IRENE:医学图像、文本、基因数据 + 多模态融合 + 疾病诊断模型
- 多模态融合方法分析与分类
- 1. 早期融合方法
- 2. 晚期融合方法
- 3. 混合融合方法
- 传统非统一的多模态融合方法的局限性
- IRENE 解法
- 子解法1:多模态表征学习
- 子解法2:双向多模态注意力机制
- IRENE算法的具体架构、双向多模态注意力机制的工作原理
- 多模态Transformer 对比 大模型Transformer
- IRENE算法如何从单一模型变成针对多模态数据的特定处理机制和层,以及在注意力机制和块结构上具体做了哪些改进
- 多模态处理机制和层
- 注意力机制的改进
- 块结构的改进
- 代码分析
知网:面向深度学习的多模态融合技术研究综述
医疗多模态文章:https://m.leiphone.com/category/healthai/CIeOmsPoB1YlP0An.html
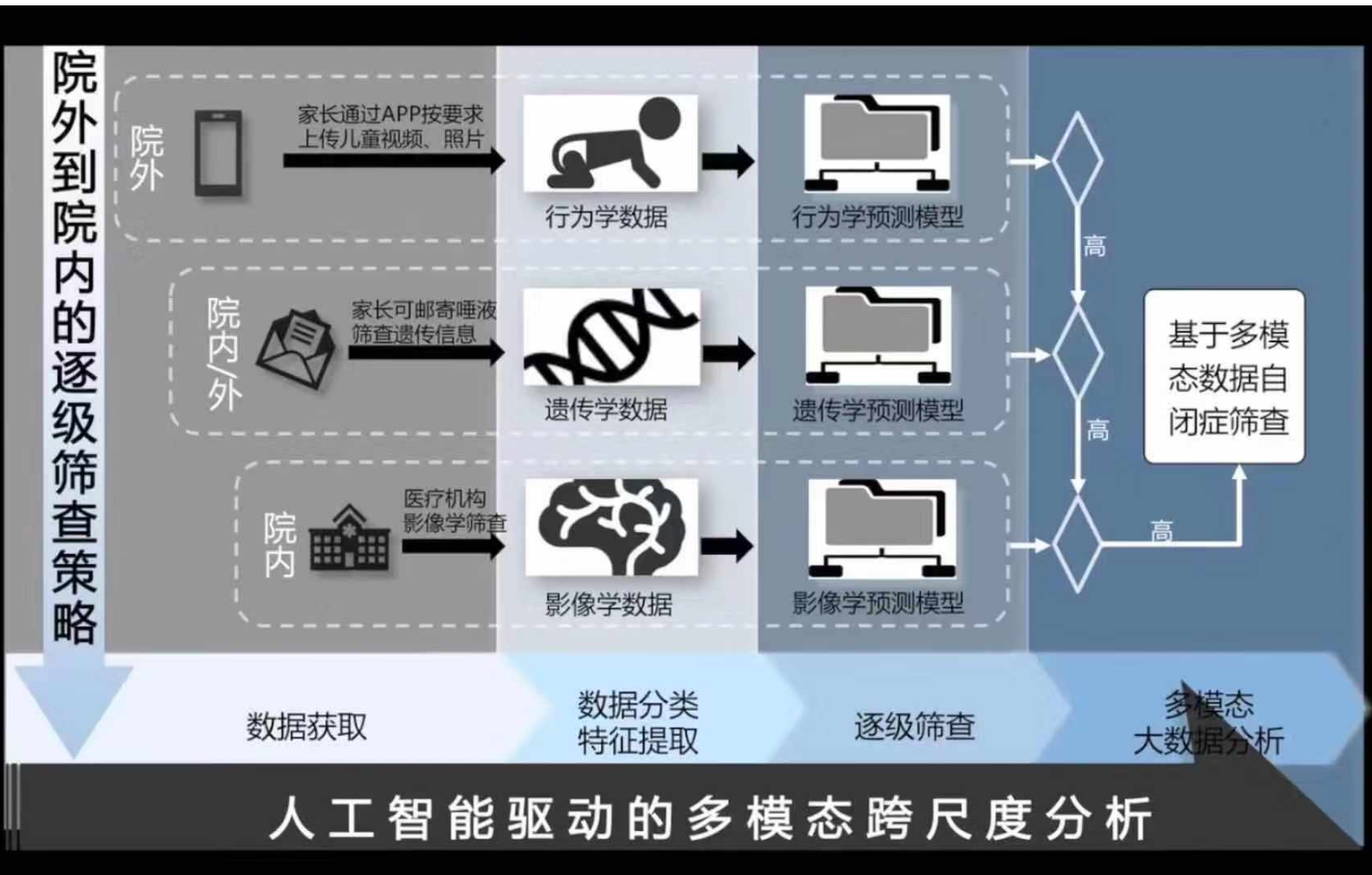

以前做医学图像分类,就是纯图像做的,现在是融合多个信息源来做,多模态融合了。
在临床诊断中,为了做出准确的决策,医生通常需要综合考虑患者的主诉、医学影像和实验室化验结果等多模态信息。
多模态融合方法分析与分类
目的:开发高效的多模态融合方法,以提高多模态诊断的准确性和效率。
解法:多模态融合方法可以分为三类:早期融合、晚期融合和混合融合。
如何用算法融合,是前融合、中融合还是后融合?
- 后融合就是每个人决定做好了,再来做预测
- 中融合是中间算法加了东西
- 前融合是数据结合起来一起融合
1. 早期融合方法
子解法1:特征层融合
- 特征:在特征层级别进行融合,先从每种模态中提取特征,然后进行融合。
- 举例:主成分分析(PCA)用于降维,融合特征以减少冗余。
子解法2:数据层融合
- 特征:直接在原始数据层面进行融合,减少特征提取步骤。
- 举例:在卷积神经网络中直接对图像和文本数据进行卷积和池化。
