堆块:
chunk
堆是以一个个的堆块构成的,这些堆块就叫chunk
chunk的大小是8字节对齐,但是一个堆块的具体大小是16字节对齐的,比如一个堆块只能是 0x40,0x50,0x60 不会是0x48这样的数据
其中一个堆块的header头部字节占16字节大小,也就是0x10字节
64位程序下的最小长度是32字节大小的
这里我们先来了解一下chunk的头部是什么样子的
header

image-20240614170750740.png)
0x10字节 包含了prev size 以及 size,prev size 指向了上一个chunk的大小,size则是本chunk的大小,size的区域中则还存在着三个类似于标志位的东西
- non-main-arema查看当前的chunk是否不属于主线程,1是不属于,0是属于
- is-mmap表示当前的chunk是否是由mmap来分配空间的,1表示是,0表示不是
- prev_inuse表示前面的一个的chunk是否被使用,1表示前面的chunk正在被用户使用,0表示前一个chunk已经被释放了
同时,我们需要知道的是,chunk的pre size记录着上一个chunk的大小,但是只有在前一个chunk被free释放的时候也就是prev_inuse是0的时候才会生效,其他时候只会作为上一个chunk的user date
bin
bin有垃圾桶的意思,顾名思义,在堆中bin指的也就是被free掉的内存了,其实也是对于这些不同大小的释放之后的chunk进行管理,同时我们按照由ptmalloc释放的内存大小分为了不同的bin

这些bin都是按照链表的形式去存储chunk的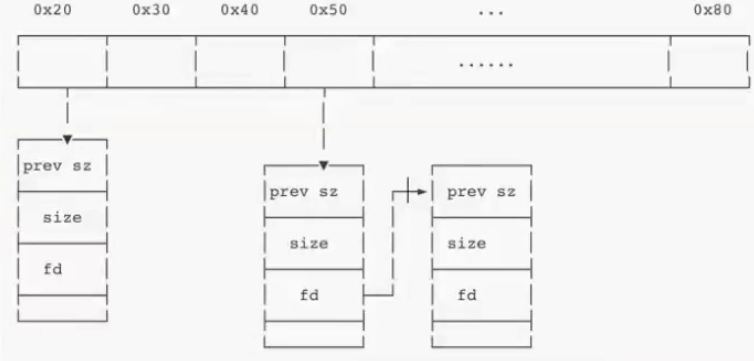
Fastbin
