拼接与合并
1. 纵向或横向拼接:pd.concat()
# 纵向拼接,在函数中放入列表,里面是想拼接的两个df
# 如果列名一致,直接对齐;如果列名不一致,则各列都会保留,空值为NaN
pd.concat([df1, df2], ignore_index = True) # >>> 此时索引是各自保留的,所以要忽略索引,重新排序# 横向拼接,需要指定轴
pd.concat([df3, df4], axis = 1)2. 数据合并:pd.merge(表1,表2, on = 用来合并的列/[多个列],how = inner/outer/left/right)
可以存在列名不同的情况
# 应用场景:用于根据某列来合并两张不同的表(比如根据客户ID,来合并订单和顾客信息表)
pd.merge(customer_info, order_table on = 'customer_ID')# 想要同时根据客户ID和订单日期来合并
pd.merge(customer_info, order_table on = ['customer_ID', 'date'])# 如果想要合并的两张表中,列名不相同,比如一张表中管客户身份叫【客户ID】,另一张表中叫【客户编号】
pd.merge(order_df3,customer_df3,left_on=['客户编号','订单日期'],right_on=['客户ID','交易日期']# 如果两张表的列名相同,但是只想指定其中一列进行合并,也是可以的,剩下的列依然都保留,并且会自动添加后缀_x , _y进行区分。如果想自己指定后缀,则用参数suffixes
pd.merge(df7,df8,on = ["日期","店铺"],suffixes=["_df7","_df8"])# how参数详解(和mysql的连表相似)
inner:只合并左右表都有匹配的值,最终结果也只有这几行
outer:保留所有值,如果匹配不上,用NaN填充
