MambaOut: Do We Really Need Mamba for Vision?
公和众和号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)


目录
0. 摘要
1. 简介
3. 概念讨论
3.1 Mamba 适合哪些任务?
3.2 视觉识别任务是否需要处理非常长的序列?
3.3 视觉识别任务是否需要因果token混合模式?
3.4 关于 Mamba 在视觉任务中必要性的假设
4. 实验
4.1 门控 CNN 和 MambaOut
4.2 ImageNet 上的图像分类
4.3 COCO上的目标检测与实例分割
4.4 ADE20K上的语义分割
5. 结论
0. 摘要
Mamba,一种具有状态空间模型(SSM)的类似 RNN 的 token 混合器架构,最近被引入以解决注意力机制的二次复杂性,并随后应用于视觉任务。然而,与卷积和基于注意力的模型相比,Mamba 在视觉方面的性能往往令人失望。本文深入探讨了 Mamba 的本质,并从概念上得出结论:Mamba 非常适合具有长序列和自回归特征的任务。对于视觉任务,由于图像分类不符合这两个特征,我们假设 Mamba 对该任务不是必要的;检测和分割任务虽然也不是自回归的,但它们符合长序列特征,因此我们认为探索 Mamba 在这些任务中的潜力仍然是值得的。为了实证验证我们的假设,我们通过堆叠 Mamba 块并移除其核心 token 混合器 SSM,构建了一系列名为 MambaOut 的模型。实验结果强烈支持我们的假设。具体而言,我们的 MambaOut 模型在 ImageNet 图像分类上超越了所有视觉 Mamba 模型,表明 Mamba 对于这一任务确实不是必要的。至于检测和分割,MambaOut 无法匹敌最先进的视觉 Mamba 模型的性能,这表明 Mamba 在长序列视觉任务中具有潜力。
本文讨论的视觉任务包括 ImageNet 上的图像分类 [19, 65],COCO 上的目标检测和实例分割 [47],以及 ADE20K 上的语义分割 [101]
项目页面:https://github.com/yuweihao/MambaOut
1. 简介
在本文中,我们研究了 Mamba 的本质,并概念性地总结出 Mamba 由于其内在的 SSM 的 RNN 机制 [27, 26, 25](见图 2 和图 3 的解释),非常适合具有两个关键特征的任务:长序列和自回归。不幸的是,许多视觉任务不具备这两个特征。例如,ImageNet 上的图像分类既不符合这两个特征,而 COCO 上的目标检测和实例分割以及 ADE20K 上的语义分割仅符合长序列特征。另一方面,自回归特征要求每个 token 仅从前面的和当前的 token 中聚合信息,这种模式被称为因果模式的 token 混合 [62](见图 3(a))。事实上,所有视觉识别任务都属于理解域而非生成域,这意味着模型可以一次性看到整个图像。因此,在视觉识别模型中对 token 混合施加额外的因果约束可能会导致性能下降(见图 3(b))。虽然这个问题可以通过双向分支 [67] 来缓解,但在每个分支内这个问题仍然不可避免。
基于上述概念性讨论,我们提出了两个假设:
- 假设1:SSM 对图像分类是没有必要的,因为该任务既不符合长序列特征也不符合自回归特征。
- 假设2:SSM 可能对目标检测、实例分割和语义分割有潜在的好处,因为这些任务符合长序列特征,尽管它们不是自回归的。
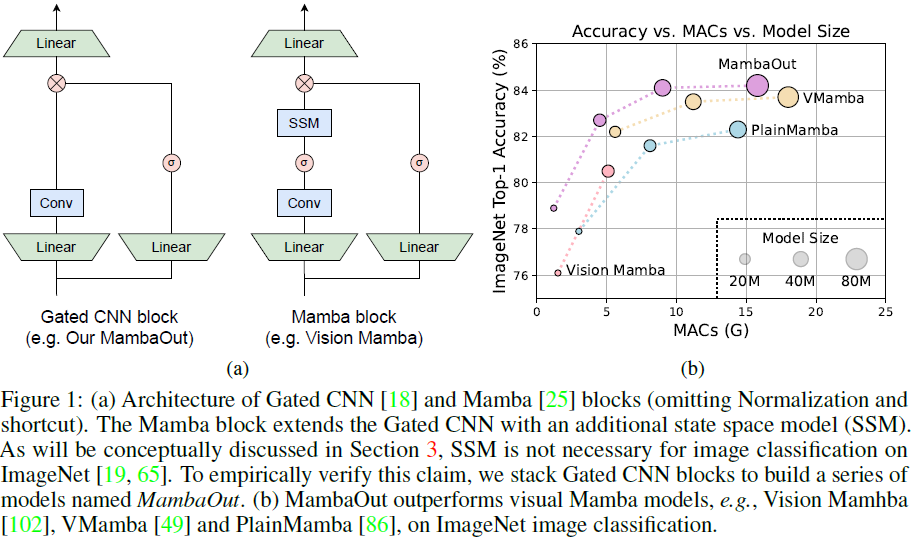
为了实验验证我们的假设,我们通过堆叠门控 CNN [18] 模块开发了一系列模型,称为MambaOut。门控 CNN 和 Mamba 模块之间的关键区别在于是否存在 SSM,如图 1(a) 所示。实验结果表明,实际上更简单的 MambaOut 模型已经超越了视觉 Mamba 模型 [102, 49, 37, 86] 的性能,这验证了我们的假设 1。我们还展示了 MambaOut 在检测和分割任务中的性能不及最先进的视觉 Mamba 模型[49, 37](见表2和表3),这强调了 SSM 在这些任务中的潜力,有效地验证了我们的假设 2。
3. 概念讨论
在本节中,我们首先讨论 Mamba 模型适合的任务特征。接下来,我们检验视觉识别任务是否符合这些特征。根据检验结果,我们提出关于 Mamba 对视觉任务必要性的假设。
3.1 Mamba 适合哪些任务?
Mamba 的 token 混合器是选择性状态空间模型(selective SSM)[26, 25],它定义了四个依赖输入的参数(Δ, A, B, C),并将它们转换为(¯A, ¯B, C),如下所示:
![]()
然后,SSM 的序列到序列转换可以表示为:

其中,t 表示时间步,x_t 表示输入,h_t 表示隐藏状态,y_t 表示输出。方程 2 的递归特性 [34] 将类 RNN 的 SSM 与因果注意力区分开来。隐藏状态 h 可以视为一个固定大小的记忆,存储所有历史信息。通过方程 2,这个内存在保持大小不变的情况下进行更新。固定大小意味着记忆不可避免地有损,但它确保了将记忆与当前输入集成的计算复杂度保持不变。相比之下,因果注意力将所有先前 token 的 key 和 value 存储为记忆,并通过添加当前 token 的 key 和 value 来扩展记忆。这种记忆在理论上是无损的。然而,随着输入的 token 越来越多,记忆大小增加,从而增加了将记忆与当前输入集成的复杂度。类 RNN 模型与因果注意力之间的记忆机制差异在图 2 中进一步说明。

由于 SSM 的记忆本质上是有损的,它在处理短序列方面不及无损的注意力。因此,Mamba 无法在处理短序列时展示其优势,这是注意力机制容易胜任的领域。然而,在涉及长序列的场景中,由于注意力机制的二次复杂性,它会遇到困难。在这种情况下,Mamba 能够明显展示其在将内存与当前输入集成方面的效率,从而顺利处理长序列。因此,Mamba 特别适合处理长序列。

尽管 SSM 的递归性质(方程2)允许 Mamba 高效地处理长序列,但它也引入了一个显著的限制:h_t 只能访问前一个和当前时间步的信息。如图 3 所示,这种 token 混合称为因果模式,可以表示为:
![]()
其中 x_t 和 y_t 分别表示第 t 个 token 的输入和输出。由于其因果性质,这种模式非常适合自回归生成任务。
另一种模式称为全可见模式,其中每个 token 可以聚合所有前后 token 的信息。这意味着每个 token 的输出依赖于所有 token 的输入:
![]()
其中 T 表示 token 的总数。全可见模式适用于理解任务,因为模型可以一次性访问所有输入。
注意力机制默认处于全可见模式,但通过对注意力图应用因果掩码,它可以轻松转变为因果模式。类 RNN 模型由于其递归性质,固有地处于因果模式,如 Mamba 的方程 2 所示。由于这种固有特性,类 RNN 模型无法转变为全可见模式。尽管 RNN 可以通过双向分支近似全可见模式,但每个分支仍然单独处于因果模式。因此,由于递归特性的限制,Mamba 适合需要因果 token 混合的任务。
综上所述,Mamba 理想适用于展示以下特征的任务:
- 特征 1:任务涉及处理长序列。
- 特征 2:任务需要因果 token 混合模式。
接下来,我们将讨论视觉识别任务是否具备这两个特征。
3.2 视觉识别任务是否需要处理非常长的序列?
在本小节中,我们探讨视觉识别任务是否需要长序列建模。我们以 Transformer 模型 [75] 为案例进行分析。考虑一个具有常见 MLP 比例为 4 的 Transformer 块;假设其输入 X ∈ R^{L×D} 具有长度为 L 的 token 和维度为 D 的通道(嵌入)维度,该块的 FLOPs 可以计算为:
![]()
由此,我们推导出二次项与线性项在 L 中的比率为:

如果 L>6D,则 L 中的二次项的计算负载超过线性项的负载。这提供了一个简单的指标来确定任务是否涉及长序列。例如,对于 ViT-S 中的 384 通道,阈值 τ_small=6×384=2304,对于 ViT-B 中的 768 通道,阈值 τ_base=6×768=4608。
对于 ImageNet 上的图像分类,典型的输入图像大小为 224×224,导致 token 数为 14×14 = 196(patch 大小为16×16)。显然,196 远小于 τ_small 和 τ_base,这表明 ImageNet 上的图像分类不属于长序列任务。
对于 COCO 上的目标检测和实例分割,推理图像大小为 800×1280,对于 ADE20K 上的语义分割,推理图像大小为 512×2048,给定 patch 大小为 16×16,token 数约为 4K。由于 4K > τ_small 且 4K ≈ τ_base,COCO 上的检测和 ADE20K 上的分割可以视为长序列任务。
3.3 视觉识别任务是否需要因果token混合模式?
如 3.1 节讨论并在图 3 中所示,全可见 token 混合模式允许无限制的混合范围,而因果模式则限制当前 token 只能访问前面的 token 信息。视觉识别被分类为理解任务,模型可以一次性看到整个图像,因此无需对 token 混合施加限制。对 token 混合施加额外的限制可能会降低模型性能。如图 3(b) 所示,当对 Vision Transformers (ViT) [23, 72] 应用因果限制时,性能明显下降。一般来说,全可见模式适用于理解任务,而因果模式更适合自回归任务。这一说法也可以通过观察到 BERT [20] 和 ViT [23](如 BEiT [4] 和 MAE [30])更多用于理解任务,而 GPT-1/2 [59, 60] 和 image GPT [9] 更多用于生成任务来支持。因此,视觉识别任务不需要因果 token 混合模式。
3.4 关于 Mamba 在视觉任务中必要性的假设
基于前面的讨论,我们总结了关于在视觉识别任务中引入 Mamba 的必要性的假设如下:
- 假设1:对于 ImageNet 上的图像分类,引入 SSM 是不必要的,因为这个任务不符合特征 1 或特征 2。
- 假设2:尽管不符合特征 1,但仍有必要进一步探索 SSM 在视觉检测和分割中的潜力,因为这些任务符合特征 2。

4. 实验
4.1 门控 CNN 和 MambaOut
接下来,我们旨在通过实验证实我们的假设。如图 1(a) 所示,Mamba 块 [25] 基于门控 CNN 块[18]。门控 CNN 和 Mamba 的元架构可以看作是 MetaFormer [89] 的 token 混合器和 MLP 的简化集成,类似于 MetaNeXt [91]。形式上,给定输入 X∈R^(N×D),元架构公式如下:

其中,Norm(·) 表示归一化 [38, 2, 82];TokenMixer(·) 指进行 token 混合的模块 [90];W1∈R^(D×rD),W2∈R^(D×rD),W3∈R^(rD×D) 是具有 MLP 扩展率 r 的可学习参数;σ 是激活函数 [24, 33]。门控 CNN 和 Mamba 的 token 混合器分别是:

比较方程 10 和 11 并参考图 1(a),门控 CNN 和 Mamba 块 [25] 之间的主要区别在于 SSM 的存在。这促使我们开发一系列基于无 SSM 的门控 CNN 块的模型,称为 MambaOut。MambaOut 将帮助我们评估 Mamba 在视觉识别任务中的必要性。
具体而言,我们将门控 CNN 的 token 混合器指定为 7×7 核大小的深度卷积 [11],参考 ConvNeXt [51, 54]。此外,为了提高实际速度,我们仅在部分通道上进行深度卷积 [53, 91, 7],参考InceptionNeXt [91]。如算法 1 所示,门控 CNN 块的实现简单且优雅。类似于 ResNet,我们采用 4 阶段框架,通过在每个阶段堆叠门控 CNN 块来构建 MambaOut,如图 4 所示。每个模型大小的配置细节显示在附录的表 4 中。