2. 晚期融合方法
子解法1:决策层融合
- 特征:对不同模态分别进行处理,然后将各自的结果进行融合。
- 举例:使用贝叶斯规则融合、最大值融合和平均值融合来组合不同模型的输出。
子解法2:规则融合
- 特征:基于预定义的规则将各个模型的结果融合。
- 举例:集成学习,通过多个分类器的组合提高预测准确性。
3. 混合融合方法
子解法1:双层融合
- 特征:结合早期融合和晚期融合的优点,同时捕捉特征关系和处理过拟合问题。
- 举例:在视频和声音信号融合中,先进行基于单一模态的特征提取,再进行多模态特征融合。
子解法2:分层融合
- 特征:在不同层次上进行融合,利用各层特征的互补性。
- 举例:在神经网络中,先对不同模态数据进行特征提取,再在更高层次上进行融合。
总结:
- 早期融合:能较好地捕捉特征间关系,但易过拟合。
- 晚期融合:处理过拟合效果好,但不允许分类器同时训练所有数据。
- 混合融合:灵活应用早期和晚期融合,性能更优。
根据融合阶段的不同,可以将传统的非统一的多模态融合方法划分为两个大类,即早期和晚期融合。
然而,无论是早期还是晚期融合都选择将多模态诊断过程分离成两个相对独立的阶段:对每种模态单独进行特征抽取和多个模态特征的融合。
这种设计有一个天然的局限性:无法发现和编码不同模态之间的内部关联。
传统非统一的多模态融合方法的局限性
早期融合:
- 方法:在每种模态单独进行特征抽取,然后在特征层面进行融合。
- 局限性:在特征抽取之前进行融合,难以捕捉模态间的高层次相关性。
- 例子:对图像和文本数据进行PCA降维后再进行融合,无法充分利用图像中的空间信息和文本中的语义信息。
晚期融合:
- 方法:每种模态单独进行特征抽取和建模,然后在决策层面进行融合。
- 局限性:各模态的特征是独立学习的,无法发现模态间的内在关联。
- 例子:使用独立的CNN处理图像,用独立的RNN处理文本,最后将两者的输出进行加权平均。这种方法不能捕捉图像和文本之间的复杂关系。
