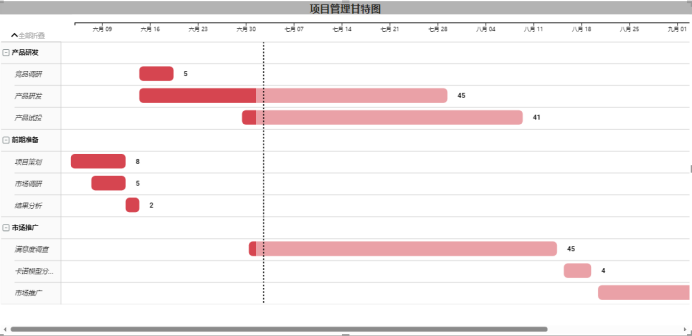
Guava Cache、EVCache、Tair、Aerospike 是不同类型的缓存解决方案,它们各有特点和应用场景。下面我会逐一分析这些缓存系统的优势、应用场景,并提供一些基本的代码示例。
Guava Cache
优势特点:
- 内置在Guava库中,易于集成和使用。
- 提供了丰富的缓存配置选项,如过期策略、缓存加载策略等。
- 适用于单机应用内的缓存场景。
应用场景:
- 本地缓存,用于提升Java应用的数据处理速度。
- 适合数据量不大,需要快速访问的场合。
代码示例:
LoadingCache<String, Object> cache = CacheBuilder.newBuilder().maximumSize(1000).expireAfterWrite(10, TimeUnit.MINUTES).build(new CacheLoader<String, Object>() {public Object load(String key) {// 缓存不存在时,加载缓存逻辑return fetchDataFromDatabase(key);}});
EVCache
优势特点:
- 基于Memcached,支持数据的分布式存储。
- 高性能和高可用性。
- 支持数据压缩和高效的序列化机制。
应用场景:
- 分布式缓存,适用于大型应用和系统。
- 高并发访问场景,如大型网站、社交网络等。
代码示例:
EVCache cache = EVCache.getCache("myCache", "myApp");
String value = cache.get("key");
Tair
优势特点:
- 由阿里巴巴开发,支持分布式数据存储。
- 提供丰富的数据结构支持,如K-V、列表、集合等。
- 高可用性和可扩展性。
应用场景:
- 适用于需要高可用、高并发、大数据量的场景。
- 适合大规模分布式系统。
代码示例:
// 示例代码为伪代码,因为Tair的具体API依赖于客户端库
TairClient tairClient = new TairClient("config.properties");
tairClient.put(1, "key", "value");
Aerospike
优势特点:
- 高性能的NoSQL数据库,支持缓存和持久化存储。
- 支持数据备份和自动恢复。
- 适用于大规模数据集和低延迟访问。
应用场景:
- 适用于需要高性能、低延迟的数据访问场景。
- 适合大规模分布式系统,如实时广告投放、用户行为分析等。
代码示例:
// 示例代码为伪代码,因为Aerospike的具体API依赖于客户端库
AerospikeClient client = new AerospikeClient("localhost", 3000);
Key key = new Key("test", "demo", "key");
Record record = client.get(null, key);
在选择适合的缓存系统时,需要根据具体的应用场景、性能要求、数据规模等因素进行综合考虑。每种缓存系统都有其独特的优势,选择合适的缓存策略对提升系统性能至关重要。
下面 V 哥来一一说一说各自的实现原理,方更兄弟们更好的理解。
实现原理
Guava Cache
Guava Cache是Google Guava库提供的一种基于内存的缓存实现,它主要用于提升数据访问速度,减少对底层存储系统(如数据库)的访问。Guava Cache的实现原理主要包括以下几个方面:
1. 缓存加载策略:
- 懒加载:当缓存项不存在时,可以通过定义的加载函数(CacheLoader)来异步加载缓存值。
- 预加载:可以在创建缓存时通过CacheBuilder的build方法传入一个CacheLoader,实现缓存的预加载。
2. 缓存回收策略:
- 基于大小回收:可以设置缓存的最大条目数(maximumSize)或最大权重(maximumWeight),当达到限制时,会根据一定的策略(如最少使用(LRU)、先进先出(FIFO)等)回收缓存项。
- 基于时间回收:可以设置缓存项在写入后多久(expireAfterWrite)或访问后多久(expireAfterAccess)失效。
3. 缓存刷新策略:
