数据分层(应用分层)技术简介
近几年虚拟化市场实现了非常大的发展,桌面虚拟化在企业中应用越来越广泛,其拥有的如下优点得到大量企业的青睐:
- 数据安全不落地。在虚拟化环境下面数据保存在中心服务器上面,只要保障中心服务器的安全,那么就能保障数据的绝对安全。
- 高扩展性。与普通的硬件PC相比,桌面虚拟化具有高扩展性,可以随时将虚拟化资源归还给虚拟化主机以及分配给其他虚拟化主机使用。
- 容易部署。桌面虚拟化一般可以通过模板话部署,将应用(数据)一键部署到新的虚拟机上。
- 统一化资产管理。资产管理一直是企业管理的难点,市面上有许多公司的管理软件都包括了资产管理这一环;在桌面虚拟化下面,资产管理得到了很好的解决。
通常情况下的虚拟化架构如下:
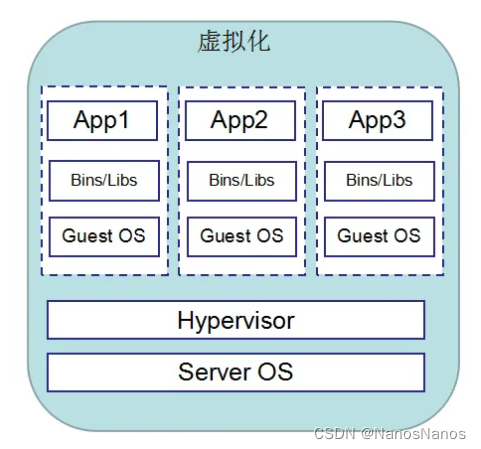
在上述架构中,我们可以安装层级来划分:
- 硬件层:主要是我们的实体硬件,包括内存,CPU,存储。
- 主机层:主要是我们的Host主机操作系统,一般来说以Linux居多。
- 客户机层:主要是我们的虚拟机操作系统,在这一层上面实现我们的具体应用(办公,开发,娱乐等)。
那么能否对客户机(Guest)这一层继续进行细化分层呢?例如我们实现:
- 我们将个人数据存放在一个单独层级。
- 无论我们使用虚拟机的还原系统,还是登录一台全新的虚拟机,我们将数据层进行合并,让我们个人数据和应用不会丢失。
本文来介绍一种在虚拟机中数据分层的技术,下面我们详细看一下其技术原理和实现。
1. 简介
数据分层是针对虚拟机来说的,以Windows系统为例,从下到上,我们可以将其分为三层:
- 系统OS层,该层表示Windows系统镜像安装的原始OS层,代表这一个可正常运行的OS。
- 应用层,该层表示各种应用程序组成的层,例如Chrome浏览器,微信,QQ等各种应用程序。
- 数据层,该层表示应用程序运行时候生成的各种文件数据,例如浏览器的记录,收藏夹;QQ微信的聊天数据。
其示意图大致如下:

一般来说,每个层都是一个独立的磁盘,将每个磁盘通过分层技术合并成一个整体可以正常使用运行的磁盘,如下:
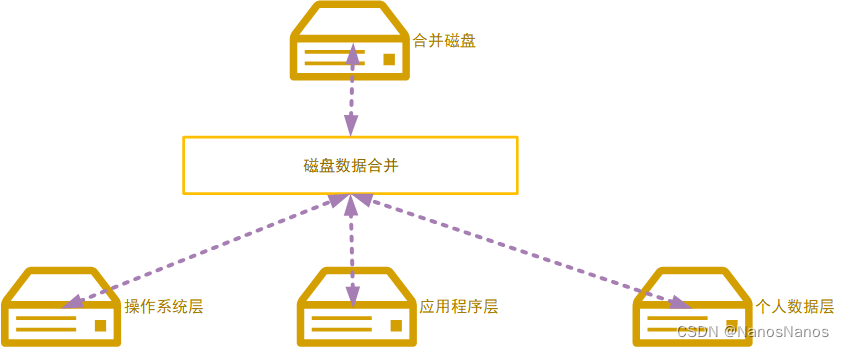
对于各层来说,一般有如下特征:
- 操作系统层,只有一个数据磁盘表示该层,表示运行的系统。
- 应用程序层,该层是一个集合层,多个应用程序层元素组成该层,表示通常情况下我们需要的应用程序。
- 个人数据层,该层可以由一个或者多个磁盘组成,不过大部分情况下,我们只需要一个磁盘层即可。