传统方法示例:
- 场景:医学诊断,包括医学影像(如X光片)和电子病历文本。
- 早期融合:先分别对影像和文本进行特征提取,然后将提取的特征进行融合。这种方法无法有效利用影像和文本之间的内在关联,比如影像中发现的特征可能与病历文本中的描述高度相关,但这种关联在特征提取阶段就已经丢失了。
- 晚期融合:分别训练一个影像诊断模型和一个文本诊断模型,最后将两个模型的输出进行加权平均。这种方法同样无法捕捉影像和文本之间的复杂关系,导致诊断精度受限。
统一方法示例(IRENE):
- 场景:同样是医学诊断。
- 方法:使用统一的Transformer架构,直接从影像和文本的多模态输入数据中学习整体表征。通过双向多模态注意力机制,可以有效发现和编码影像和文本之间的相互关联,提高诊断精度。
统一的多模态融合方法(如IRENE)能够弥补早期和晚期融合的不足,通过直接从多模态输入中学习整体表征,捕捉不同模态间的内在关联,从而提高任务的整体性能。
论文:https://arxiv.org/pdf/2306.00864
代码:https://github.com/RL4M/IRENE/tree/main/models
IRENE算法通过中期融合策略,结合早期和晚期融合的优点,采用统一的Transformer架构和双向多模态注意力机制进行整体表征学习,避免了繁琐的文本结构化步骤,并能有效发现和编码不同模态间的相互关联。
IRENE 的核心是统一的多模态诊断 Transformer(即 MDT)和双向多模态注意力机制。
MDT 是一种新的 Transformer 堆叠结构,直接从多模态输入数据中生成诊断结果。
与之前的非统一方法不同,这种新算法通过渐进地从多模态临床信息中学习整体表征,放弃了单独学习各种模态特征的技术路线。
此外,MDT 赋予 IRENE 在非结构化原始文本上进行表征学习的能力,避免了非统一方法中繁琐的文本结构化步骤。
