文章目录
- 一、关于 SHAP
- 二、安装
- 三、树集成示例(XGBoost/LightGBM/CatBoost/scikit-learn/pyspark 模型)
- 四、自然语言示例(transformers)
- 五、使用 DeepExplainer 的深度学习示例(TensorFlow/Keras 模型)
- 六、使用 GradientExplainer 的深度学习示例(TensorFlow/Keras/PyTorch 模型)
- 七、使用 KernelExplainer 的模型不可知示例(解释任何函数)
- 八、SHAP 交互值
- 九、样本 notebook
- 树解释器
- 深度解释器
- 梯度解释器
- 线性解释器
- 内核解释器
- 十、文档 notebook
- 十一、SHAP 统一的方法
一、关于 SHAP
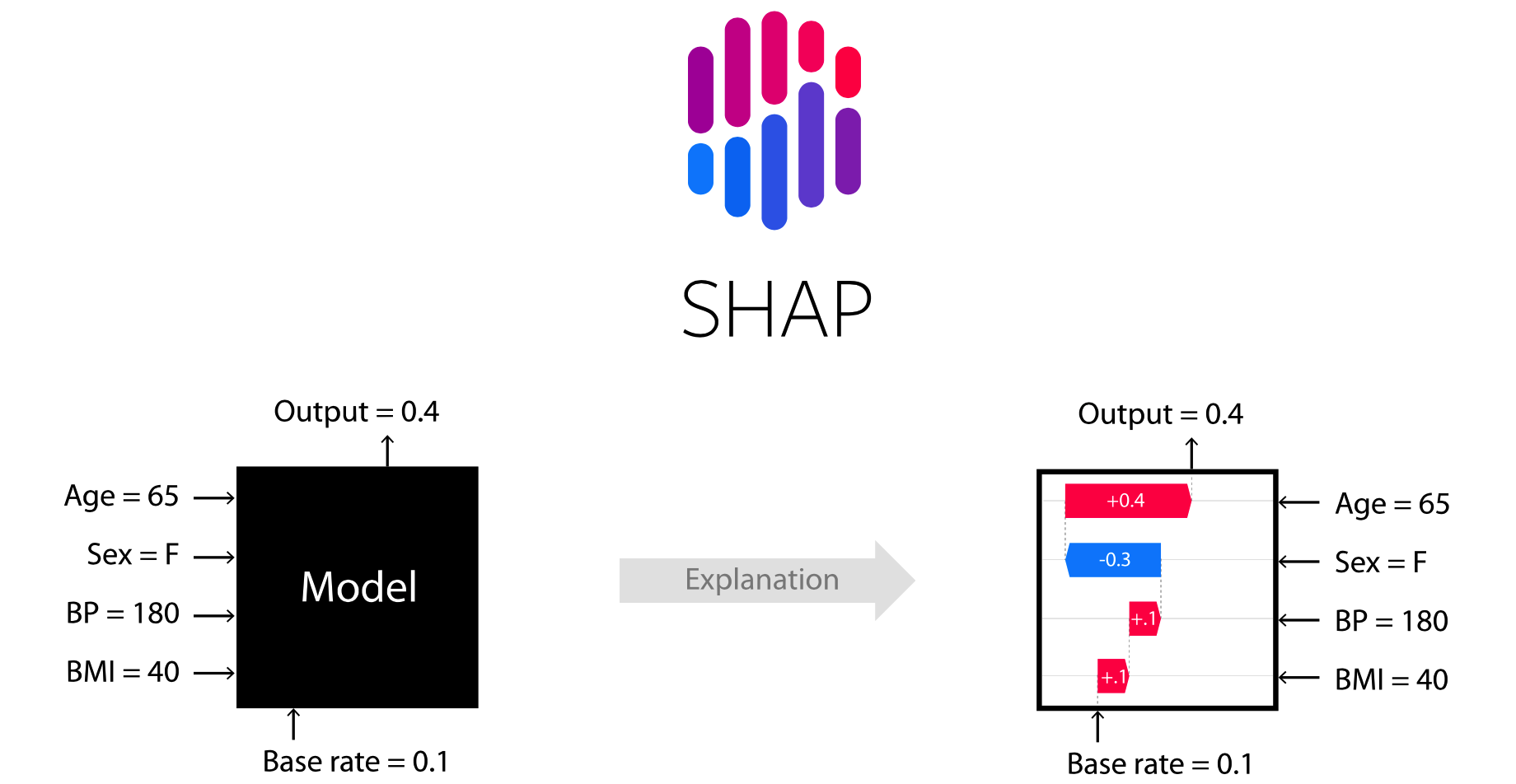
SHAP : SHapley Additive exPlanations
SHAP(SHapley Additive exPlanations) 是一种博弈论方法,用于解释任何机器学习模型的输出。它将最优信用分配与局部解释联系起来,使用博弈论中的经典 Shapley 值及其相关扩展(有关详细信息和引文,请参阅论文)。
- github : https://github.com/shap/shap
- 文档:https://shap.readthedocs.io/en/latest/
二、安装
SHAP 可以从PyPI或conda-forge安装:
pip install shap
conda install -c conda-forge shap
三、树集成示例(XGBoost/LightGBM/CatBoost/scikit-learn/pyspark 模型)
虽然 SHAP 可以解释任何机器学习模型的输出,但我们已经为树集成方法开发了一种高速精确算法(请参阅我们的Nature MI 论文)。XGBoost、LightGBM、CatBoost、scikit-learn和pyspark树模型支持快速 C++ 实现:
import xgboost
import shap# train an XGBoost model
X, y = shap.datasets.california()
model = xgboost.XGBRegressor().fit(X, y)# explain the model's predictions using SHAP
# (same syntax works for LightGBM, CatBoost, scikit-learn, transformers, Spark, etc.)
explainer = shap.Explainer(model)
