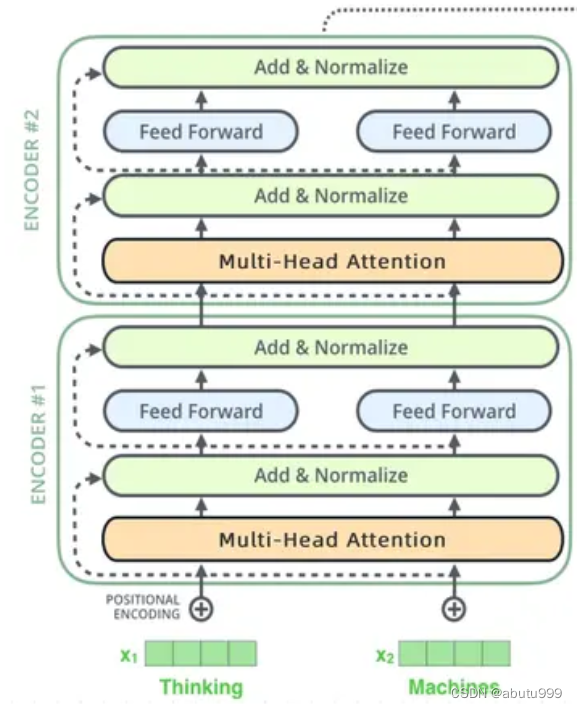
transformer
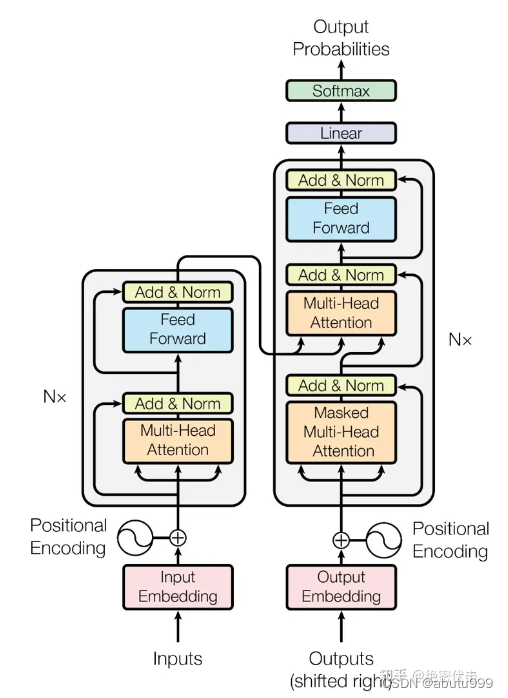
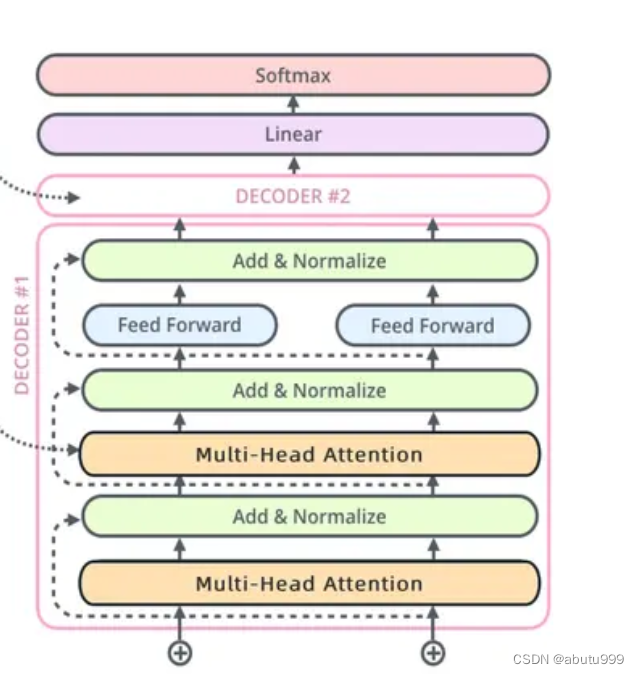
ENCODER
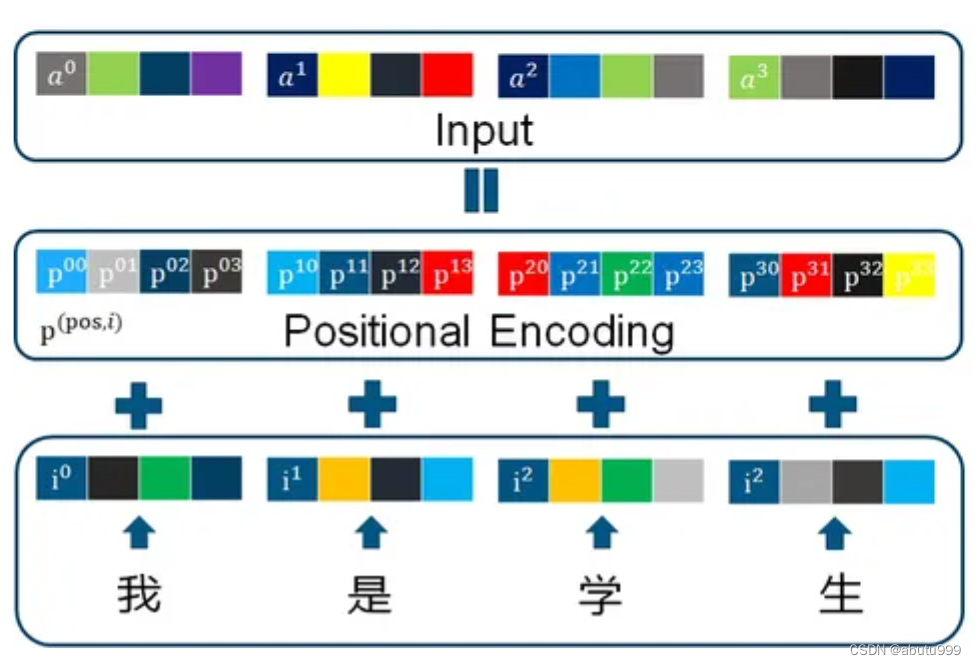
输入部分
对拆分后的语句x = [batch_size, seq_len]进行以下操作
- Embedding
将离散的输入(如单词索引或其他类别特征)转换为稠密的实数向量,以便可以在神经网络中使用。 - 位置编码
与RNN相比,RNN是一个字一个字的输入,自然每个字的顺序关系信息就会保留下来。但在Encoder中,一个句子的每一个字(词)是并行计算的(下一节解释),所以我们在输入的时候需要提前引入位置信息。
位置信息由: pos(一句话中的第几个字) 和 i (这个字编码成向量后的第i维) 来确定
下面是Positional Encoding的公式:
i为 偶 数 时 , P E p o s , i = s i n ( p o s / 1000 0 2 i / d m o d e l ) PE_{pos, i}= sin( pos/ 10000^{2i/ d_{model}}) PEpos,i=sin(pos/100002i/dmodel)
i为 奇 数 时 , P E p o s , i = c o s ( p o s / 1000 0 2 i / d m o d e l ) PE_{pos, i}= cos( pos/ 10000^{2i/ d_{model}}) PEpos,i=cos(pos/100002i/dmodel)
