作者:来自 Elastic Valentin Crettaz
当需要搜索自由文本并且 Ctrl+F / Cmd+F 不再有效时,使用词法搜索引擎通常是你想到的下一个合理选择。 词汇搜索引擎擅长分析要搜索的文本并将其标记为可在搜索时匹配的术语,但在理解和理解被索引和搜索的文本的真正含义时通常会表现不佳。
这正是向量搜索引擎的闪光点。 他们可以对同一文本进行索引,以便可以根据它所代表的含义及其与具有相似或相关含义的其他概念的关系来搜索该文本。
在本博客中,我们将简要介绍向量如何成为传达文本含义的重要数学概念。 然后,我们将深入研究 Elasticsearch 在搜索邻近向量时支持的不同相似性技术,即搜索具有相似含义的向量,以及如何对它们进行评分。
什么是向量嵌入?
本文不会深入探讨向量嵌入的复杂性。 如果你想进一步探索此主题或在继续之前需要入门知识,我们建议你查看以下指南。
简而言之,向量嵌入是通过机器学习过程(例如深度学习神经网络)获得的,该过程将任何类型的非结构化输入数据(例如原始文本、图像、视频、声音等)转换为带有其含义的数值数据和关系。 不同类型的非结构化数据需要不同类型的机器学习模型,这些模型经过训练可以 “理解” 每种类型的数据。

每个向量将特定的数据块定位为多维空间中的一个点,并且该位置表示模型用来表征数据的一组特征。 维度的数量取决于机器学习模型,但通常在几百到几千之间。 例如,OpenAI Embeddings 模型拥有 1536 个维度,而 Cohere Embeddings 模型的维度范围为 382 到 4096 个。 截至最新版本,Elasticsearch 的 dense_vector 字段类型最多支持 4096 个维度。
向量嵌入的真正壮举是具有相似含义的数据点在空间中靠近在一起。 另一个有趣的方面是向量嵌入还有助于捕获数据点之间的关系。
我们如何比较向量?
知道非结构化数据被机器学习模型分割成向量嵌入,从而捕获数据在多个维度上的相似性,我们现在需要了解这些向量的匹配是如何工作的。 事实证明,答案非常简单。
彼此接近的向量嵌入表示语义相似的数据片段。 因此,当我们查询向量数据库时,首先使用与索引所有非结构化数据相同的机器学习模型将搜索输入(图像、文本等)转换为向量嵌入,最终目标是找到与该查询向量最近的相邻向量。 因此,我们需要做的就是弄清楚如何测量查询向量与数据库中索引的所有现有向量之间的 “距离” 或 “相似度” - 就是这么简单。
距离、相似度和评分
幸运的是,由于向量算术,测量两个向量之间的距离或相似度是一个很容易解决的问题。 那么,让我们看看 Elasticsearch 支持的最流行的距离和相似度函数。 警告,有数学公式!
在我们深入讨论之前,让我们快速浏览一下得分。 事实上,Lucene 只允许分数为正。 我们将很快介绍的所有距离和相似度函数都会产生两个向量的接近或相似程度的度量,但这些原始数字很少适合用作分数,因为它们可能是负数。 因此,最终得分需要从距离或相似度值中得出,以确保得分为正,并且较大的得分对应于较高的排名(即更接近的向量)。
L1 距离
两个向量的 L1 距离,也称为曼哈顿距离,是指两个向量 及
通过将所有元素的成对绝对差相加来测量。显然
距离越小,两个向量越接近。 L1 距离公式(1)非常简单,如下所示

