“浅对齐”模型
经典多模态结构BLIP2
Motivation
-
端到端的进行vision-language预训练成本太大了,之前存在很多预训练好的模型,这篇文章希望能够使用这些训练好的参数,节约成本。
-
如果直接冻结预训练好的参数,去做下游任务,效果不佳。这是因为图像表征和文本表征是在两个不同的语料利用不同的模型训练出来的,不好对齐。
因此这篇论文提出了一个Query Transformer(Q-Former)结构,通过训练该结构能够对齐两种模态的信息,并且q-former很轻量,训练很快,花销很小。

整个训练过程被分成了两阶段。第一阶段进一步学习图像和文本表征;第二阶段从冻结的大语言模型中引导图像到文本的生成学习,实现zero-shot图像到文本生成。它冻结了图像编码器和文本编码器中的参数,不需要端到端的训练图像编码器和文本编码器,只需要训练Q-former。
Q-former结构
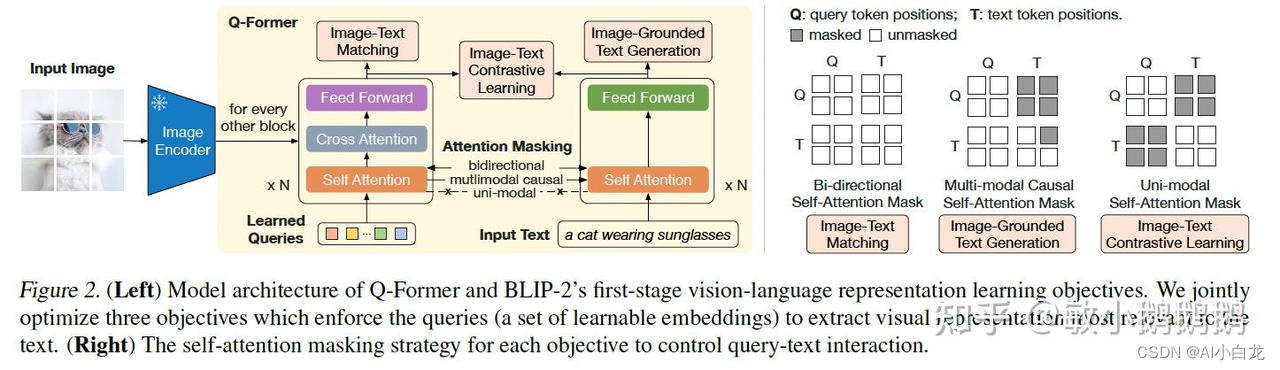
-
Image-Text Contrastive Learning (ITC)
鼓励成对正样本之间更相似,负例之间相似度更低。但由于query的存在,它并不是直接使用图像和文本编码器输出的图文表征。对于图像表征,它选择了经过图像编码器后的query representation,对于文本表征选择使用text transformer输出的[CLS]表征 t。并且由于query embedding中包含了32个query的表征,需要分别计算每一个query和 t 之间的相似度,最后只取相似度的最高值。为了避免信息泄露,这个任务使用的是unimodal self-attention mask
-
Image-grounded Text Generation (ITG)
