面向侧扫声纳目标检测的YOLOX-ViT知识精馏
- 摘要
- Introduction
- Related Work
- YOLOv-ViT
- Knowledge Distillation
- Experimental Evaluation
Knowledge Distillation in YOLOX-ViT for Side-Scan Sonar Object Detection
摘要
在本文中,作者提出了YOLOX-ViT这一新型目标检测模型,并研究了在不牺牲性能的情况下,知识蒸馏对模型尺寸减小的有效性。聚焦于水下机器人领域,作者的研究解决了关于较小模型的可行性以及视觉Transformer层在YOLOX中影响的关键问题。此外,作者引入了一个新的侧扫声纳图像数据集,并使用它来评估作者的目标检测器的性能。
结果显示,知识蒸馏有效减少了墙体检测中的误报。另外,引入的视觉Transformer层在水下环境中显著提高了目标检测的准确性。
YOLOX-ViT中的知识蒸馏源代码:https://github.com/remaro-network/KD-YOLOX-ViT
Introduction
在过去的几十年里,探索海洋环境的兴趣日益增长,这导致了水下活动范围的扩大,如基础设施开发[1]和考古探索[2]。由于水下条件的不可预测和通常是未知的特点,自主水下航行器(AUVs)在执行从调查到维护等各种任务中变得至关重要。AUVs能够根据预定义计划进行数据收集和执行水下操作。
然而,水下环境的复杂性要求提高决策能力,因此需要深入了解航行器所处的环境。基于深度学习的计算机视觉技术为这种场景下的嵌入式实时检测提供了一个有前景的解决方案[3]。然而,标准DL模型的大尺寸对于AUVs来说在电力消耗、内存分配以及实时处理需求方面提出了重大挑战。最近的研究集中在了模型简化上,以促进在嵌入式系统上实施DL模型[4]。
本文通过以下方面的贡献,为这项工作添砖加瓦:
-
提升了当前最先进的目标检测模型YOLOX,通过整合一个视觉Transformer层,形成了YOLOX-ViT模型,为目标检测领域引入了更加强大的模型结构和特性。
-
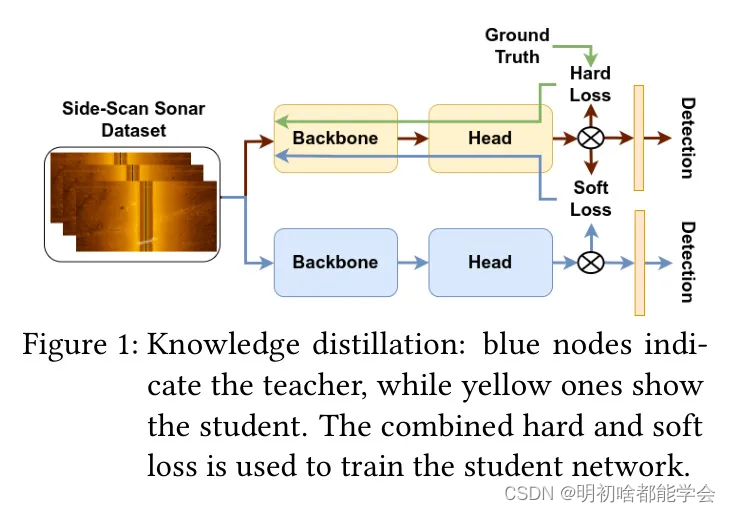
实现了一种知识蒸馏(KD)方法,用于提高较小型的YOLOX-ViT模型(如YOLOX-Nano-ViT,见图1)的性能,为在资源受限情况下提供了一种有效的性能优化手段。
-
引入了一种新型的侧扫声纳(SSS)数据集,专门用于墙壁检测,为该领域的研究和实践提供了更加全面和专业的数据支持,从而推动了墙壁检测技术的发展和应用。
Related Work
目标检测。 目标检测是计算机视觉(CV)中的基本任务,旨在数字图像中检测特定类别的视觉目标[5]。其目标是开发高效的算法,为CV应用提供必要的信息:“哪些目标在哪里?”。这些方法的质量通过检测准确性(分类和定位)和效率(预测时间)来衡量。这些方法力求在准确性和效率之间找到一个实用的折中方案。深度学习[6, 7]的日益普及,在目标检测方面取得了显著突破。因此,它被广泛应用于许多实际应用中,如自动驾驶[8]、机器人视觉[9]和视频监控[10]。