对于上面这种情况,在实际的使用场景下可以进一步简化,将操作系统层和引用程序层合并成一个层,大致如下:
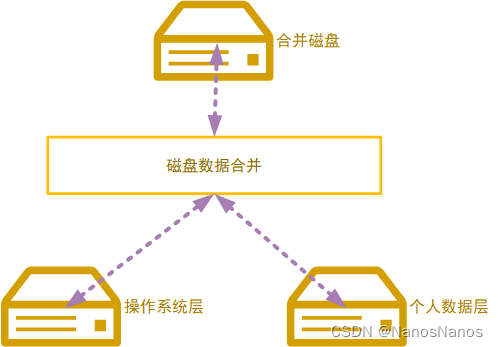
对于通常场景,我们可以将操作系统层和应用程序层合并成一个层到操作系统层;也就是说,我们在安装操作系统的时候,就将我们需要的应用软件安装好;后面使用过程中我们只需要弹性使用个人数据层即可。
我们的数据分层主要是针对这种简化的分层,对于应用分层可以参考我们的文章Windows内核沙盒原理详解。
对于数据分层我们的应用有:
- 还原系统下面,我们可以将自己程序的各种数据存放到自己的磁盘(或者云盘上面),这样我们虚拟主机是还原系统,但是数据是个人的数据,可以达到虚拟机重复利用的目的;例如我们10台主机可以分时间段给100个人(甚至更多人)使用,只要拥有个人数据磁盘就行。
- 数据上云,比如我们可以将个人数据层同步到自己的云盘;无论我们使用哪个电脑(虚拟机或者物理主机),可以将数据层进行合并,使得每台电脑使用的数据完全一致。
针对数据分层,我们主要的技术在于分层数据的合并,对于这个合并,有两个点:
- 注册表数据的合并。
- 文件数据的合并。
2. 注册表数据分层
注册表数据的分层需要对注册表的各种查询进行HOOK,然后将数据查询进行合并,将数据写入进行分发;注册表的HOOK技术有两种:
- 基于用户层API HOOK技术。
- 基于内核回调函数的HOOK技术。
这里我们使用内核回调函数的实现方式,使用CmRegisterCallbackEx来注册注册表的各种回调函数:
NTSTATUS CmRegisterCallbackEx(PEX_CALLBACK_FUNCTION Function,PCUNICODE_STRING Altitude,PVOID Driver,PVOID Context,PLARGE_INTEGER Cookie,PVOID Reserved
);
注册表的各种回调函数有如下:
typedef enum _REG_NOTIFY_CLASS {RegNtDeleteKey,RegNtPreDeleteKey,RegNtSetValueKey,RegNtPreSetValueKey,RegNtDeleteValueKey,RegNtPreDeleteValueKey,RegNtSetInformationKey,RegNtPreSetInformationKey,RegNtRenameKey,//...