为了更好地处理模态之间的差异,IRENE 引入了双向多模态注意力机制,通过发现和编码不同模态之间的相互关联,将模态独立的特征表达和面向诊断的整体表征联系起来。
这个明确的学习和编码过程可以看作是 MDT 中整体多模态表征学习过程的补充。
IRENE 具有以下三个优点:
- 使用统一架构进行多模态表征学习,避免了分离的表征学习路径
- 无需进行繁琐的文本结构化步骤,直接在原始文本上进行表征学习
- 通过双向多模态注意力机制发现和编码不同模态之间的相互关联
IRENE 解法
子解法1:多模态表征学习
- 特征:直接在原始数据上进行表征学习,避免繁琐的文本结构化。
- 之所以用这个子解法:因为可以直接从医学影像、非结构化文本和结构化临床信息中提取特征,简化流程并提高效率。
子解法2:双向多模态注意力机制
- 特征:发现和编码不同模态之间的相互关联,增强信息交互。
- 之所以用这个子解法:因为通过自注意力机制在不同模态之间建立联系,提高诊断决策的准确性。
-
多模态嵌入层
- 特征:针对不同模态的数据进行嵌入处理。
- 之所以用这个子解法:因为将图像数据、文本数据和结构化数据分别转换为嵌入表示,有助于更好地利用不同类型数据的信息。
-
双向多模态注意力机制
- 特征:在Transformer的中间层,通过双向注意力机制融合不同模态的特征。
- 之所以用这个子解法:因为在处理文本特征时,结合图像和结构化数据的信息,可以提高诊断的整体性能。
-
统一编码器
- 特征:将融合后的多模态特征进行统一编码。
- 之所以用这个子解法:因为使用多层Transformer对融合特征进行编码,能提取高级语义信息。
-
分类器
- 特征:对编码后的特征进行分类预测。
- 之所以用这个子解法:因为使用多层感知器(MLP)对提取的特征进行分类,能够输出准确的诊断结果。
-
前期嵌入:
- 图像数据:使用CNN将X光片转换为嵌入表示。
- 文本数据:使用BERT将电子病历文本转换为嵌入表示。