d m o d e l d_{model} dmodel指想用多长的 vector 来表达一个词(embedding_dim)
通过输入部分
x: [batch_size, seq_len, embedding_dim]
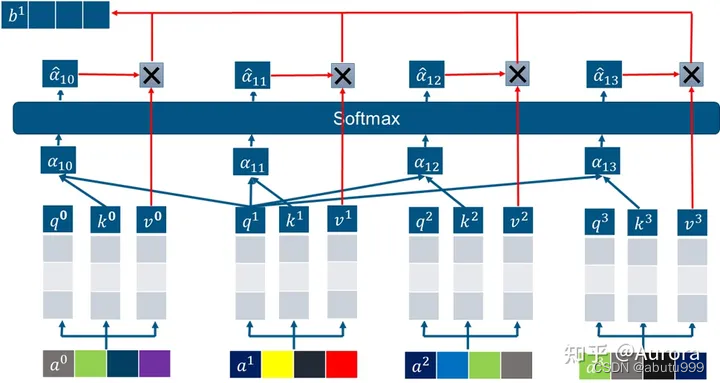
多头注意力机制
- 单头注意力机制
对一句话中第i个字的字向量 a i a_i ai,产生三个矩阵Q, K ,V
Q,K,V的维度都为[batch_size, seq_len, embedding_dim]
将 a i a_i ai分别与上面三个矩阵相乘,得到三个向量 q i , k i , v i q_i, k_i, v_i qi,ki,vi
如果要计算第1个字向量与句子中所有字向量的注意力:
将查询向量 q 1 q_1 q1与 所有的字向量的键向量 k i k_i ki相乘得到 a l p h a 10 , a l p h a 11 , . . . , a l p h a 1 , s e q l e n alpha_{10}, alpha_{11},...,alpha_{1,seqlen} alpha10,alpha11,...,alpha1,seqlen
将这写数值进行softmax处理后, 分别与 v i v_i vi相乘再合加得到最终结果 b 1 b_1 b1
- 多头注意力机制
把 Q , K , V Q,K,V Q,K,V三个大矩阵变成n个小矩阵(seq_len, embedding_dim/n) n=8
用上节相同的方式计算8个矩阵,然后把每一个head-Attention计算出来的b矩阵拼在一起,作为输出
Add&LN
Add是用了残差神经网络的思想,也就是把Multi-Head Attention的输入的a矩阵直接加上Multi-Head Attention的输出b矩阵(好处是可以让网络训练的更深)得到的和 b ˉ \bar{b} bˉ矩阵