} REG_NOTIFY_CLASS;
理论上我们需要对所有函数进行处理,主要的操作有:
RegNtPreCreateKeyEx对注册表的打开做处理(打开操作系统层的注册表还是打开数据层的注册表)。RegNtPreQueryValueKey对注册表值得查询做处理,一般来说我们需要对注册表得值进行合并(选择的方式是将数据层覆盖操作系统层的注册表值,当然还需要做很多情况的处理)。RegNtPreEnumerateKey枚举注册表项,这个函数也是最复杂的实现函数,因为我们需要对操作系统层和数据层的注册表项进行合并,去重等。RegNtPreDeleteKey和RegNtPreDeleteValueKey注册表的删除,也是非常麻烦的操作,因为我们需要对注册表进行标记处理(不能将操作系统层的数据真实删除)。
上面这些接口只是示例,实际的实现要复杂很多,大致例如如下:
regRoutineTable[RegNtPreQueryValueKey] = NanosRegNtPreQueryValueKeyCallback;
regRoutineTable[RegNtPreEnumerateValueKey] = NanosRegNtPreEnumerateValueKeyCallback;
regRoutineTable[RegNtPreQueryMultipleValueKey] = NanosRegNtPreQueryMultipleValueKeyCallback;
regRoutineTable[RegNtPreDeleteValueKey] = NanosRegNtPreDeleteValueKeyCallback;
regRoutineTable[RegNtPreDeleteKey] = NanosRegNtPreDeleteKeyCallback;
regRoutineTable[RegNtPreRenameKey] = NanosRegNtPreRenameKeyCallback;
regRoutineTable[RegNtPostRenameKey] = NanosRegNtPostRenameKeyCallback;
regRoutineTable[RegNtPreEnumerateKey] = NanosRegNtPreEnumerateKeyCallback;
regRoutineTable[RegNtPreQueryKey] = NanosRegNtPreQueryKeyCallback;
regRoutineTable[RegNtPostQueryKey] = NanosRegNtPostQueryKeyCallback;
regRoutineTable[RegNtPreSetValueKey] = NanosRegNtPreSetValueKeyCallback;
regRoutineTable[RegNtPreCreateKeyEx] = NanosRegNtPreCreateKeyExCallback;
regRoutineTable[RegNtPreOpenKeyEx] = NanosRegNtPreOpenKeyExCallback;
regRoutineTable[RegNtCallbackObjectContextCleanup] = NanosRegNtCallbackObjectContextCleanupCallback;
