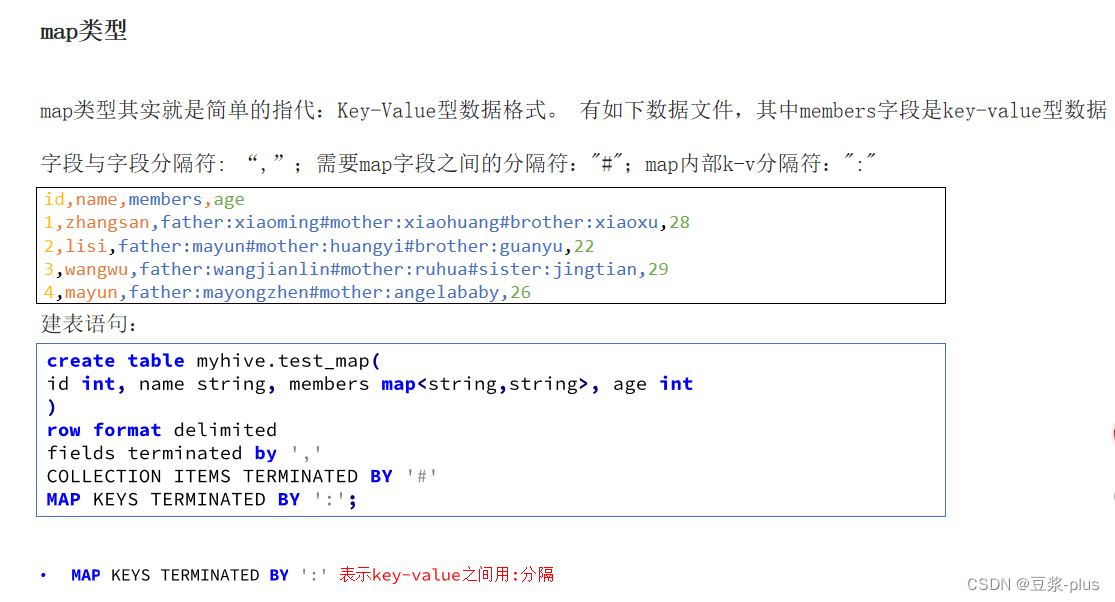

create table myhive.test_map(
id int, name string, members map<string,string>, age int
)
row format delimited
fields terminated by ','
COLLECTION ITEMS TERMINATED BY '#'
MAP KEYS TERMINATED BY ':';

Struct复杂类型:
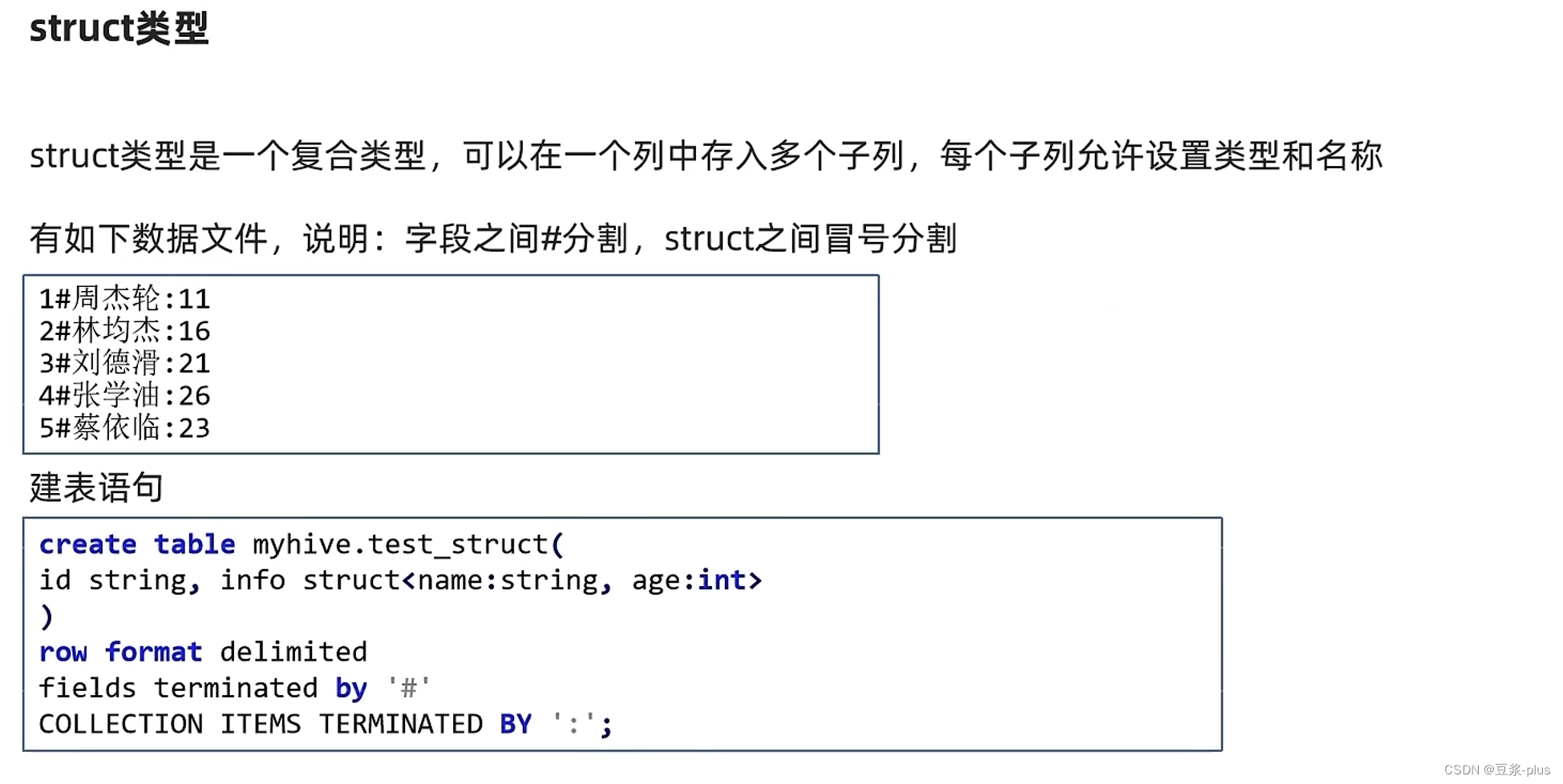
create table myhive.test_struct(
id string, info struct<name:string, age:int>
)
row format delimited
fields terminated by '#'
COLLECTION ITEMS TERMINATED BY ':';
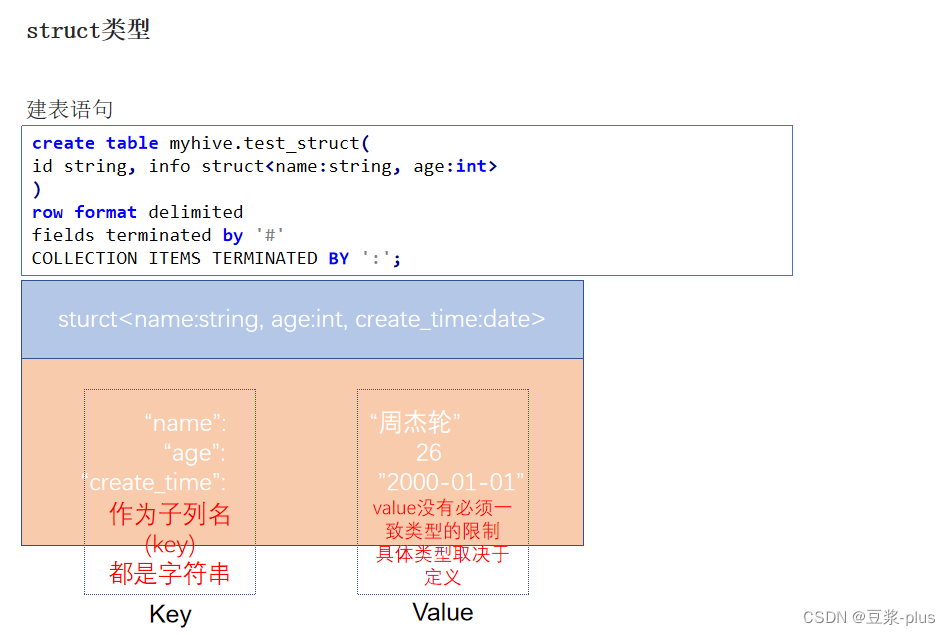
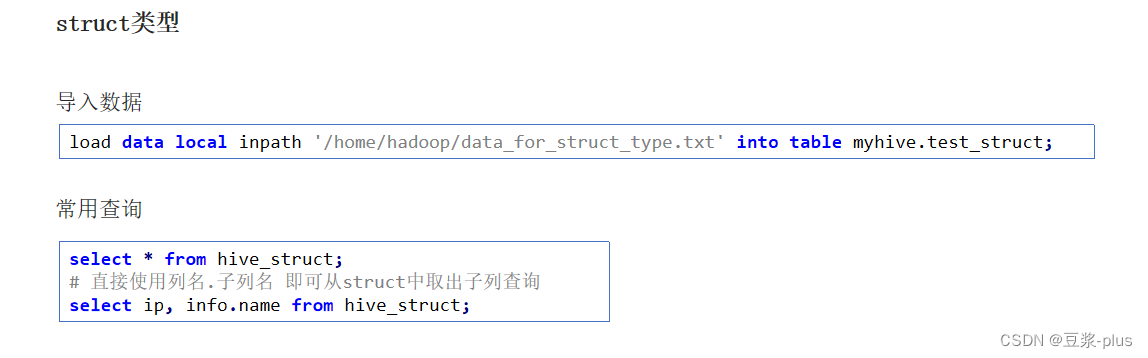