基于深度学习的目标检测器分为“两阶段检测器”和“一阶段检测器”[5]。值得注意的是,You Only Look Once(YOLO)是一种具有代表性的单阶段检测器[11],以其速度和有效性而闻名[12, 13]。YOLO的简单之处在于它能够直接通过神经网络输出边界框位置和类别[13]。在过去的几年中,引入了各种YOLO版本,如YOLO V2[14]、YOLO V3[15]、YOLO V4[16]、YOLO V5[17]和YOLOX[18]。YOLOX,一个 Anchor-Free 版本(附录B中提供详细解释),采用了更简单的设计,性能更优,旨在弥合研究与应用之间的差距[18]。
知识蒸馏。 如第1节所述,车载深度学习模型必须满足实际生活中的限制,如效率和准确性。较大的模型通常因为能够学习复杂的关系而获得更好的结果,但它们伴随着更高的计算资源消耗。在保持性能的同时减小模型尺寸的研究一直在进行中,包括专注于移除较不关键的神经元或权重[model pruning]的研究[19, 20]。
G. Hinton等人[21]引入了知识蒸馏(KD)用于图像分类,通过使用一种新的损失函数,将知识从训练良好的大模型(教师)传递到小模型(学生)。这个损失函数结合了硬目标损失 L hard L_{\text{hard}} Lhard和蒸馏损失 L soft L_{\text{soft}} Lsoft,其中前者指导预测向真实标签靠近,后者利用大模型的知识来调整小模型的行为。损失函数表达为 L = α × L hard + ( 1 − α ) × L soft L = \alpha \times L_{\text{hard}} + (1 - \alpha) \times L_{\text{soft}} L=α×Lhard+(1−α)×Lsoft,其中 α \alpha α是一个调节硬损失和软损失项的参数。
陈等人[4]证明了知识蒸馏(KD)在压缩单次射击检测器(SSD)模型中的有效性,并引入了一种改进方法,该方法使用基于中间Backbone逻辑的“提示”损失函数。
魏等人[22]提出了一种新颖的方法,学生模型同时从教师模型的最终输出和中间特征表示中学习,这提高了复杂场景下的性能。
张等人[23]为Faster R-CNN定制了KD技术,在不牺牲检测准确性的情况下实现了效率提升。
杨等人[24]将KD应用于YOLOv5,使用YOLOv5-m作为教师模型,YOLOv5-n作为学生模型进行目标检测,这使得YOLOv5-n的mAP提高了大约2%。
YOLOv-ViT
由Vaswani等人[25]提出的Transformers最初是为自然语言处理设计的,它在处理序列数据方面被证明是有效的,并且超越了当时的最新技术水平。Dosovitskiy等人[26]引入了名为ViT的视觉Transformer,这是首个计算机视觉Transformer模型,在没有卷积层的情况下,在图像识别任务上取得了最先进的表现。Carion等人[27]提出了DETR(DEtection TRansformer)用于目标检测,直接预测集合(边界框、类别标签和置信度得分),无需单独的区域 Proposal 和细化阶段。
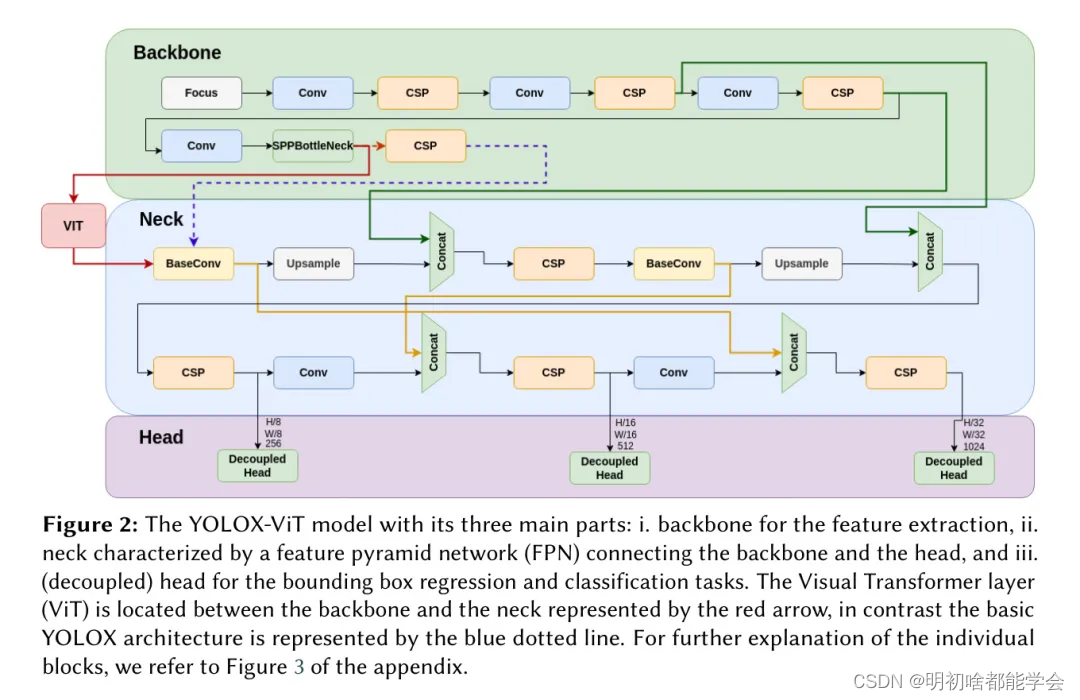