left:保留左边表的所有值,如果匹配不上,用NaN填充
right:保留右边表的所有值,如果匹配不上,用NaN填充
3. 根据索引进行合并:表1.join(表2,how = ,lsuffix = ,rsuffix = )
这个函数直接根据索引来合并,但是如果两张表中存在相同列名的列,那么就需要用lsuffix和rsuffix来指定左右两边表重名列的后缀分组聚合
1. 分组运算:df.groupby(想分组的列名)[分组后需要计算的列名].mean()等聚合函数
点击查看代码
应用场景:有些表格计算需要先分组后再运算,可以先用groupby根据某列进行分组,然后提取出想要计算的其他列,通过sum、mean、min、max等聚合函数运算即可运行了df.groupby(想分组的列名),得到的实际是一个dataframe groupby实例,但这个实例无法直接展示,它可以理解为就变成了,比如按部门分组,来计算成员平均年龄,原本数据是一行一个成员信息,那么分组后,一行表示同一个部门的多个成员信息如果不想这样,可以直接reset_index,这样层次化的分组索引就又变成一行一个了
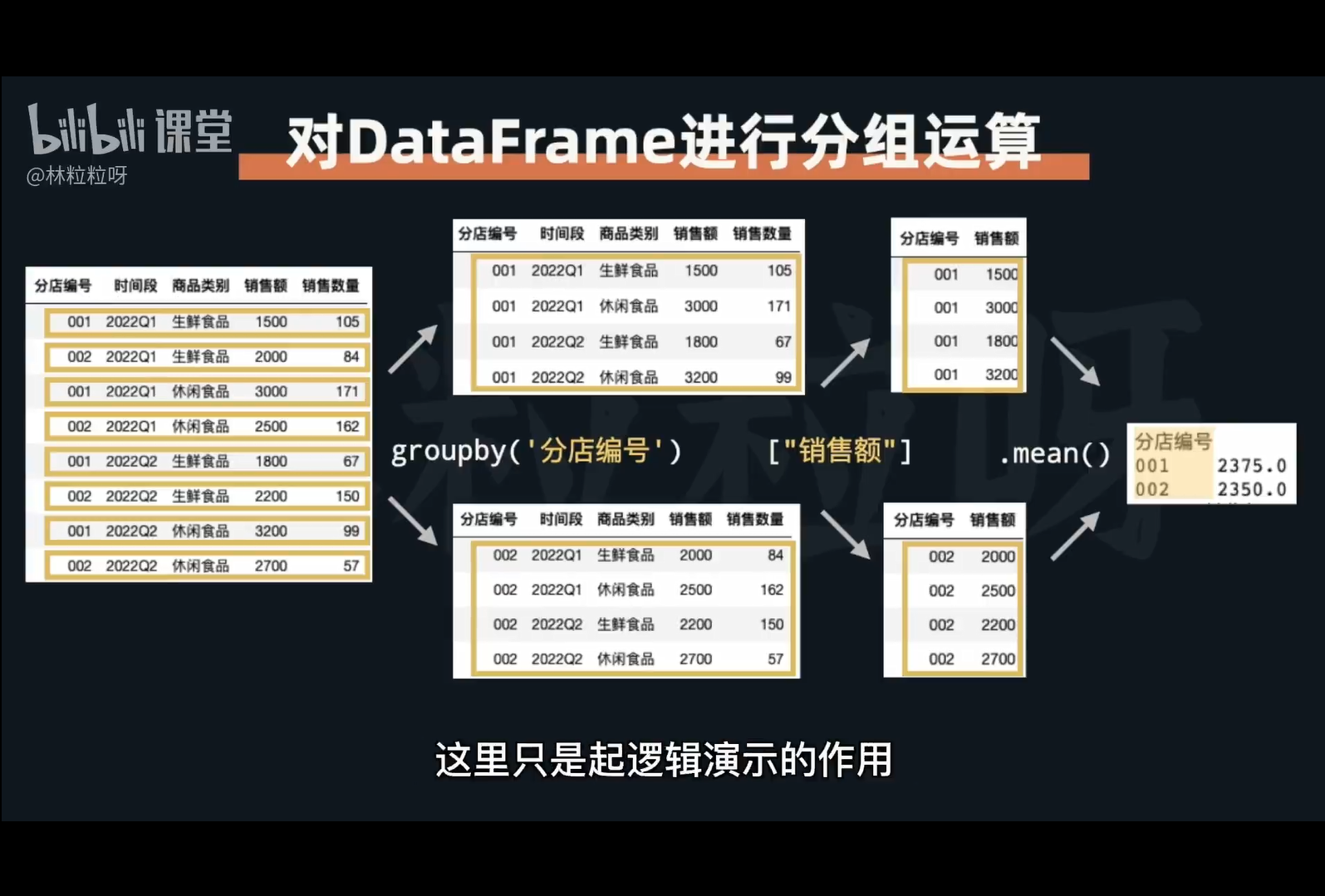
上图这里中间两步骤是演示,实际并不会得到
2. 数据聚合——透视表:pd.pivot_table(df, index = )
点击查看代码
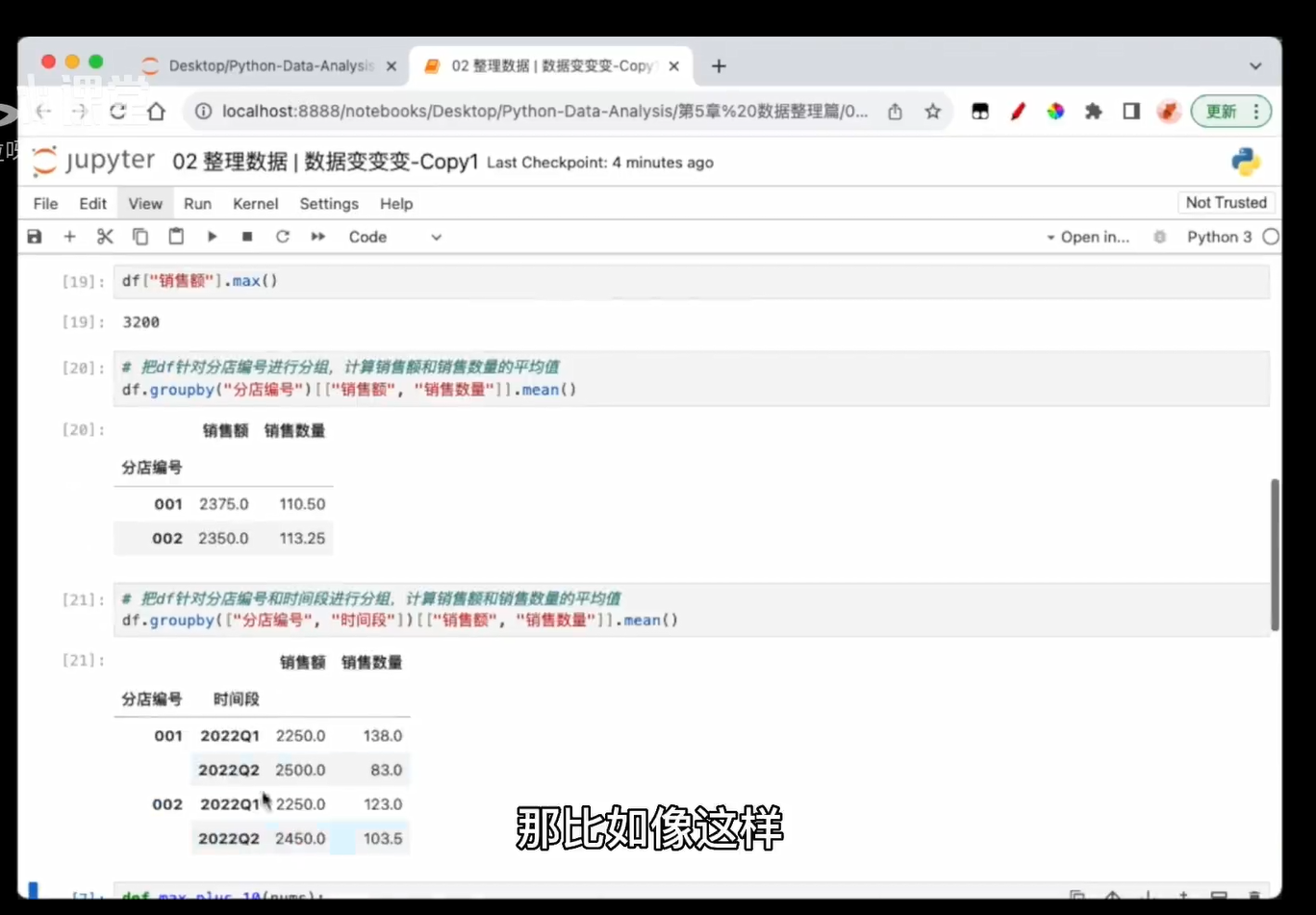
# 所谓聚合函数,就是传入一堆数据得到一个数据,就是把数据聚起来计算了# 把df的分店编号和时间段作为索引(新的行标签),商品类别作为列(按照商品类别列的值,重新分列),计算销售额的总和
pivot_table = pd.pivot_table(df, index=["分店编号", "时间段"], columns="商品类别", values="销售额", aggfunc=np.sum)# 这个代码的意思是:
pd.pivot_table(): 调用Pandas的pivot_table函数来创建一个透视表。
df: 这是您想要从中创建透视表的DataFrame。
index=["分店编号", "时间段"]: 这指定了透视表的行标签。每个唯一的“分店编号”和“时间段”组合将成为一个新的行。
columns="商品类别": 这指定了透视表的列标签。每个唯一的“商品类别”将成为一个新的列。
values="销售额": 这指定了您想要聚合的数值列。在此例中,您想要计算每个分店、每个时间段、每个商品类别的“销售额”总和。
aggfunc=np.sum: 这指定了用于聚合数据的函数。在这里,您使用了NumPy的sum函数来计算每个组合(分店编号、时间段、商品类别)的“销售额”总和。这里之所以pandas可以使用np的函数,因为pandas其实底层就是numpy

3. 区间分组:pd.cut(对象列,bins = 【分组标准,labels = [分组后叫什么])
点击查看代码
# bins 是分组的标准,列表左闭右开
比如是年龄分组的话,可以【0, 30, 40, 50, 60 ,120】, 这里的意思就是分组按0至三十岁,三十至四十岁,四十至五十岁,五十至六十岁,六十至一百二十岁分组。# labels 是分组后的抬头
比如按【0, 30, 40, 50, 60 ,120】分的组,可以对应叫【青年组、壮年组、中老年组、老年组、退休组】,进行命名这样的分类后,再搭配groupby进行聚合运算会更方便




![= ERROR [sshd internal] load metadata for docker.io/vulhub/openssh:7.7 问题解决,亲测有效!](https://img2024.cnblogs.com/blog/3304752/202406/3304752-20240629145045962-658686854.png)