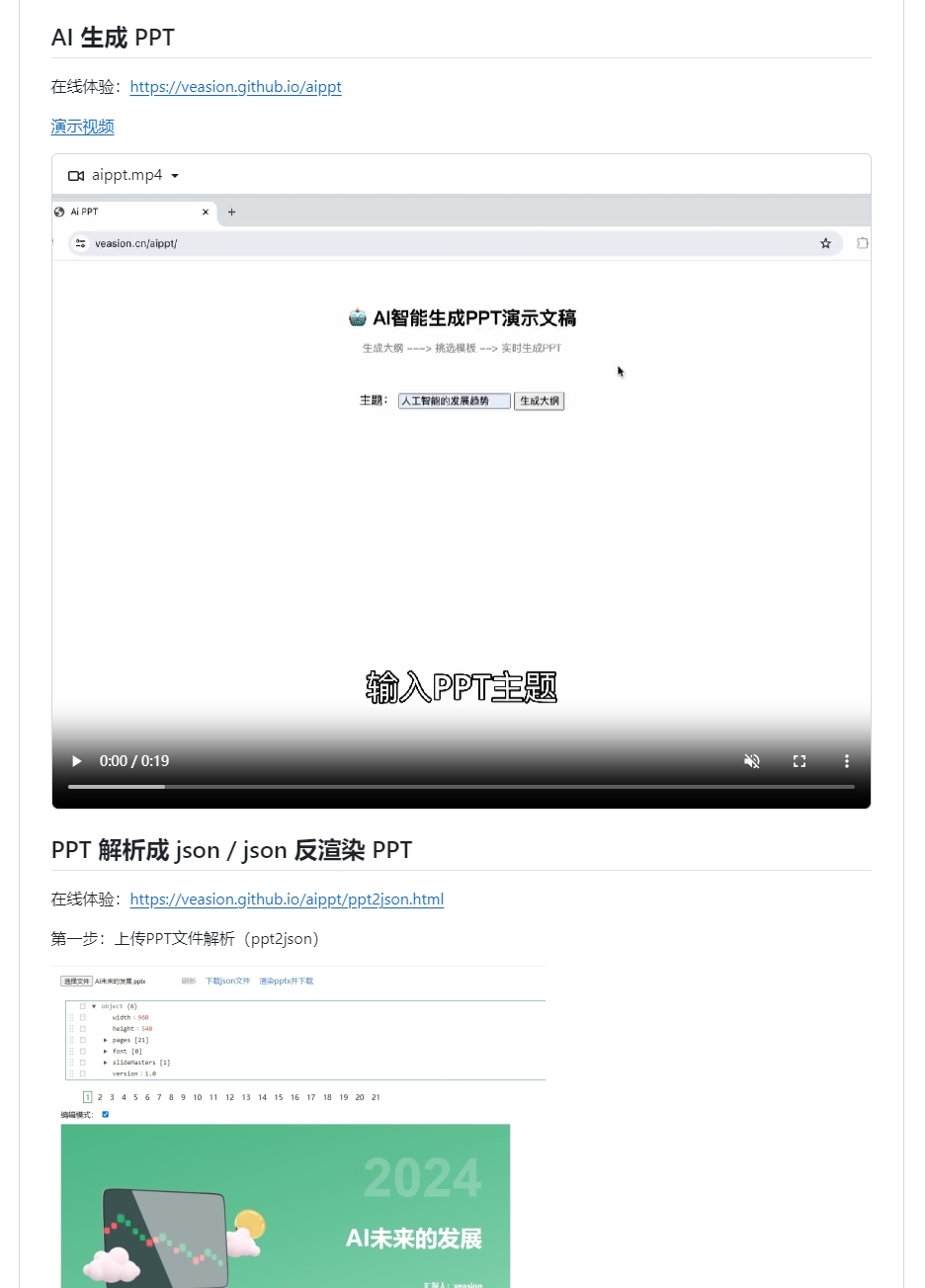
全文下载链接: http://tecdat.cn/?p=26105
最近我们被客户要求撰写关于LCTM的研究报告,包括一些图形和统计输出。
在本文中,潜类别轨迹建模 (LCTM) 是流行病学中一种相对较新的方法,用于描述生命过程中的暴露,它将异质人群简化为同质模式或类别。然而,对于给定的数据集,可以根据类的数量、模型结构和轨迹属性得出不同模型的分数
本文说明了LCTM的基本用法,用于汇总拟合的潜在类轨迹模型对象的输出。
例子
目的:通过将 BMI 建模为年龄函数,识别具有不同轨迹的参与者亚组。根据迄今为止可用的文献,我们假设初始 K=5 类 BMI 轨迹。
我们使用体重指数 (BMI) 重复测量 10,000 个样本的长格式数据框。
提供了一个示例(模拟)数据集 bmi 来描述整个步骤。
包含的变量有:
id - 个人 ID
年龄 - BMI 测量的年龄,以年为单位
bmi - 个人在 T1、T2、T3 和 T4 时间的体重指数,以 kg/m^2 为单位 true_class - 用于识别模拟个人 BMI 数据的类别的标签
加载数据
绘制数据
潜在类轨迹建模的八步示例
为了对纵向结果 yijk 进行建模,对于 k=1:K,类,对于个体 i,在时间点 j,tj可以使用许多建模选择。我们在这里给出方程来说明这些,并按照复杂度增加的顺序将它们命名为模型 A 到 G。
模型 A:无随机效应模型 | 固定效应同方差 | - 解释个人轨迹与其平均类轨迹的任何偏差仅是由于随机误差
其中假设所有类的残差方差相等,
相关视频
**
拓端
,赞17
模型 B:具有特定类别残差的固定效应模型 | 异方差 | 与模型 A 相同的解释,随机误差在不同的类别中可能更大或更小。
其中假设残差方差不同
模型 C:随机截距 解释是允许个体的初始体重不同,但假设每个班级成员遵循平均轨迹的相同形状和大小
对于 k=1:K, classes, 对于个体 i, 在时间点 j, tj,
其中随机效应分布
模型 D:随机斜率 允许个体在初始权重和平均轨迹的斜率上有所不同
对于 k=1:K,类,对于个体 i,在时间点 j , tj,
其中假设随机效应分布为
模型 E:随机二次 - 跨类的共同方差结构 允许个体在类内通过初始权重变化,但是假设每个类具有相同的变异量。对于 k=1:K, 类, 对于个体 i, 在时间点 j, tj,
其中假设随机效应分布为
