树形 DP 即在树上进行的 DP。
常见的两种转移方向:
- 父节点 \(\rightarrow\) 子节点:如求节点深度,\(dp_u = dp_{fa} + 1\)
- 子节点 \(\rightarrow\) 父节点:如求子树大小,\(dp_u = 1 + \sum dp_v\)
习题:P5658 [CSP-S2019] 括号树
暴力
本题 \(n\) 小的数据点保证为链,直接枚举 \(i\),代表从根节点到 \(i\) 号节点。枚举 \([1,i]\) 中的子区间左右端点 \([l,r]\),判断该子串是否符合括号匹配。
#include <cstdio>
typedef long long LL;
const int N = 500005;
char s[N];
int f[N];
bool check(int l, int r) {int left = 0;for (int i = l; i <= r; i++) {if (s[i] == '(') left++;else if (left == 0) return false;else left--;}return left == 0;
}
int main()
{int n; scanf("%d%s", &n, s + 1);for (int i = 2; i <= n; i++) scanf("%d", &f[i]);LL ans = 0;for (int i = 2; i <= n; i++) {// 1~iLL cnt = 0;for (int l = 1; l <= i; l++) {for (int r = l; r <= i; r++) {// [l, r]if (check(l, r)) {cnt++;}}}ans ^= cnt * i;}printf("%lld\n", ans);return 0;
}
实际得分 \(20\) 分。
特殊性质
考虑数据为链但 \(n \le 5 \times 10^5\) 的问题做法,此时可以看作是一个线性序列上的问题。
考虑用 \(dp_i\) 表示以 \(s_i\) 结尾的合法括号串,如果 \(s_i\) 是左括号,显然 \(dp_i = 0\);而如果 \(s_i\) 是右括号,这时实际上需要找到与该右括号对应匹配的左括号(这个问题可以借助一个栈来实现),则该左括号到当前的右括号构成了一个合法括号串,而实际上如果这个左括号的前一位是一个合法括号串的结尾,那么之前的合法括号串拼上刚匹配的这个括号串也是一个合法括号串,因此这时 \(dp_i = dp_{pre-1} + 1\),这里的 \(pre\) 代表当前右括号匹配的左括号的位置。
题目要求计算的是合法括号子串的数量,因此只需计算 \(dp\) 结果的前缀和即为前 \(i\) 个字符形成的字符串中合法括号子串的数量。
#include <cstdio>
#include <stack>
using namespace std;
typedef long long LL;
const int N = 500005;
char s[N];
int f[N];
LL dp[N]; // 以s[i]结尾的括号子串数量
LL sum[N]; // 1~i中的括号子串数量,即dp的前缀和
int main()
{int n; scanf("%d%s", &n, s + 1);for (int i = 2; i <= n; i++) scanf("%d", &f[i]);stack<int> stk; // 记录左括号的位置LL ans = 0;for (int i = 1; i <= n; i++) {if (s[i] == '(') {stk.push(i);} else if (!stk.empty()) {int pre = stk.top();stk.pop();dp[i] = dp[pre - 1] + 1;}sum[i] = sum[i - 1] + dp[i];ans ^= sum[i] * i;}printf("%lld\n", ans);return 0;
}
实际得分 \(55\) 分。
解题思路
把处理链的思路转化到任意树上。
其中 \(dp\) 和 \(sum\) 的计算方式可以类推过来,只不过链上通过“减一”表达上一个位置的方式对应到树上要变成“父节点”。因此原来的计算式子需要调整一下:
- \(dp_i = dp_{pre-1} + 1 \rightarrow dp_i = dp_{f_{pre}} + 1\)
- \(sum_i = sum_{i-1} + dp_i \rightarrow sum_i = sum_{f_i} + dp_i\)
除此以外,还需要解决树上的括号栈的递归与回溯问题。发生回溯后,栈里的信息可能会和当前状态不匹配。比如某个节点(左括号)有多棵子树,进入其中一棵子树之后,该子树中的右括号匹配掉了这个左括号(出栈),而接下来再进入下一棵子树时这个左括号依然需要在栈中。
