本文讲讲述如何使用Python在自定义人脸检测数据集上微调预训练的目标检测模型。学习如何为Detectron2和PyTorch准备自定义人脸检测数据集,微调预训练模型以在图像中找到人脸边界。
人脸检测是在图像中找到(边界的)人脸的任务。这在以下情况下很有用:
安全系统(识别人员的第一步)
为拍摄出色的照片进行自动对焦和微笑检测
检测年龄、种族和情感状态以用于营销

历史上,这是一个非常棘手的问题。大量的手动特征工程、新颖的算法和方法被开发出来以改进最先进技术。
如今,人脸检测模型已经包含在几乎每个计算机视觉包/框架中。其中一些表现最佳的模型使用了深度学习方法。例如,OpenCV提供了各种工具,如级联分类器。
在本指南中,您将学习如何:
准备一个用于人脸检测的自定义数据集,以用于Detectron2
使用(接近)最先进的目标检测模型在图像中查找人脸
您可以将这项工作扩展到人脸识别
Detectron2
Detectron2是一个用于构建最先进的目标检测和图像分割模型的框架,由Facebook Research团队开发。Detectron2是第一个版本的完全重写。Detectron2使用PyTorch(与最新版本兼容),并且允许进行超快速训练。您可以在Facebook Research的入门博客文章中了解更多信息。
Detectron2的真正强大之处在于模型动物园中提供了大量的预训练模型。但是,如果您不能在自己的数据集上对其进行微调,那又有什么好处呢?幸运的是,这非常容易!在本指南中,我们将看到如何完成这项工作。
安装Detectron2
在撰写本文时,Detectron2仍处于alpha阶段。虽然有官方版本,但我们将从主分支克隆和编译。这应该等于版本0.1。让我们首先安装一些要求:
!pip install -q cython pyyaml == 5.1
!pip install -q -U 'git+https://github.com/cocodataset/cocoapi.git#subdirectory=PythonAPI'然后,下载、编译和安装Detectron2包:
!git clone https://github.com/facebookresearch/detectron2 detectron2_repo
!pip install -q -e detectron2_repo此时,您需要重新启动笔记本运行时以继续!
%reload_ext watermark %watermark -v -p numpy,pandas,pycocotools,torch,torchvision,detectron2
CPython 3.6.9
IPython 5.5.0
numpy 1.17.5
pandas 0.25.3
pycocotools 2.0
torch 1.4.0
torchvision 0.5.0
detectron2 0.1import torch, torchvision
import detectron2
from detectron2.utils.logger import setup_logger
setup_logger()import globimport os
import ntpath
import numpy as np
import cv2
import random
import itertools
import pandas as pd
from tqdm import tqdm
import urllib
import json
import PIL.Image as Imagefrom detectron2 import model_zoo
from detectron2.engine import DefaultPredictor, DefaultTrainer
from detectron2.config import get_cfg
from detectron2.utils.visualizer import Visualizer, ColorMode
from detectron2.data import DatasetCatalog, MetadataCatalog, build_detection_test_loader
from detectron2.evaluation import COCOEvaluator, inference_on_dataset
from detectron2.structures import BoxModeimport seaborn as sns
from pylab import rcParams
import matplotlib.pyplot as plt
from matplotlib import rc%matplotlib inline
%config InlineBackend.figure_format='retina'sns.set(style='whitegrid', palette='muted', font_scale=1.2)HAPPY_COLORS_PALETTE = ["#01BEFE", "#FFDD00", "#FF7D00", "#FF006D", "#ADFF02", "#8F00FF"]sns.set_palette(sns.color_palette(HAPPY_COLORS_PALETTE))rcParams['figure.figsize'] = 12, 8RANDOM_SEED = 42