大小是0x20-0x80 每一个fastbin按照0x10的大小开始增长,比如0x20,则存储着大小为0x20个字节的chunk的chunk链表。同时对于大小属于fastbin的chunk被free之后下一个的chunk的preinuse不会改变,也不会合并
Smallbin、unsortedbin
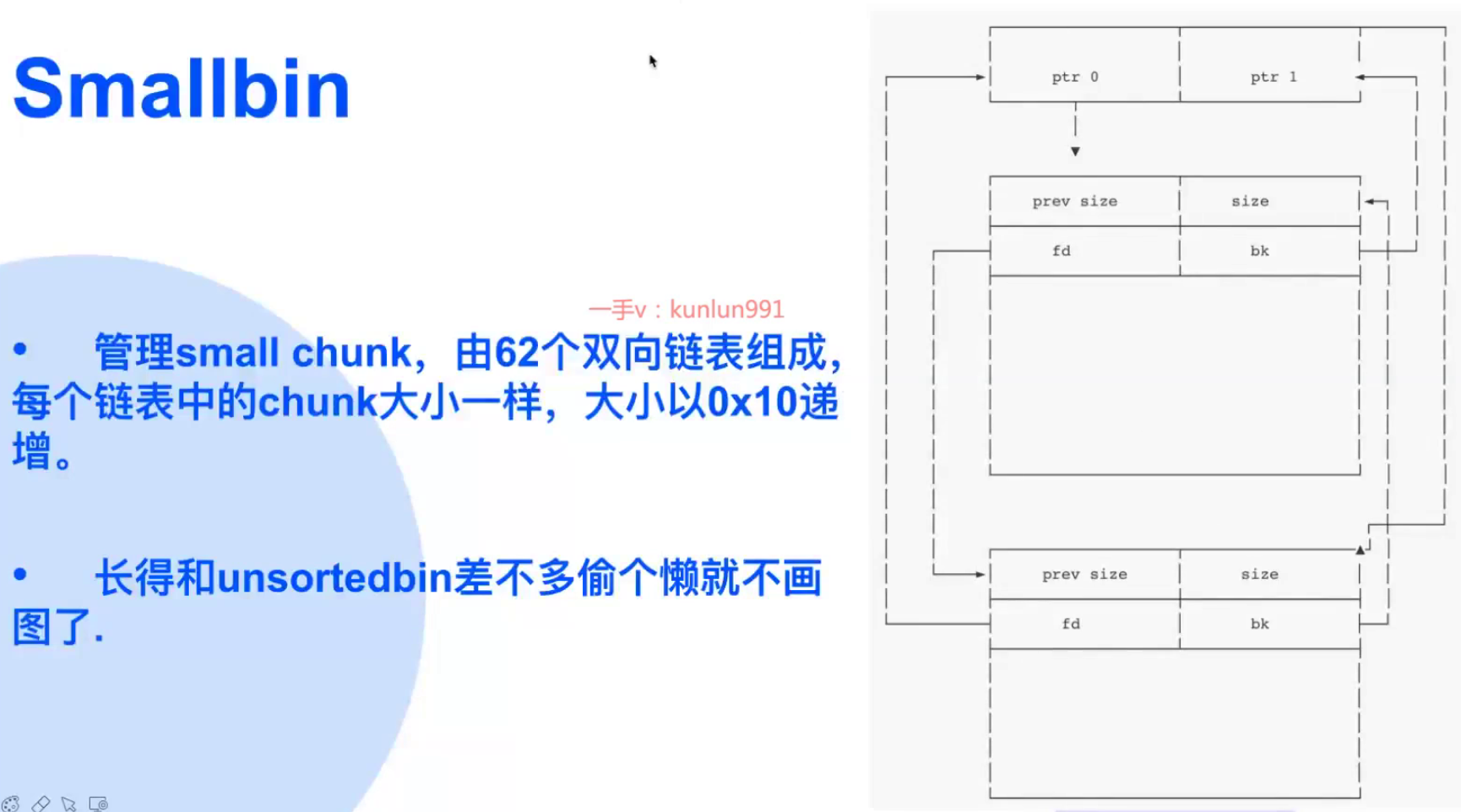
smallbin是62个chunk大小一样的双向链表,大小按照0x10进行递增图中的ptr 0 和ptr 1 分别是arena中的fd头和bk尾,所以每个smallbin都是先从arena开始,arena结束的一个双向循环链表的样子
unsortedbin其实和smallbin是一样的,但是它的链表中的chunk是大小不一的一条双向链表
largebin

largebin其实也和smallbin是一样的双向链表,只是因为,largebin的大小是0x410以上的,所以增量是不一样的,使得每一个chunk相连的时候的chunk的大小也可能是不一样的,所以这也就是为什么largebin的chunk中有四个指针
当两个相连的chunk是大小相等的时候,就只用fd和bk进行链接,这时可以视为smallchunk
当两个相连的chunk不一样大小的时候,,就需要用到fd-next-sz去链接下一个大小不一样的chunk,用bk-next-sz去链接前一个大小不一样的chunk。
合并
那我们就来看看是怎么进行释放的堆空间bin合并操作的
向前合并:查看本chunk的pre_inuse,假如是0,说明上一个chunk被释放可以和本chunk合并,那么就直接合并,同时修改size大小
向后合并:查看后面的后面的chunk的pre_inuse是否为0,是则可以进行合并
调用malloc分配内存的过程以及总结
我们已经了解过了上面的各种bin的结构了,那我们来想一想它们最初是怎么形成的呢?