数据查询:
掌握SELECT、聚合、GROUP BY、JOIN、ORDER BY等基础SQL查询:
准备数据:订单表
CREATE DATABASE itheima;
USE itheima;
CREATE TABLE itheima.orders (orderId bigint COMMENT '订单id',orderNo string COMMENT '订单编号',shopId bigint COMMENT '门店id',userId bigint COMMENT '用户id',orderStatus tinyint COMMENT '订单状态 -3:用户拒收 -2:未付款的订单 -1:用户取消 0:待发货 1:配送中 2:用户确认收货',goodsMoney double COMMENT '商品金额',deliverMoney double COMMENT '运费',totalMoney double COMMENT '订单金额(包括运费)',realTotalMoney double COMMENT '实际订单金额(折扣后金额)',payType tinyint COMMENT '支付方式,0:未知;1:支付宝,2:微信;3、现金;4、其他',isPay tinyint COMMENT '是否支付 0:未支付 1:已支付',userName string COMMENT '收件人姓名',userAddress string COMMENT '收件人地址',userPhone string COMMENT '收件人电话',createTime timestamp COMMENT '下单时间',payTime timestamp COMMENT '支付时间',totalPayFee int COMMENT '总支付金额'
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
LOAD DATA LOCAL INPATH '/home/hadoop/itheima_orders.txt' INTO TABLE itheima.orders;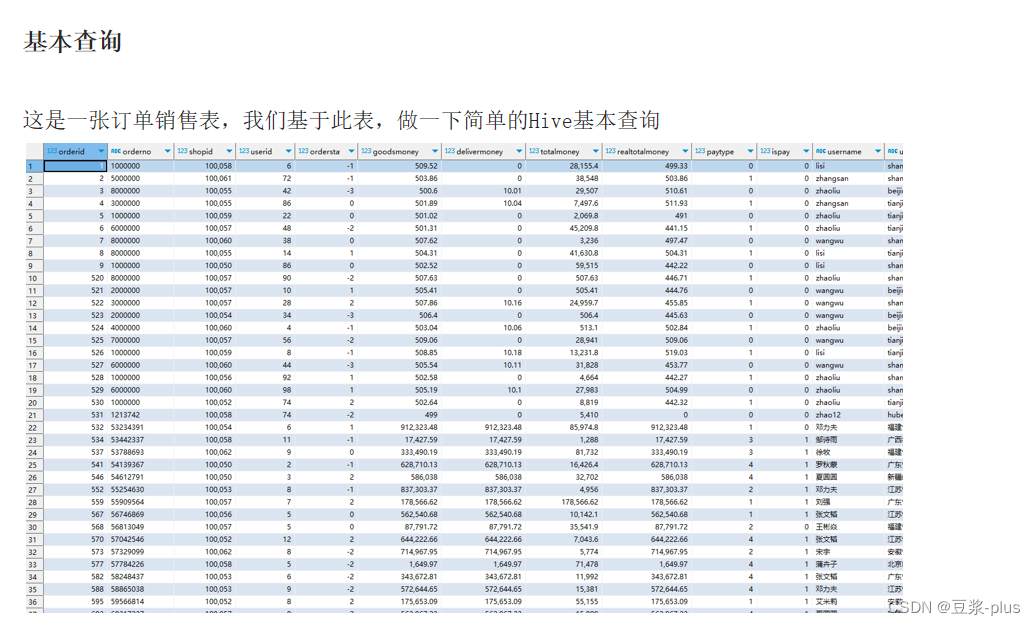 准备数据:用户表
准备数据:用户表
CREATE TABLE itheima.users (userId int,loginName string,loginSecret int,loginPwd string,userSex tinyint,userName string,trueName string,brithday date,userPhoto string,userQQ string,userPhone string,userScore int,userTotalScore int,userFrom tinyint,userMoney double,lockMoney double,createTime timestamp,payPwd string,rechargeMoney double
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';LOAD DATA LOCAL INPATH '/home/hadoop/itheima_users.txt' INTO TABLE itheima.users;
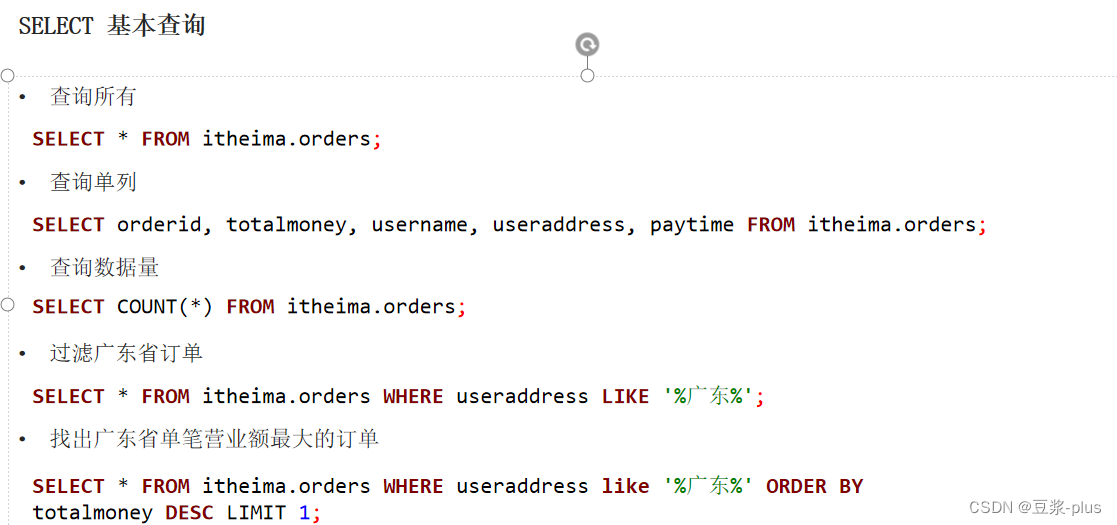
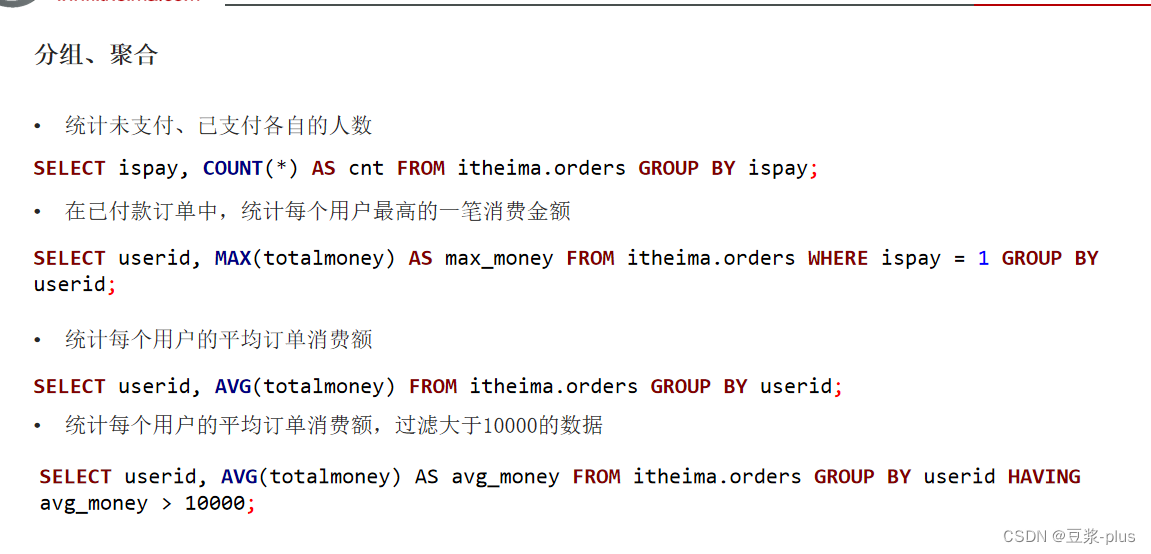
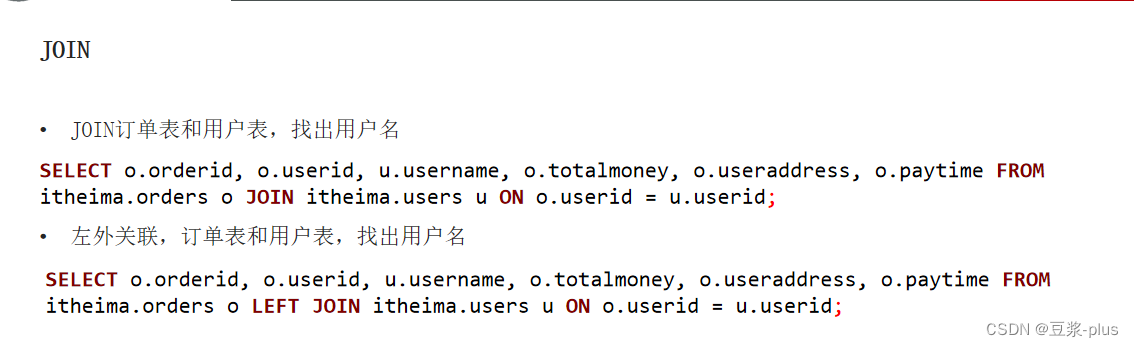

