一、编写程序
(1). 按照tag分组统计生成的日志数。
在新开的终端内输入 vi spark_exercise_testsyslog1.py ,贴入如下代码并运行。运行之前需要关闭“tail终端”内的tail命令并重新运行tail命令,否则多次运行测试可能导致没有新数据生成。
#!/usr/bin/env python3from functools import partialfrom pyspark.sql import SparkSessionfrom pyspark.sql.functions import *if __name__ == "__main__":spark = SparkSession \.builder \.appName("Structuredcronlog") \.getOrCreate()lines = spark \.readStream \.format("socket") \.option("host", "localhost") \.option("port", 9988) \.load()# Nov 24 13:17:01 spark CRON[18455]: (root) CMD ( cd / && run-parts --report /etc/cron.hourly)# 定义一个偏应用函数,从固定的pattern获取日志内匹配的字段fields = partial(regexp_extract, str="value", pattern="^(\w{3}\s*\d{1,2} \d{2}:\d{2}:\d{2}) (.*?) (.*?)\[*\d*\]*: (.*)$")words = lines.select(unix_timestamp(format_string('2022 %s', fields(idx=1)), 'yy MMM d H:m:s').alias("timestamp"),fields(idx=2).alias("hadooplyf316"),fields(idx=3).alias("tag"),fields(idx=4).alias("content"),)# (1). 按照tag分组统计日志数。windowedCounts1 = words \.groupBy("tag") \.count()# 开始运行查询并在控制台输出query = windowedCounts1 \.writeStream \.outputMode("append") \.format("console") \.option('truncate', 'false')\.trigger(processingTime="3 seconds") \.start()query.awaitTermination()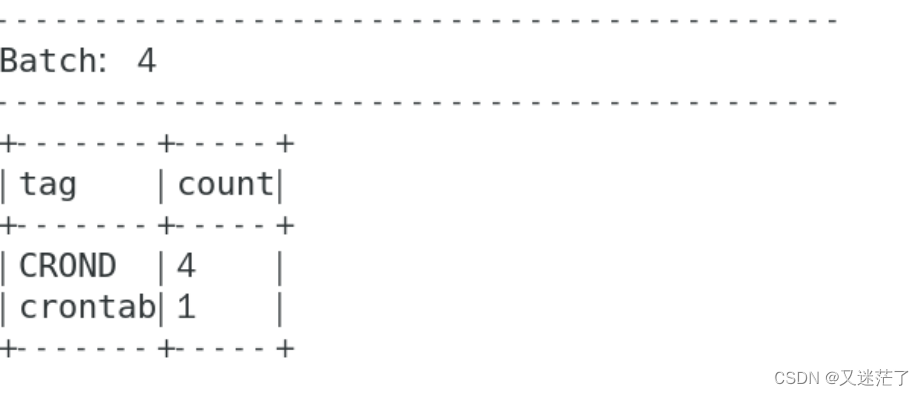
(2).输出所有日志内容带spark的日志。
在新开的终端内输入 vi spark_exercise_testsyslog3.py ,贴入如下代码并运行。运行之前需要关闭“tail终端”内的tail命令并重新运行tail命令,否则多次运行测试可能导致没有新数据生成。
#!/usr/bin/env python3from functools import partialfrom pyspark.sql import SparkSessionfrom pyspark.sql.functions import *if __name__ == "__main__":spark = SparkSession \.builder \.appName("Structuredcronlog") \.getOrCreate()lines = spark \.readStream \.format("socket") \.option("host", "localhost") \.option("port", 9988) \.load()# Nov 24 13:17:01 spark CRON[18455]: (root) CMD ( cd / && run-parts --report /etc/cron.hourly)# 定义一个偏应用函数,从固定的pattern获取日志内匹配的字段fields = partial(regexp_extract, str="value", pattern="^(\w{3}\s*\d{1,2} \d{2}:\d{2}:\d{2}) (.*?) (.*?)\[*\d*\]*: (.*)$")words = lines.select(unix_timestamp(format_string('2022 %s', fields(idx=1)), 'yy MMM d H:m:s').alias("timestamp"),fields(idx=2).alias("hostname"),fields(idx=3).alias("tag"),fields(idx=4).alias("content"),)# (3). 输出所有日志内容带spark的日志(根据自己模拟的日志内容进行筛选)。windowedCounts3 = words \.filter("content like '%spark%'")# 开始运行查询并在控制台输出query = windowedCounts3 \.writeStream \.outputMode("append") \.format("console") \.option('truncate', 'false')\.trigger(processingTime="3 seconds") \.start()query.awaitTermination()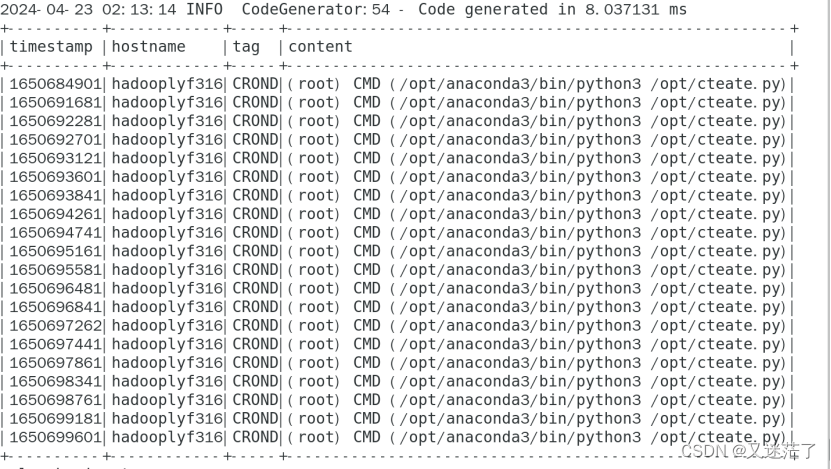


![[AI]-(第1期):OpenAI-API调用](https://img-blog.csdnimg.cn/direct/ac5b636ff9aa442890bd935cb754330a.jpeg#pic_center)