因此回溯时,我们要执行当时递归时相反的操作。比如,当前节点是右括号,如果此时栈不为空,栈会弹出一个元素以匹配当前右括号。我们可以记录这个信息,在最后回溯前把它重新压入栈中,保持状态的一致性。
参考代码
#include <cstdio>
#include <vector>
#include <stack>
using namespace std;
typedef long long LL;
const int N = 500005;
char s[N];
vector<int> tree[N];
stack<int> stk;
int f[N];
LL dp[N], sum[N];
void dfs(int cur, int fa) {int tmp = 0;if (s[cur] == '(') {stk.push(cur); tmp = -1;dp[cur] = 0;} else if (stk.empty()) {dp[cur] = 0;} else {tmp = stk.top(); stk.pop(); dp[cur] = dp[f[tmp]] + 1; }sum[cur] = sum[fa] + dp[cur];for (int to : tree[cur]) dfs(to, cur);if (tmp == -1) stk.pop();else if (tmp > 0) stk.push(tmp);
}
int main()
{int n;scanf("%d%s", &n, s + 1);for (int i = 2; i <= n; i++) {scanf("%d", &f[i]);tree[f[i]].push_back(i);}dfs(1, 0);LL ans = 0;for (int i = 1; i <= n; i++) ans ^= (sum[i] * i);printf("%lld\n", ans);return 0;
}
习题:P4084 [USACO17DEC] Barn Painting G
解题思路
设 \(dp_{u,c}\) 表示以 \(u\) 为根节点的子树,节点 \(u\) 的颜色为 \(c\) 的方案数,即对于所有初始状态,\(dp_{u,1} = dp_{u,2} = dp_{u,3} = 1\),如果某个节点被上了指定的颜色,那么该节点的状态中另外两种上色状态方案数为 \(0\)。
对于每个节点,由于不能与子节点颜色相同,则有:
- \(dp_{u,1} = \prod \limits_{v \in son_u} (dp_{v,2} + dp_{v,3})\)
- \(dp_{u,2} = \prod \limits_{v \in son_u} (dp_{v,1} + dp_{v,3})\)
- \(dp_{u,3} = \prod \limits_{v \in son_u} (dp_{v,1} + dp_{v,2})\)
参考代码
#include <cstdio>
#include <vector>
using namespace std;
const int N = 100005;
const int MOD = 1000000007;
vector<int> tree[N];
int c[N], dp[N][4];
void dfs(int u, int fa) {int ans1 = 1, ans2 = 1, ans3 = 1;for (int v : tree[u]) {if (v == fa) continue;dfs(v, u);ans1 = 1ll * (dp[v][2] + dp[v][3]) % MOD * ans1 % MOD;ans2 = 1ll * (dp[v][1] + dp[v][3]) % MOD * ans2 % MOD;ans3 = 1ll * (dp[v][1] + dp[v][2]) % MOD * ans3 % MOD;}if (c[u] == 0 || c[u] == 1) dp[u][1] = ans1;if (c[u] == 0 || c[u] == 2) dp[u][2] = ans2;if (c[u] == 0 || c[u] == 3) dp[u][3] = ans3;
}
int main()
{int n, k;scanf("%d%d", &n, &k);for (int i = 1; i < n; i++) {int x, y;scanf("%d%d", &x, &y);tree[x].push_back(y); tree[y].push_back(x);}while (k--) {int b;scanf("%d", &b); scanf("%d", &c[b]);}dfs(1, 0);printf("%d\n", ((dp[1][1] + dp[1][2]) % MOD + dp[1][3]) % MOD);return 0;
}
