本文主要介绍近邻算法原理及实践demo。
一、原理
K近邻算法(K-Nearest Neighbors,简称KNN)是一种基于距离的分类算法,其核心思想是距离越近的样本点,其类别越有可能相似。以下是KNN算法的原理详解:
1. 算法原理
KNN算法的工作原理是利用训练数据对特征向量空间进行划分,并将划分结果作为最终算法模型。当输入一个新的没有标签的数据后,将这个数据的每个特征与训练集中的数据对应的特征进行比较,找出训练集中与这个新数据特征最相近的K个样本点(即K个最近邻居),然后根据这K个邻居的类别加权或投票,来预测新数据的类别。
2. K值的选择
K的选择对算法的精度有较大影响。K值较小时,模型对噪声更敏感,容易过拟合;K值较大时,模型对异常值的鲁棒性更强,但可能会引入噪声,导致欠拟合。在实际应用中,K值的选择通常通过交叉验证等方法来确定最优的K值。
3. 距离度量
KNN算法中常用的距离度量是欧氏距离,但也可以采用曼哈顿距离、切比雪夫距离等其他距离度量方法。在进行距离度量之前,通常需要对每个属性的值进行规范化,以保证不同特征具有相同的权重。
4. 特征归一化
由于不同特征的量纲可能不同,如果不进行归一化,那么在计算距离时,数值范围大的特征会对距离计算产生较大的影响。因此,为了使每个特征具有同等的重要性,通常需要对特征进行归一化处理。
5. 算法实现
KNN算法的实现通常包括以下几个步骤:
- 导入数据并进行预处理。
- 确定K值和距离度量方法。
- 对于每一个测试数据点,计算其与训练集中每个点的距离。
- 找出距离最近的K个训练数据点。
- 根据这K个邻居的类别,通过投票或加权的方式来预测测试点的类别。
6. 算法优势与劣势
KNN算法的优势在于它简单、直观,对数据的分布没有假设,因此可以用于非线性数据的分类。同时,KNN算法也可以用于回归问题。不过,KNN算法的计算复杂度较高,尤其是在大数据集上,计算每个待分类点与所有训练点之间的距离会非常耗时。
7. 应用场景
KNN算法适用于那些样本容量较大的类域的自动分类问题,但在样本容量较小的类域上使用时,容易产生误分。此外,KNN对不平衡的数据集比较敏感,需要通过权重调整或其他方法来改进。
KNN算法是一种“懒惰学习”算法,它不会从训练数据中学习到模型,而是直接存储训练数据,在预测时才进行计算,因此训练时间复杂度为0,但分类时间复杂度为O(n)。
KNN算法是一种简单、易于实现的分类算法,但在使用时需要注意K值的选择、距离度量、特征归一化等关键因素,以提高算法的准确性和效率。
二、举个栗子
使用scikit-learn库中的KNN分类器,并用一个合成的数据集来展示如何训练模型和进行预测。
预期效果
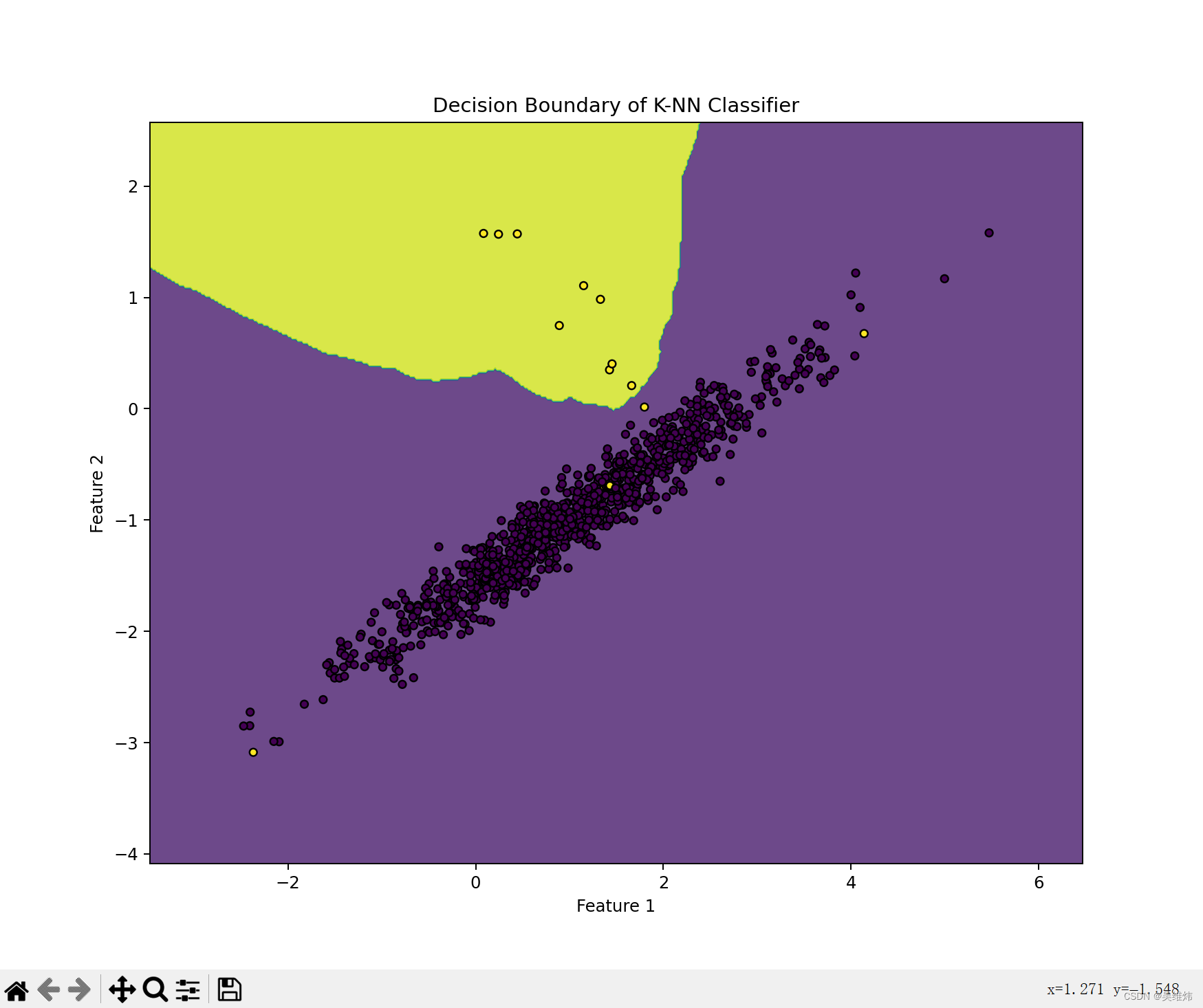
设计思路
- 使用make_classification函数创建了一个二分类的数据集。-
- 初始化了一个KNN分类器,并设置了邻居数k。
- 使用训练数据训练了KNN模型。-
- 使用predict方法预测了网格上每个点的类别。
- 使用contourf函数绘制了决策边界,并且绘制了训练数据点。
核心代码
# 导入必要的库
import numpy as np # 导入numpy,并将其别名设置为np