关于ViT的进一步描述可以在附录的C节中找到。将Transformer与CNN集成在一起,可以增强在目标检测任务中的特征提取,结合了CNN的空间层次和Transformer的全局上下文。Yu等人[28]提出了YOLOv5-TR用于集装箱和沉船检测。Aubard等人[3]展示了使用YOLOX可以实现5.5%的性能提升。作者的论文建议通过在_SPPP瓶颈_层末端的主干网络和 Neck 之间加入一个Transformer层(见图2),来增强YOLOX模型的特征提取能力。ViT层由4个多头自注意力(MHSA)子层组成。
Underwater SSS Image Dataset
声纳墙检测数据集(SWDD)包括在波尔图莱索斯港使用Klein 3500声纳在轻型自主水下航行器(LAUV)上收集的侧扫声纳(SSS)图像,该航行器由OceanScan Marine Systems & Technology公司操作。调查沿着港口墙壁产生了216张图像。由于当前数据集中的数据量较小,因此使用了数据增强方法来增加数据量并提高模型的鲁棒性。本文中使用的数据增强引入了噪声、翻转以及噪声-翻转组合变换。
噪声是一种高斯噪声,表示为 I noisy ( z , g ) = I ( z , g ) + N ( 0 , σ 2 ) I_{\text{noisy}}(z, g) = I(z, g) + N(0, \sigma^2) Inoisy(z,g)=I(z,g)+N(0,σ2)。其中 I noisy ( z , g ) I_{\text{noisy}}(z, g) Inoisy(z,g)是噪声图像中位于位置 ( z , g ) (z, g) (z,g)的像素的强度值, I ( z , g ) I(z, g) I(z,g)是位置 ( z , g ) (z, g) (z,g)的原始强度,而 N ( 0 , σ 2 ) N(0, \sigma^2) N(0,σ2)表示从均值为0、方差为 σ 2 \sigma^2 σ2的高斯分布中抽取的样本。此数据集的标准差 α \alpha α等于 0.5 × 255 0.5 \times 255 0.5×255。
水平翻转被描述为 L flipped ( z , g ) = I ( w − x − 1 , g ) L_{\text{flipped}}(z, g) = I(w - x - 1, g) Lflipped(z,g)=I(w−x−1,g)。它沿着图像的垂直轴进行镜像处理,其中 w w w是图像的宽度, ( w − x − 1 ) (w - x - 1) (w−x−1)实际上改变了每个像素的水平位置。
该数据集包含“墙壁”和“无墙壁”两类,共有2,616个标记样本。为了进行稳健的训练,作者将原始图像和增强图像结合在一起,将数据集分为70%用于训练,15%用于验证,以及15%用于测试。每张SSS图像是在每侧75米的范围内以900千赫兹的频率生成的,由500条连续线组成,从而形成一个 4.168 × 500 4.168 \times 500 4.168×500 像素的分辨率。为了与计算机视觉算法兼容,作者将图像缩放到 640 × 640 640 \times 640 640×640。
Knowledge Distillation