shap_values = explainer(X)# visualize the first prediction's explanation
shap.plots.waterfall(shap_values[0])
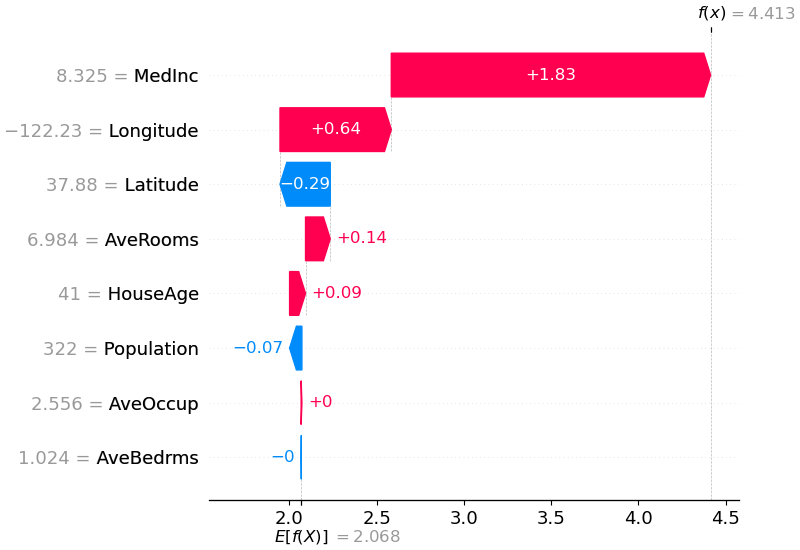
上面的解释显示了每个有助于将模型输出从基值(我们传递的训练数据集上的平均模型输出)推送到模型输出的功能。
将预测推高的特征显示为红色,将预测推低的特征显示为蓝色。
可视化相同解释的另一种方法是使用力图(这些在我们的Nature BME 论文中介绍):
# visualize the first prediction's explanation with a force plot
shap.plots.force(shap_values[0])

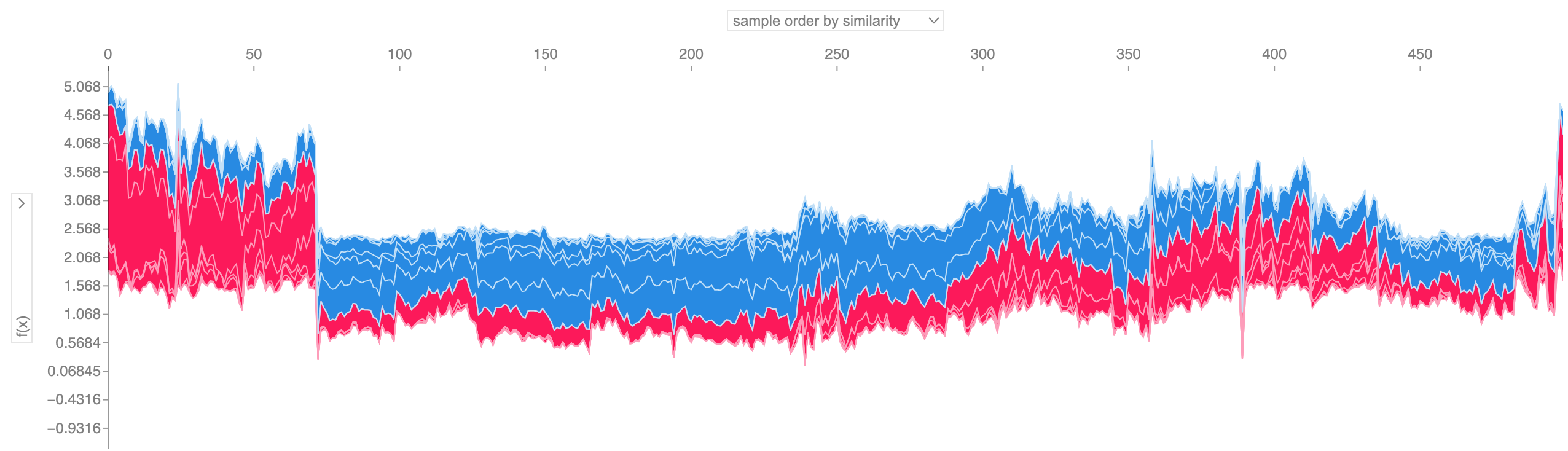
如果我们采用许多力图解释(例如上面所示的),将它们旋转 90 度,然后水平堆叠它们,我们可以看到整个数据集的解释(在 notebook 中,该图是交互式的):
# visualize all the training set predictions
shap.plots.force(shap_values[:500])
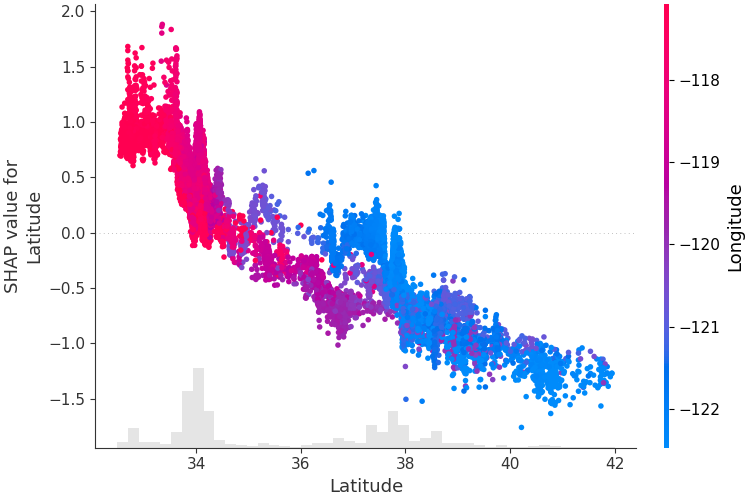
为了了解单个特征如何影响模型的输出,我们可以绘制该特征的 SHAP 值与数据集中所有示例的特征值的关系。
由于 SHAP 值代表要素对模型输出变化的责任,因此下图表示预测房价随纬度变化的变化。
单一纬度值的垂直色散表示与其他要素的相互作用效应。
为了帮助揭示这些相互作用,我们可以用另一个特征来着色。如果我们将整个解释张量传递给参数,color散点图将选择最佳的特征来着色。在本例中,它选择经度。
# create a dependence scatter plot to show the effect of a single feature across the whole dataset
shap.plots.scatter(shap_values[:, "Latitude"], color=shap_values)
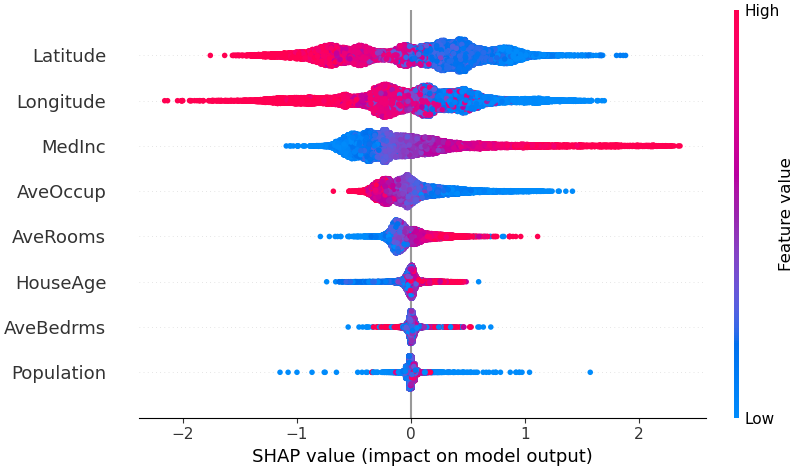
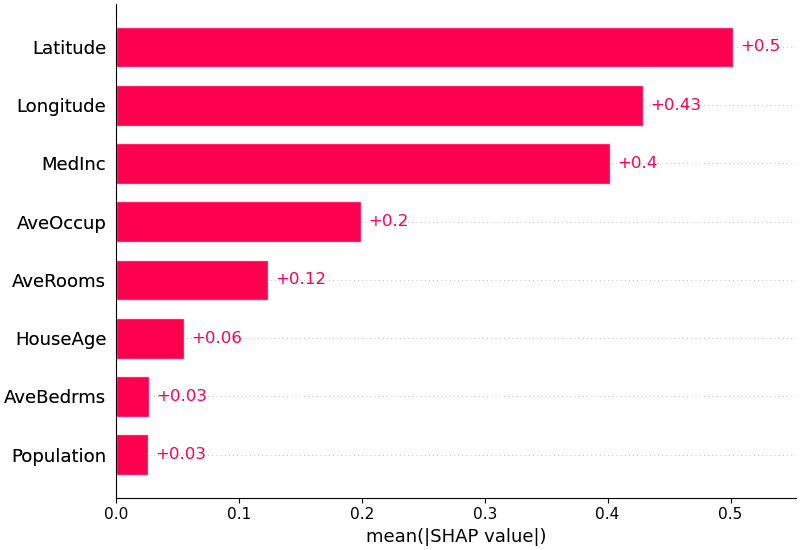
为了概述哪些特征对模型最重要,我们可以绘制每个样本的每个特征的 SHAP 值。
