接着之前我们[muduo网络库]——muduo库Socket类(剖析muduo网络库核心部分、设计思想),我们接下来继续看muduo库中的Buffer类。其实Buffer在我的另一篇博客里面已经介绍过了深究muduo网络库的Buffer类!!!,这里还是和这个之前几个类的方法保持一致,在梳理一遍Buffer类,给大家提供一个舒适的观感~
Buffer类
Buffer类封装了一个用户缓冲区,以及向这个缓冲区写数据读数据等一系列控制方法。
为什么要用Buffer
non-blocking网络编程中,non-blocking IO核心思想是避免阻塞在read()/write()或其他IO系统调用上,可以最大限度复用thread-of-control,让一个线程能服务于多个socket连接。而IO线程只能阻塞在IO-multiplexing函数上,如select()/poll()/epoll_wait(),这样应用层的缓冲区就是必须的,每个TCP socket都要有stateful的input buffer和output buffer。
设计思想
先来谈谈Buffer类整体的设计思想。因为这个编程思想,今后在各个需要缓冲区的项目编程中都可以用到。
muduo的Buffer的定义如下,其内部是 一个 std::vector,且还存在两个size_t类型的readerIndex_,writerIndex_标识来表示读写的位置。结构图如下:
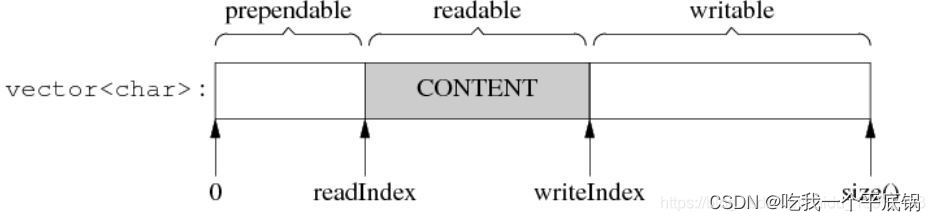
readIndex、writeIndex把整个vector内容分为3块:prependable、readable、writable,各块大小关系:
- prependable = readIndex
- readable = writeIndex - readIndex
- writable = buffer.size() - writeIndex
Buffer类是可以动态扩容的,在下面的成员函数中,会详细介绍。
重要成员变量
static const size_t kCheapPrepend = 8; //缓冲区头部
static const size_t kInitialSize = 1024; //缓冲区读写初始大小
std::vector<char> buffer_;
size_t readerIndex_;
size_t writerIndex_;
他们的作用就显而易见了
重要成员函数
- 通过构造函数,使两个标志位都指向kCheapPrepend
explicit Buffer(size_t initialSize = kInitialSize): buffer_(initialSize + kCheapPrepend), readerIndex_(kCheapPrepend), writerIndex_(kCheapPrepend){}
- 求出可读可写以及预留区的大小
size_t readableBytes() const { return writerIndex_ - readerIndex_; }
size_t writerableBytes() const { return buffer_.size() - writerIndex_; }
size_t prependableBytes() const { return readerIndex_; }
peek()函数,求出缓冲区可读数据的起始位置
const char* peek() const
{return begin() + readerIndex_;
}
- 重置标志位
readerIndex_,writerIndex_
void retrieve(size_t len) //len表示已经读了的
{if(len < readableBytes()) {//已经读的小于可读的,只读了一部分len//还剩readerIndex_ += len 到 writerIndex_readerIndex_ += len; }else //len == readableBytes(){retrieveAll();
}void retrieveAll() //都读完了
{readerIndex_ = writerIndex_ = kCheapPrepend;
}
- 把onMessage函数上报的Buffer数据,转成string类型的数据返回
std::string retrieveAllAsString()
{return retrieveAsString(readableBytes());//应用可读取数据的长度
}
std::string retrieveAsString(size_t len)
{std::string result(peek(),len); //从起始位置读len长retrieve(len);return result;
}
- 将data数据添加到缓冲区中,并且更新
writerIndex_指向。
void append(const char* data, size_t len) //添加数据
{ensureWriterableBytes(len);std::copy(data, data+len, beginWrite());writerIndex_ += len;
}
先来看看beginWrite,开始写得位置。
char* beginWrite() {return begin() + writerIndex_; }
const char* beginWrite() const {return begin() + writerIndex_; }
注意到这里有一个ensureWriterableBytes,它判断了缓冲区还有多少能写的位置,以及扩容
