
Token
在继续前行之前,需要先停下来澄清下Token这个词,以及如何将原始的语料转化为Token,在细究背后的原理之后会更加优雅的理解大模型。任何的资讯都可以生成语料,而这些语料需要被机器理解以及供后续的模型训练,那么最常见的做法是将一段文字先切片,然后一一对应的转化为数字或者向量输入模型。通常而言有三种类型的分词法:基于单词、字符以及子词的分词法。单词和字符这里就不解释,字词法运用得最为广泛,也是最为主流。字词分词法包含了BPE、WordPiece、Unigram等。GPT等主流大模型也是采用BPE的分词法。
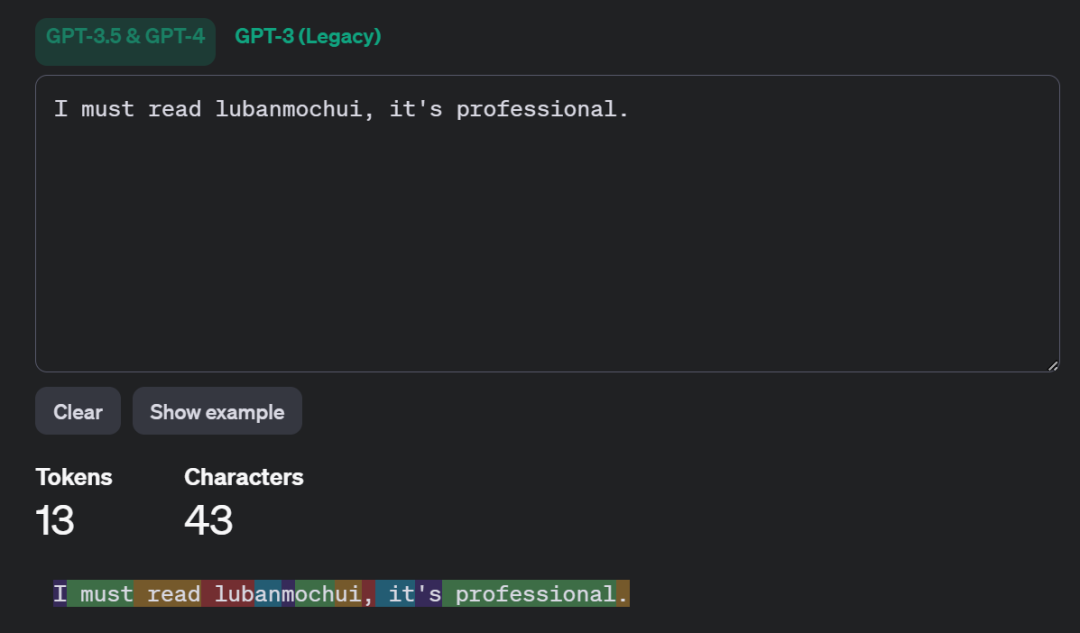
先从个列子开始以GPT-3.5为例,输入“I must read lubanmochui, it's professional.”,下图则表明整句话一共43个字符,按照不同的颜色块被切分成13份(Token)。而且每个Token都有与之对应的id。然后输入中文的时候,发现24个字符却被切成了30个Token。
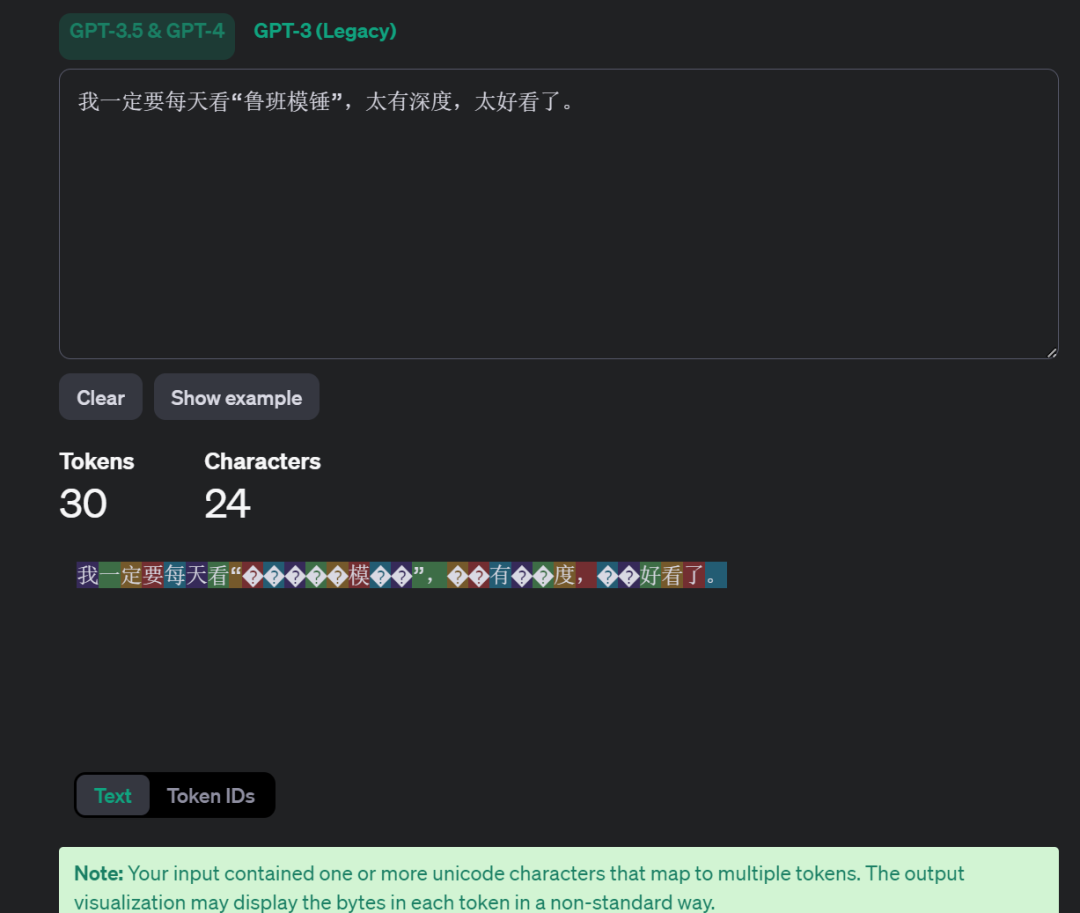
按照常识,中文不是应该一个字一个Token。因为这里举的例子是GPT,一个多语言模型,它覆盖了国际很多种语言。但是它并没有特殊的针对中文做适配,因此它采用了一种办法,将中文转为unicode,然后在按照英文的体系去切分,所以会看到有些切块是“?”的字符。其实这样一来,整体效率降低了,而且代价巨大,毕竟收费是基于Token数。

分词方法
BPE、WordPiece、SentencePiece等方法的技术专业性的详细拆解后续可以参见《大模型背后的基础模型》这个专栏。
