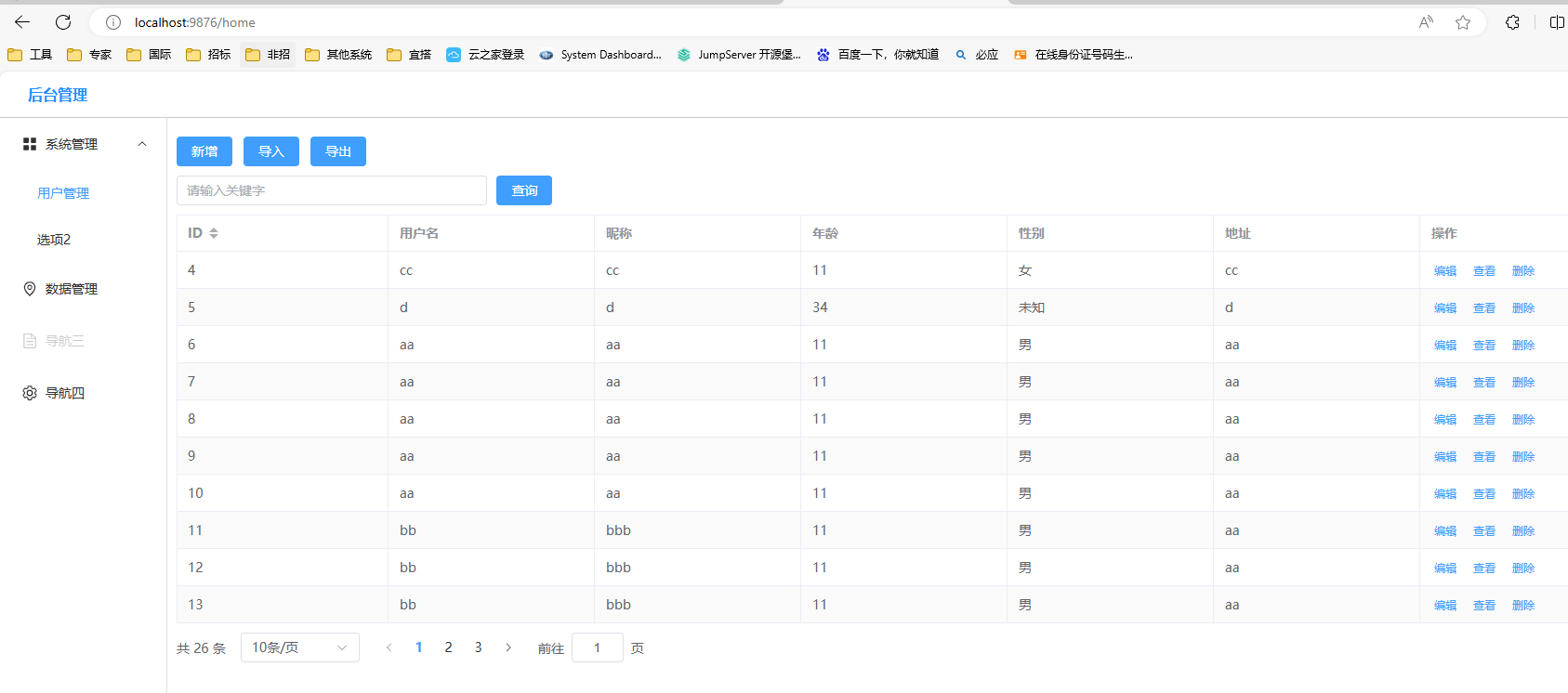
线段树题单记录
线段树的题都很板的,模板敲上去再改改就行
P3372 【模板】线段树 1
题目
Link
为什么模板是绿题,还有下面那道
思路
首先我们要明白它为什么叫线段树:
OI Wiki 上的这张图很好理解:

从这张图也可以看出来,线段树的每个节点管辖的一个又一个的线段(区间),所以我们通俗地叫它线段树。
废话
这里只讲最简单的线段树,关于什么 \(ZKW\) 线段树、动态开点 请自行了解。
普通线段树学完了好像那些奇奇怪怪的线段树优化更好理解
现在给出你一个数组的值,然后让你区间修改,区间求和 (当然树状数组也能做,就是麻烦了亿点),这就是线段树最基本的功能。当然,它也可以维护区间最值什么的,看下面的题目就知道了。
因为线段树的时空复杂度大约是树状数组和 \(st\) 表的 \(4\) 倍,所以能用树状数组或 \(st\) 表写的题目尽量不要用线段树去写。
代码
#include <bits/stdc++.h>
using namespace std;
const int N=1e5+5;
#define int long long
inline int read(){int x=0,f=1;char ch=getchar();while (ch<'0'||ch>'9'){if (ch=='-') f=-1;ch=getchar();}while (ch>='0'&&ch<='9'){x=x*10+ch-48;ch=getchar();}return x*f;
}
struct node{int l,r;int s;int lt;
}t[N*4];
int n,m;
int a[N];
void pushup(int p){t[p].s=t[p*2].s+t[p*2+1].s;}
void pushdown(int p){if(t[p].lt==0)return;t[p*2].s+=t[p].lt*(t[p*2].r-t[p*2].l+1);t[p*2+1].s+=t[p].lt*(t[p*2+1].r-t[p*2+1].l+1);t[p*2].lt+=t[p].lt;t[p*2+1].lt+=t[p].lt;t[p].lt=0;
}
void build(int p,int l,int r){t[p].l=l;t[p].r=r;if(l==r){t[p].s=a[l];return;}int mid=(l+r)>>1;build(p*2,l,mid);build(p*2+1,mid+1,r);pushup(p);
}
void update(int p,int l,int r,int c){if(t[p].l>=l&&t[p].r<=r){t[p].lt+=c;t[p].s+=c*(t[p].r-t[p].l+1);return;}pushdown(p);int mid=(t[p].l+t[p].r)>>1;if(l<=mid)update(p*2,l,r,c);if(r>mid)update(p*2+1,l,r,c);pushup(p);
}
int query(int p,int l,int r){if(t[p].l>=l&&t[p].r<=r)return t[p].s;int reu=0;int mid=(t[p].l+t[p].r)>>1;pushdown(p);if(l<=mid)reu+=query(p*2,l,r);if(r>mid)reu+=query(p*2+1,l,r);return reu;
}
signed main(){cin>>n>>m;for(int i=1;i<=n;i++)cin>>a[i];build(1,1,n);int ty;int x,y,k;for(int i=1;i<=m;i++){cin>>ty;if(ty==1){cin>>x>>y>>k;update(1,x,y,k);}else{cin>>x>>y;cout<<query(1,x,y)<<endl;}}return 0;
}
建树复杂度:\(O (NlogN)\)
查询复杂度:\(O (logN)\)
修改复杂度:\(O (logN)\)
代码解释
变量声明
结构体 node:树的结点,包含左右端点和保存的信息什么的。
数组 t:树的数组
数组 a:原始数组
int 整型 n:原始数组长度
int 整型 m:操作个数