void ensureWriterableBytes(size_t len)
{if (writerableBytes() < len){makeSpace(len); //扩容}
}
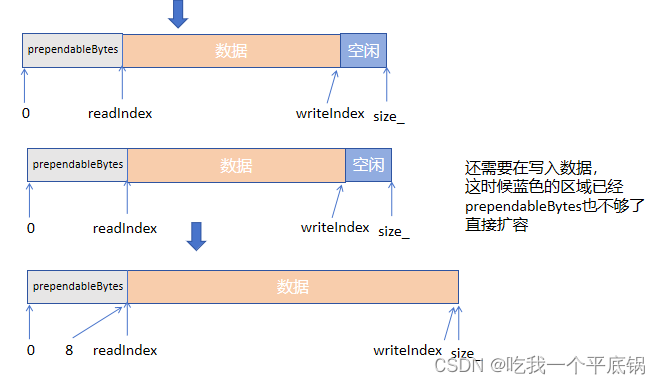
- 如何正确扩容,这就是Buffer的精髓了
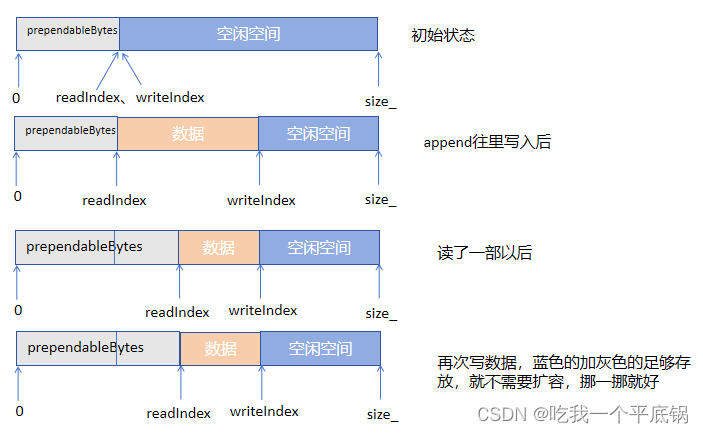
void makeSpace(size_t len){if (prependableBytes() + writerableBytes() < len + kCheapPrepend){buffer_.resize(writerIndex_ + len);}else{size_t readable = readableBytes(); //保存一下没有读取的数据std::copy(begin()+readerIndex_, begin()+writerIndex_, begin()+ kCheapPrepend); //挪一挪readerIndex_ = kCheapPrepend;writerIndex_ = readerIndex_+readable;}}
扩容巧妙思想在于,因为两个指针的不断移动,导致指向可读数据的指针一直后移,预留区越来越大,如果一味的扩容,会导致前面预留区越来越大,这样造成了浪费,所以muduo库采用了以下思路进行判断,何时需要扩容:
- 利用
prependableBytes() + writerableBytes()判断了整个Buffer上面剩余的可写入的空间,如果这个空间小于要写入的以及预留的8字节位置的总和,那么直接扩容!! - 如果大于说明目前剩余的位置还足够存放要写入的数据,那么通过vector的数据拷贝,把Buffer里面的数据挪一挪,这时候
readerIndex_就指向了初始位置,writerIndex_的位置就是目前可写入的首地址,这样在进行写入,就不需要一味的扩容。
过程图如下:
- 客户端发来数据,readFd从该TCP接收缓冲区中将数据读出来并放到Buffer中。
ssize_t Buffer::readFd(int fd,int* saveErrno)
{char extrabuf[65536] = { 0 }; //栈上内存空间struct iovec vec[2];const size_t writable = writerableBytes(); //buffer底层缓冲区剩余的可写的空间大小vec[0].iov_base = begin() + writerIndex_;vec[0].iov_len = writable;vec[1].iov_base = extrabuf;vec[1].iov_len = sizeof extrabuf;const int iovcnt = (writable < sizeof extrabuf) ? 2 : 1;const ssize_t n = ::readv(fd, vec, iovcnt);if(n < 0){*saveErrno = errno;}else if(n <= writable) //buffer可写的缓冲区已经够存储读取出来的数据{writerIndex_ += n;}else //extrabufl里面也写入了数据{writerIndex_ = buffer_.size();append(extrabuf,n-writable); //writerIndex_ 开始写n-writable的数据}return n;
}巧妙点在哪里呢?
我们在读数据的时候,不知道数据的最终大小是多少,所以采用了如下的方法:
- 首先定义了一个64K栈缓存extrabuf临时存储,利用栈的好处是可以自动的释放,并计算出目前剩余可写的空间大小;
- 利用结构体 iovec 指定了两块缓冲区,一块是目前剩余的可写的Buffer,一个是临时的缓冲区,指定了起始位置以及缓冲区的大小;
const int iovcnt = (writable < sizeof extrabuf) ? 2 : 1;如果writable < sizeof extrabuf就选2块内存readv,否则一块就够用;- 读数据const ssize_t n = ::readv(fd, vec, iovcnt);
- 若读取的数据超过现有内部buffer_的writable空间大小时, 启用备用的extrabuf 64KB空间, 并将这些数据添加到内部buffer_的末尾。
- 服务端要向这条TCP连接发送数据,将Buffer中的数据拷贝到TCP发送缓冲区中。
ssize_t Buffer::writeFd(int fd,int* saveErrno)
{ssize_t n = ::write(fd, peek(), readableBytes());if(n < 0){*saveErrno = errno;}return n;
}
这就是调用了系统的write函数。
iovec结构体定义
#include <sys/uio.h>struct iovec {ptr_t iov_base; /* Starting address */size_t iov_len; /* Length in bytes */
};
struct iovec定义了一个向量元素。通常,这个结构用作一个多元素的数组。对于每一个传输的元素,指针成员iov_base指向一个缓冲区,这个缓冲区是存放的是readv所接收的数据或是writev将要发送的数据。成员iov_len在各种情况下分别确定了接收的最大长度以及实际写入的长度。
代码地址:https://github.com/Cheeron955/mymuduo/tree/master