使用lstm对IMDB的电影评论数据进行情感分析(pytorch代码)
接下来让我们看看如何使用pytorch实现一个基于长短时记忆网络的情感分析模型。在飞桨中,不同深度学习模型的训练过程基本一致,流程如下:
数据处理:选择需要使用的数据,并做好必要的预处理工作。网络定义:使用飞桨定义好网络结构,包括输入层,中间层,输出层,损失函数和优化算法。网络训练:将准备好的训练集数据送入神经网络进行学习,并观察学习的过程是否正常,如损失函数值是否在降低,也可以打印一些中间步骤的结果出来等。网络评估:使用测试集数据测试训练好的神经网络,看看训练效果如何。
import numpy as np
import torch
import pandas as pd
import torch.nn as nn
import torch.nn.functional as F
import re#正则表达式
import string#字符串处理
import seaborn as sns#绘制热力图
from nltk.corpus import stopwords#停用词
from collections import Counter#词频统计
from sklearn.model_selection import train_test_split#数据集划分
from tqdm import tqdm#进度条
import matplotlib.pyplot as plt
from torch.utils.data import TensorDataset, DataLoader
is_cuda=torch.cuda.is_available()
if is_cuda:device=torch.device("cuda")print("GPU is available")
else:device=torch.device("cpu")print("CPU is available")
CPU is available
首先,需要下载语料用于模型训练和评估效果。我们使用的是IMDB的电影评论数据,这个数据集是一个开源的英文数据集,由训练数据和测试数据组成。每个数据都分别由若干小文件组成,每个小文件内部都是一段用户关于某个电影的真实评价,以及观众对这个电影的情感倾向(是正向还是负向)
base_csv=r'E:\kaggle\情感分析\archive (1)\IMDB Dataset.csv'
df=pd.read_csv(base_csv)
df.head()#查看前五行数据
| review | sentiment | |
|---|---|---|
| 0 | One of the other reviewers has mentioned that ... | positive |
| 1 | A wonderful little production. <br /><br />The... | positive |
| 2 | I thought this was a wonderful way to spend ti... | positive |
| 3 | Basically there's a family where a little boy ... | negative |
| 4 | Petter Mattei's "Love in the Time of Money" is... | positive |
X,y=df['review'].values,df['sentiment'].values#数据集划分,review为内容,sentiment为标签
x_train,x_test,y_train,y_test=train_test_split(X,y,stratify=y)#数据集划分,按照y的比例进行划分
print('train size:{},test size:{}'.format(len(x_train),len(x_test)))#查看数据集划分情况
train size:37500,test size:12500
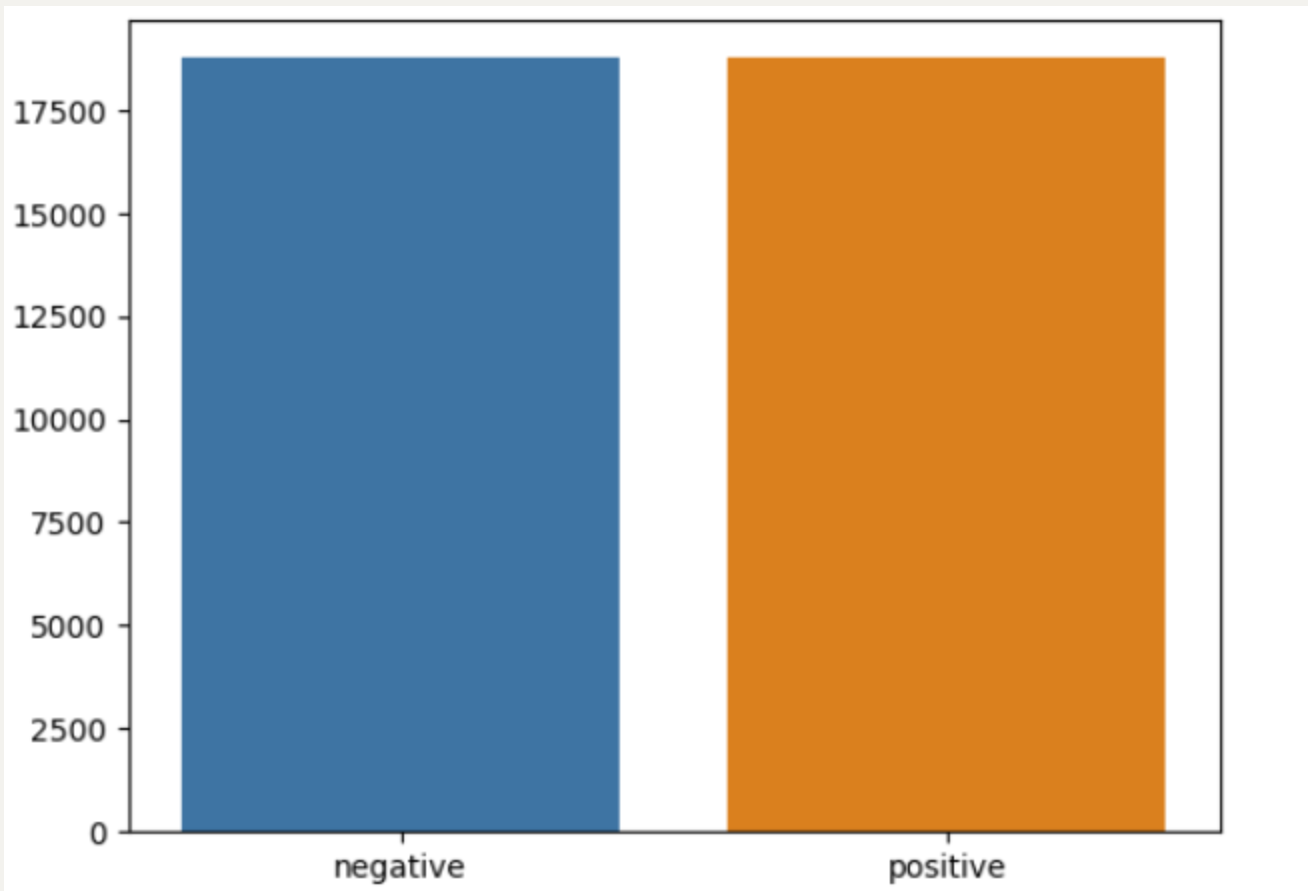
dd = pd.Series(y_train).value_counts()#统计每个类别的数量
sns.barplot(x=np.array(['negative','positive']),y=dd.values)#绘制条形图
plt.show()
def preprocess_string(s):# 删除所有非单词字符(除数字和字母外的所有字符)s = re.sub(r"[^\w\s]", '', s)# 将所有空格替换为无空格s = re.sub(r"\s+", '', s)# 用无空格的数字代替s = re.sub(r"\d", '', s)return s