考虑到YOLOX的架构,如第2节所述,知识蒸馏(KD)应用于特征金字塔网络(FPN)的每个解耦头。由于这种架构的特殊性,KD过程涉及计算学生模型与教师模型之间每个FPN输出的不同损失函数,包括分类、边界框回归和目标性得分。
一般的KD损失函数定义为:
在这个设置中,知识蒸馏(KD)的损失函数被定义为硬损失和软损失的总和,即 L KD = L hard + L soft L_{\text{KD}} = L_{\text{hard}} + L_{\text{soft}} LKD=Lhard+Lsoft。软损失项 L soft L_{\text{soft}} Lsoft根据不同类型的损失(分类、目标性、边界框)在每个FPN输出结果中进行了分解。
分类损失 L KD_cls L_{\text{KD\_cls}} LKD_cls在每个FPN输出结果中都有一部分,可以表示为:
L KD_cls = L KD_cls_FPN0 + L KD_cls_FPN1 + L KD_cls_FPN2 L_{\text{KD\_cls}} = L_{\text{KD\_cls\_FPN0}} + L_{\text{KD\_cls\_FPN1}} + L_{\text{KD\_cls\_FPN2}} LKD_cls=LKD_cls_FPN0+LKD_cls_FPN1+LKD_cls_FPN2
边界框回归损失 L KD_bbox L_{\text{KD\_bbox}} LKD_bbox在每个FPN输出结果中也有一部分,可以表示为:
L KD_bbox = L KD_bbox_FPN0 + L KD_bbox_FPN1 + L KD_bbox_FPN2 L_{\text{KD\_bbox}} = L_{\text{KD\_bbox\_FPN0}} + L_{\text{KD\_bbox\_FPN1}} + L_{\text{KD\_bbox\_FPN2}} LKD_bbox=LKD_bbox_FPN0+LKD_bbox_FPN1+LKD_bbox_FPN2
目标性损失 L KD_obj L_{\text{KD\_obj}} LKD_obj同样在每个FPN输出结果中有一部分,可以表示为:
L KD_obj = L KD_obj_FPN0 + L KD_obj_FPN1 + L KD_obj_FPN2 L_{\text{KD\_obj}} = L_{\text{KD\_obj\_FPN0}} + L_{\text{KD\_obj\_FPN1}} + L_{\text{KD\_obj\_FPN2}} LKD_obj=LKD_obj_FPN0+LKD_obj_FPN1+LKD_obj_FPN2
在作者的实验中,软损失项( L KD_cls L_{\text{KD\_cls}} LKD_cls、 L KD_bbox L_{\text{KD\_bbox}} LKD_bbox和 L KD_obj L_{\text{KD\_obj}} LKD_obj)都乘以0.5的系数,即 α bbox = α obj = α cls = 0.5 \alpha_{\text{bbox}} = \alpha_{\text{obj}} = \alpha_{\text{cls}} = 0.5 αbbox=αobj=αcls=0.5。这种设置旨在保持硬损失在学生模型学习过程中的主导作用,同时确保软损失对将教师模型的细粒度知识传递到学生模型至关重要。
