基于VAE介绍的理论,简单实现VAE生成人脸,代码如下:
utils.py
import os from torch.utils.data import Dataset from torchvision.transforms import transforms import glob import cv2 import numpy as np import torchclass MyDataset(Dataset):def __init__(self, img_path, device):super(MyDataset, self).__init__()self.device = deviceself.fnames = glob.glob(os.path.join(img_path+"*.jpg"))self.transforms = transforms.Compose([transforms.ToTensor(),])def __getitem__(self, idx):fname = self.fnames[idx]img = cv2.imread(fname, cv2.IMREAD_COLOR)img = self.transforms(img)img = img.to(self.device)return imgdef __len__(self):return len(self.fnames)
VAE.py
import torch import torch.nn as nnclass VAE(nn.Module):def __init__(self, image_size: int, in_channels: int, latent_dim: int, hid_dims: int = None):super(VAE, self).__init__()self.latent_dim = latent_dimif not hid_dims:hid_dims = [32, 64, 128, 256]feature_size = image_size // (2**4)modules = []for h_d in hid_dims:modules.append(nn.Sequential(nn.Conv2d(in_channels, h_d, 3, 2, 1),nn.BatchNorm2d(h_d),nn.LeakyReLU()))in_channels = h_dself.encoder = nn.Sequential(*modules)self.fc_mu = nn.Linear(hid_dims[-1]*feature_size**2, latent_dim)self.fc_var = nn.Linear(hid_dims[-1]*feature_size**2, latent_dim)# decoderself.decoder_input = nn.Linear(latent_dim, hid_dims[-1]*feature_size**2)hid_dims.reverse()modules = []for i in range(len(hid_dims)-1):modules.append(nn.Sequential(nn.ConvTranspose2d(hid_dims[i], hid_dims[i+1], 3, 2, 1, 1),nn.BatchNorm2d(hid_dims[i+1]),nn.LeakyReLU()))self.decoder = nn.Sequential(*modules)self.decoder_out = nn.Sequential(nn.ConvTranspose2d(hid_dims[-1], hid_dims[-1], 3, 2, 1, 1),nn.BatchNorm2d(hid_dims[-1]),nn.LeakyReLU(),nn.Conv2d(hid_dims[-1], 3, 3, 1, 1, 1),nn.Sigmoid())def encode(self, x):x = self.encoder(x)x = torch.flatten(x, start_dim=1)mu = self.fc_mu(x)var = self.fc_var(x)return mu, vardef decode(self, x):x = self.decoder_input(x)x = x.view(-1, 256, 6, 6)x = self.decoder(x)x = self.decoder_out(x)return xdef re_parameterize(self, mu, log_var):std = torch.exp_(0.5*log_var)eps = torch.randn_like(std)return mu + std*epsdef forward(self, x):mu, log_var = self.encode(x)z = self.re_parameterize(mu, log_var)out = self.decode(z)return out, mu, log_vardef sample(self, n_samples, device):z = torch.randn((n_samples, self.latent_dim)).to(device)samples = self.decode(z)return samplesif __name__ == '__main__':DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")fake_input = torch.ones((1, 3, 96, 96))model = VAE(96, 3, 1024)out, *_ = model(fake_input)print(out.shape)print(model.sample(10, DEVICE).shape)
Loss.py
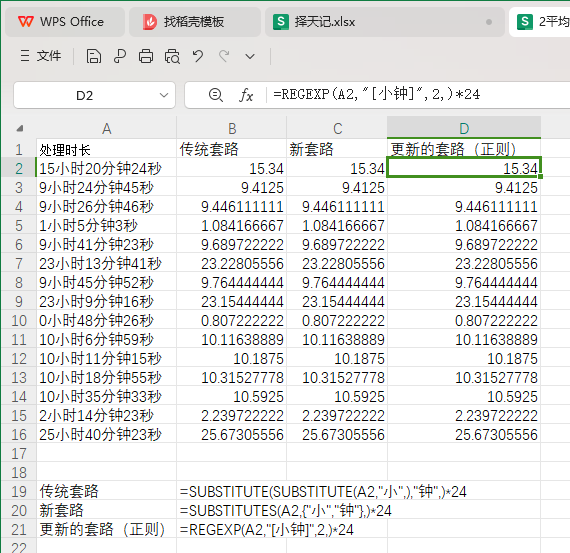
import torch import torch.nn as nnclass Loss(nn.Module):def __init__(self, kld_weight=0.03):super(Loss, self).__init__()self.kld_weight = kld_weightself.criterion = nn.MSELoss(reduction='mean')def forward(self, input, output, mu, log_var):recon_loss = self.criterion(output, input)kld_loss = -0.5 * torch.mean(1 + log_var - mu.pow(2) - log_var.exp())return recon_loss + self.kld_weight*kld_loss