- 结构化数据:将实验室结果转换为嵌入表示。
-
中期融合:
- 双向多模态注意力机制:将图像、文本和结构化数据的嵌入输入到Transformer的多头自注意力机制中,计算模态之间的相互关联,并在中间层进行融合,提取全局特征。
-
编码和分类:
- 编码器:将融合后的多模态特征输入到多层Transformer进行编码,提取高级语义信息。
- 分类器:使用多层感知器(MLP)对编码后的特征进行分类,输出诊断结果(如诊断是否患有某种疾病)。
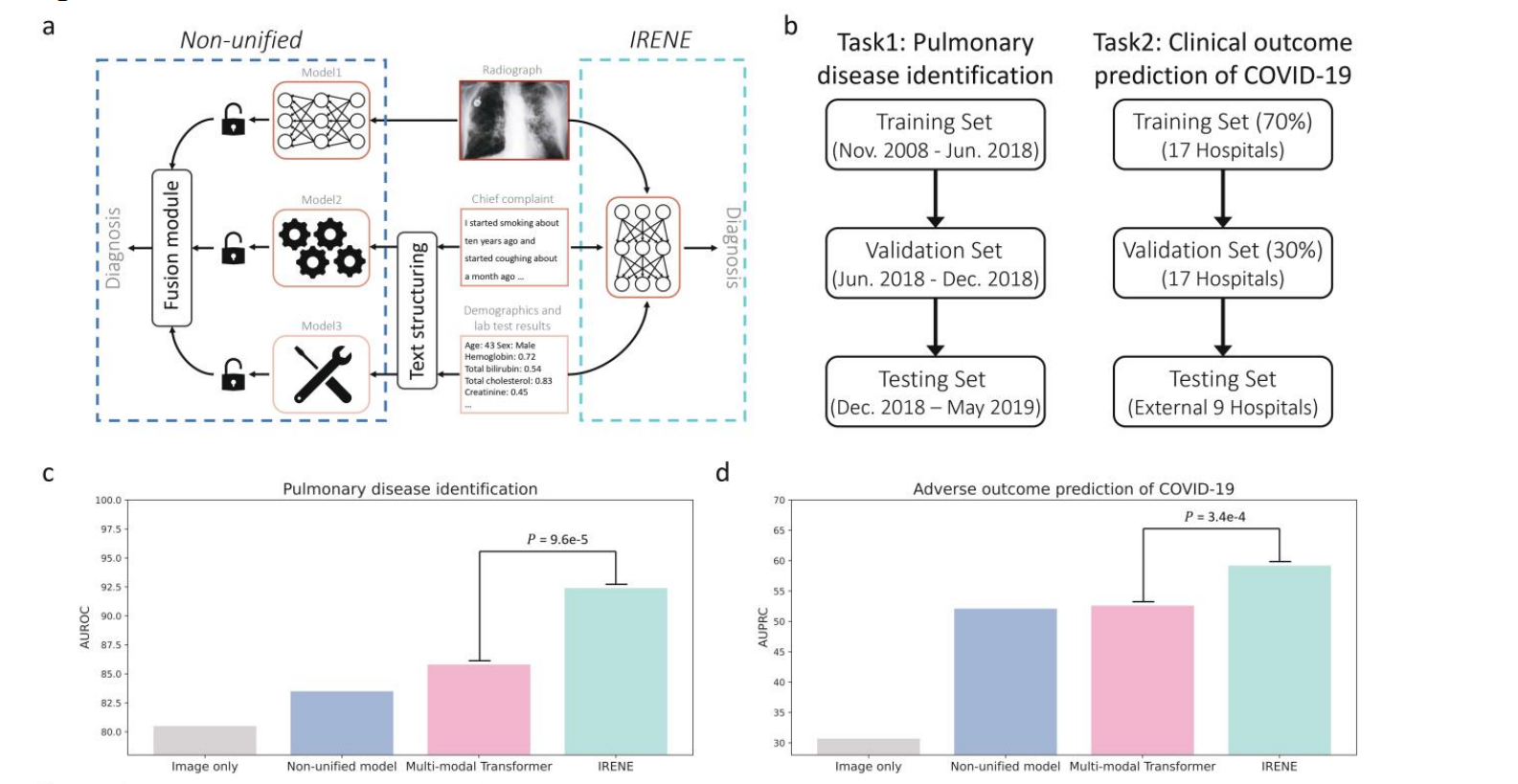
图a:融合方法对比
-
Non-unified(非统一)方法:
- 每种模态(如放射影像、主诉文本、临床数据)使用不同的模型分别处理。
- 各模态独立提取特征,最后在融合模块进行特征融合。
- 存在无法捕捉模态间高层次相关性的问题。
-
IRENE方法:
- 使用统一的Transformer架构直接从多模态输入中学习整体表征。
- 双向多模态注意力机制,能捕捉并编码模态间的相互关联。
- 避免繁琐的文本结构化步骤,提高诊断准确性和效率。
图b:实验设计
- 任务1:肺部疾病识别,数据集分为训练集、验证集和测试集。
- 任务2:COVID-19临床结果预测,数据集同样分为训练集、验证集和测试集。
图c:肺部疾病识别结果
- IRENE算法在识别肺部疾病任务中的AUROC(面积下的接收者操作特征曲线)得分显著高于仅使用图像、非统一模型和多模态Transformer。
图d:COVID-19不良结果预测
- IRENE算法在预测COVID-19不良结果任务中的AUPRC(面积下的精确召回曲线)得分也显著高于其他方法。
医学影像与文本数据融合:
- 传统方法:独立使用CNN处理X光片,使用RNN处理电子病历文本,最后将两者的输出通过简单加权平均进行融合。
- IRENE方法:使用统一的Transformer架构,将X光片、电子病历文本和结构化数据作为输入,通过双向多模态注意力机制进行中期融合,捕捉模态间的复杂关系,提高诊断准确性。