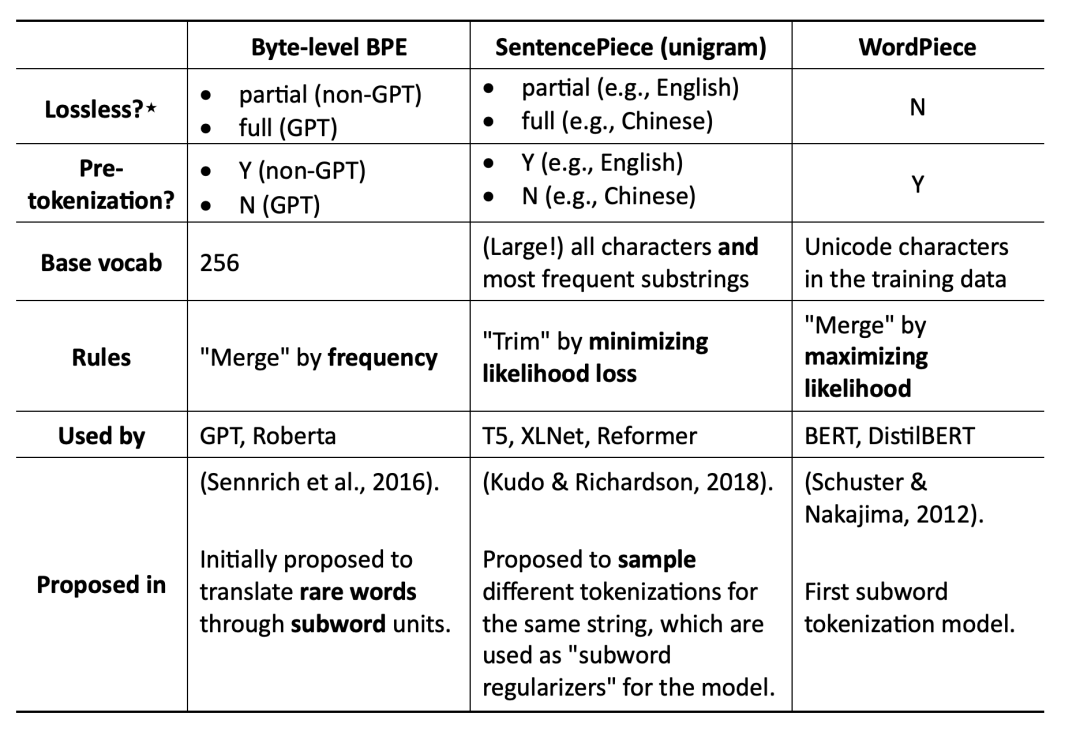
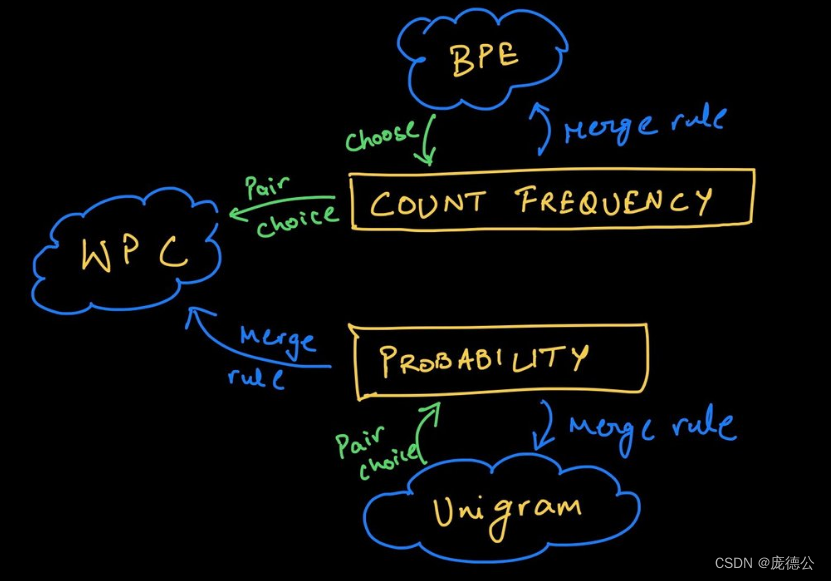
各种分词法对比,各种分词法都是基于大的词汇库然后按照特定的算法进行学习切分。BPE是贪婪而且是确定的,SentencePiece是可以针对同一个字符串进行反复的抽样。
BPE(Byte Pair Encoding)自于论文《Neural Machine Translation of Rare Words with Subword Units》。它是一种基于频率的分词方法,它从一个完整的词汇表开始,迭代地合并出现频率最高的字符对,直到预定的词汇表规模。例如:“I love lubanmochui.” 使用BPE分词法,首先将每个单词分割成字符,然后合并最常见的字符对。也许“love”会变成“lo”和“ve”,因为“lo”和“ve”在整个语料库中频繁出现。英语中“un”、“est”、“less”也经常被单独提炼出来。
WordPiece来至论文《Japanese and korean voice search》,和BPE一样在合并字符时除了考虑出现的频率,还考虑了合并后的token对整体语言模型的贡献,某种意义是基于概率的分词法。毕竟有些名词,例如针对蔬菜名合并和切分的意义不大,保留词汇的原始意义是最优的选择。
SentencePiece来至论文《Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates》。它是谷歌推出的子词开源工具包,其中集成了BPE、ULM子词算法。除此之外,SentencePiece还能支持字符和词级别的分词。为了能够处理多语言问题,SentencePiece将句子视为Unicode编码序列,从而子词算法不用依赖于语言的表示。