下图按所有样本的 SHAP 值大小总和对特征进行排序,并使用 SHAP 值显示每个特征对模型输出的影响的分布。颜色代表特征值(红色高,蓝色低)。
例如,这表明较高的中位收入会提高预测的房价。
# summarize the effects of all the features
shap.plots.beeswarm(shap_values)
我们还可以只取每个特征的 SHAP 值的平均绝对值来获得标准条形图(为多类输出生成堆叠条形图):
shap.plots.bar(shap_values)
四、自然语言示例(transformers)
SHAP 对自然语言模型(如 Hugging Face 转换器库中的模型)提供特定支持。
通过在传统 Shapley 值中添加联合规则,我们可以形成使用很少的函数评估来解释大型现代 NLP 模型的博弈。
使用此功能就像将受支持的转换器管道传递给 SHAP 一样简单:
import transformers
import shap# load a transformers pipeline model
model = transformers.pipeline('sentiment-analysis', return_all_scores=True)# explain the model on two sample inputs
explainer = shap.Explainer(model)
shap_values = explainer(["What a great movie! ...if you have no taste."])# visualize the first prediction's explanation for the POSITIVE output class
shap.plots.text(shap_values[0, :, "POSITIVE"])

五、使用 DeepExplainer 的深度学习示例(TensorFlow/Keras 模型)
Deep SHAP 是深度学习模型中 SHAP 值的高速近似算法,它建立在与SHAP NIPS 论文中描述的DeepLIFT 的连接之上。
这里的实现与原始 DeepLIFT 的不同之处在于,它使用背景样本的分布而不是单个参考值,并使用 Shapley 方程对 max、softmax、乘积、除法等组件进行线性化。
请注意,其中一些增强功能也已被自从集成到 DeepLIFT 中以来。支持使用 TensorFlow 后端的 TensorFlow 模型和 Keras 模型(也初步支持 PyTorch):