IRENE算法的具体架构、双向多模态注意力机制的工作原理
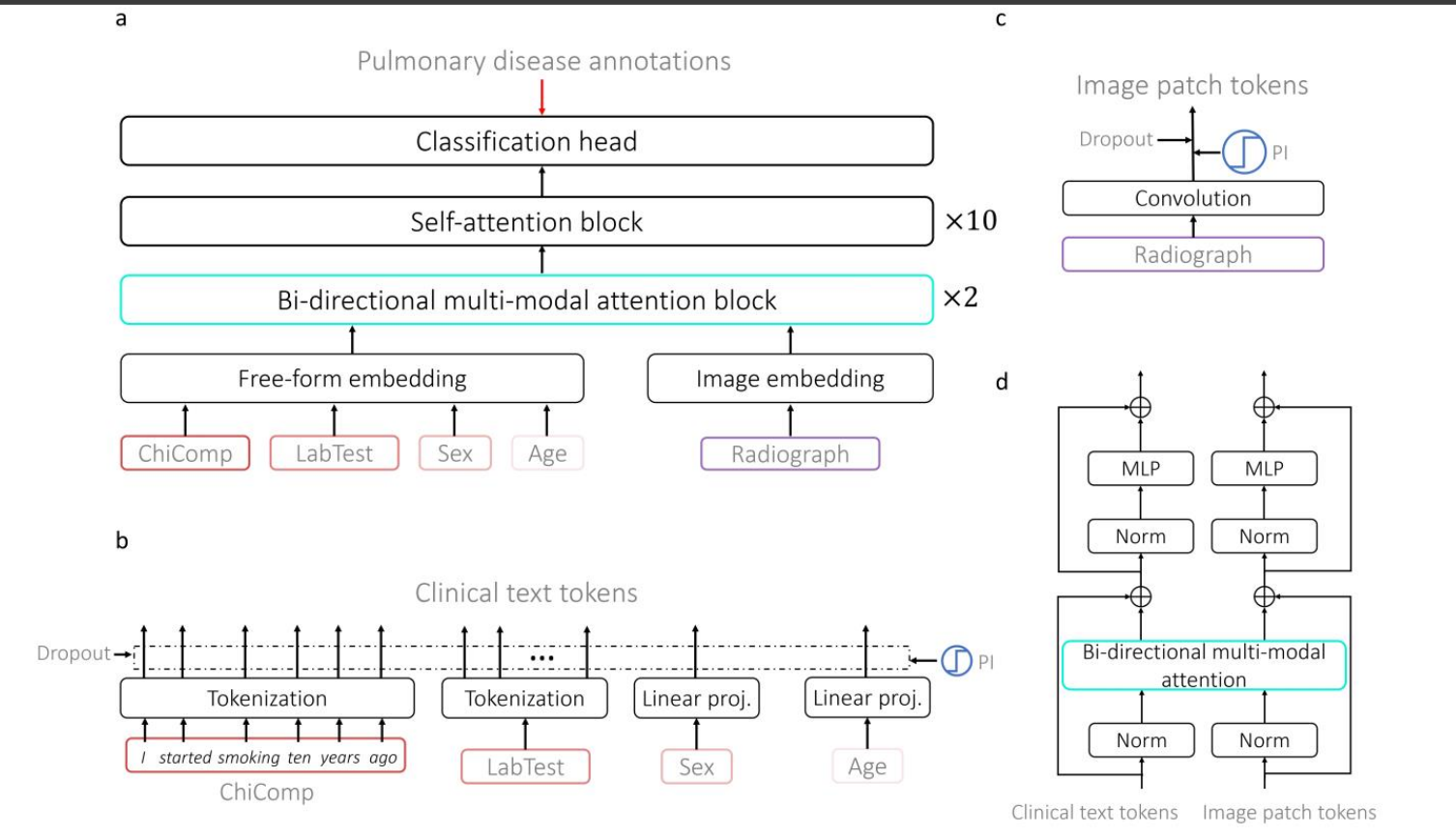
a. IRENE总体架构
- Free-form embedding:将不同模态的数据(如主诉文本、实验室测试结果、性别、年龄、放射影像)转换为嵌入表示。
- Bi-directional multi-modal attention block:使用双向多模态注意力机制进行融合,提取全局特征。
- Self-attention block:进行多层自注意力计算,进一步提取高级特征。
- Classification head:最终进行分类预测。
b. 临床文本嵌入
- Tokenization:将临床文本(如患者主诉)分词,并转换为向量表示。
- Linear projection:线性投影生成临床文本的嵌入表示。
c. 图像嵌入
- Convolution:对放射影像进行卷积处理,生成图像块嵌入。
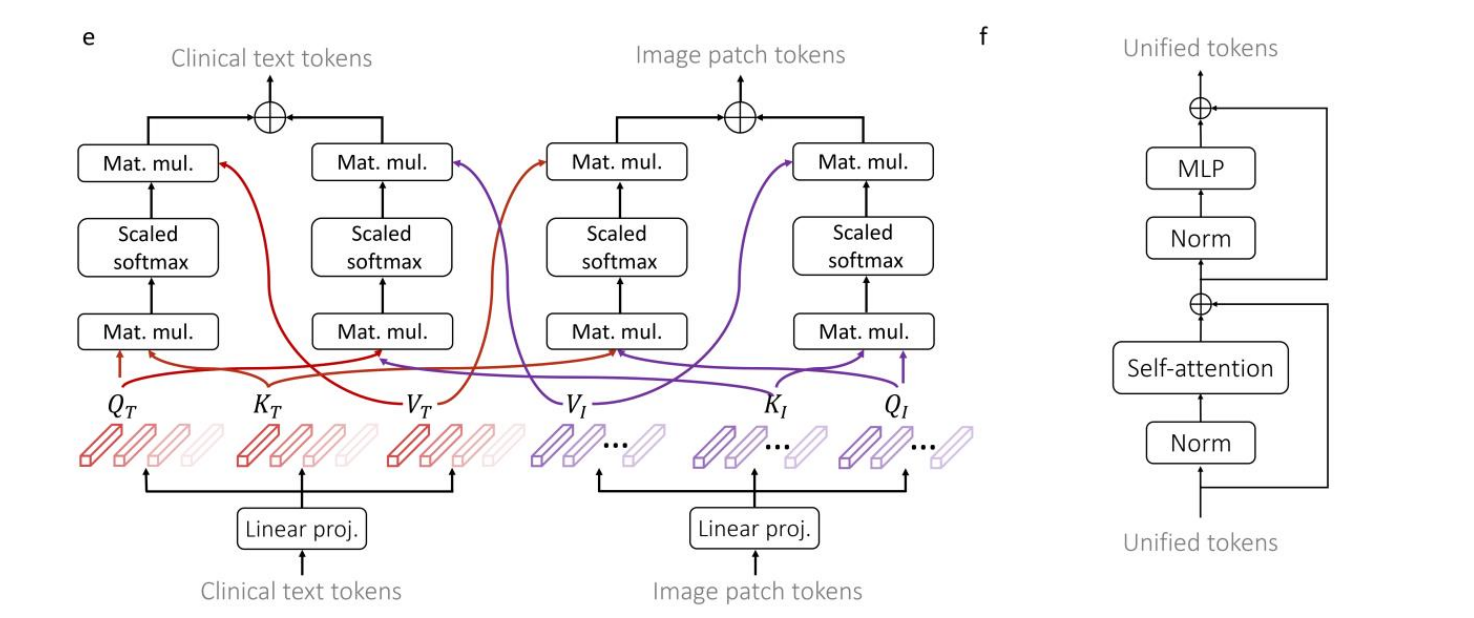
d. 双向多模态注意力
- MLP和Norm:标准的多层感知器和归一化层。
- Bi-directional multi-modal attention:处理临床文本和图像块的嵌入,捕捉模态间的相互关系。
e. 双向多模态注意力机制
- Mat. mul.:矩阵乘法计算注意力权重。
- Scaled softmax:缩放后的Softmax函数,计算注意力分布。
- Clinical text tokens和Image patch tokens:处理临床文本和图像块的嵌入,进行相互注意力计算。
f. 统一嵌入
- Unified tokens:将融合后的多模态嵌入统一表示。
- MLP和Self-attention:进一步处理融合后的嵌入,进行分类预测。