def tockenize(x_train,y_train,x_val,y_val):word_list=[]#初始化词汇表stop_words=set(stopwords.words('english'))#获取停用词for sent in tqdm(x_train):#遍历训练集for word in sent.lower().split():#遍历单词word=preprocess_string(word)#预处理if word not in stop_words and word !='' and word !=' ':#去除停用词word_list.append(word)#将单词存储在word_list中corpus=Counter(word_list)#统计词频corpus_=sorted(corpus,key=corpus.get,reverse=True)[:1000]#取前1000个词频最高的词,进行排序onehot_dict= {w:i for i,w in enumerate(corpus_)}#建立词到数字的映射{词:数字}的字典final_list_train,final_list_test=[],[]#初始化训练集和测试集for sent in x_train:final_list_train.append([onehot_dict[preprocess_string(word)] for word in sent.lower().split() if preprocess_string(word) in onehot_dict.keys()])'''再次遍历训练集的每个句子,使用 onehot_dict 将句子中的每个单词转换为对应的整数索引,并创建一个标记化列表,同理遍历测试集'''for sent in x_val:final_list_test.append([onehot_dict[preprocess_string(word)] for word in sent.lower().split() if preprocess_string(word) in onehot_dict.keys()])encoded_train=[1 if label =='positive' else 0 for label in y_train]#将标签转换为二进制数字01encoded_test=[1 if label =='positive' else 0 for label in y_val]#将标签转换为二进制数字01return np.array(final_list_train), np.array(encoded_train), np.array(final_list_test), np.array(encoded_test),onehot_dict'''
np.array(final_list_train):训练集的标记化结果,转换为NumPy数组。
np.array(encoded_train):训练集的二进制标签,转换为NumPy数组。
np.array(final_list_test):验证集的标记化结果,转换为NumPy数组。
np.array(encoded_test):验证集的二进制标签,转换为NumPy数组。
onehot_dict:单词到整数索引的映射字典'''
x_train,y_train,x_test,y_test,vocab = tockenize(x_train,y_train,x_test,y_test)#调用tockenize函数进行标记化,vocab为单词到数字的映射字典
print(f'Length of vocabulary is {len(vocab)}')#查看词汇表的长度
# vocab是一个字典
# 获取vocab字典的前50个键值对
first_50_items = list(vocab.items())[:50]# 打印这些键值对
for item in first_50_items:print(item)
Length of vocabulary is 1000
('br', 0)
('movie', 1)
('film', 2)
('one', 3)
('like', 4)
('good', 5)
('even', 6)
('would', 7)
('time', 8)
('really', 9)
('see', 10)
('story', 11)
('much', 12)
('well', 13)
('get', 14)
('great', 15)
('also', 16)
('bad', 17)
('people', 18)
('first', 19)
('dont', 20)
('movies', 21)
('made', 22)
('make', 23)
('films', 24)
('could', 25)
('way', 26)
('characters', 27)
('think', 28)
('watch', 29)
('many', 30)
('two', 31)
('seen', 32)
('character', 33)
('never', 34)
('love', 35)
('acting', 36)
('best', 37)
('plot', 38)
('little', 39)
('know', 40)
('show', 41)
('ever', 42)
('life', 43)
('better', 44)
('still', 45)
('say', 46)
('end', 47)
('scene', 48)
('man', 49)
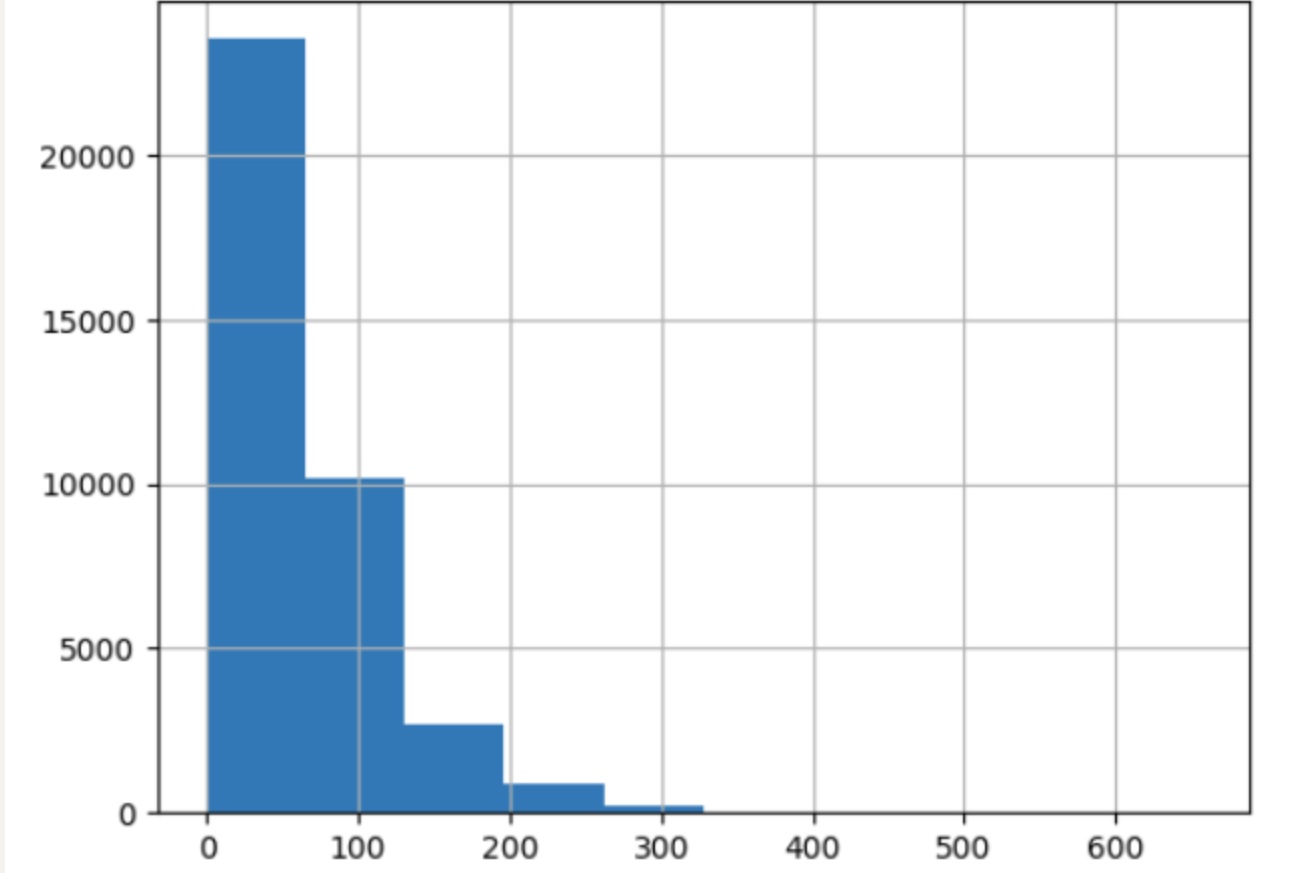
rev_lem=[len(i) for i in x_train]
pd.Series(rev_lem).hist()#绘制直方图
plt.show()
pd.Series(rev_lem).describe()#查看数据的基本统计信息
count 37500.000000
mean 69.056053
std 47.877645
min 0.000000
25% 39.000000
50% 54.000000
75% 84.000000
max 655.000000
dtype: float64