首先是理解为什么要出现我们的chunk,bin..... 这些结构的出现的原因是我们不想一直通过系统调用去申请内存,这样一直的系统调用无论是从时间上以及安全等等的角度来说都是不合理的,这也就是这些数据结构出现的真正原因
了解到了这些结构产生原因,我们再进行,topchunk是chunk的一个最大的内存,所以的chunk都是由它来一一割裂形成的,内核通过申请内存来构造了topchunk
这里我们从malloc调用申请堆内存来说明
- 比较申请内存的大小和每个fastbin,假如小于fastbin且fastbin中有可用的chunk就直接分配内存;假如大于则向smallbin申请
- 比较申请内存的大小和每个smallbin,假如满足同上申请分配,否则就去unsortedbin去申请(这里会进行malloc_consolidate操作,就是,因为需要分配的是一个大的空间,所以ptmalloc会遍历fastbin中的chunk进行合并,并链接到unsortedbin中去)
- 比较申请内存的大小和每个unsortedbin,由于unsorted的chunk大小不一样,(注意:假如取出来的chunk不满足,也就是小了,则把这个chunk放入到相应大小的small和largebin中)假如大于申请的内存则去切割这个chunk(假如切割之后的大小小于0x10就没必要去切割),将切割之后的chunk放入unsorted。不满足申请largebin
- 比较申请内存的大小和每个largbin,同上的操作,不过这里会去选择满足申请的最小的chunk,并且进行切片,切片之后的放入unsortedbin。不满足只能去topchunk切割了
- 连topchunk都不够了,只能去mmap系统调用申请内存了。
这里我们来梳理一下chunk怎么来的,由于申请之后释放内存大小不一样来使得chunk被分配到了不同的bin中,同时unsortedbin中的chunk是被切割之后的chunk的收容所同时也会收入free大于了fastbin的chunk,但是smallbin和largebin中的chunk却来自于unsortedbin
调用free,程序在干嘛?
- free的chunk属于fastbin,直接收入完成,不属于下一步
- 查看chunk的is_mmap的判断是mmap分配的吗,是则munmap回收,不属于下一步
- 释放的chunk这时去查看前一个chunk是否是空闲,是则前合并
- 释放的chunk去查看后一个chunk是否是topchunk(特殊),是则与topchunk合并了,直接完成,不属于则下一步
- 释放的chunk这时去查看后一个chunk是否是空闲,是则后合并
- 之后就直接放入unsortedbin了
unlink
unlink是用来将一个双向链表(存储着空闲的chunk)中的一个元素取出来
所以,unlink是一个取空闲元素的一个操作
在malloc中的unlink
- 从恰好大小合适的largebin中的去获取chunk(其中fastbin和smallbin中没有unlink)
- 从比申请的chunk所在的bin大的bin中取chunk
在free中的unlink
- 向后合并,合并物理地址相邻低地址空闲的chunk
- 向前合并,合并物理地址相邻高地址空闲的chunk(除开topchunk)
在malloc_consolidate中的unlink
- 向后合并,合并物理地址相邻低地址空闲的chunk
- 向前合并,合并物理地址相邻高地址空闲的chunk(除开topchunk)
![image-20240618143444860]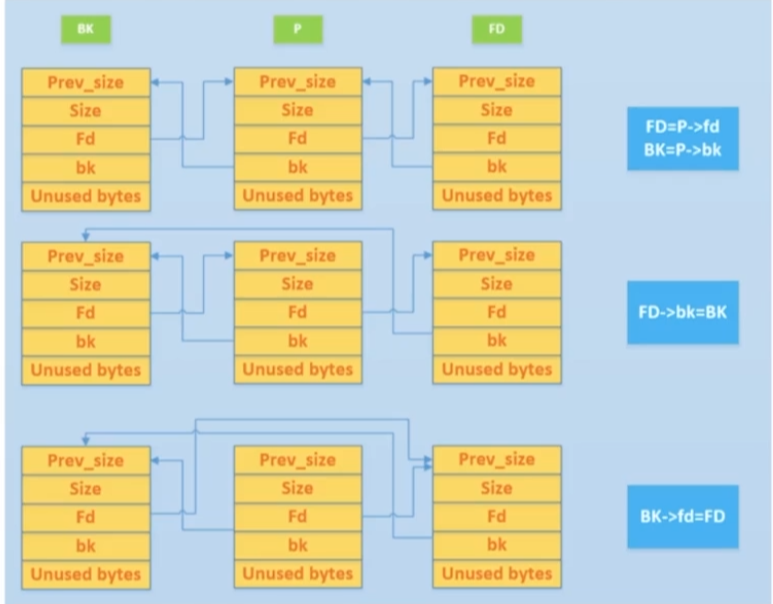
这里是unlink的过程,其实就是从 一个空闲的双链表中取出一个内存空间
但是相连的三个chunk中要取出中间的chunk是有校验的,也就是前一个chunk的bk指向当前这个chunk,后一个chunk的fd指向当前这个chunk
比如假如没有校验的情况之下,假如我们有uaf的时候,可以去控制当前的这个chunk的fd指向一块targe-0x18的位置,把我们的bk值设置为targe的expect的值,然后当我们指向回去的时候 targe-0x18 的bk就指向了我们的地址了
校验
