目录
缺失值处理
在dataframe中进行填补
使用模型填补缺失值(随机森林)
异常值
数据无量纲化
中心化
数据归一化
数据标准化
缩放处理
转换数据类型
文本—>数值preprocessing.LabelEncoder:标签专用,能够将分类转换为分类数值
preprocessing.OrdinalEncoder:特征专用,能够将分类特征转换为分类数值
preprocessing.OneHotEncoder:独热编码,创建哑变量
缺失值处理
一般有平均值(mean),中位数(median),众数(mode)
在dataframe中进行填补
# 用中位数进行填补
data.loc[:,"age"] = data.loc[:,"age"].fillna(data.loc[:."age"].median())
# 用众数进行填补
data.fillna(df.mode().iloc[0]) # df.mode(),计算众数,取每列第一个众数(如果有多个众数)
# 删除缺失值所在行
data.dropna(axis=0,inplace=True)
# 使用线性插值方法填补缺失值(连续值)
data = data.interpolate(method='linear', axis=0)
# 删除重复的行
data.drop_duplicates(keep="first",inplace=True)
inplace=True表示在原数据上进行修改,而不是创造一个副本
axis=0,删除有缺失值的行。axis=1,删除有缺失值的列。
使用模型填补缺失值(随机森林)
from sklearn.ensemble import RandomForestRegressordata2 = data.copy()
for i in['col1','col2']:#构建我们的新特征矩阵和新标签df = data2y= df[i]x= df.iloc[:,df.columns != i]#在新特征矩阵中,对含有缺失值的列,进行的填补 x0=SimpleImputer(missing_values=np.nan,strategy='constant',fill_value=0).fit_transform(x)#找出我们的训练集和测试集Ytrain = y[y.notnull()]Ytest = y[y.isnu1l()]Xtrain = x0[Ytrain.index,:]Xtest =x0[Ytest.index,:]#用随机森林回归来填补缺失值if(Xtest.sum()!=0):rfc = RandomForestRegressor(nestimators=100)rfc = rfc.fit(Xtrain,ytrain)predict =rfc.predict(Xtest)#将填补好的特征返回到我们的原始的特征矩阵中data.loc[data[i].isnull(),i] = predict
异常值
删除异常值
根据箱线图的标准确定了异常值的边界:
# 计算每列数据的箱线图边界
Q1 = df.quantile(0.25)
Q3 = df.quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR# 删除超出边界的行
df = df[(df >= lower_bound) & (df <= upper_bound)].dropna()使用Z-score,定义了异常值的阈值为均值的两倍标准差:
# 计算每列的均值和标准差
mean = df.mean()
std = df.std()# 定义异常值的阈值(均值的两倍标准差)
threshold = 2# 使用条件过滤删除异常值
df = df[(np.abs((df - mean)/std) < threshold).all(axis=1)] #沿着行的方向进行操作
数据无量纲化
中心化
数据归一化
preprocessing.MinMaxScaler
当数据(x)按照最小值中心化后,再按极差(最大值 - 最小值)缩放,数据移动了最小值个单位,并且会被收敛到[0,1]之间,而这个过程,就叫做数据归一化(Normalization,又称Min-Max Scaling)。注意,Normalization是归一化,不是正则化,真正的正则化是regularization,不是数据预处理的一种手段。归一化之后的数据服从正态分布,公式如下:
from sklearn.preprocessing.MinMaxScalerdata = pd.DataFrame(data)
scaler = MinMaxScaler()
data_1 = scaler.fit_transform(data)# 使用MinMaxScaler的参数feature_range实现将数据归一化到[0,1]以外的范围中
scaler_! = MinMaxScaler(feature_range=[5,10])
data_1 = scaler_1.fit_transform(data)# 使用numpy
X_nor = (X - X.min(axis=0)) / (X.max(axis=0) - X.min(axis=0))
X_nor如果要分训练集和测试集,则对训练集进行fit,即求 min(x) 和 max(x) ,对训练接和测试集进行transform,即二者都使用训练集的 min(x) 和 max(x) 进行归一化。
数据标准化
当数据(x)按均值(μ)中心化后,再按标准差(σ)缩放,数据就会服从为均值为0,方差为1的正态分布(即标准正态分布),而这个过程,就叫做数据标准化(Standardization,又称Z-score normalization),公式如下:
from sklearn.preprocessing import StandarScalerscaler = StandarScaler()
data_1 = scaler.fit_transform(data)scaler.mean_
scaler.var_StandardScaler和MinMaxScaler选哪个?
看情况。大多数机器学习算法中,会选择StandardScaler来进行特征缩放,因为MinMaxScaler对异常值非常敏感。在PCA,聚类,逻辑回归,支持向量机,神经网络这些算法中,StandardScaler往往是最好的选择。MinMaxScaler在不涉及距离度量、梯度、协方差计算以及数据需要被压缩到特定区间时使用广泛,比如数字图像处理中量化像素强度时,都会使用MinMaxScaler将数据压缩于[0,1]区间之中。
建议先试试看StandardScaler,效果不好换MinMaxScaler。
缩放处理
缩放的本质是通过除以一个固定值,将数据固定在某个范围之中,取对数也算是一种缩放处理。
转换数据类型
文本—>数值
preprocessing.LabelEncoder:标签专用,能够将分类转换为分类数值
from sklearn.preprocessing import LabelEncodery = data.iloc[:,-1]
le = LabelEncoder()
le.fit(y)
label = le.transform(y)
data.iloc[:,-1] = label
preprocessing.OrdinalEncoder:特征专用,能够将分类特征转换为分类数值
from sklearn.preprocessing import OrdinalEncoderdata_.iloc[:,1:-1]= ordinalEncoder().fit_transform(data_.iloc[:,1:-1])类别OrdinalEncoder可以用来处理有序变量,但对于名义变量,我们只有使用哑变量的方式来处理,才能够尽量向算法传达最准确的信息:
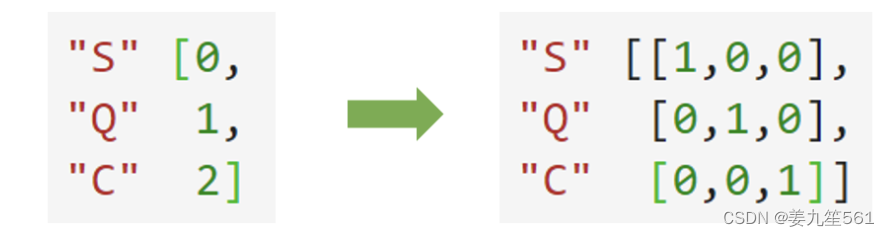
这样的变化,让算法能够彻底领悟,原来三个取值是没有可计算性质的,是“有你就没有我”的不等概念。
因此我们需要使用独热编码,将特征转换为哑变量
preprocessing.OneHotEncoder:独热编码,创建哑变量
from sklearn.preprocessing import OneHotEncoderresult = OneHotEncoder(categories='auto').fit_transform(X).toarray()#axis=1,表示跨行进行合并,也就是将量表左右相连,如果是axis=0,就是将量表上下相连
newdata = pd.concat([data,pd.DataFrame(result)],axis=1)