def padding_(sentences,seq_len):#senences为句子列表,seq_len为句子的最大长度features=np.zeros((len(sentences),seq_len),dtype=int)#初始化一个形状为(len(sentences),seq_len)的全零矩阵for ii,review in enumerate(sentences):#遍历句子列表if len(review) != 0:features[ii, -len(review):] = np.array(review)[:seq_len]#将句子的前seq_len个词的索引存储在矩阵中,不足的部分用零填充return features#返回填充后的矩阵
# 长度大于 500 的评论数量很少。
# 因此,我们将只考虑低于它的部分。
x_train_pad = padding_(x_train,500)
x_test_pad = padding_(x_test,500)
batch_size=50#设置批处理大小为50train_data=TensorDataset(torch.from_numpy( x_train_pad), torch.from_numpy(np.array(y_train)))#将训练集的数据和标签转换为张量
train_loader=DataLoader(train_data,batch_size,shuffle=True)#将训练集的数据和标签转换为数据加载器valid_data=TensorDataset(torch.from_numpy( x_test_pad), torch.from_numpy(np.array(y_test)))#将测试集的数据和标签转换为张量
valid_loader=DataLoader(test_data,batch_size,shuffle=True)#将测试集的数据和标签转换为数据加载器
# 查看一个batch的数据
dataiter = iter(train_loader)#创建一个迭代器来遍历数据加载器
sample_x, sample_y = next(dataiter)#获取一个批次的数据和标签print('Sample input size: ', sample_x.size()) # 打印样本输入的尺寸
print('Sample input: \n', sample_x)# 打印样本输入
print('Sample input: \n', sample_y)# 打印样本标签
Sample input size: torch.Size([50, 500])
Sample input: tensor([[ 0, 0, 0, ..., 194, 565, 672],[ 0, 0, 0, ..., 12, 26, 22],[ 0, 0, 0, ..., 438, 1, 795],...,[ 0, 0, 0, ..., 215, 4, 427],[ 0, 0, 0, ..., 917, 61, 194],[ 0, 0, 0, ..., 272, 647, 3]], dtype=torch.int32)
Sample input: tensor([1, 1, 0, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 0, 1,1, 0, 1, 0, 0, 0, 0, 1, 1, 1, 0, 0, 1, 0, 1, 1, 1, 1, 0, 1, 0, 1, 1, 0,0, 0], dtype=torch.int32)
class SentimentRNN(nn.Module):def __init__(self, no_layers, vocab_size, hidden_dim, embedding_dim, output_dim, drop_prob=0.5):'''no_layers为隐藏层数,vocab_size为词汇表的大小,hidden_dim为隐藏层的维度,embedding_dim为词嵌入的维度,output_dim为输出层的维度,drop_prob为dropout的概率。'''super(SentimentRNN, self).__init__()self.no_layers = no_layersself.hidden_dim = hidden_dimself.vocab_size = vocab_sizeself.output_dim = output_dimself.embedding = nn.Embedding(self.vocab_size, embedding_dim)#词嵌入层,输入为词汇表的大小和嵌入的维度# LSTM的第一层输入为嵌入的维度和隐藏层的维度self.lstm = nn.LSTM(input_size=embedding_dim, hidden_size=self.hidden_dim,num_layers=no_layers, batch_first=True)self.dropout = nn.Dropout(drop_prob) # dropout层,作用是随机将一些神经元的输出改为0,防止过拟合self.fc = nn.Linear(self.hidden_dim, output_dim)#全连接层,输入为隐藏层的维度和输出层的维度self.sig = nn.Sigmoid()#sigmoid层,作用为将输出值转换为0到1之间的概率值def forward(self, x, hidden):#x为输入张量,hidden为隐藏层的初始状态batch_size = x.size(0)#获取批处理大小embeds = self.embedding(x) # 词嵌入层的输出,输入为词汇表的索引和嵌入的维度lstm_out, hidden = self.lstm(embeds, hidden) lstm_out = lstm_out.contiguous().view(-1, self.hidden_dim)#contiguous的作用是将张量的内存连续存储,以便更快地访问它的元素。