rlike关键字进行正则匹配:



UNION关键字进行查询结果的联合:






表数据进行采样操作:



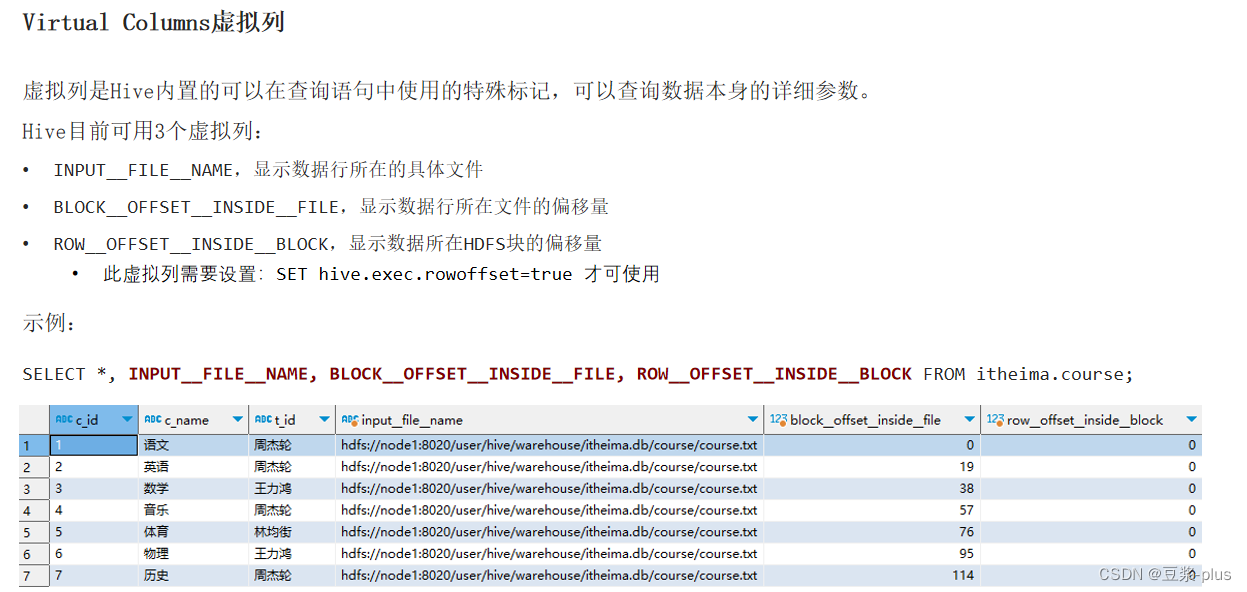
虚拟列的使用方式:
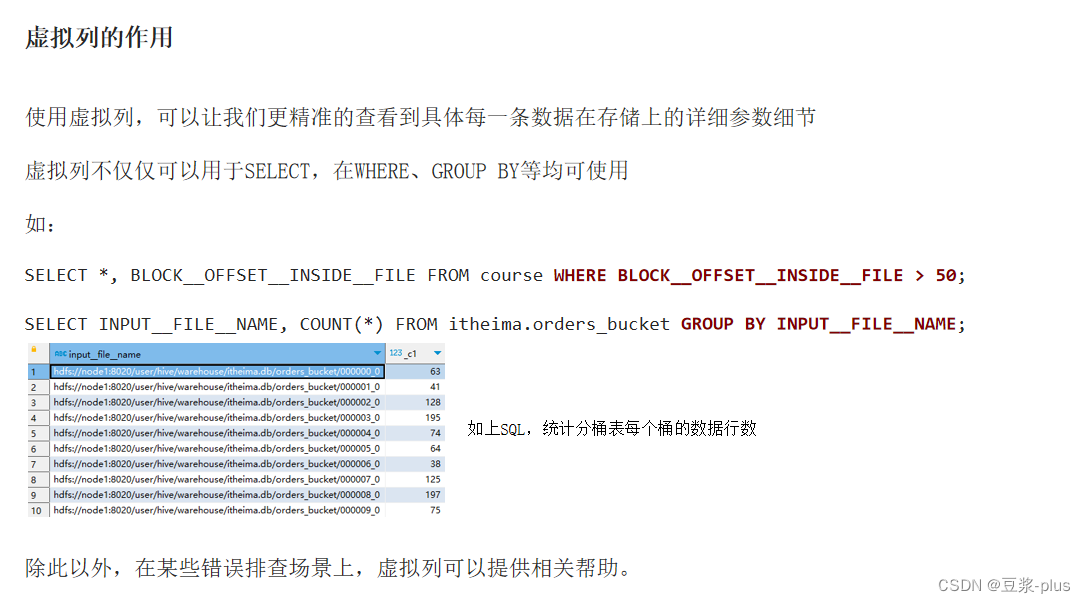

函数:



使用show functions查看当下可用的所有函数;
通过describe function extended funcname来查看函数的使用方式。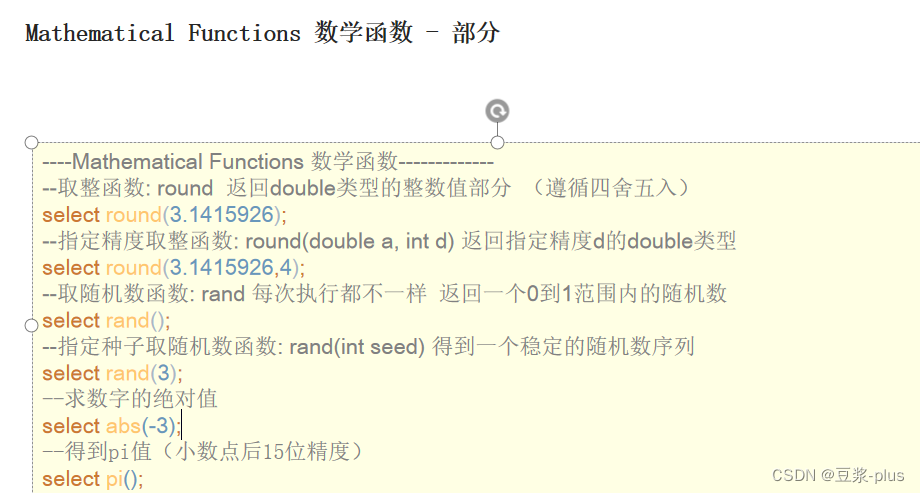
----Mathematical Functions 数学函数-------
------ --取整函数: round 返回double类型的整数值部分 (遵循四舍五入)
select round(3.1415926);
--指定精度取整函数: round(double a, int d) 返回指定精度d的double类型
select round(3.1415926,4);
--取随机数函数: rand 每次执行都不一样 返回一个0到1范围内的随机数
select rand();
--指定种子取随机数函数: rand(int seed) 得到一个稳定的随机数序列
select rand(3);
--求数字的绝对值
select abs(-3);
--得到pi值(小数点后15位精度)
select pi();