Q-former结构中,冻结的图像编码器和text tokens不能直接交互,因此想做生成时需要两步,第一步使用queries提取表征,第二步将表征通过自注意力层传递给text token(这里体现在q-former中的图像部分和文本部分使用的self-attention是共享的)因此,query被迫提取有关文本所有信息的视觉表征。
使用multimodal causal self-attention mask控制query-text交互,query看不到text,text能看到query和之前的text token。
-
Image-Text Matching (ITM)
图文匹配二分类任务。使用bi-directional self-attention mask,query和text之间可以互相看到。每一个query embedding作为二分类任务的输入都可以得到一个预测概率,最终取32个query预测概率的平均值作为输出的预测分数。这篇论文中也使用了ALBEF中的hard negative mining strategy。
LLaVA&MiniGPT-4
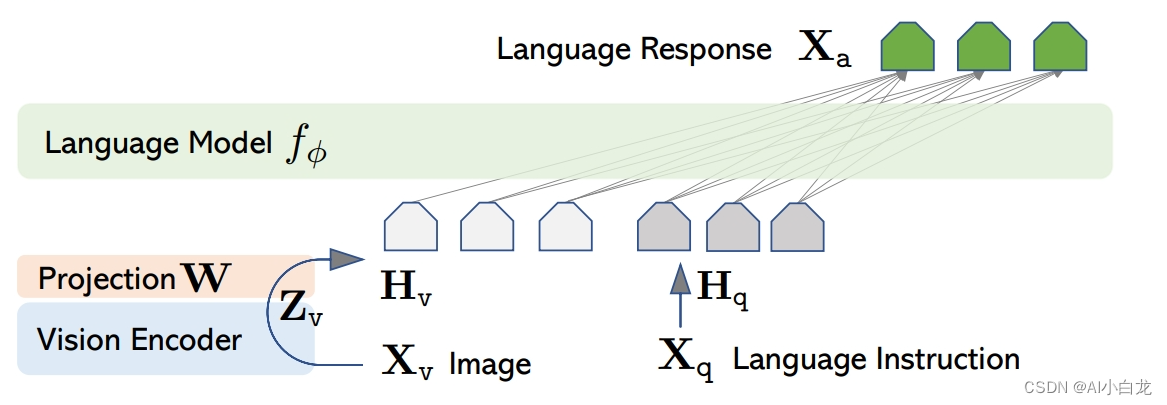
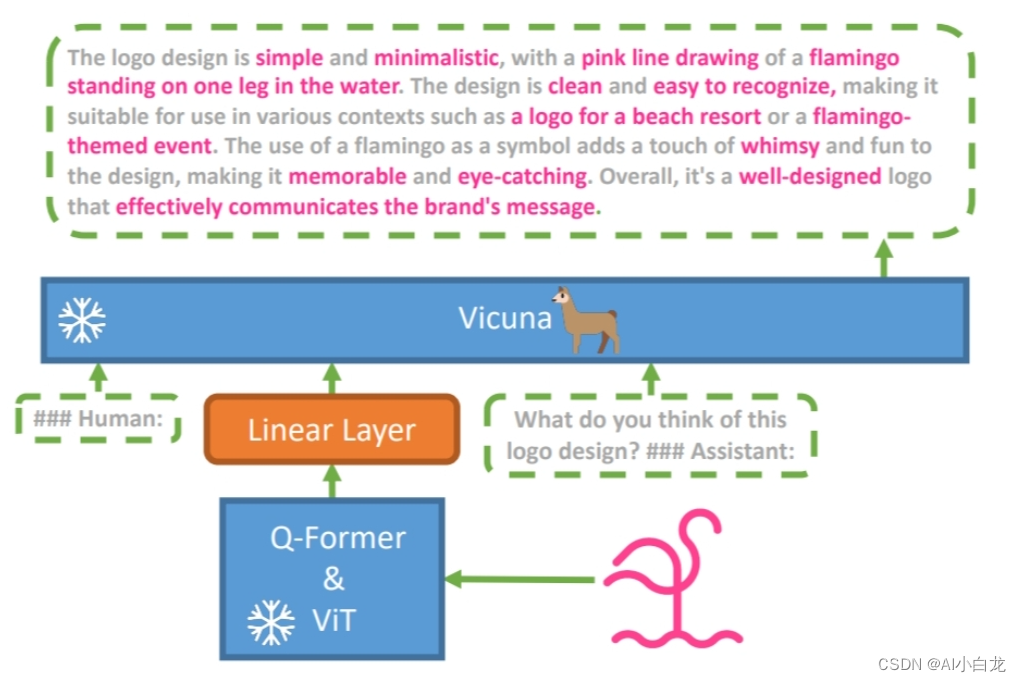
如图1与图2所示,比较典型的是LLaVA;以及MiniGPT-4和VisualGLM采用基本相同的方案,都是基于BLIP-2。
-
LLaVA是将视觉encoder处理过后的视觉向量通过一个简单的投影层直接映射到词向量空间;
-
MiniGPT-4则是使用q-former将视觉encoder产生的向量通过32个特殊tokens抓取与输入文本最相关的信息而产生32个新的tokens,再将这32个tokens通过一个投影层映射到词向量空间。
-
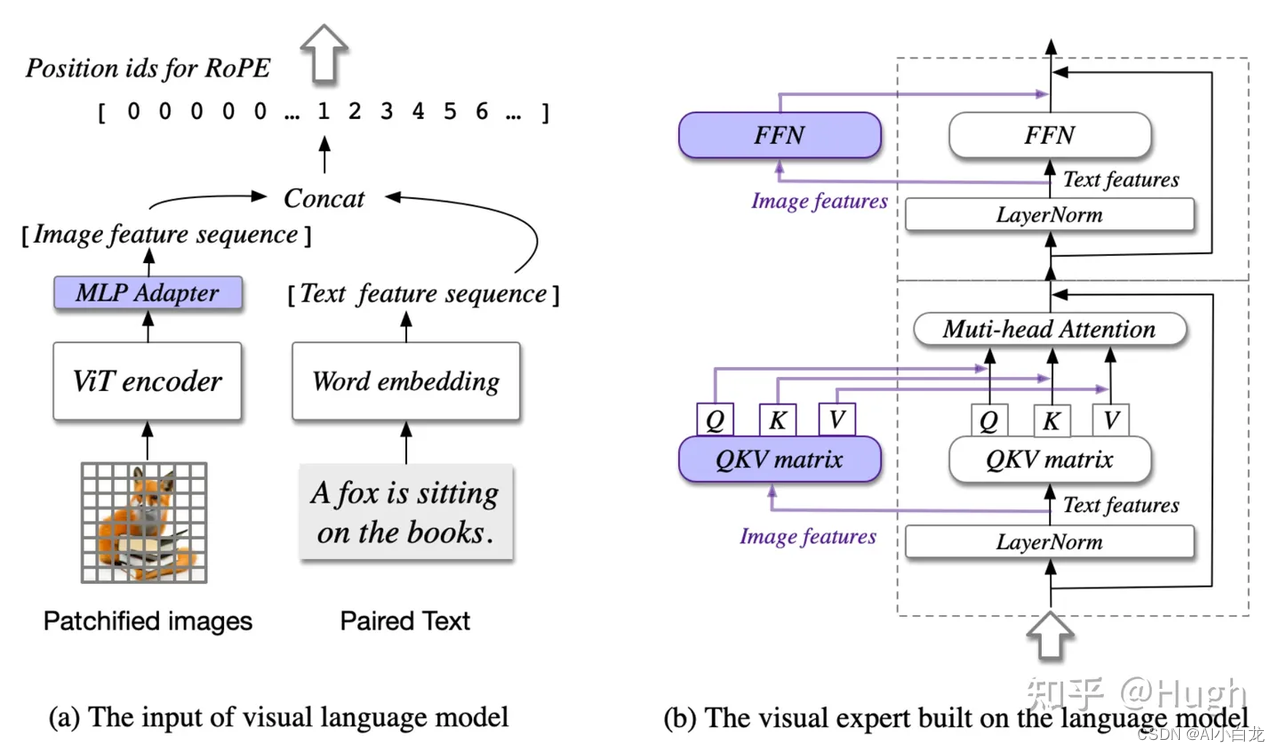
