摘要
结构重参数化在各种计算机视觉任务中引起了越来越多的关注。它旨在提高深度模型的性能,同时不引入任何推理时间成本。虽然在推理过程中效率很高,但这些模型在复杂的训练阶段中依赖于复杂的训练块来达到高准确性,导致额外的大量训练成本。本文介绍了在线卷积重参数化(OREPA),这是一个两阶段的流程,旨在通过将复杂的训练阶段块压缩为单个卷积来减少巨大的训练开销。为了实现这个目标,我们引入了一个线性缩放层,以更好地优化在线块。在降低训练成本的同时,我们还探索了一些更有效的重参数化组件。与最先进的重参数化模型相比,OREPA能够减少约70%的训练时间内存开销,并将训练速度加快约2倍。同时,配备OREPA,这些模型在ImageNet上的表现超过以前的方法,提高了最多+0.6%。我们还在目标检测和语义分割上进行了实验,并展示了对下游任务的一致改进。代码可在https://github.com/JUGGHM/OREPA_CVPR2022获取。
文章链接
论文地址:论文地址
代码地址:代码地址
基本原理
什么是结构重新参数化?
结构重新参数化是一种在神经网络训练和推理阶段优化模型性能的方法。其基本思想是通过在训练阶段使用复杂的、多分支的网络结构来提高模型的表达能力和性能,而在推理阶段将这些复杂结构重新参数化为更简单的等效结构,以减少计算开销和存储需求。
具体来说,结构重新参数化通常涉及以下几个步骤:
-
训练阶段:
- 使用复杂的网络结构进行训练。例如,一个卷积层可能被替换为多个并行的卷积层和跳跃连接(shortcut connections),以增强模型的表达能力和学习能力。
- 这种复杂的结构能够捕捉更多的特征,帮助模型在训练过程中更好地拟合数据。
-
重新参数化:
- 在训练完成后,将复杂的多分支结构转换为一个等效的简单结构。例如,将多个并行的卷积层的权重和偏置合并到一个单独的卷积层中。
- 这种转换是通过数学方法和等效变换实现的,确保在推理阶段模型的输出不变。
-
推理阶段:
- 使用重新参数化后的简单结构进行推理。由于结构更简单,推理的计算效率更高,延迟更低,所需的存储资源也更少。
- 这种优化对于部署在资源受限的设备(如移动设备)上的模型尤其有用。
结构重新参数化的一种常见应用是RepVGG模型。RepVGG在训练阶段使用多分支结构,而在推理阶段将其重新参数化为简单的VGG样式的卷积神经网络,从而兼具高性能和高效率。这种方法的优势在于,它能够在不牺牲模型性能的前提下,大幅度减少推理阶段的计算和存储需求,从而实现更快的推理速度和更低的资源占用。
OREPA关键点
- 在线优化阶段: 在这个阶段,OREPA通过移除原型块中的非线性组件,并引入线性缩放层来优化卷积层的性能。通过去除非线性组件,模型变得更易于优化。线性缩放层的引入可以提高模型的灵活性和优化效果。
- 压缩训练时模块阶段: 在这个阶段,OREPA将复杂的训练时模块压缩成一个单一的卷积操作,从而降低训练成本。通过简化结构将多个卷积层和批量归一化层合并为一个简单的卷积层,减少内存和计算成本。这种压缩结构的设计有助于提高训练效率。
- 线性缩放层: 线性缩放层是OREPA的关键组成部分,通过适当缩放权重来提高模型的灵活性和优化效果。这种线性缩放层取代了原有的非线性规范化层,保持了优化的多样性和表示能力。线性缩放层的引入有助于优化模型的训练过程,并提高模型的性能。
- 训练时模块压缩: 通过将复杂的训练时模块压缩成一个单一的卷积操作,OREPA降低了训练时的复杂性和资源消耗。这种压缩结构的设计使得在推理阶段,无论训练时的结构多么复杂,所有模型都被简化为单一的卷积层,提高了推理速度和降低了资源消耗。训练时模块压缩的过程有助于简化模型结构,提高训练和推理效率。
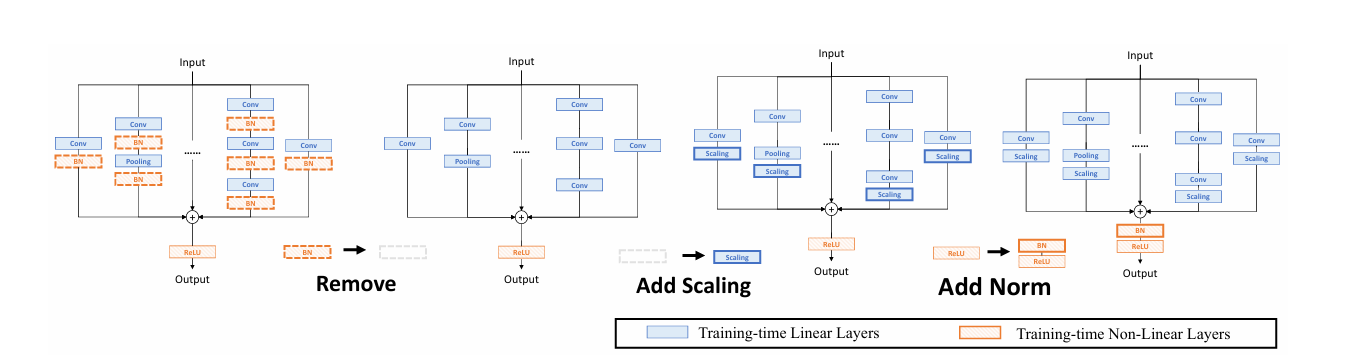
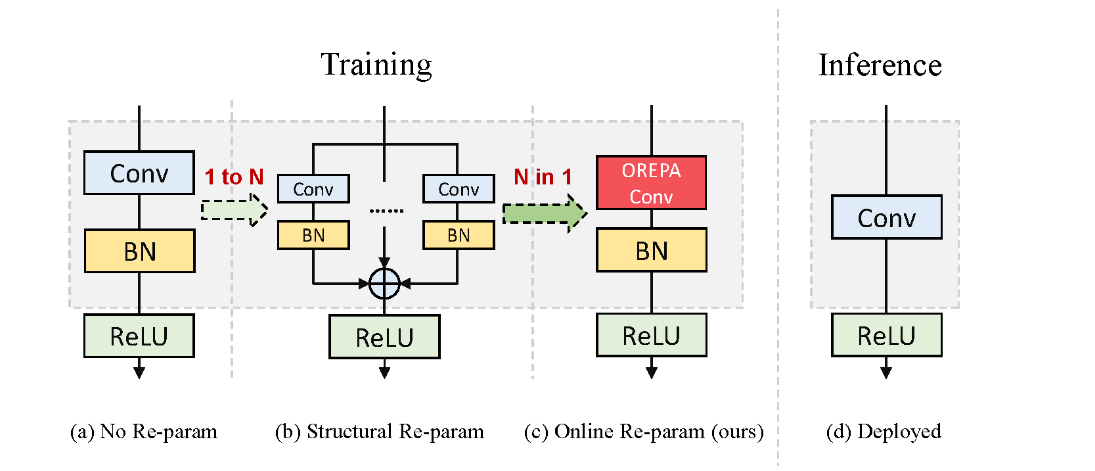
OREPA能够将复杂的训练时间块简化为单个卷积层,并保持较高的精度。OREPA的总体流程如图2所示,包括块线性化阶段和块压缩阶段。
-
块线性化
在训练过程中,中间的归一化层会阻碍单独层的合并,但直接删除它们会导致性能问题。为了解决这个困境,引入了一种通道级线性缩放操作,作为归一化的线性替代。缩放层包含一个可学习的向量,用于在通道维度上缩放特征图。线性缩放层与归一化层的作用相似,它们都鼓励多分支向不同方向优化,这是重参数化提高性能的关键。关于其具体影响的详细分析将在第3.4节中讨论。除了对性能的影响,线性缩放层还可以在训练过程中合并,使在线重参数化成为可能。