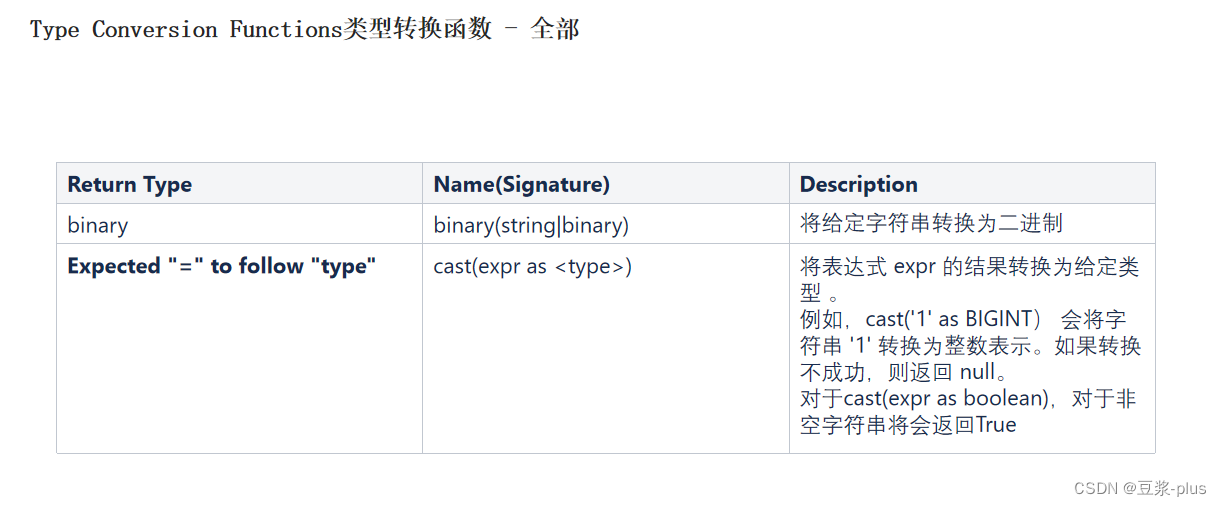
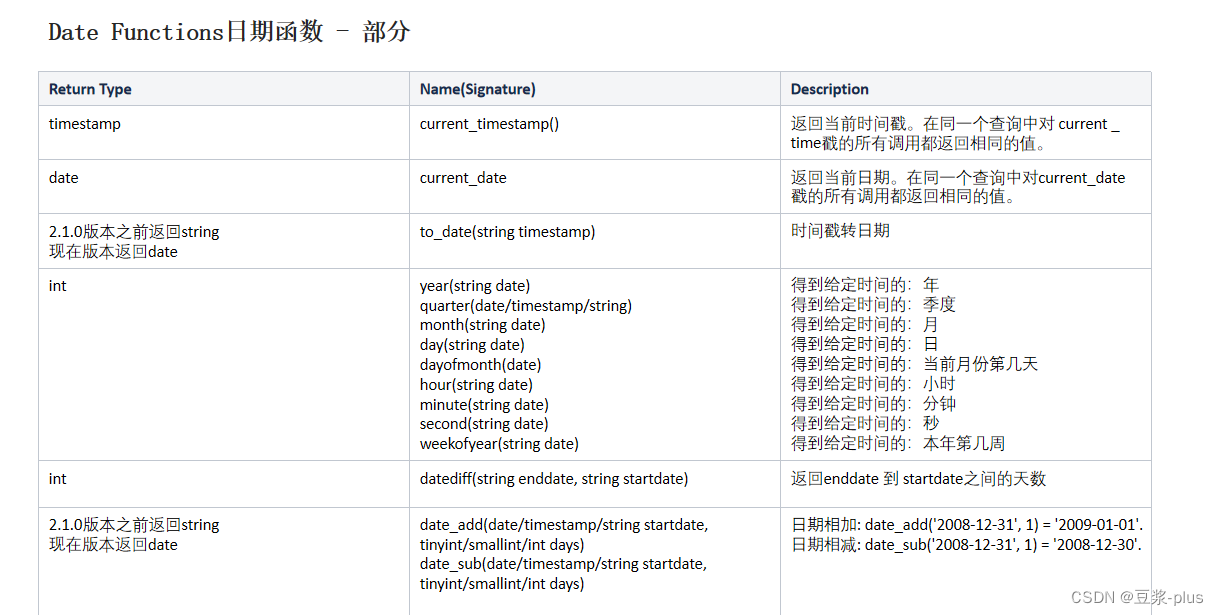
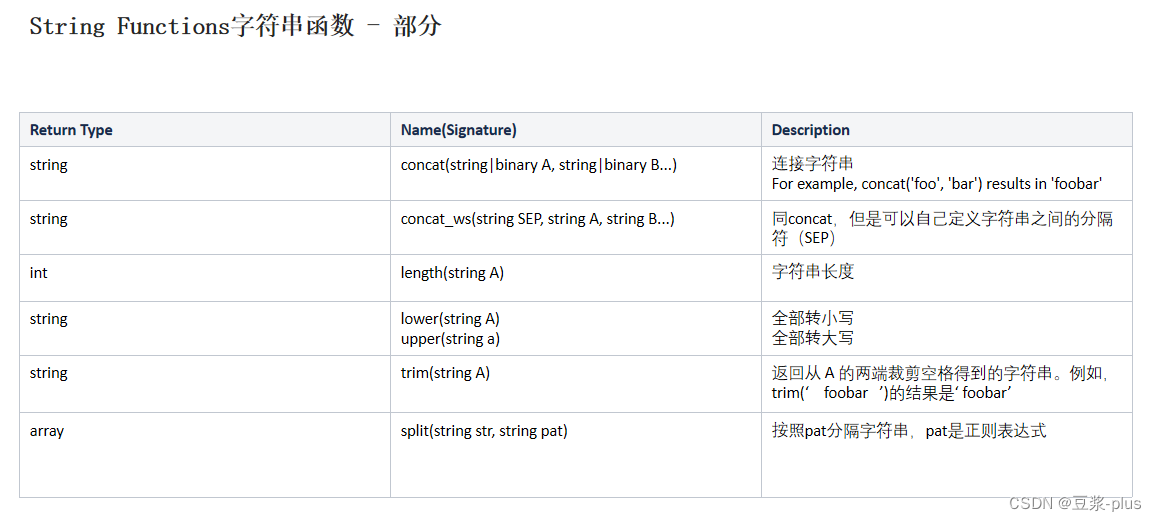
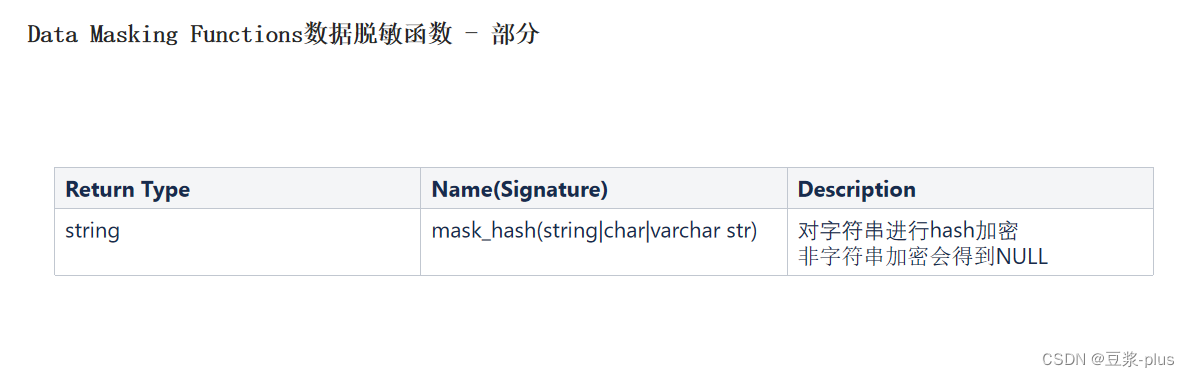