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import make_classification
import matplotlib.pyplot as plt# 创建一个合成的分类数据集
X, y = make_classification(n_samples=1000, n_features=2, n_redundant=0,n_clusters_per_class=1, weights=[0.99],random_state=42)# 选择K的值,这里我们选择K=5
k = 5# 初始化KNN分类器
knn = KNeighborsClassifier(n_neighbors=k)# 训练KNN模型
knn.fit(X, y)# 为了可视化,我们创建一个网格来绘制决策边界
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, .02),np.arange(y_min, y_max, .02))# 预测网格点所属的类别
Z = knn.predict(np.c_[xx.ravel(), yy.ravel()])# 将预测结果绘制为彩色图像
plt.figure(figsize=(10, 8))
plt.contourf(xx, yy, Z.reshape(xx.shape), alpha=0.8)# 绘制训练点
plt.scatter(X[:, 0], X[:, 1], c=y, s=20, edgecolor='k')
plt.title('Decision Boundary of K-NN Classifier')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()
三、自定义实例
预期效果
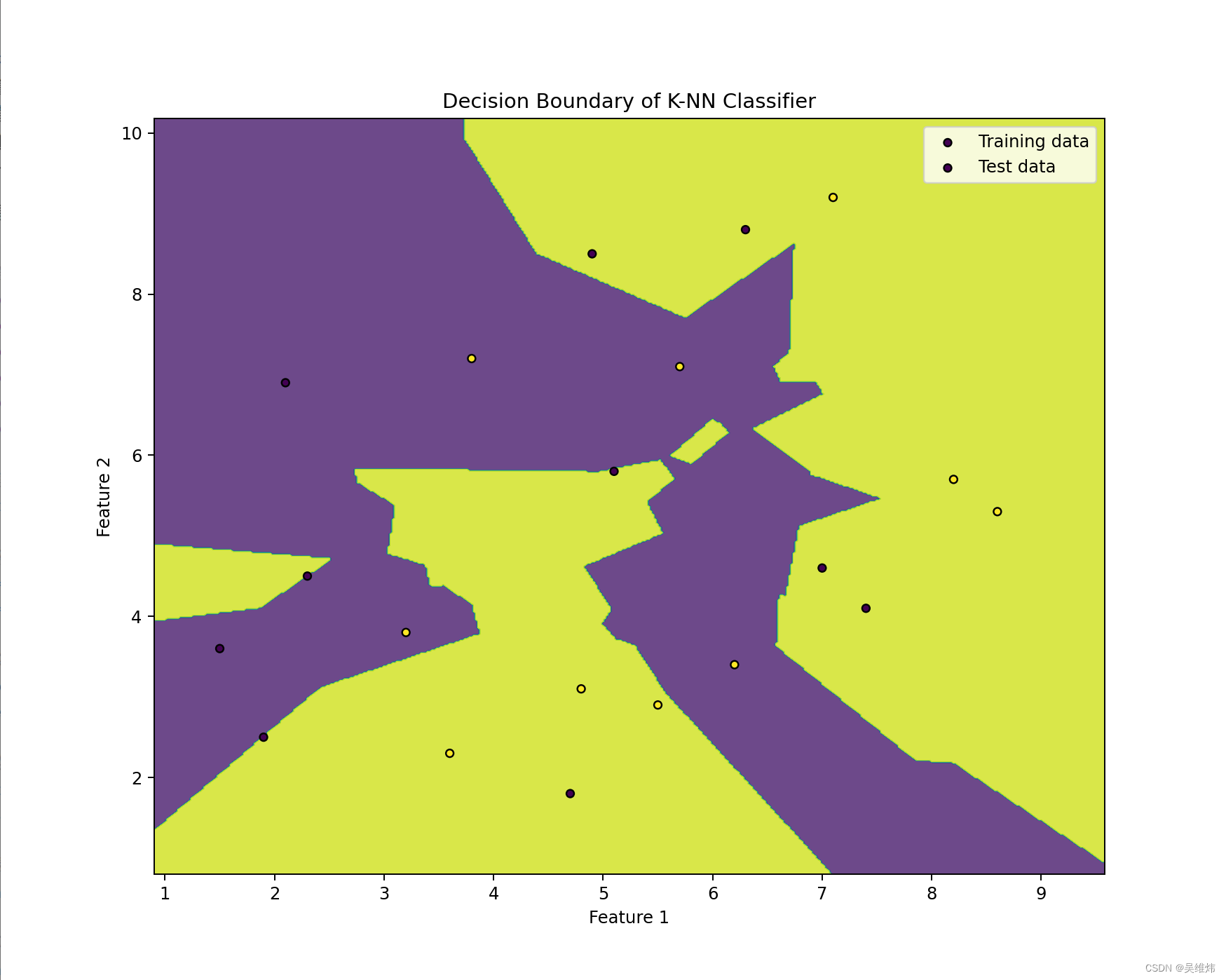
核心代码
# 导入必要的库
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
import matplotlib.pyplot as plt# 读取CSV数据集
data = pd.read_csv('knnDemoDB.csv')# 假设CSV文件的最后一列是标签
X = data.iloc[:, :-1].values # 所有行,除了最后一列的所有列
y = data.iloc[:, -1].values # 所有行,最后一列# 如果标签是非数值型的,则进行编码转换
label_encoder = LabelEncoder()
y_encoded = label_encoder.fit_transform(y)# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y_encoded, test_size=0.2, random_state=42)# 初始化KNN分类器
knn = KNeighborsClassifier(n_neighbors=5)# 训练KNN模型
knn.fit(X_train, y_train)# 为了可视化,我们创建一个网格来绘制决策边界
x_min, x_max = X_train[:, 0].min() - 1, X_train[:, 0].max() + 1
y_min, y_max = X_train[:, 1].min() - 1, X_train[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, .02),np.arange(y_min, y_max, .02))# 预测网格点所属的类别
Z = knn.predict(np.c_[xx.ravel(), yy.ravel()])# 将预测结果绘制为彩色图像
plt.figure(figsize=(10, 8))
plt.contourf(xx, yy, Z.reshape(xx.shape), alpha=0.8)# 绘制训练点和测试点
plt.scatter(X_train[:, 0], X_train[:, 1], c=y_train, s=20, edgecolor='k', label='Training data')
plt.scatter(X_test[:, 0], X_test[:, 1], c=y_test, s=20, edgecolor='k', label='Test data')
plt.title('Decision Boundary of K-NN Classifier')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.legend()
plt.show()
数据源
knnDemoDB.csv
Feature1,Feature2,Label
1.5,3.6,Class_A
2.3,4.5,Class_A
3.6,2.3,Class_B
4.8,3.1,Class_B
5.1,5.8,Class_A
6.2,3.4,Class_B
7.4,4.1,Class_A
8.6,5.3,Class_B
2.1,6.9,Class_A
3.8,7.2,Class_B
4.9,8.5,Class_A
5.7,7.1,Class_B
6.3,8.8,Class_A
7.1,9.2,Class_B
1.9,2.5,Class_A
3.2,3.8,Class_B
4.7,1.8,Class_A
5.5,2.9,Class_B
7.0,4.6,Class_A
8.2,5.7,Class_B
四、解决方案
KNN算法可以应用于生活中的许多实际问题,因为它是一种简单、直观的分类算法。以下是一些解决方案例子,展示了如何使用KNN算法解决实际问题:
1. 推荐系统
在推荐系统中,KNN可以用来根据用户的历史行为(如购买、评分或浏览历史)推荐商品或服务。通过将用户的特征(如年龄、性别、兴趣等)和他们之前的喜好作为输入,KNN可以找出相似用户群,并推荐那些用户喜欢的产品。
2. 医疗诊断
在医疗领域,KNN可以用于辅助诊断。利用病人的一系列症状、体检结果和病史作为特征,KNN可以预测可能的疾病。例如,基于病人的血糖水平、血压和胆固醇水平,KNN可以预测心脏病的风险。
3. 图像识别
KNN算法可以用于图像识别任务,如手写数字识别。每个图像可以被转换成一个特征向量,其中包含了图像的纹理、边缘和形状信息。KNN根据这些特征向量将新的图像分类到相应的类别。
4. 金融市场分析
在金融市场,KNN可以用于预测股票价格的变动或信用风险评估。通过分析历史价格、交易量和市场趋势,KNN可以帮助投资者做出更明智的投资决策。
5. 房地产市场
在房地产市场,KNN可以用来估算房屋价格。利用房屋的特征(如面积、位置、房间数量等)和近期售出的类似房屋价格作为训练数据,KNN可以预测新房屋的市场价格。
6. 垃圾邮件检测
KNN可以用于文本分类,如垃圾邮件检测。通过分析邮件内容中的关键词和短语,KNN可以将邮件分类为垃圾邮件或非垃圾邮件。
7. 交通流量预测
在智能交通系统(ITS)中,KNN可以用于预测交通流量和拥堵情况。利用历史交通数据和实时传感器数据,KNN可以预测特定路段的交通状况。
应用实例:房屋价格预测
假设我们想要使用KNN算法预测房屋价格。以下是基于前面提供的代码模板,针对房屋价格预测问题的示例:
# 导入必要的库
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestRegressor
import numpy as np
import matplotlib.pyplot as plt# 读取CSV数据集,这里假设CSV文件包含了房屋的特征和价格
data = pd.read_csv('house_prices.csv')# 假设CSV文件中包含了多个特征列和一个价格标签列
features = data.drop('Price', axis=1).values # 所有行,除了价格列的所有列
price = data['Price'].values # 所有行,价格列# 如果特征中包含非数值型数据,则进行编码转换
# 这里假设所有数据已经是数值型的# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(features, price, test_size=0.2, random_state=42)# 初始化KNN回归器
knn = KNeighborsClassifier(n_neighbors=5)# 训练KNN模型
knn.fit(X_train, y_train)# 预测测试集的价格
y_pred = knn.predict(X_test)# 评估模型性能
print('Predictions:', y_pred)
print('Actual prices:', y_test)# 如果需要可视化,可以绘制预测价格与实际价格的关系
plt.figure(figsize=(10, 6))
plt.scatter(y_test, y_pred, color='blue', label='Predicted prices')
plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], 'k--', lw=2)
plt.xlabel('Actual Price')
plt.ylabel('Predicted Price')
plt.title('KNN Predicted vs Actual Prices')
plt.legend()
plt.show()