# ...include code from https://github.com/keras-team/keras/blob/master/examples/demo_mnist_convnet.pyimport shap
import numpy as np# select a set of background examples to take an expectation over
background = x_train[np.random.choice(x_train.shape[0], 100, replace=False)]# explain predictions of the model on four images
e = shap.DeepExplainer(model, background)
# ...or pass tensors directly
# e = shap.DeepExplainer((model.layers[0].input, model.layers[-1].output), background)
shap_values = e.shap_values(x_test[1:5])# plot the feature attributions
shap.image_plot(shap_values, -x_test[1:5])

上图解释了四个不同图像的十个输出(数字 0-9)。
红色像素增加模型的输出,而蓝色像素减少输出。输入图像显示在左侧,并且每个解释后面都有几乎透明的灰度背景。
SHAP 值的总和等于预期模型输出(背景数据集的平均值)与当前模型输出之间的差。
请注意,对于“零”图像,中间的空白很重要,而对于“四”图像,顶部缺少连接使其成为四而不是九。
六、使用 GradientExplainer 的深度学习示例(TensorFlow/Keras/PyTorch 模型)
预期梯度将Integrated Gradients、SHAP 和SmoothGrad的思想结合到一个预期值方程中。这允许将整个数据集用作背景分布(而不是单个参考值)并允许局部平滑。
如果我们用每个背景数据样本和要解释的当前输入之间的线性函数来近似模型,并且我们假设输入特征是独立的,那么预期梯度将计算近似的 SHAP 值。
在下面的示例中,我们解释了 VGG16 ImageNet 模型的第 7 个中间层如何影响输出概率。
from keras.applications.vgg16 import VGG16
from keras.applications.vgg16 import preprocess_input
import keras.backend as K
import numpy as np
import json
import shap# load pre-trained model and choose two images to explain