案例:

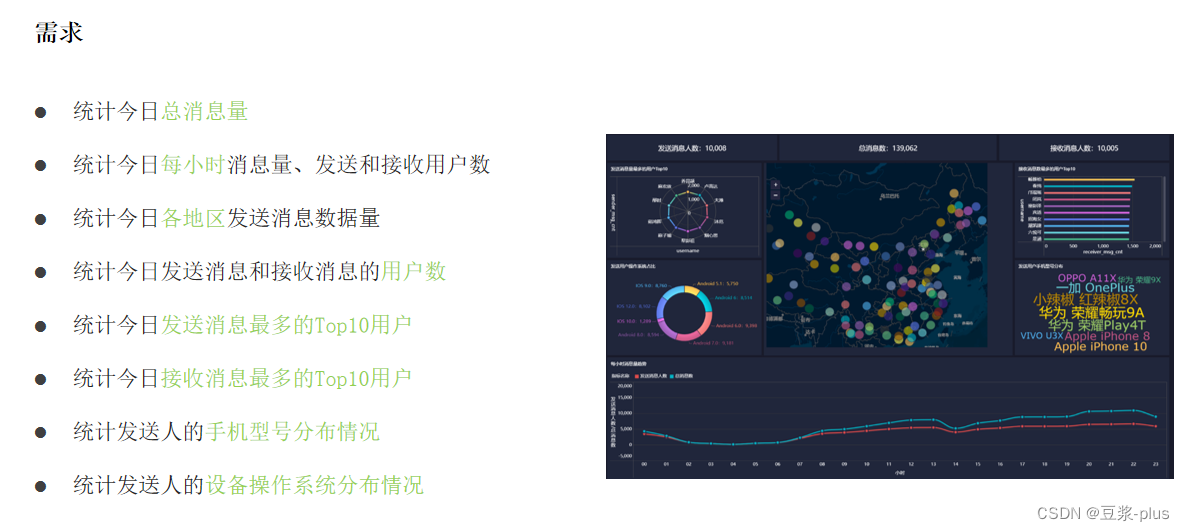
--如果数据库已存在就删除
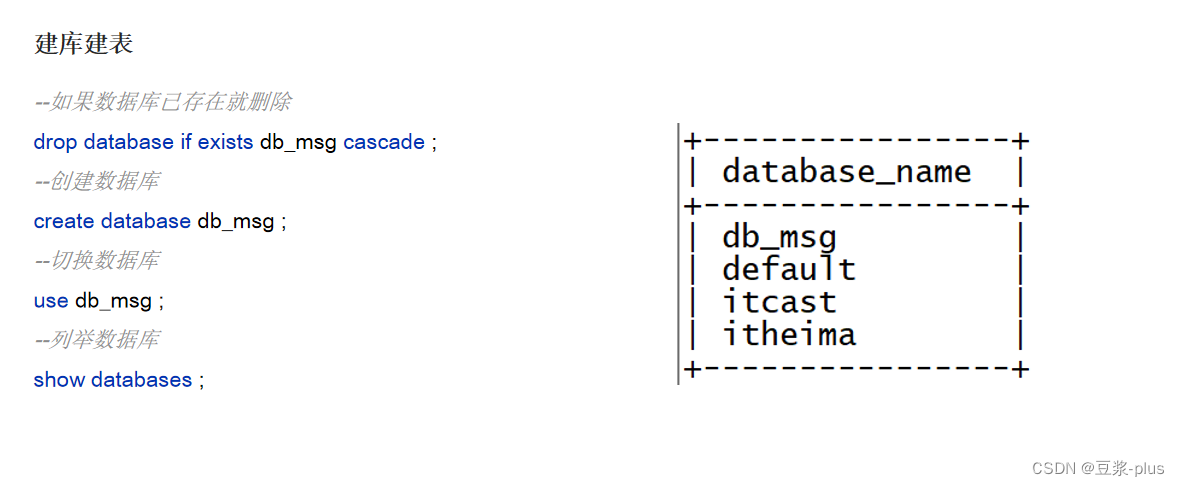
drop database if exists db_msg cascade ;
--创建数据库
create database db_msg ;
--切换数据库
use db_msg ;
--列举数据库
show databases ;