view的作用是将张量的形状改变为(batch_size * seq_len, hidden_dim)。out = self.dropout(lstm_out) out = self.fc(out)sig_out = self.sig(out)sig_out = sig_out.view(batch_size, -1)sig_out = sig_out[:, -1] # 获取最后一个标签# 返回最后的sigmoid输出和hidden状态return sig_out, hiddendef init_hidden(self, batch_size):''' 初始化隐藏层状态'''device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 确定设备# 新建两个张量,大小为 no_layers , batch_size , hidden_dim# 初始化为零,表示 LSTM 的隐藏状态和单元状态h0 = torch.zeros((self.no_layers, batch_size, self.hidden_dim)).to(device)c0 = torch.zeros((self.no_layers, batch_size, self.hidden_dim)).to(device)hidden = (h0, c0)#将隐藏状态和单元状态作为元组返回return hidden
词嵌入层(Embedding Layer)是神经网络中用于将词汇映射到高维空间的一层,这个高维空间中的每个维度都被称为一个特征。在自然语言处理(NLP)中,词嵌入层是将单词或词汇映射到连续的向量表示的关键组件,这些向量表示能够捕捉单词的语义信息和上下文关系。
词嵌入层的工作原理如下:
-
词汇索引(Indexing):首先,每个单词或词汇在词汇表中被分配一个唯一的索引。
-
权重矩阵(Weight Matrix):词嵌入层包含一个权重矩阵,其行数等于词汇表的大小,列数等于嵌入的维度(例如,300或100)。权重矩阵的每一行可以看作是对应单词的嵌入向量。
-
查找嵌入(Lookup):当输入数据(如文本序列中的单词索引)传递到词嵌入层时,层通过查找权重矩阵中与输入索引对应的行来获取每个单词的嵌入向量。
-
输出:词嵌入层的输出是一个矩阵,其中每行是一个单词的嵌入向量,列数与嵌入维度相同。
词嵌入层的关键优势在于:
-
密集向量表示:它们提供了一种将单词转换为密集向量(而非传统的one-hot编码)的方法,这使得模型能够捕捉单词之间的相似性。
-
语义信息:嵌入向量能够捕捉单词的语义信息,相似的单词在向量空间中距离较近。
-
降维:尽管嵌入层可以有很高的维度,但它通常比原始的词汇空间要小,这有助于减少模型的参数数量并提高效率。
-
预训练嵌入:词嵌入可以是随机初始化的,也可以使用大量文本数据预训练得到。预训练的嵌入(如Word2Vec、GloVe)已经在捕捉语言的语义和语法特性方面表现出色。
在PyTorch中,词嵌入层由nn.Embedding类实现,它接受输入的索引并返回对应的嵌入向量。这在处理文本数据时非常有用,尤其是在构建RNN、LSTM或Transformer等模型时。
no_layer=2#隐藏层数
vocab_size=len(vocab)+1#词汇表的大小
embedding_dim=64#词嵌入的维度
output_dim=1#输出层的维度
hidden_dim=256#隐藏层的维度
model=SentimentRNN(no_layer,vocab_size,hidden_dim,embedding_dim,output_dim,drop_prob=0.5)
model.to(device)
print(model)
SentimentRNN((embedding): Embedding(1001, 64)(lstm): LSTM(64, 256, num_layers=2, batch_first=True)(dropout): Dropout(p=0.5, inplace=False)(fc): Linear(in_features=256, out_features=1, bias=True)(sig): Sigmoid()
)
lr=0.001
criterion=nn.BCELoss()#定义损失函数为二元交叉熵损失函数
optimizer=torch.optim.Adam(model.parameters(),lr=lr)#定义优化器为Adam优化器,学习率为lr
def acc(pred,label):pred=torch.round(pred.squeeze())#将输出值转换为0和1之间的整数,round函数的作用是将张量的元素四舍五入到最接近的整数,squeeze函数的作用是将张量的维度为1的维度去掉return torch.sum(pred == label.squeeze()).item()#计算预测正确的数量,torch.sum函数的作用是计算张量的和,item函数的作用是将张量的元素转换为标量值