再在经过Layer normalization(归一化,作用加快训练速度,加速收敛)把
每一行(也就是每个句子)做归一为标准正态分布,最后得到 b ^ \hat{b} b^
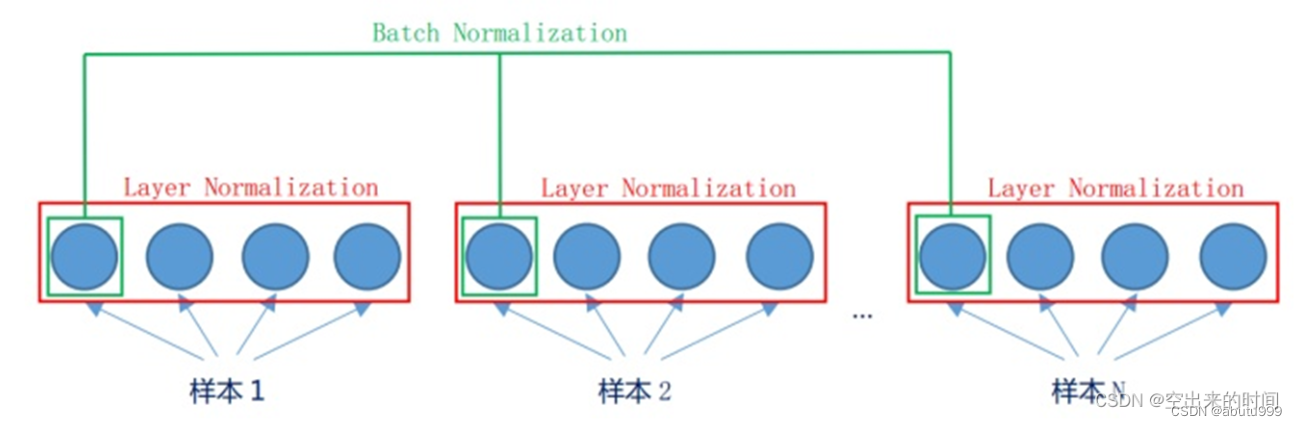
BN 和 LN:
- LN: 在一个样本内做归一化 适于RNN,transformer
- BN: 对batch_size里面的样本按对应的特征做归一化 适于CNN
Feed_forward前馈神经网络
把Add & Layer normalization输出 b ^ \hat{b} b^,经过两个全连接层,再经过Add & Layer normalization得到最后输出 o 矩阵
DECODER
masked_多头注意力机制
比如我们在中英文翻译时候,会先把"我是学生"整个句子输入到Encoder中,得到最后一层的输出后,才会在Decoder输入"S I am a student"(s表示开始),但是"S I am a student"这个句子我们不会一起输入,而是在T0时刻先输入"S"预测,预测第一个词"I";在下一个T1时刻,同时输入"S"和"I"到Decoder预测下一个单词"am";然后在T2时刻把"S,I,am"同时输入到Decoder预测下一个单词"a",依次把整个句子输入到Decoder,预测出"I am a student E"
多头注意力机制
Decoder 的 Multi-Head Attention 的输入来自两部分,
K,V 矩阵来自Encoder的输出,
Q 矩阵来自 Masked Multi-Head Attention 的输出