model = VGG16(weights='imagenet', include_top=True)
X,y = shap.datasets.imagenet50()
to_explain = X[[39,41]]# load the ImageNet class names
url = "https://s3.amazonaws.com/deep-learning-models/image-models/imagenet_class_index.json"
fname = shap.datasets.cache(url)
with open(fname) as f:class_names = json.load(f)# explain how the input to the 7th layer of the model explains the top two classes
def map2layer(x, layer):feed_dict = dict(zip([model.layers[0].input], [preprocess_input(x.copy())]))return K.get_session().run(model.layers[layer].input, feed_dict)
e = shap.GradientExplainer((model.layers[7].input, model.layers[-1].output),map2layer(X, 7),local_smoothing=0 # std dev of smoothing noise
)
shap_values,indexes = e.shap_values(map2layer(to_explain, 7), ranked_outputs=2)# get the names for the classes
index_names = np.vectorize(lambda x: class_names[str(x)][1])(indexes)# plot the explanations
shap.image_plot(shap_values, to_explain, index_names)

上图中解释了对两个输入图像的预测。红色像素代表增加类别概率的正 SHAP 值,而蓝色像素代表减少类别概率的负 SHAP 值。通过使用,ranked_outputs=2我们仅解释每个输入的两个最有可能的类别(这使我们无需解释所有 1,000 个类别)。
七、使用 KernelExplainer 的模型不可知示例(解释任何函数)
内核 SHAP 使用特殊加权的局部线性回归来估计任何模型的 SHAP 值。
