1.有如下的四个/24地址块,试进行最大可能的聚合
212.56.132.0/24 212.56.133.0/24 212.56.134.0/24 212.65.135.0/24
主要区别在第三字节
1000 0100
1000 0101
1000 0110
1000 0111
所以最长相同前缀为
1000 0100 为132
212.56.132.0/22
2.一个UDP用户数据报的数据部分为4192B,该分组应该被划分成几个IP分片?说明每一个IP分片的数据部分长度、分片偏移量的值以及MF比特的取值。
UDP首部为8B,整个UDP长度为4192+8 = 5000B,作为IP数据包的数据部分,MTU为1500B,IP数据包首部为20B。
为了将UDP用户数据报的数据部分(4192B)划分为IP分片,需要考虑IP分片的具体规则。IP分片有以下几点需要注意:
- IP数据包的总长度不能超过65535字节。
- 每个IP分片的数据部分长度应该是8字节的倍数(因为分片偏移量是以8字节为单位的)。
- 每个IP分片的头部长度是20字节。
首先计算分片的数量和每个分片的数据部分长度:
4192字节的数据部分需要分片。每个分片的数据部分最大为8字节的倍数,且IP分片的总长度应尽可能接近但不超过65535字节。
假设每个分片的数据部分尽可能大:
最大数据部分 = 1480字节(1500字节的MTU - 20字节的IP头) MTU网络层的,针对IP数据包的
计算分片数量:
分片数 = ⌈4192 / 1480⌉ = 3
因为4192字节的数据部分不能整除1480,所以最后一个分片的数据部分会少于1480字节。
具体分片如下:
-
第一个分片:
- 数据部分长度:1480字节
- 分片偏移量:0(第一个分片的偏移量为0)
- MF比特:1(还有后续分片)
-
第二个分片:
- 数据部分长度:1480字节
- 分片偏移量:185(因为1480字节 / 8 = 185)
- MF比特:1(还有后续分片)
-
第三个分片:
- 数据部分长度:1232字节(4192 - 1480 - 1480 = 1232字节)
- 分片偏移量:370(1480 * 2 / 8 = 370)
- MF比特:0(这是最后一个分片,没有后续分片)
3.一个A类网络和一个B类网络的子网号分别为16位1和8位1.分别写出这两个网络的子网掩码。这两个子网掩码所代表的意义有什么不同?
一个A类网络和一个B类网络的子网号分别为16位1和8位1,这些子网掩码有不同的表示和意义。
A类网络的子网掩码
一个A类网络默认的子网掩码是255.0.0.0,也就是只有前8位为1(前8位表示网络号)。
如果子网号为16位1,即子网掩码为:
11111111.11111111.00000000.00000000
转换为十进制表示为:
255.255.0.0
B类网络的子网掩码
一个B类网络默认的子网掩码是255.255.0.0,也就是前16位为1(前16位表示网络号)。
如果子网号为8位1,即子网掩码为:
11111111.11111111.11111111.00000000
转换为十进制表示为:
255.255.255.0
子网掩码的意义
-
A类网络的子网掩码(255.255.0.0):
- 默认子网掩码:255.0.0.0
- 子网掩码扩展到16位:255.255.0.0
- 意义:前16位(网络号 + 子网号)标识网络地址,后16位标识主机地址。
- 作用:将一个A类网络划分为多个子网,每个子网有2^16 - 2个主机地址(去掉全0和全1的地址)。
-
B类网络的子网掩码(255.255.255.0):
- 默认子网掩码:255.255.0.0
- 子网掩码扩展到24位:255.255.255.0
- 意义:前24位(网络号 + 子网号)标识网络地址,后8位标识主机地址。
- 作用:将一个B类网络划分为多个子网,每个子网有2^8 - 2个主机地址(去掉全0和全1的地址)。
总结
- A类网络子网掩码(255.255.0.0):将一个A类网络划分为更多的子网,每个子网有较多的主机。
- B类网络子网掩码(255.255.255.0):将一个B类网络划分为更多的子网,每个子网有较少的主机。
这种划分方式让网络管理员可以灵活地管理和优化网络资源,根据实际需求调整网络和子网的大小。
- 网络号(Network Address):
- 网络号是IP地址中用于标识特定网络的那部分。在IP地址的分级结构中,网络号用于区分不同的网络。
- 在A、B、C类IP地址中,网络号的长度是固定的,分别为8位、16位和24位。
- 主机号(Host Address):
- 主机号是IP地址中用于标识特定网络内特定主机的那部分。在每个网络内,主机号必须是唯一的。
- 例如,在C类IP地址(192.168.1.0/24)中,前24位是网络号,最后8位是主机号。
- 子网号(Subnet Address):
- 子网号是从主机号中借用一部分来创建子网的。通过子网划分,一个大的网络可以被划分为多个小的子网。
- 子网号用于标识特定的子网,而子网内的主机号用于标识子网内的特定设备。
- 子网掩码(Subnet Mask):
- 子网掩码是一个32位的数字,用于区分IP地址中的网络号、子网号和主机号。
- 子网掩码通常用点分十进制表示,其中网络和子网部分为255(二进制的11111111),主机部分为0或255。
- 例如,子网掩码255.255.255.0表示前24位是网络和子网号,最后8位是主机号。
4.若一个网络的子网掩码为255.255.255.248,则每个子网能够连接多少台主机
为了计算一个子网掩码为255.255.255.248的网络中每个子网能够连接多少台主机,需要了解子网掩码的细节以及如何通过子网掩码计算出主机数。
子网掩码255.255.255.248对应的二进制表示是:
11111111.11111111.11111111.11111000
这里有29位是1,这意味着网络部分占用29位,主机部分占用剩下的3位。
主机部分有3位,这意味着可以表示2^3 = 8个地址。但是,需要减去2个地址:
- 全0的地址表示网络地址
- 全1的地址表示广播地址
因此,每个子网的可用主机数计算如下:
2^3 - 2 = 8 - 2 = 6
一个子网掩码为255.255.255.248的子网可以连接6台主机。
5.写出IPv4地址202.196.75.18的IPv6兼容地址,用十六进制表示
IPv6兼容地址是一种特殊的IPv6地址格式,它允许IPv4地址嵌入在IPv6地址中。这种格式通常用于IPv4到IPv6的过渡和兼容性。IPv6兼容地址的格式是::/96,即前96位为0,后32位为嵌入的IPv4地址。
-
IPv4地址:202.196.75.18
-
将IPv4地址的每个部分转换为十六进制:
- 202 = CA
- 196 = C4
- 75 = 4B
- 18 = 12
-
组合十六进制表示:
- IPv4地址202.196.75.18转换为十六进制后为
CA.C4.4B.12
- IPv4地址202.196.75.18转换为十六进制后为
-
形成IPv6兼容地址:
- 将IPv4地址嵌入到IPv6的后32位,即
::CA:C4:4B:12
- 将IPv4地址嵌入到IPv6的后32位,即
IPv4地址202.196.75.18的IPv6兼容地址为::CA:C4:4B:12。
6.若遵守CERNET IPv6试验床地址划分及分配方案,试求辽宁大学站点的前48位地址,学校代码1014?如果信息学院所在的子网号为5,实验室的一个接口网卡的MAC地址为:00-11-5B-86-51-09,则其生成的IPv6地址如何表示?