clip=5 #定义梯度裁剪的阈值,防止梯度爆炸
epochs=5
valid_loss_min=np.Inf#初始化验证损失最小值为正无穷大
epoch_tr_loss,epoch_vl_loss=[],[]#初始化训练损失和验证损失列表
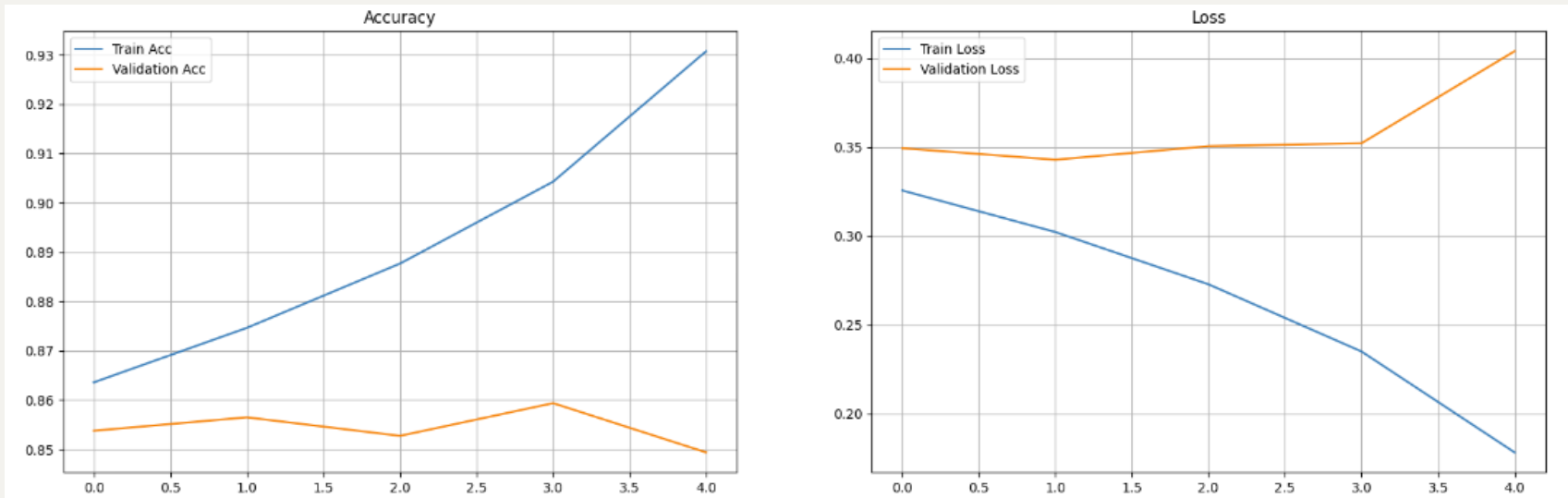
epoch_tr_acc,epoch_vl_acc=[],[]for epoch in range(epochs):train_losses=[]train_acc=0.0model.train()#设置模型为训练模式h=model.init_hidden(batch_size)#初始化隐藏层状态for inputs,labels in train_loader:inputs,labels=inputs.to(device),labels.to(device)#将输入和标签转换为设备上的张量h=tuple([each.data for each in h])#将隐藏层状态转换为元组,tuple作用是将列表转换为元组model.zero_grad()#清空梯度缓存output,h=model(inputs,h)#将输入和隐藏层状态传递给模型,获取输出和隐藏层状态loss = criterion(output.squeeze(), labels.float())#计算损失loss.backward()train_losses.append(loss.item())#将损失添加到训练损失列表accuracy=acc(output,labels)#计算准确率train_acc+=accuracy#将准确率添加到训练准确率列表# clip_grad_norm:有助于防止 RNN / LSTM 中出现梯度爆炸问题。nn.utils.clip_grad_norm_(model.parameters(), clip)optimizer.step()#更新模型参数#同理,计算验证损失和准确率 val_h = model.init_hidden(batch_size)val_losses = []val_acc = 0.0model.eval()#设置模型为评估模式for inputs, labels in valid_loader:val_h = tuple([each.data for each in val_h])inputs, labels = inputs.to(device), labels.to(device)output, val_h = model(inputs, val_h)val_loss = criterion(output.squeeze(), labels.float())val_losses.append(val_loss.item())accuracy = acc(output,labels)val_acc += accuracyepoch_train_loss = np.mean(train_losses)#计算平均训练损失epoch_val_loss = np.mean(val_losses)epoch_train_acc = train_acc/len(train_loader.dataset)#计算平均训练准确率epoch_val_acc = val_acc/len(valid_loader.dataset)epoch_tr_loss.append(epoch_train_loss)#将平均训练损失添加到训练损失列表epoch_vl_loss.append(epoch_val_loss)epoch_tr_acc.append(epoch_train_acc)#将平均训练准确率添加到训练准确率列表epoch_vl_acc.append(epoch_val_acc)print(f'Epoch {epoch+1}') print(f'train_loss : {epoch_train_loss} val_loss : {epoch_val_loss}')print(f'train_accuracy : {epoch_train_acc*100} val_accuracy : {epoch_val_acc*100}')if epoch_val_loss <= valid_loss_min:#如果验证损失小于等于最小验证损失,则保存模型torch.save(model.state_dict(), 'E:/jupyter notebook/run/state_dict.pt')print('Validation loss decreased ({:.6f} --> {:.6f}). Saving model ...'.format(valid_loss_min,epoch_val_loss))#输出验证损失下降的信息valid_loss_min = epoch_val_loss#更新最小验证损失print(25*'==')#输出分隔符
Epoch 1
train_loss : 0.3256393209497134 val_loss : 0.3494153782129288
train_accuracy : 86.35733333333333 val_accuracy : 85.37599999999999
Validation loss decreased (inf --> 0.349415). Saving model ...
==================================================Epoch 2
train_loss : 0.30226381081342696 val_loss : 0.3429294221699238
train_accuracy : 87.464 val_accuracy : 85.648
Validation loss decreased (0.349415 --> 0.342929). Saving model ...
==================================================Epoch 3
train_loss : 0.2728519992530346 val_loss : 0.35708637237549
train_accuracy : 88.768 val_accuracy : 85.272
==================================================Epoch 4
train_loss : 0.23305975874265 val_loss : 0.3521884876191616
train_accuracy : 90.42933333333333 val_accuracy : 85.9365
Epoch 5
train_loss : 0.17824131296577 val_loss : 0.40401120299100873
train_accuracy : 93.07733333333333 val_accuracy : 84.936
==================================================
fig = plt.figure(figsize = (20, 6))
plt.subplot(1, 2, 1)
plt.plot(epoch_tr_acc, label='Train Acc')
plt.plot(epoch_vl_acc, label='Validation Acc')
plt.title("Accuracy")
plt.legend()
plt.grid()plt.subplot(1, 2, 2)
plt.plot(epoch_tr_loss, label='Train Loss')
plt.plot(epoch_vl_loss, label='Validation Loss')
plt.title("Loss")
plt.legend()
plt.grid()plt.show()
def predict_text(text):#定义预测函数word_seq = np.array([vocab[preprocess_string(word)] for word in text.split() if preprocess_string(word) in vocab.keys()])#将文本转换为单词序列'''
text.split():这个函数调用将输入的文本字符串 text 按照空格分割成单词列表。if preprocess_string(word) in vocab.keys():这是一个条件表达式,用于检查处理后的单词是否存在于 vocab 字典的键中。vocab 是一个预定义的词汇表,通常包含了数据集中所有不重复单词与它们对应整数索引的映射。preprocess_string(word) 是一个对单词进行预处理的函数,可能包括转换为小写、去除标点等操作。[vocab[preprocess_string(word)] for word in text.split() if preprocess_string(word) in vocab.keys()]:这是一个列表推导式,它遍历 text.split() 生成的每个单词,对每个单词运行 preprocess_string 函数,然后检查预处理后的单词是否存在于 vocab 的键中。如果存在,它将使用 vocab 字典获取该单词对应的数值索引。np.array(...):最后,将列表推导式生成的数值索引列表转换为一个NumPy数组。'''word_seq = np.expand_dims(word_seq,axis=0) #将单词序列扩展为二维数组pad = torch.from_numpy(padding_(word_seq,500))#from_numpy()函数将 NumPy 数组转换为 PyTorch 张量。padding_()函数用于对输入的单词序列进行填充,以便其长度不超过 500。padding_()函数返回填充后的单词序列。inputs = pad.to(device)#将填充后的单词序列转换为 PyTorch 张量并将其移动到设备上batch_size = 1h = model.init_hidden(batch_size)h = tuple([each.data for each in h])#tuple()函数用于将列表转换为元组output, h = model(inputs, h)return(output.item())
# 取出两个例子测试预测结果
index = 30#设置索引
print(df['review'][index])#打印第 index 个评论
print('='*70)
print(f'Actual sentiment is : {df["sentiment"][index]}')#打印第 index 个评论的实际情感
print('='*70)
pro = predict_text(df['review'][index])#预测第 index 个评论的情感
status = "positive" if pro > 0.5 else "negative"
pro = (1 - pro) if status == "negative" else pro#将预测的概率值转换为 0 到 1 之间的数值
print(f'Predicted sentiment is {status} with a probability of {pro}')
Taut and organically gripping, Edward Dmytryk's Crossfire is a distinctive suspense thriller, an unlikely "message" movie using the look and devices of the noir cycle.<br /><br />Bivouacked in Washington, DC, a company of soldiers cope with their restlessness by hanging out in bars. Three of them end up at a stranger's apartment where Robert Ryan, drunk and belligerent, beats their host (Sam Levene) to death because he happens to be Jewish. Police detective Robert Young investigates with the help of Robert Mitchum, who's assigned to Ryan's outfit. Suspicion falls on the second of the three (George Cooper), who has vanished. Ryan slays the third buddy (Steve Brodie) to insure his silence before Young closes in.<br /><br />Abetted by a superior script by John Paxton, Dmytryk draws precise performances from his three starring Bobs. Ryan, naturally, does his prototypical Angry White Male (and to the hilt), while Mitchum underplays with his characteristic alert nonchalance (his role, however, is not central); Young may never have been better. Gloria Grahame gives her first fully-fledged rendition of the smart-mouthed, vulnerable tramp, and, as a sad sack who's leeched into her life, Paul Kelly haunts us in a small, peripheral role that he makes memorable.<br /><br />The politically engaged Dmytryk perhaps inevitably succumbs to sermonizing, but it's pretty much confined to Young's reminiscence of how his Irish grandfather died at the hands of bigots a century earlier (thus, incidentally, stretching chronology to the limit). At least there's no attempt to render an explanation, however glib, of why Ryan hates Jews (and hillbillies and...).<br /><br />Curiously, Crossfire survives even the major change wrought upon it -- the novel it's based on (Richard Brooks' The Brick Foxhole) dealt with a gay-bashing murder. But homosexuality in 1947 was still Beyond The Pale. News of the Holocaust had, however, begun to emerge from the ashes of Europe, so Hollywood felt emboldened to register its protest against anti-Semitism (the studios always quaked at the prospect of offending any potential ticket buyer).<br /><br />But while the change from homophobia to anti-Semitism works in general, the specifics don't fit so smoothly. The victim's chatting up a lonesome, drunk young soldier then inviting him back home looks odd, even though (or especially since) there's a girlfriend in tow. It raises the question whether this scenario was retained inadvertently or left in as a discreet tip-off to the original engine generating Ryan's murderous rage.