下面是一个简单的例子,用于解释经典鸢尾花数据集上的多类 SVM。
import sklearn
import shap
from sklearn.model_selection import train_test_split# print the JS visualization code to the notebook
shap.initjs()# train a SVM classifier
X_train,X_test,Y_train,Y_test = train_test_split(*shap.datasets.iris(), test_size=0.2, random_state=0)
svm = sklearn.svm.SVC(kernel='rbf', probability=True)
svm.fit(X_train, Y_train)# use Kernel SHAP to explain test set predictions
explainer = shap.KernelExplainer(svm.predict_proba, X_train, link="logit")
shap_values = explainer.shap_values(X_test, nsamples=100)# plot the SHAP values for the Setosa output of the first instance
shap.force_plot(explainer.expected_value[0], shap_values[0][0,:], X_test.iloc[0,:], link="logit")

上面的解释显示了四个特征,每个特征都有助于将模型输出从基值(我们通过的训练数据集的平均模型输出)推向零。如果有任何功能将类标签推高,它们将显示为红色。
如果我们采用如上所示的多种解释,将它们旋转 90 度,然后水平堆叠它们,我们就可以看到整个数据集的解释。这正是我们在下面对 iris 测试集中的所有示例所做的操作:
# plot the SHAP values for the Setosa output of all instances
shap.force_plot(explainer.expected_value[0], shap_values[0], X_test, link="logit")
八、SHAP 交互值
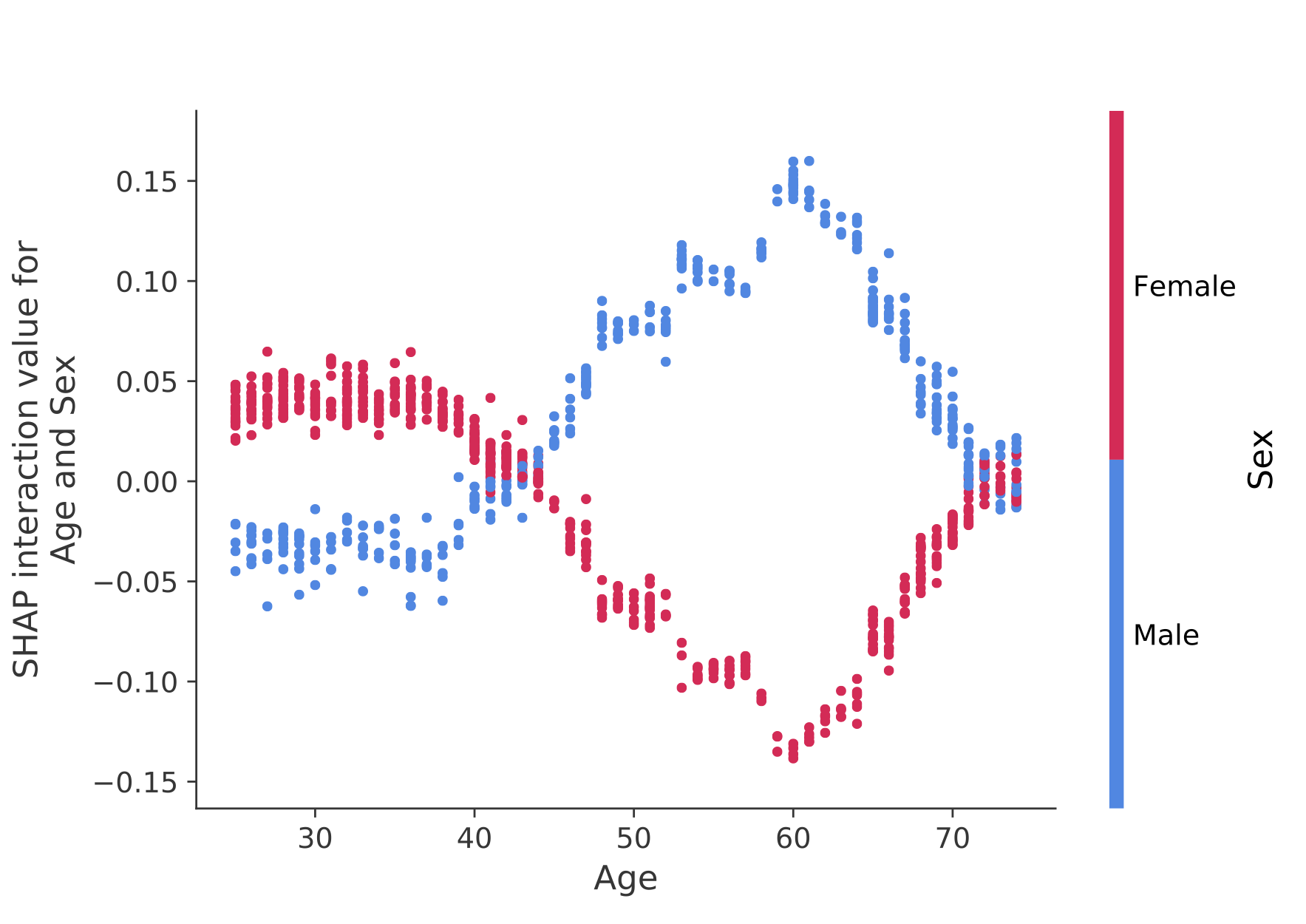
SHAP 交互值是 SHAP 值对更高阶交互的推广。为树模型实现了成对相互作用的快速精确计算shap.TreeExplainer(model).shap_interaction_values(X)。
