1.柔性数组
我们先来介绍一下什么是柔性数组:
在C语言中,柔性数组(Flexible Array)并不是一个标准的术语,但它通常指的是结构体中最后一个元素是一个没有指定大小的数组。这种结构体设计允许在运行时动态分配数组的大小,从而提供了更大的灵活性。
这里给一串代码来解释一下:
struct S
{int i;int a[0];//柔性数组成员
};但是呢有的编译器会报错无法编译这时候我们可以改成这样的:
struct st_type
{int i;int a[];//柔性数组成员
};1.1柔性数组的特点:
结构中的柔性数组成员前面必须至少一个其他成员。
sizeof返回的这种结构大小不包括柔性数组的内存
包含柔性数组成员的结构用malloc()函数进行内存的动态分配,并且分配的内存应该大于结构的大小。以适应柔性数组的预期大小。
下面我给出一个例子:
typedef struct S
{int i;//柔性数组成员前面必须至少一个其他成员。int a[0];//柔性数组成员
};
int main()
{printf("%d\n", sizeof(type_a));//输出的是4就说明sizeof返回的这种结构大小不包括柔性数组的内存return 0;
}第三个特点怎么解释:
柔性数组的这个特点意味着在使用 malloc() 函数为包含柔性数组成员的结构体动态分配内存时,需要分配的内存大小不仅要包括结构体本身的大小,还要额外分配足够的空间来容纳柔性数组的元素。
就是我们在创建一个结构体变量的时候我不是:
struct S s不是这样创建。
柔性数组成员不是这样开辟空间是使用malloc函数进行的。用malloc把包含柔性数组的结构体创建到堆上 :
malloc(sizeof(struct S)+5*sizeof(int))
这里的sizeof(struct S)只包含柔性数组前面的成员大小,然后再加上柔性数组的大小(这个空间你随意创建)
具体来说,当你使用 malloc() 为一个结构体分配内存时,你需要计算出结构体的大小,然后根据柔性数组的预期大小来增加额外的内存分配。这是因为柔性数组的大小在编译时是未知的,它需要在下面是一个具体的例子来解释这个特点:
假设我们有一个结构体 MyStruct ,它包含一个整型成员 size 和一个柔性数组成员 data :运行时根据实际情况来确定。
typedef struct {int size; // 结构体的其他成员int data[]; // 柔性数组成员
} MyStruct;如果我们想要为这个结构体分配内存,并且柔性数组的预期大小是10个整型元素,那么我们需要这样分配内存:
int main() {int n = 10; // 柔性数组的预期大小// 分配结构体和柔性数组的内存MyStruct *myStruct = malloc(sizeof(MyStruct) + sizeof(int) * n);if (myStruct != NULL) {// 初始化结构体的其他成员myStruct->size = n;// 使用柔性数组...// ...// 释放内存free(myStruct);} else {fprintf(stderr, "Memory allocation failed\n");}return 0;
