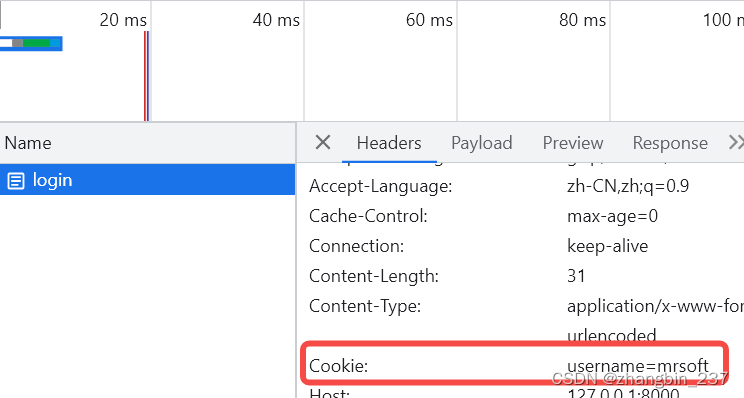
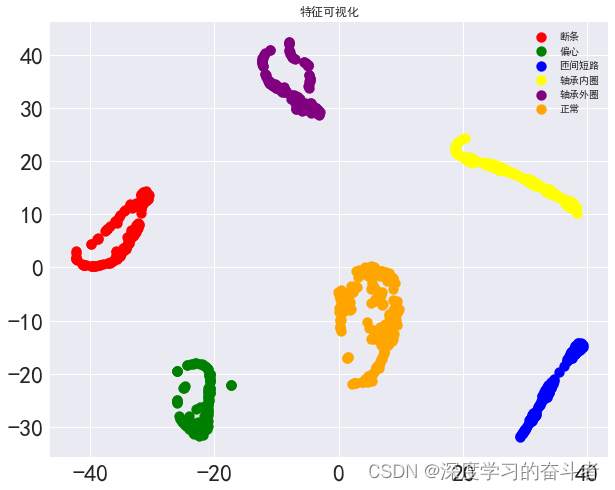
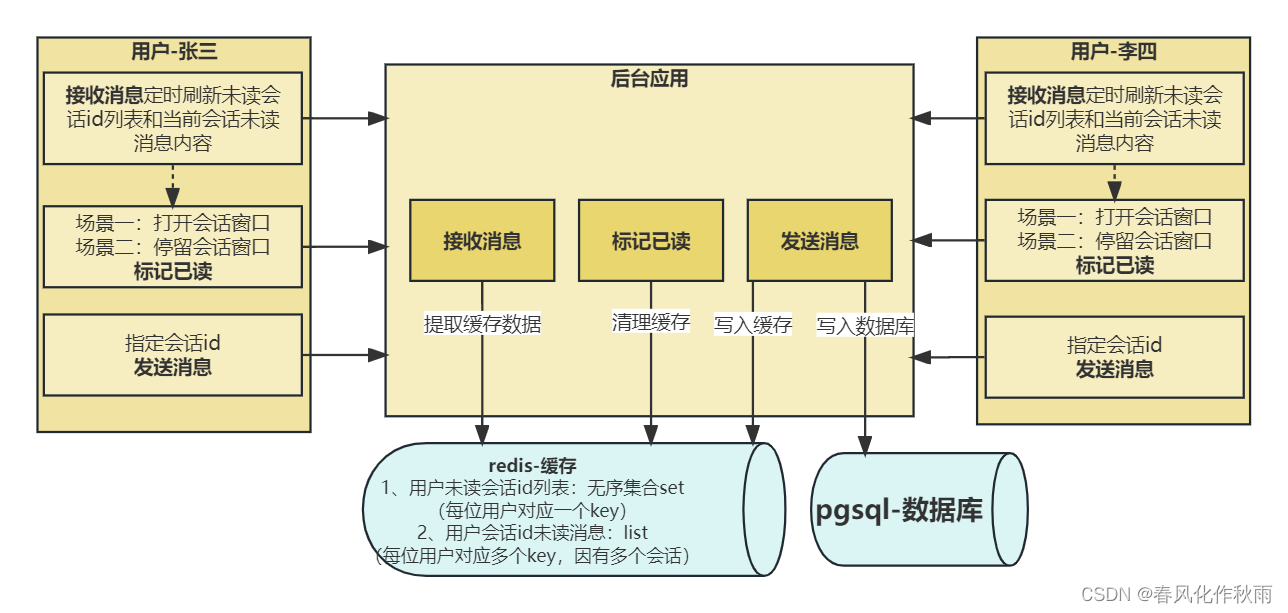
- 文献阅读:AnnoLLM: Making Large Language Models to Be Better Crowdsourced Annotators
- 1. 文章简介
- 2. 方法介绍
- 3. 实验考察
- 1. 实验结果
- 2. 消解实验
- 3. Consistency & Stability
- 4. 结论 & 思考
- 文献链接:https://arxiv.org/abs/2303.16854
1. 文章简介
这一篇文章是我司的另一篇关于GPT模型的Prompt工程调优的文章,不过这篇文章的方法挺有启发意义的,而且这篇文章的工作本身也和我最近在做的工作比较契合,因此打算在这里对这篇文章进行一下整理。
这篇文章的核心工作如前所述,是一个prompt调优的工作,用于使得GPT任务在分类任务的标注上获取更好的效果。
而这篇文章的核心思路其实还是对齐,他在文章中引入了一个叫做explain-then-annotate的方法,算是一个few-shot的变体,不过不同于few-shot的直接给答案或者人工给一些答案,文中采用的方式是先给模型一些人工标注的ground-truth,然后要求模型对此生成explanation来作为few-shot的内容。
用这种方式,某种意义上可以强制LLM对齐任务的判断标准与人的标准相同,从而使得模型在标注任务当中能够收获更好的效果。
2. 方法介绍
下面,我们来具体看一下文中的prompt的具体构造方法以及给出一个具体的prompt例子。
首先,我们来看一下AnnoLLM的整体的设计,这个可以用文中的图表进行展示:

其中,左侧是人工标注的流程,而右侧则是AnnoLLM的过程。
可以看到,其主要是包含了两个步骤:
- 给出task description以及一些标注数据,让模型来说明标注这些label的理由;
- 将上述task description,样例数据以及模型回答的理由作为few-shot prompt输入给模型,然后要求模型回答目标问题。
其具体的一个样例如下表所示:

其中,粗体的部分就是预先给到LLM答案之后由LLM自己生成的explanation,其具体的prompt如下:

通过这种方式,我们就可以迫使模型去对齐ground truth当中人类的判断标准,从而获得一个更好的效果表达。
3. 实验考察
下面,我们来看一下文中给出具体实验结果。
1. 实验结果
文中实验主要使用了如下三个数据集:

其中:
- QK数据集是一个query与keyword的relevance判断问题;
- BoolQ数据集是一个针对doc以及question的是非判断问题;
- WiC数据集则是判断同一个词在两个sentence当中是否有相同的语义;
给出三个数据集下的实验结果如下:
-
QK

-
BoolQ

-
WiC

可以看到:
- 在三个任务当中,模型都获得了很好的效果。
2. 消解实验
为了验证这个CoT方法的有效性,文中还给出了消解实验的实验结果如下:

我们首先来看一下各组实验都是什么:
- baseline,先用label生成explanation,然后在explanation之后拼上label进行强调;
- 先用label生成explanation,然后删掉句首的label内容,只保留explanation,但是在句尾拼上label的内容;
- 先用label生成explanation,然后只将explanation拼到label之后;
- 和1在格式上保持一致,但是在生成explanation时并不事先告诉模型ground truth,而是让模型自由发挥,然后在模型自由生成的explanation之后拼上ground truth;
- 和4在格式和内容上保持一致,但是对explanation通过一些简单的过滤规则进行一些后处理,去除掉那些和ground truth不一致的解释。
可以看到:
- 实验2,3主要是在考察格式对结果的影响;
- 实验4,5主要是在考察explanation的生成方式对结果的影响;
结论来说:
- 比较1和2,可以看到,句首的grouth truth对于模型的理解有很重要的作用,删除会对模型效果有所影响,即使句末会给到真实的ground truth也一样;
- 比较1和3,我们注意到句末的ground truth label的拼接对于模型效果的影响是比较微弱的;
- 比较1和4,我们发现,如果不使用label让模型生成explanation,事实上并没有起到标准对齐的效果,模型infer的效果下降会很明显;
- 比较4和5,我们注意到即使通过一些规则过滤掉一些明显与ground truth不一致的explanation的情况下,模型效果依然无法恢复到baseline的水平,这可能由于某些问题模型自身始终无法给到正确的explanation,因此无法通过简单规则过滤得到ground truth对应的解释。
3. Consistency & Stability
最后,文章中还考察了一下这一方法的一致性和稳定性,具体来说,就是以下两个点:
- 一致性:生成的不同explanation作为prompt是否都能获得较好的效果;
- 稳定性:不同的few-shot上面CoT是否都能稳定的获得收益;
给出文中的具体实验结果图如下:

可以看到:
- CoT的提升效果是稳定且一致的。
4. 结论 & 思考
综上,这篇文章依然还是一个prompt调优的工作,不过确实感觉很有启发意义。
且核心的思路根据我的理解依然还是在于对齐,虽然文中称之为CoT,不过我个人觉得不是特别合适,因为并没有看出来Chain的效果,更多的感觉还是一个个单例来迫使模型对齐了标准,从而提升了模型判断与人类判断的一致性。
而另一个好的点在于这篇文章的方法论事实上是比较泛化的,基本上可以无缝衔接到所有的分类问题当中,而且实现上也非常简单,倒是可以在我们自己的工作中也试试看,应该可以获得比较好的效果。