- 可以设置缓存项在多久之后自动刷新(refreshAfterWrite),这通常用于数据可能会更新的场景。
4. 并发控制:
- Guava Cache内部使用了锁机制来保证并发访问时的线程安全。
5. 统计功能:
- Guava Cache提供了缓存命中、未命中、加载时间等统计信息,便于监控和调优。
6. 移除监听器:
- 可以添加移除监听器(RemovalListener),当缓存项被移除时执行特定的逻辑,如资源清理等。
7. 缓存键和缓存值:
- 缓存键可以是任意不可变对象,缓存值可以是任意对象。
Guava Cache的实现原理基于以上几个核心概念,通过组合这些概念,可以创建出适合不同场景的缓存策略。例如,可以创建一个有限大小的缓存,当缓存达到最大容量时,会根据访问频率回收不常用的缓存项,同时,当缓存项长时间未被访问时,缓存会自动将其移除。
以下是Guava Cache的一个简单示例:
LoadingCache<String, String> cache = CacheBuilder.newBuilder().maximumSize(100) // 设置最大缓存条目数.expireAfterWrite(10, TimeUnit.MINUTES) // 设置写入10分钟后过期.build(new CacheLoader<String, String>() {@Overridepublic String load(String key) {// 缓存项不存在时,加载缓存值的逻辑return getDataFromDatabase(key);}});String value = cache.getUnchecked("key"); // 获取缓存值
在这个示例中,cache是一个LoadingCache实例,它会在缓存项不存在时通过load方法加载数据。缓存设置了最大条目数和写入过期时间,当缓存项达到最大数量或写入超过10分钟后,相应的缓存项会被回收。
EVCache
EVCache 是一个分布式数据缓存系统,基于 Memcached 协议构建。它主要用于缓存大量数据,以减少对后端数据库的访问,提高系统的响应速度。EVCache 的实现原理可以从以下几个方面来理解:
分布式存储:
EVCache 将数据存储在多个 Memcached 节点上,每个节点可以存储一部分数据。这种分布式存储机制可以提高数据的读取速度,因为请求可以并行发送到不同的节点。
数据一致性:
EVCache 通常使用一致性哈希(Consistent Hashing)算法来决定数据应该存储在哪个节点上。这种算法可以使得数据在节点之间均匀分布,并且当节点加入或离开集群时,能够最小化数据迁移的数量。
数据复制:
为了提高可用性和容错性,EVCache 支持数据复制。可以将数据的副本存储在多个节点上,这样即使某个节点发生故障,其他节点上的副本仍然可以提供服务。
缓存失效策略:
Memcached 内置了简单的缓存失效机制,例如 LRU(Least Recently Used)和到期失效(Time-to-Live, TTL)。EVCache 继承了这些特性,允许开发者设置数据的过期时间,以确保缓存数据的时效性和新鲜度。
客户端支持:
EVCache 提供了客户端库,使得开发者可以轻松地在应用程序中集成 EVCache。客户端库通常提供了丰富的 API,用于数据的存取、缓存管理和其他高级功能。
性能优化:
EVCache 优化了网络通信和数据序列化/反序列化过程,以减少延迟并提高吞吐量。它还支持数据压缩,以减少网络带宽的使用。
监控和管理:
EVCache 支持监控和管理功能,允许开发者监控缓存节点的健康状况、性能指标和统计数据。这有助于及时发现和解决问题,以及进行性能调优。
EVCache 的应用场景包括需要高速缓存的大型网站和服务,如 Amazon、Netflix 等公司就使用了 EVCache 来缓存大量的用户数据,以提高用户体验和系统性能。
由于 EVCache 是一个复杂的系统,它通常需要与 Memcached 服务器、客户端库和应用程序集成在一起。因此,它的实现细节可能会因具体的部署和配置而有所不同。
Tair
Tair 是一个分布式高性能缓存系统,由阿里巴巴集团开发。它支持多种数据结构,如键值对(K-V)、列表、集合等,并且提供了高可用性和可扩展性。Tair 的实现原理可以从以下几个方面来理解:
数据分片:
Tair 将数据分散存储在多个节点上,每个节点负责存储一部分数据。这种分片机制允许系统水平扩展,通过增加节点来提高存储容量和吞吐量。
一致性哈希:
Tair 使用一致性哈希算法来决定数据应该存储在哪个节点上。这种算法可以使得数据在节点之间均匀分布,并且在节点加入或离开集群时,能够最小化数据迁移的数量。
数据复制:
为了提高数据的可靠性和可用性,Tair 支持数据复制。可以将数据的副本存储在多个节点上,这样即使某个节点发生故障,其他节点上的副本仍然可以提供服务。
多种数据结构支持:
Tair 不仅支持简单的键值对存储,还支持列表、集合等复杂数据结构,这使得它能够适用于多种不同的业务场景。
持久化存储:
Tair 支持将数据持久化存储到磁盘上,这样即使系统发生故障,数据也不会丢失。这使得 Tair 既可以作为缓存系统使用,也可以作为轻量级的分布式存储系统使用。
缓存失效策略:
Tair 支持多种缓存失效策略,如 LRU(Least Recently Used)、TTL(Time-to-Live)等,以确保缓存数据的时效性和新鲜度。
客户端支持:
Tair 提供了客户端库,使得开发者可以轻松地在应用程序中集成 Tair。客户端库通常提供了丰富的 API,用于数据的存取、缓存管理和其他高级功能。
高可用性和故障转移:
Tair 设计了故障转移机制,当某个节点发生故障时,系统可以自动将请求路由到其他健康的节点上,从而保证服务的高可用性。
Tair 的应用场景包括需要高并发、大数据量、低延迟访问的分布式系统。例如,它可以用于存储用户会话信息、商品信息、分布式锁等。由于 Tair 提供了多种数据结构支持,它能够满足不同业务场景的需求。
由于 Tair 是一个复杂的分布式系统,它的实现细节涉及到数据分片、复制、一致性保证、故障转移等多个方面。这些细节通常由 Tair 的内部架构和算法来处理,对用户来说是透明的。
Aerospike
Aerospike 是一个分布式NoSQL数据库,它专为高速、可扩展性、和高可用性而设计。Aerospike 的实现原理可以从以下几个方面来理解:
数据模型:
Aerospike 使用了一个简单的数据模型,由“namespace”、“set”和“record”组成。每个记录由一个唯一的键(key)和一个或多个二进制数据结构(bin)组成,其中bins存储实际的数据。
分布式架构:
Aerospike 设计为分布式系统,数据分布在多个服务器节点上。它使用了一种称为“哈希分区”(hash partitioning)的技术,将数据均匀地分布在集群中的所有节点上。
内存中存储:
Aerospike 主要将数据存储在内存中,以实现快速的数据访问。它使用了一种名为“内存中索引”(in-memory index)的技术,允许对数据进行快速查询。
持久化存储:
尽管数据主要存储在内存中,Aerospike 还支持将数据持久化到磁盘上。它使用了一种名为“写后日志”(write-ahead logging, WAL)的技术,确保数据的持久性和一致性。
数据复制:
Aerospike 支持数据复制,可以配置数据的副本数量。副本存储在不同的节点上,以提高数据的可靠性和可用性。
缓存和存储一体化:
Aerospike 结合了缓存和存储的特点,既可以作为高速缓存使用,也可以作为持久化存储使用。它通过自动管理内存中的数据和磁盘上的数据来实现这一点。
动态集群管理:
Aerospike 集群可以动态地添加或移除节点,而不会影响到正在进行的操作。这使得系统能够适应负载的变化和扩展需求。
强大的查询功能:
Aerospike 支持复杂的查询操作,包括二级索引、聚合查询和地理位置查询等。这些查询操作可以快速执行,因为它们主要在内存中完成。
事务支持:
Aerospike 支持原子性的事务操作,确保了多个操作在逻辑上的完整性和一致性。
Aerospike 的应用场景包括需要高速、低延迟数据访问的场合,如实时推荐、用户行为分析、在线广告等。它的设计目标是提供高吞吐量和低延迟,同时保持数据的持久性和一致性。
Aerospike 的实现细节涉及到数据分布、内存管理、磁盘I/O优化、数据复制和一致性保证等多个方面。这些技术确保了 Aerospike 能够在高速、可扩展和高可用的环境中稳定运行。
最后
除了Redis 框架,以上是对 GuavaCache、EVCache、Tair、Aerospike 缓存框架的比较,在实际项目中选持适合的才是最好的。关注威哥爱编程,让我们一起在技术海洋奔跑