在2.23版本之上的libc就对于这样的数据有校验了,也就是
P->fd->bk=P
P->bk->fd=P
所以我们只能申请一段fake_chunk来使得fd指向P的低0x10的位置,使得bk来指向P低0x18的位置,这样才能绕过校验
于是的结果就是P原本的chunk地址,因为fd的指向被修改到了P的低0x18个字节的位置
fastbin_attack
fastbin_attack通过fastbin来进行的攻击,其中的漏洞就是通过去利用去修改本来应该已经被free的fastbin中的chunk
USF(use after free)
顾名思义就是在当前的chunk被free之后还是能够进行的进行使用,也就是我们可以直接去修改chunk中的fd值,从而实现再一次进行申请地址时,我们可以去申请到我们fd指向的target_addr
double free
double free也是我们能够去利用的一个点
其中的原理其实就是,我们去free了chunk1,再去free一次chunk1,这样的结果就是,第一次free的chunk1的fd指向了chunk1,然后我们再去申请出来一个chunk1,然后去修改chunk1中的fd,指向我们的target_addr,然后再次free两次就可以直接去到target
随着glibc版本的增强,double free的检测也在增强,能够连续free两次同一个地址也会报错了
这时我们就会使用——>chunk1——>chunk2——>chunk1这样的形式去利用我们的结果,同样可以做到任意地址写
house of spirit
这里算是一个校验了,不太算是一个攻击,但是我们攻击取要用到这个,house of spirit针对的是fastbin这样的单链结构,当我们在想要利用构造fakechunk来实现我们的劫持程序的过程中,这里会对于我们构造的fake_chunk的size大小是否是当前fastbin对应的大小,只有当其对应的大小等于了我们的fastbin的大小,才会去给到这块fd指向的地址分配,同时不管这里是栈上,bss段上,还是什么地方,都还是把它视为堆的,所以它有prev_size,size等等
OFF BY ONE
通过去溢出一个字节,从而使得去修改了size的大小(比如:通过两个连续的chunk,我们去修改了第一个chunk的size大小【通过溢出手段,比如一个0x38大小的chunk,p指针指向这个chunk,然后p[0x38]=size,就修改了size的大小】),然后再进行free,就覆盖掉了两个chunk,然后我们再申请该大小的chunk就可以直接去修改第二个chunk的fd,bk了就可以间接劫持程序流。
#include <stdlib.h>
int main()
{void *p1,*p2,*p3;p1=malloc(0x38);p2=malloc(0x30);p3=malloc(0x30);char *p=p1;p[0x38]=0x81;free(p2);p2=malloc(0x71);return 0;
}
OFF BY NULL
chunk shrink
通过去使得chunk缩小,利用unlink构造出chunk overlap(两个chunk直接有重叠的空间)
我们同样是通过去溢出一个字节(这里我们需要知道的是只能溢出一个字节,也就是两个十六进制为)比如:当不再是fastbin的时候,申请了一个0x230大小的一个chunk,我们只能溢出修改的是0x30的位置
- 首先:我们去申请符合unsortedbin要去的chunk1 比如0x230,再申请一个chunk2,0x100(用于之后总体合并)
- 然后我们将第一个chunk1,free掉,并且将其size修改小,由于我们只能去修改一个字节大小的数据,所有我们只能将chunk的size设置为0x200,(注意,这里我们要提前去找到chunk1+0x200的位置,构造fake_chunk,使得fake_chunk的pre_size是0x200,这样才能过unlink的check)