HuggingFace Tokenizer
HuggingFace(重量级的大模型社区)的介绍会放在后续,这里主要介绍下HuggingFace提供的Tokenizer的库。在HuggingFace里面它对于输入文本的处理流程(黄色部分)如下图所示,粉色则为处理的输出结果。

注意:
GPT, GPT-2, RoBERTa, BART, DeBERTa 等模型使用了 BPE,其中 GPT-2 使用了 byte-level BPE 。
BERT,DistilBERT,MobileBERT,Funnel Transformers,MPNET等模型使用了WordPiece。Hugging Face中的实现是基于已发表文献的模拟。
AlBERT,T5,mBART,Big Bird,XLNet等模型使用了 Unigram。
-
Normalization:标准化步骤,包括一些常规清理,例如删除不必要的空格、小写、以及删除重音符号
-
Pre-tokenization:tokenizer 不能单独在原始文本上进行训练。相反,我们首先需要将文本拆分为小的单元,例如单词。这就是pre-tokenization 步骤。基于单词的tokenizer可以简单地基于空白和标点符号将原始文本拆分为单词。这些词将是tokenizer在训练期间可以学习的子词边界
-
Model:执行tokenization从而生成token序列
-
Postprocessor:针对具体任务插入special token,以及生成attention mask和token-type ID