这会为每个预测返回一个矩阵,其中主效应位于对角线上,交互效应位于非对角线上。这些值经常揭示有趣的隐藏关系,例如男性死亡风险的增加如何在 60 岁时达到峰值(有关详细信息,请参阅 NHANES notebook ):
九、样本 notebook
下面的 notebook 演示了 SHAP 的不同用例。如果您想自己尝试使用原始 notebook ,请查看存储库的 notebook 目录。
树解释器
Tree SHAP 的实现,一种快速而精确的算法,用于计算树和树集合的 SHAP 值。
- 具有 XGBoost 和 SHAP 交互值的 NHANES 生存模型 - 本 notebook 使用 20 年随访的死亡率数据演示了如何使用 XGBoost 并
shap揭示复杂的风险因素关系。 - 使用 LightGBM 进行人口普查收入分类- 该 notebook 使用标准成人人口普查收入数据集,使用 LightGBM 训练梯度提升树模型,然后使用 解释预测
shap。 - 使用 XGBoost 预测英雄联盟获胜- 使用包含 180,000 场英雄联盟排名比赛的 Kaggle 数据集,我们使用 XGBoost 训练和解释梯度提升树模型,以预测玩家是否会赢得比赛。
深度解释器
Deep SHAP 的实现,这是一种更快(但只是近似)的算法,用于计算深度学习模型的 SHAP 值,该算法基于 SHAP 和 DeepLIFT 算法之间的连接。
- 使用 Keras 进行 MNIST 数字分类- 该 notebook 使用 MNIST 手写识别数据集,使用 Keras 训练神经网络,然后使用 解释预测
shap。 - 用于 IMDB 情感分类的 Keras LSTM - 此 notebook 在 IMDB 文本情感分析数据集上使用 Keras 训练 LSTM,然后使用 解释预测
shap。
梯度解释器
实现深度学习模型的近似 SHAP 值的预期梯度。它基于 SHAP 和积分梯度算法之间的联系。 GradientExplainer 比 DeepExplainer 慢,并且做出不同的近似假设。
- 解释 ImageNet 上 VGG16 的中间层- 本 notebook 演示了如何使用内部卷积层解释预训练的 VGG16 ImageNet 模型的输出。
线性解释器
对于具有独立特征的线性模型,我们可以分析计算精确的 SHAP 值。如果我们愿意估计特征协方差矩阵,我们还可以考虑特征相关性。 LinearExplainer 支持这两个选项。
- 使用逻辑回归进行情感分析- 本 notebook 演示了如何解释线性逻辑回归情感分析模型。
内核解释器
内核 SHAP 的实现,这是一种与模型无关的方法,用于估计任何模型的 SHAP 值。因为 KernelExplainer 不对模型类型做出任何假设,所以它比其他模型类型特定的算法慢。