根据CERNET IPv6试验床地址划分及分配方案,以下是对辽宁大学信息学院实验室的IPv6地址生成过程的解析:
-
计算前48位地址
-
6Bone地址空间: 0x3FFE
-
CERNET分配的地址块: 0x32
-
正式使用的地址: 0(0x00)
-
东北地区的编号: 8
-
辽宁省的编号: 1
-
辽宁大学的编号: 3F6
将这些信息组合成前48位地址:
3FFE:3208:13F6::/48
解释:
- 3FFE: 6Bone的地址空间前缀
- 32: CERNET分配的地址块
- 08: 东北地区
- 1: 辽宁省
- 3F6: 辽宁大学
- 信息学院的子网号
信息学院的子网号为5,转换为16进制表示为0005。将其添加到前48位地址中,形成64位前缀地址:
3FFE:3208:13F6:0005::/64
-
生成EUI-64格式的网络接口标识符
-
MAC地址: 00-11-5B-86-51-09
-
将MAC地址转换为EUI-64格式:
- 将MAC地址拆分为两部分:00-11-5B 和 86-51-09
- 插入
FF:FE到中间:00-11-5B-FF-FE-86-51-09
-
翻转第7位(从左边数的第一个字节的倒数第二位):
- 原字节:00(00000000)
- 翻转第7位:02(00000010)
- 新的MAC地址:02-11-5B-FF-FE-86-51-09
-
将结果分组并写入IPv6地址:
- 02:11:5B:FF:FE:86:51:09
-
组合完整的IPv6地址
将EUI-64格式的地址添加到64位前缀中,最终的IPv6地址是:
3FFE:3208:13F6:0005:0211:5BFF:FE86:5109
-
前48位地址:
3FFE:3208:13F6::/48 -
IPv6地址:
3FFE:3208:13F6:0005:0211:5BFF:FE86:5109
7.写出IPv4地址202.196.73.16的IPv6兼容地址和映射地址:
IPv4地址202.196.73.16可以转换为IPv6兼容地址和IPv6映射地址。以下是这两种地址的定义和计算过程。
- IPv6兼容地址
这些地址用于将IPv4地址嵌入到IPv6地址中,使得IPv6节点能够与IPv4节点直接通信。
IPv6兼容地址用于表示双栈节点,即同时支持IPv4和IPv6的节点。这种地址结构前96位为0,后32位为IPv4地址。
计算IPv6兼容地址
- IPv4地址:202.196.73.16
- 将IPv4地址转换为十六进制:
- 202 = CA
- 196 = C4
- 73 = 49
- 16 = 10
IPv6兼容地址格式为::/96 + IPv4地址部分:
::CA:C4:49:10
- IPv6映射地址
这些地址用于在IPv6网络中表示IPv4网络,它们允许IPv6节点将IPv4网络视为IPv6网络的一部分。
IPv6映射地址用于在纯IPv6环境中表示一个IPv4节点。这种地址结构前80位为0,接下来16位为1(FFFF),后32位为IPv4地址。
计算IPv6映射地址
- IPv4地址:202.196.73.16
- 将IPv4地址转换为十六进制:
- 202 = CA
- 196 = C4
- 73 = 49
- 16 = 10
IPv6映射地址格式为::FFFF:0:0/96 + IPv4地址部分:
::FFFF:CA:C4:49:10
-
IPv6兼容地址:
::CA:C4:49:10 -
IPv6映射地址:
::FFFF:CA:C4:49:10
这两种地址用于不同的场景,兼容地址用于IPv4/IPv6双栈节点,映射地址用于表示纯IPv6环境中的IPv4节点。
8.现截取了 3 个以太网帧 Frame#1-Frame#3,假设这些以太网帧通过了错误校验,用十六进制表示的帧内容如下:
Frame#1Server→Client
00 80 C8 5A E3 88 00 60 2F 87 01 03 08 00 45 08
00 2C D1 22 40 00 3F 06 8A 27 8C 80 63 05 8C 80
64 74 00 14 02 66 AA a1 20 8D 00 00 00 00 60 02
40 00 5E 3C 00 00 02 04 05 B4
Frame#2Client→Server
00 60 2F 87 01 03 00 80 C8 5A E3 88 08 00 45 00
00 2C 81 0E 40 00 80 06 99 43 8C 80 64 74 8C 80
63 05 02 66 00 14 12 38 BB 3E AA A1 20 8E 60 12
22 38 C0 7C 00 00 02 04 05 b4
Frame#3Server→Client
00 80 c8 5a e3 88 00 60 2f 87 01 03 08 00 45 08
00 28 d1 23 40 00 3f 06 8a 2a 8c 80 63 05 8c 80
64 74 00 14 02 66 aa a1 19 8e 12 38 bb 3f 50 10
44 70 b6 01 00 00
这 3 个数据包主要用于建立一个 TCP 连接,根据协议的封装关系,以及各层数据包格式的
结构,对这些数据包进行分析,回答如下问题:“
(1) Client 端和 Server 端的以太网网卡 48 位地址是何值?
(2)Frame#1 帧中封装的 IP 分组的总长度、首部长度、IP 数据长度分别是多少?”
(3)Client 端和 Server 端的 32 位 IP 地址(用点分十进制格式表示)各是多少?"
(4)Frame#1 帧中封装的 IP 分组的生存时间值是多少?协议字段值是多少?IP 分组中封装的是
哪一个协议的数据?"
(5)Frame#1 中封装的 IP 分组的首部是否含有“选项”字段?如何判断?”
(6)写出 TCP 连接的套接字对,用十六进制形式表示
(7)使用这个 TCP 连接的 Server 端和 Client 端,其各自“序列号”分别为何值?
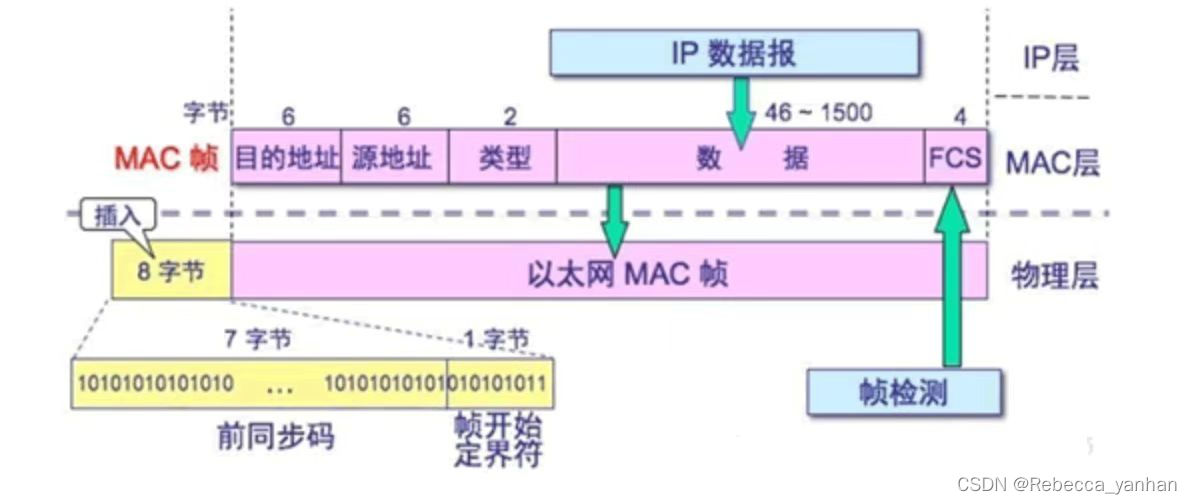
为了详细分析这三个以太网帧,我们需要按照以下步骤逐一解析每个帧的内容。我们将通过解码帧头和IP头来回答各个问题。
Frame#1 分析
为16进制 每两位代表一字节,前14位是MAC帧首部,后4位是FCS帧检测,中间是IP数据报
00 80 C8 5A E3 88 00 60 2F 87 01 03 08 00 45 08
00 2C D1 22 40 00 3F 06 8A 27 8C 80 63 05 8C 80
64 74 00 14 02 66 AA A1 20 8D 00 00 00 00 60 02
40 00 5E 3C 00 00 02 04 05 B4
(1) Client 端和 Server 端的以太网网卡 48 位地址是何值?
以太网帧头格式:
- 目标MAC地址:6字节
- 源MAC地址:6字节
- 以太网类型:2字节
Frame#1 的以太网帧头:
- 目标MAC地址(Server):00 80 C8 5A E3 88
- 源MAC地址(Client):00 60 2F 87 01 03
因此:
- Client 端 MAC 地址:00:60:2F:87:01:03
- Server 端 MAC 地址:00:80:C8:5A:E3:88
关于类型:
08 00: IPv4协议
86 DD: IPv6协议
(2) Frame#1 帧中封装的 IP 分组的总长度、首部长度、IP 数据长度分别是多少?

IP头格式(20字节):
- 版本和首部长度:1字节
- 服务类型:1字节
- 总长度:2字节
- 标识:2字节
- 标志和片偏移:2字节
- 生存时间:1字节
- 协议:1字节
- 首部校验和:2字节
- 源IP地址:4字节
- 目标IP地址:4字节
Frame#1 的 IP 头部分:
45 08 00 2C D1 22 40 00 3F 06 8A 27 8C 80 63 05 8C 80 64 74
- 版本和首部长度:45
- 版本:4(IPv4)
- 首部长度:5 * 4 = 20字节 (在IPv4协议中,首部长度的单位是4字节,所以乘4)
- 总长度:00 2C = 44字节 (直接转为10进制,得到对应长度)
- IP数据长度:总长度 - 首部长度 = 44 - 20 = 24字节
因此:
- 总长度:44字节
- 首部长度:20字节
- IP数据长度:24字节
(3) Client 端和 Server 端的 32 位 IP 地址(用点分十进制格式表示)各是多少?
Frame#1 的源IP地址和目标IP地址:
- 源IP地址:8C 80 63 05
- 目的IP地址:8C 80 64 74
转换为点分十进制格式:
- 目的IP地址:140.128.99.5
- 源IP地址:140.128.100.116
因此:
- Client端 IP 地址:140.128.99.5
- Server端 IP 地址:140.128.100.116
(4) Frame#1 帧中封装的 IP 分组的生存时间值是多少?协议字段值是多少?IP 分组中封装的是哪一个协议的数据?
Frame#1 的生存时间和协议字段:
- 生存时间:3F
- 协议:06
生存时间值(TTL):63(0x3F)
协议字段值:6(TCP)
01 - ICMP (Internet Control Message Protocol)
06 - TCP (Transmission Control Protocol)
11 - UDP (User Datagram Protocol)
因此,IP分组中封装的是TCP协议的数据。
(5) Frame#1 中封装的 IP 分组的首部是否含有“选项”字段?如何判断?
选项字段属于IP分组的首部,此IP分组的首部位20B,不含有选项字段。
首部长度字段的值为5,表示没有“选项”字段。IPv4的首部长度单位是4字节,5表示首部长度为20字节(5 * 4 = 20字节),这是标准的IPv4头部长度,所以没有包含选项字段。
(6) 写出 TCP 连接的套接字对,用十六进制形式表示
套接字对:就是地址:端口号
Frame#1 的TCP头:
00 14 02 66 AA A1 20 8D 00 00 00 00 60 02 40 00 5E 3C 00 00 02 04 05 B4
源端口:00 14 = 20
目标端口:02 66 = 614
因此,TCP连接的套接字对是:(地址:端口号) 地址前面已经求出
- 源:140.128.99.5:20
- 目标:140.128.100.116:614
用十六进制表示:
- 源:8C 80 63 05:0014
- 目标:8C 80 64 74:0266
(7) 使用这个 TCP 连接的 Server 端和 Client 端,其各自“序列号”分别为何值?
Frame#1 的TCP头中的序列号:
- 序列号:AA A1 20 8D
因此:
- Server端序列号:AA A1 20 8D
- Client端序列号:无(从帧中解析的内容来看,Frame#1是Server到Client的帧,没有Client端的序列号)
Frame#2 分析
00 60 2F 87 01 03 00 80 C8 5A E3 88 08 00 45 00
00 2C 81 0E 40 00 80 06 99 43 8C 80 64 74 8C 80
63 05 02 66 00 14 12 38 BB 3E AA A1 20 8E 60 12
22 38 C0 7C 00 00 02 04 05 b4
(1) Client 端和 Server 端的以太网网卡 48 位地址是何值?
以太网帧头:
- 目标MAC地址(Server):00 60 2F 87 01 03
- 源MAC地址(Client):00 80 C8 5A E3 88
(3) Client 端和 Server 端的 32 位 IP 地址(用点分十进制格式表示)各是多少?
Frame#2 的源IP地址和目标IP地址:
- 源IP地址:8C 80 64 74
- 目标IP地址:8C 80 63 05
转换为点分十进制格式:
- 源IP地址:140.128.100.116
- 目标IP地址:140.128.99.5
Frame#3 分析
00 80 c8 5a e3 88 00 60 2f 87 01 03 08 00 45 08
00 28 d1 23 40 00 3f 06 8a 2a 8c 80 63 05 8c 80
64 74 00 14 02 66 aa a1 19 8e 12 38 bb 3f 50 10
44 70 b6 01 00 00
(1) Client 端和 Server 端的以太网网卡 48 位地址是何值?
以太网帧头:
- 目标MAC地址(Server):00 80 C8 5A E3 88
- 源MAC地址(Client):00 60 2F 87 01 03
(3) Client 端和 Server 端的 32 位 IP 地址(用点分十进制格式表示)各是多少?
Frame#3 的源IP地址和目标IP地址:
- 源IP地址:8C 80 63 05
- 目标IP地址:8C 80 64 74
转换为点分十进制格式:
- 源IP地址:140.128.99.5
- 目标IP地址:140.128.100.116
总结
-
Client 端和 Server 端的以太网网卡 48 位地址:
- Client 端:00:60:2F:87:01:03
- Server 端:00:80:C8:5A:E3:88
-
Frame#1 帧中封装的 IP 分组的总长度、首部长度、IP 数据长度:
- 总长度:44字节
- 首部长度:20字节
- IP数据长度:24字节
-
Client 端和 Server 端的 32 位 IP 地址:
- Client 端:140.128.99.5
- Server 端:140.128.100.116
-
Frame#1 帧中封装的 IP 分组的生存时间值和协议字段值:
- 生存时间(TTL):64
- 协议字段值:6(TCP)
-
Frame#1 中封装的 IP 分组的首部是否含有“选项”字段:
- 不含有选项字段
-
TCP 连接的套接字对:
- 源:8C 80 63 05:0014
- 目标:8C 80 64 74:0266
-
Server 端和 Client 端的序列号:
- Server端序列号:AA A1 20 8D
9.主机A向主机B连续发送了两个TCP报文段,其序号分别为80和120。试问:
(1)第一个报文段携带了【填空1】个字节的数据
(2)主机B收到第一个报文段后发回的确认中的确认号应当是【填空2】。
(3)如果主机B收到第二个报文段后发回的确认中的确认号是180,试问A发送的第二个报文段中的数据有【填空3字节】。
(4)如果A发送的第一个报文段丢失了,但第二个报文段到达了B。B在第二个报文段到达后向A发送确认。试问这个确认号应为【填空4】。
好的,以下是对每个问题的详细解释及背后考察的知识点:
TCP(传输控制协议)是一种面向连接的、可靠的传输层协议。TCP通过序号和确认机制来保证数据包的有序、可靠传输。
- 序号(Sequence Number): 表示数据流中第一个字节的位置。
- 确认号(Acknowledgment Number): 表示接收方期望接收到的下一个字节的位置。
TCP的序号和确认号机制确保了数据包能够按照正确的顺序到达,并且发送方可以知道哪些数据已经被成功接收。
问题解析
(1)第一个报文段携带了【填空1】个字节的数据
问题: 主机A向主机B连续发送了两个TCP报文段,其序号分别为80和120。第一个报文段携带了多少个字节的数据?
解析:
- 第一个报文段的序号是80。
- 第二个报文段的序号是120。
- 序号是基于字节的,因此两个报文段之间的差值就是第一个报文段的数据长度。
计算方法:
[ \text{数据长度} = 120 - 80 = 40 ]
因此,填空1的答案是40字节。
(2)主机B收到第一个报文段后发回的确认中的确认号应当是【填空2】
问题: 主机B收到第一个报文段后发回的确认中的确认号应当是多少?
解析:
- 主机B收到第一个报文段,其序号是80,携带了40字节的数据。
- 确认号表示接收方期望接收的下一个字节的位置。
计算方法:
[ \text{确认号} = 80 + 40 = 120 ]
因此,填空2的答案是120。
(3)如果主机B收到第二个报文段后发回的确认中的确认号是180,试问A发送的第二个报文段中的数据有【填空3】字节
问题: 如果主机B收到第二个报文段后发回的确认号是180,A发送的第二个报文段中的数据有多少字节?
解析:
- 第二个报文段的序号是120。
- 主机B发回的确认号是180,这表示B已经收到了序号从120到179的数据,并期望收到序号180的数据。
计算方法:
[ \text{数据长度} = 180 - 120 = 60 ]
因此,填空3的答案是60字节。
(4)如果A发送的第一个报文段丢失了,但第二个报文段到达了B。B在第二个报文段到达后向A发送确认。试问这个确认号应为【填空4】
问题: 如果A发送的第一个报文段丢失了,但第二个报文段到达了B,B在第二个报文段到达后向A发送确认。这个确认号应为多少?
解析:
- 第一个报文段的序号是80,携带40字节数据,但丢失了。
- 第二个报文段的序号是120,携带60字节数据,但由于第一个报文段丢失,B无法接收和处理第二个报文段的数据。
- 按照TCP的机制,B会发送一个期望接收的下一个字节的位置,这个位置是第一个报文段的开始位置,因为B还没有收到任何数据。
因此,B期望接收的数据位置仍然是80。
所以,填空4的答案是80。
10.一个网络中,设定的P地址范围是172.88.32.1~172.88.63.254,试确定其合适的子网掩码【填空】
255.255.224.0
11.给定的IP地址为192.55.12.120,子网掩码为255.255.255.240,那么网络地址和主机号分别是「填空1]【填空2]:直接广播地址是[填空3]
要回答这个问题,我们需要理解以下几个网络基础概念:
- IP地址(Internet Protocol Address): 是分配给计算机设备的唯一标识,用于在网络中进行通信。
- 子网掩码(Subnet Mask): 是用于划分IP地址的网络部分和主机部分的一个32位掩码。
- 网络地址(Network Address): 是子网的第一个地址,用于标识子网。
- 主机号(Host Number): 是IP地址中用于标识网络中主机的部分。
- 直接广播地址(Direct Broadcast Address): 是网络中所有主机的目标地址,用于发送广播消息。
具体解答
给定:
- IP地址:192.55.12.120
- 子网掩码:255.255.255.240
(1)计算网络地址和主机号
子网掩码的二进制表示:
255.255.255.240 = 11111111.11111111.11111111.11110000
IP地址的二进制表示:
192.55.12.120 = 11000000.00110111.00001100.01111000
计算网络地址:
网络地址是通过将IP地址与子网掩码进行逐位“与”(AND)运算得到的。
11000000.00110111.00001100.01111000 (IP地址)
AND
11111111.11111111.11111111.11110000 (子网掩码)
-----------------------------------
11000000.00110111.00001100.01110000 (网络地址)
网络地址的二进制表示转换为十进制:
11000000.00110111.00001100.01110000 = 192.55.12.112
计算主机号:
主机号是IP地址中主机部分的二进制值,即:
11000000.00110111.00001100.01111000 (IP地址)
AND
00000000.00000000.00000000.00001111 (反掩码)
-----------------------------------
00000000.00000000.00000000.00001000 (主机号)
主机号的二进制表示转换为十进制:
00000000.00000000.00000000.00001000 = 8
所以:
- 网络地址是:192.55.12.112
- 主机号是:8
(2)计算直接广播地址
直接广播地址是将网络地址的主机部分全部置为1。
直接广播地址的二进制表示:
11000000.00110111.00001100.01110000 (网络地址)
OR
00000000.00000000.00000000.00001111 (反掩码)
-----------------------------------
11000000.00110111.00001100.01111111 (直接广播地址)
直接广播地址的二进制表示转换为十进制:
11000000.00110111.00001100.01111111 = 192.55.12.127
所以:
- 直接广播地址是:192.55.12.127
最终答案
- 网络地址是:192.55.12.112
- 主机号是:8
- 直接广播地址是:192.55.12.127
考察的知识点
- IP地址和子网掩码的基本概念和二进制表示: 了解如何将IP地址和子网掩码转换为二进制形式。
- 网络地址计算: 通过IP地址和子网掩码的逐位“与”运算来计算网络地址。
- 主机号计算: 通过IP地址和子网掩码的逐位“与”运算来分离主机号部分。
- 直接广播地址计算: 了解如何通过网络地址和反掩码的逐位“或”运算来计算直接广播地址。
12.假设一个有效载荷为4349B的原IPv6分组·需要从结点A传送到结点B。已经探测到从A到B的路由MTU,即PMTU为1500B。所以源结点A必须对这个IPv6分组进行分片处理。请间需要分几个分片?