训练YOLOX-L。
- 初始化YOLOX-Nano的训练。
- 对于每个批次,使用YOLOX-L进行推理。
- 计算YOLOX-L和YOLOX-Nano之间的FPN逻辑值之间的差异。
- 差异与相结合。
由于每次迭代都需要进行推理,这种在线知识蒸馏方法需要一周的时间。为了减少时间上的投入,本文采用了无需在YOLOX-Nano训练期间进行随机在线数据增强的离线知识蒸馏方法。工作流程如下:
训练YOLOX-L。
执行YOLOX-L推理,并保存每个训练样本的FPN逻辑值。
启动YOLOX-Nano的训练。
为每张图像检索相应的FPN逻辑值。
计算YOLOX-L和YOLOX-Nano每个FPN输出的逻辑值之间的Csoft ,
将Lsoft与Lhard相结合。
Experimental Evaluation
除了在训练期间获得的初步结果外,作者还实施了一个在线验证过程,以评估模型在真实世界数据上的表现。这一评估围绕一个来自不同调查的6分57秒的视频进行。为了进行彻底的评估,作者精确计时并手动记录了视频分析过程中的真阳性和假阳性检测。此外,作者还从视频中提取并标注了帧,以便更精确地评估模型的准确性,总共标注了6,243张图像。
作者对YOLOX-L、YOLOX-Nano和YOLOX-ViT等模型在视频上的推理结果进行了保存,并利用Object Detection Metrics仓库计算了各种指标,如True Positive(TP)、False Positive(FP)、Precision(Pr)、Average Precision (AP) 等。该评估过程分为两个部分,第一部分使用在线随机数据增强进行训练,第二部分则没有使用。
对比YOLOX-L和YOLOX-L-ViT模型,尤其是在提取图像的实验中,揭示了在线数据增强模型的一些局限性。YOLOX-L和YOLOX-L-ViT模型表现不佳,相比没有在线数据增强的YOLOX-L-noAug和YOLOX-L-ViT-noAug模型。这表明,移除在线数据增强可能会提高模型性能,而有限数据集的大小可能会不成比例地影响较大模型的效率。视觉实验也证实了这一点,即YOLOX-L-noAug在保持检测时间更长方面优于YOLOX-L,但假阳性增加了大约8.13%。此外,视觉实验表明,YOLOX-L-ViT在检测性能上表现更优越。
接下来,作者利用知识蒸馏(KD)技术,从YOLOX-L和YOLOX-L-ViT作为“教师”的模型中,将知识传递到YOLOX-Nano-noAug和YOLOX-Nano-ViT-noAug作为“学生”的模型中。结果表明,KD技术有效地降低了“假阳性”率,而ViT层进一步降低了学生模型中的“假阳性”率。对于Nano-noAug模型,基础模型将“假阳性”降低了约0.3%,而ViT变体则降低了约6%。
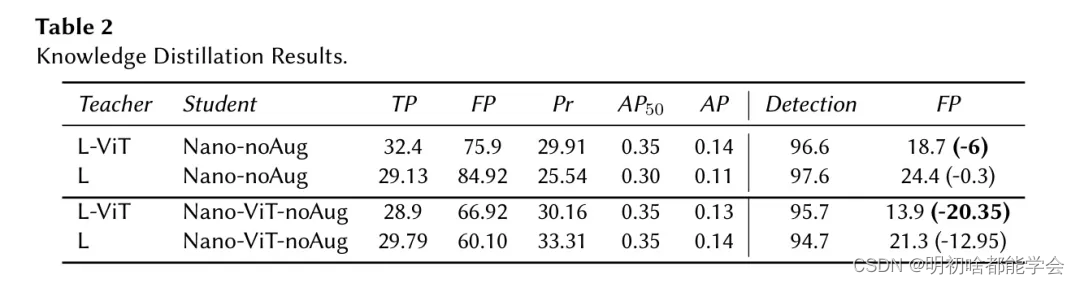
Nano-ViT-noAug模型,以基本模型为指导,将误报(False Positives)减少了大约12.95%,而ViT版本则实现了约20.35%的降低。这些结果强调了ViT层帮助模型专注于更有效的特征提取的能力。