习题:P2899 [USACO08JAN] Cell Phone Network G
解题思路
注意本题和 P2016 战略游戏 的区别,战略游戏是选择一些点从而覆盖所有的边,本题是选择一些点从而覆盖所有的点。
在战略游戏中,一条边可能会被两端的点覆盖到,因此对于每个点对应的子树需要设计两个状态(选/不选)。类似地,在本题中,我们可以要分三种状态:
- \(dp_{u,0}\) 表示 \(u\) 被自己覆盖的情况下对应子树的最少信号塔数量
- \(dp_{u,1}\) 表示 \(u\) 被子节点覆盖的情况下对应子树的最少信号塔数量
- \(dp_{u,2}\) 表示 \(u\) 被父节点覆盖的情况下对应子树的最少信号塔数量
则有状态转移:
- \(dp_{u,0} = \sum \limits_{v \in son_u} \min \{dp_{v,0},dp_{v,1},dp_{v,2}\}\),因为 \(u\) 处自己放置了信号塔,因此子节点处放或不放都可以
- \(dp_{u,1} = dp_{v',0} + \sum \limits_{v \in son_u \land v \ne v'} \min \{ dp_{v,0},dp_{v,1} \}\),此时至少要有一个子节点放置信号塔,其他可放可不放,因此 \(v'\) 应该是所有子节点 \(v\) 中 \(dp_{v,0} - \min \{ dp_{v,0}, dp_{v,1} \}\) 最小的那个子节点;注意若 \(u\) 没有子树即 \(u\) 为叶子节点,此时 \(dp_{u,1}=1\)
- \(dp_{u,2} = \sum \limits_{v \in son_u} \min \{ dp_{v,0}, dp_{v,1} \}\),因为本节点处不放,靠父节点放置来覆盖,所以子节点中除了状态 \(2\) 以外都可以
参考代码
#include <cstdio>
#include <vector>
#include <algorithm>
using namespace std;
const int N = 10005;
vector<int> tree[N];
int dp[N][3];
// dp[u][0]:u处放置
// dp[u][1]:u处依赖子节点放置
// dp[u][2]:u处依赖父节点放置
void dfs(int u, int fa) {dp[u][0] = 1;int best = -1;for (int v : tree[u]) {if (v == fa) continue;dfs(v, u);dp[u][0] += min(min(dp[v][0], dp[v][1]), dp[v][2]);dp[u][2] += min(dp[v][0], dp[v][1]);dp[u][1] += min(dp[v][0], dp[v][1]);// 寻找必须要放置的那个子节点int cur_diff = dp[v][0] - min(dp[v][0], dp[v][1]);int best_diff = dp[best][0] - min(dp[best][0], dp[best][1]);if (best == -1 || cur_diff < best_diff)best = v;}if (best != -1) {// 至少要在一个子节点处放置dp[u][1] += dp[best][0] - min(dp[best][0], dp[best][1]);} else {dp[u][1] = 1; // 没有子树,必须放置}
}
int main()
{int n; scanf("%d", &n);for (int i = 1; i < n; i++) {int a, b; scanf("%d%d", &a, &b);tree[a].push_back(b);tree[b].push_back(a);}dfs(1, 0);printf("%d\n", min(dp[1][0], dp[1][1]));return 0;
}
习题:P3574 [POI2014] FAR-FarmCraft
解题思路
设 \(dp_u\) 表示假如在 \(0\) 时刻到达 \(u\),它的子树被安装好的时间。
发现对下面子树的遍历顺序会影响最终结果,考虑这个顺序,假设针对 \(u\) 的某两棵子树 \(v_1\) 和 \(v_2\):
- 假设先走 \(v_1\) 再走 \(v_2\),则此时可能的完成时间是 \(\max (1 + dp_{v_1}, 2 \times sz_{v_1} + 1 + dp_{v_2})\),前者表示 \(v_1\) 那棵子树完成时间更晚,后者表示 \(v_2\) 那棵子树完成时间更晚,此时要先走完 \(v_1\) 子树再走到 \(v_2\) 才能加 \(dp_{v_2}\)
- 假设先走 \(v_2\) 再走 \(v_1\),则此时可能的完成时间是 \(\max (1 + dp_{v_2}, 2 \times sz_{v_2} + 1 + dp_{v_1})\)