4.2 ImageNet 上的图像分类
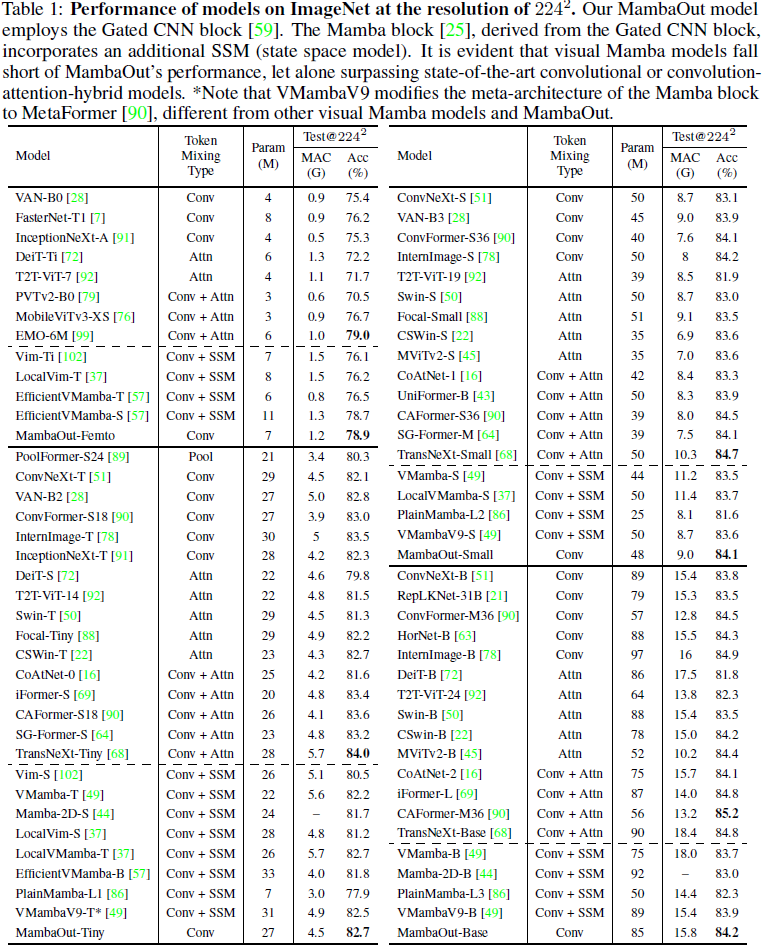
表 1 展示了我们的 MambaOut 模型、视觉 Mamba 模型以及各种其他基于卷积和注意力的模型在 ImageNet [19, 65] 上的表现。值得注意的是,我们的 MambaOut 模型(不包含 SSM)在所有模型大小上均一致地超越了包含 SSM 的视觉 Mamba 模型 [102, 49, 37, 57, 86]。例如,MambaOut-Small 模型实现了 84.1% 的 top-1 准确率,比 LocalVMamba-S [37] 高 0.4%,而所需的 MAC 仅为其 79%。这些结果强烈支持我们的假设 1,即引入 SSM 用于 ImageNet 上的图像分类是不必要的,这也符合奥卡姆剃刀原理。
此外,目前的视觉 Mamba 模型与最先进的卷积和注意力模型相比,仍存在显著的性能差距。例如,CAFormer-M36 [90],它采用了传统的 token 混合器,如简单的可分离卷积 [66] 和标准的注意力机制 [75],其准确率比所有同等大小的视觉 Mamba 模型高出超过 1%。如果未来的研究旨在挑战我们的假设 1,则需要开发具有卷积和 SSM 的 token 混合器的视觉 Mamba 模型,以在 ImageNet 上实现最先进的性能。
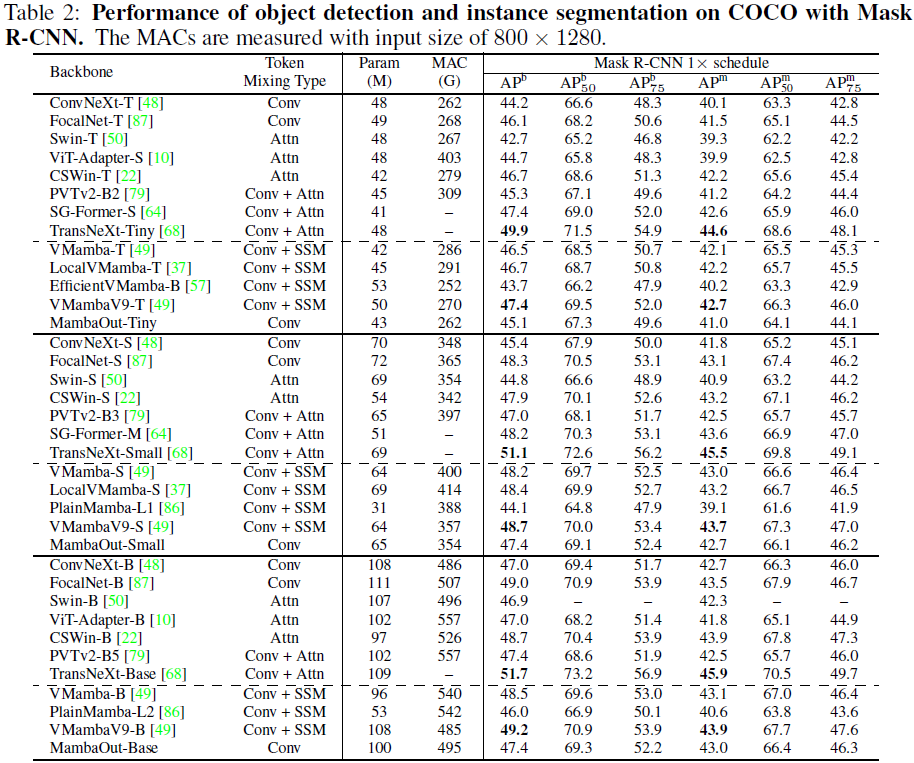
4.3 COCO上的目标检测与实例分割
尽管 MambaOut 在 COCO 上的目标检测和实例分割任务中可以超过一些视觉 Mamba 模型 [57, 86],但仍然落后于最先进的视觉 Mamba,如 VMamba [49] 和 LocalVMamba [49]。例如,作为Mask R-CNN 的骨干网络,MambaOut-Tiny 的性能比 VMamba-T [49] 低 1.4 APb 和 1.1 APm。这种性能差距强调了在长序列视觉任务中集成 Mamba 的好处,进一步证实了我们的假设 2。然而,与最先进的卷积-注意力混合模型 TransNeXt [68] 相比,视觉 Mamba 仍然存在显著的性能差距。视觉 Mamba 需要通过在视觉检测任务中超越其他最先进的模型来进一步验证其有效性。