基于线性缩放层,对重参数化块进行修改,如图3所示。具体来说,块线性化阶段包括以下三个步骤:
- 去除所有非线性层:移除重参数化块中的所有非线性层,如归一化层。
- 添加尺度层:在每个分支的末尾添加一个尺度层,即线性缩放层,以保持优化多样性。
- 添加后归一化层:在合并所有分支之后,添加一个后归一化层,以稳定训练过程。
一旦完成线性化阶段,re-param块中只存在线性层,这意味着可以在训练阶段合并块中的所有组件。
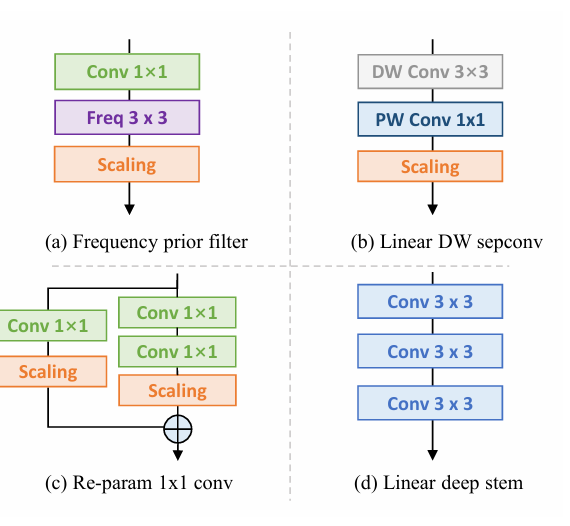
由于所提出的的OREPA大大节省了训练成本,它使能够探索更复杂的训练块。为此,通过对最先进的DBB模型进行线性化,并插入以下组件(图5),设计了一种新的重参数化模型OREPA-ResNet。
- 频率先验滤波器
在之前的工作中,块中使用了池化层。Qin 等人认为池化层是一种特殊的频率滤波器。为此,添加了一个 Conv1×1 频率滤波器分支。-
线性深度可分卷积
对深度可分卷积进行了稍微修改,去掉了中间的非线性激活层,使其在训练时可以合并。
-
1×1 卷积的重参数化
以前的工作主要集中在 3×3 卷积层的重参数化,而忽略了 1×1 层。建议对 1×1 层进行重参数化,因为它们在瓶颈结构中扮演着重要角色。具体来说,添加了一个额外的 Conv1×1 - Conv1×1 分支。
-
线性深 Stem
大型卷积核通常放置在最开始的层,如 7×7 stem 层,目的是获得更大的接收野。Guo 等人将 7×7 卷积层替换为堆叠的 3×3 层。
块压缩
得益于块的线性化,得到了一个线性块。块压缩步骤将中间特征映射上的操作转换为更高效的内核操作。这将重参数化的额外训练成本从 (O(H \times W)) 降低到 (O(K_H \times K_W)),其中 (H) 和 (W) 是特征图的空间尺寸,(K_H) 和 (K_W) 是卷积核的尺寸。
一般来说,无论线性重参数块多么复杂,以下两个属性始终有效:
- 块中的所有线性层,例如深度卷积、平均池化和线性缩放层,都可以用退化的卷积层表示,并具有相应的一组参数。
- 块可以由一系列并行分支表示,每个分支由一系列卷积层组成。
核心代码
class OREPA(nn.Module):def __init__(self,in_channels,out_channels,kernel_size,stride=1,padding=0,dilation=1,groups=1,internal_channels_1x1_3x3=None,deploy=False,nonlinear=None,single_init=False, weight_only=False,init_hyper_para=1.0, init_hyper_gamma=1.0):super(OREPA, self).__init__()self.deploy = deployif nonlinear is None:self.nonlinear = nn.Identity()else:self.nonlinear = nonlinearself.weight_only = weight_onlyself.kernel_size = kernel_sizeself.in_channels = in_channelsself.out_channels = out_channelsself.groups = groupsassert padding == kernel_size // 2self.stride = strideself.padding = paddingself.dilation = dilationif deploy:self.orepa_reparam = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride,padding=padding, dilation=dilation, groups=groups, bias=True)else:self.branch_counter = 0self.weight_orepa_origin = nn.Parameter(torch.Tensor(out_channels, int(in_channels / self.groups),kernel_size, kernel_size))init.kaiming_uniform_(self.weight_orepa_origin, a=math.sqrt(0.0))self.branch_counter += 1self.weight_orepa_avg_conv = nn.Parameter(torch.Tensor(out_channels, int(in_channels / self.groups), 1,1))self.weight_orepa_pfir_conv = nn.Parameter(torch.Tensor(out_channels, int(in_channels / self.groups), 1,1))init.kaiming_uniform_(self.weight_orepa_avg_conv, a=0.0)init.kaiming_uniform_(self.weight_orepa_pfir_conv, a=0.0)self.register_buffer('weight_orepa_avg_avg',torch.ones(kernel_size,kernel_size).mul(1.0 / kernel_size / kernel_size))self.branch_counter += 1self.branch_counter += 1self.weight_orepa_1x1 = nn.Parameter(torch.Tensor(out_channels, int(in_channels / self.groups), 1,1))init.kaiming_uniform_(self.weight_orepa_1x1, a=0.0)self.branch_counter += 1if internal_channels_1x1_3x3 is None:internal_channels_1x1_3x3 = in_channels if groups <= 4 else 2 * in_channelsif internal_channels_1x1_3x3 == in_channels:self.weight_orepa_1x1_kxk_idconv1 = nn.Parameter(torch.zeros(in_channels, int(in_channels / self.groups), 1, 1))id_value = np.zeros((in_channels, int(in_channels / self.groups), 1, 1))for i in range(in_channels):id_value[i, i % int(in_channels / self.groups), 0, 0] = 1id_tensor = torch.from_numpy(id_value).type_as(self.weight_orepa_1x1_kxk_idconv1)self.register_buffer('id_tensor', id_tensor)else:self.weight_orepa_1x1_kxk_idconv1 = nn.Parameter(torch.zeros(internal_channels_1x1_3x3,int(in_channels / self.groups), 1, 1))id_value = np.zeros((internal_channels_1x1_3x3, int(in_channels / self.groups), 1, 1))for i in range(internal_channels_1x1_3x3):id_value[i, i % int(in_channels / self.groups), 0, 0] = 1id_tensor = torch.from_numpy(id_value).type_as(self.weight_orepa_1x1_kxk_idconv1)self.register_buffer('id_tensor', id_tensor)#init.kaiming_uniform_(#self.weight_orepa_1x1_kxk_conv1, a=math.sqrt(0.0))self.weight_orepa_1x1_kxk_conv2 = nn.Parameter(torch.Tensor(out_channels,int(internal_channels_1x1_3x3 / self.groups),kernel_size, kernel_size))init.kaiming_uniform_(self.weight_orepa_1x1_kxk_conv2, a=math.sqrt(0.0))self.branch_counter += 1expand_ratio = 8self.weight_orepa_gconv_dw = nn.Parameter(torch.Tensor(in_channels * expand_ratio, 1, kernel_size,kernel_size))self.weight_orepa_gconv_pw = nn.Parameter(torch.Tensor(out_channels, int(in_channels * expand_ratio / self.groups), 1, 1))init.kaiming_uniform_(self.weight_orepa_gconv_dw, a=math.sqrt(0.0))init.kaiming_uniform_(self.weight_orepa_gconv_pw, a=math.sqrt(0.0))self.branch_counter += 1self.vector = nn.Parameter(torch.Tensor(self.branch_counter, self.out_channels))if weight_only is False:self.bn = nn.BatchNorm2d(self.out_channels)self.fre_init()init.constant_(self.vector[0, :], 0.25 * math.sqrt(init_hyper_gamma)) #origininit.constant_(self.vector[1, :], 0.25 * math.sqrt(init_hyper_gamma)) #avginit.constant_(self.vector[2, :], 0.0 * math.sqrt(init_hyper_gamma)) #priorinit.constant_(self.vector[3, :], 0.5 * math.sqrt(init_hyper_gamma)) #1x1_kxkinit.constant_(self.vector[4, :], 1.0 * math.sqrt(init_hyper_gamma)) #1x1init.constant_(self.vector[5, :], 0.5 * math.sqrt(init_hyper_gamma)) #dws_convself.weight_orepa_1x1.data = self.weight_orepa_1x1.mul(init_hyper_para)self.weight_orepa_origin.data = self.weight_orepa_origin.mul(init_hyper_para)self.weight_orepa_1x1_kxk_conv2.data = self.weight_orepa_1x1_kxk_conv2.mul(init_hyper_para)self.weight_orepa_avg_conv.data = self.weight_orepa_avg_conv.mul(init_hyper_para)self.weight_orepa_pfir_conv.data = self.weight_orepa_pfir_conv.mul(init_hyper_para)self.weight_orepa_gconv_dw.data = self.weight_orepa_gconv_dw.mul(math.sqrt(init_hyper_para))self.weight_orepa_gconv_pw.data = self.weight_orepa_gconv_pw.mul(math.sqrt(init_hyper_para))if single_init:# Initialize the vector.weight of origin as 1 and others as 0. This is not the default setting.self.single_init() task与yaml配置
详见:https://blog.csdn.net/shangyanaf/article/details/139465775





![[C++ Primer] 泛型算法](https://zzz-drawing-bed.oss-cn-nanjing.aliyuncs.com/img/image-20240629004308151.png)