🐶博主主页:@ᰔᩚ. 一怀明月ꦿ
❤️🔥专栏系列:线性代数,C初学者入门训练,题解C,C的使用文章,「初学」C++,linux
🔥座右铭:“不要等到什么都没有了,才下定决心去做”
🚀🚀🚀大家觉不错的话,就恳求大家点点关注,点点小爱心,指点指点🚀🚀🚀
目录
共享内存
共享内存的特点:
rm和unlink的区别
源码
comm.h
server.cc
client.cc
Makefile
共享内存的字段
消息队列 (了解)
创建消息队列
发送数据
接收数据
删除消息队列
消息队列的字段
信号量
创建信号量集:
信号量的控制
共享内存
shmat返回的是共享内存的起始地址
共享内存的特点:
1.共享内存的通信方式,并没有同步机制
2.共享内存是所有进程间通信,速度最快的
例如:
管道文件通信:需要把数据写到字符串中然后写入文件,读的时候,是从文件读到字符串中
共享内存通信:直接把数据写到共享内存中,读的时候,直接从共享内存中读
3.共享内存可以提供较大的空间
rm和unlink的区别
在Linux中,rm和unlink都是用于删除文件的命令和函数,它们有以下区别:
1. 命令与函数:rm是一个命令,用于在终端上执行删除文件的操作;unlink是一个系统调用函数,用于在程序中删除文件。
2. 功能:rm命令可以删除指定的文件或目录,包括其中的所有内容。它还支持删除多个文件和使用递归选项来删除目录及其内容。unlink函数仅用于删除一个文件的目录项,即删除文件的硬链接。
3. 使用方式:rm命令的基本语法如下:
rm [选项] 文件...
unlink函数的基本语法如下:
int unlink(const char *pathname);
4. 错误处理:rm命令会在删除文件时给出警告或错误信息,例如询问是否删除只读文件、权限不足等。unlink函数在删除文件失败时返回-1,并将错误码存储在errno变量中,可以使用perror或其他错误处理机制来处理错误。
总的来说,rm命令更方便用于终端上删除文件和目录,而unlink函数更适用于在程序中删除文件的目录项。
源码
comm.h
#pragma once #include <iostream> #include <string> #include <sys/types.h> #include <sys/ipc.h> #include <sys/stat.h> #include<cstring> #include<sys/shm.h>#define FILENAME ".fifo" // 隐藏文件using namespace std;const string pathname = "/home/BCH/1_27/shm"; // 路径给的是当前工作路径const int proj_id = 0x11223344; // 随便设的一个数字// 共享内存的大小,建议设置成为n*4096,因为底层分配shm大小的时候,是以4096的为基数倍增的 const int size = 4096;// 创建key值key_t getkey(){key_t key = ftok(pathname.c_str(), proj_id);if (key < 0){cerr << "error: " << errno << "errstring :" << strerror(errno) << endl;exit(1);}return key; }string tohex(int id){char buffer[1024];snprintf(buffer, sizeof(buffer), "0x%x", id);return buffer; }int createshmHelper(key_t key, int flag){int shmid = shmget(key, size, flag);if (shmid < 0){cerr << "error: " << errno << "errstring :" << strerror(errno) << endl;return -1;}return shmid; }// 是给用户端使用的 int createshm(key_t key){return createshmHelper(key, IPC_CREAT | IPC_EXCL | 0666); }// 是给客户端使用的 int getshm(key_t key){return createshmHelper(key, IPC_CREAT); }bool Mkfifo(){int n = mkfifo(FILENAME, 0666);if (n < 0){cerr << "error: " << errno << "errstring :" << strerror(errno) << endl;return false;}return true; }server.cc
#include <iostream> #include <sys/ipc.h> #include <sys/shm.h> #include <sys/types.h> #include <cstring> #include <unistd.h> #include <sys/stat.h> #include <fcntl.h> #include "comm.hpp"using namespace std;class Init{ public:Init(){// 创建命名管道bool r = Mkfifo();if (!r)return; // 创建不成功就返回key_t key = getkey();cout << "key :" << tohex(key) << endl;// key:不要在应用层使用,只用来在内核标志shm的唯一性(类似fd)// shmid:应用这个共享内存的时候,我们使用shmid来进行操作共享内存(类似FILE*)// 创建在内存shmcout << "创建shm成功" << endl;shmid = createshm(key);cout << "shmid :" << shmid << endl;// 挂接虚拟地址cout << "开始将shm映射到进程虚拟地址空间中" << endl;s = (char *)shmat(shmid, nullptr, 0); // 设置为nullptr,是让os从共享区找一块连续空间rfd = open(FILENAME, O_RDONLY);}~Init(){// 取消挂接虚拟地址cout << "开始将shm从进程的地址空间移除" << endl;shmdt(s);// 控制shm// 1.删除shmcout << "开始将shm从os中删除" << endl;shmctl(shmid, IPC_RMID, nullptr);close(rfd);// unlink删除管道文件unlink(FILENAME);}int shmid;int rfd;char *s; };int main(){Init init;while (true){// wait// 因为共享内存做不到同步机制,但是我们可以借助命名管道实现机制,来实现共享内存的同步机制// 我们可以创建一个管道,让服务端先读管道里的东西,然后再读共享内存里的东西,如果客户端// 没有在管道里写东西,则服务端就一直等客户端在管道里写东西,不然不会读取共享内存里的东西int code = 0;ssize_t n = read(init.rfd, &code, sizeof(code));if (n > 0){// 直接读取内容cout << "s: " << init.s << endl;sleep(1);}else if (n == 0){break;}}return 0; }client.cc
#include <iostream> #include <sys/ipc.h> #include <sys/shm.h> #include <sys/types.h> #include <cstring> #include <unistd.h> #include <sys/stat.h>#include <fcntl.h> #include "comm.hpp"using namespace std;int main(){// 创建key值key_t key = getkey();int shmid = getshm(key);// 挂接shmchar *s = (char *)shmat(shmid, nullptr, 0);int wfd = open(FILENAME, O_WRONLY);char c = 'a';for (; c <= 'z'; c++){s[c - 'a'] = c;cout << "write: " << c << "done" << endl;sleep(1);int code = 1;write(wfd, &code, sizeof(code));}// 取消挂接shmdt(s);close(wfd);return 0; }Makefile
.PHONY:all all:client serverclient:client.cc g++ -o $@ $^ -std=c++11server:server.cc g++ -o $@ $^ -std=c++11.PHONY:clean clean: rm -f client server在 Linux 中,unlink 是一个系统调用,它允许用户空间程序删除文件的目录项(directory entry),从而减少文件的链接计数。这个系统调用的原型通常可以在 unistd.h 头文件中找到。同时,C 语言标准库也提供了一个与系统调用对应的函数 unlink,它是通过对系统调用的封装来实现的。通过调用这个库函数,程序可以方便地使用 unlink 系统调用来删除文件。因此,unlink 在 Linux 中既是一个系统调用,也是一个 C 标准库函数。
共享内存的字段
内核源码:The buf argument is a pointer to a shmid_ds structure, defined in <sys/shm.h> as follows:struct shmid_ds {struct ipc_perm shm_perm; /* Ownership and permissions */size_t shm_segsz; /* Size of segment (bytes) */time_t shm_atime; /* Last attach time */time_t shm_dtime; /* Last detach time */time_t shm_ctime; /* Last change time */pid_t shm_cpid; /* PID of creator */pid_t shm_lpid; /* PID of last shmat(2)/shmdt(2) */shmatt_t shm_nattch; /* No. of current attaches */...};The ipc_perm structure is defined as follows (the highlighted fields are settable using IPC_SET):struct ipc_perm {key_t __key; /* Key supplied to shmget(2) */uid_t uid; /* Effective UID of owner */gid_t gid; /* Effective GID of owner */uid_t cuid; /* Effective UID of creator */gid_t cgid; /* Effective GID of creator */unsigned short mode; /* Permissions + SHM_DEST andSHM_LOCKED flags */unsigned short __seq; /* Sequence number */};注释: struct ipc_perm shm_perm; // 共享内存段的权限信息 size_t shm_segsz; // 共享内存段的大小(字节数) time_t shm_atime; // 上次访问共享内存段的时间 time_t shm_dtime; // 上次与共享内存段断开连接的时间 time_t shm_ctime; // 上次更改共享内存段属性的时间 pid_t shm_cpid; // 创建共享内存段的进程ID pid_t shm_lpid; // 最后操作共享内存段的进程ID unsigned short shm_nattch; // 当前连接到共享内存段的进程数 unsigned short shm_unused; // 保留字段,未使用struct ipc_perm {key_t __key; // 对象的键值uid_t uid; // 拥有者的用户IDgid_t gid; // 拥有者的组IDuid_t cuid; // 创建者的用户IDgid_t cgid; // 创建者的组IDunsigned short mode; // 访问权限和标志unsigned short __seq; // 序列号 };共享内存=共享内存空间+属性
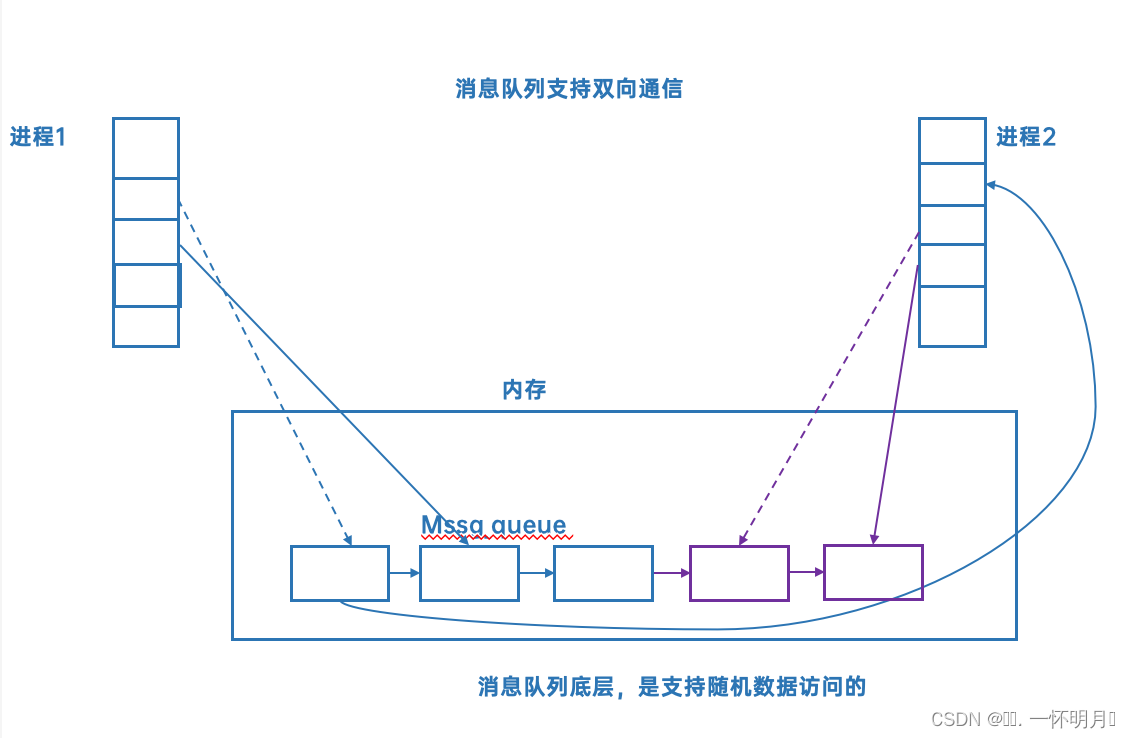
消息队列 (了解)
一个进程给另一个进程发送数据块
创建消息队列,也需要key(标识符),和创建共享内存的key一样
注意:管道是一种单向通信的方式,创建两个管道,从而实现双向通信的效果。而共享内存和消息队列等可以实现双向通信
虽然两个进程都可以把数据放在同一个消息队列里面,但肯定每一个进程放的数据是有自己的标识的,所以一定能够分清楚队列里面的数据是谁的
创建消息队列
int msgget(key_t key, int msgflg);//msgfla标志位,和shmget类似发送数据
int msgsnd(int msqid, const void *msgp, size_t msgsz, int msgflg); 各个参数的含义如下:* msqid:消息队列的标识符,是由 msgget 调用返回的消息队列标识符。 * msgp:指向消息数据的指针,通常是一个自定义的结构体指针,用于存储要发送的消息内容。 * msgsz:消息的大小,以字节为单位。 * msgflg:用于指定发送消息的选项,常用的选项包括 0 或 IPC_NOWAIT,表示发送操作的阻塞或非阻塞方式。接收数据
ssize_t msgrcv(int msqid, void *msgp, size_t msgsz, long msgtyp, int msgflg);//就是消息的 各个参数的含义如下: * msqid:消息队列的标识符,是由 msgget 调用返回的消息队列标识符。 * msgp:指向接收消息数据的缓冲区指针,通常是一个自定义的结构体指针,用于存储接收到的消息内容。 * msgsz:缓冲区的大小,以字节为单位,用于指定可以接收的消息的最大大小。 * msgtyp:用于选择接收哪种类型的消息,如果为 0,则表示接收队列中的第一条消息;如果大于 0,则表示接收类型字段与 msgtyp相匹配的第一条消息;如果小于 0,则表示接收类型字段小于或等于 msgtyp 绝对值的第一条消息。 * msgflg:用于指定接收消息的选项,常用的选项包括 0 或 IPC_NOWAIT,表示接收操作的阻塞或非阻塞方式。删除消息队列
int msgctl(int msqid, int cmd, struct msqid_ds *buf);//和shmctl消息队列,系统中可不可以同时存在多个消息队列?可以
消息队列也要在内核中,把它管理起来,如何管理呢?现描述,再组织
消息队列=队列+队列属性
消息队列的字段
The msqid_ds data structure is defined in <sys/msg.h> as follows:struct msqid_ds {struct ipc_perm msg_perm; /* Ownership and permissions */time_t msg_stime; /* Time of last msgsnd(2) */time_t msg_rtime; /* Time of last msgrcv(2) */time_t msg_ctime; /* Time of last change */unsigned long __msg_cbytes; /* Current number of bytes inqueue (nonstandard) */msgqnum_t msg_qnum; /* Current number of messagesin queue */msglen_t msg_qbytes; /* Maximum number of bytesallowed in queue */pid_t msg_lspid; /* PID of last msgsnd(2) */pid_t msg_lrpid; /* PID of last msgrcv(2) */};The ipc_perm structure is defined as follows (the highlighted fields are settable using IPC_SET):struct ipc_perm {key_t __key; /* Key supplied to msgget(2) */uid_t uid; /* Effective UID of owner */gid_t gid; /* Effective GID of owner */uid_t cuid; /* Effective UID of creator */gid_t cgid; /* Effective GID of creator */unsigned short mode; /* Permissions */unsigned short __seq; /* Sequence number */};
信号量
信号量本质:就是一个计数器,保护共享资源(信号量是一种用于进程间同步和互斥的系统资)
信号量一次可以创建多个,类似于数组的形式
semaphore:信号量
创建信号量集:
在 Linux 中,semget 函数用于创建一个新的信号量集或获取一个已存在的信号量集的标识符。下面是 semget 函数的函数原型:
#include <sys/types.h> #include <sys/ipc.h> #include <sys/sem.h>int semget(key_t key, int nsems, int semflg); 各个参数的含义如下: * key:用于标识信号量集的键值。可以使用 ftok 函数生成一个唯一的键值。 * nsems:指定需要创建或获取的信号量集中的信号量数量。 * semflg:用于指定信号量的权限和选项,常用的选项包括 IPC_CREAT(如果不存在则创建)和 IPC_EXCL(与 IPC_CREAT 一起使用,确保只创建新的信号量集)等。 调用 semget 函数后,它会返回一个信号量集的标识符,用于后续对该信号量集进行操作,比如通过 semop 执行 P/V 操作。需要注意的是,如果是创建新的信号量集,需要指定 IPC_CREAT 标志和合适的权限位,例如 0666。如果是获取已存在的信号量集,只需要提供相应的键值即可。
信号量的控制
在 Linux 中,semctl 函数用于对信号量集进行控制操作,比如获取或设置信号量的值、删除信号量集等。
下面是 semctl 函数的函数原型:
#include <sys/types.h> #include <sys/ipc.h> #include <sys/sem.h> int semctl(int semid, int semnum, int cmd, …);//因为创建信号量是创建的信号量集,semnum的值(首个信号量是0)就是信号量集其中一个信号量 各个参数的含义如下: * semid:要操作的信号量集的标识符。 * semnum:指定要操作的具体信号量的索引。对于整个信号量集的操作,可以指定为 0。 * cmd:指定要执行的操作命令,可以是以下之一:* GETVAL:获取指定信号量的值。* SETVAL:设置指定信号量的值。* IPC_RMID:删除信号量集。 在使用 semctl 函数时,具体的操作和参数会根据 cmd 的不同而有所变化。例如,当 cmd 为 GETVAL 时,需要提供一个 union semun 类型的第四个参数,用于接收信号量的值。当 cmd 为 SETVAL 时,需要提供一个 union semun 类型的第四个参数,用于设置信号量的值。
内核是如何看待IPC资源的!
1.他是单独设计的模块
2.理清楚ipc资源再内核中维护的方式
在内核底层,都是通过共享内存、消息队列、信号量继承ipc资源
🌸🌸🌸如果大家还有不懂或者建议都可以发在评论区,我们共同探讨,共同学习,共同进步。谢谢大家! 🌸🌸🌸