医学影像与文本数据融合:
- 传统方法:独立使用CNN处理X光片,用RNN处理电子病历文本,最后通过简单加权平均进行融合。
- IRENE方法:使用统一的Transformer架构,将X光片、电子病历文本和结构化数据作为输入,通过双向多模态注意力机制进行中期融合,捕捉模态间的复杂关系,提高诊断准确性。
这种架构通过双向多模态注意力机制,在不同模态的数据之间建立联系,生成统一的嵌入表示,从而提高模型的诊断性能。
背景:开发一个医学诊断模型,使用患者的医学影像(如X光片)、电子病历文本和结构化临床数据(如实验室结果)来提高诊断准确性。
具体实现
-
前期嵌入:
- 图像数据:使用CNN将X光片转换为嵌入表示。
- 文本数据:使用BERT将电子病历文本转换为嵌入表示。
- 结构化数据:将实验室结果转换为嵌入表示。
-
中期融合:
- 双向多模态注意力机制:
- 将图像、文本和结构化数据的嵌入输入到Transformer的多头自注意力机制中,计算模态之间的相互关联。
- 在中间层进行融合,提取全局特征。
- 双向多模态注意力机制:
-
统一编码和分类:
- 编码器:将融合后的多模态特征输入到多层Transformer进行编码,提取高级语义信息。
- 分类器:使用多层感知器(MLP)对编码后的特征进行分类,输出诊断结果(如诊断是否患有某种疾病)。
示例流程
- 输入:一位患者的X光片、电子病历文本和实验室结果。
- 前期嵌入:
- 图像:CNN提取图像特征。
- 文本:BERT提取文本特征。
- 结构化数据:转换为向量表示。
- 中期融合:使用双向多模态注意力机制将图像、文本和结构化数据的特征融合在一起。
- 编码和分类:Transformer对融合后的特征进行编码,并通过MLP进行分类,最终输出诊断结果。
这种方法可以在中间层捕捉不同模态之间的关系,提高诊断的准确性和效率。
多模态Transformer 对比 大模型Transformer
主要体现在设计和处理方式上.