- 使用 scikit-learn 进行人口普查收入分类- 使用标准成人人口普查收入数据集,本 notebook 使用 scikit-learn 训练 k 最近邻分类器,然后使用 解释预测
shap。 - ImageNet VGG16 Model with Keras - 解释经典 VGG16 卷积神经网络对图像的预测。这是通过将与模型无关的 Kernel SHAP 方法应用于超像素分割图像来实现的。
- 鸢尾花分类- 使用流行的鸢尾花物种数据集的基本演示。它解释了 scikit-learn 中使用 6 个不同模型的预测
shap。
十、文档 notebook
这些 notebook 全面演示了如何使用特定的功能和对象。
shap.decision_plot和shap.multioutput_decision_plotshap.dependence_plot
十一、SHAP 统一的方法
- LIME: Ribeiro、Marco Tulio、Sameer Singh 和 Carlos Guestrin。 “我为什么要相信你?:解释任何分类器的预测。”第 22 届 ACM SIGKDD 国际知识发现和数据挖掘会议论文集。美国CM,2016。
- Shapley 采样值: Strumbelj、Erik 和 Igor Kononenko。 “通过特征贡献解释预测模型和个体预测。”知识和信息系统41.3(2014):647-665。
- DeepLIFT: Shrikumar、Avanti、Peyton Greenside 和 Anshul Kundaje。 “通过传播激活差异来学习重要特征。” arXiv 预印本 arXiv:1704.02685 (2017)。
- QII: Datta、Anupam、Shayak Sen 和 Yair Zick。 “通过定量输入影响实现算法透明度:学习系统的理论和实验。”安全与隐私 (SP),2016 年 IEEE 研讨会。 IEEE,2016。
- 逐层相关性传播: Bach、Sebastian 等人。 “通过逐层相关性传播对非线性分类器决策进行像素级解释。” PloS one 10.7 (2015): e0130140。
- Shapley 回归值: Lipovetsky、Stan 和 Michael Conklin。 “博弈论方法中的回归分析。”商业和工业中的应用随机模型 17.4 (2001): 319-330。
- *树解释者:*萨巴斯、安藤。解释随机森林。http://blog.datadive.net/interpreting-random-forests/
2024-05-15(三)