要解决这个问题,我们需要了解IPv6分片的基本原理和相关的计算方法。
背景知识
IPv6分片: IPv6使用分片扩展头来实现分片。分片扩展头包含以下字段:
- Fragment Offset(分片偏移量): 指定当前分片相对于原始数据包的偏移量,以8字节为单位。
- M标志位(More Fragment flag): 表示是否有更多分片,如果是最后一个分片则M标志位为0,否则为1。
- Payload Length(有效载荷长度): 分片数据部分的长度,不包括IPv6头和分片扩展头的长度。
MTU(Maximum Transmission Unit): 路由器能传输的最大数据包大小,包括IPv6头和任何扩展头。
在此问题中,给定的MTU为1500字节,因此IPv6头和分片扩展头的开销将减少有效载荷的大小。IPv6头为40字节,分片扩展头为8字节,所以每个分片可以携带的最大数据为:
有效载荷=MTU−IPv6头−分片扩展头=1500−40−8=1452字节
由于分片偏移量以8字节为单位,因此每个分片的有效载荷长度必须是8的倍数。
分片计算
-
确定每个分片的有效载荷长度:
- 每个分片的有效载荷长度为1452字节。
- 但是1452不是8的倍数,所以我们需要取8的最大倍数。
- 因此,每个分片的有效载荷长度为1448字节(1452-4)。取小
-
计算所需的分片数:
- 原始有效载荷为4349字节。
- 每个分片的有效载荷为1448字节。
- 分片数计算:
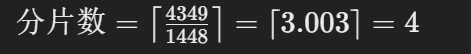
-
各分片的详细信息:
- 第1-3个分片的有效载荷长度为1448字节。
- 最后一个分片的有效载荷长度为4349 - 3 * 1448 = 5字节。
- 各分片的分片偏移量为前一个分片的偏移量加上有效载荷长度除以8的结果。
表格结果
| 分片编号 | 有效载荷长度(字节) | M标志位 | 分片偏移量 |
|---|---|---|---|
| 1 | 1448 | 1 | 0 |
| 2 | 1448 | 1 | 181 |
| 3 | 1448 | 1 | 362 |
| 4 | 5 | 0 | 543 |
详细计算过程
-
第1个分片:
- 有效载荷长度:1448字节
- M标志位:1(还有后续分片)
- 分片偏移量:0
-
第2个分片:
- 有效载荷长度:1448字节
- M标志位:1(还有后续分片)
- 分片偏移量:((0 + 1448) / 8 = 181)
-
第3个分片:
- 有效载荷长度:1448字节
- M标志位:1(还有后续分片)
- 分片偏移量:((181 \times 8 + 1448) / 8 = 362)
-
第4个分片:
- 有效载荷长度:5字节
- M标志位:0(没有后续分片)
- 分片偏移量:((362 \times 8 + 1448) / 8 = 543)
最终结果
| 分片编号 | 有效载荷长度(字节) | M标志位 | 分片偏移量 |
|---|---|---|---|
| 1 | 1448 | 1 | 0 |
| 2 | 1448 | 1 | 181 |
| 3 | 1448 | 1 | 362 |
| 4 | 5 | 0 | 543 |
考察的知识点
- IPv6头和扩展头的结构和功能: 特别是分片扩展头的格式。
- MTU的概念和作用: 了解MTU限制对数据传输的影响。
- 分片的计算方法: 如何根据MTU和有效载荷长度进行分片,并正确设置分片偏移量和M标志位。
- 数据包处理和传输: 数据包在网络中传输时如何处理分片和重组。
13.、若一个主机网卡接口的MAC地址为F8-32-E4-9A-7E-86,试写出该接口相对应的EUI-64格式的网络接口标识符【填空1】。假设该主机连接在前缀为3FFE:3002:1100::/48,并且在子网地址为10(十进制数)的网络上,请写出该主机接口的IPv6可聚合全局单播地址【填空2】,以及其所对应的被请求节点多播地址【填空3】。
- 计算EUI-64格式的网络接口标识符
EUI-64格式的网络接口标识符是基于MAC地址生成的,需要以下几个步骤:
-
将MAC地址分为两个24位的部分:
- 原始MAC地址:F8-32-E4-9A-7E-86
- 前24位:F8-32-E4
- 后24位:9A-7E-86
-
在中间插入16位的值FFFE:
- 前24位:F8-32-E4
- 插入16位:FFFE
- 后24位:9A-7E-86
组合起来就是:F8-32-E4-FF-FE-9A-7E-86
-
将MAC地址的第7位(全局/本地位)翻转:
- 原始MAC地址的第一个字节是F8,二进制表示为:1111 1000
- 第7位是1(从左数),翻转后为0
- 得到的第一个字节是FA(1111 1010)
所以,EUI-64格式的网络接口标识符是:FA-32-E4-FF-FE-9A-7E-86
填空1:FA32:E4FF:FE9A:7E86
- 生成IPv6可聚合全局单播地址
给定:
- 网络前缀:3FFE:3002:1100::/48
- 子网地址:10(十进制),即0A(十六进制)
IPv6地址格式:

将上述信息组合起来:
- 前缀:3FFE:3002:1100
- 子网标识符:000A
- 接口标识符:FA32:E4FF:FE9A:7E86
组合后:
[ 3FFE:3002:1100:000A:FA32:E4FF:FE9A:7E86 ]
填空2:3FFE:3002:1100:000A:FA32:E4FF:FE9A:7E86
- 计算被请求节点多播地址
被请求节点多播地址格式为:
[ FF02::1:FFXX:XXXX ]
其中,XX:XXXX是接口标识符的最后24位。
接口标识符:FA32:E4FF:FE9A:7E86
最后24位:9A:7E:86
被请求节点多播地址:
[ FF02::1:FF9A:7E86 ]
填空3:FF02::1:FF9A:7E86
最终答案
-
EUI-64格式的网络接口标识符:
FA32:E4FF:FE9A:7E86 -
IPv6可聚合全局单播地址:
3FFE:3002:1100:000A:FA32:E4FF:FE9A:7E86 -
被请求节点多播地址:
FF02::1:FF9A:7E86
考察的知识点
- MAC地址与EUI-64格式转换: 了解如何从MAC地址生成EUI-64格式的网络接口标识符。
- IPv6地址结构与生成: 了解IPv6地址的前缀、子网标识符和接口标识符的构成及其组合。
- 多播地址的构成与计算: 了解被请求节点多播地址的格式及其生成方法。
14.若IPv6分组由基本首部和TCP报文段组成,假设TCP报文段的总长度是256B。试表示这个分组,并给出所能确定字段的值。
IPv6分组由基本首部(IPv6基本头)和数据部分(例如TCP报文段)组成。以下是IPv6基本头的结构以及我们需要确定的字段值。
IPv6基本头结构
IPv6基本头由以下字段组成,总长度为40字节:
- 版本(Version): 4位,表示IP版本号,IPv6的值为6。
- 流量类别(Traffic Class): 8位,用于区分不同的流量类别。
- 流标签(Flow Label): 20位,用于标识数据流。
- 有效载荷长度(Payload Length): 16位,表示有效载荷(不包括IPv6头)的长度。
- 下一个头(Next Header): 8位,表示紧跟在IPv6头之后的头部类型,TCP协议的值为6。
- 跳限(Hop Limit): 8位,表示数据包可以经过的最大跳数。
- 源地址(Source Address): 128位,表示发送端的IPv6地址。
- 目的地址(Destination Address): 128位,表示接收端的IPv6地址。
假设和给定条件
- TCP报文段的总长度是256B。
- IPv6基本头的长度是40B。
需要确定的字段值
- 版本(Version): 6
- 流量类别(Traffic Class): 0(假设默认值)
- 流标签(Flow Label): 0(假设默认值)
- 有效载荷长度(Payload Length): 256(TCP报文段长度) + 0(假设没有其他扩展头) = 256
- 下一个头(Next Header): 6(TCP协议)
- 跳限(Hop Limit): 64(常见默认值,但具体值依赖于实现)
- 源地址(Source Address): 例如,2001:0db8:85a3:0000:0000:8a2e:0370:7334(示例地址)
- 目的地址(Destination Address): 例如,2001:0db8:85a3:0000:0000:8a2e:0370:1234(示例地址)
IPv6分组表示
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|Version| Traffic Class | Flow Label |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Payload Length | Next Header | Hop Limit |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| |
+ +
| |
+ Source Address +
| |
+ +
| |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| |
+ +
| |
+ Destination Address +
| |
+ +
| |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| |
+ +
| |
+ TCP Payload (256B) +
| |
+ +
| |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
确定字段的值
- 版本(Version): 0110(二进制) -> 6
- 流量类别(Traffic Class): 00000000(二进制) -> 0
- 流标签(Flow Label): 0000 0000 0000 0000 0000(二进制) -> 0
- 有效载荷长度(Payload Length): 0000 0001 0000 0000(二进制) -> 256
- 下一个头(Next Header): 0000 0110(二进制) -> 6
- 跳限(Hop Limit): 0100 0000(二进制) -> 64
- 源地址(Source Address): 2001:db8:85a3:0:0:8a2e:370:7334(示例)
- 目的地址(Destination Address): 2001:db8:85a3:0:0:8a2e:370:1234(示例)
完整的IPv6分组表示
|版本| 流量类别 | 流标签 |
|0110| 0000 0000 | 0000 0000 0000 0000 0000 |
| 有效载荷长度 | 下一个头 | 跳限 |
| 0000 0001 0000 0000 | 0000 0110 | 0100 0000 |
| 源地址(128位) |
| 2001:0db8:85a3:0000:0000:8a2e:0370:7334 |
| 目的地址(128位) |
| 2001:0db8:85a3:0000:0000:8a2e:0370:1234 |
| TCP有效载荷(256B) |
结论
IPv6基本头由以上字段组成,其中有些字段是固定值或默认值(如版本、流量类别、流标签等),有些字段(如源地址、目的地址、有效载荷长度、下一个头、跳限等)需要根据具体情况来填写。在本例中,有效载荷长度为256,表示TCP报文段的长度,下一个头为6表示TCP协议,跳限为64,源地址和目的地址为示例地址。
15.如果网卡的MAC地址为00-11-5B-86-51-09,则按上述式映射成的64位网络接口标识号为(用十六进制数表示)
0211:5BFF:FE86:5109
16.试写出对扩展首部追加1OB的padN填充选项,其格式何如?
在IPv6中,扩展首部的填充选项(PadN)用于确保特定字段在适当的边界对齐。PadN选项可以填充任意数量的字节。PadN选项的格式如下:
- 下一个头(Next Header): 指示下一个扩展首部或上层协议的类型。
- 头部扩展长度(Header Extension Length): 表示扩展首部的长度。
- PadN选项类型(Option Type): 表示这是一个PadN选项。
- PadN选项长度(Option Length): 表示填充字节的数量。
- 填充字节(Padding): 实际的填充字节,用于对齐。
示例:对扩展首部追加10字节的PadN填充选项
假设我们有一个IPv6扩展首部,需要在其中添加一个长度为10字节的PadN选项。PadN选项的格式如下:
- PadN选项类型(Option Type): 1字节,固定值为1。
- PadN选项长度(Option Length): 1字节,表示填充字节的数量。
- 填充字节(Padding): 实际的填充字节。
PadN选项格式
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Option Type | Option Length | Padding |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| 1 | 10 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
各字段解释
- Option Type(选项类型): 0x01
- Option Length(选项长度): 0x0A(表示填充10字节)
- Padding(填充): 10个0字节
填充选项示例
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| 1 | 10 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| 0 | 0 |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
总结
上述格式是PadN选项的具体格式,其中Option Type为1,Option Length为10,后面紧跟着10个填充的0字节。这个选项可以插入到IPv6扩展首部中,以确保特定字段在适当的边界对齐。
17
(1)请写出IPv6单播地址3FFE:3201:3001:1:020D:87FF:FE04:6F30所对应的被请求结点多播地址
(2)若某主机子网地址为562E:1234:2341:CDAB::1123接口标识符为64位,试确定该主机所连接的子网地址
(1)IPv6单播地址对应的被请求节点多播地址
被请求节点多播地址是用来在IPv6网络中通过多播方式查询某个单播地址的邻居的。这种多播地址的格式为:FF02::1:FFXX:XXXX,其中XX:XXXX为单播地址的最后24位。
给定的单播地址
单播地址:3FFE:3201:3001:1:020D:87FF:FE04:6F30
提取单播地址的最后24位
单播地址的最后24位是:04:6F30
构造被请求节点多播地址
被请求节点多播地址格式:FF02::1:FFXX:XXXX
将最后24位04:6F30填入多播地址:
被请求节点多播地址:FF02::1:FF04:6F30
(2)确定主机所连接的子网地址
给定的子网地址为:562E:1234:2341:CDAB::1123,接口标识符为64位。
子网地址结构
IPv6子网地址由前64位的网络前缀和后64位的接口标识符组成。要确定主机所连接的子网地址,需要将接口标识符部分置为全零。
提取网络前缀
前64位的网络前缀是:562E:1234:2341:CDAB
构造子网地址
将接口标识符部分置为全零:
子网地址:562E:1234:2341:CDAB::
总结
-
IPv6单播地址3FFE:3201:3001:1:020D:87FF:FE04:6F30对应的被请求节点多播地址是:
FF02::1:FF04:6F30 -
某主机子网地址为562E🔢2341:CDAB::1123,接口标识符为64位,主机所连接的子网地址是:
562E:1234:2341:CDAB::
18.假设一个有效载荷为2902字节的原IPv6分组,没有扩展首部。需要通过以太网MTU=(1500B)传送。必须对该IPv6分组进行分片,分多少分片?
-
计算初始分组的总大小:
- 有效载荷:2902字节
- IPv6固定首部:40字节
- 总大小:2902字节 + 40字节 = 2942字节
-
计算每个分片的最大有效载荷大小:
- 每个分片的最大大小:1500字节(以太网MTU)
- 分片首部:8字节
- 每个分片的最大有效载荷:1500字节 - 40字节(IPv6固定首部) - 8字节(分片首部) = 1452字节
-
调整为8字节的倍数:
- 每个分片的最大有效载荷:1448字节(最接近的8字节倍数) 最大有效载荷应该为8B的整数倍
-
计算需要的分片数:
- 第一个分片的有效载荷:1448字节
- 第二个分片的有效载荷:1448字节
- 剩余的有效载荷:2902字节 - 1448字节 - 1448字节 = 6字节
因此,实际上需要三个分片:
- 第一个分片:1448字节有效载荷 + 40字节(固定首部)+ 8字节(分片首部)= 1496字节
- 第二个分片:1448字节有效载荷 + 40字节(固定首部)+ 8字节(分片首部)= 1496字节
- 第三个分片:6字节有效载荷 + 40字节(固定首部)+ 8字节(分片首部)= 54字节
这样,每个分片的有效载荷都是8字节的倍数,并且总大小也符合以太网MTU的要求。
所以,需要3个分片来传输这个IPv6分组。
19.FEC0::1:0250:3EFF:FEE4:4B01的被请求结点的多播地址是
FF02::1:FFE4:4B01
20.设IP数据报使用固定首部,其各字段的具体数值如图所示,试用十六进制数填写首部检验和【填空1]
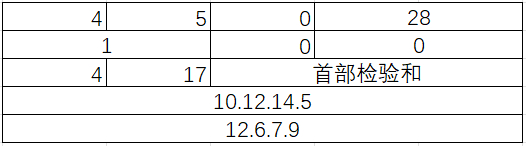
为了计算IP数据报的首部检验和,需要将各字段的值转换为16位的十六进制数,然后按位相加,最后取反得到检验和。下面是具体步骤:
-
把各字段的值转换为十六进制表示
-
版本(Version)和头部长度(IHL):
- 版本:4
- 头部长度:5
- 合并:45 (因为版本占4位,头部长度占4位)
-
区分服务(DS)和ECN:
- DS:0
- ECN:0
- 合并:00
-
总长度(Total Length):
- 总长度:28
- 转换为十六进制:001C
-
标识(Identification):
- 标识:1
- 转换为十六进制:0001
-
标志(Flags)和片偏移(Fragment Offset):
- 标志:0
- 片偏移:0
- 合并:0000
-
生存时间(TTL):
- TTL:4
- 转换为十六进制:04
-
协议(Protocol):
- 协议:17
- 转换为十六进制:11
-
源地址(Source Address):
- 10.12.14.5
- 转换为十六进制:0A0C0E05
-
目的地址(Destination Address):
- 12.6.7.9
- 转换为十六进制:0C060709
-
按顺序写出各字段的十六进制表示
45 00 00 1C 00 01 00 00 04 11 0000 0A0C0E05 0C060709
- 按16位(两个字节)分组
4500
001C
0001
0000
0411
0000
0A0C
0E05
0C06
0709
4. 计算各组的和
4500 + 001C + 0001 + 0000 + 0411 + 0000 + 0A0C + 0E05 + 0C06 + 0709
逐项相加:
4500 + 001C = 451C
451C + 0001 = 451D
451D + 0000 = 451D
451D + 0411 = 493E
493E + 0000 = 493E
493E + 0A0C = 533A
533A + 0E05 = 613F
613F + 0C06 = 6D45
6D45 + 0709 = 745E
- 检查和处理进位
先查看和是否有进位,即如果有高于16位的结果:
745E
没有需要处理的进位。
6. 取反得到检验和
~745E = 8BA1
所以,首部检验和是 8BA1。
因此,填空1应填入 8BA1。
21.某大学获得6Bone地址是3FFE:3205:3001::/48,结点所在的链路子网的前缀为3FFE:3205:3001:1::/64。如果网卡的MAC地址为00-0D-87-04-6F-30,那么当该结点启动时将自动从IPv6路由器获得网络地址,并生成自己的IPv6。该IPv6地址是什么?
生成基于MAC地址的IPv6地址涉及以下几个步骤和知识点:
步骤详解
-
拆分MAC地址
-
给定的MAC地址:
00-0D-87-04-6F-30 -
将其拆分为两部分:
前3个字节:00-0D-87 后3个字节:04-6F-30
-
-
插入固定值FFFE
-
根据EUI-64标准,在MAC地址的中间插入固定值FFFE:
00-0D-87-FF-FE-04-6F-30
-
-
修改第7位
-
修改MAC地址的第一个字节的第7位(从左数),即将第一个字节的第2个最低有效位(LSB)翻转。
-
00的二进制表示是:
00000000 -
将第7位翻转(从0变为1):
00000010 -
结果为:
02 -
修改后的EUI-64地址为:
02-0D-87-FF-FE-04-6F-30
-
-
构建IPv6地址
-
将链路子网前缀
3FFE:3205:3001:1::/64与 EUI-64地址拼接在一起:3FFE:3205:3001:1:020D:87FF:FE04:6F30
-
知识点考察
-
IPv6地址结构
- IPv6地址长度为128位,通常表示为八组16位的十六进制数,每组之间用冒号分隔。
- IPv6地址可以分为网络前缀和接口标识符(IID)。网络前缀标识网络,接口标识符标识网络中的具体接口。
-
EUI-64格式
- EUI-64格式用于根据MAC地址生成64位的接口标识符。
- 该格式将48位的MAC地址转换为64位的接口标识符,通过在MAC地址的中间插入
FFFE。 - 同时,需翻转MAC地址的第7位以符合IPv6规范。
-
IPv6无状态自动配置(SLAAC)
- 当IPv6设备连接到网络时,它可以通过无状态地址自动配置(SLAAC)机制自动生成其IPv6地址。
- 设备会从本地路由器获取网络前缀,然后使用EUI-64方法生成唯一的接口标识符。
- 最终的IPv6地址是网络前缀与EUI-64生成的接口标识符的组合。
-
MAC地址和EUI-64
- MAC地址通常为48位,用于在网络中唯一标识每个设备。
- EUI-64是基于MAC地址生成64位标识符的方法,适用于IPv6的接口标识符。
通过上述步骤和知识点,可以理解如何从MAC地址生成IPv6地址以及涉及的原理和标准。
22.假设结点A和结点B在同一条以太网链路上,都支持IPv6协议机制。
结点A的本地站点地址为FEC0::1:0250:3EFF:FEE4:4C00,链路层地址为00-50-3E-E4-4C-00:。
结点B的本地站点地址为FEC0:1:0250:3EFF:FEE4:4B01,链路层地址为00-50-3E-E4-4B-01。
请写出结点A解析结点B的MAC地址的工作过程
结点A要解析结点B的MAC地址,使用的是IPv6的邻居发现协议(Neighbor Discovery Protocol,NDP)。这个协议包括发送邻居请求(Neighbor Solicitation,NS)和接收邻居通告(Neighbor Advertisement,NA)消息。以下是详细的步骤:
步骤详解
-
准备邻居请求(NS)消息
- 源IPv6地址:FEC0::1:0250:3EFF:FEE4:4C00(结点A的本地站点地址)
- 目标IPv6地址:FEC0::1:0250:3EFF:FEE4:4B01(结点B的本地站点地址)
- 目标链路层地址:未填(此时不确定)
-
计算目标IPv6地址的请求节点多播地址
- 目标IPv6地址:FEC0::1:0250:3EFF:FEE4:4B01
- 提取最后24位:E4:4B01
- 生成请求节点多播地址:FF02::1:FFE4:4B01
-
发送邻居请求(NS)消息
- 目的地址:FF02::1:FFE4:4B01(请求节点多播地址)
- NS消息内容:包含目标IPv6地址和源IPv6地址
- 链路层目的地址:33:33:FF:E4:4B:01(对应IPv6多播地址的以太网地址)
-
结点B接收邻居请求(NS)消息
- 结点B监听并接收发送给FF02::1:FFE4:4B01多播地址的消息
- 解析并确认消息中的目标IPv6地址是自己(FEC0::1:0250:3EFF:FEE4:4B01)
-
准备邻居通告(NA)消息
- 源IPv6地址:FEC0::1:0250:3EFF:FEE4:4B01(结点B的本地站点地址)
- 目的IPv6地址:FEC0::1:0250:3EFF:FEE4:4C00(结点A的本地站点地址)
- 目标链路层地址:00-50-3E-E4-4B-01(结点B的链路层地址)
-
发送邻居通告(NA)消息
- 目的地址:FEC0::1:0250:3EFF:FEE4:4C00(结点A的本地站点地址)
- NA消息内容:包含目标IPv6地址和源IPv6地址以及目标链路层地址
- 链路层目的地址:00-50-3E-E4-4C-00(结点A的链路层地址)
-
结点A接收邻居通告(NA)消息
- 结点A接收到来自结点B的NA消息
- 解析NA消息,提取结点B的MAC地址:00-50-3E-E4-4B-01
- 将结点B的MAC地址与其IPv6地址FEC0::1:0250:3EFF:FEE4:4B01关联在一起,更新邻居缓存(Neighbor Cache)
知识点考察
-
IPv6邻居发现协议 (NDP)
- IPv6中的NDP协议替代了IPv4中的ARP协议,用于解析IPv6地址到链路层地址。
- 包括五种ICMPv6消息:Router Solicitation、Router Advertisement、Neighbor Solicitation、Neighbor Advertisement、Redirect。
-
请求节点多播地址 (Solicited-Node Multicast Address)
- 生成方法:前缀为FF02::1:FF00:0/104,加上目标地址的最后24位。
- 作用:减少多播范围,仅对目标节点发送请求。
-
邻居请求 (Neighbor Solicitation, NS) 和 邻居通告 (Neighbor Advertisement, NA) 消息
- NS消息:请求目标节点的链路层地址。
- NA消息:响应NS消息,提供自己的链路层地址。
-
链路层地址解析
- 利用NDP消息中的源地址和目标地址进行解析和绑定。
- 维护邻居缓存(Neighbor Cache),存储已解析的地址对。
通过以上步骤,结点A能够通过IPv6邻居发现协议解析到结点B的MAC地址,并在其邻居缓存中保存该信息以供后续通信使用。
23.试编写C语言函数,实现下列功能:(1)判断给定的IP(点分十进制形式)是否为多播地址(2)判断给定的以太网地址是否为以太网多播地址
C语言函数实现
下面是两个C语言函数,用于实现判断给定的IP地址是否为多播地址以及判断给定的以太网地址是否为以太网多播地址的功能。
-
判断给定的IP(点分十进制形式)是否为多播地址
- 多播IP地址范围是
224.0.0.0到239.255.255.255。 - 这可以通过检查IP地址的第一个八位组是否在
224到239之间来实现。
- 多播IP地址范围是
-
判断给定的以太网地址是否为以太网多播地址
- 以太网多播地址的最低有效位(最右边的一位)为1。
- 以太网地址通常表示为六个十六进制数,用冒号分隔。
代码实现
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <stdbool.h>// 函数声明
bool isMulticastIP(const char *ip);
bool isMulticastMAC(const char *mac);int main() {// 测试IP地址和MAC地址const char *testIP1 = "224.0.0.1";const char *testIP2 = "192.168.1.1";const char *testMAC1 = "01:00:5E:00:00:00";const char *testMAC2 = "00:1A:2B:3C:4D:5E";// 判断IP地址是否为多播地址if (isMulticastIP(testIP1)) {printf("IP %s 是多播地址\n", testIP1);} else {printf("IP %s 不是多播地址\n", testIP1);}if (isMulticastIP(testIP2)) {printf("IP %s 是多播地址\n", testIP2);} else {printf("IP %s 不是多播地址\n", testIP2);}// 判断MAC地址是否为以太网多播地址if (isMulticastMAC(testMAC1)) {printf("MAC %s 是以太网多播地址\n", testMAC1);} else {printf("MAC %s 不是以太网多播地址\n", testMAC1);}if (isMulticastMAC(testMAC2)) {printf("MAC %s 是以太网多播地址\n", testMAC2);} else {printf("MAC %s 不是以太网多播地址\n", testMAC2);}return 0;