}在这个例子中,我们首先计算了结构体的大小( sizeof(MyStruct) ),然后根据柔性数组的预期大小( n 个整型元素)计算了额外需要分配的内存大小( sizeof(int) * n )。接着,我们使用 malloc() 函数将这两部分内存大小相加,为结构体和柔性数组分配了足够的内存。
这样,我们就可以在运行时动态地为柔性数组分配内存,并且可以按照需要调整柔性数组的大小。这种灵活性是柔性数组设计的核心优势之一。
1.2柔性数组的使用
#include <stdio.h>
#include <stdlib.h>
typedef struct type_a
{int i;int a[0];
};int main()
{int i = 0;type_a *p = (type_a*)malloc(sizeof(type_a)+100*sizeof(int));//业务处理p->i = 100;for(i=0; i<100; i++){p->a[i] = i;}free(p);return 0;
}这样的柔性数组成员a,相当于获得了100个整型元素的连续空间。
1.3柔性数组的优势
上述的type_a结构也可以设计为下面的结构,也能完成同样的效果。
#include <stdio.h>
#include <stdlib.h>
typedef struct st_type
{int i;int *p_a;
}type_a;
int main()
{type_a *p = (type_a *)malloc(sizeof(type_a));p->i = 100;p->p_a = (int *)malloc(p->i*sizeof(int));//业务处理for(i=0; i<100; i++){p->p_a[i] = i;}//释放空间free(p->p_a);p->p_a = NULL;free(p);
p = NULL;return 0;
} 上述 代码1 和 代码2 可以完成同样的功能,但是 方法1的实现有两个好处:
第一个好处是:方便内存释放
如果我们的代码是在一个给别人用的函数中,你在里面做了二次内存分配,并把整个结构体返回给用户。用户调用自由可以释放结构体,但是用户并不知道这个结构体内的成员也需要自由,所以你不能指望用户来发现这个事。所以,如果我们把结构体的内存以及其成员要的内存一次性分配好了,并返回给用户一个结构体指针,用户做一次免费就可以把所有的内存也给释放掉。
第二个好处是:这样有利于访问速度
连续的内存有益于提高访问速度,也有益于减少内存碎片。(其实,我个人觉得也没多高了,反正你跑不了要用做偏移量的加法来寻址)
2.总结c/c++中程序内存区域划分
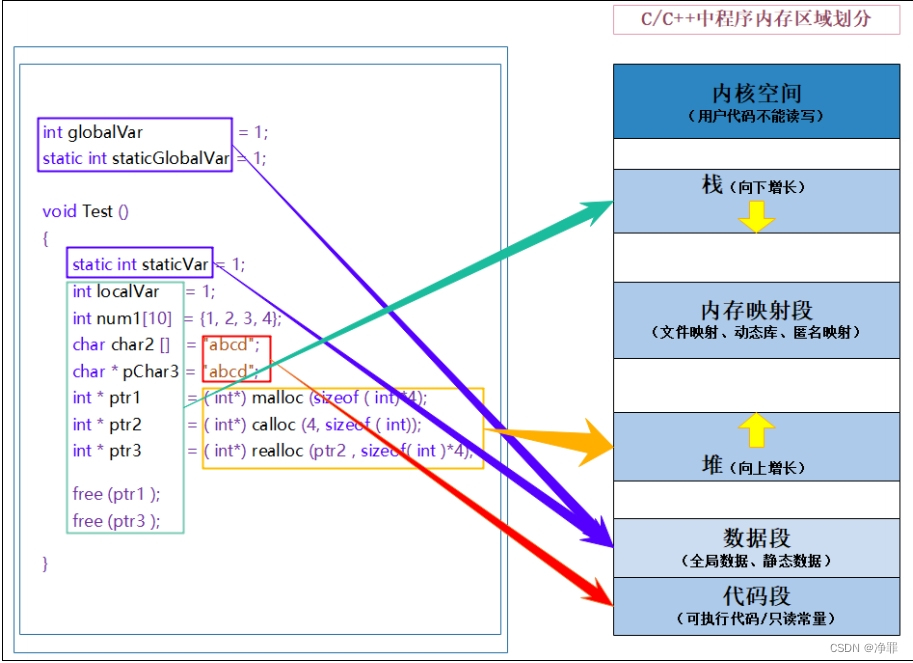
C/C++程序内存分配的几个区域:
1.栈区(stack):在执行函数时,函数内局部变量的存储单元都可以在栈上创建,函数执行结束时这些存储单元自动被释放。栈内存分配运算内置于处理器的指令集中,效率很高,但是分配的内存容量有限。 栈区主要存放运行函数而分配的局部变量、函数参数、返回数据、返回地址等。
《函数栈帧的创建和销毁》
堆区(heap):一般由程序员分配释放,若程序员不释放,程序结束时可能由0S回收。分配方式类似于链表。
数据段(静态区):(static)存放全局变量、静态数据。程序结束后由系统释放。
代码段:存放函数体(类成员函数和全局函数)的二进制代码。