np.random.seed(RANDOM_SEED)
torch.manual_seed(RANDOM_SEED)人脸检测数据
该数据集在公共领域免费提供。它由Dataturks提供,并托管在Kaggle上:图像中标有边界框的人脸。有大约500张图像,通过边界框手动标记了大约1100个人脸。
我已经下载了包含注释的JSON文件,并将其上传到了Google Drive。让我们获取它:
!gdown --id 1K79wJgmPTWamqb04Op2GxW0SW9oxw8KS让我们将文件加载到Pandas数据框中:
faces_df = pd.read_json('face_detection.json', lines=True)每行包含一个单独的人脸注释。请注意,多行可能指向单个图像(例如,每个图像有多个人脸)。
数据预处理
数据集仅包含图像URL和注释。我们将不得不下载这些图像。我们还将对注释进行标准化,以便稍后在Detectron2中更容易使用:
os.makedirs("faces", exist_ok=True)dataset = []for index, row in tqdm(faces_df.iterrows(), total=faces_df.shape[0]):img = urllib.request.urlopen(row["content"])img = Image.open(img)img = img.convert('RGB')image_name = f'face_{index}.jpeg'img.save(f'faces/{image_name}', "JPEG")annotations = row['annotation']for an in annotations:data = {}width = an['imageWidth']height = an['imageHeight']points = an['points']data['file_name'] = image_namedata['width'] = widthdata['height'] = heightdata["x_min"] = int(round(points[0]["x"] * width))data["y_min"] = int(round(points[0]["y"] * height))data["x_max"] = int(round(points[1]["x"] * width))data["y_max"] = int(round(points[1]["y"] * height))data['class_name'] = 'face'dataset.append(data)让我们将数据放入数据框中,以便我们可以更好地查看:
df = pd.DataFrame(dataset)
print(df.file_name.unique().shape[0], df.shape[0])409 1132我们总共有409张图像(比承诺的500张少得多)和1132个注释。让我们将它们保存到磁盘上(以便您可以重用它们):
数据
让我们查看一些示例注释数据。我们将使用OpenCV加载图像,添加边界框并调整大小。我们将定义一个助手函数来完成所有这些操作:
def annotate_image(annotations, resize=True):file_name = annotations.file_name.to_numpy()[0]img = cv2.cvtColor(cv2.imread(f'faces/{file_name}'), cv2.COLOR_BGR2RGB)for i, a in annotations.iterrows():cv2.rectangle(img, (a.x_min, a.y_min), (a.x_max, a.y_max), (0, 255, 0), 2)if not resize:return imgreturn cv2.resize(img, (384, 384), interpolation = cv2.INTER_AREA)让我们首先显示一些带注释的图像:


这些都是不错的图像,注释清晰可见。我们可以使用torchvision创建一个图像网格。请注意,这些图像具有不同的大小,因此我们将对其进行调整大小:

您可以清楚地看到一些注释缺失(第4列)。这就是现实生活中的数据,有时您必须以某种方式处理它。
使用Detectron 2进行人脸检测
现在,我们将逐步介绍使用自定义数据集微调模型的步骤。但首先,让我们保留5%的数据进行测试:
df = pd.read_csv('annotations.csv')IMAGES_PATH = f'faces'unique_files = df.file_name.unique()train_files = set(np.random.choice(unique_files, int(len(unique_files) * 0.95), replace=False))
train_df = df[df.file_name.isin(train_files)]
test_df = df[~df.file_name.isin(train_files)]在这里,经典的训练测试分割方法不适用,因为我们希望在文件名之间进行分割。
接下来的部分以稍微通用的方式编写。显然,我们只有一个类别-人脸。但是,添加更多类别应该就像向数据框中添加更多注释一样简单:
classes = df.class_name.unique().tolist()接下来,我们将编写一个将我们的数据集转换为Detectron2:
def create_dataset_dicts(df, classes):dataset_dicts = []for image_id, img_name in enumerate(df.file_name.unique()):record = {}image_df = df[df.file_name == img_name]file_path = f'{IMAGES_PATH}/{img_name}'record["file_name"] = file_pathrecord["image_id"] = image_idrecord["height"] = int(image_df.iloc[0].height)record["width"] = int(image_df.iloc[0].width)objs = []for _, row in image_df.iterrows():xmin = int(row.x_min)ymin = int(row.y_min)xmax = int(row.x_max)ymax = int(row.y_max)poly = [(xmin, ymin), (xmax, ymin),(xmax, ymax), (xmin, ymax)]poly = list(itertools.chain.from_iterable(poly))obj = {"bbox": [xmin, ymin, xmax, ymax],"bbox_mode": BoxMode.XYXY_ABS,"segmentation": [poly],"category_id": classes.index(row.class_name),"iscrowd": 0}objs.append(obj)record["annotations"] = objsdataset_dicts.append(record)return dataset_dicts使用的格式的函数:我们将每个注释行转换为一个具有注释列表的单个记录。您可能还会注意到,我们正在构建一个与边界框完全相同形状的多边形。这对于Detectron2中的图像分割模型是必需的。
您将不得不将数据集注册到数据集和元数据目录中:
for d in ["train", "val"]:DatasetCatalog.register("faces_" + d, lambda d=d: create_dataset_dicts(train_df if d == "train" else test_df, classes))MetadataCatalog.get("faces_" + d).set(thing_classes=classes)statement_metadata = MetadataCatalog.get("faces_train")不幸的是,默认情况下不包含测试集的评估器。我们可以通过编写自己的训练器轻松修复它:
class CocoTrainer(DefaultTrainer):@classmethoddef build_evaluator(cls, cfg, dataset_name, output_folder=None):if output_folder is None:os.makedirs("coco_eval", exist_ok=True)output_folder = "coco_eval"return COCOEvaluator(dataset_name, cfg, False, output_folder)如果未提供文件夹,则评估结果将存储在coco_eval文件夹中。
在Detectron2模型上微调与编写PyTorch代码完全不同。我们将加载配置文件,更改一些值,然后启动训练过程。但是嘿,如果您知道自己在做什么,这真的会有所帮助。在本教程中,我们将使用Mask R-CNN X101-FPN模型。它在COCO数据集上进行了预训练,并且表现非常好。缺点是训练速度较慢。
让我们加载配置文件和预训练的模型权重:
cfg = get_cfg()cfg.merge_from_file(model_zoo.get_config_file("COCO-InstanceSegmentation/mask_rcnn_X_101_32x8d_FPN_3x.yaml")
)cfg.MODEL.WEIGHTS = model_zoo.get_checkpoint_url("COCO-InstanceSegmentation/mask_rcnn_X_101_32x8d_FPN_3x.yaml"
