引言
随着自动驾驶技术的迅速发展,特斯拉的全自动驾驶(FSD)系统也在不断进化。最近,特斯拉开始采用端到端的模型来优化其FSD算法,这种变革引发了广泛关注。本文将探讨特斯拉FSD在车载计算能力和模型压缩技术方面的最新进展,并通过一张详细的对比表,展示特斯拉与其他车厂在自动驾驶算力方面的对比。

端到端设计对车载计算能力的挑战
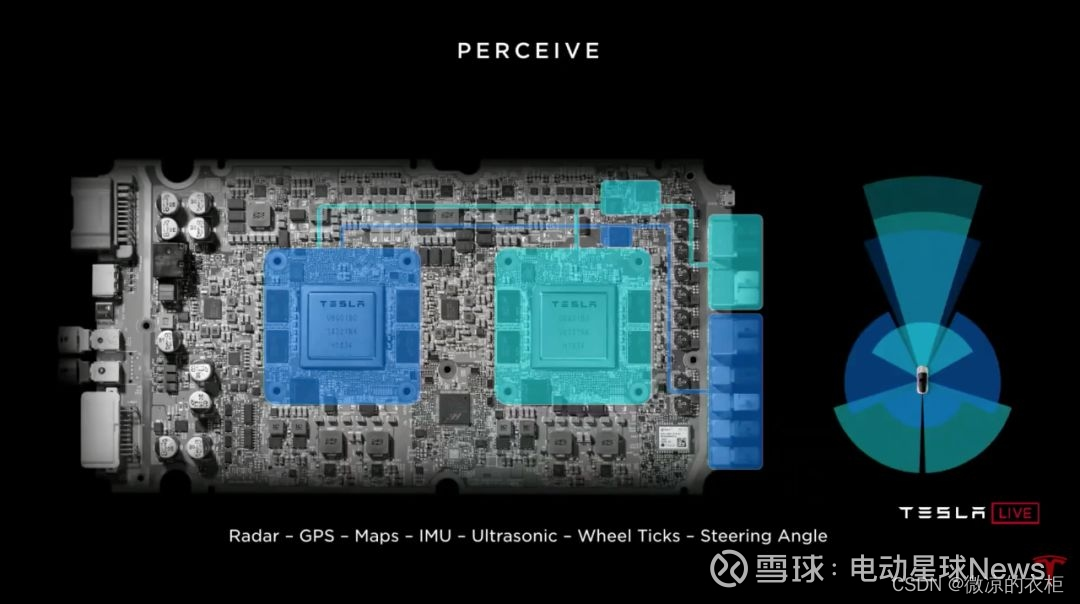
端到端设计的采用大大增加了对计算资源的需求。特斯拉自动驾驶的核心,FSD计算单元,在硬件3.0和4.0版本间有显著的升级。硬件3.0配置了两块特斯拉自研的SOC芯片,每块芯片提供72TOPS的算力,由于设计为双机冗余,实际可用算力为72TOPS。而在硬件4.0中,特斯拉将每块SOC的NPU从两个增加到三个,并提升了主频,使得单个SOC的算力提升到约122TOPS,整体可用算力增加至244TOPS。
模型压缩技术的应用
为了在有限的车载计算资源上运行复杂的端到端模型,特斯拉采用了模型压缩技术。模型压缩通常包括减脂量化和知识蒸馏等手段。通过这些技术,可以显著减小模型的体积,同时保持或仅轻微降低模型的性能。特斯拉采用INT8精度来执行模型推理,既保证了运算速度,又节省了存储空间。
模型量化与结构化剪枝
量化技术通过降低数据精度(如从FP32转为INT8),在几乎不损失精度的前提下减小模型大小和提高运算速度。此外,结构化剪枝通过删除模型中不重要的权重或神经元来减少模型大小,这种方式虽然可能需要对模型进行微调,但能有效减少计算资源的需求。
硬件发展的未来展望
随着模型和算法的进一步优化,未来的特斯拉车辆可能需要更强大的计算单元来处理更复杂的任务。特斯拉可能会在未来的硬件版本中继续提升处理能力,例如硬件5.0可能会针对端到端模型进行专门优化,提供更高的算力来支撑更大的模型和更复杂的处理任务。
特斯拉与其他车厂自动驾驶算力对比表
| 车厂 | 硬件版本 | 算力(TOPS) | 配置细节 |
|---|---|---|---|
| 特斯拉 | 3.0 | 72 | 双SOC, 14NM Samsung, INT8精度 |
| 特斯拉 | 4.0 | 244 | 提升NPU数量与主频, 双SOC备份 |
| 小米 | SU七标准版 | 200 | 英伟达ORIN, 双芯片配置 |
| 奔驰 | MBUX | 1000+ | 四块ORIN芯片, 高算力配置 |
| 奥迪 | zFAS | 150 | 使用多个芯片,如Mobileye, Nvidia |
结论
虽然特斯拉的硬件在自动驾驶领域看似不占优势,但其通过技术创新如模型压缩和算法优化,成功实现了在较低的硬件成本下运行复杂的自动驾驶软件。这种策略不仅减少了成本,也降低了能耗,展示了特斯拉在自动驾驶技术领域的独到见解和创新能力。
推荐阅读资源
- 特斯拉自动驾驶技术详解
- 端到端学习在自动驾驶中的应用
- 深入浅出模型压缩与网络剪枝