llama3简介
llama3 是meta 2024年4月18日发布的开源的大语言模型, 发布当时是state-of-art(最牛逼)的开源LLM,下图是llama3和其他主流模型评测对比:
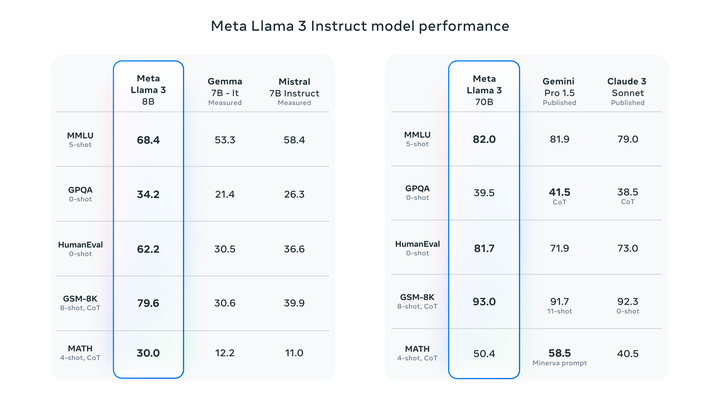
llama3官方发布了两个模型的参数:8B和70B(B代表Billion, 10亿),以及发布了用于推理的源代码,官方github地址:https://github.com/meta-llama/llama3
下载代码后,我们主要讲解8B模型, 其中model.py就是模型的核心代码,generation.py是推理代码(我们把模型接收用户输入, 然后吐出输出的计算过程叫做推理:inference)。 接下来上干货, 跟着作者一步一步来拆解这个模型。
llama3主体介绍
llama3主要的技术框架为Transformer, 具体是decode-only transformer, 主体框架和GPT-2差不多.
generation.py的class Llama的build方法来创建model
model = Transformer(model_args)
Transformer是model.py里的Transformer类
model_args是模型参数:
-
max_seq_len: 最大序列长度, 这个长度是推理计算中最长的token长度,后面还会讲到这个长度
-
max_batch_size:最大一批大小,模型一次处理多少次推理(这个可有讲, 以后有机会再讲)
-
vocab_size : token 表大小
模型接受用户输入, 该输入称为prompt(中文为提示,大家知道为什么将大模型使用者叫做提示工程师吗🤣)
tokenizer
首先使用tokenizer, 把输入分割成一个一个token, token并不是和字或者字母一对一对应,有可能是几个单词对应一个token,有可能一个字拆分为几个token,为什么要分割以及根据什么依据来分割, 大家可以问下chatGPT

llama3使用了自己的tokenizer, 每个LLM都会自己的tokenizer.
然后模型根据输入来推理, 然后输出一个token,然后再把输出的token, 拼接到输入后面, 再计算下一个token. 直到遇到代表输出停止的符号(
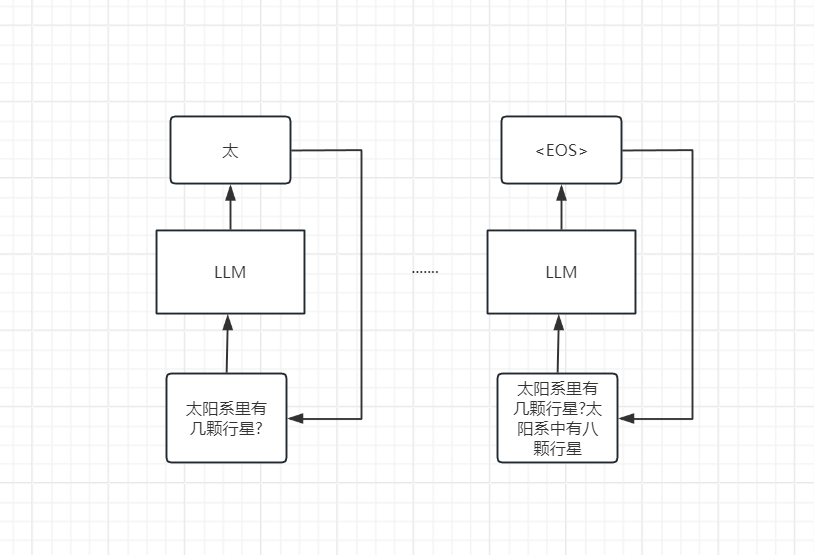
所以LLM又叫做自回归模型(Auto Regression Model). 那你想问为什么用户问LLM问题, LLM能够回答问题.