--如果表已存在就删除
drop table if exists db_msg.tb_msg_source ;
--建表
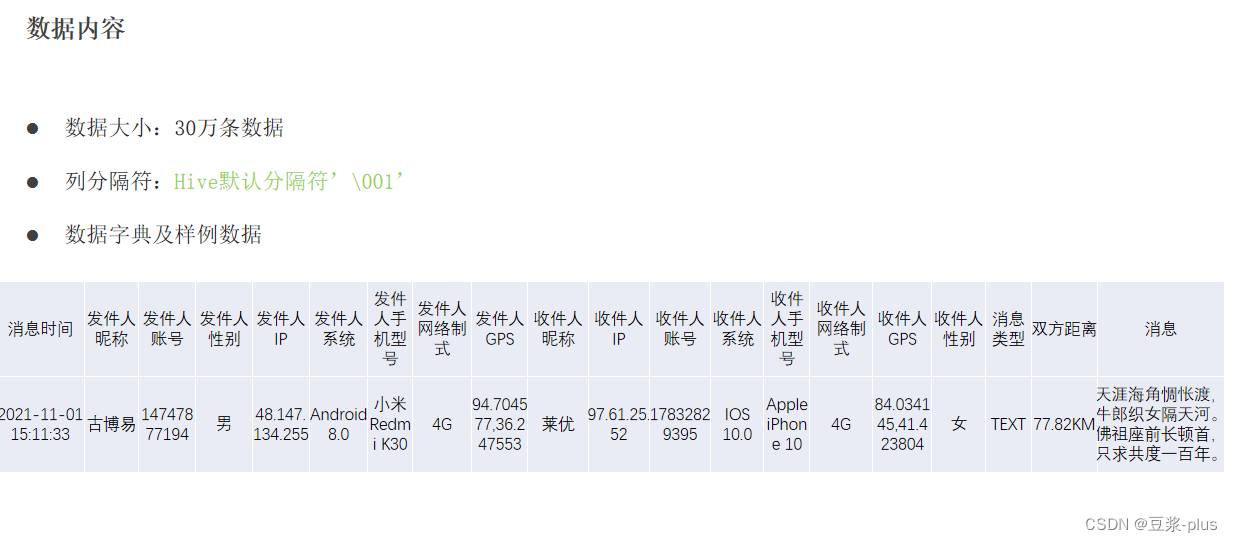
create table db_msg.tb_msg_source(
msg_time string comment "消息发送时间",
sender_name string comment "发送人昵称",
sender_account string comment "发送人账号",
sender_sex string comment "发送人性别",
sender_ip string comment "发送人ip地址",
sender_os string comment "发送人操作系统",
sender_phonetype string comment "发送人手机型号",
sender_network string comment "发送人网络类型",
sender_gps string comment "发送人的GPS定位",
receiver_name string comment "接收人昵称",
receiver_ip string comment "接收人IP",
receiver_account string comment "接收人账号",
receiver_os string comment "接收人操作系统",
receiver_phonetype string comment "接收人手机型号",
receiver_network string comment "接收人网络类型",
receiver_gps string comment "接收人的GPS定位",
receiver_sex string comment "接收人性别",
msg_type string comment "消息类型",
distance string comment "双方距离",
message string comment "消息内容"
);
load data local inpath '/home/hadoop/chat_data-30W.csv' overwrite into table tb_msg_source;
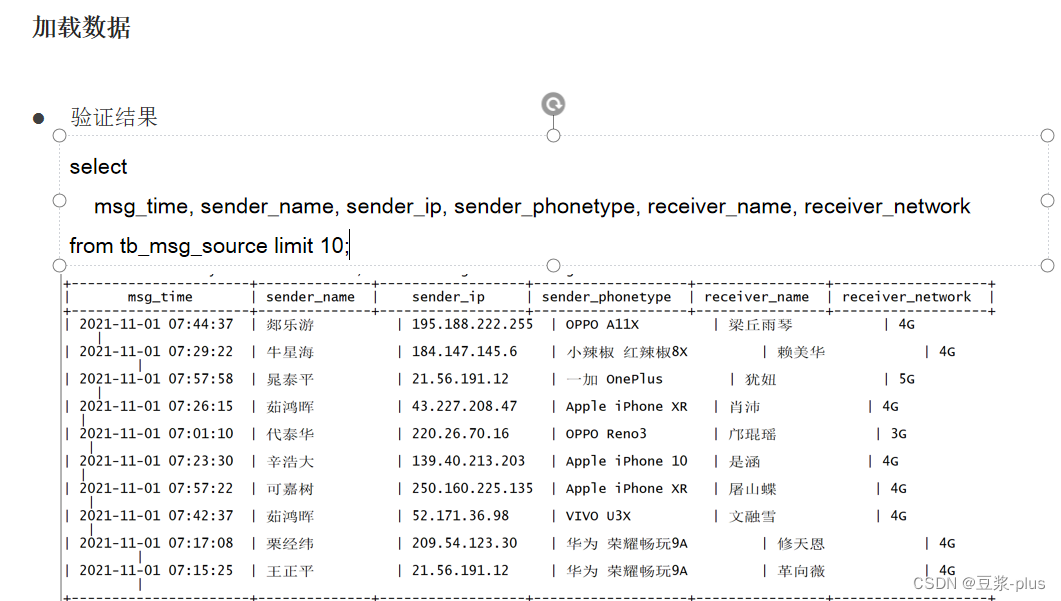
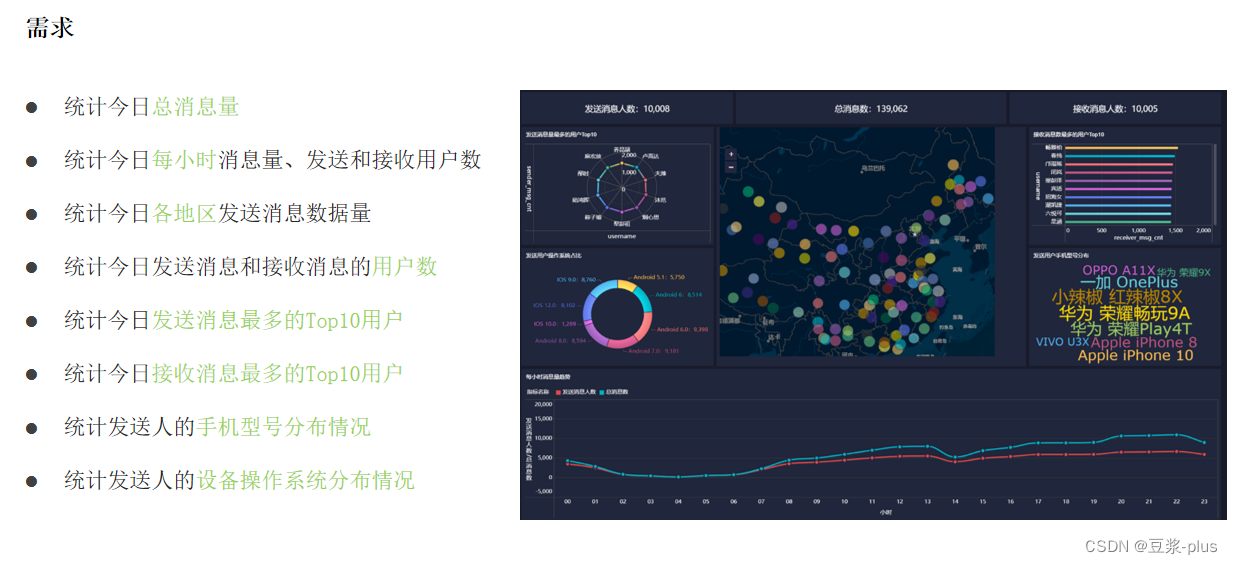
select msg_time, sender_name, sender_ip, sender_phonetype, receiver_name, receiver_network
from tb_msg_source limit 10;
完成数据源的清洗工作:

select msg_time, sender_name, sender_gps from db_msg.tb_msg_source where length(sender_gps) = 0 limit 10;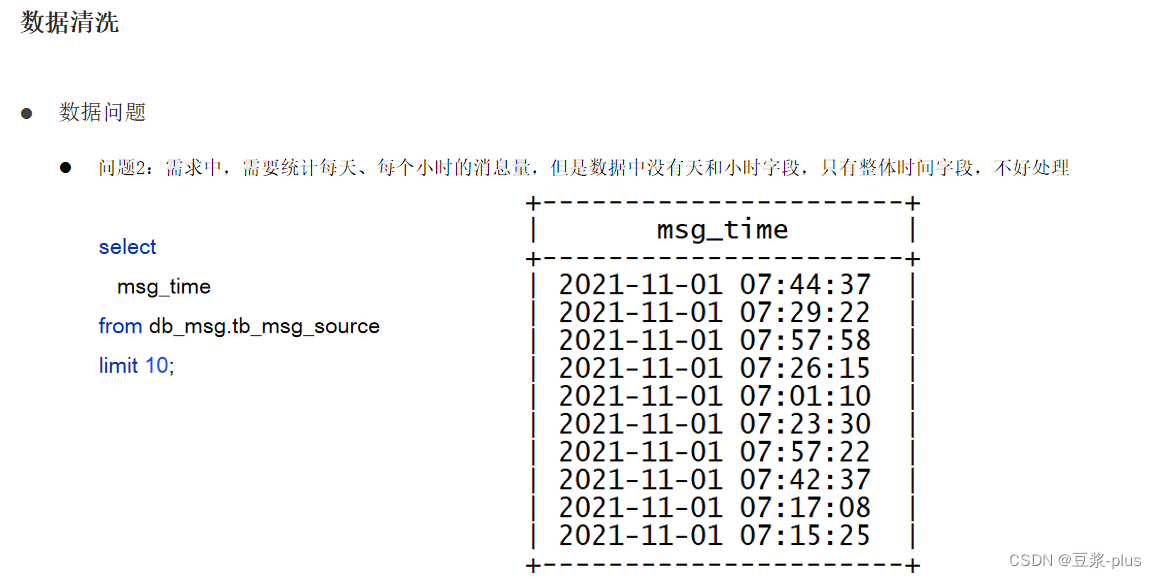
select msg_time from db_msg.tb_msg_source limit 10;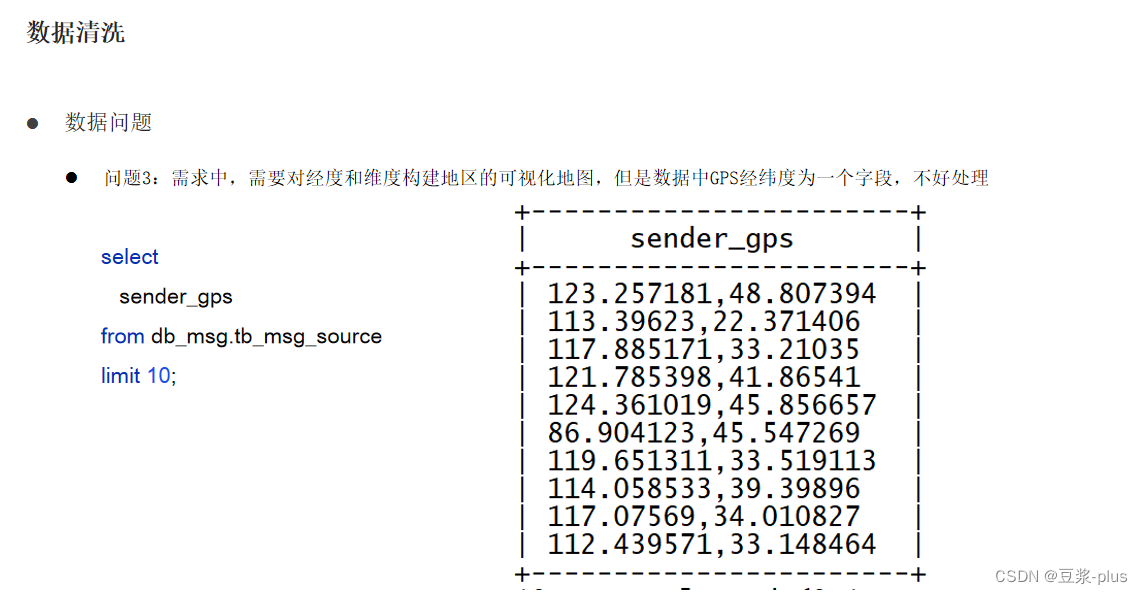
select sender_gpsfrom db_msg.tb_msg_sourcelimit 10;

create table db_msg.tb_msg_etl(
msg_time string comment "消息发送时间",
sender_name string comment "发送人昵称",
sender_account string comment "发送人账号",
sender_sex string comment "发送人性别",
sender_ip string comment "发送人ip地址",
sender_os string comment "发送人操作系统",
sender_phonetype string comment "发送人手机型号",
sender_network string comment "发送人网络类型",
sender_gps string comment "发送人的GPS定位",
receiver_name string comment "接收人昵称",
receiver_ip string comment "接收人IP",
receiver_account string comment "接收人账号",
receiver_os string comment "接收人操作系统",
receiver_phonetype string comment "接收人手机型号",
receiver_network string comment "接收人网络类型",
receiver_gps string comment "接收人的GPS定位",
receiver_sex string comment "接收人性别",
msg_type string comment "消息类型",
distance string comment "双方距离",
message string comment "消息内容",
msg_day string comment "消息日",
msg_hour string comment "消息小时",
sender_lng double comment "经度",
sender_lat double comment "纬度"
);

INSERT OVERWRITE TABLE db_msg.tb_msg_etl
SELECT *, day(msg_time) as msg_day, HOUR(msg_time) as msg_hour, split(sender_gps, ',')[0] AS sender_lng,split(sender_gps, ',')[1] AS sender_lat
FROM tb_msg_source WHERE LENGTH(sender_gps) > 0;

select msg_time, msy_day, msg_hour, sender_gps, sender_lng, sender_latfrom db_msg.tb_msg_etllimit 10;

基于Hive完成需求的各个指标计算: