Candidate–aware Graph Contrastive Learning for Recommendation论文阅读笔记
Abstract
现存问题:
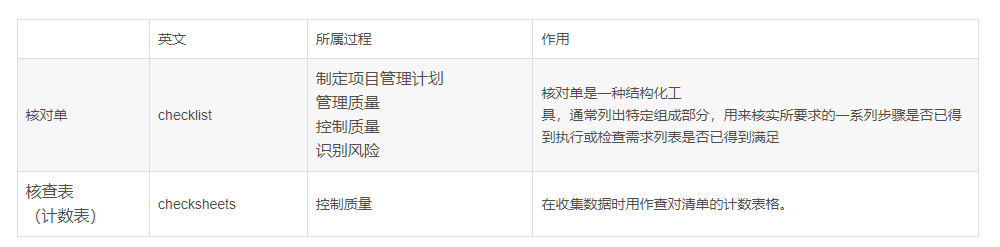
大多数基于gcl的方法使用启发式数据增强方法,即随机节点/边下降和属性掩蔽,来构造对比对,导致重要信息的丢失。
解决方案:
为了解决基于gcl的方法中的问题,我们提出了一种新的方法,候选感知图对比学习推荐,称为CGCL。在CGCL中,我们探讨了不同层嵌入中的用户和候选项之间的关系,并使用相似的语义嵌入来构造对比对。通过我们提出的CGCL,我们构造了结构邻域对比学习对象、候选对比学习对象和候选结构邻域对比学习对象,以获得高质量的节点嵌入。
Introduction
虽然基于gcl的方法已经做了一些改进,但它们忽略了不同层的用户和候选项之间的关系,这限制了它们的性能。具体来说,这些基于gcl的方法只从结构扰动、节点相似度或图结构的角度来构建对比对,而忽略了用户与候选项的不同层嵌入之间的关系。在嵌入空间中,具有相似语义信息的嵌入应该比没有相似语义信息的嵌入更接近。以图1为例,鸡腿应该靠近可乐和西瓜,远离嵌入空间中的书籍和耳机,因为鼓腿、可乐和西瓜属于同一类食物。

在不同层建立用户和候选项目之间的连接可以更好地建模用户的兴趣和项目的特征,并可以更好地探索以更细粒度的用户与项目交互的意图。通过这样做,可以有效地提取出节点间的协同信号。因此,为了更好地建模用户和候选项目之间的关系,我们提出了一种新的图对比学习方法,称为候选感知图对比推荐学习(CGCL)。
本文的贡献如下:
- 为了建立更好的对比对模型,我们建议根据语义相似性,从用户和候选项目的不同嵌入层中选择对比学习对象的锚点、正向实例和负向实例。据我们所知,我们是第一个探索用户和候选条目在不同嵌入层之间关系的图对比学习方法。
- 在CGCL中,我们提出了结构化邻构学习损失对象、候选对比学习损失对象和候选结构邻域对比学习损失对象来提取用户与候选项之间的低阶和高阶关系。有效地提高了节点嵌入的质量。
Method
在这项工作中,我们旨在探索用户和候选项目之间的关系,以提高GNN学习到的节点嵌入的质量。所提出的CGCL模型如图2所示,它由三个组成部分组成:
-
首先,为了建立结构邻居与中心节点之间的关系,我们提出了结构邻居对比学习对象。
-
其次,为了建立用户和候选项目之间的关系,我们提出了候选对比学习对象。
-
第三,为了建立用户的结构邻居与候选项之间的关系,我们提出了候选结构邻居对比学习对象。
模型的结构图如下:

与结构邻居的对比学习
同构的用户(项目)节点通过卷积传播被连接起来。可以认为它们具有相似的语义信息,并且在嵌入空间中彼此更接近。
因此,我们将中心节点本身的嵌入作为锚点,将中心节点的同构邻节点嵌入作为正实例,将其他中心节点的同构邻节点嵌入作为负实例。基于InfoNCE损失,我们提出了结构对比学习对象来最小化齐次邻居节点之间的距离。用户侧的结构邻域对比学习损失函数可以表示如下:
\(\mathcal{L}_S^U=\sum_{u\in\mathcal{U}}-\log\frac{\exp\left(sim\left(e_u^{(k)},e_u^{(0)}\right)/\tau\right)}{\sum_{v\in\mathcal{U}}\exp\left(sim\left(e_u^{(k)},e_v^{(0)}\right)/\tau\right)}.\)
其中,\(e_u^{(k)}\)为用户侧𝑘层卷积的嵌入,𝑘为偶数,𝑠𝑖𝑚为余弦相似度,𝜏为softmax的温度超参数。
同样,项目侧的结构邻域对比学习损失函数可以表示如下:
\(\mathcal{L}_S^I=\sum_{i\in I}-\log\frac{\exp\left(sim\left(e_i^{(k)},e_i^{(0)}\right)/\tau\right)}{\sum_{j\in I}\exp\left(sim\left(e_i^{(k)},e_j^{(0)}\right)/\tau\right)}.\)
其中,\(e_i^{(k)}\)表示𝑘层卷积在项目侧的嵌入。结合这两种损失,我们得到了结构邻域对比学习损失的目标函数如下:
\(\mathcal{L}_{S}=\alpha\mathcal{L}_{S}^{U}+(1-\alpha)\mathcal{L}_{S}^{I}.\)
与候选节点进行对比学习
在本小节中,我们将介绍候选的对比学习对象。对于给定的用户𝑢和候选项𝑖,推荐系统的目标是预测它们之间是否会有交互作用。根据推荐系统的基本假设,相似用户可以与同一项目进行交互。如果用户𝑢和候选项目𝑖具有更高的交互可能性,那么该用户应该与嵌入空间中候选项目的历史交互用户相似。此外,用户𝑢不应该类似于嵌入空间中其他项目的历史交互用户。
因此,在用户方面,我们以用户𝑢的嵌入作为锚点,以候选项𝑖的一阶邻居节点嵌入作为正实例,以其他项的一阶邻居节点嵌入作为负实例。用户侧的候选对比学习损失可以表示如下:
\(\mathcal{L}_{C}^{U}=\sum_{i\in I}-\log\frac{\exp\left(sim\left(e_i^{\left(k^{\prime}\right)},e_u^{(0)}\right)/\tau\right)}{\sum_{v\in\mathcal{U}}\exp\left(sim\left(e_i^{\left(k^{\prime}\right)},e_v^{(0)}\right)/\tau\right)}.\)
其中,\(e_i^{\left(k^{\prime}\right)}\)表示项目侧在𝑘’层的嵌入,𝑘‘为奇数。
同样,在候选项目方面,损失函数与用户的相似
最终的损失函数如下:
\(\mathcal{L}_C=\alpha\mathcal{L}_C^U+(1-\alpha)\mathcal{L}_C^I.\)
与候选结构邻居的对比学习
在本小节中,我们将介绍候选结构邻域对比学习对象,它对应于图2中的C部分。用户(项目)的结构性邻居包含具有相似兴趣的项目(用户)。用户的二阶邻居和项目的一阶邻居是相同类型的节点(用户的类型)。在进行多层卷积时,它们将被连接起来,并且它们之间存在着长距离的依赖关系。如果用户𝑢可以与候选项𝑖交互,则用户𝑢的用户类型邻居节点更接近于嵌入空间中的候选项𝑖的用户类型邻居节点。同时,用户𝑢的项目类型邻居节点也靠近嵌入空间中的项目𝑖的项目类型邻居节点。因此,我们选择用户(项目)的同质性邻居节点作为项目(用户)的正实例。此外,中心节点与远离中心节点的邻居节点之间的关系较弱,因为这种关系包含了更多的噪声和不相关的信息。
因此,我们将距离中心节点较近的邻居节点的嵌入作为锚点,将距离中心节点较远的邻居节点的嵌入作为正例,将距离中心节点较远的其他交互对的结构邻居的嵌入作为负例。用户侧的候选结构邻接对比学习损失可表示如下:
\(\mathcal{L}_{CS}^{U}=\sum_{i\in I}-\log\frac{\exp\left(sim\left(e_i^{(k)},e_u^{(k^{\prime})}\right)/\tau\right)}{\sum_{v\in\mathcal{U}}\exp\left(sim\left(e_i^{(k)},e_v^{(k^{\prime})}\right)/\tau\right)}.\)
项目侧的损失函数相似
最终的损失函数如下:
\(\mathcal{L}_{CS}=\alpha\mathcal{L}_{CS}^{U}+(1-\alpha)\mathcal{L}_{CS}^{I}.\)
CGCL的优化目标
\(\mathcal{L}_{CGCL}=\mathcal{L}_{Rec}+\lambda_{1}\mathcal{L}_{S}+\lambda_{2}\mathcal{L}_{C}+\lambda_{3}\mathcal{L}_{CS}+\lambda_{4}\left\|\Theta\right\|_{2}^{2}.\)
总体算法流程如下:

这篇文章整体看下来感觉都是莫名其妙的层间对比,就是给不同层之间对比找了个理由,候选项目的故事讲的不错,但是方法里面似乎没有体现到。