build
定义:void build (int p,int l,int r)
传入三个参数:节点编号 \(p\),该节点的左端点 \(l\) 和右端点 \(r\)。
然后对其进行赋值 t [p].l=l;t [p].r=r;(有些题目可能要赋的值比较多)。
然后递归建树:
if(l==r){t[p].s=a[l];return;}int mid=(l+r)>>1;build(p*2,l,mid);build(p*2+1,mid+1,r);pushup(p);
如果说当前节点的左右端点编号相等,就证明它已经建到叶子节点了,就可以赋值 return 了。
否则,就将区间不严格对半拆开,然后递归建树,然后 pushup。
然后你就看到了突然出现的 pushup。
pushup
声明:void pushup (int p)
其中 \(p\) 是节点编号。该节点的和等于它左右儿子的和的和。有些题目可能要维护的东西比较多,比如下面的 P1471 方差 那道题。
它的作用很简单,就是在儿子节点修改后将修改值给向上推给父亲:{t [p].s=t [p*2].s+t[p*2+1].s;}
现在树建完了,然后该维护和查询了。
update
声明:void update (int p,int l,int r,int c)
传入 \(4\) 个参数:
当前节点 \(p\)、当前修改的左端点 \(l\)、当前修改的右端点 \(r\)、当前修改值 \(c\)。
如果说当前节点的左右端点已经被完全包含了,那么就在当前节点修改并 return:
if(t[p].l>=l&&t[p].r<=r){t[p].lt+=c;t[p].s+=c*(t[p].r-t[p].l+1);return;}
否则,继续往下递归修改:
pushdown(p);int mid=(t[p].l+t[p].r)>>1;if(l<=mid)update(p*2,l,r,c);if(r>mid)update(p*2+1,l,r,c);pushup(p);
于是我们就看到了 pushdown 函数和 莫名其妙的 \(lt\) 变量。
先来解释 \(lt\)。
\(lt\)
它是 \(LazyTag\) 的缩写,中文即懒标记。
它的作用很简单。
当我们修改到某一个节点,而这个节点被修改区间包含时,我们就可以直接修改该区间的值。
但是由于它的儿子没有被修改,所以我们需要记录已经修改的值再 return。
如果下一次经过这个节点,就先将 \(lt\) 给 \(pushdown\) 下去,以保证儿子的和是最新的。否则,可能你的某次修改就会被吞掉。
那么 pushdown 的作用就很明显了。
pushdown
声明:void pushdown (int p)
传入要进行 pushdown 操作的节点编号 \(p\),然后进行修改,就像这样:
{if(t[p].lt==0)return;t[p*2].s+=t[p].lt*(t[p*2].r-t[p*2].l+1);t[p*2+1].s+=t[p].lt*(t[p*2+1].r-t[p*2+1].l+1);t[p*2].lt+=t[p].lt;t[p*2+1].lt+=t[p].lt;t[p].lt=0;
}
那个 if (t [p].lt==0) return; 是用来进行判断的:如果当前节点没有需要进行 pushdown 操作的懒标记就 return。没有它也行,它主要是用来加快程序运行的。
这里也是题目设难点的一个重灾区,某些题目要考虑的情况很多,一不注意就 \(WA\) 了
现在我们来看查询 query。
query
声明:int query (int p,int l,int r)
传入三个参数:
当前节点编号 \(p\)、当前修改的左端点 \(l\)、当前修改的右端点 \(r\)。
和 update 差不多,query 的判断逻辑也是如果说当前节点的左右端点已经被查询区间完全包含了,那么就 return 当前节点的查询值:
if(t[p].l>=l&&t[p].r<=r)return t[p].s;
否则就接着往下查询:
int reu=0;int mid=(t[p].l+t[p].r)>>1;pushdown(p);if(l<=mid)reu+=query(p*2,l,r);if(r>mid)reu+=query(p*2+1,l,r);return reu;
至此,整个线段树的核心代码就讲完了。
VSCode:277 行真 6