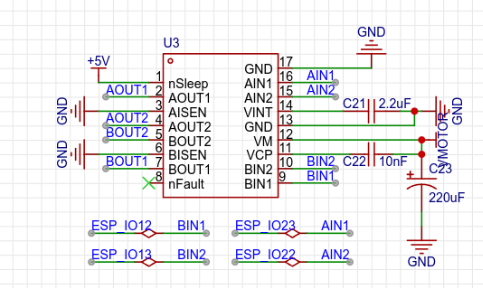
mosaic 是yolov4中提出的一个数据增强的方式,通过将4张图片拼接在一起送入训练,有效提升了模型的map。mosaic的优点包括如下:
- 增加数据多样性,随机选取四张图像进行组合,组合得到图像个数比原图个数要多。
- 增强模型鲁棒性,混合四张具有不同语义信息的图片,可以让模型检测超出常规语境的目标。
- 加强批归一化层(Batch Normalization)的效果。当模型设置 BN 操作后,训练时会尽可能增大批样本总量(BatchSize),因为 BN 原理为计算每一个特征层的均值和方差,如果批样本总量越大,那么 BN 计算的均值和方差就越接近于整个数据集的均值和方差,效果越好。
- Mosaic 数据增强算法有利于提升小目标检测性能。Mosaic 数据增强图像由四张原始图像拼接而成,这样每张图像会有更大概率包含小目标。
- 训练的难度增大,有助于模型性能的提
本篇分析mosaic的实现方式。
代码分析
def load_mosaic(self, index):# YOLOv5 4-mosaic loader. Loads 1 image + 3 random images into a 4-image mosaiclabels4, segments4 = [], []s = self.img_sizeyc, xc = (int(random.uniform(-x, 2 * s + x)) for x in self.mosaic_border) # mosaic center x, yindices = [index] + random.choices(self.indices, k=3) # 3 additional image indicesrandom.shuffle(indices)for i, index in enumerate(indices):# Load imageimg, _, (h, w) = self.load_image(index)# place img in img4if i == 0: # top leftimg4 = np.full((s * 2, s * 2, img.shape[2]), 114, dtype=np.uint8) # base image with 4 tilesx1a, y1a, x2a, y2a = max(xc - w, 0), max(yc - h, 0), xc, yc # xmin, ymin, xmax, ymax (large image)x1b, y1b, x2b, y2b = w - (x2a - x1a), h - (y2a - y1a), w, h # xmin, ymin, xmax, ymax (small image)elif i == 1: # top rightx1a, y1a, x2a, y2a = xc, max(yc - h, 0), min(xc + w, s * 2), ycx1b, y1b, x2b, y2b = 0, h - (y2a - y1a), min(w, x2a - x1a), helif i == 2: # bottom leftx1a, y1a, x2a, y2a = max(xc - w, 0), yc, xc, min(s * 2, yc + h)x1b, y1b, x2b, y2b = w - (x2a - x1a), 0, w, min(y2a - y1a, h)elif i == 3: # bottom rightx1a, y1a, x2a, y2a = xc, yc, min(xc + w, s * 2), min(s * 2, yc + h)x1b, y1b, x2b, y2b = 0, 0, min(w, x2a - x1a), min(y2a - y1a, h)img4[y1a:y2a, x1a:x2a] = img[y1b:y2b, x1b:x2b] # img4[ymin:ymax, xmin:xmax]padw = x1a - x1bpadh = y1a - y1b# Labelslabels, segments = self.labels[index].copy(), self.segments[index].copy()if labels.size:labels[:, 1:] = xywhn2xyxy(labels[:, 1:], w, h, padw, padh) # normalized xywh to pixel xyxy formatsegments = [xyn2xy(x, w, h, padw, padh) for x in segments]labels4.append(labels)segments4.extend(segments)# Concat/clip labelslabels4 = np.concatenate(labels4, 0)for x in (labels4[:, 1:], *segments4):np.clip(x, 0, 2 * s, out=x) # clip when using random_perspective()# img4, labels4 = replicate(img4, labels4) # replicate# Augmentimg4, labels4, segments4 = copy_paste(img4, labels4, segments4, p=self.hyp['copy_paste'])img4, labels4 = random_perspective(img4,labels4,segments4,degrees=self.hyp['degrees'],translate=self.hyp['translate'],scale=self.hyp['scale'],shear=self.hyp['shear'],perspective=self.hyp['perspective'],border=self.mosaic_border) # border to removereturn img4, labels4
马赛克之后的结果如下:




mosaic 的过程可以分为如下几步:
- 确定四张图片的中心点
- 计算上下左右四张图片的左上右下坐标点
- 图片上的标注框做相应的转换
- 裁剪标注框多余部分
确定四张图片的中心点
马赛克的第一步就是选择一个中心点,以中心点为基准放置4张图片。中心点选择不是随便的,需要一个范围能够马赛克之后的效果可控。
labels4, segments4 = [], []
s = self.img_size
yc, xc = (int(random.uniform(-x, 2 * s + x)) for x in self.mosaic_border) # mosaic center x, y
其中 self.mosaic_border = [-img_size // 2, -img_size // 2],所以 self.mosaic_border = [320, 320]
s = 640,所以 random.uniform(320, 960) 就是用320到960之间选择四张图片的中心点。