显然我们希望 \(v_1\) 子树和 \(v_2\) 子树形成更好的遍历顺序,考虑按这上面的式子对子树排序。
注意,用上面的式子比大小对子节点排序需要证明 \(\max (1 + dp_{v_1}, 2 \times sz_{v_1} + 1 + dp_{v_2}) < \max (1 + dp_{v_2}, 2 \times sz_{v_2} + 1 + dp_{v_1})\) 这个式子具有传递性。这是可以证明的:假设小于号前面的式子取到第一项,此时这个式子必然满足,因为小于号后面式子的第二项必然比它大,传递性显然成立;假如小于号前面的式子取到第二项,此时相当于需要 \(2 \times sz_{v_1} + dp_{v_2} < 2 \times sz_{v_2} + dp_{v_1}\),这个式子经过移项可以使得小于号左边只和 \(v_1\) 有关,右边只和 \(v_2\) 有关,因此传递性得证。
所以我们可以按这种方式对子树排序,按照子树的遍历依次更新 \(dp_u\),这里的转移式是 \(2 \times sum + 1 + dp_v\),其中 \(sum\) 代表在 \(v\) 这棵子树之前的子树大小总和。
注意最后答案是 \(dp_1\) 和 \(2 \times (n-1) + c_1\) 的较大值,因为题目要求走一圈后回到点 \(1\) 才能开始给 \(1\) 装软件。
参考代码
#include <cstdio>
#include <vector>
#include <algorithm>
using std::vector;
using std::sort;
using std::max;
const int N = 5e5 + 5;
vector<int> tree[N];
int c[N], sz[N], n, dp[N];
void dfs(int u, int fa) {dp[u] = c[u]; sz[u] = 1;for (int v : tree[u]) {if (v == fa) continue;dfs(v, u);sz[u] += sz[v];}sort(tree[u].begin(), tree[u].end(), [](int i, int j) {int i_before_j = max(1 + dp[i], 2 * sz[i] + 1 + dp[j]);int j_before_i = max(1 + dp[j], 2 * sz[j] + 1 + dp[i]);return i_before_j < j_before_i;});int sum = 0;for (int v : tree[u]) {if (v == fa) continue;dp[u] = max(dp[u], 2 * sum + 1 + dp[v]);sum += sz[v];}
}
int main()
{scanf("%d", &n);for (int i = 1; i <= n; i++) {scanf("%d", &c[i]);}for (int i = 1; i < n; i++) {int a, b; scanf("%d%d", &a, &b);tree[a].push_back(b); tree[b].push_back(a);}dfs(1, 0);// 1号点要等回来才能装,所以要考虑2*(n-1)+c[1]printf("%d\n", max(dp[1], 2 * (n - 1) + c[1])); return 0;
}
换根 DP
树形 DP 中的换根 DP 问题又被称为二次扫描,通常需要求以每个点为根时某个式子的答案。
这一类问题通常需要遍历两次树,第一次遍历先求出以某个点(如 \(1\))为根时的答案,在第二次遍历时考虑由根为 \(u\) 转化为根为 \(v\) 时答案的变化(换根)。这个变化往往分为两部分,\(v\) 子树外的点到 \(v\) 相比于到 \(u\) 会增加一条边,而 \(v\) 子树内的点到 \(v\) 相比于到 \(u\) 会减少一条边。所以往往在第一次遍历时可以顺带求出一些子树信息,利用这些信息辅助第二次遍历时的换根操作。
例题:P3478 [POI2008] STA-Station
给定一棵 \(n\) 个节点的树,求出一个节点,使得以这个节点为根时,所有节点的深度之和最大。
数据范围:\(n \le 10^6\)。
随便选择一个节点 \(u\) 作为根节点,遍历整棵树,则得到了以 \(u\) 为根节点时的深度之和。
令 \(dp_u\) 表示以 \(u\) 为根时,所有节点的深度之和。设 \(v\) 为当前节点的某个子节点,考虑“换根”,即以 \(u\) 为根转移到以 \(v\) 为根,显然在换根的过程中,以 \(v\) 为根会导致每个节点的深度都产生改变。具体表现为:
- 所有在 \(v\) 的子树上的节点深度都减少了一,那么总深度和就减少了 \(sz_v\),这里用 \(sz_i\) 表示以 \(i\) 为根的子树中的节点个数。