CogVLM解读
CogVLM在“浅对齐”的基础上,往大语言模型的每个decoder层添加视觉专家模块,实现了更深层次的对齐。
思路
受到p-tuning和LoRA的效果对比的启发(P-tuning通过学习给LLM添加前缀prompt来微调LLM,这与多模态大模型的"浅对齐"方式类似;而LoRA通过在LLM的每一个attention模块上添加低秩矩阵来实现微调。LoRA的微调效果要远强于P-tuning)作者想到了给LLM添加视觉专家模块。
深层解释
给模型添加视觉模块还有两个原因:
-
语言模型中的冻结权重是针对文本标记进行训练的。视觉特征在输入文本空间中没有完美的对应。因此,在多层转换后,视觉特征可能不再匹配深层权重的输入分布。
-
在预训练过程中,图像caption任务的先验,例如文字风格和caption长度,只能在浅对齐方法中编码到视觉特征中。它削弱了视觉特征与内容之间的一致性。
如果将视觉和语言信息一起训练可能可以解决这些问题。但是后果是会造成灾难性遗忘。而CogVLM采用的方案是给原LLM的每个decoder层加上一个视觉专家模型,每个视觉专家模型由一个完整的decoder模块构成(即Attention + FFN)。在训练过程中,原LLM的参数被固定不训练,所以训练消耗的FLOPs不变(笔者个人理解,不变是不可能的,只是增加的不多)。并且由于LLM的参数被固定,所以LLM原有的能力不受影响。
LLaMA-Adapter系列
LLaMA-Adapter
LLaMA- Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention
模型图如下,红色的表示初始化的可训练的 adaption prompts,蓝色的表示参数冻结的 LLM 模型
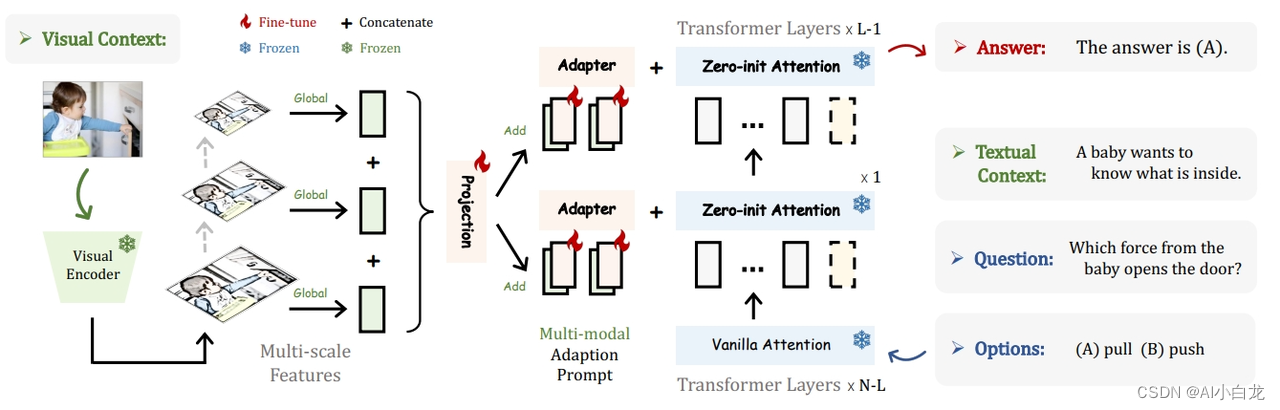