4.4 ADE20K上的语义分割
在 ADE20K 上的语义分割任务的性能趋势与 COCO 上的目标检测类似。MambaOut 可以超过一些视觉 Mamba 模型,但无法与最先进的 Mamba 模型的结果匹敌。例如,LocalVMamba-T [37] 在单尺度(SS)和多尺度(MS)评估中都比 MambaOut-Tiny 高出 0.5 mIoU,从而进一步通过实验证实了我们的假设 2。此外,与更先进的混合模型相比,这些模型集成了卷积和注意力机制,如SG-Former [64] 和 TransNeXt [68],视觉 Mamba 模型继续显示出显著的性能差距。视觉 Mamba需要通过在视觉分割任务中展示其长序列建模的优势来进一步展示其实力。
5. 结论
在本文中,我们从概念上讨论了 Mamba 机制,并得出结论:它非常适合具有长序列和自回归特征的任务。我们根据这些标准分析了常见的视觉任务,并认为引入 Mamba 用于 ImageNet 图像分类是没有必要的,因为它不符合这两个特征。然而,Mamba 在符合长序列特征的视觉检测和分割任务中的潜力值得进一步探索。为了实证验证我们的观点,我们开发了 MambaOut 模型,这些模型使用了没有核心 token 混合器 SSM 的 Mamba 模块。MambaOut 在 ImageNet 上超越了所有视觉 Mamba 模型,但与最先进的视觉 Mamba 模型相比,表现出明显的性能差距,从而验证了我们的主张。
由于计算资源的限制,本文仅验证了 Mamba 概念在视觉任务中的应用。未来,我们可能会进一步探索 Mamba 和 RNN 概念,以及 RNN 和 Transformer 在大语言模型(LLM)和大多模态模型(LMM)中的集成。





![[动画详解]LeetCode151.翻转字符串里的单词](https://img-blog.csdnimg.cn/direct/6f594249c0f7473dad7adba588aec775.gif)