- 所有不在 \(v\) 的子树上的节点深度都增加了一,那么总深度和就增加了 \(n - sz_v\)。
根据这两个条件就可以推出状态转移方程:\(dp_v = dp_u + n - 2 \times sz_v\),因此可以在第一次遍历时顺便计算一下 \(sz\),第二次遍历时用状态转移方程计算出最终的答案。
#include <cstdio>
#include <vector>
#include <algorithm>
using namespace std;
typedef long long LL;
const int N = 1000005;
vector<int> tree[N];
int sz[N], res, n;
LL ans;
void dfs(int cur, int fa, int depth) {ans += depth;sz[cur] = 1;for (int to : tree[cur]) {if (to == fa) continue;dfs(to, cur, depth + 1);sz[cur] += sz[to];}
}
void solve(int cur, int fa, LL sum) {for (int to : tree[cur]) {if (to == fa) continue;LL tmp = sum + n - 2 * sz[to];if (tmp > ans) {ans = tmp; res = to;}solve(to, cur, tmp);}
}
int main()
{scanf("%d", &n);for (int i = 1; i < n; i++) {int u, v; scanf("%d%d", &u, &v);tree[u].push_back(v); tree[v].push_back(u);}dfs(1, 0, 1);res = 1;solve(1, 0, ans);printf("%d\n", res);return 0;
}
习题:P2986 [USACO10MAR] Great Cow Gathering G
解题思路
与上一题类似,只不过这题换根时的变化量是点权和(即牛棚中奶牛的数量)的变化乘以边权。
参考代码
#include <cstdio>
#include <vector>
using namespace std;
typedef long long LL;
const int N = 100005;
int n, c[N];
LL ans;
struct Edge {int to, l;
};
vector<Edge> tree[N];
void dfs(int cur, int fa, int depth) {ans += 1ll * depth * c[cur];for (Edge e : tree[cur]) {if (e.to == fa) continue;dfs(e.to, cur, depth + e.l);c[cur] += c[e.to];}
}
void solve(int cur, int fa, LL sum) {for (Edge e : tree[cur]) {if (e.to == fa) continue;LL tmp = sum + 1ll * (c[1] - 2 * c[e.to]) * e.l;ans = min(ans, tmp);solve(e.to, cur, tmp);}
}
int main()
{scanf("%d", &n);for (int i = 1; i <= n; i++) scanf("%d", &c[i]);for (int i = 1; i < n; i++) {int a, b, l; scanf("%d%d%d", &a, &b, &l);tree[a].push_back({b, l}); tree[b].push_back({a, l});}dfs(1, 0, 0);solve(1, 0, ans);printf("%lld\n", ans);return 0;
}
习题:P3047 [USACO12FEB] Nearby Cows G
解题思路
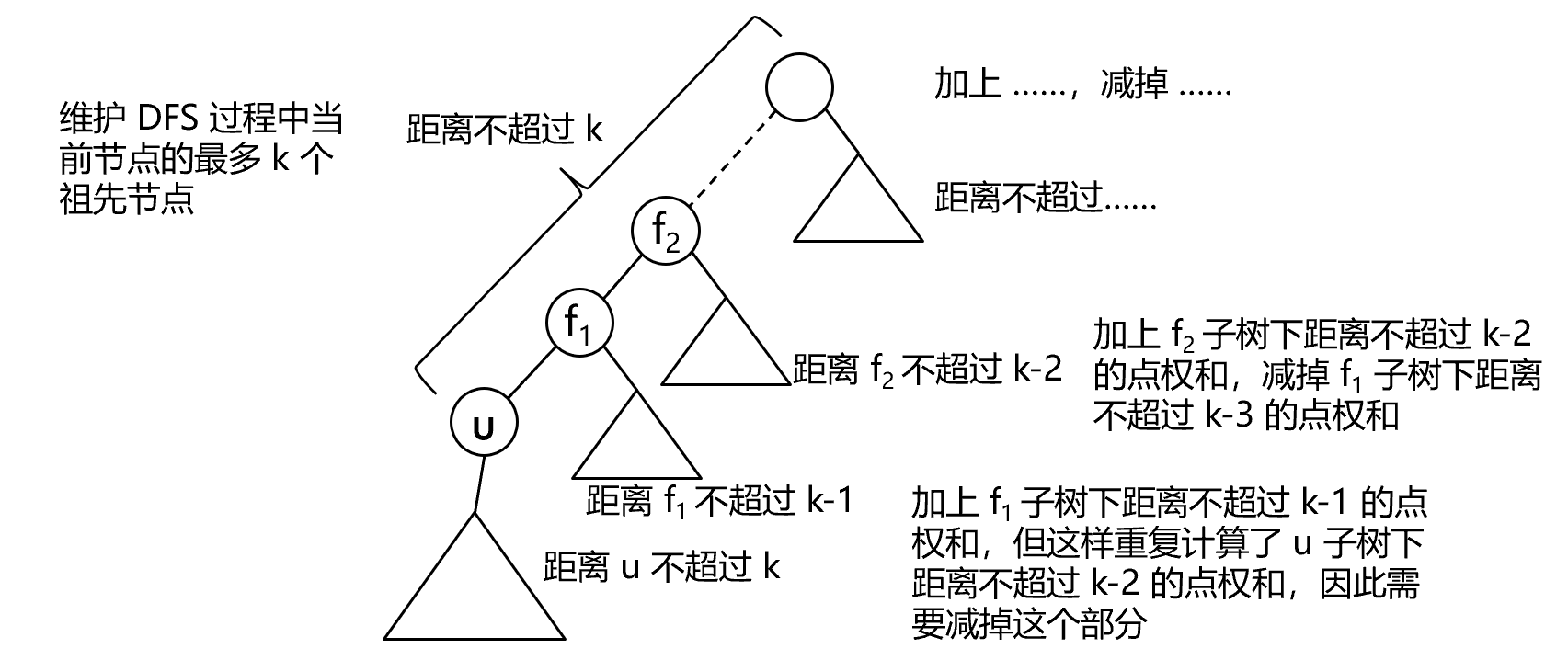
可以先对树做一次遍历得到每个节点对应的子树下距离子树根节点距离 \(0 \sim x\) 之间的点权和,
然后考虑每个点距离 \(k\) 之内的点权和。子树下的点权和在第一次遍历时已经计算完成,因此还需要计算的是在该点子树外的距离 \(k\) 以内的部分,而这个部分可以通过对该点上方最多 \(k\) 个祖先节点的处理,如下图所示。
参考代码
#include <cstdio>
#include <vector>
using std::vector;
const int N = 100005;
const int K = 25;