模型 F 和 G:随机二次 - 允许方差结构跨类变化的比例约束 ,增加模型 E 的灵活性,因为允许方差结构相差一个乘法因子,以允许某些类具有更大或更小的类内方差。该模型可以被认为是模型 G 的更简洁版本(将要估计的方差-协方差参数的数量从 6xK 参数减少到 6+(K-1)个参数。
对于 k=1:K, classes, 对于个体 i, 在时间点 j, tj,
其中假设随机效应分布为
第一步:选择随机效应结构的形式
为了确定随机效应的初始工作模型结构,可以遵循 Verbeke 和 Molenbergh 的基本原理来检查没有随机效应的模型中每个 K 类的标准化残差图的形状。
如果残差轮廓可以近似为平坦、直线或曲线,则分别考虑随机截距、斜率或二次项。
为了拟合没有随机效应的潜在类模型。
hlmfixed(bmig)然后,我们将拟合模型输入 LCTM中的 step1 函数,以检查特定类别的残差。
第2步
优化步骤 1 中的初步工作模型以确定最佳类数,测试 K=1,...7。可以根据最低贝叶斯信息标准 (BIC) 来选择所选类别的数量。
set.seed(100)for (i in 2:4) {
mi <- lchlme( data.frame(bmg[1:500,])
}
#> Be patient, hlme is running ...
#> The program took 0.29 seconds
#> Be patient, hlme is running ...
#> The program took 0.69 seconds
#> Be patient, hlme is running ...
#> The program took 2.3 secondsmodelut <-kable(lin)第 3 步
使用步骤 2 中推导出的偏好 K 进一步细化模型,测试最优模型结构。我们测试了七个模型,从简单的固定效应模型(模型 A)到允许残差在类别之间变化的基本方法(模型 B)到一组具有不同方差结构的五个随机效应模型(模型 CG)。
- A(SAS、PROC TRAJ)
- B型(R,mmlcr)
调用 source() 命令。
mmldata = bmi_l01
# )# model_b$BIC- C (SAS、PROC TRAJ)
- D 型(SAS、PROC TRAJ)
- E型 (R, lcmm)
moe <- hlmfixed = bmi ~1+ age + I(age^2),
mixture = ~1 + age + I(age^2)
#> Be patient, hlme is running ...