)指定我们将用于训练和评估的数据集(我们注册了这些数据集):
cfg.DATASETS.TRAIN = ("faces_train",)
cfg.DATASETS.TEST = ("faces_val",)
cfg.DATALOADER.NUM_WORKERS = 4至于优化器,我们将进行一些魔法以收敛到某个好的值:
cfg.SOLVER.IMS_PER_BATCH = 4
cfg.SOLVER.BASE_LR = 0.001
cfg.SOLVER.WARMUP_ITERS = 1000
cfg.SOLVER.MAX_ITER = 1500
cfg.SOLVER.STEPS = (1000, 1500)
cfg.SOLVER.GAMMA = 0.05除了标准的内容(批量大小、最大迭代次数和学习率)外,我们还有几个有趣的参数:
WARMUP_ITERS - 学习率从0开始,并在此次数的迭代中逐渐增加到预设值
STEPS - 学习率将在其检查点(迭代次数)降低的次数
最后,我们将指定类别的数量以及我们将在测试集上进行评估的周期:
cfg.MODEL.ROI_HEADS.BATCH_SIZE_PER_IMAGE = 64
cfg.MODEL.ROI_HEADS.NUM_CLASSES = len(classes)cfg.TEST.EVAL_PERIOD = 500是时候开始训练了,使用我们自定义的训练器:
os.makedirs(cfg.OUTPUT_DIR, exist_ok=True)trainer = CocoTrainer(cfg)
trainer.resume_or_load(resume=False)
trainer.train()评估目标检测模型
与评估标准分类或回归模型相比,评估目标检测模型有点不同。您需要了解的主要指标是IoU(交并比)。它测量两个边界之间的重叠程度-预测的和真实的。它可以在0和1之间获得值。

使用IoU,可以定义阈值(例如> 0.5)来分类预测是否为真阳性(TP)或假阳性(FP)。现在,您可以通过获取精度-召回曲线下的区域来计算平均精度(AP)现在,AP@X(例如AP50)只是某个IoU阈值下的AP。这应该让您对如何评估目标检测模型有一个工作的了解。
我已经准备了一个预训练模型,因此不必等待训练完成。下载它:
!gdown --id 18Ev2bpdKsBaDufhVKf0cT6RmM3FjW3nL
!mv face_detector.pth output/model_final.pth我们可以通过加载模型并设置最低的85%的置信度阈值来开始进行预测,以此来将预测视为正确:
cfg.MODEL.WEIGHTS = os.path.join(cfg.OUTPUT_DIR, "model_final.pth")
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.85
predictor = DefaultPredictor(cfg)运行评估器与训练好的模型:
evaluator = COCOEvaluator("faces_val", cfg, False, output_dir="./output/")
val_loader = build_detection_test_loader(cfg, "faces_val")
inference_on_dataset(trainer.model, val_loader, evaluator)在图像中查找人脸
接下来,让我们创建一个文件夹,并保存测试集中所有带有预测注释的图像:
os.makedirs("annotated_results", exist_ok=True)test_image_paths = test_df.file_name.unique()
for clothing_image in test_image_paths:file_path = f'{IMAGES_PATH}/{clothing_image}'im = cv2.imread(file_path)outputs = predictor(im)v = Visualizer(im[:, :, ::-1],metadata=statement_metadata,scale=1.,instance_mode=ColorMode.IMAGE)instances = outputs["instances"].to("cpu")instances.remove('pred_masks')v = v.draw_instance_predictions(instances)result = v.get_image()[:, :, ::-1]file_name = ntpath.basename(clothing_image)write_res = cv2.imwrite(f'annotated_results/{file_name}', result)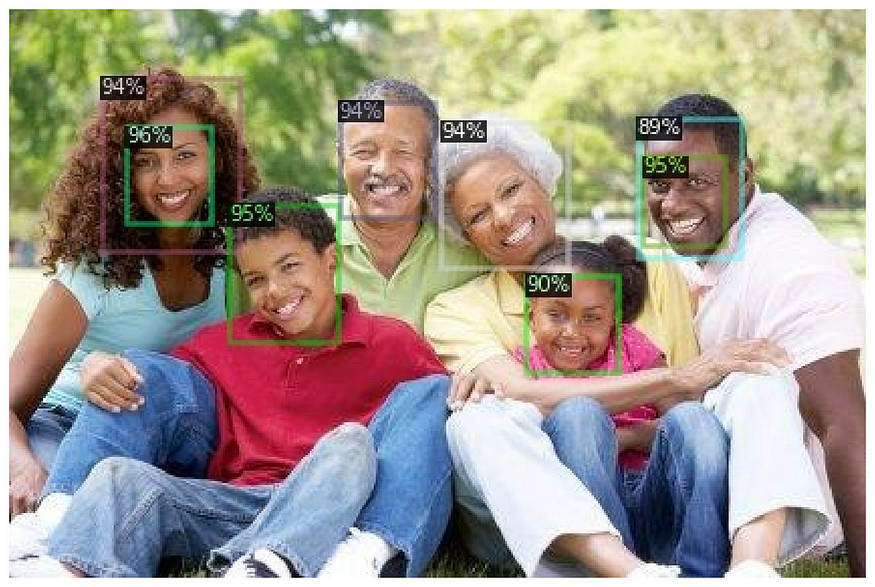
· END ·
HAPPY LIFE

本文仅供学习交流使用,如有侵权请联系作者删除