vector<int> tree[N];
int n, k, sum[N][K], c[N], ans[N];
void dfs(int u, int fa) {for (int v : tree[u]) {if (v == fa) continue;dfs(v, u);for (int i = 1; i <= k; i++) {sum[u][i] += sum[v][i - 1];}}sum[u][0] = c[u];
}
void calc(int u, int fa, vector<int> pre) {int dis = pre.size();pre.push_back(u);// u的子树内的距离范围内的点权和ans[u] = sum[u][k];// 计算u的子树外的距离范围内的点权和for (int i = 0; i + 1 < pre.size(); i++) {int cur = pre[i], nxt = pre[i + 1];// 对于边cur->nxtans[u] += sum[cur][k - dis]; // 加上cur子树下的距离内点权和if (k - dis > 0) ans[u] -= sum[nxt][k - dis - 1]; // 减去nxt子树下刚刚被重复计算的部分dis--;}vector<int> path;if (pre.size() == k + 1) {// pre[0]即将超出下面的点的距离范围k,要被淘汰for (int i = 1; i < pre.size(); i++) path.push_back(pre[i]);} else path = pre;for (int v : tree[u]) {if (v == fa) continue;calc(v, u, path);}
}
int main()
{scanf("%d%d", &n, &k);for (int i = 1; i < n; i++) {int u, v; scanf("%d%d", &u, &v);tree[u].push_back(v); tree[v].push_back(u);}for (int i = 1; i <= n; i++) scanf("%d", &c[i]);dfs(1, 0);// 生成前缀和for (int i = 1; i <= n; i++) {for (int j = 1; j <= k; j++) sum[i][j] += sum[i][j - 1];}vector<int> tmp;calc(1, 0, tmp);for (int i = 1; i <= n; i++) printf("%d\n", ans[i]);return 0;
}
树上背包
树上的背包问题,也就是背包问题与树形 DP 的结合。
例题:P2014 [CTSC1997] 选课
有 \(n\) 门课程,第 \(i\) 门课程的学分为 \(a_i\),每门课程有零门或一门先修课,有先修课的课程需要先学完其先修课,才能学习该课程。一位学生要学习 \(m\) 门课程,求其能获得的最多学分数。
数据范围:\(n,m \le 300\)
由于每门课最多只有一门先修课,与有根树中一个点最多只有一个父亲节点的特点类似。可以利用这个性质来建树,从而所有课程形成了一个森林结构。为了方便起见,可以新增一门 \(0\) 学分的课程(编号为 \(0\)),作为所有无先修课课程的先修课,这样原本的森林就变成了一棵以 \(0\) 号节点为根的树。
设 \(dp_{u,i,j}\) 表示以 \(u\) 为根的子树中,已经遍历了 \(u\) 号点的前 \(i\) 棵子树,选了 \(j\) 门课程的最大学分。
转移的过程结合了树形 DP 和背包问题的特点,枚举点 \(u\) 的每个子节点 \(v\),同时枚举以 \(v\) 为根的子树选了几门课程,将子树的结果合并到 \(u\) 上。
将点 \(x\) 的子节点个数记为 \(s_x\),以 \(x\) 为根的子树大小为 \(sz_x\),则有状态转移方程:\(dp_{u,i,j} = \max \{ dp_{u,i-1,j-k} + dp_{v,s_v,k} \}\),注意有一些状态是无效的,比如 \(k>j\) 或是 \(k>sz_v\) 时。
第二维可以通过滚动数组优化掉,此时需要倒序枚举 \(j\) 的值,同 0-1 背包问题。
该做法的时间复杂度为 \(O(nm)\),证明见 子树合并背包类型的dp的复杂度证明。
#include <cstdio>
#include <vector>
#include <algorithm>
using namespace std;
const int N = 305;
vector<int> tree[N];
int s[N], dp[N][N], n, m;