}// 判断给定的IP(点分十进制形式)是否为多播地址
bool isMulticastIP(const char *ip) {unsigned int octet1;sscanf(ip, "%u", &octet1); // 只读取第一个八位组return (octet1 >= 224 && octet1 <= 239);
}// 判断给定的以太网地址是否为以太网多播地址
bool isMulticastMAC(const char *mac) {unsigned int macBytes[6];sscanf(mac, "%x:%x:%x:%x:%x:%x", &macBytes[0], &macBytes[1], &macBytes[2], &macBytes[3], &macBytes[4], &macBytes[5]);// 检查第一字节的最低有效位return (macBytes[0] & 1) != 0;
}
解释
-
isMulticastIP函数- 该函数接受一个字符串形式的IP地址,使用
sscanf解析出第一个八位组。 - 判断第一个八位组是否在
224到239之间,如果是,则该IP地址为多播地址。
- 该函数接受一个字符串形式的IP地址,使用
-
isMulticastMAC函数- 该函数接受一个字符串形式的MAC地址,使用
sscanf解析出六个十六进制字节。 - 检查第一字节的最低有效位(使用按位与操作
& 1),如果为1,则该MAC地址为多播地址。
- 该函数接受一个字符串形式的MAC地址,使用
测试
上述代码在main函数中提供了测试用例,可以通过运行程序验证函数的正确性。
24.一棵PIM-SM共享树,如下图所示。假定R3为共享树的根,请写出各路由器关于(*,235.80.1.1)共享树的多播路由表的信息:若指定路由器DR(如R2,R4,R5)检测出多播178.16.1.1发送多播分组的速率超过某一门限值,则建立一棵基于源的SPT树。假设从该源到各个多播组成员的SPT树已经建好,请写出关于多播源(178.16.1.1,235.80.1.1)的多播路由表的信息。
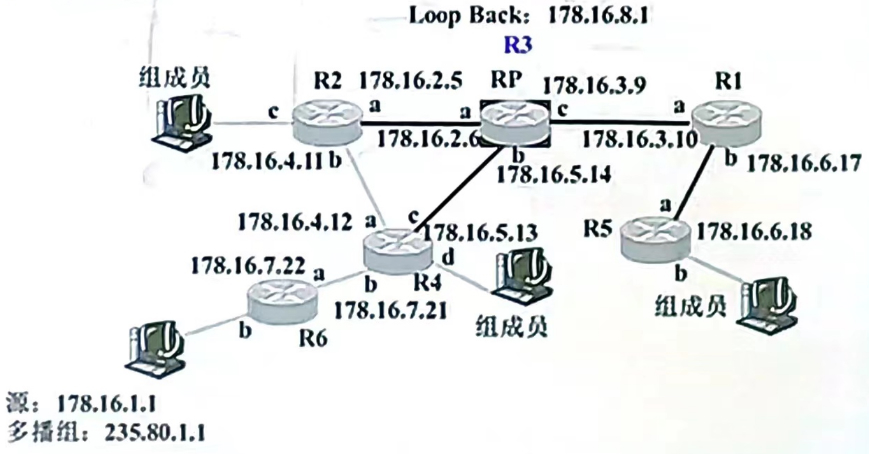
题目要求
- 写出各路由器关于(*,235.80.1.1)共享树的多播路由表的信息。
- 假定从指定路由器DR(如R2,R4,R5)检测出多播178.16.1.1发送多播分组的速率超过某一门限值,建立一棵基于源的SPT树。写出关于多播源(178.16.1.1,235.80.1.1)的多播路由表的信息。
详细解析
1. 共享树(RPT)信息
共享树以R3为根。假设所有的路由器都使用PIM-SM协议,并且多播组地址为235.80.1.1。
-
确定RP
- 根据题目,R3是RP(Rendezvous Point)。
- 共享树以RP为根,将流量从RP传播到所有组成员。
-
构建各路由器的多播路由表项(*,G)
- R3 (RP): 是共享树的根,没有入接口,只有出接口连接到R2、R4和R1。
- 其他路由器: 有一个入接口指向其连接到RP的路径,出接口指向其直接连接的组成员。
根据上面的原则,我们可以构建如下表格:
| 路由器 | 接口 | 入接口 | 出接口 |
|---|---|---|---|
| R3 (RP) | N/A | N/A | a: 178.16.2.6, b: 178.16.5.14, c: 178.16.3.10 |
| R2 | a | 178.16.2.6 | c: 178.16.4.11 |
| R4 | b | 178.16.5.14 | a: 178.16.7.21, d: 178.16.7.22, c: 178.16.5.13 |
| R1 | c | 178.16.3.10 | a: 178.16.6.17, b: 178.16.6.18 |
| R6 | a | 178.16.7.21 | N/A |
| R5 | b | 178.16.6.18 | N/A |
2. 基于源的SPT树信息
当DR检测到源(178.16.1.1)的发送速率超过门限值时,从源到组成员建立基于源的SPT树。
-
确定源
- 多播源为178.16.1.1。
-
构建基于源的SPT树
- 基于源的SPT树以源为根,将流量直接从源传播到所有组成员。
- 每个路由器的入接口为其连接到源的路径,出接口为其直接连接的组成员。
构建如下表格:
| 路由器 | 接口 | 入接口 | 出接口 |
|---|---|---|---|
| R3 (RP) | N/A | 178.16.1.1 | a: 178.16.2.6, b: 178.16.5.14, c: 178.16.3.10 |
| R2 | a | 178.16.2.6 | c: 178.16.4.11 |
| R4 | b | 178.16.5.14 | a: 178.16.7.21, d: 178.16.7.22, c: 178.16.5.13 |
| R1 | c | 178.16.3.10 | a: 178.16.6.17, b: 178.16.6.18 |
| R6 | a | 178.16.7.21 | N/A |
| R5 | b | 178.16.6.18 | N/A |
详细步骤解释
-
共享树构建(*,G)
- RP(R3)作为共享树的根,不需要入接口,只有出接口连接到其他路由器。
- R2、R4、R1等路由器的入接口指向连接到RP的路径,出接口连接到直接的组成员。
- R6、R5由于直接连接到组成员,只需要入接口,出接口为空。
-
基于源的SPT树构建(S,G)
- R3作为源直接连接的路由器,入接口指向源,出接口连接到其他路由器。
- 其他路由器的入接口指向连接到源的路径,出接口连接到直接的组成员。
最终结果
根据上面的分析和构建步骤,得到如下的多播路由表:
共享树(*,235.80.1.1)
| 路由器 | 接口 | 入接口 | 出接口 |
|---|---|---|---|
| R3 (RP) | N/A | N/A | a: 178.16.2.6, b: 178.16.5.14, c: 178.16.3.10 |
| R2 | a | 178.16.2.6 | c: 178.16.4.11 |
| R4 | b | 178.16.5.14 | a: 178.16.7.21, d: 178.16.7.22, c: 178.16.5.13 |
| R1 | c | 178.16.3.10 | a: 178.16.6.17, b: 178.16.6.18 |
| R6 | a | 178.16.7.21 | N/A |
| R5 | b | 178.16.6.18 | N/A |
基于源的SPT树(178.16.1.1,235.80.1.1)
| 路由器 | 接口 | 入接口 | 出接口 |
|---|---|---|---|
| R3 (RP) | N/A | 178.16.1.1 | a: 178.16.2.6, b: 178.16.5.14, c: 178.16.3.10 |
| R2 | a | 178.16.2.6 | c: 178.16.4.11 |
| R4 | b | 178.16.5.14 | a: 178.16.7.21, d: 178.16.7.22, c: 178.16.5.13 |
| R1 | c | 178.16.3.10 | a: 178.16.6.17, b: 178.16.6.18 |
| R6 | a | 178.16.7.21 | N/A |
| R5 | b | 178.16.6.18 | N/A |
24.例如:三台主机,在时间0收到查询报文,对每一个组的随机响应时间,如下图所示。若每个主机发送响应报文,则需要多少个报文?若使用延迟响应则只需要多少个报文?