计算四张图片的左上右下坐标点
确定了中心点之后就可以将四张图片分别放置在上左,上右,下左,下右四个位置上。
indices = [index] + random.choices(self.indices, k=3) # 3 additional image indices
random.shuffle(indices)
for i, index in enumerate(indices):# Load imageimg, _, (h, w) = self.load_image(index)# place img in img4if i == 0: # top leftimg4 = np.full((s * 2, s * 2, img.shape[2]), 114, dtype=np.uint8) # base image with 4 tilesx1a, y1a, x2a, y2a = max(xc - w, 0), max(yc - h, 0), xc, yc # xmin, ymin, xmax, ymax (large image)x1b, y1b, x2b, y2b = w - (x2a - x1a), h - (y2a - y1a), w, h # xmin, ymin, xmax, ymax (small image)elif i == 1: # top rightx1a, y1a, x2a, y2a = xc, max(yc - h, 0), min(xc + w, s * 2), ycx1b, y1b, x2b, y2b = 0, h - (y2a - y1a), min(w, x2a - x1a), helif i == 2: # bottom leftx1a, y1a, x2a, y2a = max(xc - w, 0), yc, xc, min(s * 2, yc + h)x1b, y1b, x2b, y2b = w - (x2a - x1a), 0, w, min(y2a - y1a, h)elif i == 3: # bottom rightx1a, y1a, x2a, y2a = xc, yc, min(xc + w, s * 2), min(s * 2, yc + h)x1b, y1b, x2b, y2b = 0, 0, min(w, x2a - x1a), min(y2a - y1a, h)img4[y1a:y2a, x1a:x2a] = img[y1b:y2b, x1b:x2b] # img4[ymin:ymax, xmin:xmax]
从剩余的图片中随机抽取三张,包括当前这一张一共四张,打乱顺序。遍历四张图片,分别处理。首先处理上左。
img4 = np.full((s * 2, s * 2, img.shape[2]), 114, dtype=np.uint8)
首先建立一张空画布,长宽都是两张图片的长宽,1280 * 1280,空白画布如下:

然后画布中上左图片的位置。x1a, y1a是图片在画布中左上角的坐标,x2a, y2a是右下角的坐标。
x1a, y1a, x2a, y2a = max(xc - w, 0), max(yc - h, 0), xc, yc # xmin, ymin, xmax, ymax (large image)
x2a, y2a 可以想象就是中心点,也就是xc, yc。x1a 等于中心点横坐标减去图片宽,y1a等于中心点纵坐标减去图片高。可能会出现中心坐标比较靠左,图片超过画布的情况,x1a,y1a会变成一个负值,所以需要判断,当x1a,y1a变成一个负值时,要等于0。
可能存在的如下两种情况:

x1b, y1b, x2b, y2b = w - (x2a - x1a), h - (y2a - y1a), w, h
当出现第二种情况时,就需要先裁剪图片再填充到画布中,所以还需要计算出图片裁剪的坐标。
x1b,y1b是裁剪的左上角坐标, x2b, y2b是裁剪的右下角坐标。当然,如果图片没有超出画布,这两个值就刚好等于图片的全部大小。
img4[y1a:y2a, x1a:x2a] = img[y1b:y2b, x1b:x2b]
最后将图片裁剪之后的像素拷贝到画布中。
剩余三个照片也是同理粘贴。

图片上的标注框做相应的转换
将图片放置在画布上之后,标注框也要放置在画布上。由于图片放在画布上会让标注框产生偏移,所以需要将这些偏移量加到标注框上。
padw = x1a - x1b
padh = y1a - y1b# Labels
labels, segments = self.labels[index].copy(), self.segments[index].copy()
if labels.size:labels[:, 1:] = xywhn2xyxy(labels[:, 1:], w, h, padw, padh) # normalized xywh to pixel xyxy formatsegments = [xyn2xy(x, w, h, padw, padh) for x in segments]
labels4.append(labels)
segments4.extend(segments)
假设画布中心点就是正方形中心,那么左上角的图片则刚贴合。标注框相当于图片的左上角而言,现在图片和画布上左完全重合,就不需要处理。但是通常画布的中心点不会那么正,相对于中心点有偏移。图片相对于画布的左上角也有偏移,那么标注框也得加上对应的偏移才能回到图片上的位置。
偏移量的计算如下:
padw = x1a - x1b
padh = y1a - y

在xywhn2xyxy中将xywh格式的标注框转换成xyxy格式,同时加上对应的偏移量。让标注框从以原图为坐标系变成以画布为坐标系。
def xywhn2xyxy(x, w=640, h=640, padw=0, padh=0):# Convert nx4 boxes from [x, y, w, h] normalized to [x1, y1, x2, y2] where xy1=top-left, xy2=bottom-righty = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)y[:, 0] = w * (x[:, 0] - x[:, 2] / 2) + padw # top left xy[:, 1] = h * (x[:, 1] - x[:, 3] / 2) + padh # top left yy[:, 2] = w * (x[:, 0] + x[:, 2] / 2) + padw # bottom right xy[:, 3] = h * (x[:, 1] + x[:, 3] / 2) + padh # bottom right yreturn y
同理上右也是如此:

裁剪标注框多余部分
将标注框超出画布的部分裁剪掉,下图的蓝框所在区域。
# Concat/clip labels
labels4 = np.concatenate(labels4, 0)
for x in (labels4[:, 1:], *segments4):np.clip(x, 0, 2 * s, out=x) # clip when using random_perspective()
np.clip 用于将数组中的元素限制在指定的范围内。如果元素的值低于给定的最小值,则会被设置为该最小值;如果元素的值高于给定的最大值,则会被设置为该最大值。

In [22]: arr = np.array([-1, 0.5, 1.5, 2, 3])
In [23]: arr
Out[23]: array([-1. , 0.5, 1.5, 2. , 3. ])In [24]: np.clip(arr, 0, 2)
Out[24]: array([0. , 0.5, 1.5, 2. , 2. ])
使用np.clip函数将标签超出的部分都裁剪掉。
将标注框显示在图片中的效果如下。