Multi-modal Reasoning of LLaMA-Adapter。LLaMAAdapter被扩展为多模态变体,用于图像条件问答。给定图像作为视觉上下文,我们通过多尺度聚合获得全局图像标记,并将其巧妙地添加到视觉指令跟随的自适应提示中。
LLaMA-Adapter V2
通过解锁更多的可学习参数,增强了LLaMA-Adapter,比如Norm、bias和scale,这能将instruction-following能力分散到整个LLaMA模型,除了adapters。
一个图文对和instruction-following数据的联合训练模式通过优化可学习参数的拆分组被引入。这个策略有效的减轻了两个任务间的推理:图文对齐和instruction following,并且只使用一小部分图文和instruction数据集,取得了好的多模态推理。
在推理中,我们将额外的expert模型融合到了LLaMA-Adapter中去,在不需要增加训练成本下,进一步增强它的图像理解能力。
主要贡献:
-
更强的语言指导模型。有参数高效微调的方法、高质量语言instruction数据,LLaMA-Adapter V2在语言instruction-following性能上超过了LLaMA-Adapter。而且,LLaMA-Adapter V2能够开展多轮对话,展示了它的更强的语言instruction能力。
-
平衡的视觉Instruction 微调 我们提出了一个简单的早期融合策略去解决图文匹配和Instruction Following之间的干扰。因此,我们将LLaMA-Adapter V2变成了视觉Instruction 模型,不需要多模态Instruction训练数据。
-
加入专家系统。没有在大规模的图文对上预训练,而是采用整合不同的专家系统去增强LLMs的图像理解能力。