- 这时候chunk2的pre_size的值仍然是0x230(这样再我们继续申请chunk时就可以直接去将中间的chunk合并完了),这时候我们会发现我们的unsortedbin里面由free的0x230变为了0x200,(可以注意的问题是:我们下面的代码由于直接去将0x200申请到了每一个位置,所有原本的0x100是被挤没了的,其实我们注意一下写入的chunk接入到ptr3的位置,是可以不挤掉的。)这时候我们去清空unsortedbin的内容,比如0x180+0x60(最好有一个0x60,申请之后就是0x70,可以找到相应的chunk的size大小)
- 然后我们去free0x180的chunk,(为了什么?因为0x180之后是0x60,他们之间的chunk链是合法的,free了0x180之后0x60的pre_size是0x180并且自己也是合法的大小)
- 最后我们去free(chunk2),由于chunk2的pre_size是之前chunk1的size,会导致直接去free掉了从chunk1到chunk2之间的所有堆空间,但是:我们的申请的0x60并没有被我们free,所有导致的结果就是,可以free同一块chunk了
#include <stdio.h>
#include <stdlib.h>
int main()
{void *ptr1=malloc(0x18);void *ptr2=malloc(0x220);void *ptr3=malloc(0x100);malloc(0x10);size_t *p1=ptr2;for(int i=0;i<0x220/8;i++){p1[i]=0x200;}free(ptr2); char *p2=ptr1;p2[0x18]=0;ptr1=malloc(0x180);void *ptr4=malloc(0x60);free(ptr1);free(ptr3);free(ptr4);return 0;
}
House Of Einherjar
这是一种堆利用的方式,采用的思路也是通过构造overlap实现间接劫持程序流,利用的手法也就是通过去修改chunk的pre_size,去实现两个不相邻chunk的unlink,从而实现中间chunk的overlap
#include <stdio.h>
#include <stdlib.h>
int main()
{void *ptr1=malloc(0x200);void *ptr2=malloc(0x18);void *ptr3=malloc(0x100-0x10);malloc(0x10);free(ptr1);size_t *p=ptr3;p[-1]=0x100;p[-2]=0x230;free(ptr3);free(ptr2);return 0;
}
这里是最简单的一个house of einherjar 直接就是通过去修改我们的ptr3的pre_size和size,使得我们free的结果指向了ptr1,然后直接进行了合并。这时候overlap就是我们的ptr2.
但是:面对于高版本的glibc,会增加很多的check手段
- 比如说当我们进行合并的时候,会进行unlink的检测,也就是合并的ptr1(按照上面的来说)的chunk1的fd——>FD,chunk1的bk——>BK之后,检测FD——>bk=chunk1以及BK——>fd=chunk1。
- 这时候我们绕过的方式就是通过构造fake_chunk,使得fake_chunk的fd=fake_chunk本身,fake_chunk的bk=fake_chunk本身,这样的结果就是直接绕过检测了
- 在以上代码中,我们将free之后的ptr3+pre_size指向了ptr1,这样完成了覆盖ptr2,但同时进行的检测还有我们指向的ptr1的size必须==ptr3的pre_size,所有我们同时构造的fake_chunk的size必须等于ptr3的pre_size
高版本绕过:
#include <stdio.h>
#include <stdlib.h>
int main()
{void *ptr1=malloc(0x200);void *ptr2=malloc(0x18);void *ptr3=malloc(0x100-0x10);malloc(0x10);size_t *p=ptr1;p[0]=0;p[1]=0x221;p[2]=ptr1;p[3]=ptr1;p=ptr3;p[-1]=0x100;p[-2]=0x220;free(ptr3);free(ptr2);return 0;
}