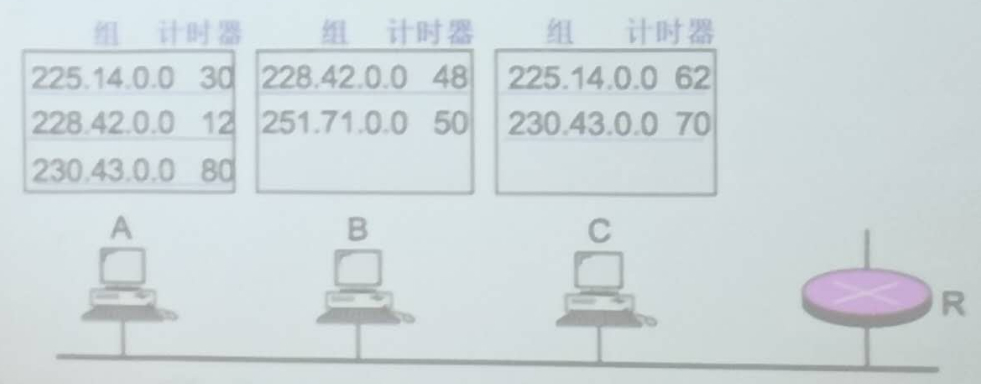
解析步骤
-
查询报文:在时间0,所有主机收到一个查询报文。每个主机都会为每个组选择一个随机响应时间。IGMP(Internet Group Management Protocol)是用于管理主机和路由器之间多播组成员关系的协议。
-
随机响应时间:每个主机为每个组选择一个随机响应时间。假设三个主机A、B、C分别为各自的多播组选择响应时间,响应时间为随机值,用于减少冲突。
IGMP的基本原理
- 查询报文(Query Message):由路由器发送给所有主机,询问哪些主机是某个多播组的成员。
- 成员报告(Membership Report):主机在收到查询报文后,选择一个随机响应时间,在这个时间内发送成员报告。如果在等待期间收到其他主机的报告,则取消自己的报告,以减少冗余报文。
主机的随机响应时间
-
主机A:
- 225.14.0.0 - 30秒
- 228.42.0.0 - 12秒
- 230.43.0.0 - 80秒
-
主机B:
- 228.42.0.0 - 48秒
- 251.71.0.0 - 50秒
-
主机C:
- 225.14.0.0 - 62秒
- 230.43.0.0 - 70秒
不使用延迟响应
若每个主机在自己的随机时间内发送响应报文,则总共需要发送:
- 主机A:3个报文(225.14.0.0,228.42.0.0,230.43.0.0)
- 主机B:2个报文(228.42.0.0,251.71.0.0)
- 主机C:2个报文(225.14.0.0,230.43.0.0)
总共需要:3 + 2 + 2 = 7 个报文。
使用延迟响应
通过选择最小的随机响应时间来减少报文数量。如下:
-
225.14.0.0
- 主机A:30秒
- 主机C:62秒
- 最小响应时间:30秒(由主机A发送)
-
228.42.0.0
- 主机A:12秒
- 主机B:48秒
- 最小响应时间:12秒(由主机A发送)
-
230.43.0.0
- 主机A:80秒
- 主机C:70秒
- 最小响应时间:70秒(由主机C发送)
-
251.71.0.0
- 主机B:50秒
- 只有主机B参与,50秒(由主机B发送)
总共需要:1(225.14.0.0) + 1(228.42.0.0) + 1(230.43.0.0) + 1(251.71.0.0) = 4 个报文。
知识点
- IGMP协议:用于在主机和相邻路由器之间建立和维护多播组成员关系。
- 查询-响应机制:路由器发送查询报文,主机根据随机响应时间发送成员报告,减少了不必要的报文冲突。
- 随机响应时间:通过随机响应时间,主机可以减少同时发送报文的概率,从而降低冲突和网络拥塞。
结论
通过延迟响应机制,可以显著减少IGMP成员报告的数量,从而优化网络性能:
- 不使用延迟响应:7个报文
- 使用延迟响应:4个报文
25.在 DVMRP 多播路由协议中,路由器对多播分组的处理过程中,需要进行 RPF 检查。根据 RPF 检查的结果,决定对分组进行丢弃还是转发。本题所使用的网络环境如图 9-31 所示。
路由器 RA 从接口 S0 收到了来自192.168.0.22 的多播分组,从接口 S1 收到了来自 172.16.32.66
的多播分组。路由器 RA 分别对这两个多播分组进行 RPF 检查,请对路由器的行为进行判断(丢弃还是转发)
(1)来自源 192.168.0.22 分组
(2)来自源 172.16.32.66 分组
路由器RA的单播路由表
| 目的网络 | 接口 |
|---|---|
| 192.168.0.0/16 | E1 |
| 172.16.32.0/24 | S1 |
| 202.194.210.0/24 | E0 |
解析步骤
-
了解DVMRP和RPF检查:
- DVMRP(Distance Vector Multicast Routing Protocol)是一种基于距离矢量的多播路由协议。
- RPF(Reverse Path Forwarding)检查用于确保多播分组是从源地址的最佳路径上到达的。
- RPF检查步骤:对于一个多播分组,路由器检查该分组是否从到达路由器的最佳路径接口到达。如果是,则转发;如果不是,则丢弃。
-
查看路由器RA的单播路由表:
目的网络 接口 192.168.0.0/16 E1 172.16.32.0/24 S1 202.194.210.0/24 E0 -
进行RPF检查:
(1) 来自源192.168.0.22的分组:
- 检查RA的单播路由表,192.168.0.22属于192.168.0.0/16网段,最佳路径接口是E1。
- 实际接收接口:S0。
- RPF检查失败,因为最佳路径接口(E1)与实际接收接口(S0)不同。
- 结论:丢弃分组。
(2) 来自源172.16.32.66的分组:
- 检查RA的单播路由表,172.16.32.66属于172.16.32.0/24网段,最佳路径接口是S1。
- 实际接收接口:S1。
- RPF检查通过,因为最佳路径接口(S1)与实际接收接口(S1)相同。
- 结论:转发分组。
最终结果表格
| 源地址 | 接口 | RPF检查结果 | 动作 |
|---|---|---|---|
| 192.168.0.22 | S0 | 失败 | 丢弃 |
| 172.16.32.66 | S1 | 通过 | 转发 |
考察的知识点
- DVMRP协议:了解如何进行多播路由以及路由器的多播路由表和单播路由表之间的关系。
- RPF检查:掌握如何使用RPF检查来确定多播分组是否从最佳路径接口到达,以决定是丢弃还是转发该分组。
- 网络路由表的理解和应用:理解路由表的内容并应用于实际的多播路由决策中。
26。以太网上的路由器收到多播IP分组,其GroupID为226.17.18.4。当主机检查其多播组表时找到了这个地址,请回答下列问题:
(1)试说明路由器怎样将这个IP分组封装成以太网块,并将它发送给各接收结点?试给出这个以太网顿的所有字段的值。
(2)该路由器转发接口的IP地址是185.22.5.6,而对应的物理地址为4A-22-45-12-E1-E2。这个路由器需要ARP的服务吗?
(3)若路由器在它的组表中找不到GroupID时会怎么样?
(1) 路由器如何将多播IP分组封装成以太网帧并发送给接收节点
步骤:
-
确定以太网多播地址:
- IPv4多播地址范围:224.0.0.0到239.255.255.255
- 对应的以太网多播地址范围:01:00:5E:00:00:00到01:00:5E:7F:FF:FF
-
计算以太网多播地址:
- 多播IP地址:226.17.18.4(转换为二进制:11100010.00010001.00010010.00000100)
- 去掉前25位(11100010.00010001.0001),取后23位(00 010010.00000100)
- 以太网多播地址前24位固定为:01:00:5E
- 以太网多播地址后24位由IP地址的后23位构成,高位补0
- 结果:01:00:5E:12:04
封装后的以太网帧字段:
- 目标MAC地址:01:00:5E:12:04
- 源MAC地址:4A:22:45:12:E1:E2(路由器的物理地址)
- 以太网类型:0x0800(表示封装的是IPv4分组)
- IP数据部分:原始的多播IP分组数据
(2) 路由器是否需要ARP的服务
ARP(地址解析协议):
- 用于将IP地址解析为MAC地址。
- 多播组的MAC地址是固定的,通过IP地址计算得出。
情景分析:
- 路由器的IP地址:185.22.5.6
- 路由器的物理地址:4A-22-45-12-E1-E2
路由器发送多播分组时,需要将多播IP地址转换为对应的以太网多播MAC地址。此转换不需要ARP,因为多播MAC地址通过算法直接从IP地址计算得到。因此:
- 结论:路由器在发送多播分组时,不需要ARP服务。
(3) 路由器在组表中找不到GroupID时的行为
组表(Multicast Group Table):
- 路由器维护一个多播组表,记录多播组及其成员信息。
情景:
- 收到的多播IP分组的GroupID为226.17.18.4
- 路由器检查其组表,未找到该GroupID
行为:
- 丢弃分组:路由器将丢弃该多播分组,因为没有接收该组分组的成员。
总结
表格形式展示结果:
| 问题 | 回答 |
|---|---|
| 封装成以太网帧的字段 | - 目标MAC地址:01:00:5E:12:04 - 源MAC地址:4A:22:45:12:E1:E2 - 以太网类型:0x0800 |
| 路由器是否需要ARP的服务 | 否,路由器可以通过算法直接计算出多播MAC地址 |
| 找不到GroupID时的行为 | 丢弃该多播分组 |