regRoutineTable[RegNtPreQueryKeySecurity] = NanosRegNtPreQueryKeySecurityCallback;
regRoutineTable[RegNtPreSetKeySecurity] = NanosRegNtPreSetKeySecurityCallback;
完成上述注册表的函数之后,我们就完成了注册表的分层合并和写入的功能了。
3. 文件分层
文件分层来说和注册表类似也可以使用两种方式来实现:
- 基于用户层API HOOK技术。
- 基于文件过滤驱动来实现。
这里我们使用基于Minifilter的文件系统过滤驱动来实现,Minfilter基本框架如下:
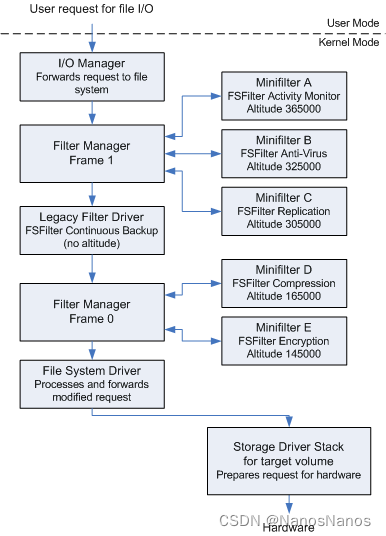
我们使用FltRegisterFilter来注册文件系统过滤驱动,如下:
NTSTATUS FLTAPI FltRegisterFilter(PDRIVER_OBJECT Driver,const FLT_REGISTRATION *Registration,PFLT_FILTER *RetFilter
);
该函数需要我们提供各种文件系统的回调函数,如下:
typedef struct _FLT_REGISTRATION {USHORT Size;USHORT Version;FLT_REGISTRATION_FLAGS Flags;const FLT_CONTEXT_REGISTRATION *ContextRegistration;const FLT_OPERATION_REGISTRATION *OperationRegistration;PFLT_FILTER_UNLOAD_CALLBACK FilterUnloadCallback;PFLT_INSTANCE_SETUP_CALLBACK InstanceSetupCallback;PFLT_INSTANCE_QUERY_TEARDOWN_CALLBACK InstanceQueryTeardownCallback;PFLT_INSTANCE_TEARDOWN_CALLBACK InstanceTeardownStartCallback;PFLT_INSTANCE_TEARDOWN_CALLBACK InstanceTeardownCompleteCallback;PFLT_GENERATE_FILE_NAME GenerateFileNameCallback;PFLT_NORMALIZE_NAME_COMPONENT NormalizeNameComponentCallback;PFLT_NORMALIZE_CONTEXT_CLEANUP NormalizeContextCleanupCallback;PFLT_TRANSACTION_NOTIFICATION_CALLBACK TransactionNotificationCallback;PFLT_NORMALIZE_NAME_COMPONENT_EX NormalizeNameComponentExCallback;PFLT_SECTION_CONFLICT_NOTIFICATION_CALLBACK SectionNotificationCallback;