IRENE算法
- 专门设计:IRENE专为处理多模态临床数据设计,可能包含针对医疗任务的特定模块。
- 融合策略:IRENE可能采用中期融合,通过特定层将不同模态的数据在中间层融合,增强信息交互。
- 轻量化:相对于大模型,IRENE可能更轻量化,适用于特定的临床数据处理任务。
大模型Transformer
- 通用设计:大模型Transformer(如GPT-4、BERT)设计更通用,可以处理各种任务。
- 复杂架构:大模型可能采用更复杂的融合策略和层次结构,处理大规模、多模态数据。
- 资源消耗:大模型通常需要更多的计算资源和数据支持,适用于大规模医疗数据分析和复杂任务。
具体区别
- 任务适应性:IRENE专注于特定临床任务,可能在处理特定类型数据上更高效。大模型则具有更广泛的适用性。
- 融合机制:IRENE可能更注重中期融合,提高不同模态数据的交互性。大模型可能使用多种融合策略,包括前期、中期和晚期融合。
- 计算资源:大模型需要更多的计算资源和训练数据,适用于大规模、多任务处理。IRENE可能更轻量级,适合特定的临床应用。
IRENE针对特定的多模态医疗任务进行了优化,而大模型Transformer则更通用,适用于更广泛的多模态数据处理任务。具体实现和设计上的差异需要结合各自的代码和应用场景进行详细分析。
IRENE算法如何从单一模型变成针对多模态数据的特定处理机制和层,以及在注意力机制和块结构上具体做了哪些改进
多模态处理机制和层
-
多模态嵌入层:
- 普通Transformer:处理单一类型的数据(如文本)的嵌入层。
- IRENE:包含多个嵌入层,每个模态(如图像、文本、音频等)各自有专门的嵌入层。通过这种方式,模型可以处理多模态数据。
-
融合层:
- 在嵌入层之后,IRENE添加了融合层,用于将不同模态的嵌入表示进行融合。这样可以将不同类型的数据整合到一个统一的表示中,便于后续处理。
注意力机制的改进
-
模态间注意力:
- 普通Transformer:使用标准的多头注意力机制来处理输入序列。
- IRENE:引入模态间注意力机制,专门用于计算不同模态之间的相关性。这样可以更好地捕捉不同模态数据之间的关系。
-
多级注意力:
- IRENE可能使用多级注意力机制,不仅在单个模态内进行注意力计算,还在多个模态之间进行分层注意力计算。
块结构的改进
-
自定义块结构:
- 普通Transformer:标准的编码器块由多头注意力机制和前馈神经网络组成。
- IRENE:可能在编码器块中加入了专门处理多模态数据的层,例如模态特定的处理层和模态融合层。
-
并行块处理:
- IRENE可能采用并行块处理机制,同时处理多种模态的数据,减少处理时间并提高效率。
代码分析
假设我们在modeling_irene.py文件中找到以下代码片段:
class MultiModalTransformer(nn.Module):def __init__(self, config):super(MultiModalTransformer, self).__init__()self.text_embedding = TextEmbedding(config)self.image_embedding = ImageEmbedding(config)self.audio_embedding = AudioEmbedding(config)self.fusion_layer = FusionLayer(config)self.encoder = Encoder(config)def forward(self, text, image, audio):text_emb = self.text_embedding(text)image_emb = self.image_embedding(image)audio_emb = self.audio_embedding(audio)fused_emb = self.fusion_layer(text_emb, image_emb, audio_emb)output = self.encoder(fused_emb)return output
- TextEmbedding/ImageEmbedding/AudioEmbedding:分别处理文本、图像和音频的嵌入层。
- FusionLayer:融合不同模态的嵌入表示。
- Encoder:在融合后的表示上进行编码。
通过这种设计,IRENE可以高效地处理多模态数据,并通过改进的注意力机制和块结构提升性能。
详细代码和实现可以参考GitHub仓库。