======================================================================
Actual sentiment is : positive
======================================================================
1
Predicted sentiment is positive with a probability of 0.8768146634101868
index = 32
print(df['review'][index])
print('='*70)
print(f'Actual sentiment is : {df["sentiment"][index]}')
print('='*70)
pro = predict_text(df['review'][index])
status = "positive" if pro > 0.5 else "negative"
pro = (1 - pro) if status == "negative" else pro
print(f'predicted sentiment is {status} with a probability of {pro}')
My first exposure to the Templarios & not a good one. I was excited to find this title among the offerings from Anchor Bay Video, which has brought us other cult classics such as "Spider Baby". The print quality is excellent, but this alone can't hide the fact that the film is deadly dull. There's a thrilling opening sequence in which the villagers exact a terrible revenge on the Templars (& set the whole thing in motion), but everything else in the movie is slow, ponderous &, ultimately, unfulfilling. Adding insult to injury: the movie was dubbed, not subtitled, as promised on the video jacket.
======================================================================
Actual sentiment is : negative
======================================================================
1
predicted sentiment is negative with a probability of 0.9996319290075917
the film is deadly dull. There’s a thrilling opening sequence in which the villagers exact a terrible revenge on the Templars (& set the whole thing in motion), but everything else in the movie is slow, ponderous &, ultimately, unfulfilling. Adding insult to injury: the movie was dubbed, not subtitled, as promised on the video jacket.
======================================================================
Actual sentiment is : negative
======================================================================
1
predicted sentiment is negative with a probability of 0.9996319290075917
参考:https://www.kaggle.com/code/kako523/lstm-pytorch/notebook