int dfs(int u) {int sz_u = 1;dp[u][1] = s[u];for (int v : tree[u]) {int sz_v = dfs(v);for (int i = min(sz_u, m + 1); i > 0; i--)for (int j = 1; j <= sz_v && i + j <= m + 1; j++)dp[u][i + j] = max(dp[u][i + j], dp[u][i] + dp[v][j]);sz_u += sz_v;}return sz_u;
}
int main()
{scanf("%d%d", &n, &m);for (int i = 1; i <= n; i++) {int k;scanf("%d%d", &k, &s[i]);tree[k].push_back(i);}dfs(0);printf("%d\n", dp[0][m + 1]);return 0;
}
习题:P3177 [HAOI2015] 树上染色
解题思路
显然设 \(dp_{u,i}\) 代表以 \(u\) 为根节点的子树,将其中 \(i\) 个点染成黑色的状态。
但是这个值存什么呢?如果直接表示子树内黑点、白点间的收益,这个状态没有办法转移,因为子树内最大化收益的染色方案被合并上去后未必是最优的方案,也就是有后效性。
考虑每条边对最终答案的贡献,如果一条边的两侧有一对黑点或白点,则这条边对这两个点构成的路径是有贡献的。也就是说,一条边对总答案的贡献次数等于边的两侧同色点个数的乘积。而子树内每条边对总答案的贡献这个状态值在子树合并过程中是可以向上传递的。
因此 \(dp_{u,i}\) 代表以 \(u\) 为根节点的子树中有 \(i\) 个点被染成黑色后子树内每一条边对总答案的贡献,类似树上背包,当要合并某个子节点 \(v\) 对应的子树时,枚举子树中的黑点数量 \(j\),则对应的转移为 \(dp_{u,i-j} + dp_{v,j} + w(u,v) \times c(u,v)\),其中 \(w(u,v)\) 代表边权,\(c(u,v)\) 代表 u-v 这条边对总答案的贡献,而 \(c(u,v) = j \times (k - j) + (sz_v - j) \times (n - sz_v - (k - j))\)。
参考代码
#include <cstdio>
#include <utility>
#include <vector>
#include <algorithm>
using std::pair;
using std::vector;
using std::min;
using std::max;
typedef long long LL;
typedef pair<int, int> PII;
const int N = 2005;
int n, k;
vector<PII> tree[N];
LL dp[N][N]; // dp[u][i] u的子树内染i个黑点时边对答案的总贡献
int dfs(int u, int fa) {int sz_u = 1;for (PII p : tree[u]) {int v = p.first, w = p.second;if (v == fa) continue;int sz_v = dfs(v, u);for (int i = min(k, sz_u); i >= 0; i--) {for (int j = 1; j <= sz_v && i + j <= k; j++) {LL black = 1ll * w * j * (k - j);LL white = 1ll * w * (sz_v - j) * (n - sz_v - (k - j));dp[u][i + j] = max(dp[u][i + j], dp[u][i] + dp[v][j] + black + white);}// 若将j=0放在循环中,则会立马更新dp[u][i]// 导致接下来计算dp[u][i+j]时用到的dp[u][i]已经不是之前的值了LL white = 1ll * w * sz_v * (n - sz_v - k);dp[u][i] += dp[v][0] + white;}sz_u += sz_v;}return sz_u;
}
int main()
{scanf("%d%d", &n, &k);for (int i = 1; i < n; i++) {int u, v, w; scanf("%d%d%d", &u, &v, &w);tree[u].push_back({v, w}); tree[v].push_back({u, w});}dfs(1, 0);printf("%lld\n", dp[1][k]);return 0;
}



![CSP历年复赛题-P1036 [NOIP2002 普及组] 选数](https://img2024.cnblogs.com/blog/3330618/202401/3330618-20240131111304043-1609597753.png)