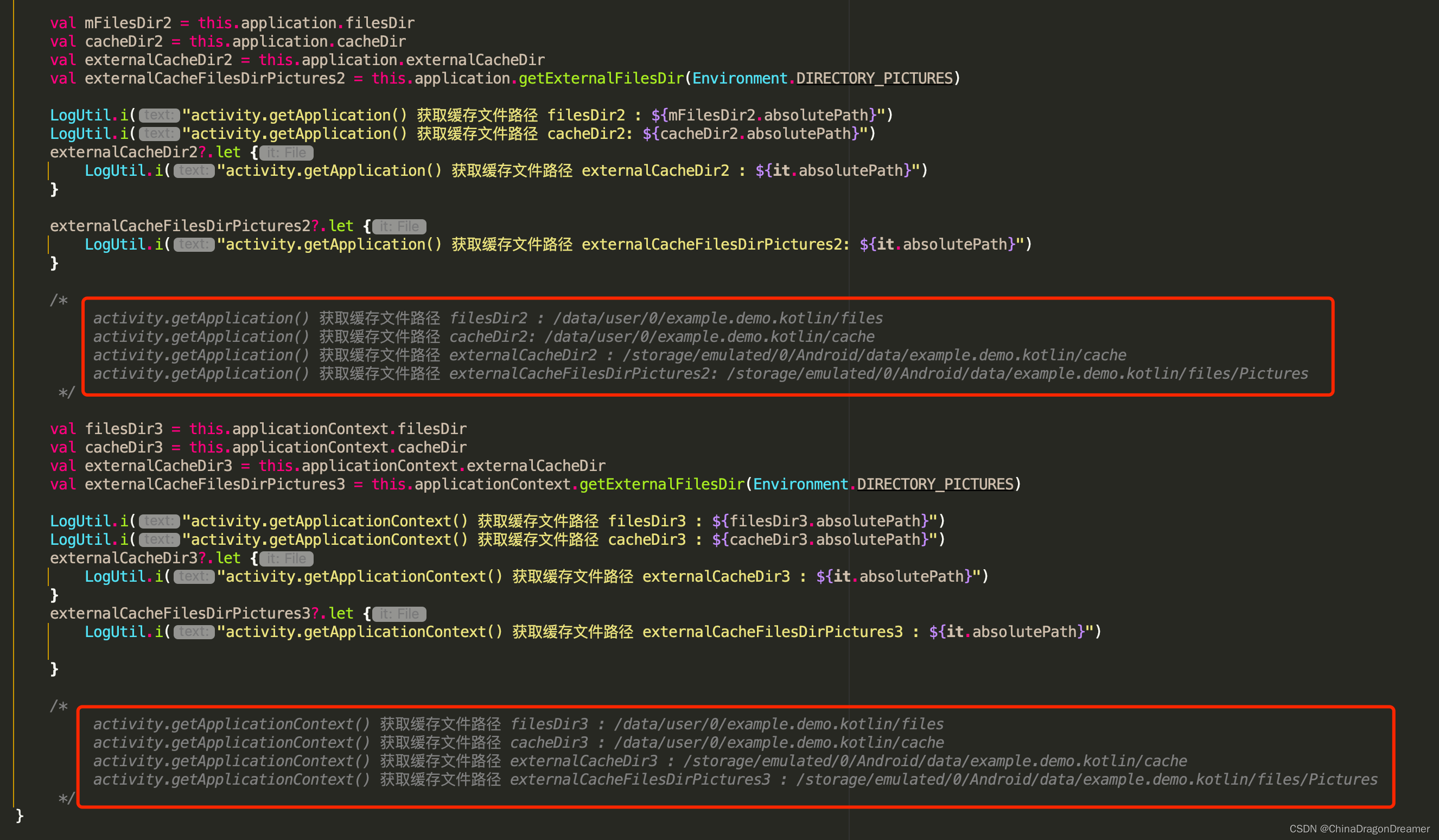
从视觉上看,L1 距离可以如下图所示(红色):

计算以下两个向量的 L1 距离 及
将生成 ∣1–2∣+∣2–0.5∣=2.5。
重要提示:值得注意的是,L1 距离函数仅支持使用 script_score DSL 查询的精确向量搜索(也称为强力搜索),而不支持使用knn 搜索选项或 knn DSL 查询的近似 kNN 搜索。
L2 距离
两个向量的 L2 距离,也称为欧几里德距离, 向量 和向量
之间的距离通过首先将所有元素的成对差值的平方相加。然后对结果求平方根来测量。 它基本上是两点之间的最短路径。 与L1类似,
距离越小,两个向量越接近:

L2 距离如下图红色所示:

让我们重用相同的两个样本向量 及
,正如我们所使用的
距离。我们现在可以计算
距离为:
=
1.803。
就评分而言,两个向量之间的距离越小,它们就越接近(即越相似)。 因此,为了得出分数,我们需要反转距离度量,以便最小的距离产生最高的分数。 使用 L2 距离计算分数的方式如下式(3)所示:

重用前面示例中的样本向量,它们的分数将是 。彼此非常接近的两个向量的分数将接近 1,而彼此相距很远的两个向量的分数将趋向于 0。
总结 L1 和 L2 距离函数,比较它们的一个很好的类比是将 A 和 B 视为纽约曼哈顿的两座建筑物。 从 A 到 B 的出租车必须沿着 L1 路径(街道和大道)行驶,而鸟可能会使用 L2 路径(直线)。
余弦相似度
与 L1 和 L2 相比,余弦相似度并不衡量两个向量 和
之间的距离,而是它们的相对角度,即它们是否都指向大致相同的方向。 相似度
越高 , 两个向量之间的角度 𝛼 越小,因此它们越 “接近” 并且它们传达的含义越 “相似”。
为了说明这一点,让我们想象一下在野外的两个人朝不同的方向看。 下图中,蓝衣人看向向量所代表的方向 及 红衣人向量方向上的
。他们越将视线转向同一方向(即,他们的向量越接近),蓝色和红色区域所代表的视野就越重叠。 他们的视野重叠程度就是他们的余弦相似度。 然而,请注意,人 B 看起来比人 A 更远(即向量
更长)。B 可能正在看着地平线上远处的一座山,而 A 可能正在看着附近的一棵树。 对于余弦相似度,这不起作用,因为它仅与角度有关。