train_vae.py
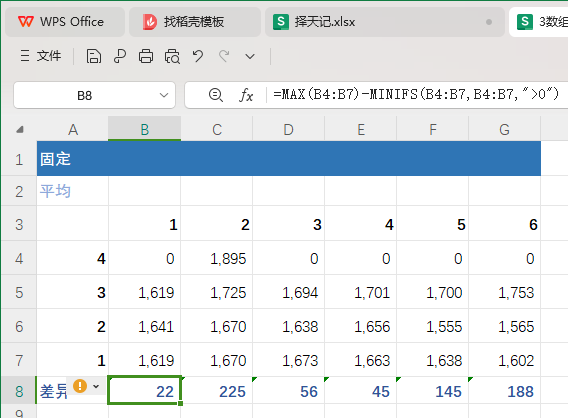
import os import numpy as np import torch from VAE import VAE import argparse from torch.utils.data import DataLoader from PIL import Image from torch.optim import Adam from utils import MyDataset from torchvision.utils import save_image from Loss import Loss from tqdm import tqdmdef args_parser():parser = argparse.ArgumentParser(description="Parameters of training vae model")parser.add_argument("-b", "--batch_size", type=int, default=128)parser.add_argument("-i", "--in_channels", type=int, default=3)parser.add_argument("-d", "--latent_dim", type=int, default=256)parser.add_argument("-l", "--lr", type=float, default=1e-3)parser.add_argument("-w", "--weight_decay", type=float, default=1e-5)parser.add_argument("-e", "--epoch", type=int, default=500)parser.add_argument("-v", "--snap_epoch", type=int, default=1)parser.add_argument("-n", "--num_samples", type=int, default=64)parser.add_argument("-p", "--path", type=str, default="./results_linear")return parser.parse_args()def train(model, input_data, loss_fn, optimizer):optimizer.zero_grad()out, mu, log_var = model(input_data)total_loss = loss_fn(input_data, out, mu, log_var)total_loss.backward()optimizer.step()print("loss:", total_loss.item())if __name__ == '__main__':DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")opt = args_parser()loss_fn = Loss(kld_weight=0.03)dataset = MyDataset(img_path="../faces/", device=DEVICE)train_loader = DataLoader(dataset=dataset, batch_size=opt.batch_size, shuffle=True, num_workers=0)model = VAE(image_size=96, in_channels=opt.in_channels, latent_dim=opt.latent_dim)model.to(DEVICE)optimizer = Adam(model.parameters(), lr=opt.lr, weight_decay=opt.weight_decay)for epoch in range(opt.epoch):model.train()data_bar = tqdm(train_loader)for step, data in enumerate(data_bar):train(model, data.to(DEVICE), loss_fn, optimizer)if epoch % opt.snap_epoch == 0 or epoch == opt.epoch - 1:model.eval()images = model.sample(opt.num_samples, DEVICE)imgs = images.detach().cpu().numpy()saved_image_path = os.path.join(opt.path, "images")os.makedirs(saved_image_path, exist_ok=True)fname = './my_generated-images-{0:0=4d}.png'.format(epoch)save_image(images, fname, nrow=8)saved_model_path = os.path.join(opt.path, "models")os.makedirs(saved_model_path, exist_ok=True)torch.save(model.state_dict(), os.path.join(saved_model_path, f"epoch_{epoch}.pth"))
没有调参,训练333个epoch,模型生成的结果如下:




![[LeetCode] 169. Majority Element](https://img2024.cnblogs.com/blog/747577/202406/747577-20240630141555355-145697356.png)

![[python] Python日志记录库loguru使用指北](https://gitcode.net/LuohenYJ/article_picture_warehouse/-/raw/main/wechat/content/%E5%8A%A0%E6%B2%B9%E9%B8%AD.gif)

