文章目录
- 前言
- 一、常见的数据权限
- 二、通用数据权限设计思路
- 通用权限示例(灵活配置最简单方式)
- 两个表
- 业务理解
- 最终拼接出来的sql 为:
- 总结
前言
权限一般分为操作权限和数据权限
操作权限: 菜单,页面,按钮
数据权限: 能看到的数据,包括各种页面的数据范围
一、常见的数据权限
例如:
- 多租户,每个租户只能看到各自租户内部的数据
一般通过字段级别过滤,mybatis/mybatis-plus通常通过拦截器自动凭拼接或 手动拼接;
- 单独配置某个特定的数据权限: 例如之前的项目,单独分配区域权限,这样每个人可以灵活看到区域数据,达到数据权限的配置;
一般是特定的数据权限,类似于用户级别的属性一样,每次查询用户 单独查询,类似于菜单权限数据一样; 这里推荐将此类数据权限放在 角色 上
本文讲解,通用数据权限: 即类似于多租户的感觉,适用于所有表的过滤
与多租户不同的是,多租户的数据权限字段是固定的,不灵活,这里根据当前项目,分享两种灵活思路!
二、通用数据权限设计思路
- 通过类似枚举定义,在每个角色中,增加一个属性为数据范围, 分为各个等级; 其中等级的限制条件可以是各种维度的一种: 机构,区域,组织,然后类似于通过等级的不同,生成sql片段手动拼接到查询条件中;
例如: 当前组织以及子组织 (不是迭代)
sql片段为: org_code = 1 or org_code = 1-1
等级可以是: 当前组织; 子组织; 当前以及子组织; 当前以及迭代子集;当前组织的三级组织;等等
- 通过一种灵活的配置,达到不同字段的范围限制;
思路是通过exist / in 然后限制某个字段的值,这个字段是灵活的,可以自由配置,然后也是通过生成sql片段,手动拼接到查询中
通用权限示例(灵活配置最简单方式)
两个表
- 普通业务表 category
- 配置限制表 limit_table
CREATE DATABASE /*!32312 IF NOT EXISTS*/`test` /*!40100 DEFAULT CHARACTER SET latin1 */;USE `test`;/*Table structure for table `category` */DROP TABLE IF EXISTS `category`;CREATE TABLE `category` (`id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'id',`name` varchar(255) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '名称',`pid` int(11) DEFAULT NULL COMMENT '父节点id',PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci ROW_FORMAT=DYNAMIC;/*Data for the table `category` */insert into `category`(`id`,`name`,`pid`) values
(1,'文学',NULL),
(2,'童书',1),
(3,'社会科学',1),
(4,'经济学',1),
(5,'科普百科',2),
(7,'法律',3);/*Table structure for table `limit_table` */DROP TABLE IF EXISTS `limit_table`;CREATE TABLE `limit_table` (`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'ID',`field` varchar(55) CHARACTER SET utf8mb4 DEFAULT NULL COMMENT '字段',`field_value` varchar(255) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '值',PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci ROW_FORMAT=DYNAMIC COMMENT='留言表';/*Data for the table `limit_table` */insert into `limit_table`(`id`,`field`,`field_value`) values
(1,'name','文学'),
(2,'name','童书'),
(3,'title','你好'),
(4,'title','不好');/*!40101 SET SQL_MODE=@OLD_SQL_MODE */;
/*!40014 SET FOREIGN_KEY_CHECKS=@OLD_FOREIGN_KEY_CHECKS */;
/*!40014 SET UNIQUE_CHECKS=@OLD_UNIQUE_CHECKS */;
/*!40111 SET SQL_NOTES=@OLD_SQL_NOTES */;业务理解
我想通过限制表,限制业务表中的数据,具体是通过field中的name字段限制,限制条件在限制表的field_value中
最终拼接出来的sql 为:
SELECT c.* FROM
categoryc WHERE EXISTS (SELECT 1 FROMlimit_tableb WHERE b.field= ‘name’ AND b.field_value= c.name)
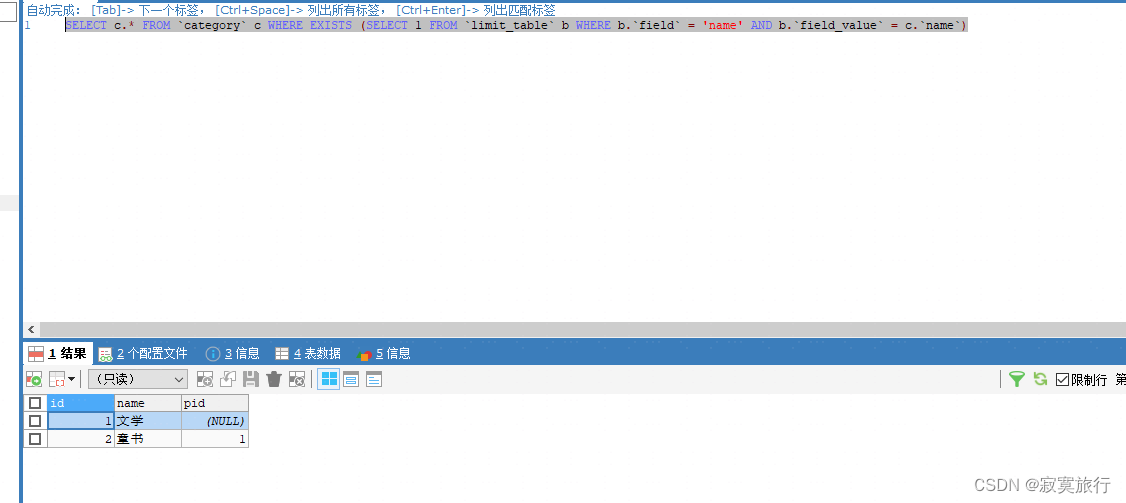
只有调用的人才知道具体要用哪个字段,限定哪张表,所以应该用哪个字段,以及用哪个表的哪个属性限制,需要调用的人传入;例如本示例中, b.
field= ‘name’ 中的 name 和 b.field_value= c.name中的 c.name为调用方传入的一对对应关系!!
这里最牛的思路我认为有两个:
- 通过exists 的特性加速查询,还是通过特性,达到了b.
field_value= c.name过滤效果 - 通过灵活的配置,以及传入参数实现了数据权限sql片段生成的灵活性
总结
这里不做扩展,其实这里仅仅是最简单的方式,即直接通过限制表达到对于业务表的数据过滤,那么其实我们还可以通过其他方式限制;
例如:
- 通过字典组限制,那么exists内部在拼接之前可能需要二次处理;
- 通过sql语句配置限定条件,那么我们需要拼接sql语句,甚至当sql语句中有变量,我们需要解析后,再拼接到sql片段中;
- 通过多个条件的限制,这里是单一条件,那么我可能有多个条件,这时候,这样的单表就无法满足了,我们需要创建更多的配置表,达到条件的配置以及组合( and / or 等),设置包括字典组和sql解析,然后最终形成一个复杂的sql片段;
单个条件组内的sql 需要 unin all
多个条件默认为 or