现在让我们计算余弦相似度。 公式 (4) 非常简单,其中分子由两个向量的点积组成,分母包含它们的大小(即它们的长度)的乘积:

和
之间的余弦相似度如下图所示,作为它们之间角度的测量(红色):
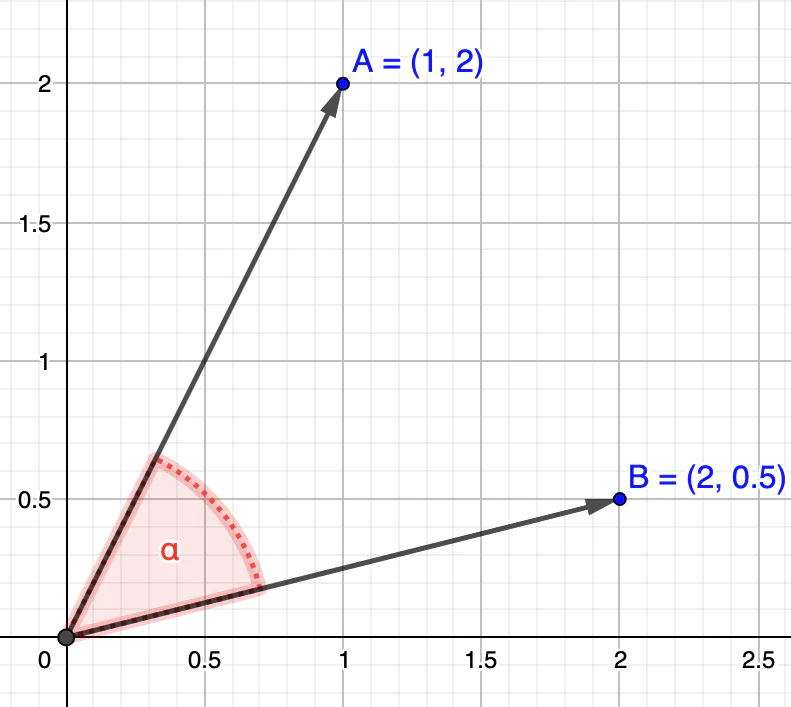
让我们快速绕一下,以便解释这些余弦相似度值的具体含义。 如下图所示,在余弦函数中,值总是在 [-1,1] 之间。

请记住,为了使两个向量被认为相似,它们的角度必须尽可能锐利,最好接近 0°。这可以归结为完美的相似度 1。换句话说,当向量 ...
1) 彼此靠近,它们的角度的余弦接近 1 (即接近 0° )

2)不相关,它们的角度的余弦接近 0 (即接近 90°)

3)相反,它们的角度的余弦接近 -1 (即接近 180°)

现在我们知道如何计算两个向量之间的余弦相似度,并且知道如何解释结果值,我们可以重用相同的样本向量 及
并使用我们之前看到的公式(4)计算它们的余弦相似度:
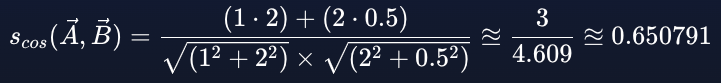
我们得到相似度 0.650791,比 0 相比较,更接近 1。意味着两个向量有些相似,即不完全相似,但也不是完全不相关,当然也不具有相反的含义。
为了从任何余弦相似度值中得出正分数,我们需要使用下面的公式(5),它将余弦相似度值在 [-1,1] 之间震荡,而分数介于 [0. 1] 之间:

样本向量 及
的分数将是:
。
点积相似度
余弦相似度的一个缺点是,它只考虑两个向量之间的角度,而不考虑它们的大小,这意味着如果两个向量大致指向同一方向,但其中一个比另一个长得多,则两个向量仍将被视为相似。 点积相似度(也称为标量相似度或内积相似度)通过考虑向量的角度和大小来改进这一点,从而提供更准确的相似度度量。 为了使向量的大小无关,点积相似度要求首先对向量进行归一化,因此我们最终只比较单位长度为 1 的向量。
让我们尝试用与之前相同的两个人再次说明这一点,但这一次,我们将他们放在圆形房间的中间,以便他们的视线范围完全相同(即房间的半径)。 与余弦相似度类似,它们越转向同一方向(即它们的向量越接近),它们的视野重叠就越多。 然而,与余弦相似性不同,两个向量具有相同的长度并且两个区域具有相同的表面,这意味着两个人在相同的距离处观看完全相同的图片。 这两个区域的重叠程度表示它们的点积相似性。
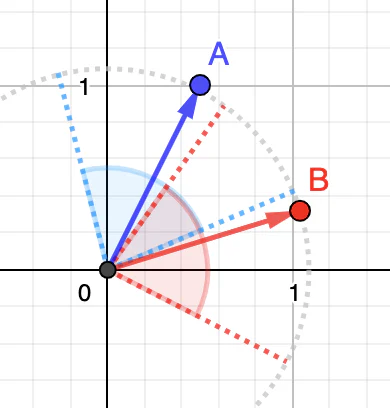
在介绍点积相似度公式之前,我们先快速了解一下如何对向量进行归一化。 这非常简单,只需两个简单的步骤即可完成:
- 计算向量的大小
- 将每个分量除以 1 中获得的大小。
作为例子,我们以向量 =
为例,我们可以计算它的大小
正如我们之前在回顾余弦相似度时所看到的,即
。然后,将向量的每个分量除以其大小,我们得到以下归一化向量:

对第二个向量 =
进行相同的过程将产生以下归一化向量
:

为了导出点积相似度公式,我们可以使用公式(4)计算归一化向量 和
之间的余弦相似度,如下:

由于现在两个归一化向量的大小都是 1,点积相似度公式(6)就变成了……你猜对了,两个归一化向量的点积:
![]()

使用我们的新公式(6),我们可以计算两个归一化向量的点积相似度,毫不奇怪,它产生与余弦向量完全相同的相似度值:

利用点积相似度时,根据向量是否包含浮点值或字节值,计算分数的方式有所不同。 在前一种情况下,分数的计算方式与余弦相似度相同,使用下面的公式 (7):

然而,当向量由字节值组成时,评分的计算方式略有不同,如下面的公式(8)所示,其中 dims 是向量的维数:

此外,为了产生准确的分数,所有向量(包括查询向量)必须具有相同的长度,但不一定是 1。
最大内积相似度
自版本 8.11 以来,出现了一个新的相似度函数,它比点积相似度的约束更少,因为向量不需要标准化。 其主要原因将在下一篇文章中详细解释,但总而言之,某些数据集不太适合对其向量进行归一化(例如 Cohere 嵌入),这样做可能会导致相关性问题。
计算最大内积相似度的公式与点积一(6)完全相同。 改变的是通过使用分段函数缩放最大内积相似度来计算分数的方式,分段函数的公式取决于相似度是正还是负,如下面的公式(9)所示:
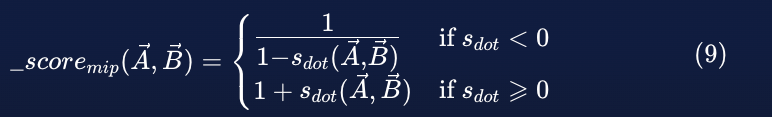
这个分段函数的作用是缩放所有负最大内积相似度值到区间 [0,1] 并且所有正值到区间 [1,∞]。
总之
从数学上来说,这是一次相当长的旅程,但这里有一些你可能会发现有用的要点。
你可以使用哪种相似度函数,最终取决于你的向量嵌入是否归一化。 如果你的向量已归一化,或者你的数据集与向量归一化无关(即,相关性不会受到影响),你可以继续归一化你的向量并使用点积相似度,因为它的计算速度比余弦快得多因为不需要计算每个向量的长度。 当比较数百万个向量时,这些计算量加起来会相当大。
如果你的向量未归一化,那么你有两种选择:
- 如果无法选择向量归一化,请使用余弦相似度
- 如果你希望向量的大小有助于评分,请使用新的最大内积相似度,因为它们确实具有意义(例如,Cohere 嵌入)
此时,计算向量嵌入之间的距离或相似度以及如何得出它们的分数对你来说应该有意义。 我们希望你觉得这篇文章有用。
准备好将 RAG 构建到你的应用程序中了吗? 想要尝试使用矢量数据库的不同 LLMs?
在 Github 上查看我们的 LangChain、Cohere 等示例笔记本,并参加即将开始的 Elasticsearch 工程师培训!
原文:Vector similarity techniques and scoring — Elastic Search Labs





![Python 机器学习 基础 之 监督学习 [决策树集成] 算法 的简单说明](https://img-blog.csdnimg.cn/direct/38db55aef2814b9aac494fb93b408478.png)