最近学习了快速排序,鼠鼠俺来做笔记了!
本篇博客用排升序为例介绍快速排序!
1.快速排序
快速排序是Hoare于1962年提出的一种二叉树结构的交换排序方法,其基本思想为:任取待排序元素序列中的某元素作为基准值,按照该排序码将待排序集合分割成两子序列,左子序列中所有元素均小于基准值,右子序列中所有元素均大于基准值,然后最左右子序列重复该过程,直到所有元素都排列在相应位置上为止。
如果对上面的介绍蒙圈的话,没关系,我们继续看下面的内容,会仔细介绍的!
1.1.快速排序的”单趟“
快速排序的”单趟“简单来说就是在需排序乱序数组中任取一个元素作为基准值,经过”单趟“过后,大于或者等于基准值的元素都排在基准值的后面,小于或者等于基准值的元素都排在基准值的前面,也就是说基准值所在的位置就是它应该出现的位置,这个基准值就排好了!
对于”单趟“的实现方法有但不限于下面三种:
1.1.1.hoare版本
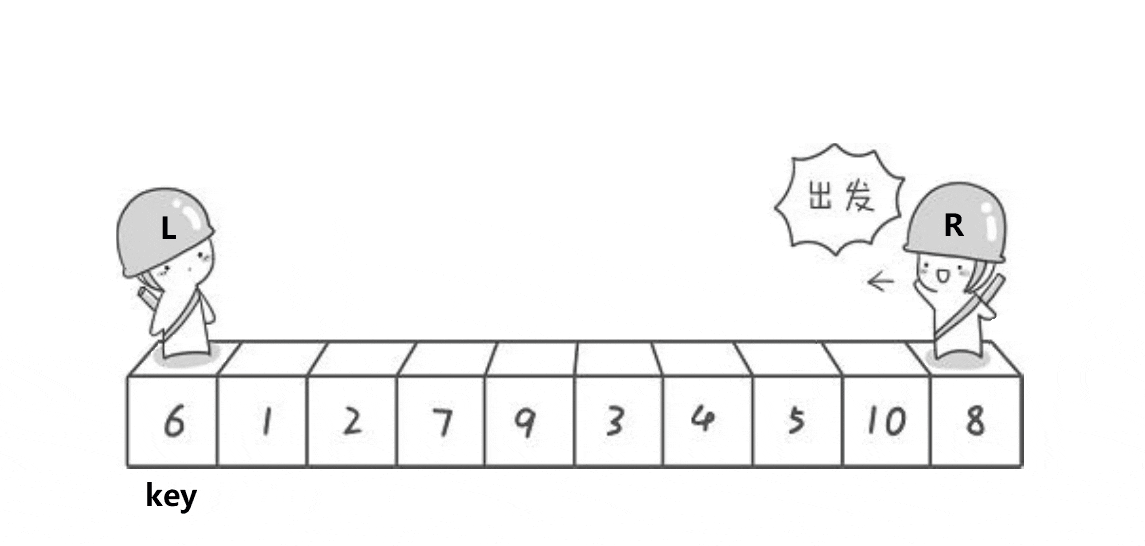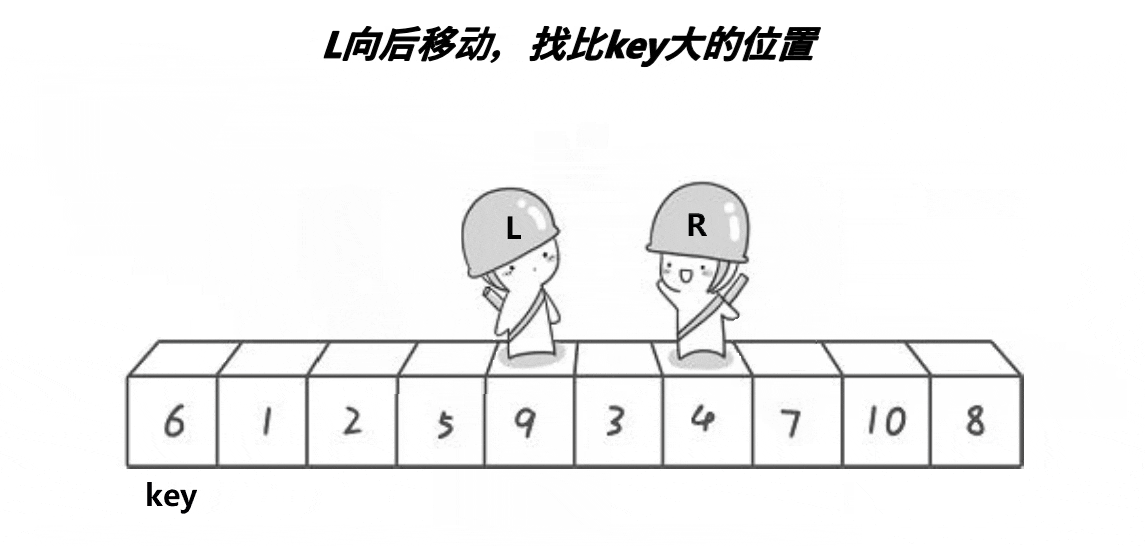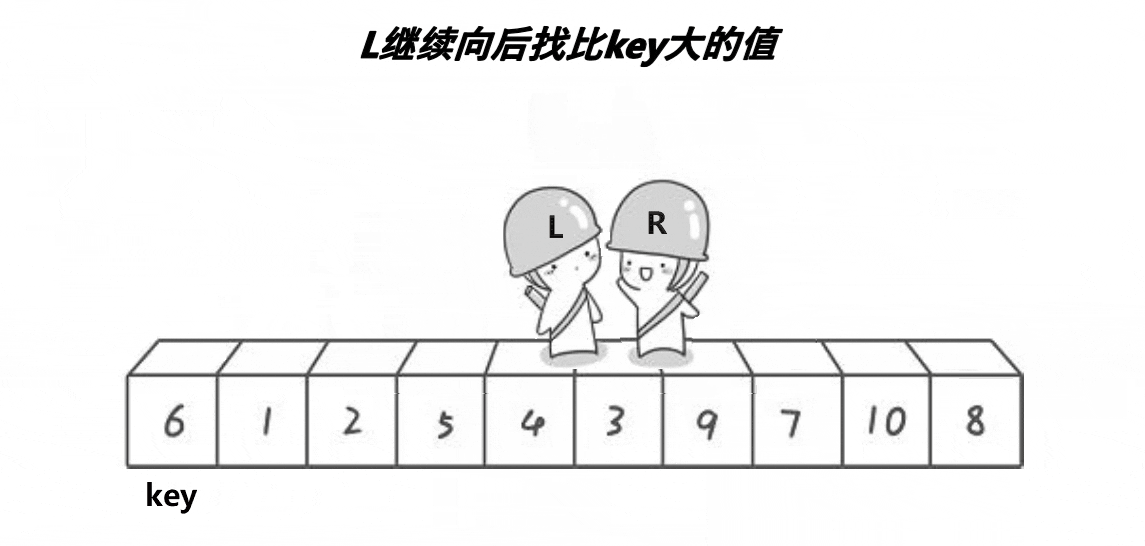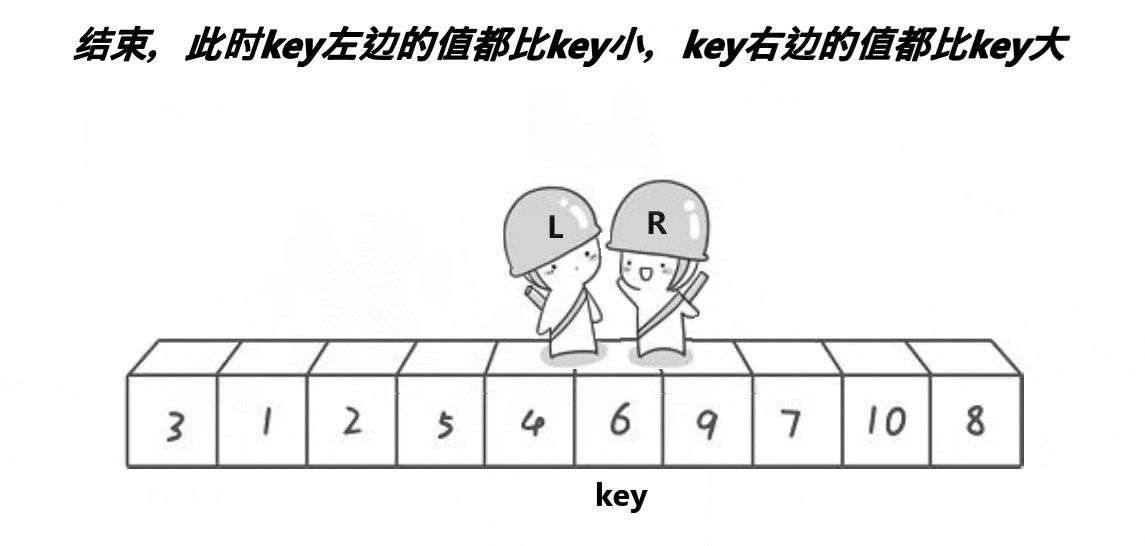
这个动图就是hoare版本的”单趟“实现方法!这里取第一个元素6为基准值;R从最”右边“开始找比基准值小的元素,L从最”左边“开始找比基准值大的元素, 然后交换下标为R和L的元素;R继续找比基准值小的元素,L继续找比基准值大的元素,再交换下标为R和L的元素…………直到R和L相遇,将基准值和相遇位置的元素即可!
其实这个本质就是将比基准值大的元素”甩“到”后面“,将比基准值小的元素”甩“到”前面“。
也许会有疑问,怎么保证相遇位置的元素一定不大于基准值呢?
因为只要是R先动,L后动的话必然能保证相遇的元素一定不大于基准值!
相遇无非两种情况:
1.R遇L:R在去找小于基准值的元素的过程中,下标为L的元素必然是不大于基准值的元素。当R去找小于基准值的元素没有找到却遇到L时, 那么相遇位置的值就是不大于基准值的元素。
2.L遇R:由于R先动,那么L在找大于基准值的元素的过程中,下标为R的元素必然是不大于基准值的元素。当L去找大于基准值的元素没有找到却遇到R时,那么相遇位置的值就是不大于基准值的元素。

hoare版本的“单趟”代码如下,需排序乱序数组下标为begin—end:
//hoare版本int keyi = begin;int left = begin, right = end;while (left < right){while (left < right && a[right] >= a[keyi]){right--;}while (left < right && a[left] <= a[keyi]){left++;}Swap(&a[left], &a[right]);}Swap(&a[keyi], &a[right]);keyi = right;由于hoare版本写起来很容易出错误,所以我们一般写下面两种版本!
1.1.2.挖坑法版本
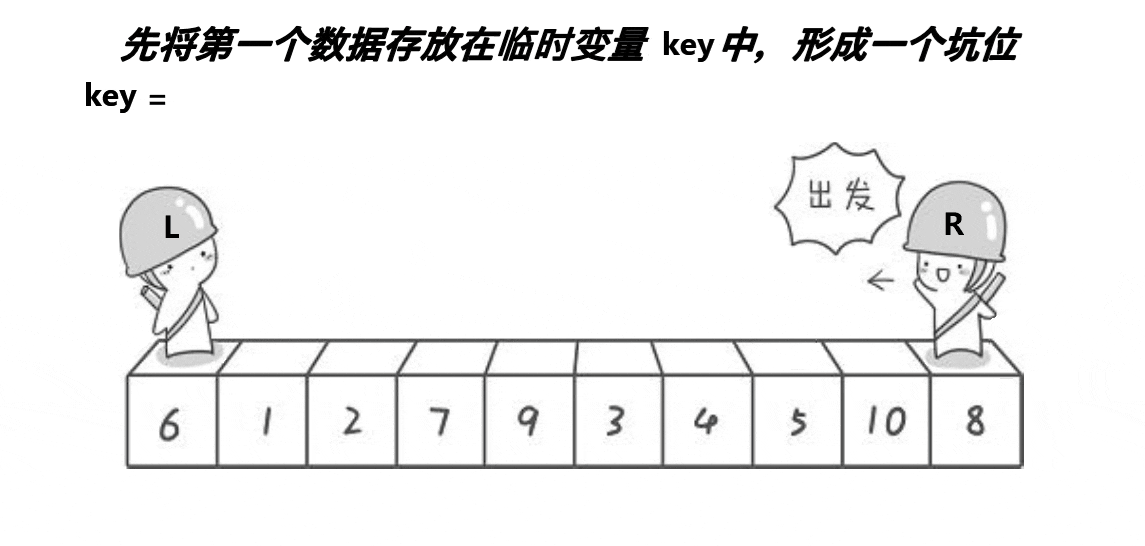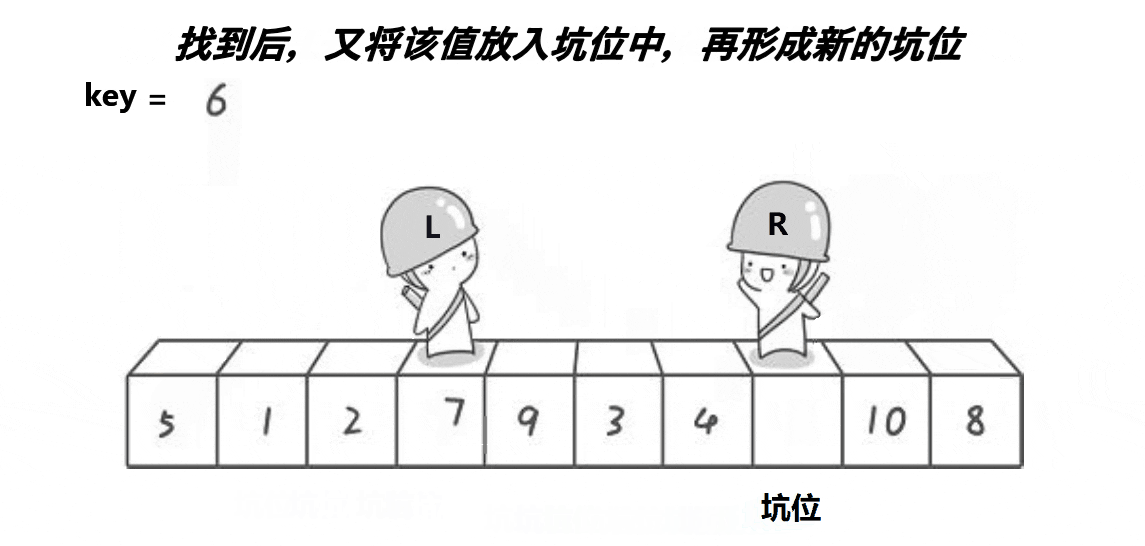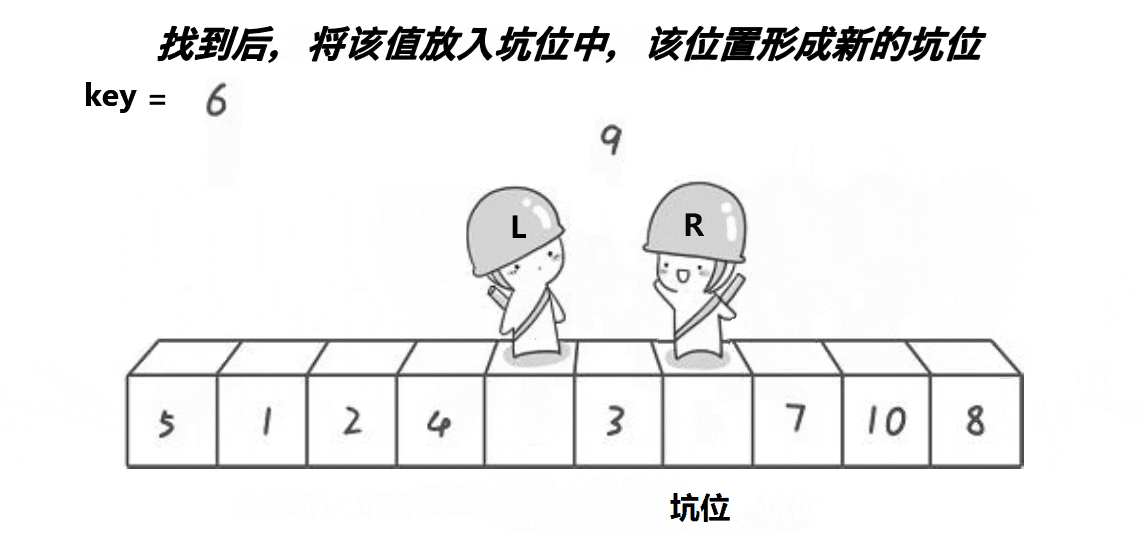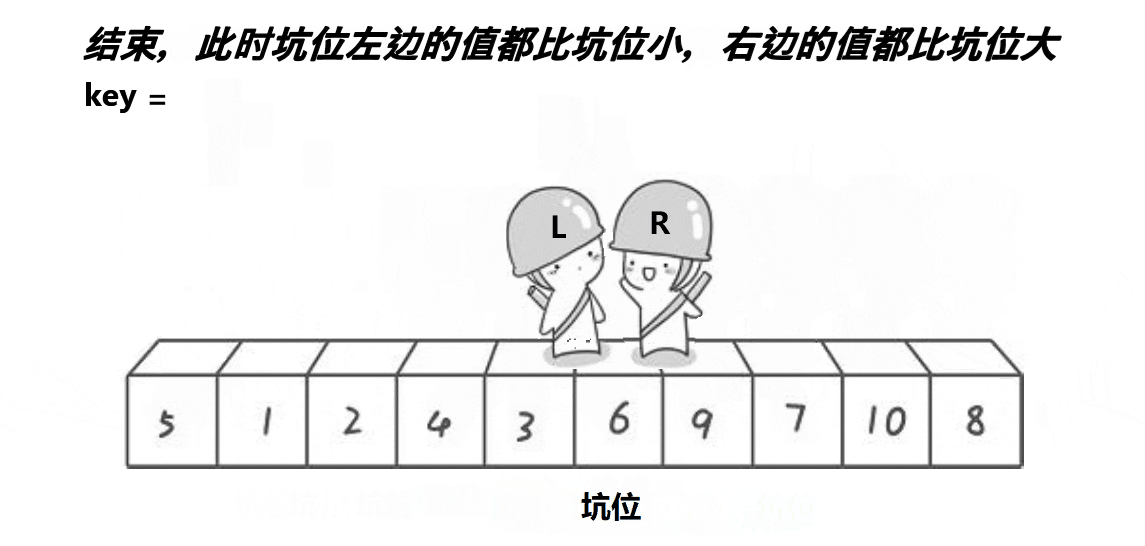
也是取第一个元素6为基准值。初始坑位设置为基准值下标。让R从最“右边”开始找比基准值小的元素,找到后将下标为R的元素填入坑位,那么新的坑位就变成了R;让L从最“左边”开始找比基准值大的元素,找到后将下标为L的元素填入坑位,那么新的坑位就变成了L;R再找比基准值小的元素……直到R和L相遇,将基准值填入坑位即可。
本质就是R找小填入“左边”坑位,L找大填入“右边”坑位,最后一个坑位必定是R和L相遇位置,填入基准值就好。
挖坑法版本“单趟”代码如下,需排序乱序数组下标为begin—end:
//挖坑法版本int key=a[begin];int left = begin, right = end;int hole = begin;while (left < right){while (left < right && a[right] >= key){right--;;}a[hole] = a[right];hole = right;while (left < right && a[left] <= key){left++;}a[hole] = a[left];hole = left;}a[hole] = key;int keyi = hole;1.1.3.前后指针版本
取第一个元素6为基准值。prev初始指向基准值,cur初始指向基准值的下一个元素。cur遍历数组:如果cur遇到大于基准值的元素,++cur;否则++prev、cur指向的元素和prev指向的元素交换、++cur。
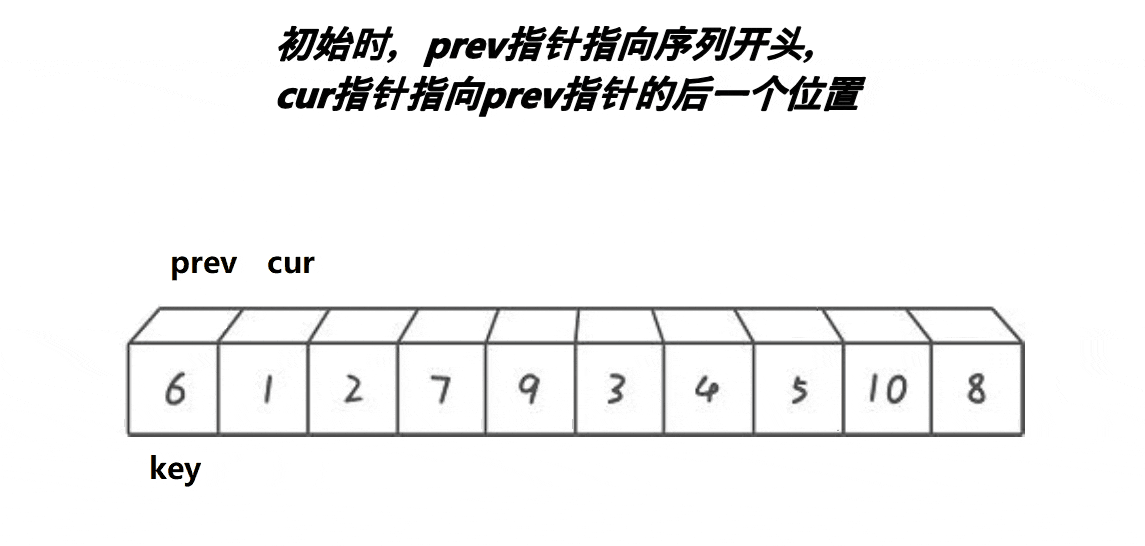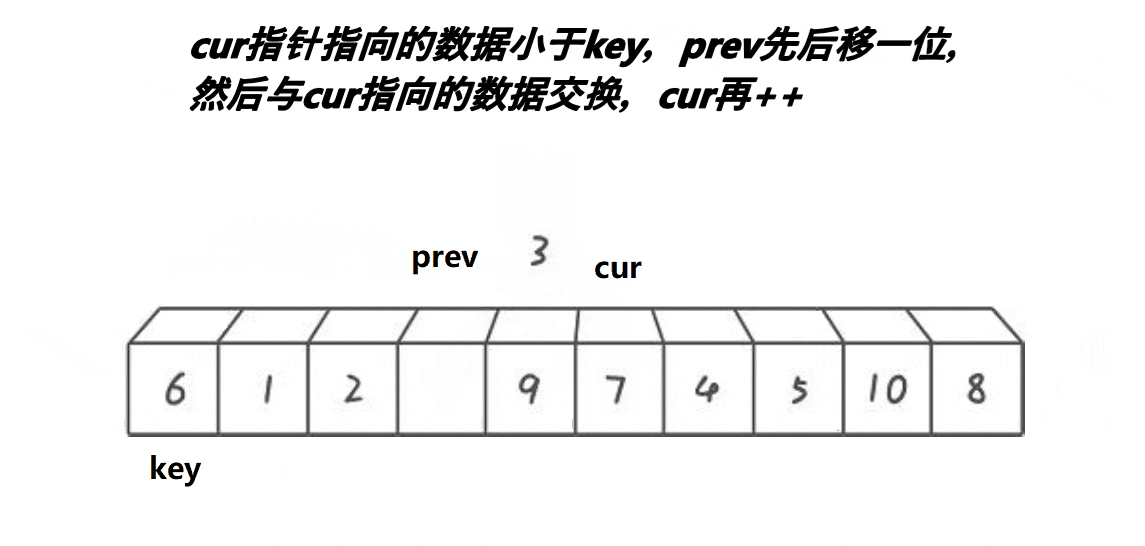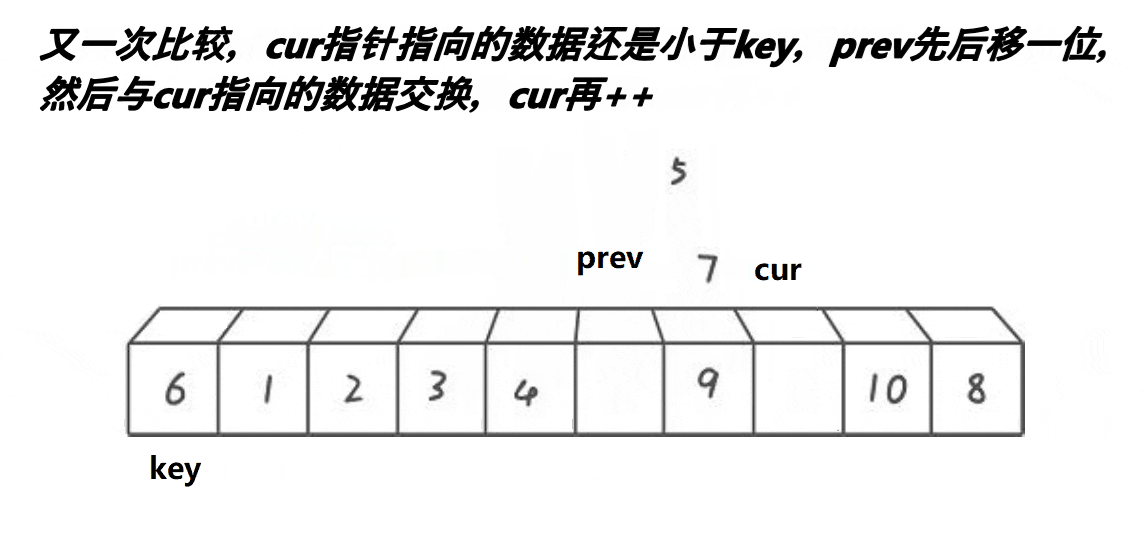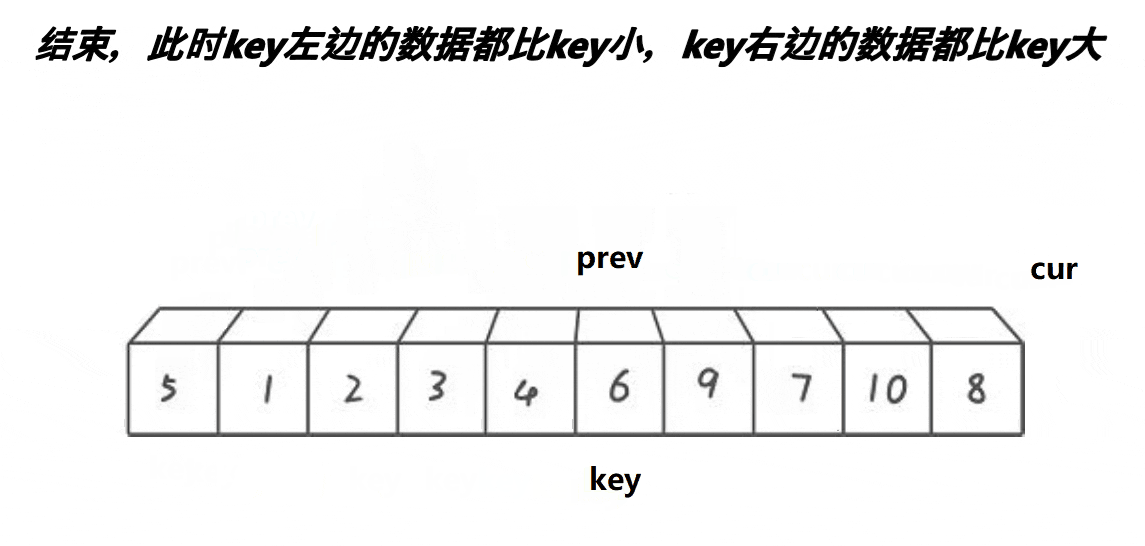
前后指针版本“单趟”代码如下, 需排序乱序数组下标为begin—end:
//前后指针版本int cur = begin + 1, prev = begin;int keyi = begin;while (cur <= end){if (a[cur] > a[keyi]){++cur;}else{++prev;Swap(&a[prev], &a[cur]);++cur;}}Swap(&a[keyi], &a[prev]);keyi = prev;这里指针写成了下标的形式,思想没变,本质上还是一样的!
1.2.快速排序的递归写法
经过“单趟”过后,被选中的基准值就排在了它该出现的位置,就是说当数组排好变得有序后,基准值就在“单趟”过后出现的位置!
既然基准值已经拍好了,如果基准值的“左边”的元素集合能有序并且基准值的“右边”的元素集合能有序,那么需排序的乱序数组就排好了,变得有序了。举个例子:
如图, 所以说快速排序一种二叉树结构的交换排序方法。进行“单趟”排好基准值,递归“左边”元素集合…………“左边”元素集合排好后,递归“右边”元素集合…………“右边”元素集合排好后就搞定了!
递归结束条件:当元素集合只有1个值或为空。

看看快速排序的递归写法代码:
void QuickSort(int* a, int begin, int end)
{if (begin >= end){return;}//hoare版本/*int keyi = begin;int left = begin, right = end;while (left < right){while (left < right && a[right] >= a[keyi]){right--;}while (left < right && a[left] <= a[keyi]){left++;}Swap(&a[left], &a[right]);}Swap(&a[keyi], &a[right]);keyi = right;*///挖坑法版本int key=a[begin];int left = begin, right = end;int hole = begin;while (left < right){while (left < right && a[right] >= key){right--;;}a[hole] = a[right];hole = right;while (left < right && a[left] <= key){left++;}a[hole] = a[left];hole = left;}a[hole] = key;int keyi = hole;//前后指针版本/*int cur = begin + 1, prev = begin;int keyi = begin;while (cur <= end){if (a[cur] > a[keyi]){++cur;}else{++prev;Swap(&a[prev], &a[cur]);++cur;}}Swap(&a[keyi], &a[prev]);keyi = prev;*/QuickSort(a, begin, keyi - 1);QuickSort(a, keyi + 1, end);
}我们试试这个快速排序:
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>void PrintArrar(int* a, int n)
{for (int i = 0; i < n; i++){printf("%d ", a[i]);}printf("\n");
}void Swap(int* a, int* b)
{int tmp = *a;*a = *b;*b = tmp;
}void QuickSort(int* a, int begin, int end)
{if (begin >= end){return;}//hoare版本/*int keyi = begin;int left = begin, right = end;while (left < right){while (left < right && a[right] >= a[keyi]){right--;}while (left < right && a[left] <= a[keyi]){left++;}Swap(&a[left], &a[right]);}Swap(&a[keyi], &a[right]);keyi = right;*///挖坑法版本/*int key=a[begin];int left = begin, right = end;int hole = begin;while (left < right){while (left < right && a[right] >= key){right--;;}a[hole] = a[right];hole = right;while (left < right && a[left] <= key){left++;}a[hole] = a[left];hole = left;}a[hole] = key;int keyi = hole;*///前后指针版本int cur = begin + 1, prev = begin;int keyi = begin;while (cur <= end){if (a[cur] > a[keyi]){++cur;}else{++prev;Swap(&a[prev], &a[cur]);++cur;}}Swap(&a[keyi], &a[prev]);keyi = prev;QuickSort(a, begin, keyi - 1);QuickSort(a, keyi + 1, end);
}int main()
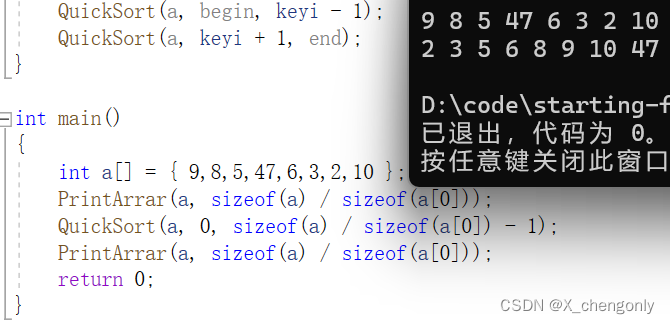
{int a[] = { 9,8,5,47,6,3,2,10 };PrintArrar(a, sizeof(a) / sizeof(a[0]));QuickSort(a, 0, sizeof(a) / sizeof(a[0]) - 1);PrintArrar(a, sizeof(a) / sizeof(a[0]));return 0;
}没问题的:
1.3.快速排序的非递归写法
鼠鼠这里介绍一种快速排序的非递归写法。
需要用到鼠鼠前面博客 介绍的栈,利用到栈写的快速排序没有用到递归但思想却很像递归!

非递归写法思想如上图。我们看快速排序非递归代码如下,其中变量s是栈。鼠鼠这里“单趟”选择挖坑法版本,当然老爷们可以用其他版本:
void QuickSortNonr(int* a, int begin, int end)
{Stack s;StackInit(&s);StackPush(&s, end);StackPush(&s, begin);while (!StackEmpty(&s)){int start = StackTop(&s);StackPop(&s);int finish = StackTop(&s);StackPop(&s);int key = a[start];int left = start, right = finish;int hole = start;while (left < right){while (left < right && a[right] >= key){right--;;}a[hole] = a[right];hole = right;while (left < right && a[left] <= key){left++;}a[hole] = a[left];hole = left;}a[hole] = key;if (start < left - 1){StackPush(&s, left - 1);StackPush(&s, start);}if (left + 1 < finish){StackPush(&s, finish);StackPush(&s, left + 1);}}StackDestroy(&s);
}我们要用到栈,所以记得将我们自己写的栈的头文件和源文件拷贝一份到快速排序的工程目录下 ,再包栈的头文件就可以用了。我们试试:
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
#include"Stack.h" //注意包含栈的头文件void PrintArrar(int* a, int n)
{for (int i = 0; i < n; i++){printf("%d ", a[i]);}printf("\n");
}void QuickSortNonr(int* a, int begin, int end)
{Stack s;StackInit(&s);StackPush(&s, end);StackPush(&s, begin);while (!StackEmpty(&s)){int start = StackTop(&s);StackPop(&s);int finish = StackTop(&s);StackPop(&s);int key = a[start];int left = start, right = finish;int hole = start;while (left < right){while (left < right && a[right] >= key){right--;;}a[hole] = a[right];hole = right;while (left < right && a[left] <= key){left++;}a[hole] = a[left];hole = left;}a[hole] = key;if (start < left - 1){StackPush(&s, left - 1);StackPush(&s, start);}if (left + 1 < finish){StackPush(&s, finish);StackPush(&s, left + 1);}}StackDestroy(&s);
}int main()
{int a[] = { 9,8,5,47,6,3,2,10 };PrintArrar(a, sizeof(a) / sizeof(a[0]));QuickSortNonr(a, 0, sizeof(a) / sizeof(a[0]) - 1);PrintArrar(a, sizeof(a) / sizeof(a[0]));return 0;
}
没问题吧!
2.快速排序递归写法优化
2.1.三数取中法选基准值
对于递归写法来说,对于需排序数组本身就是升序或者降序的情况适应的不是很好,因为:
1.固定了选择元素集合第一个元素为基准值,每次“单趟”过后都会导致某一边元素集合为空的情况。这样的话如果本身就是升序或者降序的需排序数组个数有n个的话,就要递归n层,很容易栈溢出!
2.每次“单趟”时间复杂度是O(N),递归n层的话快速排序时间复杂度是O(N^2),时间效率不划算!
所以我们有三数取中选基准值,我们取元素集合第一个元素、最后一个元素和中间那个元素,这三个元素比较得出第二大的元素,将这个元素与元素集合第一个元素交换再进行“单趟”。
这样的话就能很好适应需排序数组本身就是升序或者降序的情况,因为这样经过“单趟”之后,基准值一定会出现在“中间”。这样子去递归的话,每一层递归都会被“二分”,递归层数大大减少,递归log(N)层就行!
加入了三数取中选基准值的递归写法的快速排序时间复杂度是O(N*logN)。
而且加入了三数取中选基准值的递归写法的快速排序对于需排序数组本身不是升序或者降序的情况一样有帮助,可以让每层递归尽量“二分”,从而减少递归层数!
三数取中法代码:
int GetMidi(int* a, int begin, int end)
{int midi = begin + (end - begin) / 2;if (a[begin] > a[midi]){if (a[begin] > a[end]){if (a[midi] > a[end]){return midi;}elsereturn end;}else{return begin;}}else{if (a[midi] > a[end]){if (a[end] > a[begin]){return end;}else{return begin;}}else{return midi;}}
}当没有加入三数取中选基准值的递归写法的快速排序排10000个升序元素组成的数组时,在Debug环境下就会崩溃,栈溢出了:
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
#include<stdlib.h>
#include<time.h>int GetMidi(int* a, int begin, int end)
{int midi = begin + (end - begin) / 2;if (a[begin] > a[midi]){if (a[begin] > a[end]){if (a[midi] > a[end]){return midi;}elsereturn end;}else{return begin;}}else{if (a[midi] > a[end]){if (a[end] > a[begin]){return end;}else{return begin;}}else{return midi;}}
}void Swap(int* a, int* b)
{int tmp = *a;*a = *b;*b = tmp;
}void QuickSort(int* a, int begin, int end)
{if (begin >= end){return;}//三数取中选基准值/*int midi = GetMidi(a, begin, end);Swap(&a[begin], &a[midi]);*///前后指针版本int cur = begin + 1, prev = begin;int keyi = begin;while (cur <= end){if (a[cur] > a[keyi]){++cur;}else{++prev;Swap(&a[prev], &a[cur]);++cur;}}Swap(&a[keyi], &a[prev]);keyi = prev;QuickSort(a, begin, keyi - 1);QuickSort(a, keyi + 1, end);
}int main()
{int n = 10000;int* a = (int*)malloc(sizeof(int) * n);srand((unsigned int)time(0));a[0] = rand();for (int i = 1; i < n ; i++){a[i] = a[i-1] + 1;}int begin = clock();QuickSort(a, 0, n - 1);int end = clock();printf("%d\n", end - begin);return 0;
}
结果:

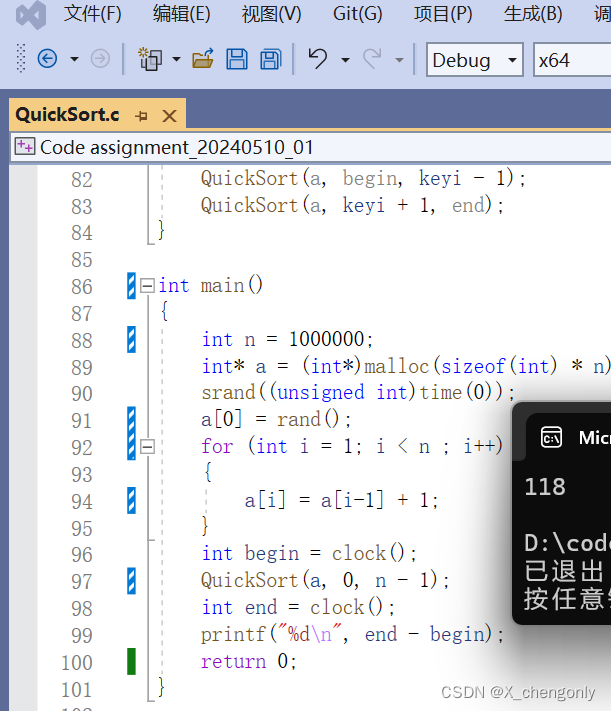
当加入三数取中选基准值的递归写法的快速排序,排100w个升序元素组成的数组都没问题,Debug环境下:
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
#include<stdlib.h>
#include<time.h>int GetMidi(int* a, int begin, int end)
{int midi = begin + (end - begin) / 2;if (a[begin] > a[midi]){if (a[begin] > a[end]){if (a[midi] > a[end]){return midi;}elsereturn end;}else{return begin;}}else{if (a[midi] > a[end]){if (a[end] > a[begin]){return end;}else{return begin;}}else{return midi;}}
}void Swap(int* a, int* b)
{int tmp = *a;*a = *b;*b = tmp;
}void QuickSort(int* a, int begin, int end)
{if (begin >= end){return;}//三数取中选基准值int midi = GetMidi(a, begin, end);Swap(&a[begin], &a[midi]);//前后指针版本int cur = begin + 1, prev = begin;int keyi = begin;while (cur <= end){if (a[cur] > a[keyi]){++cur;}else{++prev;Swap(&a[prev], &a[cur]);++cur;}}Swap(&a[keyi], &a[prev]);keyi = prev;QuickSort(a, begin, keyi - 1);QuickSort(a, keyi + 1, end);
}int main()
{int n = 1000000;int* a = (int*)malloc(sizeof(int) * n);srand((unsigned int)time(0));a[0] = rand();for (int i = 1; i < n ; i++){a[i] = a[i-1] + 1;}int begin = clock();QuickSort(a, 0, n - 1);int end = clock();printf("%d\n", end - begin);return 0;
}结果:
2.2.小区间优化
递归到小的子区间(数量少的元素集合)时,可以考虑使用插入排序。这样子可以减少大部分的递归,因为大部分的递归都是由小的子区间产生的。不过由于编译器优化的厉害,小区间优化效果不是很明显,鼠鼠就在这里顺便提一提算了!
感谢阅读!