#> The program took 0.77 secondsme$BIC- F型 (R, lcmm)
fixed = bmi ~1+ age + I(age^2),
mixture = ~1 + age + I(age^2)mod$BIC- G (SAS、PROC TRAJ)
第四步
执行一些模型充分性评估。首先,对于每个参与者,计算被分配到每个轨迹类的后验概率,并将个体分配到概率最高的类。在所有类别中,这些最大后验分配概率 (APPA) 的平均值高于 70% 被认为是可以接受的。使用正确分类、不匹配的几率进一步评估模型的充分性。
LCTMdel_f第 5 步
- 图形表示方法;
- 绘制包含每个类的时间平均轨迹
- 每个类具有 95% 预测区间的平均轨迹图,显示每个类内预测的随机变化
plotpred <- predictY
plototp- 个人水平的“面条图”随时间变化,取决于样本量,可能使用参与者的随机样本
ggplot(bm, aes(x = age, y = bmi)) + geom_lineggplot(bmong) + geom_line点击标题查阅往期内容
R语言用潜类别混合效应模型(Latent Class Mixed Model ,LCMM)分析老年痴呆年龄数据
左右滑动查看更多
01
02
03
04
第 6 步
评估模型。
第 7 步
使用四种方法评估临床特征和合理性;
1. 评估轨迹模式的临床意义,旨在包括至少 1% 的人群的类别
postprb( modf )2. 评估轨迹类别的临床合理性
使用生成的图 来评估预测的趋势对于正在研究的组是否现实。例如,对于研究 BMI,显示下降到 <5 kg/m2 的预测趋势是不现实的。
3. 潜在类别与传统分类的特征列表
使用从所选模型中提取类分配;
然后用描述性变量反馈到主数据集中。
然后可以根据需要将这些制成表格。
等等。
4. 使用 kappa 统计的类成员与传统 BMI 类别成员的一致性
# 定义BMI类别,这些类别的数量需要与类别的数量相等
confusionMatrix(bmi_class, bmclass
kable(y, row.names = )第 8 步
酌情进行敏感性分析。
本文摘选 《 R语言潜类别(分类)轨迹模型LCTM分析体重指数 (BMI)数据可视化 》 ,点击“阅读原文”获取全文完整资料。
点击标题查阅往期内容
R语言用潜类别混合效应模型(Latent Class Mixed Model ,LCMM)分析老年痴呆年龄数据
R语言贝叶斯广义线性混合(多层次/水平/嵌套)模型GLMM、逻辑回归分析教育留级影响因素数据R语言估计多元标记的潜过程混合效应模型(lcmm)分析心理测试的认知过程
R语言因子实验设计nlme拟合非线性混合模型分析有机农业施氮水平
R语言非线性混合效应 NLME模型(固定效应&随机效应)对抗哮喘药物茶碱动力学研究
R语言用线性混合效应(多水平/层次/嵌套)模型分析声调高低与礼貌态度的关系
R语言LME4混合效应模型研究教师的受欢迎程度R语言nlme、nlmer、lme4用(非)线性混合模型non-linear mixed model分析藻类数据实例
R语言混合线性模型、多层次模型、回归模型分析学生平均成绩GPA和可视化
R语言线性混合效应模型(固定效应&随机效应)和交互可视化3案例
R语言用lme4多层次(混合效应)广义线性模型(GLM),逻辑回归分析教育留级调查数据R语言 线性混合效应模型实战案例
R语言混合效应逻辑回归(mixed effects logistic)模型分析肺癌数据
R语言如何用潜类别混合效应模型(LCMM)分析抑郁症状
R语言基于copula的贝叶斯分层混合模型的诊断准确性研究
R语言建立和可视化混合效应模型mixed effect model
R语言LME4混合效应模型研究教师的受欢迎程度
R语言 线性混合效应模型实战案例
R语言用Rshiny探索lme4广义线性混合模型(GLMM)和线性混合模型(LMM)
R语言基于copula的贝叶斯分层混合模型的诊断准确性研究
R语言如何解决线性混合模型中畸形拟合(Singular fit)的问题
基于R语言的lmer混合线性回归模型
R语言用WinBUGS 软件对学术能力测验建立层次(分层)贝叶斯模型
R语言分层线性模型案例
R语言用WinBUGS 软件对学术能力测验(SAT)建立分层模型
使用SAS,Stata,HLM,R,SPSS和Mplus的分层线性模型HLM
R语言用WinBUGS 软件对学术能力测验建立层次(分层)贝叶斯模型
SPSS中的多层(等级)线性模型Multilevel linear models研究整容手术数据
用SPSS估计HLM多层(层次)线性模型模型