} FLT_REGISTRATION, *PFLT_REGISTRATION;
同样对于上述文件过滤驱动我们需要实现其所有回调函数,这里我们简要介绍几个功能:
IRP_MJ_CREATE是文件创建的回调函数,在该函数中,我们需要实现文件的重查询,文件的写时拷贝,文件安装属性等功能。IRP_MJ_SET_INFORMATION文件设置,这里有两个重要的流程需要处理就是删除和重命名,对于操作系统层的文件,需要对其进行虚拟删除(一般是通过标记法来标记文件的删除)。IRP_MJ_DIRECTORY_CONTROL这个是目录文件的查询,这个函数也是非常复杂的一个函数,主要需要对操作系统层和数据层的数据进行查询合并。
我们对IRP_MJ_CREATE重查询的关键代码做分析,大致如下实现对文件的重查询:
FLT_PREOP_CALLBACK_STATUS NanosFileCreatePreCallback(PFLT_CALLBACK_DATA Cbd, PCFLT_RELATED_OBJECTS FltObjects, PVOID *CompletionContext)
{ UNICODE_SIRING NewFileName; //将要重定向的目标文件路径//... FileObject = Cbd->Iopb->TargetFileObject;status = IoReplaceFileObjectName(FileObject ,NewFileName.Buffer,NewFileName.Length); //替换文件对象的名称if (status < 0){FileObject->FileName = NewFileName;NewFileName.Length = 0;NewFileName.MaximumLength = 0;NewFileName.Buffer = 0;}Cbd->IoStatus.Status = STATUS_REPARSE; //告诉系统重新分析文件对象的名称,将对新文件名发起一个新的I/O请求。//...
}
4. 实现效果
通过上面的文件和注册表分层实现之后,我们就可以完成对数据的分层实现了;一般来说为例不影响用户的体验,对于分层数据磁盘我们是隐藏起来;因此在使用的时候,我们并无法看到该磁盘的存在;该磁盘被合并到了整个操作系统层,实现如下:
首先我们将分层驱动停用,查看操作系统盘和数据盘数据,如下:
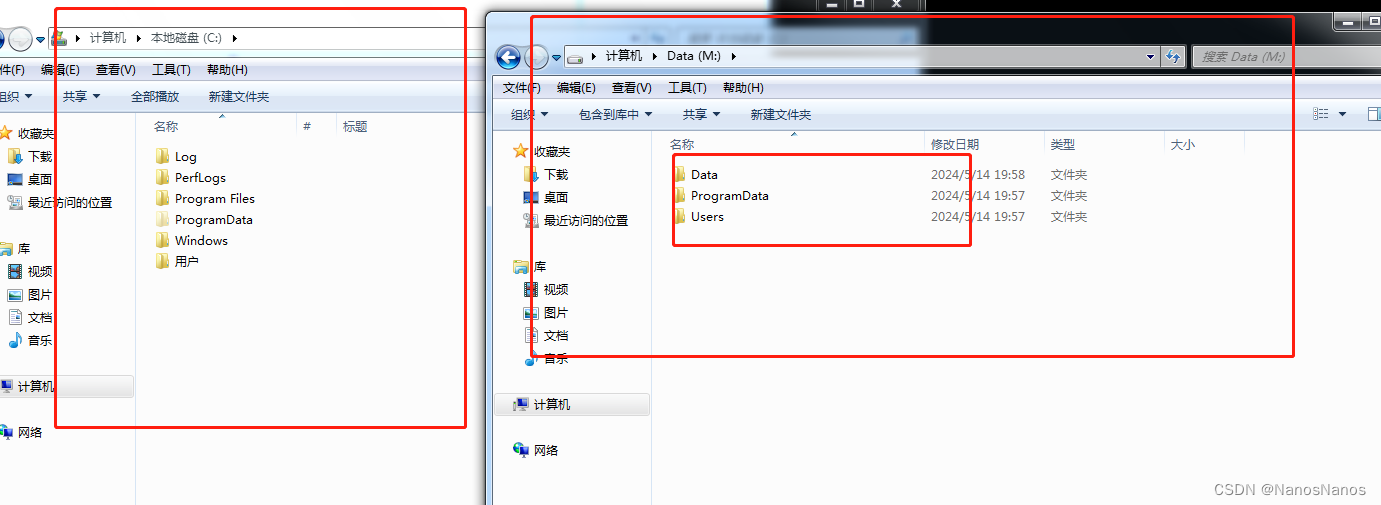
启用我们数据分层驱动之后,我们可以看到数据盘的数据已经合并到了操作系统盘C盘,如下:
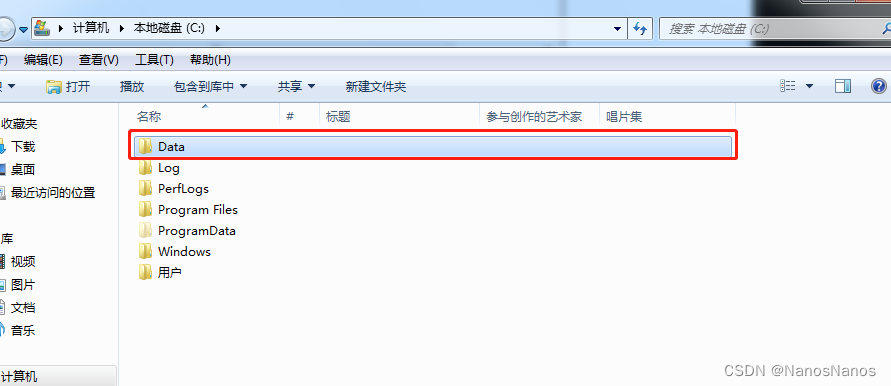
可以查看具体数据如下:
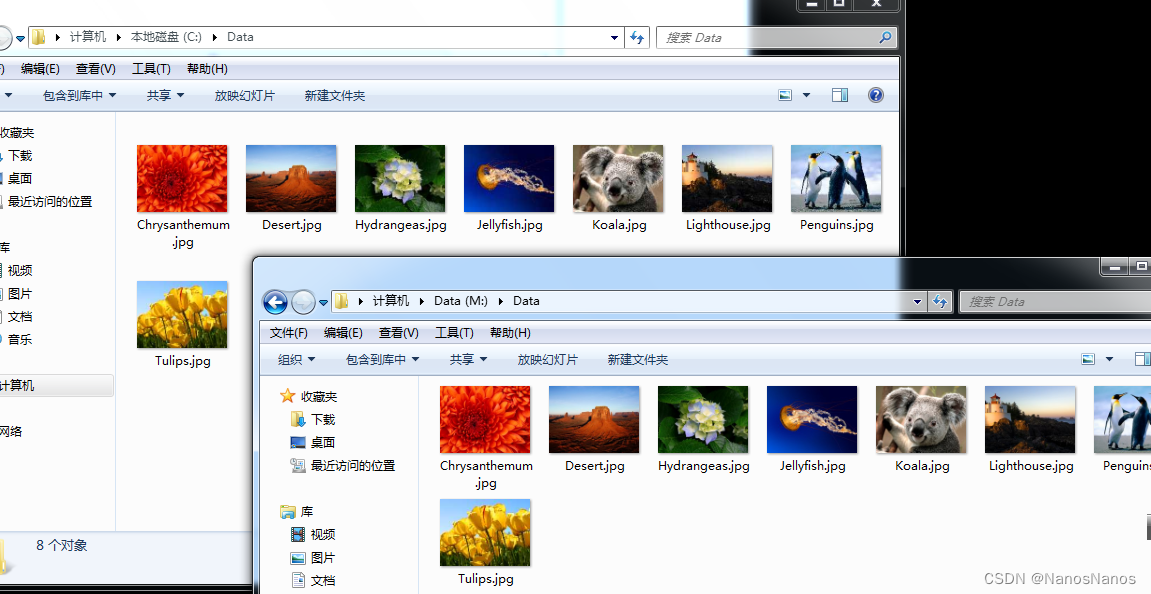
至此,我们完成了操作系统和整个数据盘的合并(或者换一种说法我们将操作系统和数据层分开存储,但是合并显示了)。
和数据分层类似,我们可以对整个应用程序进行分层,可以参考https://blog.csdn.net/tianxilink/article/details/132612811?spm=1001.2014.3001.5502的实现。