LLM的训练过程
粗略的来理解一下,LLM在训练的过程中使用了海量文本的数据, 海量的文本数据先切成最大为max_seq_len大小, 切出的分片一般具有完整的语义信息(比如一篇文章的其中一个自然段具有完整的语义信息), 然后以前面的一句或几句话作为输入, 让模型计算下一个token, 模型计算的token 和真实文本的token一般都是不一样的, 这样就产生了误差(loss), 然后再用真实的token添加到输入的后面(是真实的token不是模型产生的token, 该过程在专业术语叫做指导学习), 就这样一个一个token的计算, 直至遇到
给定输入token \(X_{1...i}\), 与模型的参数\(\Theta\)运算,然后输出下一个token \(X_{i+1}\)的概率
模型输出的大小为vocab_size大小的概率分布, 每个概率值代表着对应的token做为下一个token输出的概率大小, 训练的目标就是使得模型输出下一个真实的(ground truth)token的概率最大化, 如果模型输出下一个token概率分布中真实的token概率为1, 其他的token为0, 那将不会产生loss, loss等于0,不会进行反向传播, 反之输出的真实的token概率不是1, 甚至不是最大的, 那么loss不等于0, loss将会进行反向传播, 逐级传递到每层参数中,然后按照梯度下降的方向调整参数, 使得模型学会输出正确的token。
llama3预测下一个token
llama3还不太一样, 没有完全用最大概率预测下个token
logits = self.model.forward(tokens[:, prev_pos:cur_pos], prev_pos)
if temperature > 0:probs = torch.softmax(logits[:, -1] / temperature, dim=-1)next_token = sample_top_p(probs, top_p)
else:next_token = torch.argmax(logits[:, -1], dim=-1)m=-1)
logits是未归一化(归一化就是使得所有元素之和等于1)的分数, 经过softmax运算后才是概率。temperature就是各种大语言模型里API中的temperature参数,用于控制生成token时的随机性和多样性,通过调整 temperature,可以影响模型生成token的确定性和创造性。sample_top_p是top p算法函数, 原理为输出的token概率按从大到小排序, 选择前m项token,其概率的和刚超过了设定的阈值top_p, 然后再从选择的token中按照其归一化后的概率大小采样(玩过统计概率的都知道采样是什么意思, 通俗的来讲就是抽奖,token概率越大, 被抽中的可能性越高)。
如果temperature为0, 就是简单的取最大概率的token。
生成的token再经过 tokenizer.decode(t) 就可以解码成对应的单词。
llama3结构图
接下来我们讲深入模型内部, 一探究竟。
我们先看下模型的结构图
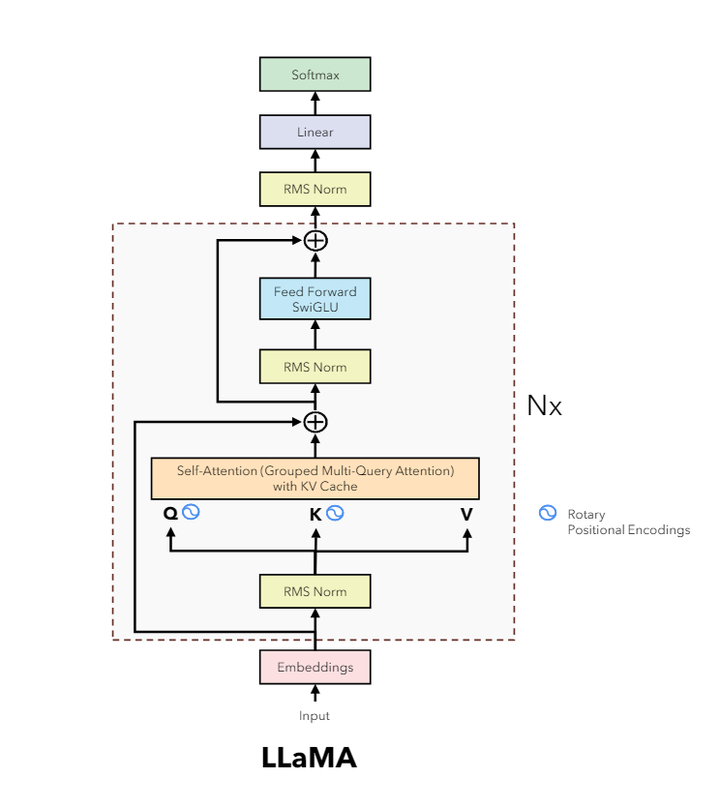
Nx表示重复N层
⊕ 表示残差连接
太极符号表示旋转位置编码, 每一层的自注意力运算前q和k都加入位置编码信息
中间的自注意力机制使用的是分组查询注意力机制, 并且使用了kv cache缓存
llama3 8B 模型超参数
我们以Meta-Llama-3-8B-Instruct模型为例, 看下模型的超参, 就是params.json
{"dim": 4096,"n_layers": 32,"n_heads": 32,"n_kv_heads": 8,"vocab_size": 128256,"multiple_of": 1024,"ffn_dim_multiplier": 1.3,"norm_eps": 1e-05,"rope_theta": 500000.0
}
dim是token向量的维度
n_layers表示有多少层TransformerBlock
n_heads表示多头注意力机制(Multi-Head Attention)里的头数
n_kv_heads表示分组查询注意力机制(Group Query Attention)里的kv头数
vocab_size表示字典大小
multiple_of表示TransformerBlock中最后的全连接FeadForward中的隐藏层维度hidden_dim的倍数因子(注意哈, 是倍数因子不是倍数, hidden_dim 为 multiple_of 的整数倍)
ffn_dim_multiplier表示上面的hidden_dim放大倍数
norm_eps归一化层用到的很小的数, 以免出现除以0的错误
rope_theta是位置编码用到的参数θ
欲知详情, 请见下回分解